 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
How Robust are Randomized Smoothing based Defenses to Data Poisoning?
Dec 02, 2020
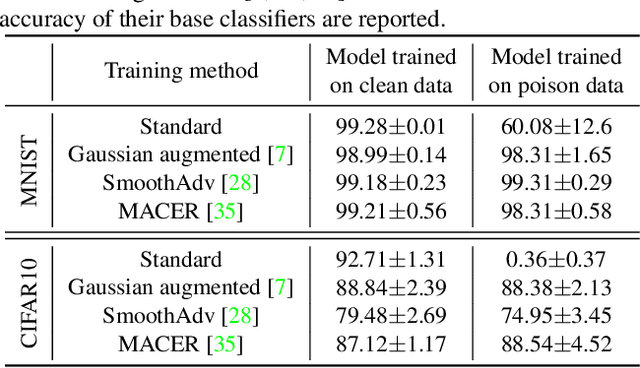
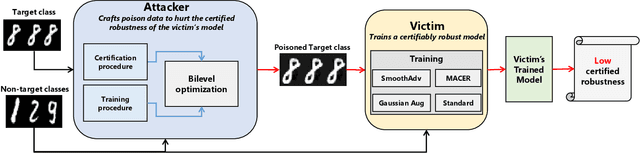

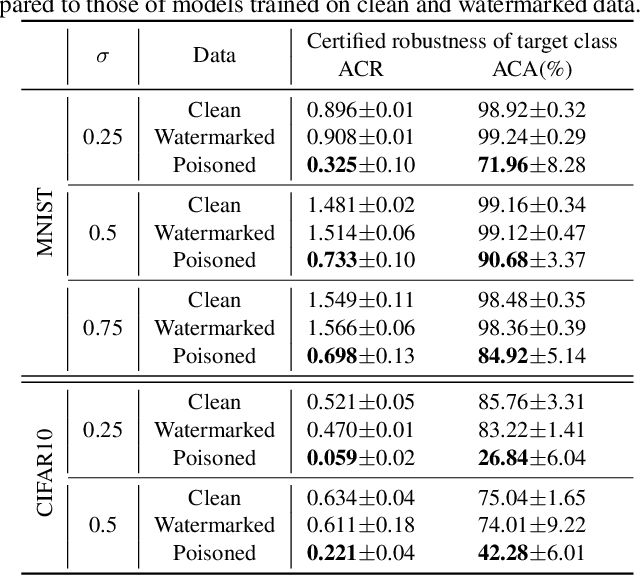
The prediction of certifiably robust classifiers remains constant around a neighborhood of a point, making them resilient to test-time attacks with a guarantee. In this work, we present a previously unrecognized threat to robust machine learning models that highlights the importance of training-data quality in achieving high certified robustness. Specifically, we propose a novel bilevel optimization based data poisoning attack that degrades the robustness guarantees of certifiably robust classifiers. Unlike other data poisoning attacks that reduce the accuracy of the poisoned models on a small set of target points, our attack reduces the average certified radius of an entire target class in the dataset. Moreover, our attack is effective even when the victim trains the models from scratch using state-of-the-art robust training methods such as Gaussian data augmentation\cite{cohen2019certified}, MACER\cite{zhai2020macer}, and SmoothAdv\cite{salman2019provably}. To make the attack harder to detect we use clean-label poisoning points with imperceptibly small distortions. The effectiveness of the proposed method is evaluated by poisoning MNIST and CIFAR10 datasets and training deep neural networks using the previously mentioned robust training methods and certifying their robustness using randomized smoothing. For the models trained with these robust training methods our attack points reduce the average certified radius of the target class by more than 30% and are transferable to models with different architectures and models trained with different robust training methods.
Fairness in Forecasting and Learning Linear Dynamical Systems
Jun 12, 2020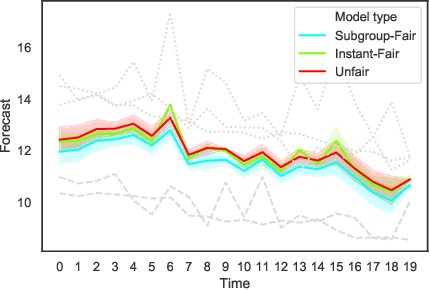
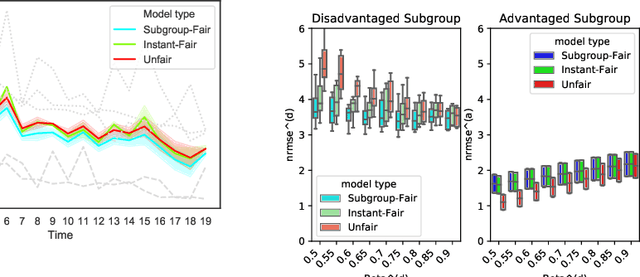
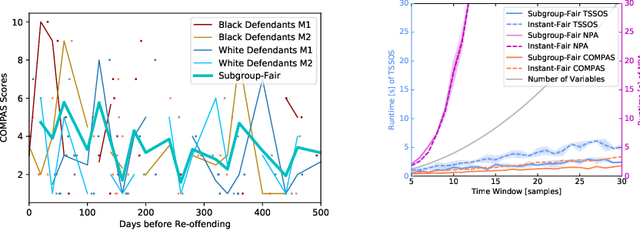
As machine learning becomes more pervasive, the urgency of assuring its fairness increases. Consider training data that capture the behaviour of multiple subgroups of some underlying population over time. When the amounts of training data for the subgroups are not controlled carefully, under-representation bias may arise. We introduce two natural concepts of subgroup fairness and instantaneous fairness to address such under-representation bias in forecasting problems. In particular, we consider the learning of a linear dynamical system from multiple trajectories of varying lengths, and the associated forecasting problems. We provide globally convergent methods for the subgroup-fair and instant-fair estimation using hierarchies of convexifications of non-commutative polynomial optimisation problems. We demonstrate both the beneficial impact of fairness considerations on the statistical performance and the encouraging effects of exploiting sparsity on the estimators' run-time in our computational experiments.
S3CNet: A Sparse Semantic Scene Completion Network for LiDAR Point Clouds
Dec 16, 2020

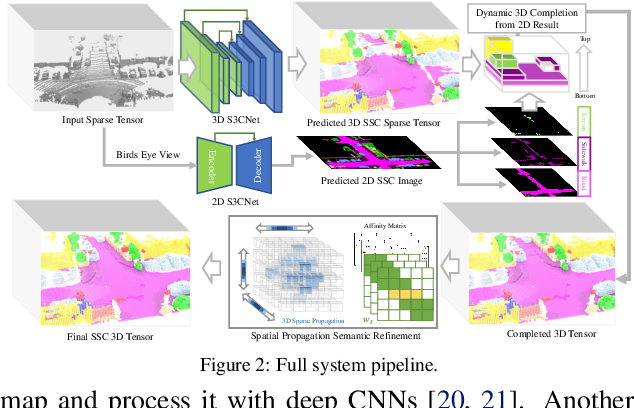
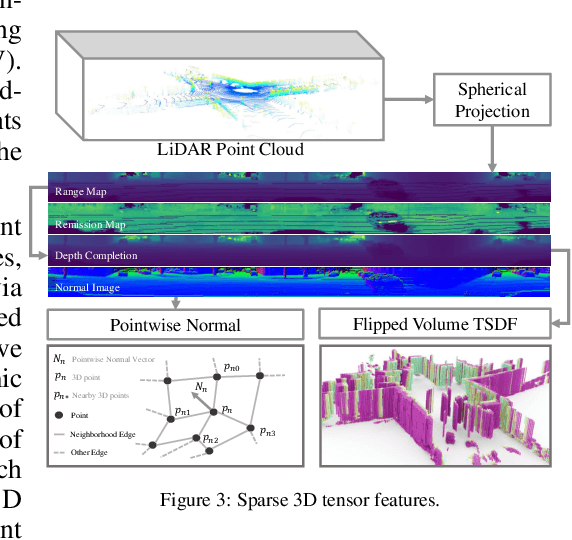
With the increasing reliance of self-driving and similar robotic systems on robust 3D vision, the processing of LiDAR scans with deep convolutional neural networks has become a trend in academia and industry alike. Prior attempts on the challenging Semantic Scene Completion task - which entails the inference of dense 3D structure and associated semantic labels from "sparse" representations - have been, to a degree, successful in small indoor scenes when provided with dense point clouds or dense depth maps often fused with semantic segmentation maps from RGB images. However, the performance of these systems drop drastically when applied to large outdoor scenes characterized by dynamic and exponentially sparser conditions. Likewise, processing of the entire sparse volume becomes infeasible due to memory limitations and workarounds introduce computational inefficiency as practitioners are forced to divide the overall volume into multiple equal segments and infer on each individually, rendering real-time performance impossible. In this work, we formulate a method that subsumes the sparsity of large-scale environments and present S3CNet, a sparse convolution based neural network that predicts the semantically completed scene from a single, unified LiDAR point cloud. We show that our proposed method outperforms all counterparts on the 3D task, achieving state-of-the art results on the SemanticKITTI benchmark. Furthermore, we propose a 2D variant of S3CNet with a multi-view fusion strategy to complement our 3D network, providing robustness to occlusions and extreme sparsity in distant regions. We conduct experiments for the 2D semantic scene completion task and compare the results of our sparse 2D network against several leading LiDAR segmentation models adapted for bird's eye view segmentation on two open-source datasets.
Do You Live a Healthy Life? Analyzing Lifestyle by Visual Life Logging
Nov 24, 2020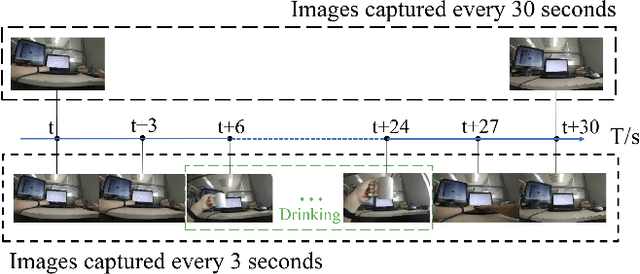

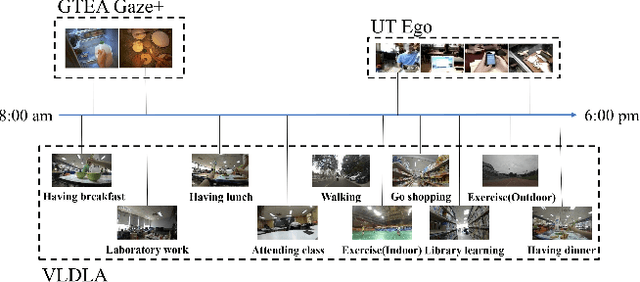

A healthy lifestyle is the key to better health and happiness and has a considerable effect on quality of life and disease prevention. Current lifelogging/egocentric datasets are not suitable for lifestyle analysis; consequently, there is no research on lifestyle analysis in the field of computer vision. In this work, we investigate the problem of lifestyle analysis and build a visual lifelogging dataset for lifestyle analysis (VLDLA). The VLDLA contains images captured by a wearable camera every 3 seconds from 8:00 am to 6:00 pm for seven days. In contrast to current lifelogging/egocentric datasets, our dataset is suitable for lifestyle analysis as images are taken with short intervals to capture activities of short duration; moreover, images are taken continuously from morning to evening to record all the activities performed by a user. Based on our dataset, we classify the user activities in each frame and use three latent fluents of the user, which change over time and are associated with activities, to measure the healthy degree of the user's lifestyle. The scores for the three latent fluents are computed based on recognized activities, and the healthy degree of the lifestyle for the day is determined based on the scores for the latent fluents. Experimental results show that our method can be used to analyze the healthiness of users' lifestyles.
Monitoring Robotic Systems using CSP: From Safety Designs to Safety Monitors
Jul 07, 2020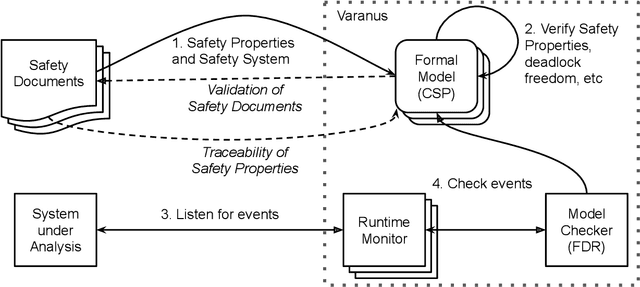
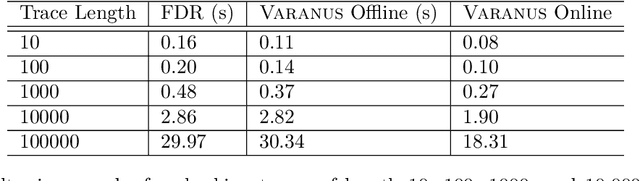
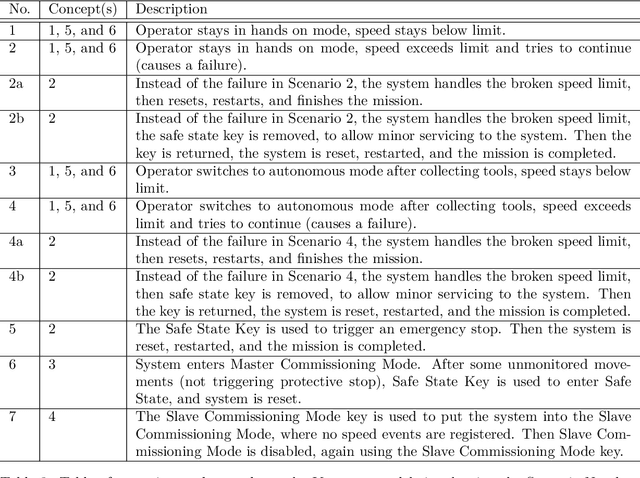
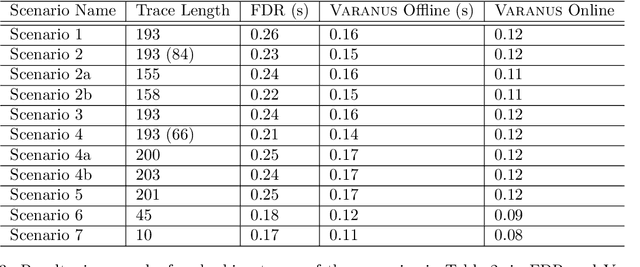
Runtime Verification (RV) involves monitoring a system to check if it satisfies or violates a property. It is effective at bridging the reality gap between design-time assumptions and run-time environments; which is especially useful for robotic systems, because they operate in the real-world. This paper presents an RV approach that uses a Communicating Sequential Processes (CSP) model, derived from natural-language safety documents, as a runtime monitor. We describe our modelling process and monitoring toolchain, Varanus. The approach is demonstrated on a teleoperated robotic system, called MASCOT, which enables remote operations inside a nuclear reactor. We show how the safety design documents for the MASCOT system were modelled (including how modelling revealed an underspecification in the document) and evaluate the utility of the Varanus toolchain. As far as we know, this is the first RV approach to directly use a CSP model. This approach provides traceability of the safety properties from the documentation to the system, a verified monitor for RV, and validation of the safety documents themselves.
FedGAN: Federated Generative AdversarialNetworks for Distributed Data
Jun 12, 2020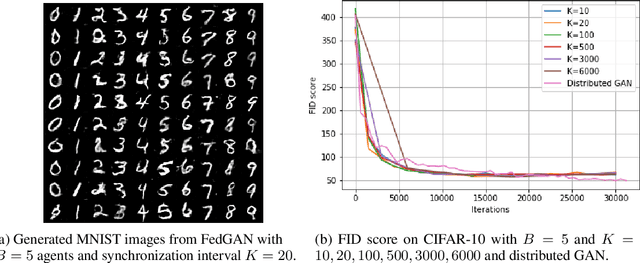
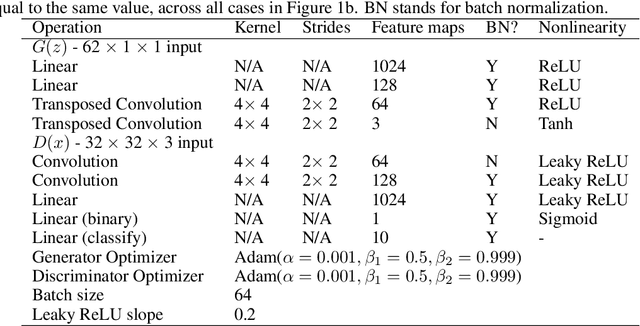
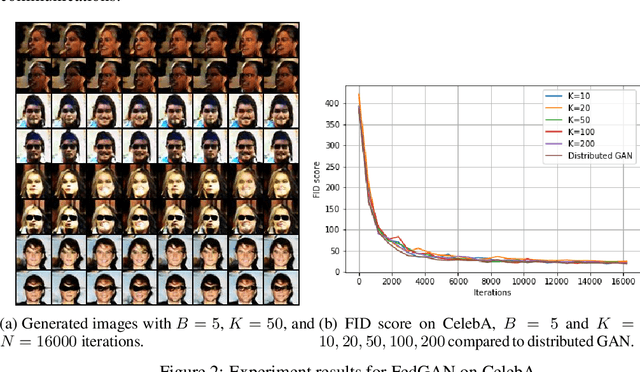
We propose Federated Generative Adversarial Network (FedGAN) for training a GAN across distributed sources of non-independent-and-identically-distributed data sources subject to communication and privacy constraints. Our algorithm uses local generators and discriminators which are periodically synced via an intermediary that averages and broadcasts the generator and discriminator parameters. We theoretically prove the convergence of FedGAN with both equal and two time-scale updates of generator and discriminator, under standard assumptions, using stochastic approximations and communication efficient stochastic gradient descents. We experiment FedGAN on toy examples (2D system, mixed Gaussian, and Swiss role), image datasets (MNIST, CIFAR-10, and CelebA), and time series datasets (household electricity consumption and electric vehicle charging sessions). We show FedGAN converges and has similar performance to general distributed GAN, while reduces communication complexity. We also show its robustness to reduced communications.
Robust Mean Estimation on Highly Incomplete Data with Arbitrary Outliers
Aug 18, 2020
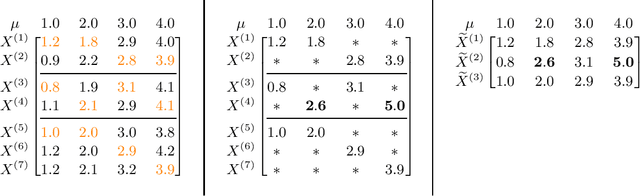
We study the problem of robustly estimating the mean of a $d$-dimensional distribution given $N$ examples, where $\varepsilon N$ examples may be arbitrarily corrupted and most coordinates of every example may be missing. Assuming each coordinate appears in a constant factor more than $\varepsilon N$ examples, we show algorithms that estimate the mean of the distribution with information-theoretically optimal dimension-independent error guarantees in nearly-linear time $\widetilde O(Nd)$. Our results extend recent work on computationally-efficient robust estimation to a more widely applicable incomplete-data setting.
Multi-Agent Coverage in Urban Environments
Aug 17, 2020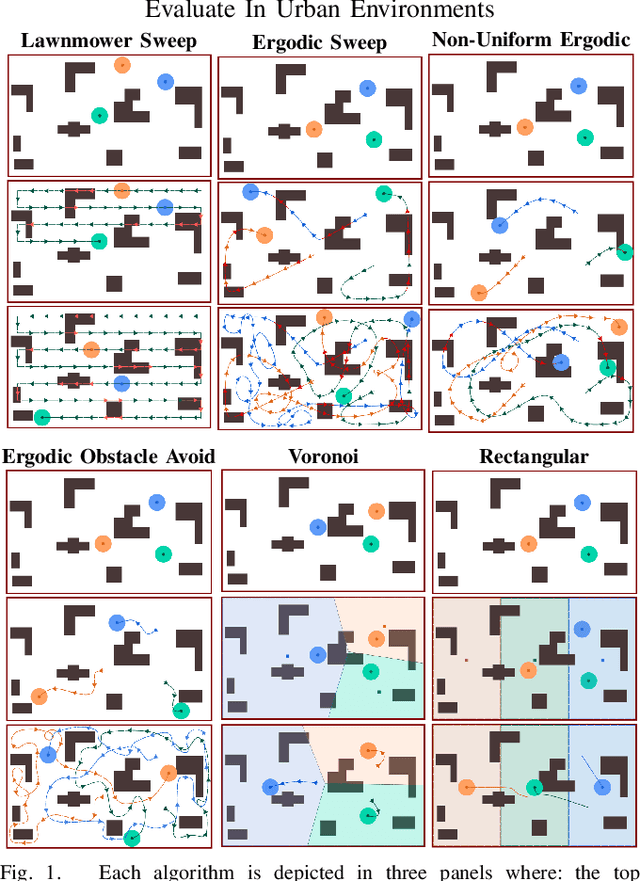
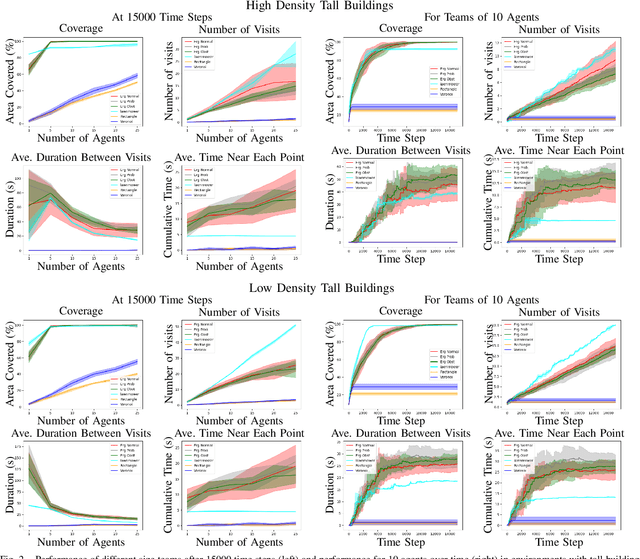
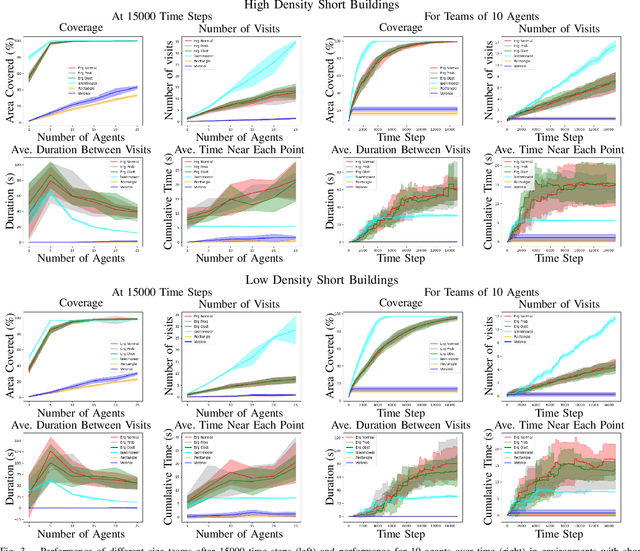
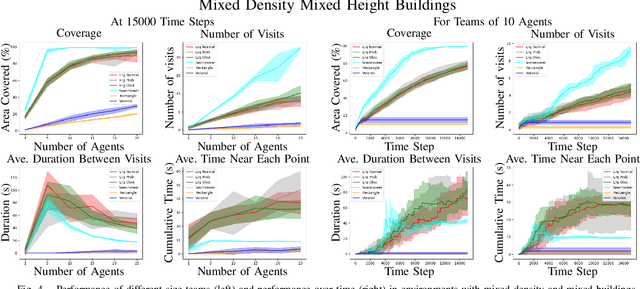
We study multi-agent coverage algorithms for autonomous monitoring and patrol in urban environments. We consider scenarios in which a team of flying agents uses downward facing cameras (or similar sensors) to observe the environment outside of buildings at street-level. Buildings are considered obstacles that impede movement, and cameras are assumed to be ineffective above a maximum altitude. We study multi-agent urban coverage problems related to this scenario, including: (1) static multi-agent urban coverage, in which agents are expected to observe the environment from static locations, and (2) dynamic multi-agent urban coverage where agents move continuously through the environment. We experimentally evaluate six different multi-agent coverage methods, including: three types of ergodic coverage (that avoid buildings in different ways), lawn-mower sweep, voronoi region based control, and a naive grid method. We evaluate all algorithms with respect to four performance metrics (percent coverage, revist count, revist time, and the integral of area viewed over time), across four types of urban environments [low density, high density] x [short buildings, tall buildings], and for team sizes ranging from 2 to 25 agents. We believe this is the first extensive comparison of these methods in an urban setting. Our results highlight how the relative performance of static and dynamic methods changes based on the ratio of team size to search area, as well the relative effects that different characteristics of urban environments (tall, short, dense, sparse, mixed) have on each algorithm.
Efficient planning of peen-forming patterns via artificial neural networks
Aug 18, 2020
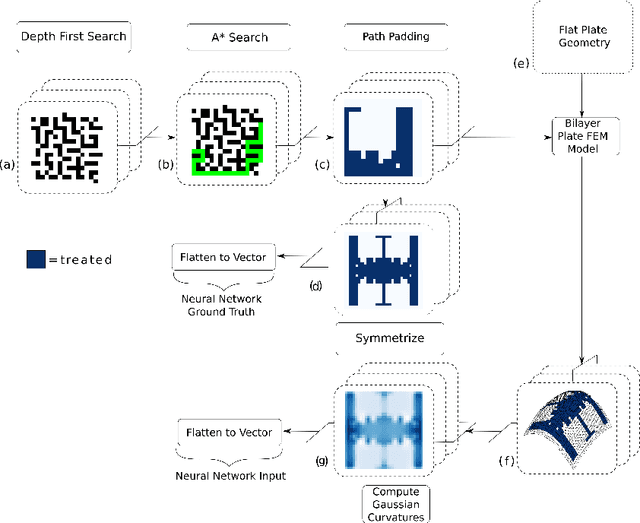
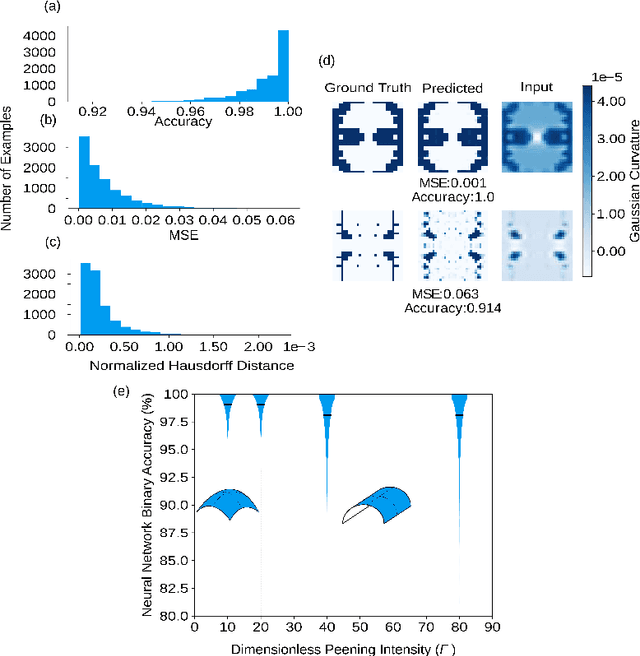
Robust automation of the shot peen forming process demands a closed-loop feedback in which a suitable treatment pattern needs to be found in real-time for each treatment iteration. In this work, we present a method for finding the peen-forming patterns, based on a neural network (NN), which learns the nonlinear function that relates a given target shape (input) to its optimal peening pattern (output), from data generated by finite element simulations. The trained NN yields patterns with an average binary accuracy of 98.8\% with respect to the ground truth in microseconds.
Studying Robustness of Semantic Segmentation under Domain Shift in cardiac MRI
Nov 15, 2020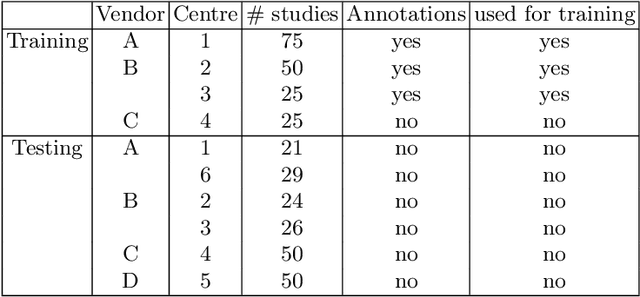
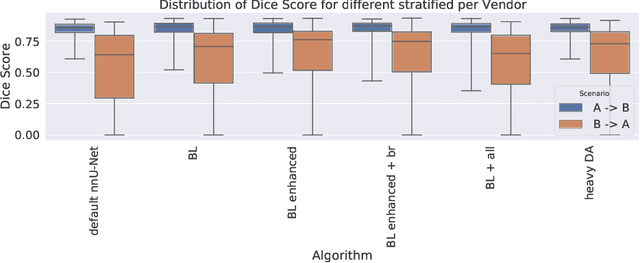

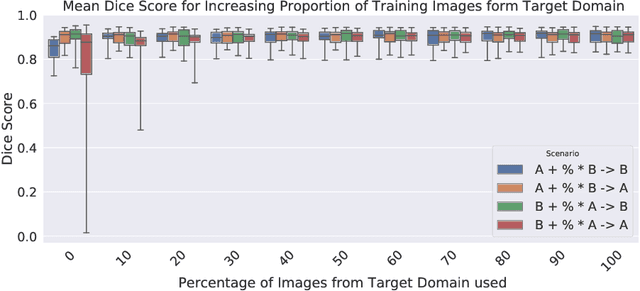
Cardiac magnetic resonance imaging (cMRI) is an integral part of diagnosis in many heart related diseases. Recently, deep neural networks have demonstrated successful automatic segmentation, thus alleviating the burden of time-consuming manual contouring of cardiac structures. Moreover, frameworks such as nnU-Net provide entirely automatic model configuration to unseen datasets enabling out-of-the-box application even by non-experts. However, current studies commonly neglect the clinically realistic scenario, in which a trained network is applied to data from a different domain such as deviating scanners or imaging protocols. This potentially leads to unexpected performance drops of deep learning models in real life applications. In this work, we systematically study challenges and opportunities of domain transfer across images from multiple clinical centres and scanner vendors. In order to maintain out-of-the-box usability, we build upon a fixed U-Net architecture configured by the nnU-net framework to investigate various data augmentation techniques and batch normalization layers as an easy-to-customize pipeline component and provide general guidelines on how to improve domain generalizability abilities in existing deep learning methods. Our proposed method ranked first at the Multi-Centre, Multi-Vendor & Multi-Disease Cardiac Image Segmentation Challenge (M&Ms).