 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Bio-inspired Obstacle Avoidance for Flying Robots with Active Sensing
Oct 10, 2020
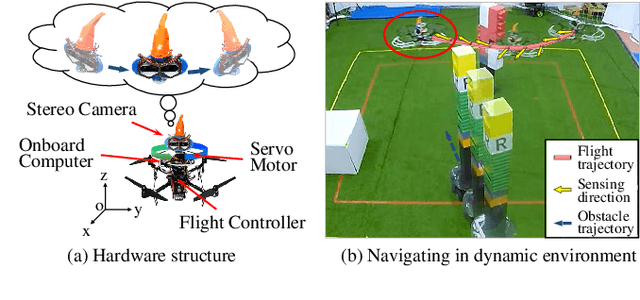
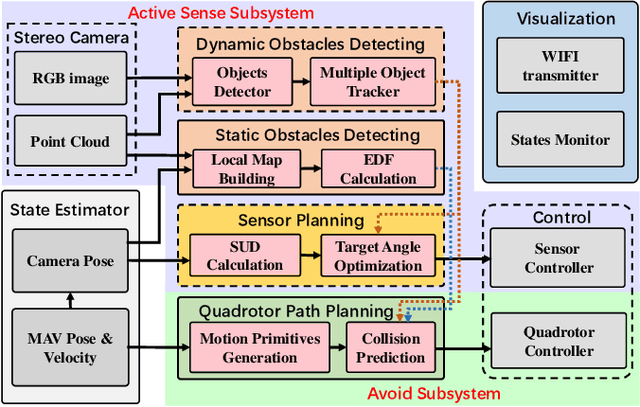
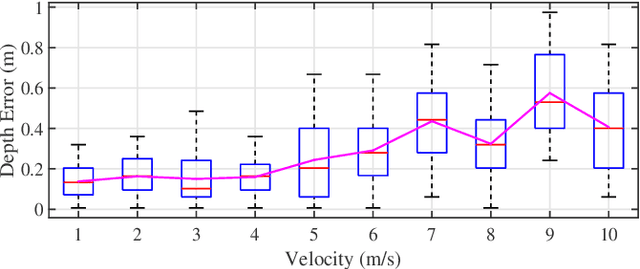
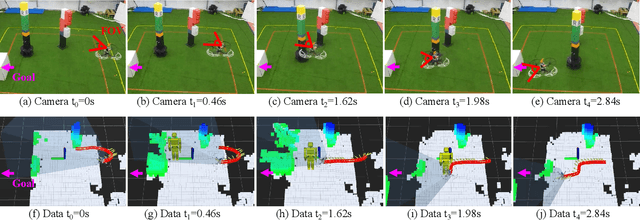
This paper presents a novel vision-based obstacle avoidance system for flying robots working in dynamic environments. Instead of fusing multiple sensors to enlarge the view field, we introduce a bio-inspired solution that utilizes a stereo camera with independent rotational DOF to sense the obstacles actively. In particular, the rotation is planned heuristically by multiple objectives that can benefit flight safety, including tracking dynamic obstacles, observing the heading direction, and exploring the previously unseen area. With this sensing result, a flight path is planned based on real-time sampling and collision checking in state space, which constitutes an active sense and avoid (ASAA) system. Experiments demonstrate that this system is capable of handling environments with dynamic obstacles and abrupt changes in goal direction. Since only one stereo camera is utilized, this system provides a low-cost but effective approach to overcome the view field limitation in visual navigation.
Robust Mean Estimation on Highly Incomplete Data with Arbitrary Outliers
Aug 19, 2020
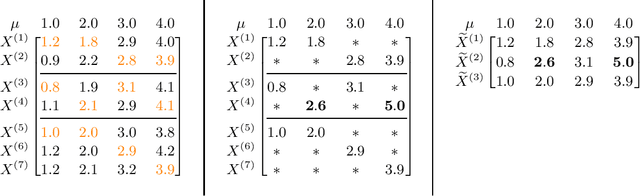
We study the problem of robustly estimating the mean of a $d$-dimensional distribution given $N$ examples, where $\varepsilon N$ examples may be arbitrarily corrupted and most coordinates of every example may be missing. Assuming each coordinate appears in a constant factor more than $\varepsilon N$ examples, we show algorithms that estimate the mean of the distribution with information-theoretically optimal dimension-independent error guarantees in nearly-linear time $\widetilde O(Nd)$. Our results extend recent work on computationally-efficient robust estimation to a more widely applicable incomplete-data setting.
In Depth Bayesian Semantic Scene Completion
Oct 16, 2020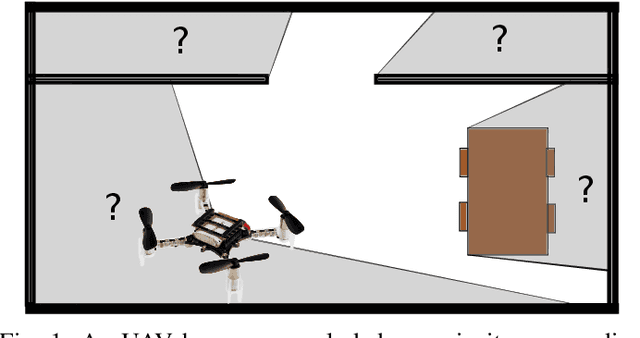
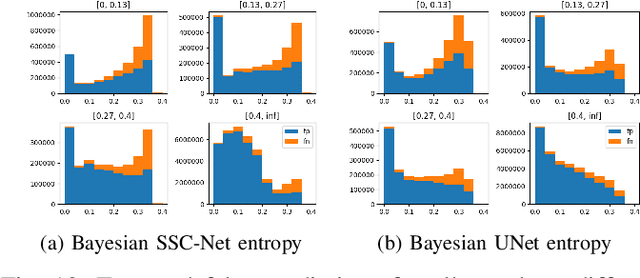
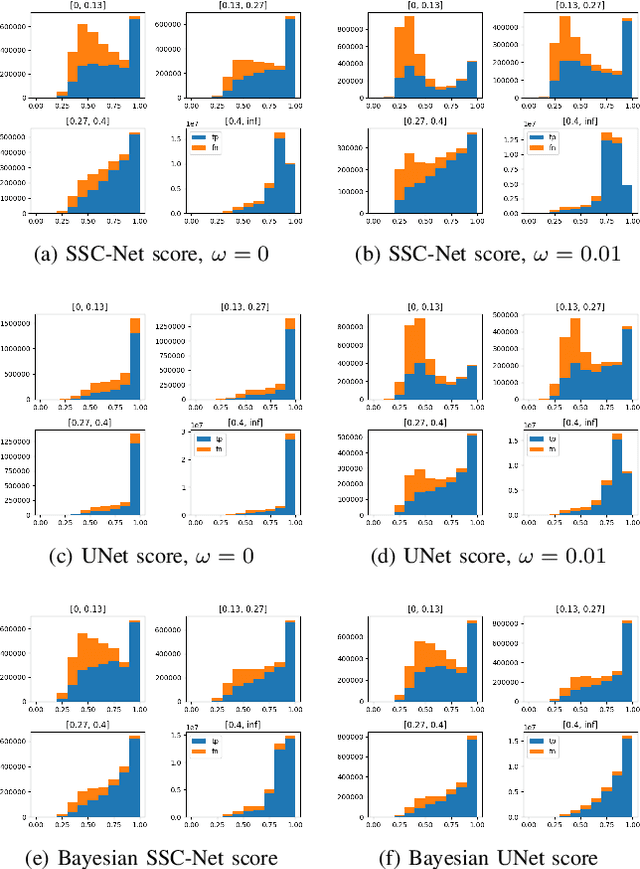
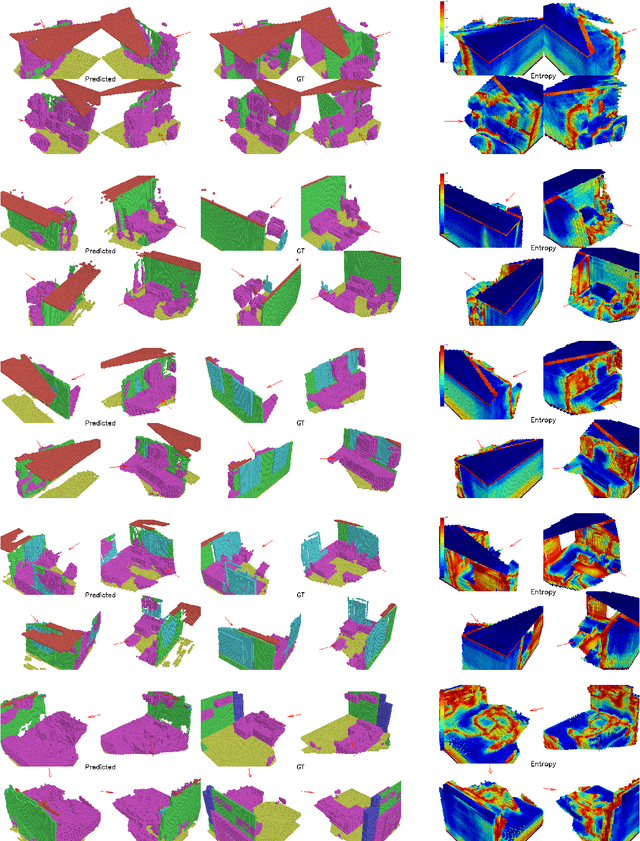
This work studies Semantic Scene Completion which aims to predict a 3D semantic segmentation of our surroundings, even though some areas are occluded. For this we construct a Bayesian Convolutional Neural Network (BCNN), which is not only able to perform the segmentation, but also predict model uncertainty. This is an important feature not present in standard CNNs. We show on the MNIST dataset that the Bayesian approach performs equal or better to the standard CNN when processing digits unseen in the training phase when looking at accuracy, precision and recall. With the added benefit of having better calibrated scores and the ability to express model uncertainty. We then show results for the Semantic Scene Completion task where a category is introduced at test time on the SUNCG dataset. In this more complex task the Bayesian approach outperforms the standard CNN. Showing better Intersection over Union score and excels in Average Precision and separation scores.
Theory and Algorithms for Shapelet-based Multiple-Instance Learning
Jun 12, 2020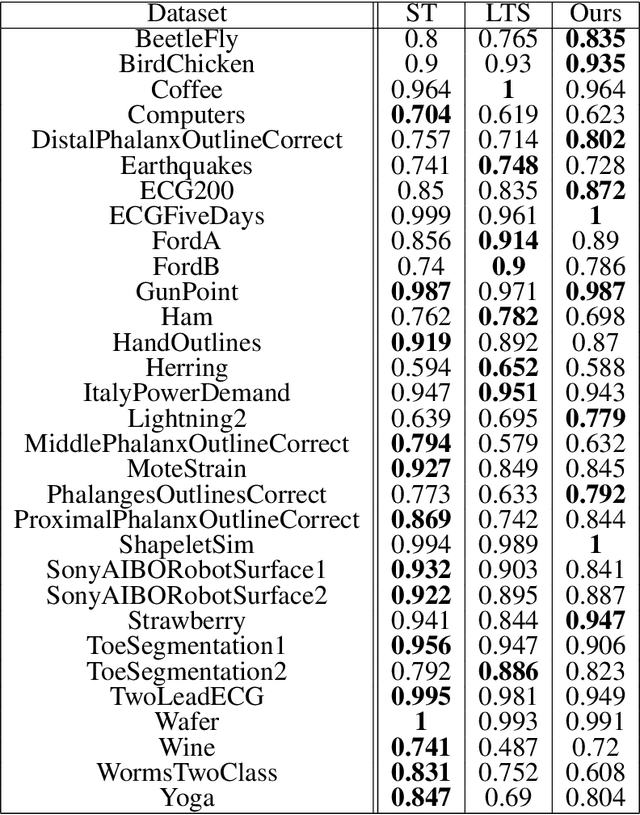
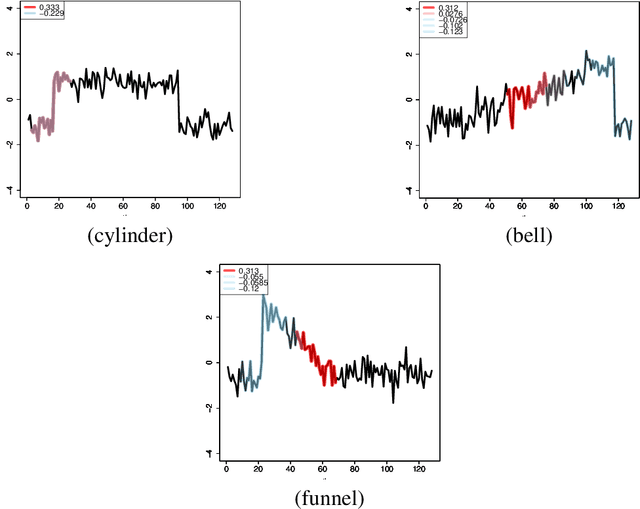
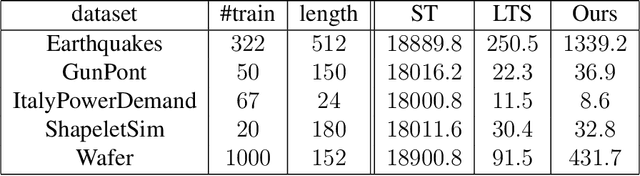
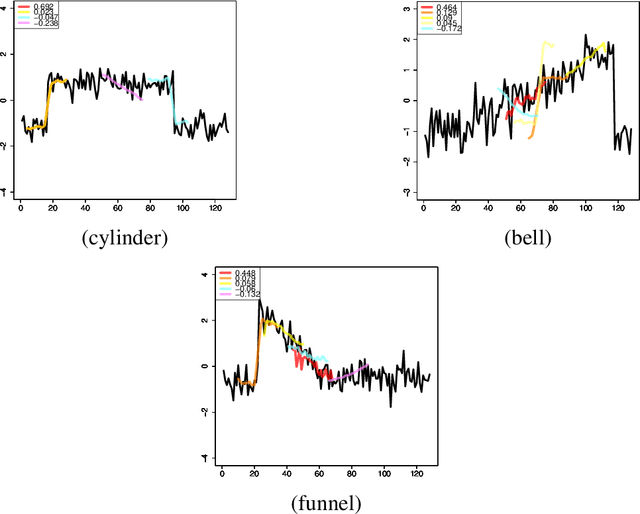
We propose a new formulation of Multiple-Instance Learning (MIL), in which a unit of data consists of a set of instances called a bag. The goal is to find a good classifier of bags based on the similarity with a "shapelet" (or pattern), where the similarity of a bag with a shapelet is the maximum similarity of instances in the bag. In previous work, some of the training instances are chosen as shapelets with no theoretical justification. In our formulation, we use all possible, and thus infinitely many shapelets, resulting in a richer class of classifiers. We show that the formulation is tractable, that is, it can be reduced through Linear Programming Boosting (LPBoost) to Difference of Convex (DC) programs of finite (actually polynomial) size. Our theoretical result also gives justification to the heuristics of some of the previous work. The time complexity of the proposed algorithm highly depends on the size of the set of all instances in the training sample. To apply to the data containing a large number of instances, we also propose a heuristic option of the algorithm without the loss of the theoretical guarantee. Our empirical study demonstrates that our algorithm uniformly works for Shapelet Learning tasks on time-series classification and various MIL tasks with comparable accuracy to the existing methods. Moreover, we show that the proposed heuristics allow us to achieve the result with reasonable computational time.
Properly Learning Poisson Binomial Distributions in Almost Polynomial Time
Nov 12, 2015We give an algorithm for properly learning Poisson binomial distributions. A Poisson binomial distribution (PBD) of order $n$ is the discrete probability distribution of the sum of $n$ mutually independent Bernoulli random variables. Given $\widetilde{O}(1/\epsilon^2)$ samples from an unknown PBD $\mathbf{p}$, our algorithm runs in time $(1/\epsilon)^{O(\log \log (1/\epsilon))}$, and outputs a hypothesis PBD that is $\epsilon$-close to $\mathbf{p}$ in total variation distance. The previously best known running time for properly learning PBDs was $(1/\epsilon)^{O(\log(1/\epsilon))}$. As one of our main contributions, we provide a novel structural characterization of PBDs. We prove that, for all $\epsilon >0,$ there exists an explicit collection $\cal{M}$ of $(1/\epsilon)^{O(\log \log (1/\epsilon))}$ vectors of multiplicities, such that for any PBD $\mathbf{p}$ there exists a PBD $\mathbf{q}$ with $O(\log(1/\epsilon))$ distinct parameters whose multiplicities are given by some element of ${\cal M}$, such that $\mathbf{q}$ is $\epsilon$-close to $\mathbf{p}$. Our proof combines tools from Fourier analysis and algebraic geometry. Our approach to the proper learning problem is as follows: Starting with an accurate non-proper hypothesis, we fit a PBD to this hypothesis. More specifically, we essentially start with the hypothesis computed by the computationally efficient non-proper learning algorithm in our recent work~\cite{DKS15}. Our aforementioned structural characterization allows us to reduce the corresponding fitting problem to a collection of $(1/\epsilon)^{O(\log \log(1/\epsilon))}$ systems of low-degree polynomial inequalities. We show that each such system can be solved in time $(1/\epsilon)^{O(\log \log(1/\epsilon))}$, which yields the overall running time of our algorithm.
Evorus: A Crowd-powered Conversational Assistant Built to Automate Itself Over Time
Jan 10, 2018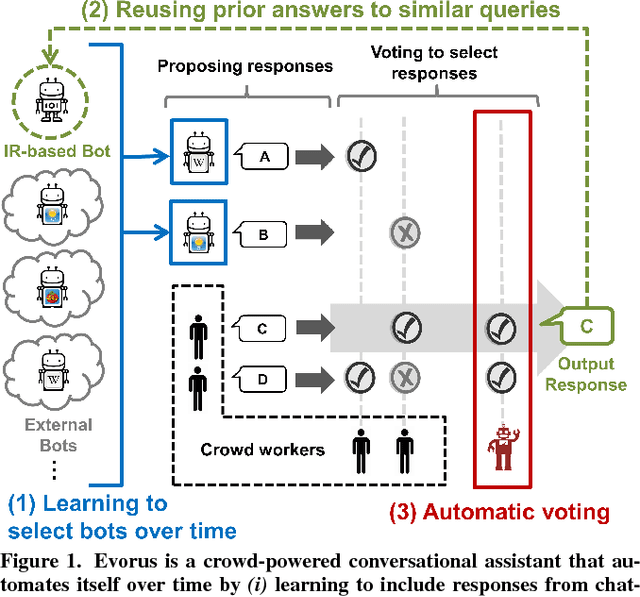
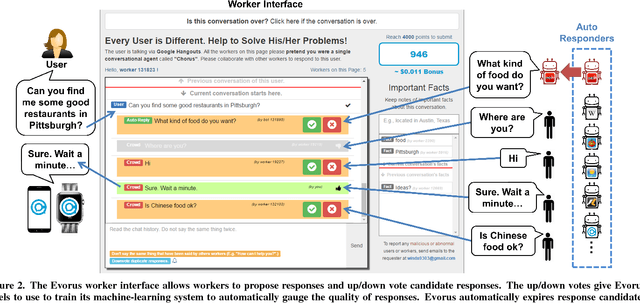
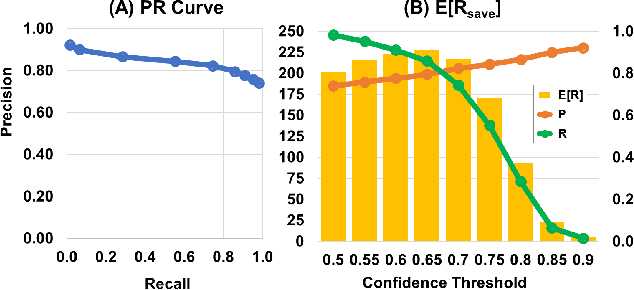
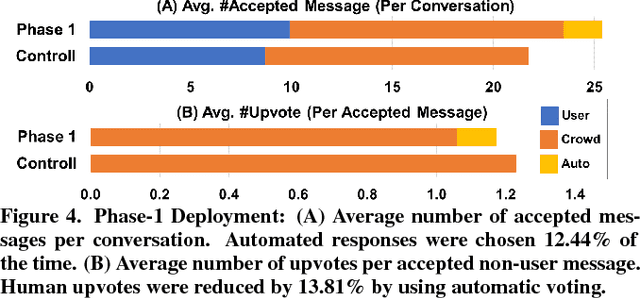
Crowd-powered conversational assistants have been shown to be more robust than automated systems, but do so at the cost of higher response latency and monetary costs. A promising direction is to combine the two approaches for high quality, low latency, and low cost solutions. In this paper, we introduce Evorus, a crowd-powered conversational assistant built to automate itself over time by (i) allowing new chatbots to be easily integrated to automate more scenarios, (ii) reusing prior crowd answers, and (iii) learning to automatically approve response candidates. Our 5-month-long deployment with 80 participants and 281 conversations shows that Evorus can automate itself without compromising conversation quality. Crowd-AI architectures have long been proposed as a way to reduce cost and latency for crowd-powered systems; Evorus demonstrates how automation can be introduced successfully in a deployed system. Its architecture allows future researchers to make further innovation on the underlying automated components in the context of a deployed open domain dialog system.
Multivariate Time-series Similarity Assessment via Unsupervised Representation Learning and Stratified Locality Sensitive Hashing: Application to Early Acute Hypotensive Episode Detection
Dec 04, 2018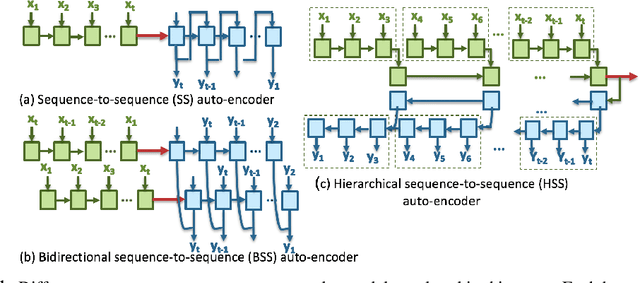
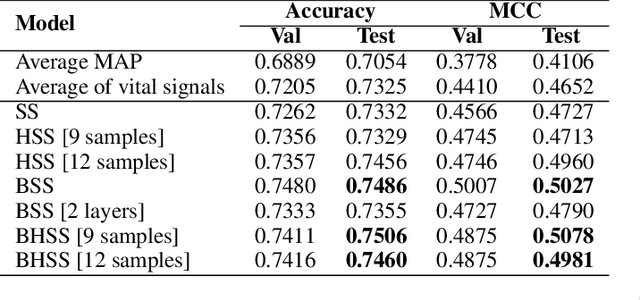
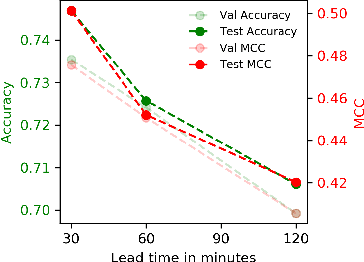
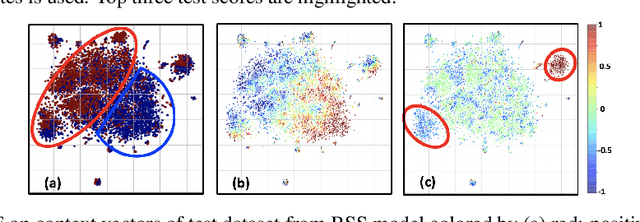
Timely prediction of clinically critical events in Intensive Care Unit (ICU) is important for improving care and survival rate. Most of the existing approaches are based on the application of various classification methods on explicitly extracted statistical features from vital signals. In this work, we propose to eliminate the high cost of engineering hand-crafted features from multivariate time-series of physiologic signals by learning their representation with a sequence-to-sequence auto-encoder. We then propose to hash the learned representations to enable signal similarity assessment for the prediction of critical events. We apply this methodological framework to predict Acute Hypotensive Episodes (AHE) on a large and diverse dataset of vital signal recordings. Experiments demonstrate the ability of the presented framework in accurately predicting an upcoming AHE.
Identifying Pairs in Simulated Bio-Medical Time-Series
May 12, 2013
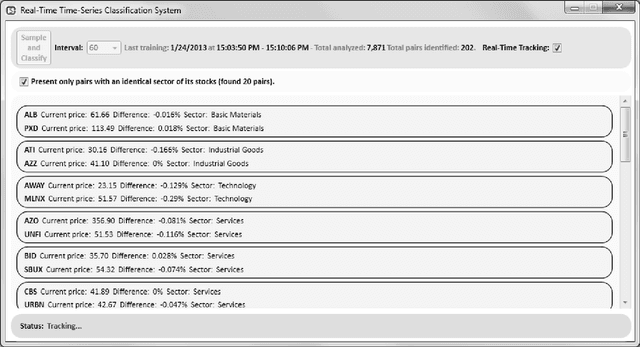
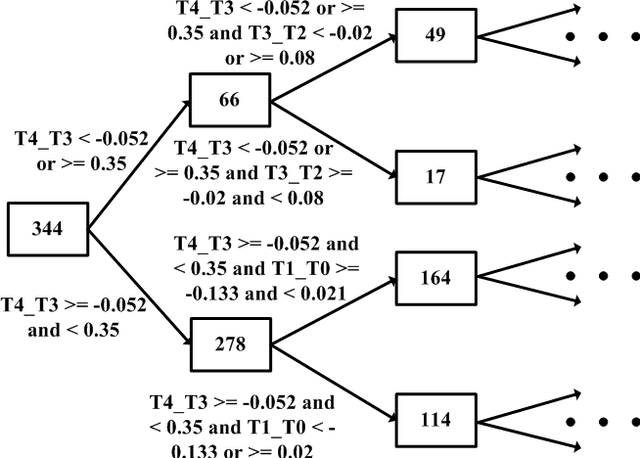

The paper presents a time-series-based classification approach to identify similarities in pairs of simulated human-generated patterns. An example for a pattern is a time-series representing a heart rate during a specific time-range, wherein the time-series is a sequence of data points that represent the changes in the heart rate values. A bio-medical simulator system was developed to acquire a collection of 7,871 price patterns of financial instruments. The financial instruments traded in real-time on three American stock exchanges, NASDAQ, NYSE, and AMEX, simulate bio-medical measurements. The system simulates a human in which each price pattern represents one bio-medical sensor. Data provided during trading hours from the stock exchanges allowed real-time classification. Classification is based on new machine learning techniques: self-labeling, which allows the application of supervised learning methods on unlabeled time-series and similarity ranking, which applied on a decision tree learning algorithm to classify time-series regardless of type and quantity.
Locally adaptive factor processes for multivariate time series
Jun 21, 2013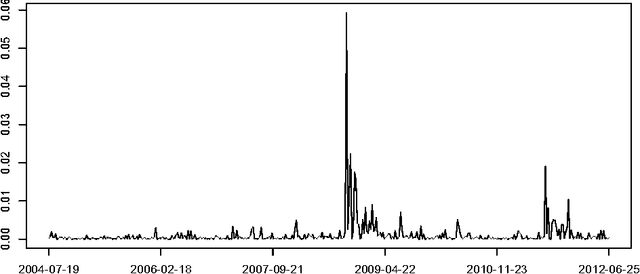
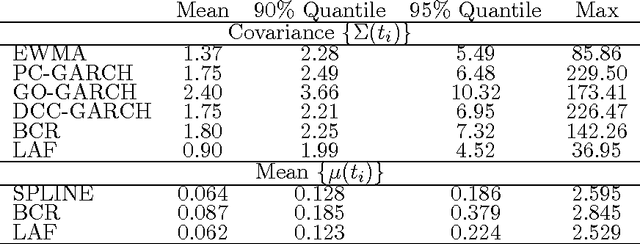
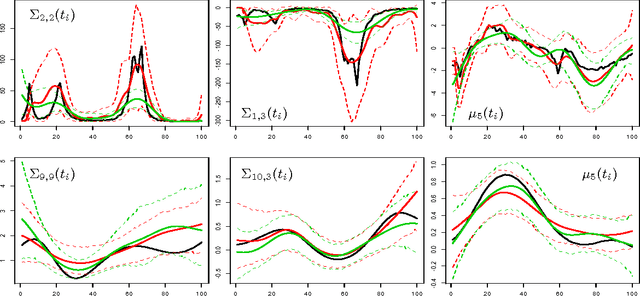
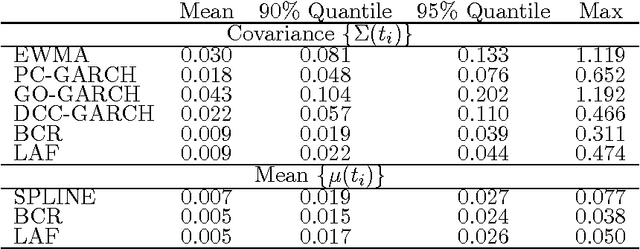
In modeling multivariate time series, it is important to allow time-varying smoothness in the mean and covariance process. In particular, there may be certain time intervals exhibiting rapid changes and others in which changes are slow. If such time-varying smoothness is not accounted for, one can obtain misleading inferences and predictions, with over-smoothing across erratic time intervals and under-smoothing across times exhibiting slow variation. This can lead to mis-calibration of predictive intervals, which can be substantially too narrow or wide depending on the time. We propose a locally adaptive factor process for characterizing multivariate mean-covariance changes in continuous time, allowing locally varying smoothness in both the mean and covariance matrix. This process is constructed utilizing latent dictionary functions evolving in time through nested Gaussian processes and linearly related to the observed data with a sparse mapping. Using a differential equation representation, we bypass usual computational bottlenecks in obtaining MCMC and online algorithms for approximate Bayesian inference. The performance is assessed in simulations and illustrated in a financial application.
Solving Mixed Integer Programs Using Neural Networks
Dec 23, 2020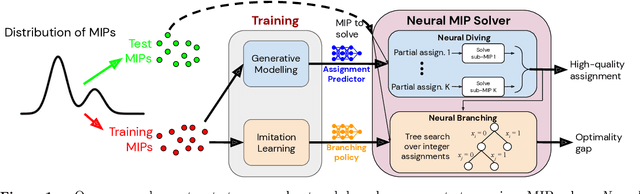
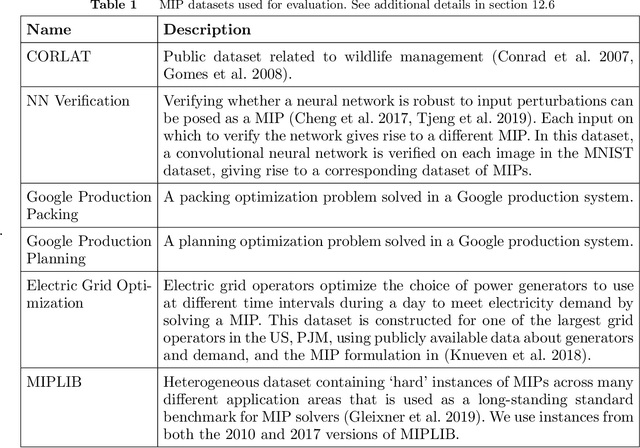
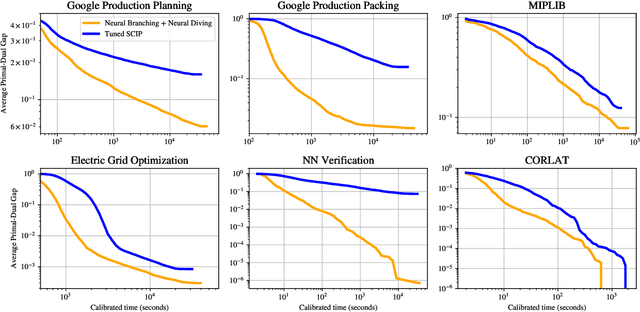
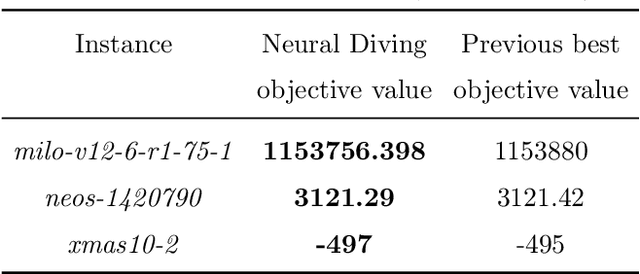
Mixed Integer Programming (MIP) solvers rely on an array of sophisticated heuristics developed with decades of research to solve large-scale MIP instances encountered in practice. Machine learning offers to automatically construct better heuristics from data by exploiting shared structure among instances in the data. This paper applies learning to the two key sub-tasks of a MIP solver, generating a high-quality joint variable assignment, and bounding the gap in objective value between that assignment and an optimal one. Our approach constructs two corresponding neural network-based components, Neural Diving and Neural Branching, to use in a base MIP solver such as SCIP. Neural Diving learns a deep neural network to generate multiple partial assignments for its integer variables, and the resulting smaller MIPs for un-assigned variables are solved with SCIP to construct high quality joint assignments. Neural Branching learns a deep neural network to make variable selection decisions in branch-and-bound to bound the objective value gap with a small tree. This is done by imitating a new variant of Full Strong Branching we propose that scales to large instances using GPUs. We evaluate our approach on six diverse real-world datasets, including two Google production datasets and MIPLIB, by training separate neural networks on each. Most instances in all the datasets combined have $10^3-10^6$ variables and constraints after presolve, which is significantly larger than previous learning approaches. Comparing solvers with respect to primal-dual gap averaged over a held-out set of instances, the learning-augmented SCIP is 2x to 10x better on all datasets except one on which it is $10^5$x better, at large time limits. To the best of our knowledge, ours is the first learning approach to demonstrate such large improvements over SCIP on both large-scale real-world application datasets and MIPLIB.