 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Semi-supervised Knowledge Distillation for Overlapping Cervical Cell Instance Segmentation
Jul 21, 2020
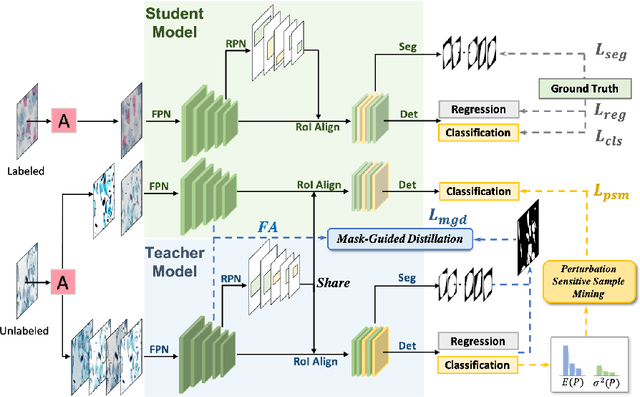
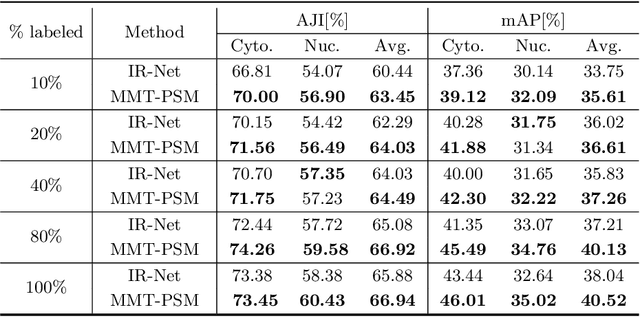
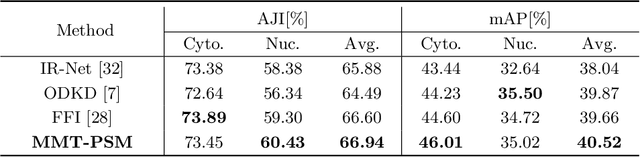

Deep learning methods show promising results for overlapping cervical cell instance segmentation. However, in order to train a model with good generalization ability, voluminous pixel-level annotations are demanded which is quite expensive and time-consuming for acquisition. In this paper, we propose to leverage both labeled and unlabeled data for instance segmentation with improved accuracy by knowledge distillation. We propose a novel Mask-guided Mean Teacher framework with Perturbation-sensitive Sample Mining (MMT-PSM), which consists of a teacher and a student network during training. Two networks are encouraged to be consistent both in feature and semantic level under small perturbations. The teacher's self-ensemble predictions from $K$-time augmented samples are used to construct the reliable pseudo-labels for optimizing the student. We design a novel strategy to estimate the sensitivity to perturbations for each proposal and select informative samples from massive cases to facilitate fast and effective semantic distillation. In addition, to eliminate the unavoidable noise from the background region, we propose to use the predicted segmentation mask as guidance to enforce the feature distillation in the foreground region. Experiments show that the proposed method improves the performance significantly compared with the supervised method learned from labeled data only, and outperforms state-of-the-art semi-supervised methods.
Quantization in Relative Gradient Angle Domain For Building Polygon Estimation
Jul 10, 2020
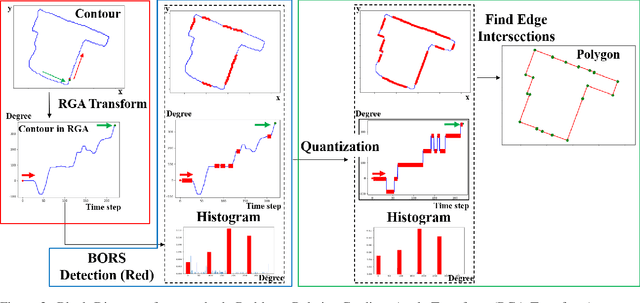
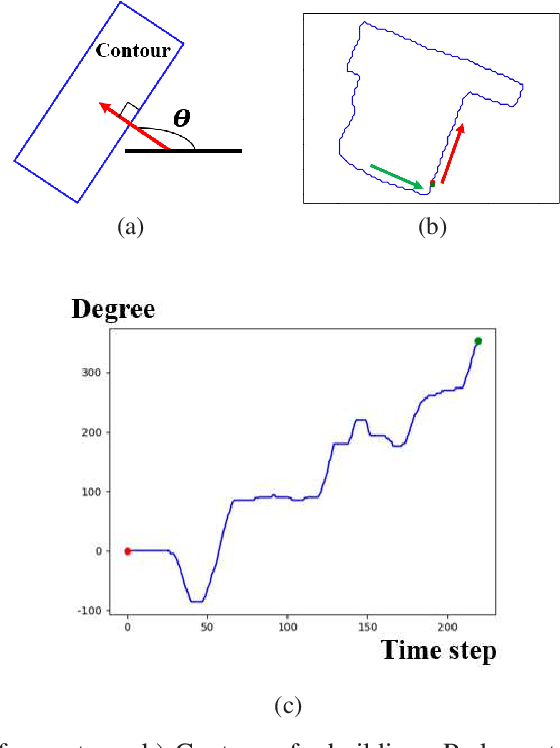
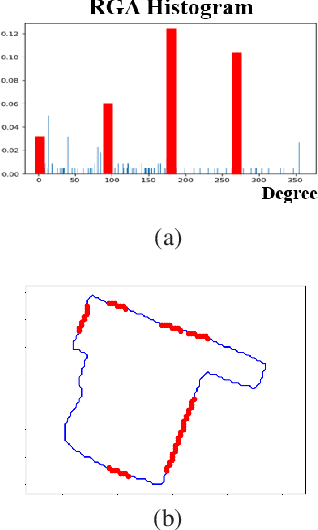
Building footprint extraction in remote sensing data benefits many important applications, such as urban planning and population estimation. Recently, rapid development of Convolutional Neural Networks (CNNs) and open-sourced high resolution satellite building image datasets have pushed the performance boundary further for automated building extractions. However, CNN approaches often generate imprecise building morphologies including noisy edges and round corners. In this paper, we leverage the performance of CNNs, and propose a module that uses prior knowledge of building corners to create angular and concise building polygons from CNN segmentation outputs. We describe a new transform, Relative Gradient Angle Transform (RGA Transform) that converts object contours from time vs. space to time vs. angle. We propose a new shape descriptor, Boundary Orientation Relation Set (BORS), to describe angle relationship between edges in RGA domain, such as orthogonality and parallelism. Finally, we develop an energy minimization framework that makes use of the angle relationship in BORS to straighten edges and reconstruct sharp corners, and the resulting corners create a polygon. Experimental results demonstrate that our method refines CNN output from a rounded approximation to a more clear-cut angular shape of the building footprint.
L$^2$C -- Learning to Learn to Compress
Jul 31, 2020
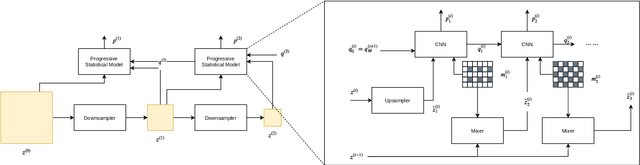
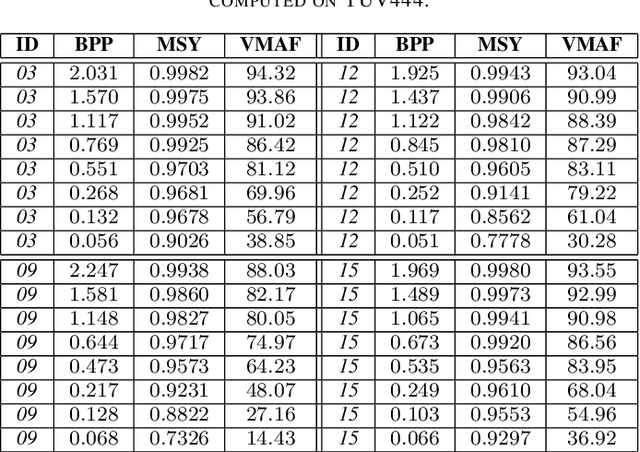

In this paper we present an end-to-end meta-learned system for image compression. Traditional machine learning based approaches to image compression train one or more neural network for generalization performance. However, at inference time, the encoder or the latent tensor output by the encoder can be optimized for each test image. This optimization can be regarded as a form of adaptation or benevolent overfitting to the input content. In order to reduce the gap between training and inference conditions, we propose a new training paradigm for learned image compression, which is based on meta-learning. In a first phase, the neural networks are trained normally. In a second phase, the Model-Agnostic Meta-learning approach is adapted to the specific case of image compression, where the inner-loop performs latent tensor overfitting, and the outer loop updates both encoder and decoder neural networks based on the overfitting performance. Furthermore, after meta-learning, we propose to overfit and cluster the bias terms of the decoder on training image patches, so that at inference time the optimal content-specific bias terms can be selected at encoder-side. Finally, we propose a new probability model for lossless compression, which combines concepts from both multi-scale and super-resolution probability model approaches. We show the benefits of all our proposed ideas via carefully designed experiments.
The Case for Retraining of ML Models for IoT Device Identification at the Edge
Nov 17, 2020
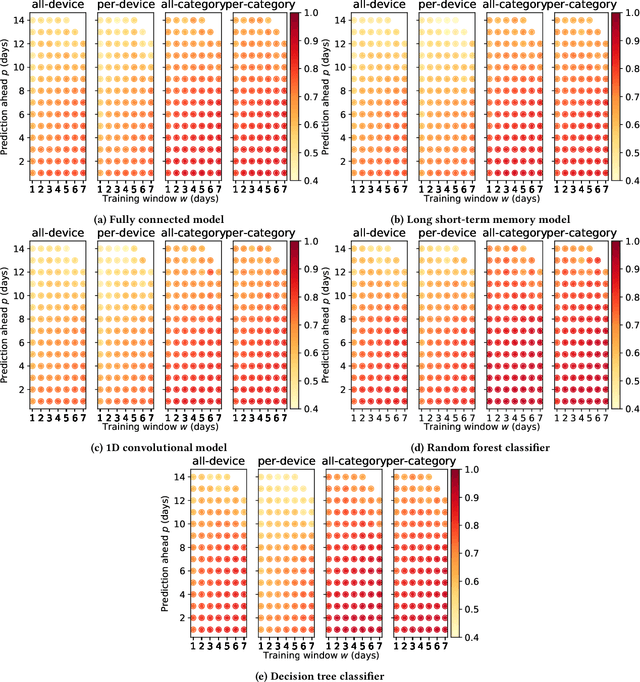
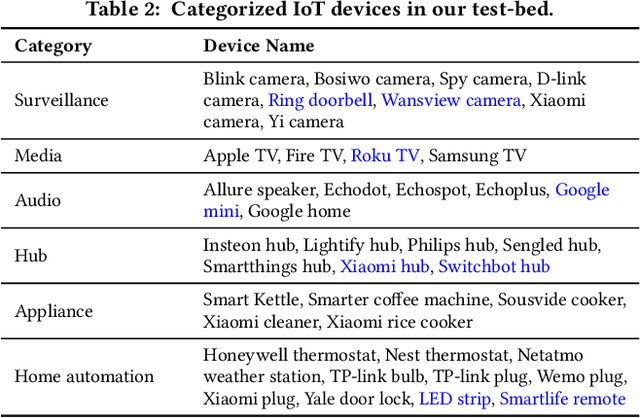
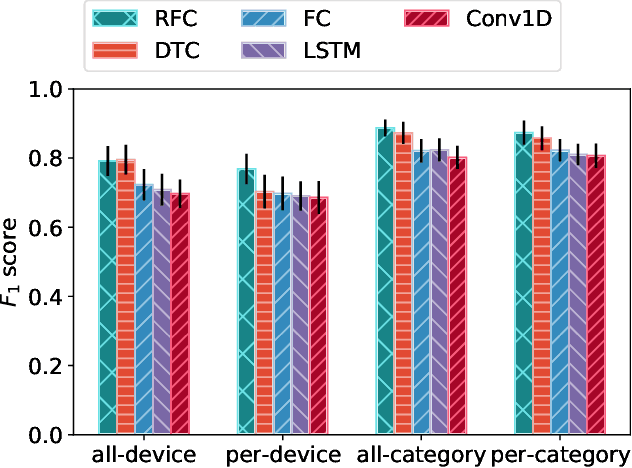
Internet-of-Things (IoT) devices are known to be the source of many security problems, and as such they would greatly benefit from automated management. This requires robustly identifying devices so that appropriate network security policies can be applied. We address this challenge by exploring how to accurately identify IoT devices based on their network behavior, using resources available at the edge of the network. In this paper, we compare the accuracy of five different machine learning models (tree-based and neural network-based) for identifying IoT devices by using packet trace data from a large IoT test-bed, showing that all models need to be updated over time to avoid significant degradation in accuracy. In order to effectively update the models, we find that it is necessary to use data gathered from the deployment environment, e.g., the household. We therefore evaluate our approach using hardware resources and data sources representative of those that would be available at the edge of the network, such as in an IoT deployment. We show that updating neural network-based models at the edge is feasible, as they require low computational and memory resources and their structure is amenable to being updated. Our results show that it is possible to achieve device identification and categorization with over 80% and 90% accuracy respectively at the edge.
Deep Networks for Direction-of-Arrival Estimation in Low SNR
Nov 17, 2020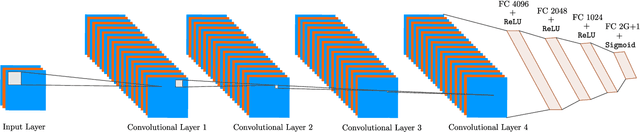
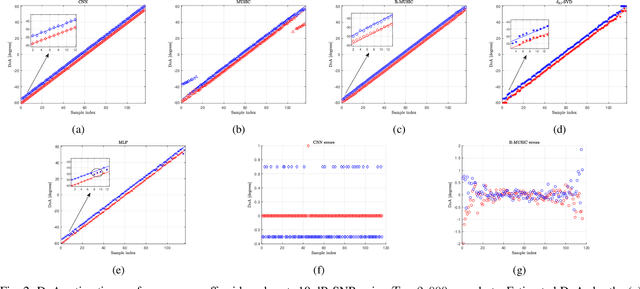
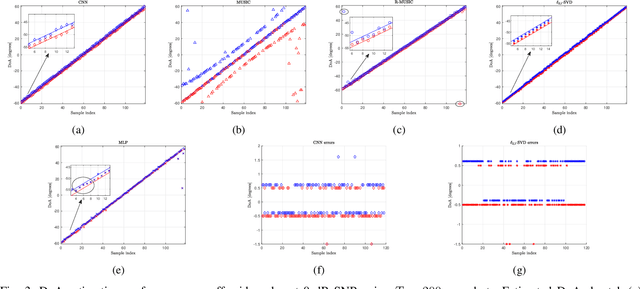
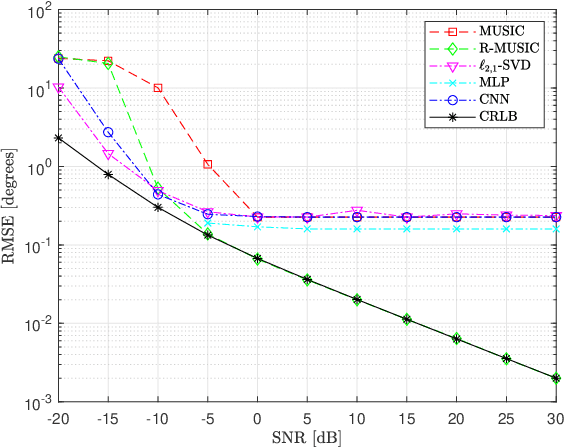
In this work, we consider direction-of-arrival (DoA) estimation in the presence of extreme noise using Deep Learning (DL). In particular, we introduce a Convolutional Neural Network (CNN) that is trained from mutli-channel data of the true array manifold matrix and is able to predict angular directions using the sample covariance estimate. We model the problem as a multi-label classification task and train a CNN in the low-SNR regime to predict DoAs across all SNRs. The proposed architecture demonstrates enhanced robustness in the presence of noise, and resilience to a small number of snapshots. Moreover, it is able to resolve angles within the grid resolution. Experimental results demonstrate significant performance gains in the low-SNR regime compared to state-of-the-art methods and without the requirement of any parameter tuning. We relax the assumption that the number of sources is known a priori and present a training method, where the CNN learns to infer the number of sources jointly with the DoAs. Simulation results demonstrate that the proposed CNN can accurately estimate off-grid angles in low SNR, while at the same time the number of sources is successfully inferred for a sufficient number of snapshots. Our robust solution can be applied in several fields, ranging from wireless array sensors to acoustic microphones or sonars.
Differentiable Weighted Finite-State Transducers
Oct 02, 2020

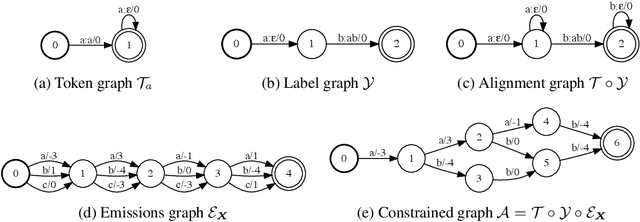
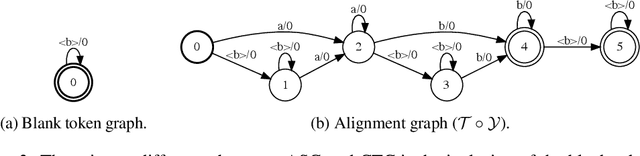
We introduce a framework for automatic differentiation with weighted finite-state transducers (WFSTs) allowing them to be used dynamically at training time. Through the separation of graphs from operations on graphs, this framework enables the exploration of new structured loss functions which in turn eases the encoding of prior knowledge into learning algorithms. We show how the framework can combine pruning and back-off in transition models with various sequence-level loss functions. We also show how to learn over the latent decomposition of phrases into word pieces. Finally, to demonstrate that WFSTs can be used in the interior of a deep neural network, we propose a convolutional WFST layer which maps lower-level representations to higher-level representations and can be used as a drop-in replacement for a traditional convolution. We validate these algorithms with experiments in handwriting recognition and speech recognition.
Leveraging Discourse Rewards for Document-Level Neural Machine Translation
Oct 19, 2020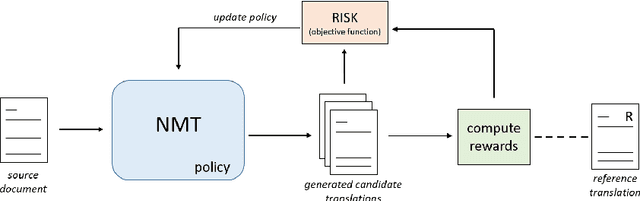
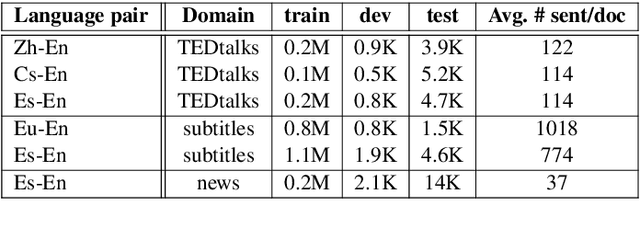
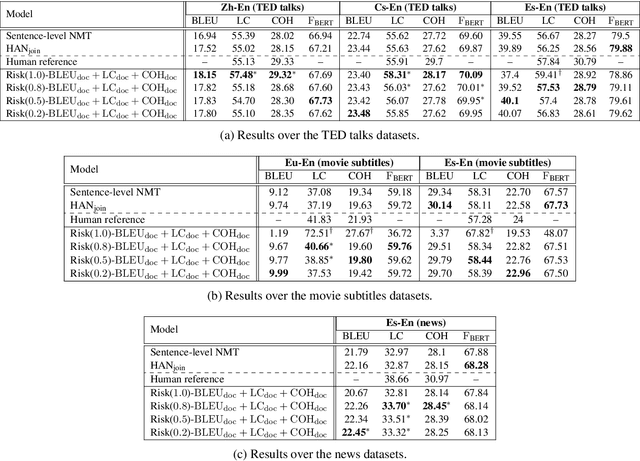
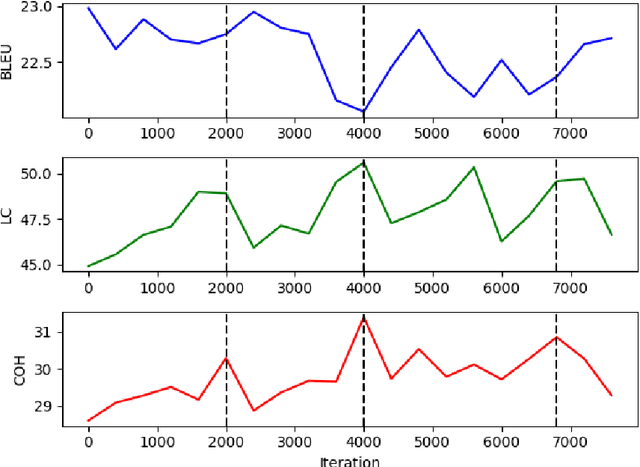
Document-level machine translation focuses on the translation of entire documents from a source to a target language. It is widely regarded as a challenging task since the translation of the individual sentences in the document needs to retain aspects of the discourse at document level. However, document-level translation models are usually not trained to explicitly ensure discourse quality. Therefore, in this paper we propose a training approach that explicitly optimizes two established discourse metrics, lexical cohesion (LC) and coherence (COH), by using a reinforcement learning objective. Experiments over four different language pairs and three translation domains have shown that our training approach has been able to achieve more cohesive and coherent document translations than other competitive approaches, yet without compromising the faithfulness to the reference translation. In the case of the Zh-En language pair, our method has achieved an improvement of 2.46 percentage points (pp) in LC and 1.17 pp in COH over the runner-up, while at the same time improving 0.63 pp in BLEU score and 0.47 pp in F_BERT.
Understanding Clinical Trial Reports: Extracting Medical Entities and Their Relations
Oct 08, 2020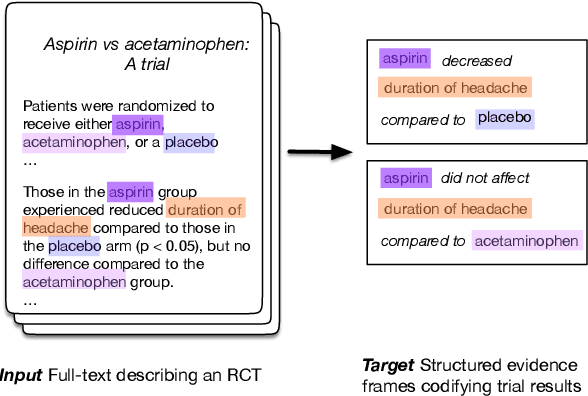
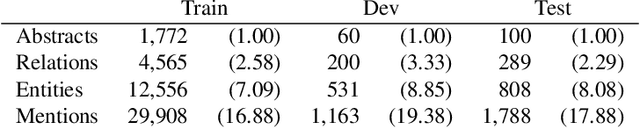
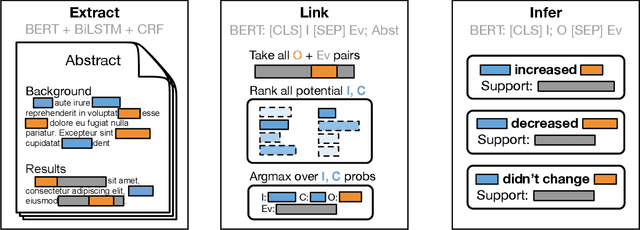

The best evidence concerning comparative treatment effectiveness comes from clinical trials, the results of which are reported in unstructured articles. Medical experts must manually extract information from articles to inform decision-making, which is time-consuming and expensive. Here we consider the end-to-end task of both (a) extracting treatments and outcomes from full-text articles describing clinical trials (entity identification) and, (b) inferring the reported results for the former with respect to the latter (relation extraction). We introduce new data for this task, and evaluate models that have recently achieved state-of-the-art results on similar tasks in Natural Language Processing. We then propose a new method motivated by how trial results are typically presented that outperforms these purely data-driven baselines. Finally, we run a fielded evaluation of the model with a non-profit seeking to identify existing drugs that might be re-purposed for cancer, showing the potential utility of end-to-end evidence extraction systems.
Language in Our Time: An Empirical Analysis of Hashtags
May 11, 2019
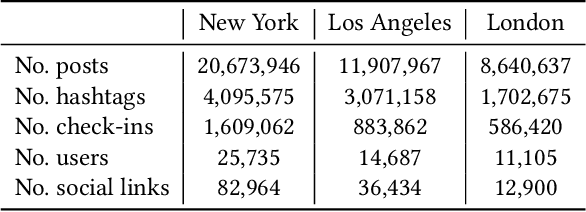
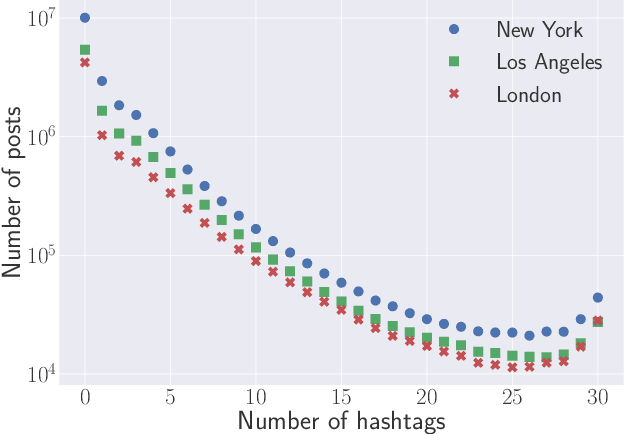
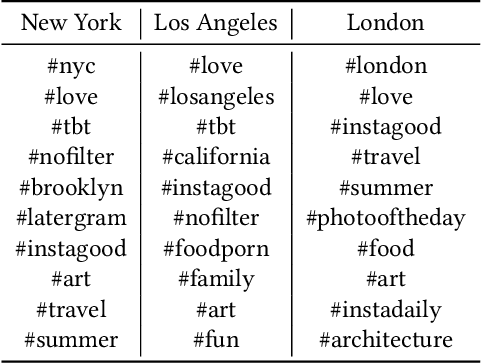
Hashtags in online social networks have gained tremendous popularity during the past five years. The resulting large quantity of data has provided a new lens into modern society. Previously, researchers mainly rely on data collected from Twitter to study either a certain type of hashtags or a certain property of hashtags. In this paper, we perform the first large-scale empirical analysis of hashtags shared on Instagram, the major platform for hashtag-sharing. We study hashtags from three different dimensions including the temporal-spatial dimension, the semantic dimension, and the social dimension. Extensive experiments performed on three large-scale datasets with more than 7 million hashtags in total provide a series of interesting observations. First, we show that the temporal patterns of hashtags can be categorized into four different clusters, and people tend to share fewer hashtags at certain places and more hashtags at others. Second, we observe that a non-negligible proportion of hashtags exhibit large semantic displacement. We demonstrate hashtags that are more uniformly shared among users, as quantified by the proposed hashtag entropy, are less prone to semantic displacement. In the end, we propose a bipartite graph embedding model to summarize users' hashtag profiles, and rely on these profiles to perform friendship prediction. Evaluation results show that our approach achieves an effective prediction with AUC (area under the ROC curve) above 0.8 which demonstrates the strong social signals possessed in hashtags.
FLAG: Adversarial Data Augmentation for Graph Neural Networks
Oct 19, 2020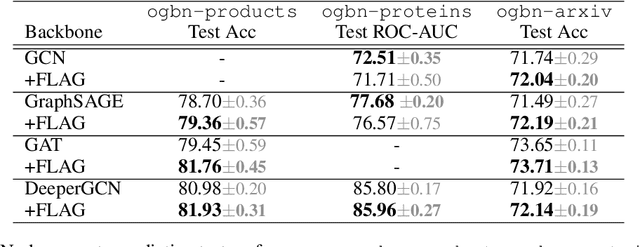
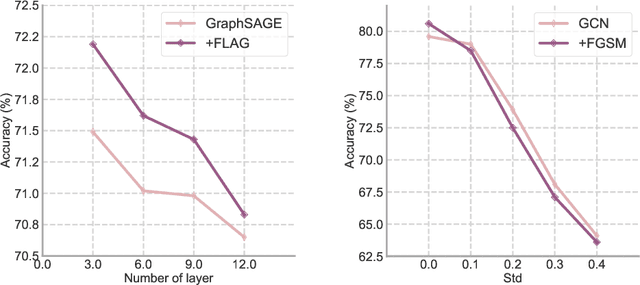

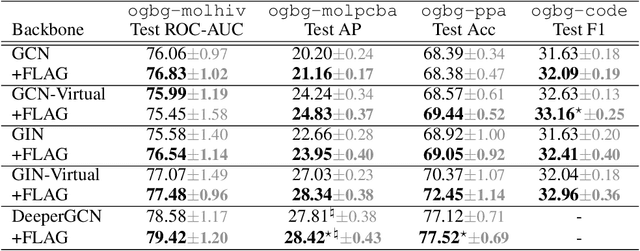
Data augmentation helps neural networks generalize better, but it remains an open question how to effectively augment graph data to enhance the performance of GNNs (Graph Neural Networks). While most existing graph regularizers focus on augmenting graph topological structures by adding/removing edges, we offer a novel direction to augment in the input node feature space for better performance. We propose a simple but effective solution, FLAG (Free Large-scale Adversarial Augmentation on Graphs), which iteratively augments node features with gradient-based adversarial perturbations during training, and boosts performance at test time. Empirically, FLAG can be easily implemented with a dozen lines of code and is flexible enough to function with any GNN backbone, on a wide variety of large-scale datasets, and in both transductive and inductive settings. Without modifying a model's architecture or training setup, FLAG yields a consistent and salient performance boost across both node and graph classification tasks. Using FLAG, we reach state-of-the-art performance on the large-scale ogbg-molpcba, ogbg-ppa, and ogbg-code datasets.