 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MOTS: Minimax Optimal Thompson Sampling
Mar 03, 2020
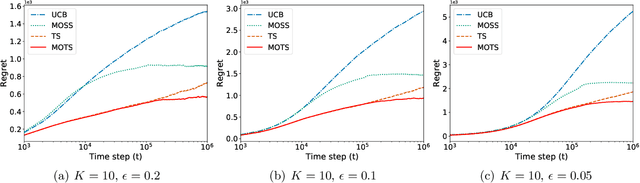
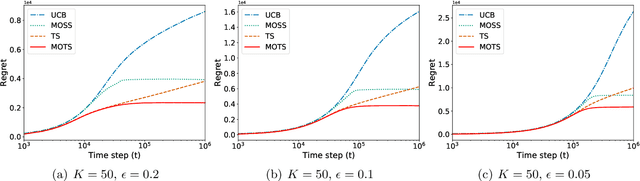
Thompson sampling is one of the most widely used algorithms for many online decision problems, due to its simplicity in implementation and superior empirical performance over other state-of-the-art methods. Despite its popularity and empirical success, it has remained an open problem whether Thompson sampling can achieve the minimax optimal regret $O(\sqrt{KT})$ for $K$-armed bandit problems, where $T$ is the total time horizon. In this paper, we solve this long open problem by proposing a new Thompson sampling algorithm called MOTS that adaptively truncates the sampling result of the chosen arm at each time step. We prove that this simple variant of Thompson sampling achieves the minimax optimal regret bound $O(\sqrt{KT})$ for finite time horizon $T$ and also the asymptotic optimal regret bound when $T$ grows to infinity as well. This is the first time that the minimax optimality of multi-armed bandit problems has been attained by Thompson sampling type of algorithms.
Multicenter Assessment of Augmented Reality Registration Methods for Image-guided Interventions
Dec 03, 2020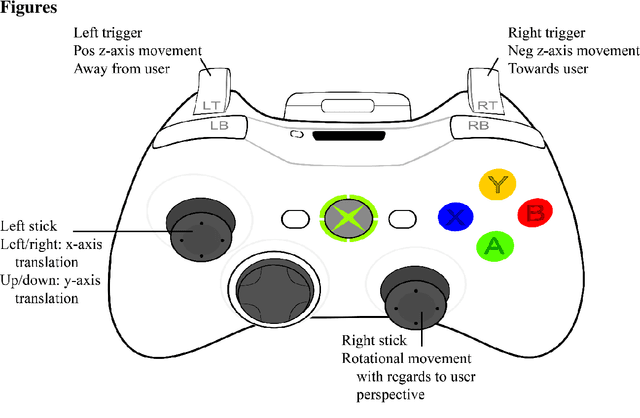
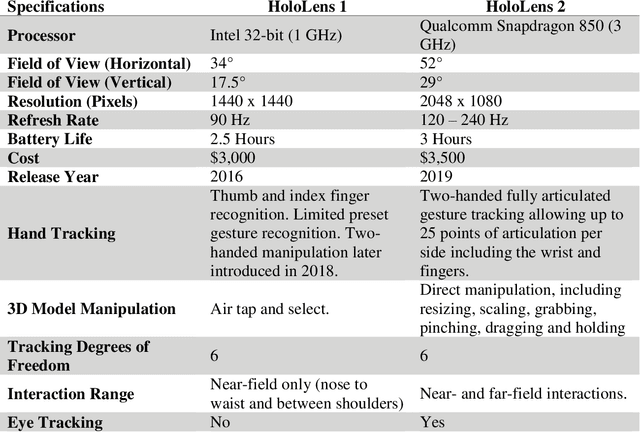

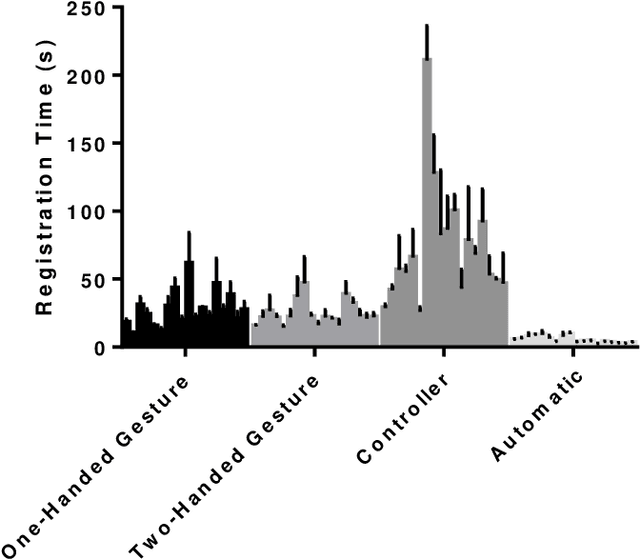
Purpose: To evaluate manual and automatic registration times as well as accuracy with augmented reality during alignment of a holographic 3-dimensional (3D) model onto the real-world environment. Method: 18 participants in various stages of clinical training across two academic centers registered a 3D CT phantom model onto a CT grid using the HoloLens 2 augmented reality headset 3 consecutive times. Registration times and accuracy were compared among different registration methods (hand gesture, Xbox controller, and automatic registration), levels of clinical experience, and consecutive attempts. Registration times were also compared with prior HoloLens 1 data. Results: Mean aggregate manual registration times were 27.7, 24.3, and 72.8 seconds for one-handed gesture, two-handed gesture, and Xbox controller, respectively; mean automatic registration time was 5.3s (ANOVA p<0.0001). No significant difference in registration times was found among attendings, residents and fellows, and medical students (p>0.05). Significant improvements in registration times were detected across consecutive attempts using hand gestures (p<0.01). Compared with previously reported HoloLens 1 experience, hand gesture registration times were 81.7% faster (p<0.05). Registration accuracies were not significantly different across manual registration methods, measuring at 5.9, 9.5, and 8.6 mm with one-handed gesture, two-handed gesture, and Xbox controller, respectively (p>0.05). Conclusions: Manual registration times decreased significantly with updated hand gesture maneuvers on HoloLens 2 versus HoloLens 1, approaching the registration times of automatic registration and outperforming Xbox controller mediated registration. These results will encourage wider clinical integration of HoloLens 2 in procedural medical care.
A Clustering-Based Method for Automatic Educational Video Recommendation Using Deep Face-Features of Lecturers
Oct 09, 2020
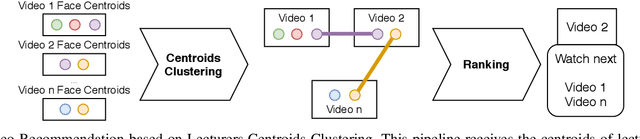
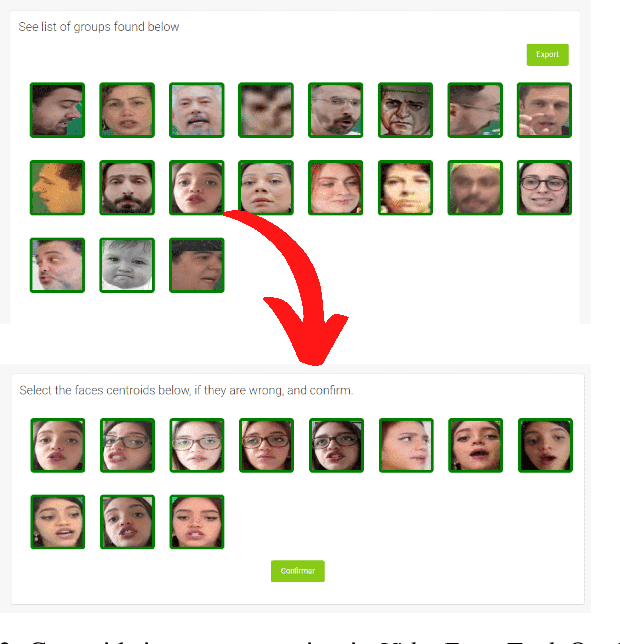

Discovering and accessing specific content within educational video bases is a challenging task, mainly because of the abundance of video content and its diversity. Recommender systems are often used to enhance the ability to find and select content. But, recommendation mechanisms, especially those based on textual information, exhibit some limitations, such as being error-prone to manually created keywords or due to imprecise speech recognition. This paper presents a method for generating educational video recommendation using deep face-features of lecturers without identifying them. More precisely, we use an unsupervised face clustering mechanism to create relations among the videos based on the lecturer's presence. Then, for a selected educational video taken as a reference, we recommend the ones where the presence of the same lecturers is detected. Moreover, we rank these recommended videos based on the amount of time the referenced lecturers were present. For this task, we achieved a mAP value of 99.165%.
Prognostic and Health Management (PHM) tool for Robot Operating System (ROS)
Nov 18, 2020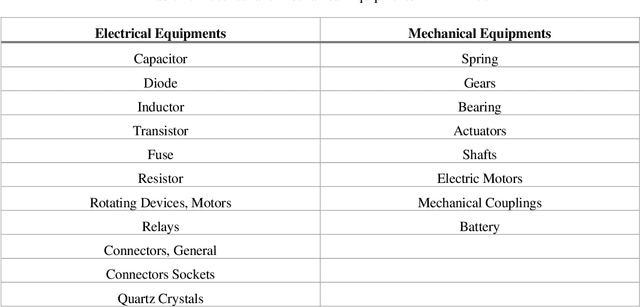


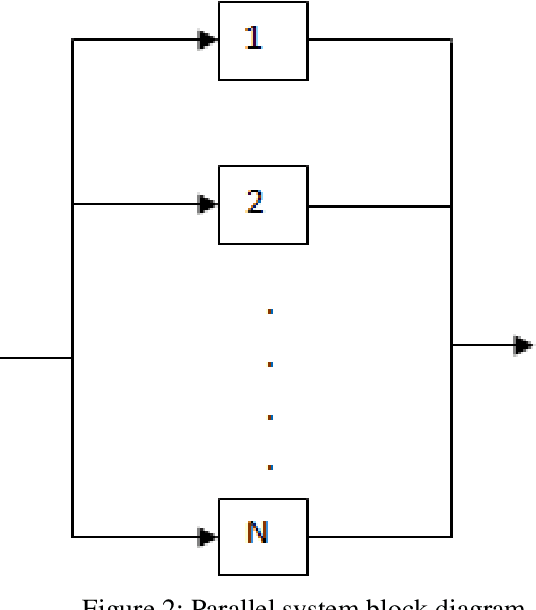
Nowadays, prognostics-aware systems are increasingly used in many systems and it is critical for sustaining autonomy. All engineering systems, especially robots, are not perfect. Absence of failures in a certain time is the perfect system and it is impossible practically. In all engineering works, we must try to predict or minimize/prevent failures in the system. Failures in the systems are generally unknown, so prediction of these failures and reliability of the system is made by prediction process. Reliability analysis is important for the improving the system performance, extending system lifetime, etc. Prognostic and Health Management (PHM) includes reliability, safety, predictive fault detection / isolation, advanced diagnostics / prognostics, component lifecycle tracking, health reporting and information management, etc. This study proposes an open source robot prognostic and health management tool using model-based methodology namely "Prognostics and Health Management tool for ROS". This tool is a generic tool for using with any kind of robot (mobile robot, robot arm, drone etc.) with compatible with ROS. Some features of this tool are managing / monitoring robots' health, RUL, probability of task completion (PoTC) etc. User is able to enter the necessary equations and components information (hazard rates, robot configuration etc.) to the PHM tool and the other sensory data like temperature, humidity, pressure, load etc. In addition to these, a case study is conducted for the mobile robots (OTA) using this tool.
Find it if You Can: End-to-End Adversarial Erasing for Weakly-Supervised Semantic Segmentation
Nov 09, 2020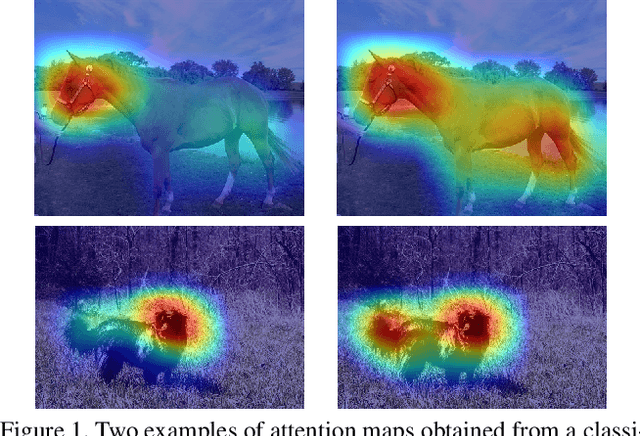
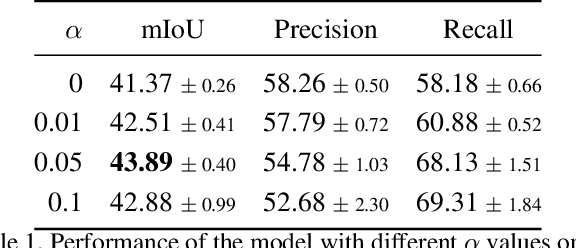


Semantic segmentation is a task that traditionally requires a large dataset of pixel-level ground truth labels, which is time-consuming and expensive to obtain. Recent advancements in the weakly-supervised setting show that reasonable performance can be obtained by using only image-level labels. Classification is often used as a proxy task to train a deep neural network from which attention maps are extracted. However, the classification task needs only the minimum evidence to make predictions, hence it focuses on the most discriminative object regions. To overcome this problem, we propose a novel formulation of adversarial erasing of the attention maps. In contrast to previous adversarial erasing methods, we optimize two networks with opposing loss functions, which eliminates the requirement of certain suboptimal strategies; for instance, having multiple training steps that complicate the training process or a weight sharing policy between networks operating on different distributions that might be suboptimal for performance. The proposed solution does not require saliency masks, instead it uses a regularization loss to prevent the attention maps from spreading to less discriminative object regions. Our experiments on the Pascal VOC dataset demonstrate that our adversarial approach increases segmentation performance by 2.1 mIoU compared to our baseline and by 1.0 mIoU compared to previous adversarial erasing approaches.
Fuzzy c-Shape: A new algorithm for clustering finite time series waveforms
Aug 03, 2016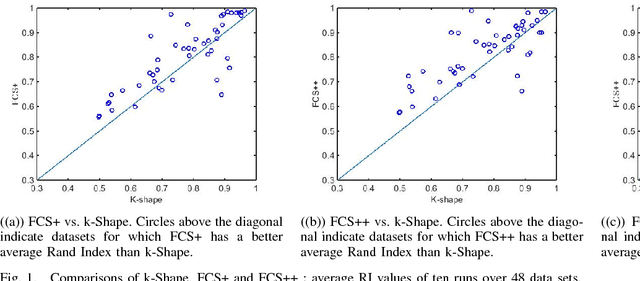
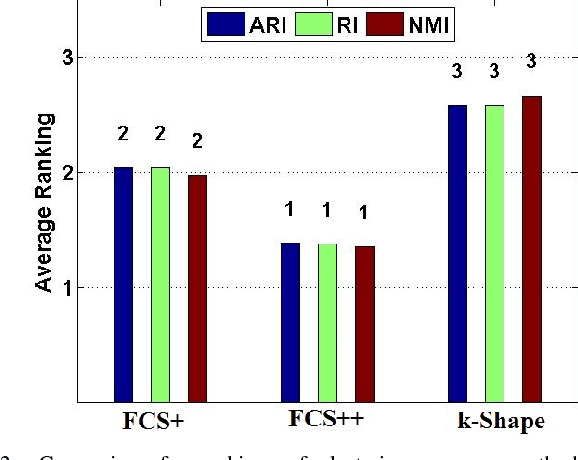
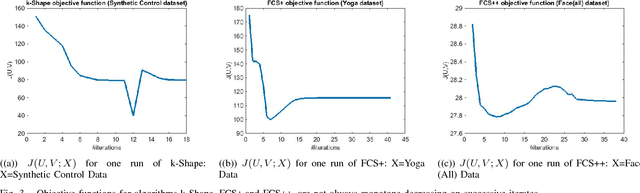
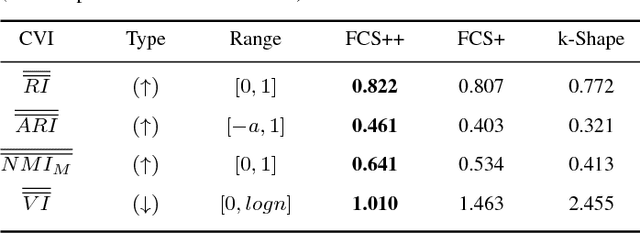
The existence of large volumes of time series data in many applications has motivated data miners to investigate specialized methods for mining time series data. Clustering is a popular data mining method due to its powerful exploratory nature and its usefulness as a preprocessing step for other data mining techniques. This article develops two novel clustering algorithms for time series data that are extensions of a crisp c-shapes algorithm. The two new algorithms are heuristic derivatives of fuzzy c-means (FCM). Fuzzy c-Shapes plus (FCS+) replaces the inner product norm in the FCM model with a shape-based distance function. Fuzzy c-Shapes double plus (FCS++) uses the shape-based distance, and also replaces the FCM cluster centers with shape-extracted prototypes. Numerical experiments on 48 real time series data sets show that the two new algorithms outperform state-of-the-art shape-based clustering algorithms in terms of accuracy and efficiency. Four external cluster validity indices (the Rand index, Adjusted Rand Index, Variation of Information, and Normalized Mutual Information) are used to match candidate partitions generated by each of the studied algorithms. All four indices agree that for these finite waveform data sets, FCS++ gives a small improvement over FCS+, and in turn, FCS+ is better than the original crisp c-shapes method. Finally, we apply two tests of statistical significance to the three algorithms. The Wilcoxon and Friedman statistics both rank the three algorithms in exactly the same way as the four cluster validity indices.
Faster Biological Gradient Descent Learning
Sep 27, 2020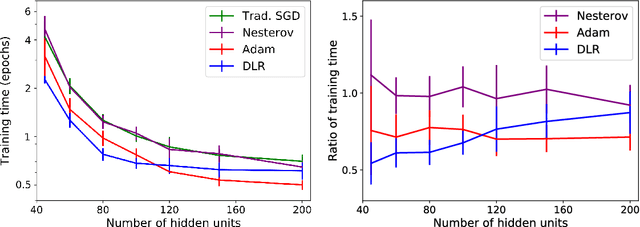
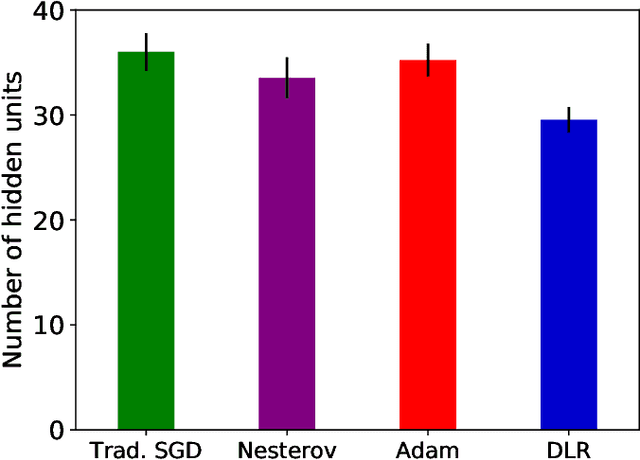
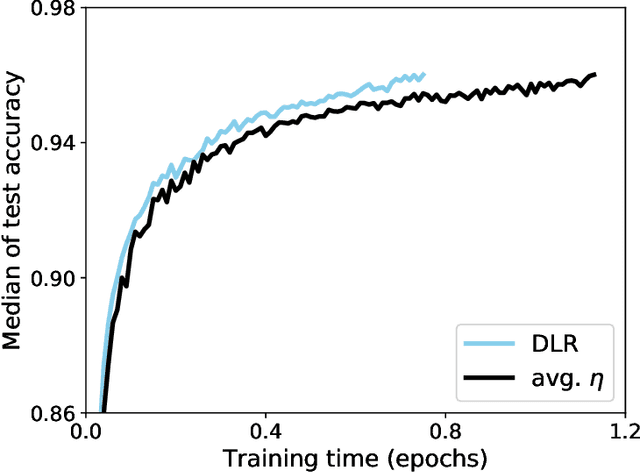
Back-propagation is a popular machine learning algorithm that uses gradient descent in training neural networks for supervised learning, but can be very slow. A number of algorithms have been developed to speed up convergence and improve robustness of the learning. However, they are complicated to implement biologically as they require information from previous updates. Inspired by synaptic competition in biology, we have come up with a simple and local gradient descent optimization algorithm that can reduce training time, with no demand on past details. Our algorithm, named dynamic learning rate (DLR), works similarly to the traditional gradient descent used in back-propagation, except that instead of having a uniform learning rate across all synapses, the learning rate depends on the current neuronal connection weights. Our algorithm is found to speed up learning, particularly for small networks.
High-order Semantic Role Labeling
Oct 09, 2020
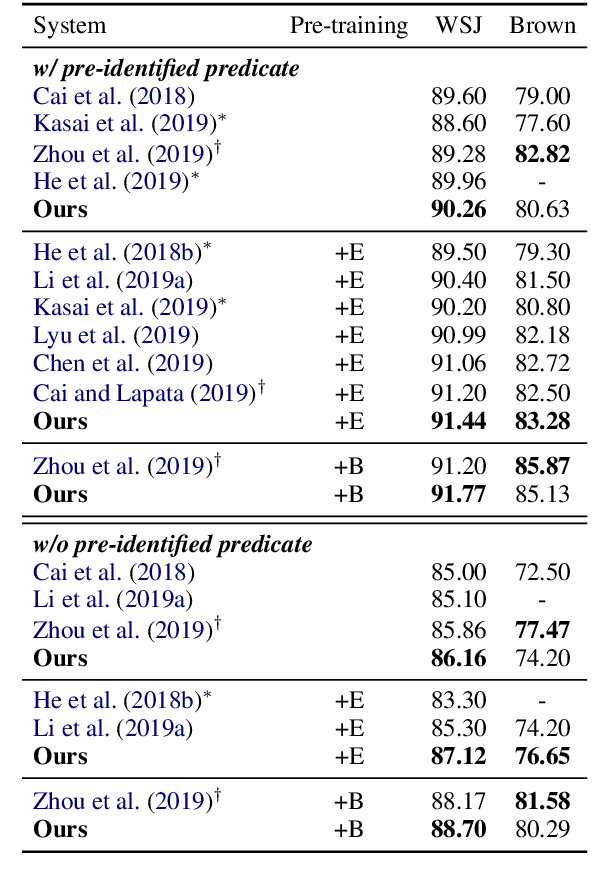
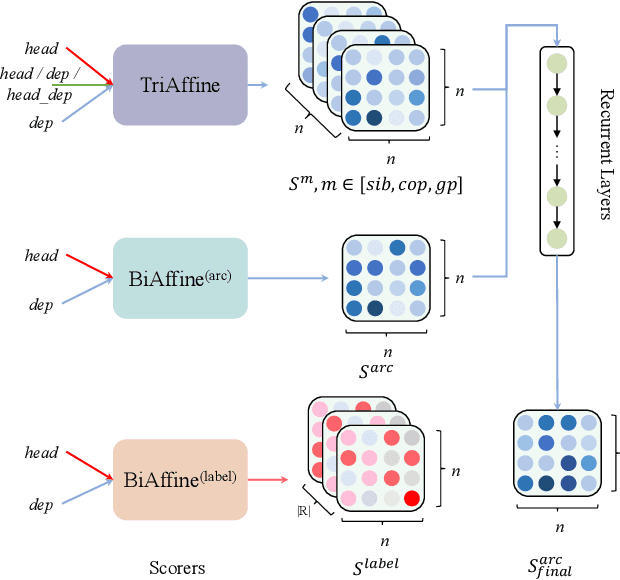
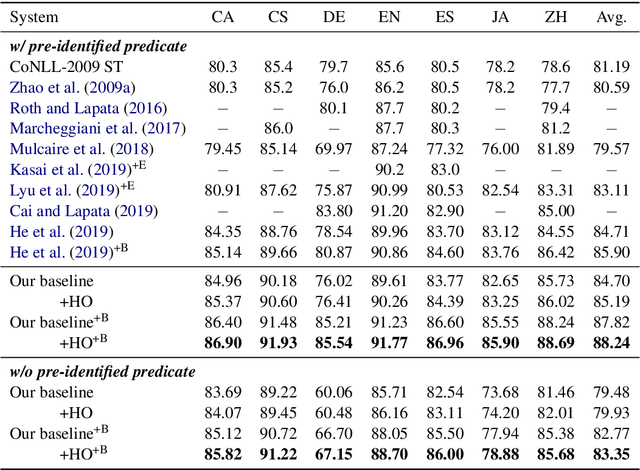
Semantic role labeling is primarily used to identify predicates, arguments, and their semantic relationships. Due to the limitations of modeling methods and the conditions of pre-identified predicates, previous work has focused on the relationships between predicates and arguments and the correlations between arguments at most, while the correlations between predicates have been neglected for a long time. High-order features and structure learning were very common in modeling such correlations before the neural network era. In this paper, we introduce a high-order graph structure for the neural semantic role labeling model, which enables the model to explicitly consider not only the isolated predicate-argument pairs but also the interaction between the predicate-argument pairs. Experimental results on 7 languages of the CoNLL-2009 benchmark show that the high-order structural learning techniques are beneficial to the strong performing SRL models and further boost our baseline to achieve new state-of-the-art results.
Deep Learning Based Detection and Localization of Cerebal Aneurysms in Computed Tomography Angiography
May 22, 2020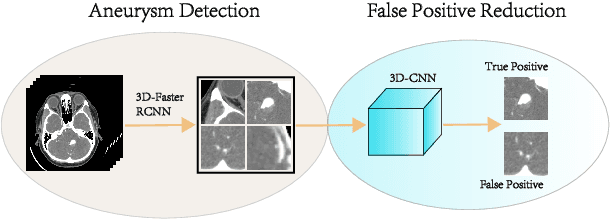
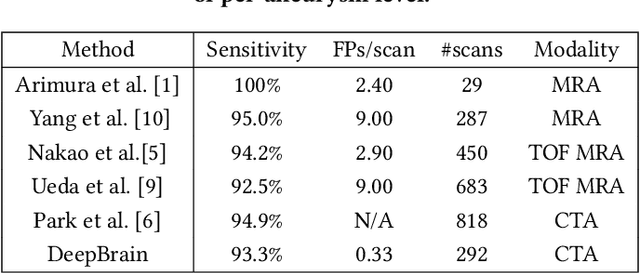
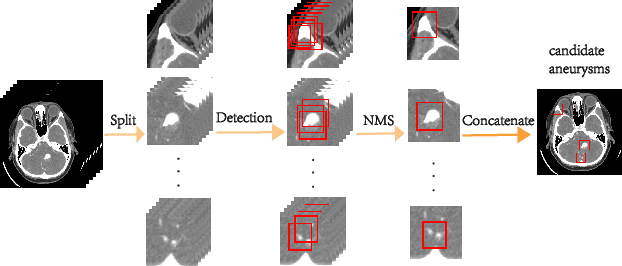
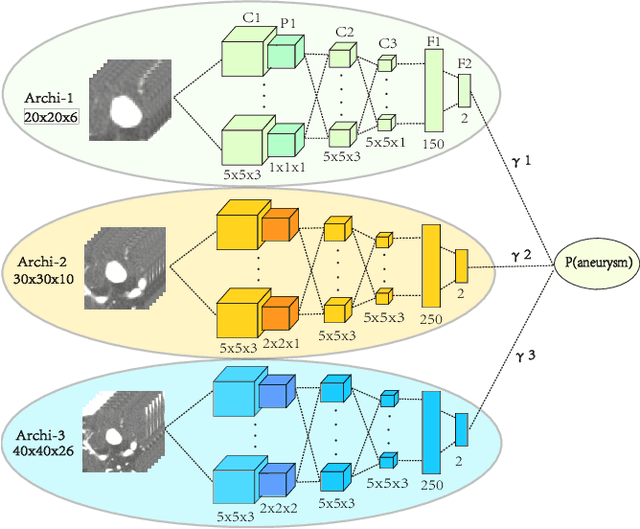
Detecting cerebral aneurysms is an important clinical task of brain computed tomography angiography (CTA). However, human interpretation could be time consuming due to the small size of some aneurysms. In this work, we proposed DeepBrain, a deep learning based cerebral aneurysm detection and localization algorithm. The algorithm consisted of a 3D faster region-proposal convolution neural network for aneurysm detection and localization, and a 3D multi-scale fully convolutional neural network for false positive reduction. Furthermore, a novel hierarchical non-maximum suppression algorithm was proposed to process the detection results in 3D, which greatly reduced the time complexity by eliminating unnecessary comparisons. DeepBrain was trained and tested on 550 brain CTA scans and achieved sensitivity of 93.3% with 0.3 false positives per patient on average.
Multi-Agent Reinforcement Learning for Joint Channel Assignment and Power Allocation in Platoon-Based C-V2X Systems
Nov 09, 2020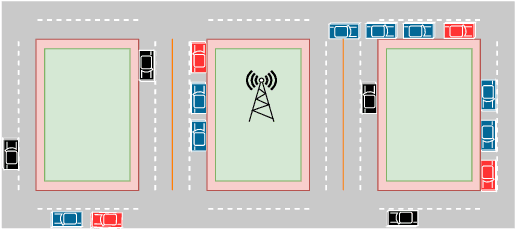
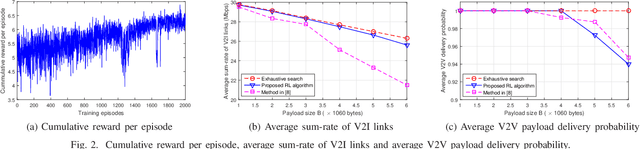

We consider the problem of joint channel assignment and power allocation in underlaid cellular vehicular-to-everything (C-V2X) systems where multiple vehicle-to-infrastructure (V2I) uplinks share the time-frequency resources with multiple vehicle-to-vehicle (V2V) platoons that enable groups of connected and autonomous vehicles to travel closely together. Due to the nature of fast channel variant in vehicular environment, traditional centralized optimization approach relying on global channel information might not be viable in C-V2X systems with large number of users. Utilizing a reinforcement learning (RL) approach, we propose a distributed resource allocation (RA) algorithm to overcome this challenge. Specifically, we model the RA problem as a multi-agent system. Based solely on the local channel information, each platoon leader, who acts as an agent, collectively interacts with each other and accordingly selects the optimal combination of sub-band and power level to transmit its signals. Toward this end, we utilize the double deep Q-learning algorithm to jointly train the agents under the objectives of simultaneously maximizing the V2I sum-rate and satisfying the packet delivery probability of each V2V link in a desired latency limitation. Simulation results show that our proposed RL-based algorithm achieves a close performance compared to that of the well-known exhaustive search algorithm.