 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Recurrent Neural Networks for Time Series Forecasting: Current Status and Future Directions
Sep 24, 2019
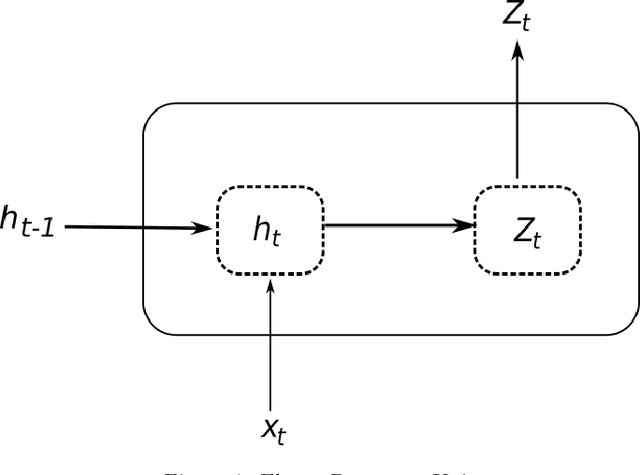


Recurrent Neural Networks (RNN) have become competitive forecasting methods, as most notably shown in the winning method of the recent M4 competition. However, established statistical models such as ETS and ARIMA gain their popularity not only from their high accuracy, but they are also suitable for non-expert users as they are robust, efficient, and automatic. In these areas, RNNs have still a long way to go. We present an extensive empirical study and an open-source software framework of existing RNN architectures for forecasting, that allow us to develop guidelines and best practices for their use. For example, we conclude that RNNs are capable of modelling seasonality directly if the series in the dataset possess homogeneous seasonal patterns, otherwise we recommend a deseasonalization step. Comparisons against ETS and ARIMA demonstrate that the implemented (semi-)automatic RNN models are no silver bullets, but they are competitive alternatives in many situations.
Fine-grained Language Identification with Multilingual CapsNet Model
Jul 12, 2020
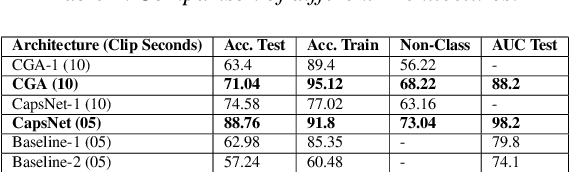
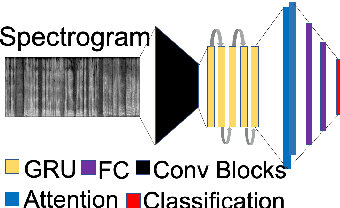
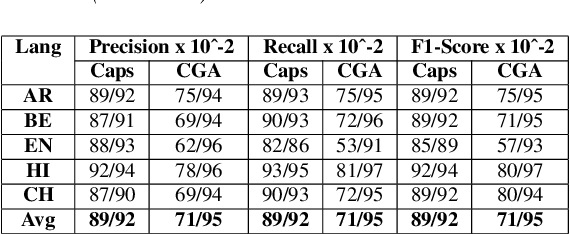
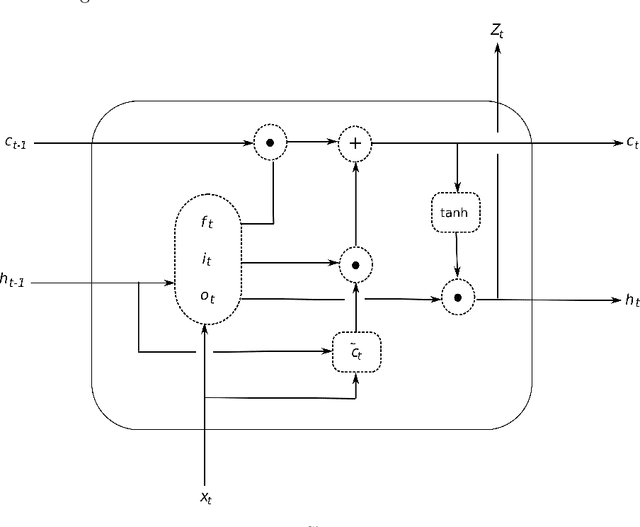
Due to a drastic improvement in the quality of internet services worldwide, there is an explosion of multilingual content generation and consumption. This is especially prevalent in countries with large multilingual audience, who are increasingly consuming media outside their linguistic familiarity/preference. Hence, there is an increasing need for real-time and fine-grained content analysis services, including language identification, content transcription, and analysis. Accurate and fine-grained spoken language detection is an essential first step for all the subsequent content analysis algorithms. Current techniques in spoken language detection may lack on one of these fronts: accuracy, fine-grained detection, data requirements, manual effort in data collection \& pre-processing. Hence in this work, a real-time language detection approach to detect spoken language from 5 seconds' audio clips with an accuracy of 91.8\% is presented with exiguous data requirements and minimal pre-processing. Novel architectures for Capsule Networks is proposed which operates on spectrogram images of the provided audio snippets. We use previous approaches based on Recurrent Neural Networks and iVectors to present the results. Finally we show a ``Non-Class'' analysis to further stress on why CapsNet architecture works for LID task.
A Clustering-Based Method for Automatic Educational Video Recommendation Using Deep Face-Features of Lecturers
Oct 09, 2020
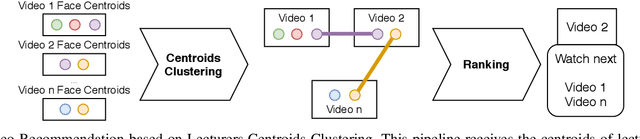
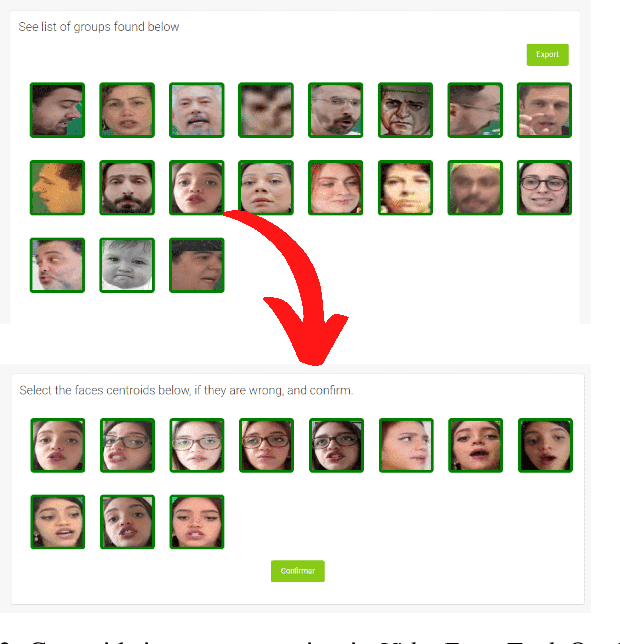

Discovering and accessing specific content within educational video bases is a challenging task, mainly because of the abundance of video content and its diversity. Recommender systems are often used to enhance the ability to find and select content. But, recommendation mechanisms, especially those based on textual information, exhibit some limitations, such as being error-prone to manually created keywords or due to imprecise speech recognition. This paper presents a method for generating educational video recommendation using deep face-features of lecturers without identifying them. More precisely, we use an unsupervised face clustering mechanism to create relations among the videos based on the lecturer's presence. Then, for a selected educational video taken as a reference, we recommend the ones where the presence of the same lecturers is detected. Moreover, we rank these recommended videos based on the amount of time the referenced lecturers were present. For this task, we achieved a mAP value of 99.165%.
Continuous Lyapunov Controller and Chaotic Non-linear System Optimization using Deep Machine Learning
Oct 31, 2020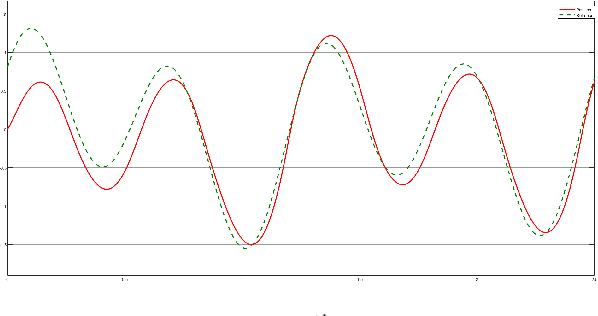
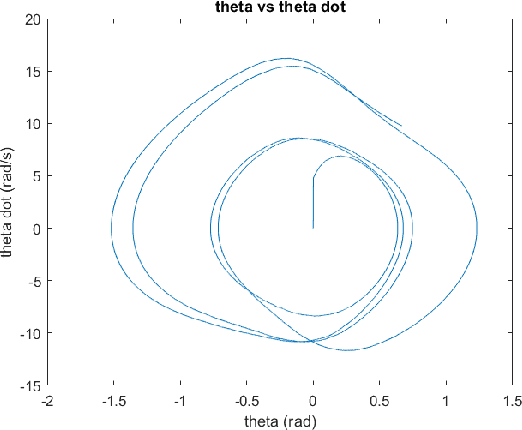

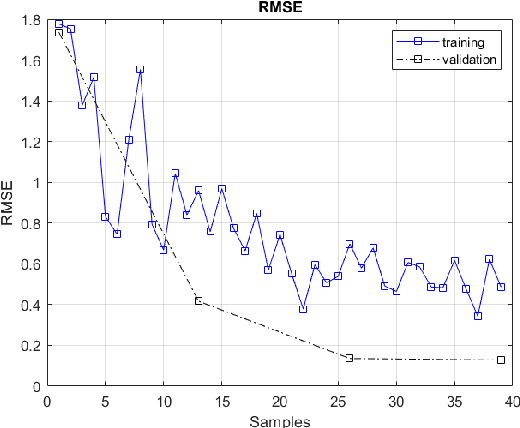
The introduction of unexpected system disturbances and new system dynamics does not allow initially selected static system and controller parameters to guarantee continued system stability and performance. In this research we present a novel approach for detecting early failure indicators of non-linear highly chaotic system and accordingly predict the best parameter calibrations to offset such instability using deep machine learning regression model. The approach proposed continuously monitors the system and controller signals. The Re-calibration of the system and controller parameters is triggered according to a set of conditions designed to maintain system stability without compromise to the system speed, intended outcome or required processing power. The deep neural model predicts the parameter values that would best counteract the expected system in-stability. To demonstrate the effectiveness of the proposed approach, it is applied to the non-linear complex combination of Duffing Van der pol oscillators. The approach is also tested under different scenarios the system and controller parameters are initially chosen incorrectly or the system parameters are changed while running or new system dynamics are introduced while running to measure effectiveness and reaction time.
High-order Semantic Role Labeling
Oct 09, 2020
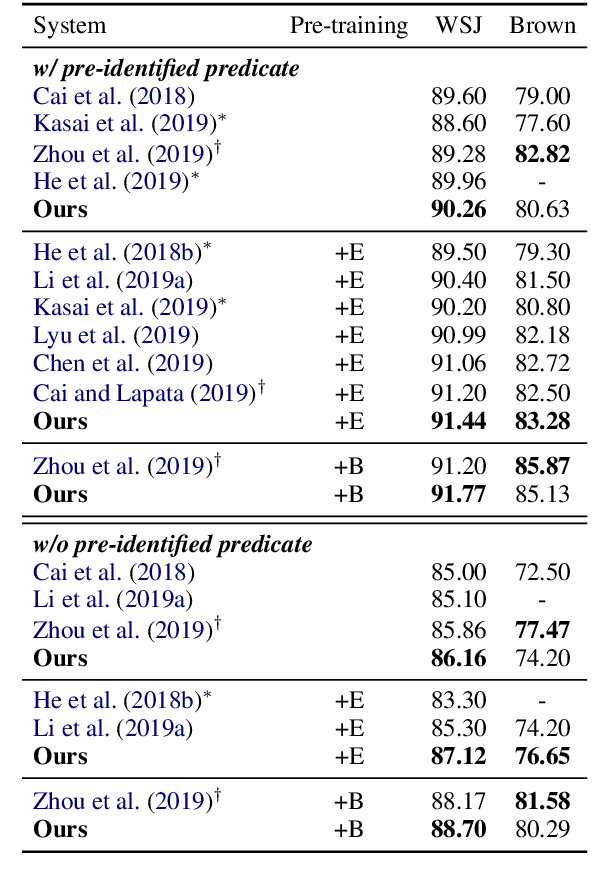
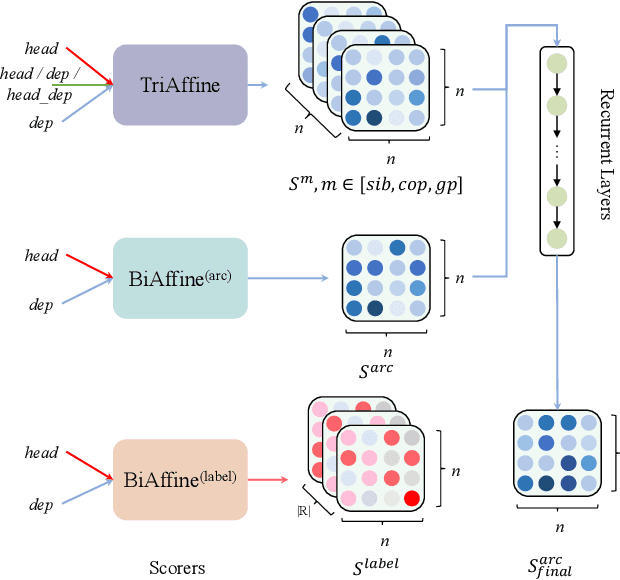
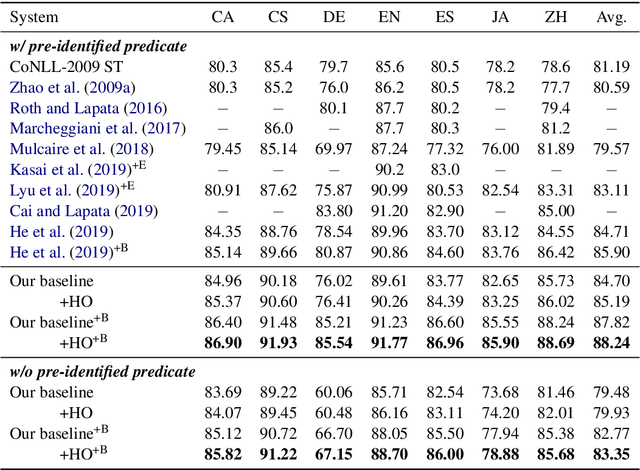
Semantic role labeling is primarily used to identify predicates, arguments, and their semantic relationships. Due to the limitations of modeling methods and the conditions of pre-identified predicates, previous work has focused on the relationships between predicates and arguments and the correlations between arguments at most, while the correlations between predicates have been neglected for a long time. High-order features and structure learning were very common in modeling such correlations before the neural network era. In this paper, we introduce a high-order graph structure for the neural semantic role labeling model, which enables the model to explicitly consider not only the isolated predicate-argument pairs but also the interaction between the predicate-argument pairs. Experimental results on 7 languages of the CoNLL-2009 benchmark show that the high-order structural learning techniques are beneficial to the strong performing SRL models and further boost our baseline to achieve new state-of-the-art results.
Coupled regularized sample covariance matrix estimator for multiple classes
Nov 09, 2020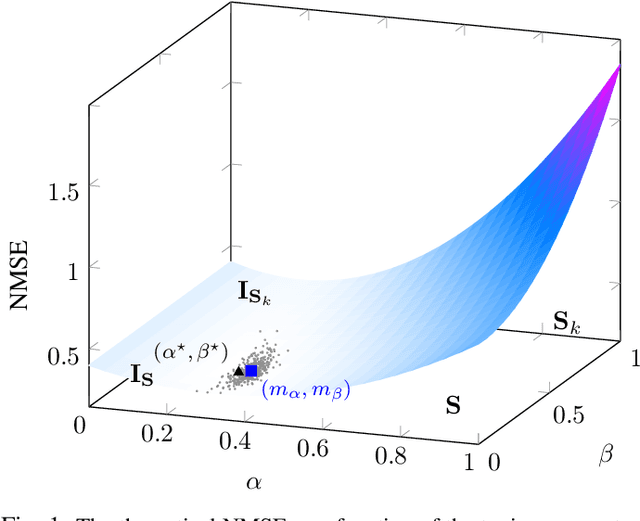
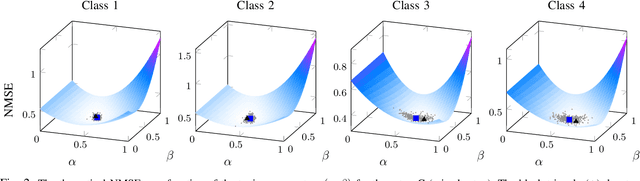
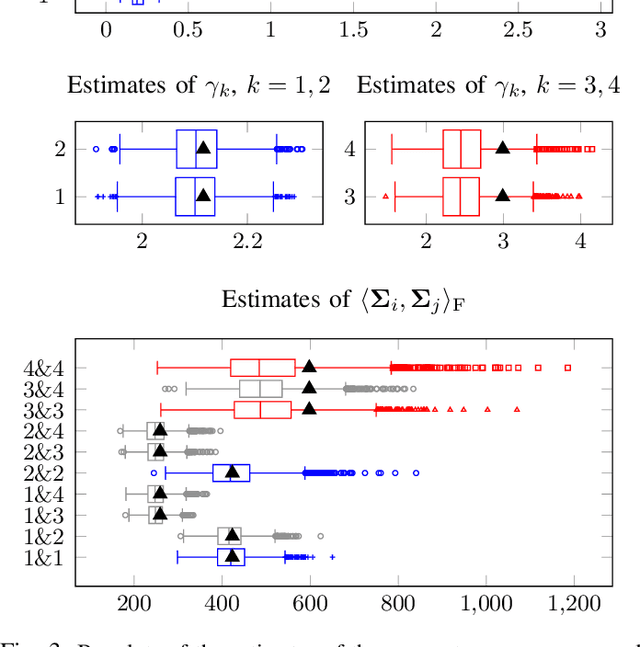
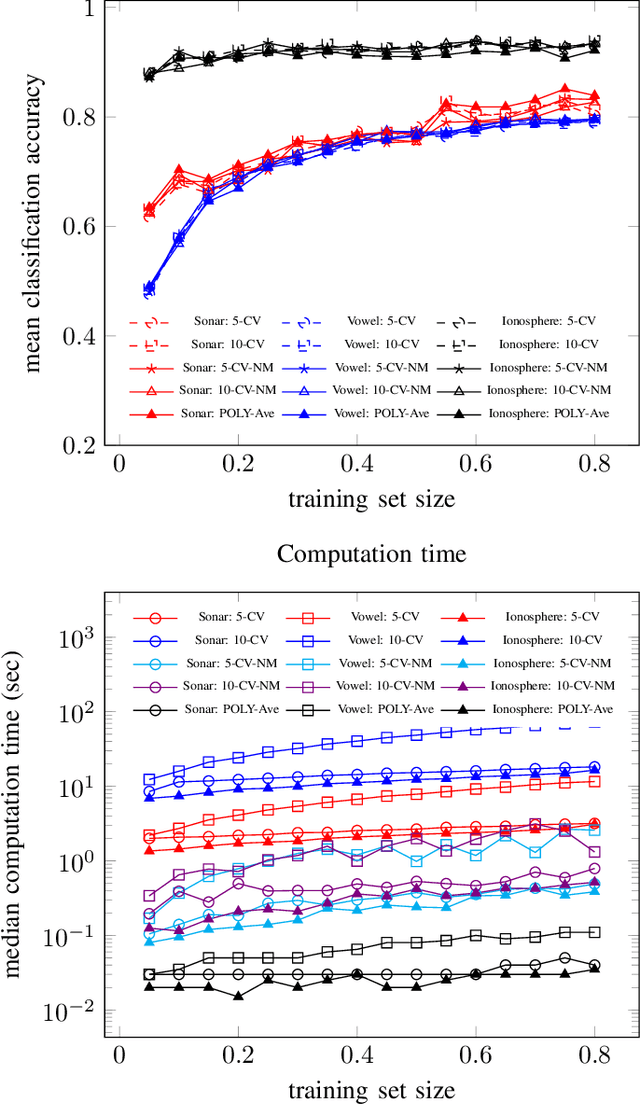
The estimation of covariance matrices of multiple classes with limited training data is a difficult problem. The sample covariance matrix (SCM) is known to perform poorly when the number of variables is large compared to the available number of samples. In order to reduce the mean squared error (MSE) of the SCM, regularized (shrinkage) SCM estimators are often used. In this work, we consider regularized SCM (RSCM) estimators for multiclass problems that couple together two different target matrices for regularization: the pooled (average) SCM of the classes and the scaled identity matrix. Regularization toward the pooled SCM is beneficial when the population covariances are similar, whereas regularization toward the identity matrix guarantees that the estimators are positive definite. We derive the MSE optimal tuning parameters for the estimators as well as propose a method for their estimation under the assumption that the class populations follow (unspecified) elliptical distributions with finite fourth-order moments. The MSE performance of the proposed coupled RSCMs are evaluated with simulations and in a regularized discriminant analysis (RDA) classification set-up on real data. The results based on three different real data sets indicate comparable performance to cross-validation but with a significant speed-up in computation time.
FLAT: Fast, Lightweight and Accurate Method for Cardinality Estimation
Nov 18, 2020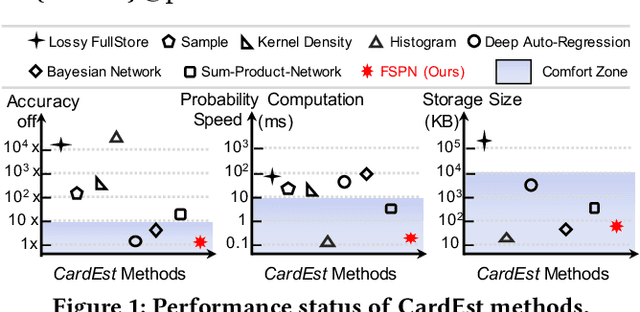
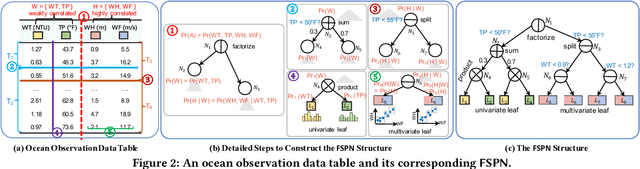
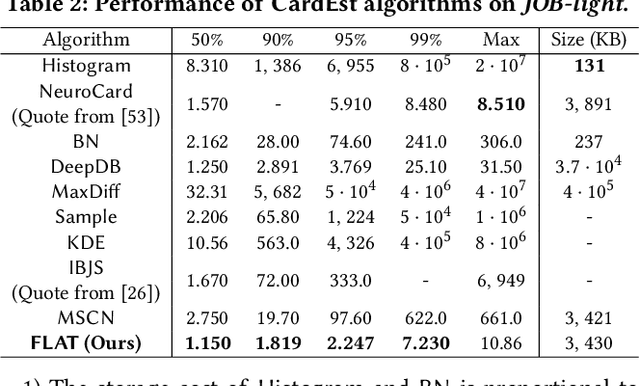

Query optimizers rely on accurate cardinality estimation (CardEst) to produce good execution plans. The core problem of CardEst is how to model the rich joint distribution of attributes in an accurate and compact manner. Despite decades of research, existing methods either over simplify the models only using independent factorization which leads to inaccurate estimates and sub optimal query plans, or over-complicate them by lossless conditional factorization without any independent assumption which results in slow probability computation. In this paper, we propose FLAT, a CardEst method that is simultaneously fast in probability computation, lightweight in model size and accurate in estimation quality. The key idea of FLAT is a novel unsupervised graphical model, called FSPN. It utilizes both independent and conditional factorization to adaptively model different levels of attributes correlations, and thus subsumes all existing CardEst models and dovetails their advantages. FLAT supports efficient online probability computation in near liner time on the underlying FSPN model, and provides effective offline model construction. It can estimate cardinality for both single table queries and multi-table join queries. Extensive experimental study demonstrates the superiority of FLAT over existing CardEst methods on well-known benchmarks: FLAT achieves 1 to 5 orders of magnitude better accuracy, 1 to 3 orders of magnitude faster probability computation speed (around 0.2ms) and 1 to 2 orders of magnitude lower storage cost (only tens of KB).
Across Scales \& Across Dimensions: Temporal Super-Resolution using Deep Internal Learning
Mar 19, 2020When a very fast dynamic event is recorded with a low-framerate camera, the resulting video suffers from severe motion blur (due to exposure time) and motion aliasing (due to low sampling rate in time). True Temporal Super-Resolution (TSR) is more than just Temporal-Interpolation (increasing framerate). It can also recover new high temporal frequencies beyond the temporal Nyquist limit of the input video, thus resolving both motion-blur and motion-aliasing effects that temporal frame interpolation (as sophisticated as it maybe) cannot undo. In this paper we propose a "Deep Internal Learning" approach for true TSR. We train a video-specific CNN on examples extracted directly from the low-framerate input video. Our method exploits the strong recurrence of small space-time patches inside a single video sequence, both within and across different spatio-temporal scales of the video. We further observe (for the first time) that small space-time patches recur also across-dimensions of the video sequence - i.e., by swapping the spatial and temporal dimensions. In particular, the higher spatial resolution of video frames provides strong examples as to how to increase the temporal resolution of that video. Such internal video-specific examples give rise to strong self-supervision, requiring no data but the input video itself. This results in Zero-Shot Temporal-SR of complex videos, which removes both motion blur and motion aliasing, outperforming previous supervised methods trained on external video datasets.
NICER: Aesthetic Image Enhancement with Humans in the Loop
Dec 03, 2020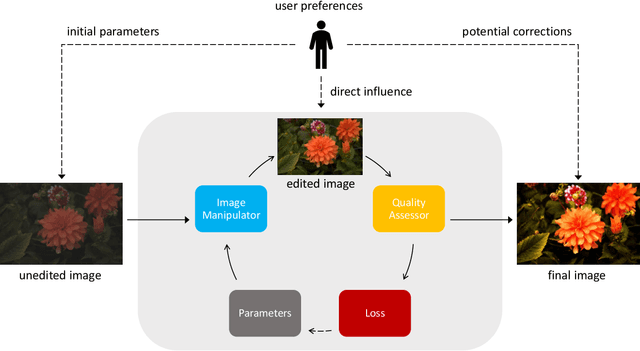
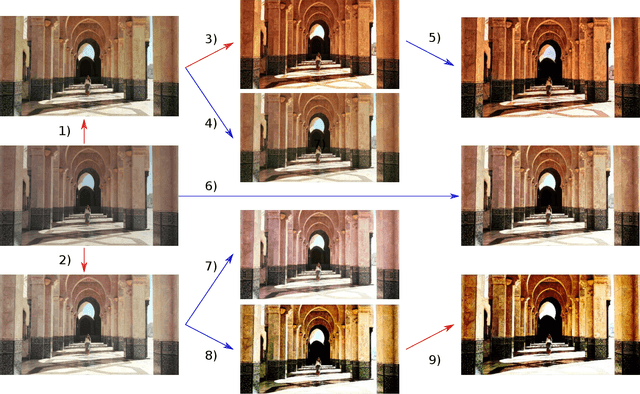
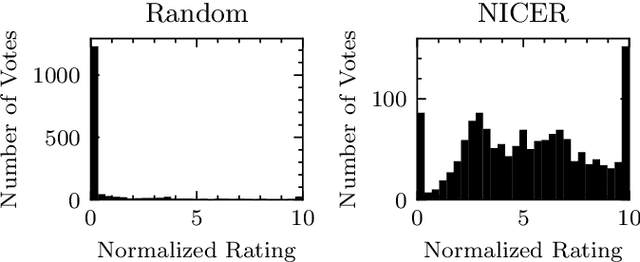
Fully- or semi-automatic image enhancement software helps users to increase the visual appeal of photos and does not require in-depth knowledge of manual image editing. However, fully-automatic approaches usually enhance the image in a black-box manner that does not give the user any control over the optimization process, possibly leading to edited images that do not subjectively appeal to the user. Semi-automatic methods mostly allow for controlling which pre-defined editing step is taken, which restricts the users in their creativity and ability to make detailed adjustments, such as brightness or contrast. We argue that incorporating user preferences by guiding an automated enhancement method simplifies image editing and increases the enhancement's focus on the user. This work thus proposes the Neural Image Correction & Enhancement Routine (NICER), a neural network based approach to no-reference image enhancement in a fully-, semi-automatic or fully manual process that is interactive and user-centered. NICER iteratively adjusts image editing parameters in order to maximize an aesthetic score based on image style and content. Users can modify these parameters at any time and guide the optimization process towards a desired direction. This interactive workflow is a novelty in the field of human-computer interaction for image enhancement tasks. In a user study, we show that NICER can improve image aesthetics without user interaction and that allowing user interaction leads to diverse enhancement outcomes that are strongly preferred over the unedited image. We make our code publicly available to facilitate further research in this direction.
* The code can be found at https://github.com/mr-Mojo/NICER
Faster Biological Gradient Descent Learning
Sep 27, 2020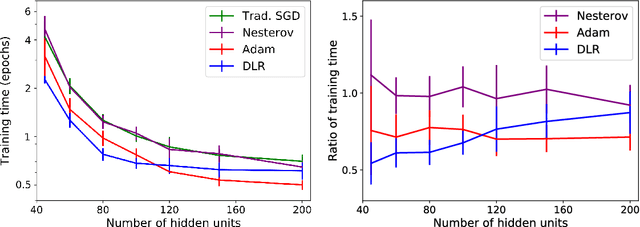
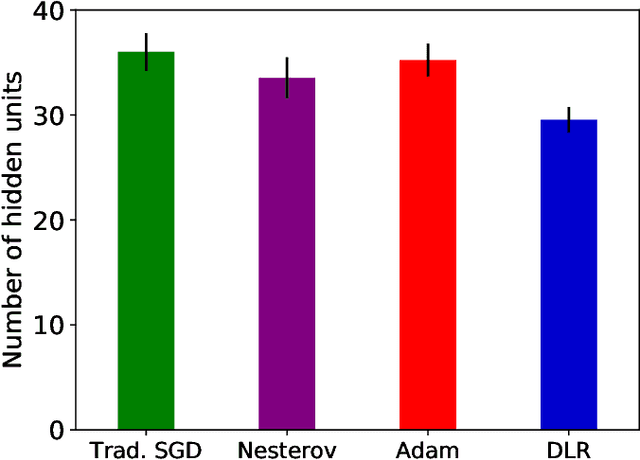
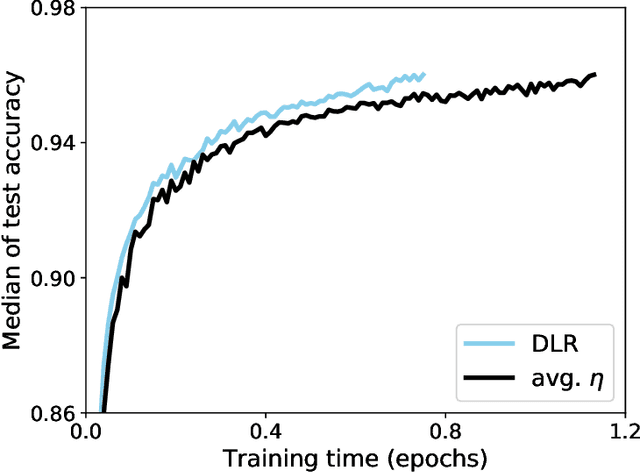
Back-propagation is a popular machine learning algorithm that uses gradient descent in training neural networks for supervised learning, but can be very slow. A number of algorithms have been developed to speed up convergence and improve robustness of the learning. However, they are complicated to implement biologically as they require information from previous updates. Inspired by synaptic competition in biology, we have come up with a simple and local gradient descent optimization algorithm that can reduce training time, with no demand on past details. Our algorithm, named dynamic learning rate (DLR), works similarly to the traditional gradient descent used in back-propagation, except that instead of having a uniform learning rate across all synapses, the learning rate depends on the current neuronal connection weights. Our algorithm is found to speed up learning, particularly for small networks.