 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Once-for-All Adversarial Training: In-Situ Tradeoff between Robustness and Accuracy for Free
Nov 10, 2020
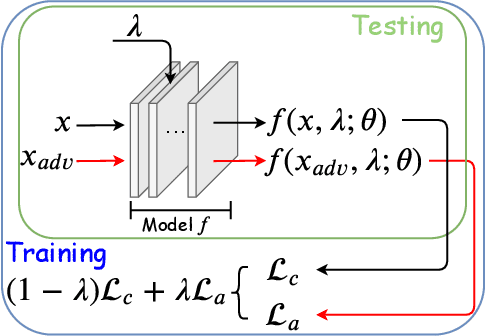
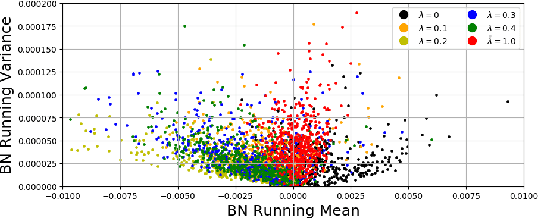
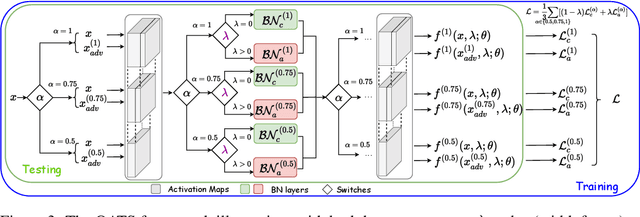
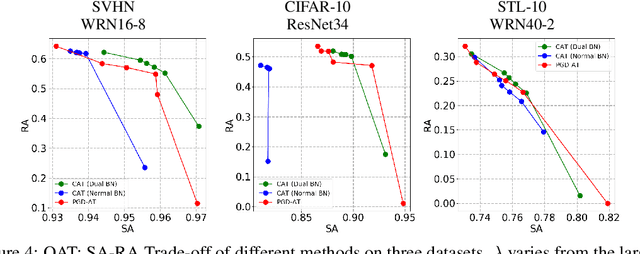
Adversarial training and its many variants substantially improve deep network robustness, yet at the cost of compromising standard accuracy. Moreover, the training process is heavy and hence it becomes impractical to thoroughly explore the trade-off between accuracy and robustness. This paper asks this new question: how to quickly calibrate a trained model in-situ, to examine the achievable trade-offs between its standard and robust accuracies, without (re-)training it many times? Our proposed framework, Once-for-all Adversarial Training (OAT), is built on an innovative model-conditional training framework, with a controlling hyper-parameter as the input. The trained model could be adjusted among different standard and robust accuracies "for free" at testing time. As an important knob, we exploit dual batch normalization to separate standard and adversarial feature statistics, so that they can be learned in one model without degrading performance. We further extend OAT to a Once-for-all Adversarial Training and Slimming (OATS) framework, that allows for the joint trade-off among accuracy, robustness and runtime efficiency. Experiments show that, without any re-training nor ensembling, OAT/OATS achieve similar or even superior performance compared to dedicatedly trained models at various configurations. Our codes and pretrained models are available at: https://github.com/VITA-Group/Once-for-All-Adversarial-Training.
In-the-wild Drowsiness Detection from Facial Expressions
Oct 21, 2020
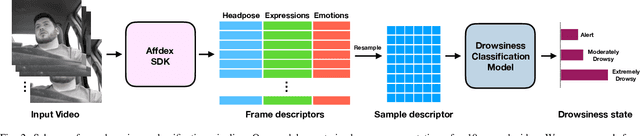
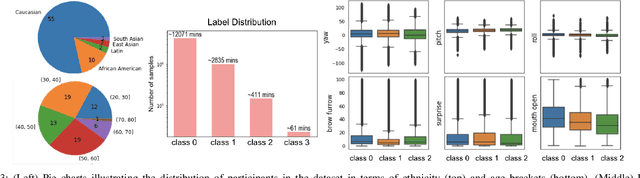
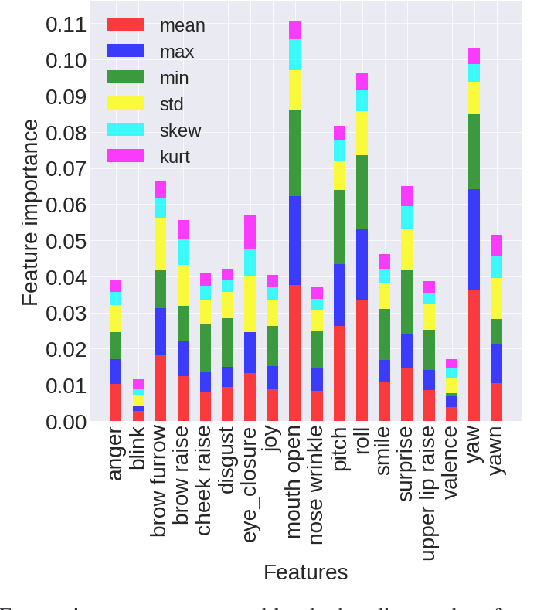
Driving in a state of drowsiness is a major cause of road accidents, resulting in tremendous damage to life and property. Developing robust, automatic, real-time systems that can infer drowsiness states of drivers has the potential of making life-saving impact. However, developing drowsiness detection systems that work well in real-world scenarios is challenging because of the difficulties associated with collecting high-volume realistic drowsy data and modeling the complex temporal dynamics of evolving drowsy states. In this paper, we propose a data collection protocol that involves outfitting vehicles of overnight shift workers with camera kits that record their faces while driving. We develop a drowsiness annotation guideline to enable humans to label the collected videos into 4 levels of drowsiness: `alert', `slightly drowsy', `moderately drowsy' and `extremely drowsy'. We experiment with different convolutional and temporal neural network architectures to predict drowsiness states from pose, expression and emotion-based representation of the input video of the driver's face. Our best performing model achieves a macro ROC-AUC of 0.78, compared to 0.72 for a baseline model.
Quantitative Propagation of Chaos for SGD in Wide Neural Networks
Jul 13, 2020In this paper, we investigate the limiting behavior of a continuous-time counterpart of the Stochastic Gradient Descent (SGD) algorithm applied to two-layer overparameterized neural networks, as the number or neurons (ie, the size of the hidden layer) $N \to +\infty$. Following a probabilistic approach, we show 'propagation of chaos' for the particle system defined by this continuous-time dynamics under different scenarios, indicating that the statistical interaction between the particles asymptotically vanishes. In particular, we establish quantitative convergence with respect to $N$ of any particle to a solution of a mean-field McKean-Vlasov equation in the metric space endowed with the Wasserstein distance. In comparison to previous works on the subject, we consider settings in which the sequence of stepsizes in SGD can potentially depend on the number of neurons and the iterations. We then identify two regimes under which different mean-field limits are obtained, one of them corresponding to an implicitly regularized version of the minimization problem at hand. We perform various experiments on real datasets to validate our theoretical results, assessing the existence of these two regimes on classification problems and illustrating our convergence results.
Domain aware medical image classifier interpretation by counterfactual impact analysis
Jul 13, 2020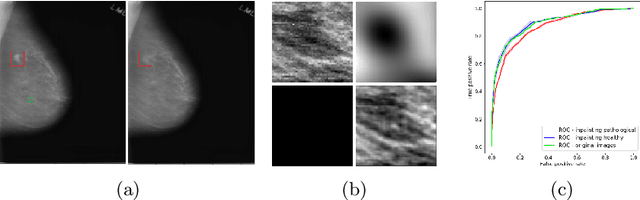

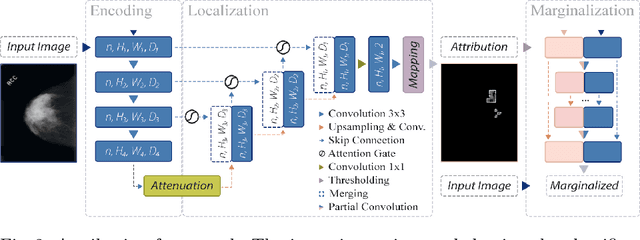
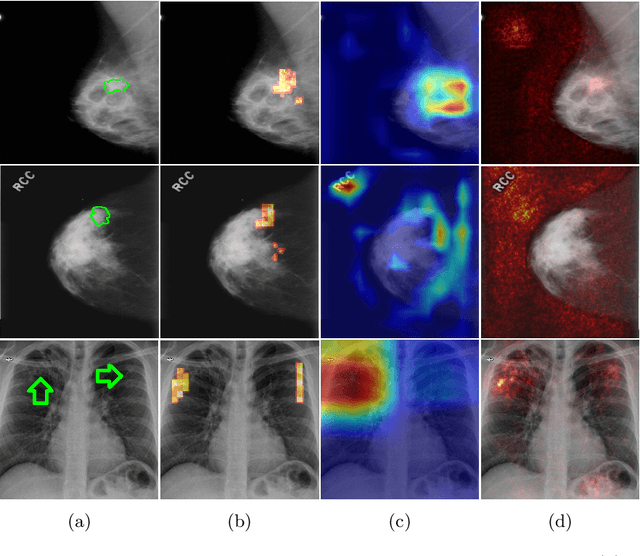
The success of machine learning methods for computer vision tasks has driven a surge in computer assisted prediction for medicine and biology. Based on a data-driven relationship between input image and pathological classification, these predictors deliver unprecedented accuracy. Yet, the numerous approaches trying to explain the causality of this learned relationship have fallen short: time constraints, coarse, diffuse and at times misleading results, caused by the employment of heuristic techniques like Gaussian noise and blurring, have hindered their clinical adoption. In this work, we discuss and overcome these obstacles by introducing a neural-network based attribution method, applicable to any trained predictor. Our solution identifies salient regions of an input image in a single forward-pass by measuring the effect of local image-perturbations on a predictor's score. We replace heuristic techniques with a strong neighborhood conditioned inpainting approach, avoiding anatomically implausible, hence adversarial artifacts. We evaluate on public mammography data and compare against existing state-of-the-art methods. Furthermore, we exemplify the approach's generalizability by demonstrating results on chest X-rays. Our solution shows, both quantitatively and qualitatively, a significant reduction of localization ambiguity and clearer conveying results, without sacrificing time efficiency.
CharacterBERT: Reconciling ELMo and BERT for Word-Level Open-Vocabulary Representations From Characters
Oct 21, 2020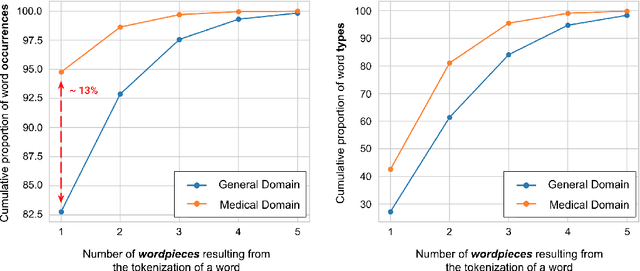

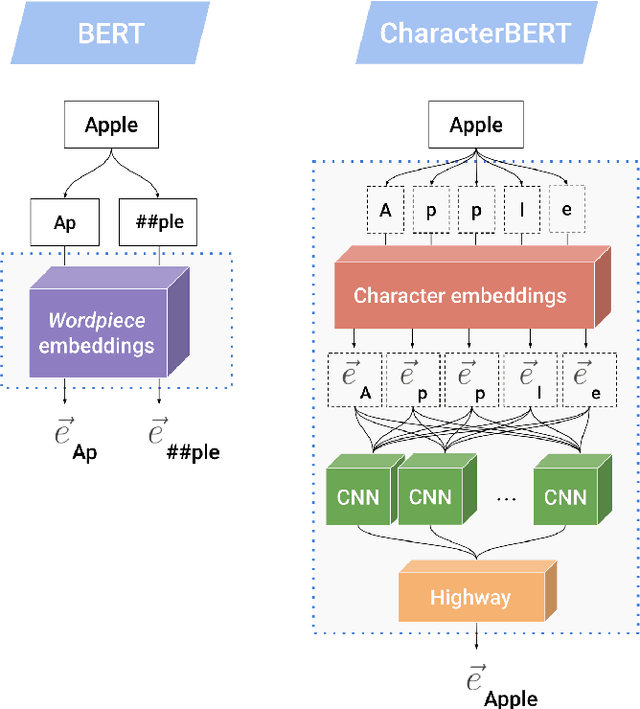
Due to the compelling improvements brought by BERT, many recent representation models adopted the Transformer architecture as their main building block, consequently inheriting the wordpiece tokenization system despite it not being intrinsically linked to the notion of Transformers. While this system is thought to achieve a good balance between the flexibility of characters and the efficiency of full words, using predefined wordpiece vocabularies from the general domain is not always suitable, especially when building models for specialized domains (e.g., the medical domain). Moreover, adopting a wordpiece tokenization shifts the focus from the word level to the subword level, making the models conceptually more complex and arguably less convenient in practice. For these reasons, we propose CharacterBERT, a new variant of BERT that drops the wordpiece system altogether and uses a Character-CNN module instead to represent entire words by consulting their characters. We show that this new model improves the performance of BERT on a variety of medical domain tasks while at the same time producing robust, word-level and open-vocabulary representations.
When Hearst Is not Enough: Improving Hypernymy Detection from Corpus with Distributional Models
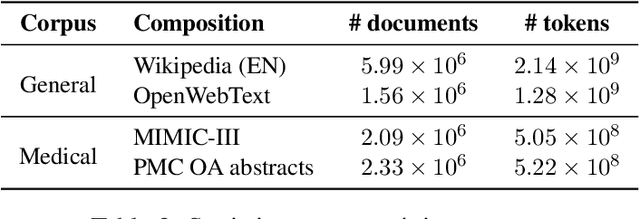
Oct 10, 2020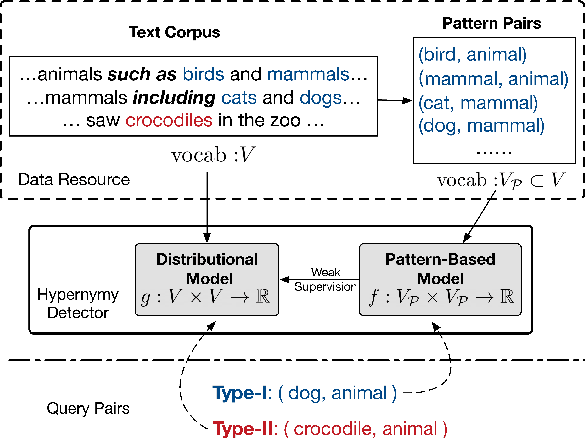
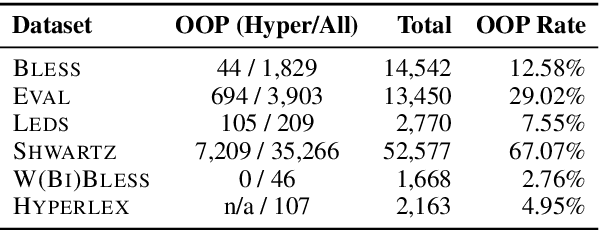
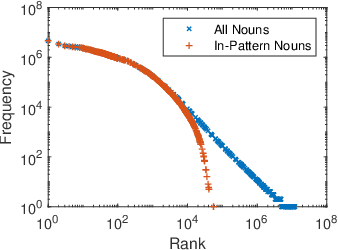
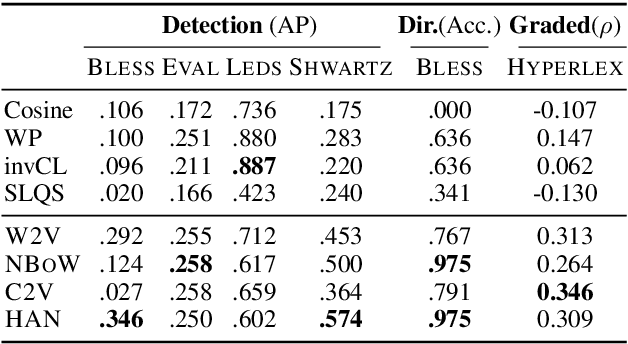
We address hypernymy detection, i.e., whether an is-a relationship exists between words (x, y), with the help of large textual corpora. Most conventional approaches to this task have been categorized to be either pattern-based or distributional. Recent studies suggest that pattern-based ones are superior, if large-scale Hearst pairs are extracted and fed, with the sparsity of unseen (x, y) pairs relieved. However, they become invalid in some specific sparsity cases, where x or y is not involved in any pattern. For the first time, this paper quantifies the non-negligible existence of those specific cases. We also demonstrate that distributional methods are ideal to make up for pattern-based ones in such cases. We devise a complementary framework, under which a pattern-based and a distributional model collaborate seamlessly in cases which they each prefer. On several benchmark datasets, our framework achieves competitive improvements and the case study shows its better interpretability.
Image Animation with Perturbed Masks
Nov 18, 2020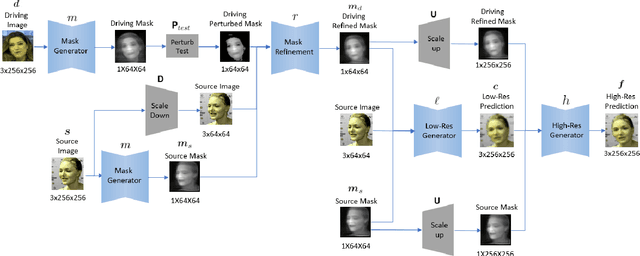
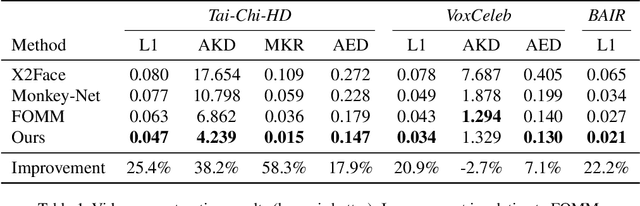
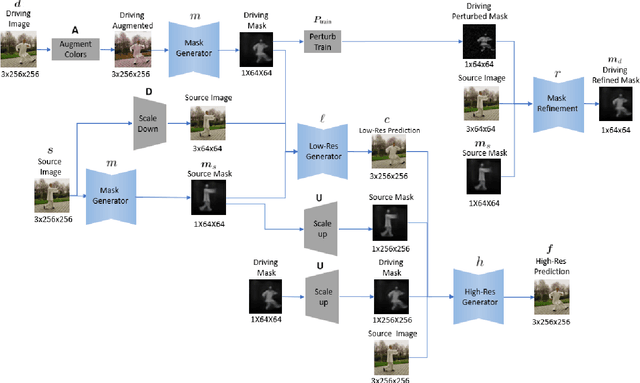
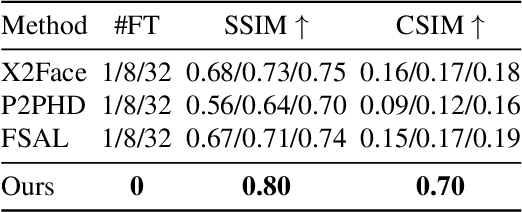
We present a novel approach for image-animation of a source image by a driving video, both depicting the same type of object. We do not assume the existence of pose models and our method is able to animate arbitrary objects without knowledge of the object's structure. Furthermore, both the driving video and the source image are only seen during test-time. Our method is based on a shared mask generator, which separates the foreground object from its background, and captures the object's general pose and shape. A mask-refinement module then replaces, in the mask extracted from the driver image, the identity of the driver with the identity of the source. Conditioned on the source image, the transformed mask is then decoded by a multi-scale generator that renders a realistic image, in which the content of the source frame is animated by the pose in the driving video. Due to lack of fully supervised data, we train on the task of reconstructing frames from the same video the source image is taken from. In order to control {the} source of the identity of the output frame, we employ during training perturbations that remove the unwanted identity information. Our method is shown to greatly outperform the state of the art methods on multiple benchmarks. Our code and samples are available at https://github.com/itsyoavshalev/Image-Animation-with-Perturbed-Masks
Effects of Voice-Based Synthetic Assistant on Performance of Emergency Care Provider in Training
Aug 12, 2020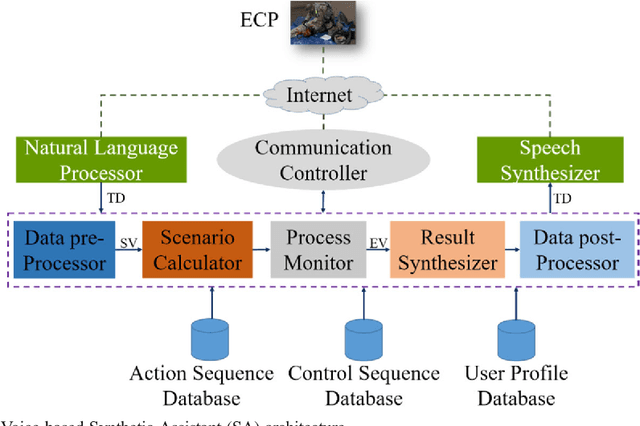
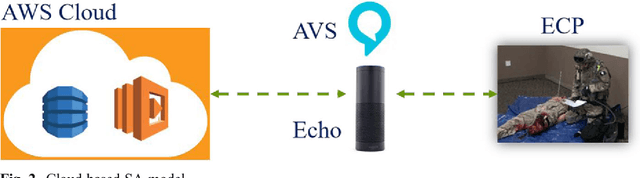


As part of a perennial project, our team is actively engaged in developing new synthetic assistant (SA) technologies to assist in training combat medics and medical first responders. It is critical that medical first responders are well trained to deal with emergencies more effectively. This would require real-time monitoring and feedback for each trainee. Therefore, we introduced a voice-based SA to augment the training process of medical first responders and enhance their performance in the field. The potential benefits of SAs include a reduction in training costs and enhanced monitoring mechanisms. Despite the increased usage of voice-based personal assistants (PAs) in day-to-day life, the associated effects are commonly neglected for a study of human factors. Therefore, this paper focuses on performance analysis of the developed voice-based SA in emergency care provider training for a selected emergency treatment scenario. The research discussed in this paper follows design science in developing proposed technology; at length, we discussed architecture and development and presented working results of voice-based SA. The empirical testing was conducted on two groups as user studies using statistical analysis tools, one trained with conventional methods and the other with the help of SA. The statistical results demonstrated the amplification in training efficacy and performance of medical responders powered by SA. Furthermore, the paper also discusses the accuracy and time of task execution (t) and concludes with the guidelines for resolving the identified problems.
Artificial Intelligence & Cooperation
Dec 10, 2020The rise of Artificial Intelligence (AI) will bring with it an ever-increasing willingness to cede decision-making to machines. But rather than just giving machines the power to make decisions that affect us, we need ways to work cooperatively with AI systems. There is a vital need for research in "AI and Cooperation" that seeks to understand the ways in which systems of AIs and systems of AIs with people can engender cooperative behavior. Trust in AI is also key: trust that is intrinsic and trust that can only be earned over time. Here we use the term "AI" in its broadest sense, as employed by the recent 20-Year Community Roadmap for AI Research (Gil and Selman, 2019), including but certainly not limited to, recent advances in deep learning. With success, cooperation between humans and AIs can build society just as human-human cooperation has. Whether coming from an intrinsic willingness to be helpful, or driven through self-interest, human societies have grown strong and the human species has found success through cooperation. We cooperate "in the small" -- as family units, with neighbors, with co-workers, with strangers -- and "in the large" as a global community that seeks cooperative outcomes around questions of commerce, climate change, and disarmament. Cooperation has evolved in nature also, in cells and among animals. While many cases involving cooperation between humans and AIs will be asymmetric, with the human ultimately in control, AI systems are growing so complex that, even today, it is impossible for the human to fully comprehend their reasoning, recommendations, and actions when functioning simply as passive observers.
SSN: Soft Shadow Network for Image Compositing
Jul 16, 2020

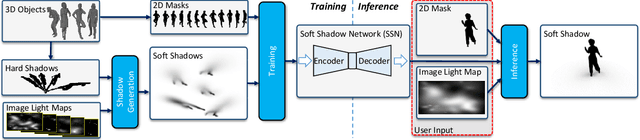

In image compositing tasks, objects from different sources are put together to form a new image. Artists often increase realism by adding object shadows to match the scene geometry and lighting. However, creating realistic soft shadows requires skill and is time-consuming. We introduce a Soft Shadow Network to generate convincing soft shadows for 2D object cutouts automatically. SSN takes an object cutout mask as input and thus is agnostic to image types such as painting and vector art. Although inferring the 3D shape of an object from its silhouette can be ambiguous, it is easy for humans to get the 3D geometry from a 2D projection when it is in an iconic view. We follow this intuition and train the SSN to render soft shadows for objects' iconic views. To train our model, we design an efficient pipeline to produce diverse soft shadow training data using 3D object models. Our pipeline first computes a set of soft shadow bases by sampling hard shadows. During training, environment lighting maps that cover a wide spectrum of possible configurations are used to calculate the soft shadow ground truth using the shadow bases. This enables our model to see a complex lighting pattern and to learn the interaction between the lights and 3D geometries. In addition, we propose an inverse shadow map representation, which makes the training focused on the shadow area and leads to much faster convergence and better performance. We show that our model produces realistic soft shadow details for objects of different shapes. A user study shows that SSN generated shadows are often indistinguishable from shadows calculated by physics-based rendering. Our SSN can produce a shadow in real-time and it allows real-time interactive shadow manipulation. We develop a simple user interface and a second user study shows that amateur users can easily use our tool to generate soft shadows matching a reference shadow.