 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Modeling extra-deep EM logs using a deep neural network
May 18, 2020
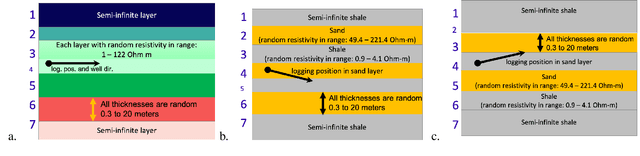
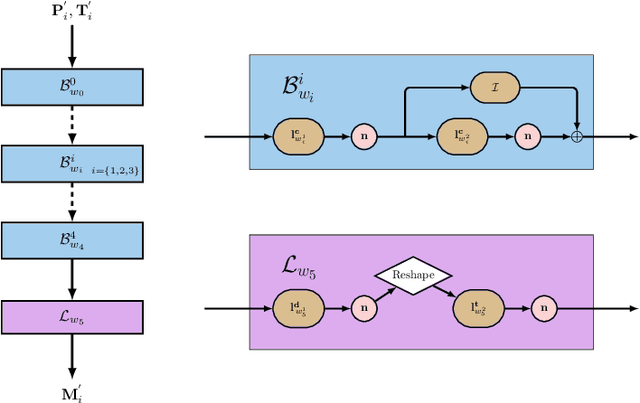
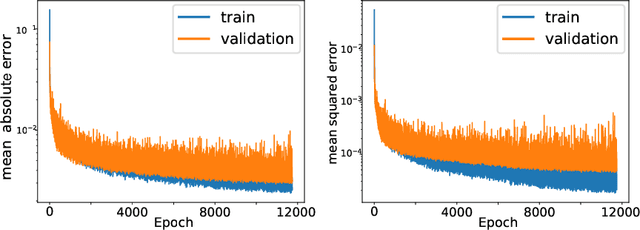
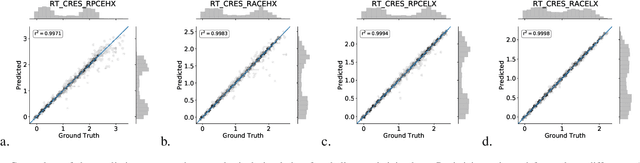
Modern geosteering is heavily dependent on real-time interpretation of deep electromagnetic (EM) measurements. This work presents a deep neural network (DNN) model trained to reproduce the full set of extra-deep real-time EM logs consisting of 22 measurements per logging position. The model is trained in a 1D layered environment and has sensitivity for up to seven layers with different resistivity values. A commercial simulator provided by a tool vendor is utilized to generate a training dataset. The impossibility of parallel execution of the simulator effectively limits the permissible dataset size. Therefore, the geological rules and geosteering specifics supported by the forward model are embraced when designing the dataset. It is then used to produce a fully parallel EM simulator based on a DNN without access to the proprietary information about the EM tool configuration or the original simulator source code. Despite a relatively small training set size, the resulting DNN forward model is quite accurate for synthetic geosteering cases, yet independent of the logging instrument vendor. The observed average evaluation time of 0.15 milliseconds per logging position makes it also suitable for future use as part of evaluation-hungry statistical and/or Monte-Carlo inversion algorithms.
Deep Learning Towards Edge Computing: Neural Networks Straight from Compressed Data
Dec 26, 2020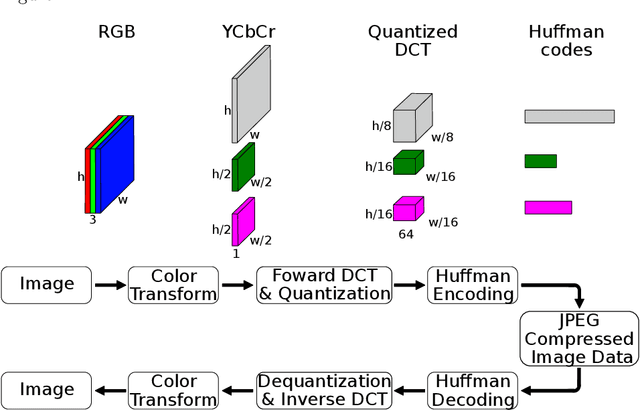
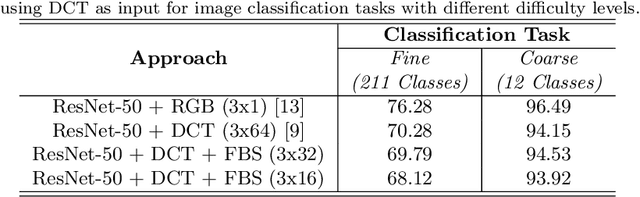
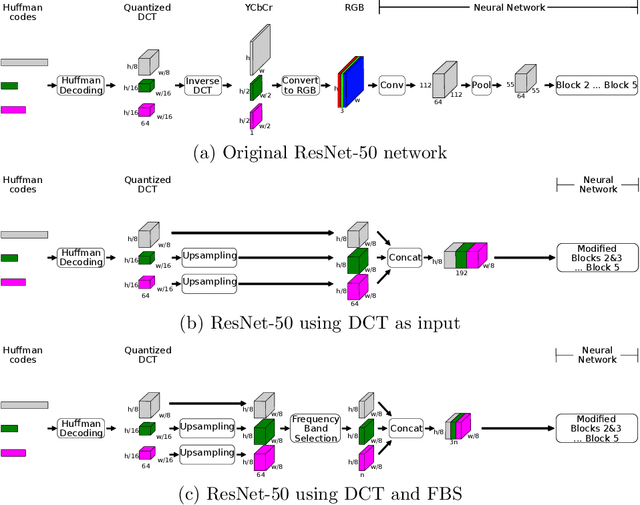
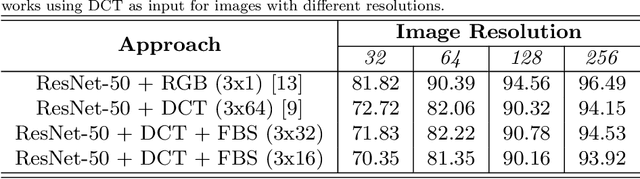
Due to the popularization and grow in computational power of mobile phones, as well as advances in artificial intelligence, many intelligent applications have been developed, meaningfully enriching people's life. For this reason, there is a growing interest in the area of edge intelligence, that aims to push the computation of data to the edges of the network, in order to make those applications more efficient and secure. Many intelligent applications rely on deep learning models, like convolutional neural networks (CNNs). Over the past decade, they have achieved state-of-the-art performance in many computer vision tasks. To increase the performance of these methods, the trend has been to use increasingly deeper architectures and with more parameters, leading to a high computational cost. Indeed, this is one of the main problems faced by deep architectures, limiting their applicability in domains with limited computational resources, like edge devices. To alleviate the computational complexity, we propose a deep neural network capable of learning straight from the relevant information pertaining to visual content readily available in the compressed representation used for image and video storage and transmission. The novelty of our approach is that it was designed to operate directly on frequency domain data, learning with DCT coefficients rather than RGB pixels. This enables to save high computational load in full decoding the data stream and therefore greatly speed up the processing time, which has become a big bottleneck of deep learning. We evaluated our network on two challenging tasks: (1) image classification on the ImageNet dataset and (2) video classification on the UCF-101 and HMDB-51 datasets. Our results demonstrate comparable effectiveness to the state-of-the-art methods in terms of accuracy, with the advantage of being more computationally efficient.
Fantastic Features and Where to Find Them: Detecting Cognitive Impairment with a Subsequence Classification Guided Approach
Oct 13, 2020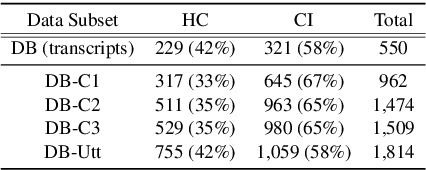

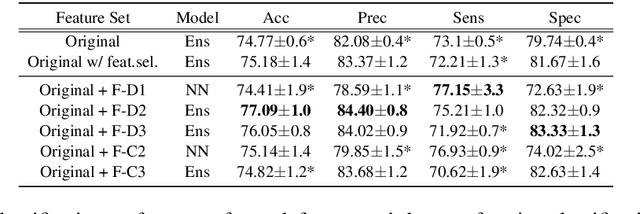

Despite the widely reported success of embedding-based machine learning methods on natural language processing tasks, the use of more easily interpreted engineered features remains common in fields such as cognitive impairment (CI) detection. Manually engineering features from noisy text is time and resource consuming, and can potentially result in features that do not enhance model performance. To combat this, we describe a new approach to feature engineering that leverages sequential machine learning models and domain knowledge to predict which features help enhance performance. We provide a concrete example of this method on a standard data set of CI speech and demonstrate that CI classification accuracy improves by 2.3% over a strong baseline when using features produced by this method. This demonstration provides an ex-ample of how this method can be used to assist classification in fields where interpretability is important, such as health care.
Deep traffic light detection by overlaying synthetic context on arbitrary natural images
Nov 10, 2020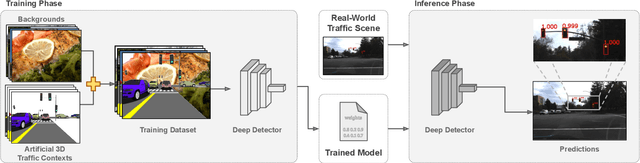
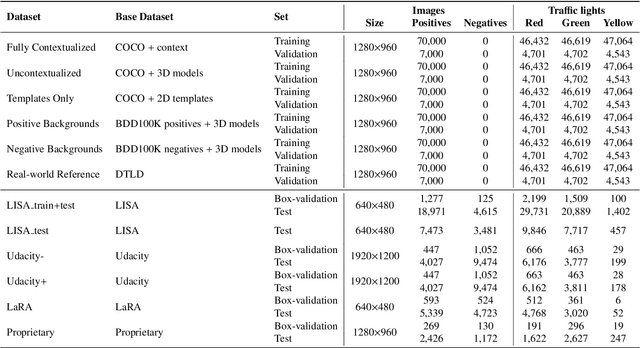
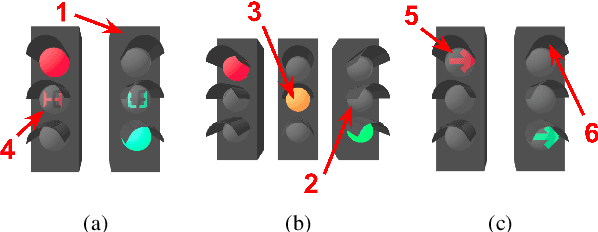
Deep neural networks come as an effective solution to many problems associated with autonomous driving. By providing real image samples with traffic context to the network, the model learns to detect and classify elements of interest, such as pedestrians, traffic signs, and traffic lights. However, acquiring and annotating real data can be extremely costly in terms of time and effort. In this context, we propose a method to generate artificial traffic-related training data for deep traffic light detectors. This data is generated using basic non-realistic computer graphics to blend fake traffic scenes on top of arbitrary image backgrounds that are not related to the traffic domain. Thus, a large amount of training data can be generated without annotation efforts. Furthermore, it also tackles the intrinsic data imbalance problem in traffic light datasets, caused mainly by the low amount of samples of the yellow state. Experiments show that it is possible to achieve results comparable to those obtained with real training data from the problem domain, yielding an average mAP and an average F1-score which are each nearly 4 p.p. higher than the respective metrics obtained with a real-world reference model.
An Event Correlation Filtering Method for Fake News Detection
Dec 13, 2020
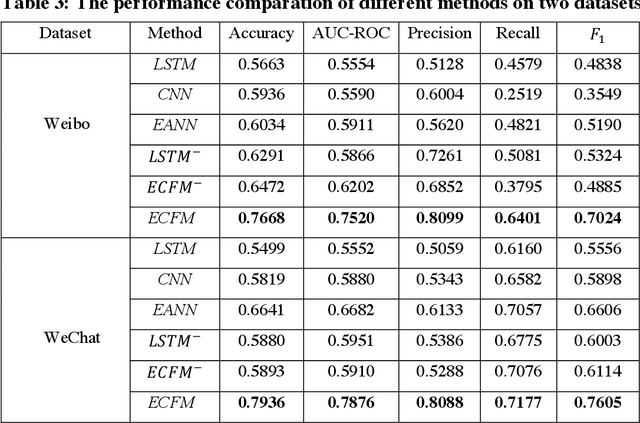
Nowadays, social network platforms have been the prime source for people to experience news and events due to their capacities to spread information rapidly, which inevitably provides a fertile ground for the dissemination of fake news. Thus, it is significant to detect fake news otherwise it could cause public misleading and panic. Existing deep learning models have achieved great progress to tackle the problem of fake news detection. However, training an effective deep learning model usually requires a large amount of labeled news, while it is expensive and time-consuming to provide sufficient labeled news in actual applications. To improve the detection performance of fake news, we take advantage of the event correlations of news and propose an event correlation filtering method (ECFM) for fake news detection, mainly consisting of the news characterizer, the pseudo label annotator, the event credibility updater, and the news entropy selector. The news characterizer is responsible for extracting textual features from news, which cooperates with the pseudo label annotator to assign pseudo labels for unlabeled news by fully exploiting the event correlations of news. In addition, the event credibility updater employs adaptive Kalman filter to weaken the credibility fluctuations of events. To further improve the detection performance, the news entropy selector automatically discovers high-quality samples from pseudo labeled news by quantifying their news entropy. Finally, ECFM is proposed to integrate them to detect fake news in an event correlation filtering manner. Extensive experiments prove that the explainable introduction of the event correlations of news is beneficial to improve the detection performance of fake news.
Similarity-based data mining for online domain adaptation of a sonar ATR system
Sep 16, 2020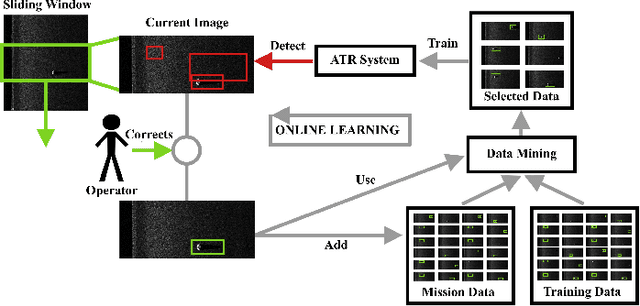
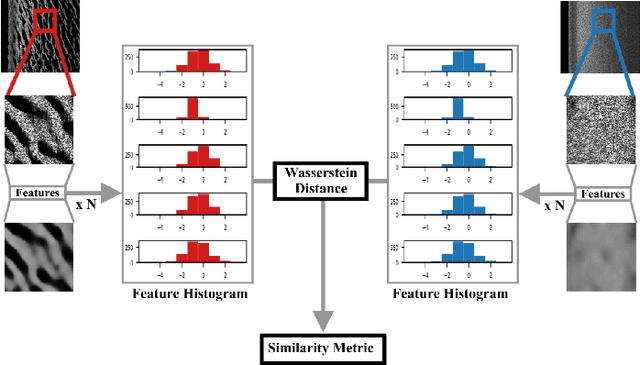

Due to the expensive nature of field data gathering, the lack of training data often limits the performance of Automatic Target Recognition (ATR) systems. This problem is often addressed with domain adaptation techniques, however the currently existing methods fail to satisfy the constraints of resource and time-limited underwater systems. We propose to address this issue via an online fine-tuning of the ATR algorithm using a novel data-selection method. Our proposed data-mining approach relies on visual similarity and outperforms the traditionally employed hard-mining methods. We present a comparative performance analysis in a wide range of simulated environments and highlight the benefits of using our method for the rapid adaptation to previously unseen environments.
* Accepted for publication in IEEE OCEANS2020
Faster Convergence of Stochastic Gradient Langevin Dynamics for Non-Log-Concave Sampling
Oct 19, 2020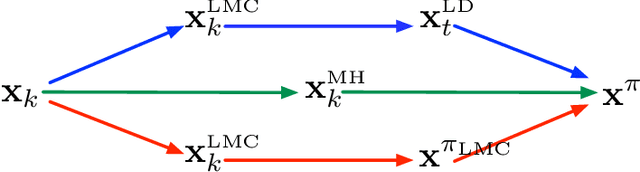
We establish a new convergence analysis of stochastic gradient Langevin dynamics (SGLD) for sampling from a class of distributions that can be non-log-concave. At the core of our approach is a novel conductance analysis of SGLD using an auxiliary time-reversible Markov Chain. Under certain conditions on the target distribution, we prove that $\tilde O(d^4\epsilon^{-2})$ stochastic gradient evaluations suffice to guarantee $\epsilon$-sampling error in terms of the total variation distance, where $d$ is the problem dimension, which improves existing results on the convergence rate of SGLD (Raginsky et al., 2017; Xu et al., 2018). We further show that provided an additional Hessian Lipschitz condition on the log-density function, SGLD is guaranteed to achieve $\epsilon$-sampling error within $\tilde O(d^{15/4}\epsilon^{-3/2})$ stochastic gradient evaluations. Our proof technique provides a new way to study the convergence of Langevin based algorithms, and sheds some light on the design of fast stochastic gradient based sampling algorithms.
A Linear Transportation $\mathrm{L}^p$ Distance for Pattern Recognition
Sep 23, 2020
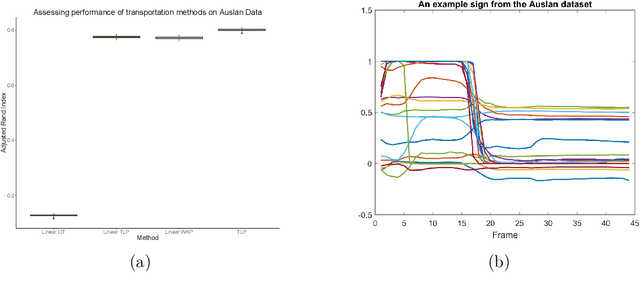
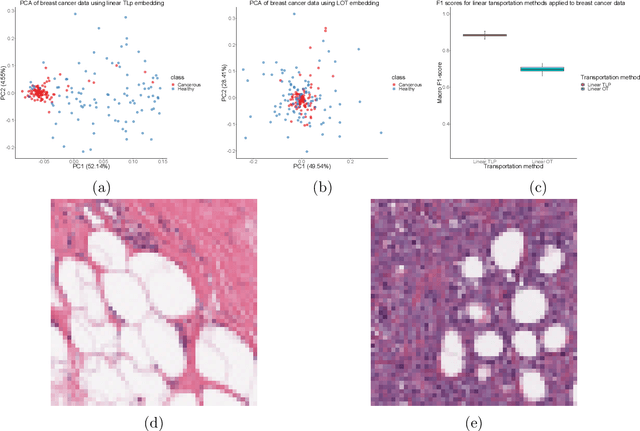
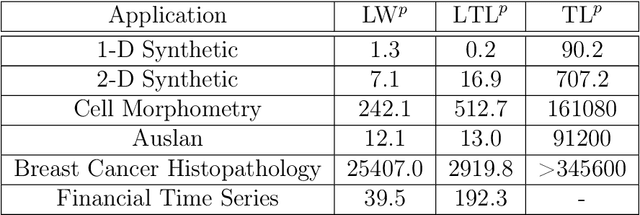
The transportation $\mathrm{L}^p$ distance, denoted $\mathrm{TL}^p$, has been proposed as a generalisation of Wasserstein $\mathrm{W}^p$ distances motivated by the property that it can be applied directly to colour or multi-channelled images, as well as multivariate time-series without normalisation or mass constraints. These distances, as with $\mathrm{W}^p$, are powerful tools in modelling data with spatial or temporal perturbations. However, their computational cost can make them infeasible to apply to even moderate pattern recognition tasks. We propose linear versions of these distances and show that the linear $\mathrm{TL}^p$ distance significantly improves over the linear $\mathrm{W}^p$ distance on signal processing tasks, whilst being several orders of magnitude faster to compute than the $\mathrm{TL}^p$ distance.
Multilayer Network Analysis for Improved Credit Risk Prediction
Oct 19, 2020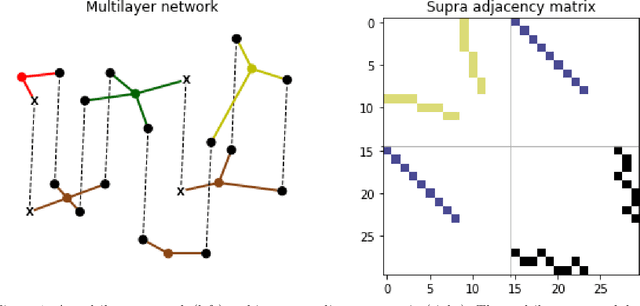
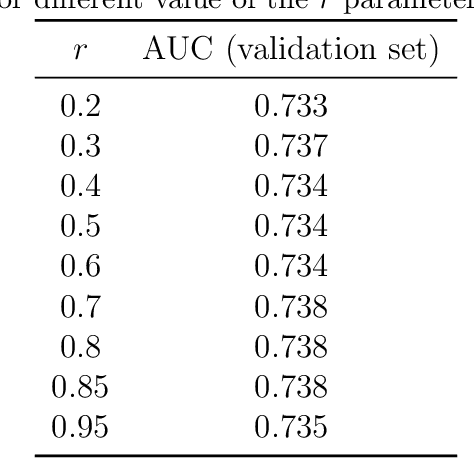
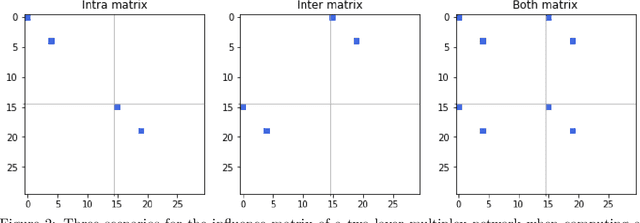
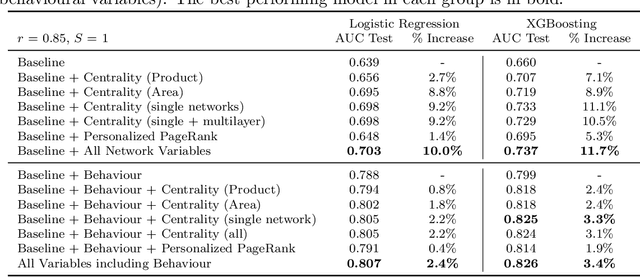
We present a multilayer network model for credit risk assessment. Our model accounts for multiple connections between borrowers (such as their geographic location and their economic activity) and allows for explicitly modelling the interaction between connected borrowers. We develop a multilayer personalized PageRank algorithm that allows quantifying the strength of the default exposure of any borrower in the network. We test our methodology in an agricultural lending framework, where it has been suspected for a long time default correlates between borrowers when they are subject to the same structural risks. Our results show there are significant predictive gains just by including centrality multilayer network information to the model, and this gains are increased by more complex information such as the multilayer PageRank variables. The results suggest default risk is highest when an individual is connected to many defaulters, but this risk is mitigated by the size of the neighbourhood of the individual, showing both default risk and financial stability propagate throughout the network.
CLAR: Contrastive Learning of Auditory Representations
Oct 19, 2020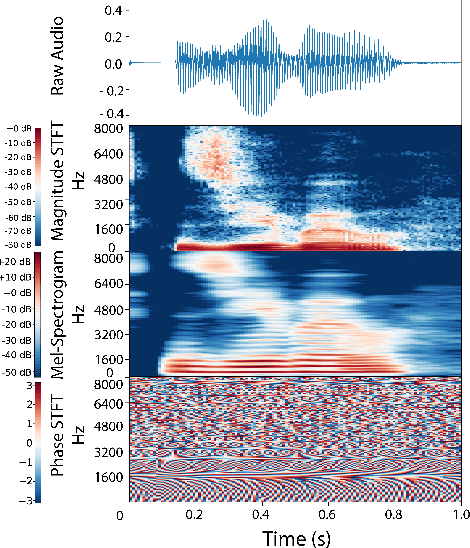
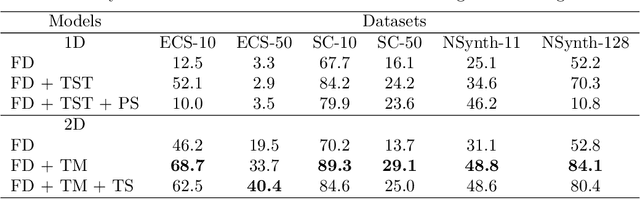
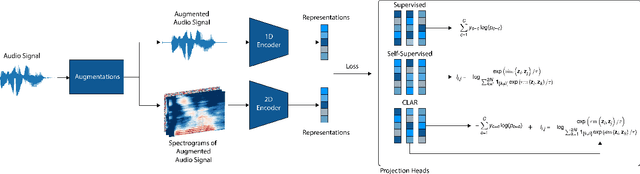
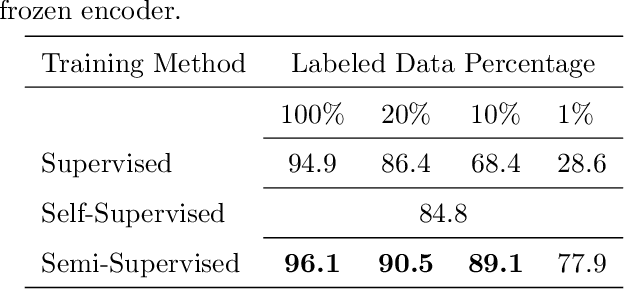
Learning rich visual representations using contrastive self-supervised learning has been extremely successful. However, it is still a major question whether we could use a similar approach to learn superior auditory representations. In this paper, we expand on prior work (SimCLR) to learn better auditory representations. We (1) introduce various data augmentations suitable for auditory data and evaluate their impact on predictive performance, (2) show that training with time-frequency audio features substantially improves the quality of the learned representations compared to raw signals, and (3) demonstrate that training with both supervised and contrastive losses simultaneously improves the learned representations compared to self-supervised pre-training followed by supervised fine-tuning. We illustrate that by combining all these methods and with substantially less labeled data, our framework (CLAR) achieves significant improvement on prediction performance compared to supervised approach. Moreover, compared to self-supervised approach, our framework converges faster with significantly better representations.