 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Neuromorphic control for optic-flow-based landings of MAVs using the Loihi processor
Nov 01, 2020




Neuromorphic processors like Loihi offer a promising alternative to conventional computing modules for endowing constrained systems like micro air vehicles (MAVs) with robust, efficient and autonomous skills such as take-off and landing, obstacle avoidance, and pursuit. However, a major challenge for using such processors on robotic platforms is the reality gap between simulation and the real world. In this study, we present for the very first time a fully embedded application of the Loihi neuromorphic chip prototype in a flying robot. A spiking neural network (SNN) was evolved to compute the thrust command based on the divergence of the ventral optic flow field to perform autonomous landing. Evolution was performed in a Python-based simulator using the PySNN library. The resulting network architecture consists of only 35 neurons distributed among 3 layers. Quantitative analysis between simulation and Loihi reveals a root-mean-square error of the thrust setpoint as low as 0.005 g, along with a 99.8% matching of the spike sequences in the hidden layer, and 99.7% in the output layer. The proposed approach successfully bridges the reality gap, offering important insights for future neuromorphic applications in robotics. Supplementary material is available at https://mavlab.tudelft.nl/loihi/.
Uncertainty-driven ensembles of deep architectures for multiclass classification. Application to COVID-19 diagnosis in chest X-ray images
Nov 27, 2020

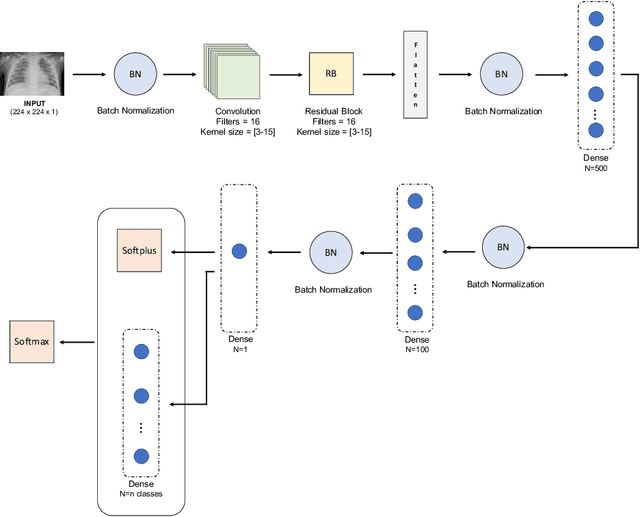
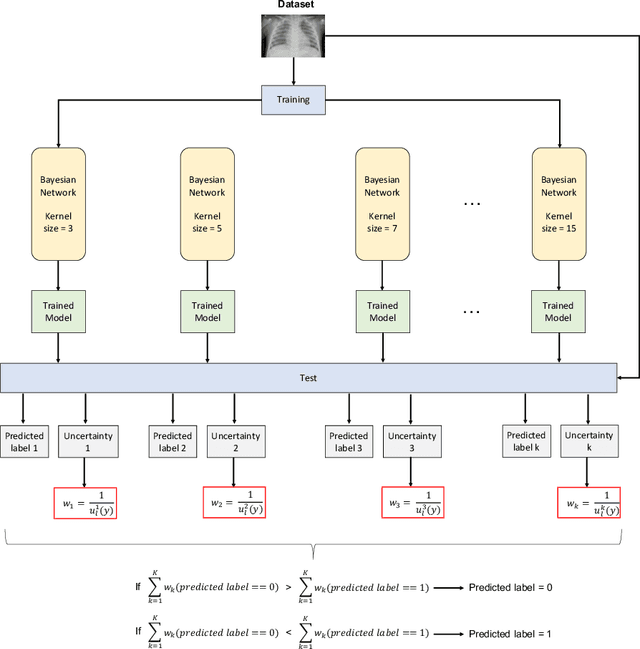
Respiratory diseases kill million of people each year. Diagnosis of these pathologies is a manual, time-consuming process that has inter and intra-observer variability, delaying diagnosis and treatment. The recent COVID-19 pandemic has demonstrated the need of developing systems to automatize the diagnosis of pneumonia, whilst Convolutional Neural Network (CNNs) have proved to be an excellent option for the automatic classification of medical images. However, given the need of providing a confidence classification in this context it is crucial to quantify the reliability of the model's predictions. In this work, we propose a multi-level ensemble classification system based on a Bayesian Deep Learning approach in order to maximize performance while quantifying the uncertainty of each classification decision. This tool combines the information extracted from different architectures by weighting their results according to the uncertainty of their predictions. Performance of the Bayesian network is evaluated in a real scenario where simultaneously differentiating between four different pathologies: control vs bacterial pneumonia vs viral pneumonia vs COVID-19 pneumonia. A three-level decision tree is employed to divide the 4-class classification into three binary classifications, yielding an accuracy of 98.06% and overcoming the results obtained by recent literature. The reduced preprocessing needed for obtaining this high performance, in addition to the information provided about the reliability of the predictions evidence the applicability of the system to be used as an aid for clinicians.
Graph Attention Networks for Speaker Verification
Oct 22, 2020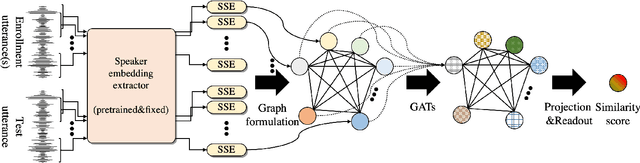
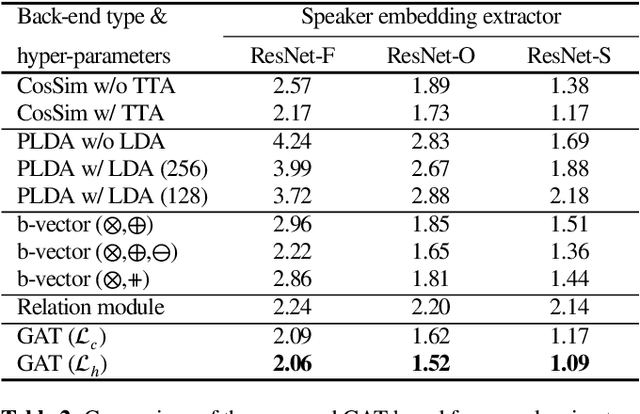
This work presents a novel back-end framework for speaker verification using graph attention networks. Segment-wise speaker embeddings extracted from multiple crops within an utterance are interpreted as node representations of a graph. The proposed framework inputs segment-wise speaker embeddings from an enrollment and a test utterance and directly outputs a similarity score. We first construct a graph using segment-wise speaker embeddings and then input these to graph attention networks. After a few graph attention layers with residual connections, each node is projected into a one-dimensional space using affine transform, followed by a readout operation resulting in a scalar similarity score. To enable successful adaptation for speaker verification, we propose techniques such as separating trainable weights for attention map calculations between segment-wise speaker embeddings from different utterances. The effectiveness of the proposed framework is validated using three different speaker embedding extractors trained with different architectures and objective functions. Experimental results demonstrate consistent improvement over various baseline back-end classifiers, with an average equal error rate improvement of 20% over the cosine similarity back-end without test time augmentation.
Quantitative Propagation of Chaos for SGD in Wide Neural Networks
Jul 14, 2020In this paper, we investigate the limiting behavior of a continuous-time counterpart of the Stochastic Gradient Descent (SGD) algorithm applied to two-layer overparameterized neural networks, as the number or neurons (ie, the size of the hidden layer) $N \to +\infty$. Following a probabilistic approach, we show 'propagation of chaos' for the particle system defined by this continuous-time dynamics under different scenarios, indicating that the statistical interaction between the particles asymptotically vanishes. In particular, we establish quantitative convergence with respect to $N$ of any particle to a solution of a mean-field McKean-Vlasov equation in the metric space endowed with the Wasserstein distance. In comparison to previous works on the subject, we consider settings in which the sequence of stepsizes in SGD can potentially depend on the number of neurons and the iterations. We then identify two regimes under which different mean-field limits are obtained, one of them corresponding to an implicitly regularized version of the minimization problem at hand. We perform various experiments on real datasets to validate our theoretical results, assessing the existence of these two regimes on classification problems and illustrating our convergence results.
Glioma Classification Using Multimodal Radiology and Histology Data
Nov 10, 2020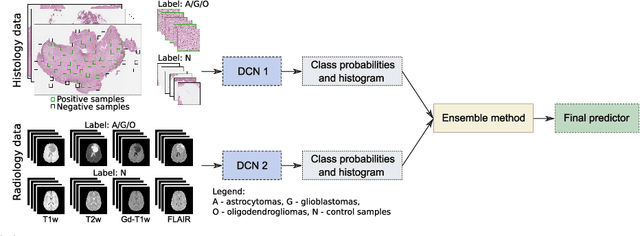
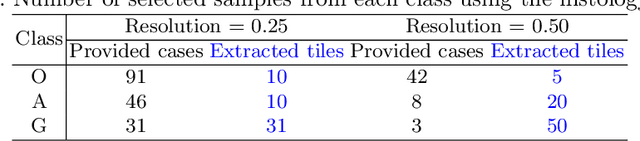
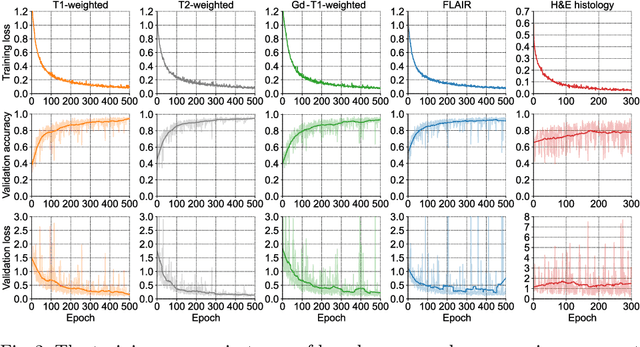
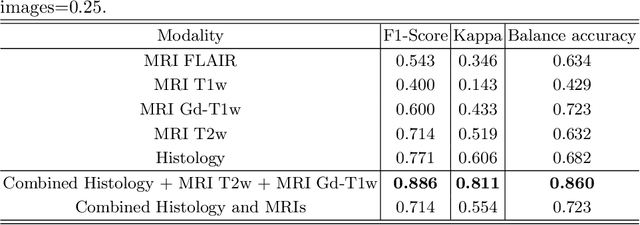
Gliomas are brain tumours with a high mortality rate. There are various grades and sub-types of this tumour, and the treatment procedure varies accordingly. Clinicians and oncologists diagnose and categorise these tumours based on visual inspection of radiology and histology data. However, this process can be time-consuming and subjective. The computer-assisted methods can help clinicians to make better and faster decisions. In this paper, we propose a pipeline for automatic classification of gliomas into three sub-types: oligodendroglioma, astrocytoma, and glioblastoma, using both radiology and histopathology images. The proposed approach implements distinct classification models for radiographic and histologic modalities and combines them through an ensemble method. The classification algorithm initially carries out tile-level (for histology) and slice-level (for radiology) classification via a deep learning method, then tile/slice-level latent features are combined for a whole-slide and whole-volume sub-type prediction. The classification algorithm was evaluated using the data set provided in the CPM-RadPath 2020 challenge. The proposed pipeline achieved the F1-Score of 0.886, Cohen's Kappa score of 0.811 and Balance accuracy of 0.860. The ability of the proposed model for end-to-end learning of diverse features enables it to give a comparable prediction of glioma tumour sub-types.
VOR Adaptation on a Humanoid iCub Robot Using a Spiking Cerebellar Model
Mar 03, 2020
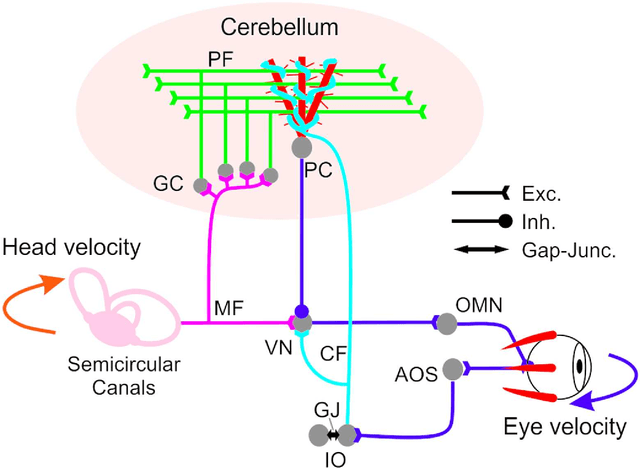
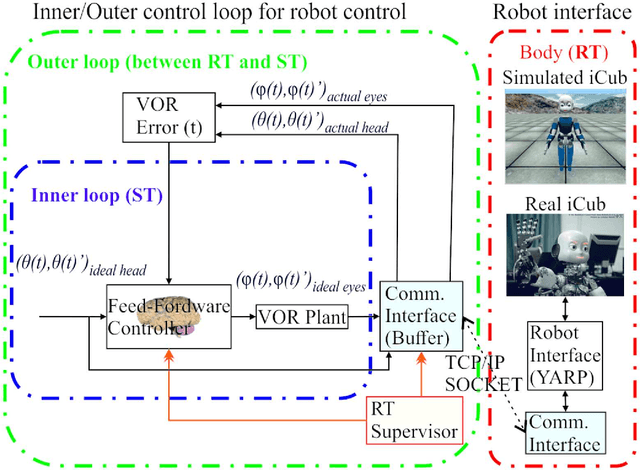
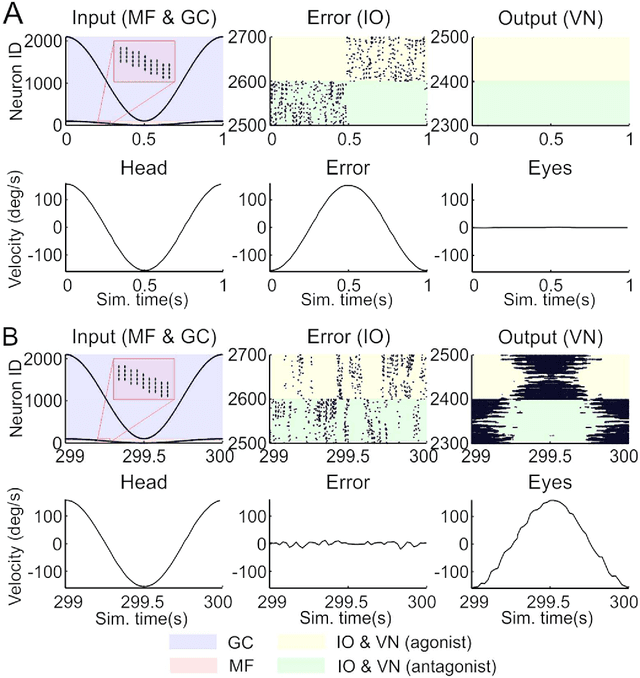
We embed a spiking cerebellar model within an adaptive real-time (RT) control loop that is able to operate a real robotic body (iCub) when performing different vestibulo-ocular reflex (VOR) tasks. The spiking neural network computation, including event- and time-driven neural dynamics, neural activity, and spike-timing dependent plasticity (STDP) mechanisms, leads to a nondeterministic computation time caused by the neural activity volleys encountered during cerebellar simulation. This nondeterministic computation time motivates the integration of an RT supervisor module that is able to ensure a well-orchestrated neural computation time and robot operation. Actually, our neurorobotic experimental setup (VOR) benefits from the biological sensory motor delay between the cerebellum and the body to buffer the computational overloads as well as providing flexibility in adjusting the neural computation time and RT operation. The RT supervisor module provides for incremental countermeasures that dynamically slow down or speed up the cerebellar simulation by either halting the simulation or disabling certain neural computation features (i.e., STDP mechanisms, spike propagation, and neural updates) to cope with the RT constraints imposed by the real robot operation. This neurorobotic experimental setup is applied to different horizontal and vertical VOR adaptive tasks that are widely used by the neuroscientific community to address cerebellar functioning. We aim to elucidate the manner in which the combination of the cerebellar neural substrate and the distributed plasticity shapes the cerebellar neural activity to mediate motor adaptation. This paper underlies the need for a two-stage learning process to facilitate VOR acquisition.
Prediction of Hemolysis Tendency of Peptides using a Reliable Evaluation Method
Dec 11, 2020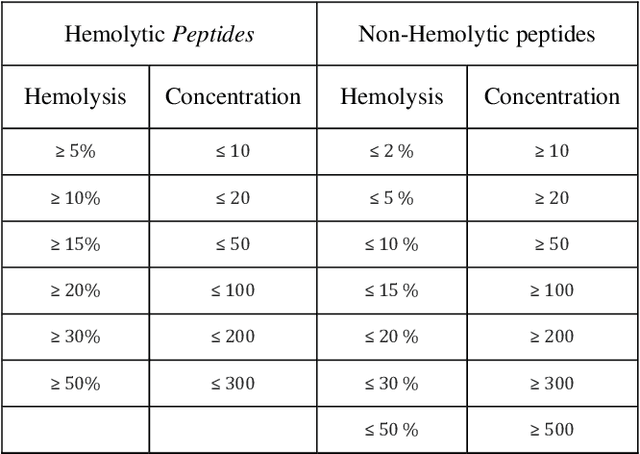
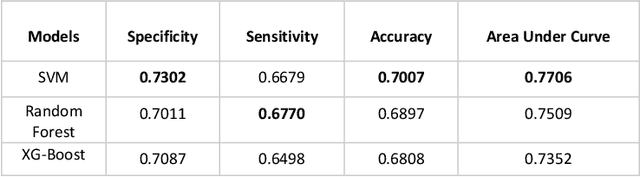
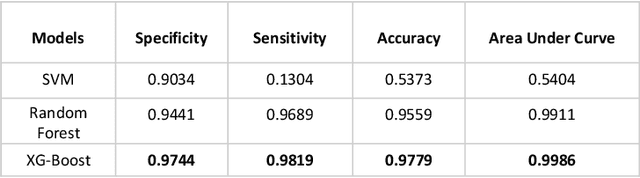
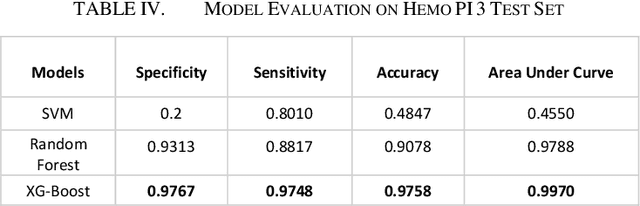
There are numerous peptides discovered through past decades, which exhibit antimicrobial and anti-cancerous tendencies. Due to these reasons, peptides are supposed to be sound therapeutic candidates. Some peptides can pose low metabolic stability, high toxicity and high hemolity of peptides. This highlights the importance for evaluating hemolytic tendencies and toxicity of peptides, before using them for therapeutics. Traditional methods for evaluation of toxicity of peptides can be time-consuming and costly. In this study, we have extracted peptides data (Hemo-DB) from Database of Antimicrobial Activity and Structure of Peptides (DBAASP) based on certain hemolity criteria and we present a machine learning based method for prediction of hemolytic tendencies of peptides (i.e. Hemolytic or Non-Hemolytic). Our model offers significant improvement on hemolity prediction benchmarks. we also propose a reliable clustering-based train-tests splitting method which ensures that no peptide in train set is more than 40% similar to any peptide in test set. Using this train-test split, we can get reliable estimated of expected model performance on unseen data distribution or newly discovered peptides. Our model tests 0.9986 AUC-ROC (Area Under Receiver Operating Curve) and 97.79% Accuracy on test set of Hemo-DB using traditional random train-test splitting method. Moreover, our model tests AUC-ROC of 0.997 and Accuracy of 97.58% while using clustering-based train-test data split. Furthermore, we check our model on an unseen data distribution (at Hemo-PI 3) and we recorded 0.8726 AUC-ROC and 79.5% accuracy. Using the proposed method, potential therapeutic peptides can be screened, which may further in therapeutics and get reliable predictions for unseen amino acids distribution of peptides and newly discovered peptides.
Deep-learning based down-scaling of summer monsoon rainfall data over Indian region
Nov 27, 2020
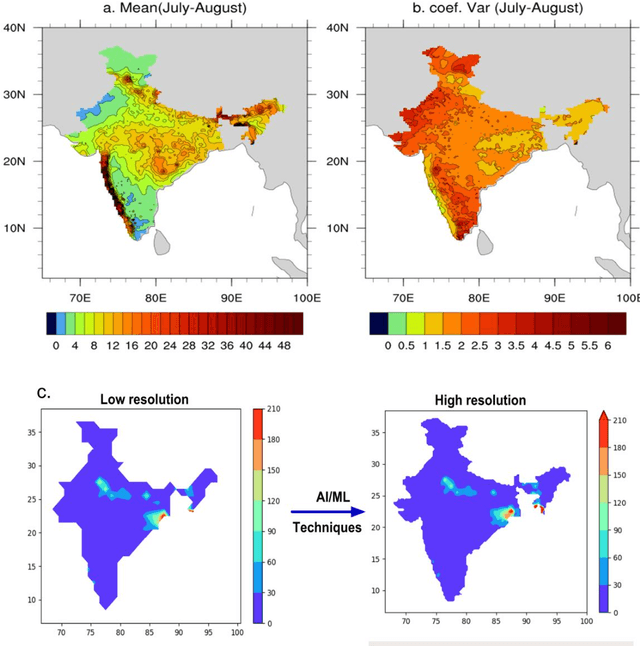
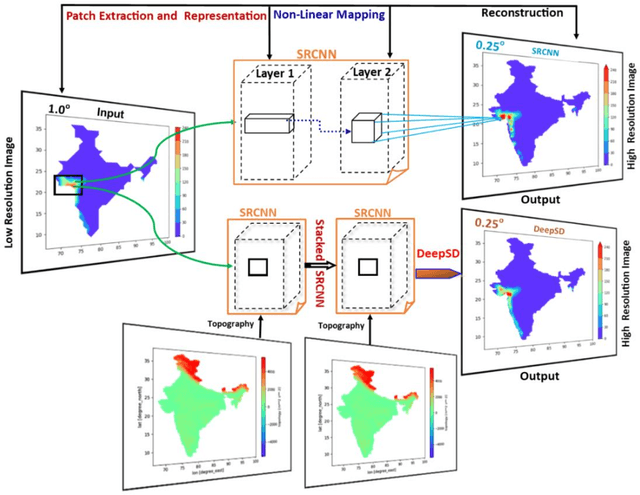
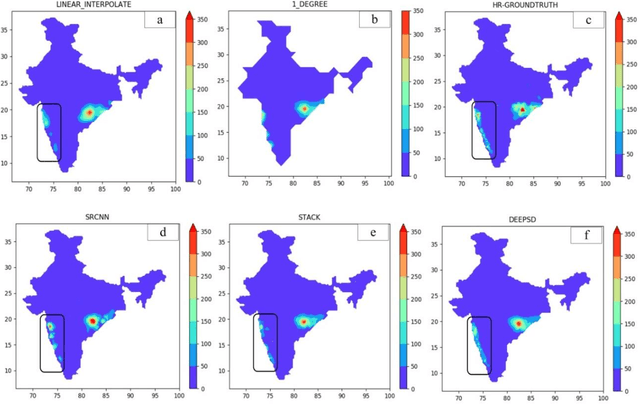
Downscaling is necessary to generate high-resolution observation data to validate the climate model forecast or monitor rainfall at the micro-regional level operationally. Dynamical and statistical downscaling models are often used to get information at high-resolution gridded data over larger domains. As rainfall variability is dependent on the complex Spatio-temporal process leading to non-linear or chaotic Spatio-temporal variations, no single downscaling method can be considered efficient enough. In data with complex topographies, quasi-periodicities, and non-linearities, deep Learning (DL) based methods provide an efficient solution in downscaling rainfall data for regional climate forecasting and real-time rainfall observation data at high spatial resolutions. In this work, we employed three deep learning-based algorithms derived from the super-resolution convolutional neural network (SRCNN) methods, to precipitation data, in particular, IMD and TRMM data to produce 4x-times high-resolution downscaled rainfall data during the summer monsoon season. Among the three algorithms, namely SRCNN, stacked SRCNN, and DeepSD, employed here, the best spatial distribution of rainfall amplitude and minimum root-mean-square error is produced by DeepSD based downscaling. Hence, the use of the DeepSD algorithm is advocated for future use. We found that spatial discontinuity in amplitude and intensity rainfall patterns is the main obstacle in the downscaling of precipitation. Furthermore, we applied these methods for model data postprocessing, in particular, ERA5 data. Downscaled ERA5 rainfall data show a much better distribution of spatial covariance and temporal variance when compared with observation.
Stochastic Modified Equations for Continuous Limit of Stochastic ADMM
Mar 07, 2020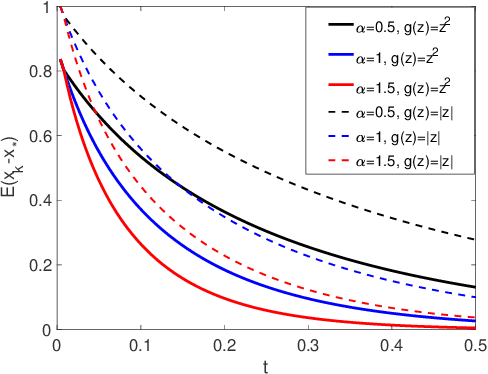
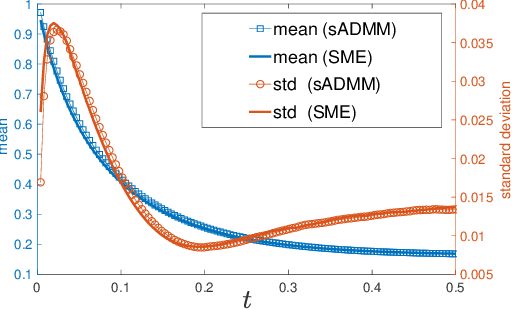
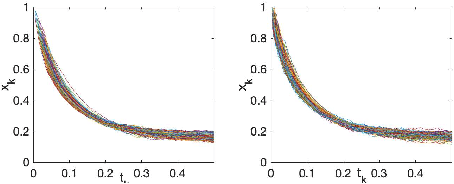
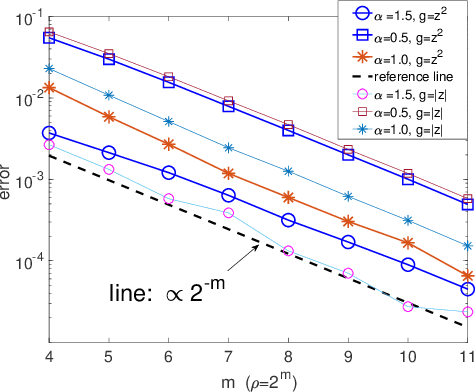
Stochastic version of alternating direction method of multiplier (ADMM) and its variants (linearized ADMM, gradient-based ADMM) plays a key role for modern large scale machine learning problems. One example is the regularized empirical risk minimization problem. In this work, we put different variants of stochastic ADMM into a unified form, which includes standard, linearized and gradient-based ADMM with relaxation, and study their dynamics via a continuous-time model approach. We adapt the mathematical framework of stochastic modified equation (SME), and show that the dynamics of stochastic ADMM is approximated by a class of stochastic differential equations with small noise parameters in the sense of weak approximation. The continuous-time analysis would uncover important analytical insights into the behaviors of the discrete-time algorithm, which are non-trivial to gain otherwise. For example, we could characterize the fluctuation of the solution paths precisely, and decide optimal stopping time to minimize the variance of solution paths.
GCNv2: Efficient Correspondence Prediction for Real-Time SLAM
Mar 23, 2019
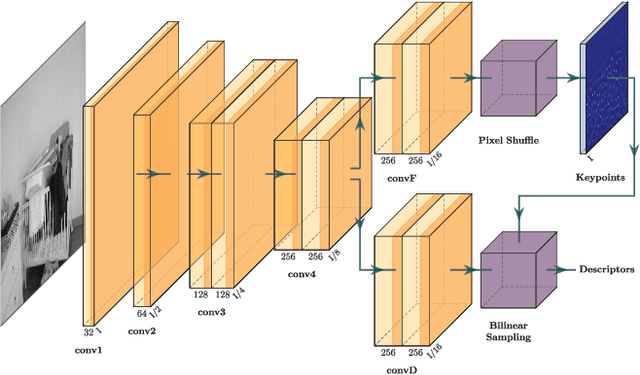
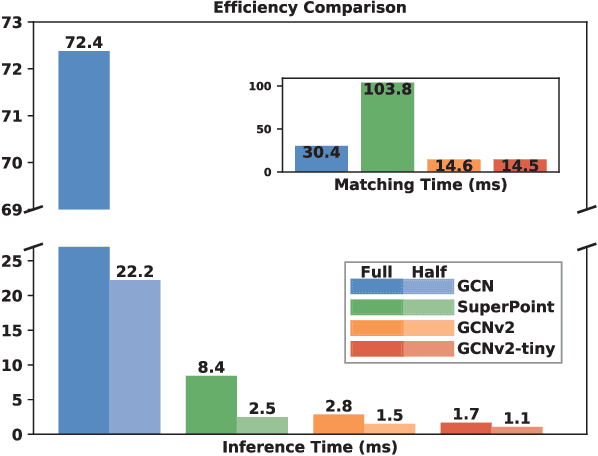
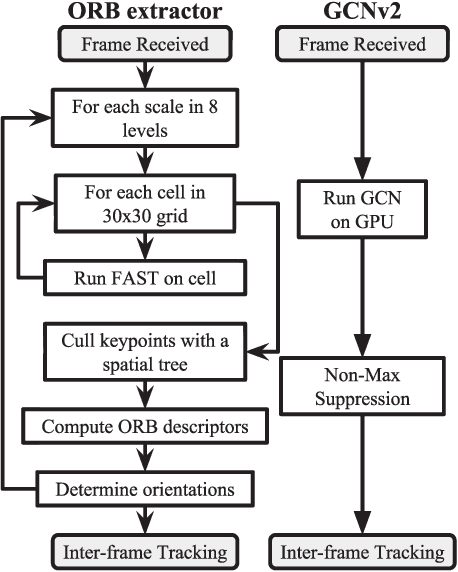
In this paper, we present a deep learning-based network, GCNv2, for generation of keypoints and descriptors. GCNv2 is built on our previous method, GCN, a network trained for 3D projective geometry. GCNv2 is designed with a binary descriptor vector as the ORB feature so that it can easily replace ORB in systems such as ORB-SLAM. GCNv2 significantly improves the computational efficiency over GCN that was only able to run on desktop hardware. We show how a modified version of ORB-SLAM using GCNv2 features runs on a Jetson TX2, an embdded low-power platform. Experimental results show that GCNv2 retains almost the same accuracy as GCN and that it is robust enough to use for control of a flying drone.