 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Multilinear Sampling Algorithm to Estimate Shapley Values
Oct 22, 2020
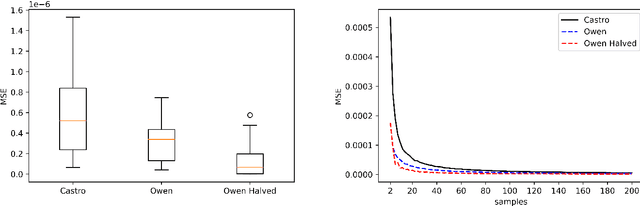
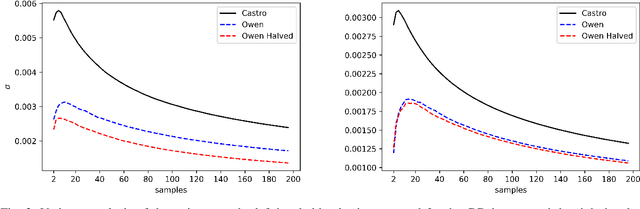
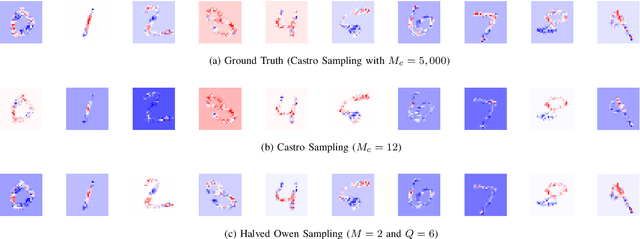
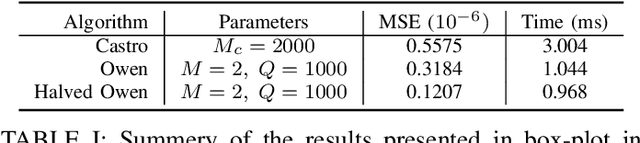
Shapley values are great analytical tools in game theory to measure the importance of a player in a game. Due to their axiomatic and desirable properties such as efficiency, they have become popular for feature importance analysis in data science and machine learning. However, the time complexity to compute Shapley values based on the original formula is exponential, and as the number of features increases, this becomes infeasible. Castro et al. [1] developed a sampling algorithm, to estimate Shapley values. In this work, we propose a new sampling method based on a multilinear extension technique as applied in game theory. The aim is to provide a more efficient (sampling) method for estimating Shapley values. Our method is applicable to any machine learning model, in particular for either multi-class classifications or regression problems. We apply the method to estimate Shapley values for multilayer perceptrons (MLPs) and through experimentation on two datasets, we demonstrate that our method provides more accurate estimations of the Shapley values by reducing the variance of the sampling statistics.
A Spectral Method for Activity Shaping in Continuous-Time Information Cascades
Sep 15, 2017
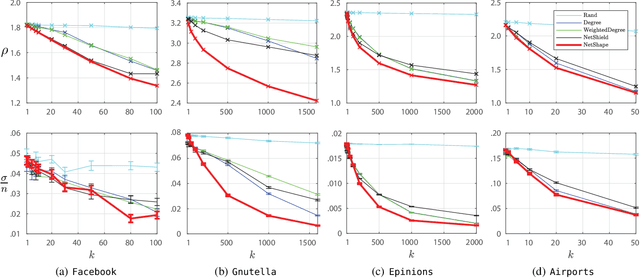
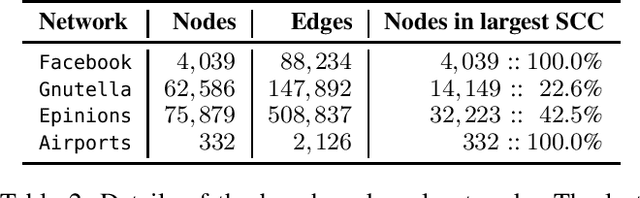
Information Cascades Model captures dynamical properties of user activity in a social network. In this work, we develop a novel framework for activity shaping under the Continuous-Time Information Cascades Model which allows the administrator for local control actions by allocating targeted resources that can alter the spread of the process. Our framework employs the optimization of the spectral radius of the Hazard matrix, a quantity that has been shown to drive the maximum influence in a network, while enjoying a simple convex relaxation when used to minimize the influence of the cascade. In addition, use-cases such as quarantine and node immunization are discussed to highlight the generality of the proposed activity shaping framework. Finally, we present the NetShape influence minimization method which is compared favorably to baseline and state-of-the-art approaches through simulations on real social networks.
Quantitative Propagation of Chaos for SGD in Wide Neural Networks
Jul 14, 2020In this paper, we investigate the limiting behavior of a continuous-time counterpart of the Stochastic Gradient Descent (SGD) algorithm applied to two-layer overparameterized neural networks, as the number or neurons (ie, the size of the hidden layer) $N \to +\infty$. Following a probabilistic approach, we show 'propagation of chaos' for the particle system defined by this continuous-time dynamics under different scenarios, indicating that the statistical interaction between the particles asymptotically vanishes. In particular, we establish quantitative convergence with respect to $N$ of any particle to a solution of a mean-field McKean-Vlasov equation in the metric space endowed with the Wasserstein distance. In comparison to previous works on the subject, we consider settings in which the sequence of stepsizes in SGD can potentially depend on the number of neurons and the iterations. We then identify two regimes under which different mean-field limits are obtained, one of them corresponding to an implicitly regularized version of the minimization problem at hand. We perform various experiments on real datasets to validate our theoretical results, assessing the existence of these two regimes on classification problems and illustrating our convergence results.
Proceedings of the AI-HRI Symposium at AAAI-FSS 2020
Nov 11, 2020The Artificial Intelligence (AI) for Human-Robot Interaction (HRI) Symposium has been a successful venue of discussion and collaboration since 2014. In that time, the related topic of trust in robotics has been rapidly growing, with major research efforts at universities and laboratories across the world. Indeed, many of the past participants in AI-HRI have been or are now involved with research into trust in HRI. While trust has no consensus definition, it is regularly associated with predictability, reliability, inciting confidence, and meeting expectations. Furthermore, it is generally believed that trust is crucial for adoption of both AI and robotics, particularly when transitioning technologies from the lab to industrial, social, and consumer applications. However, how does trust apply to the specific situations we encounter in the AI-HRI sphere? Is the notion of trust in AI the same as that in HRI? We see a growing need for research that lives directly at the intersection of AI and HRI that is serviced by this symposium. Over the course of the two-day meeting, we propose to create a collaborative forum for discussion of current efforts in trust for AI-HRI, with a sub-session focused on the related topic of explainable AI (XAI) for HRI.
Keep your Eyes on the Lane: Attention-guided Lane Detection
Oct 22, 2020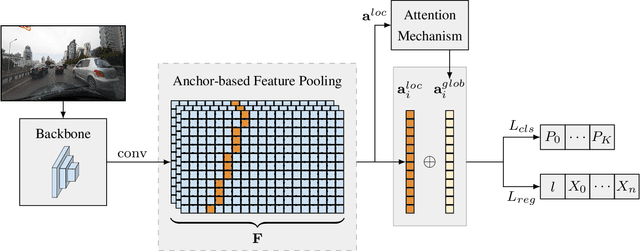
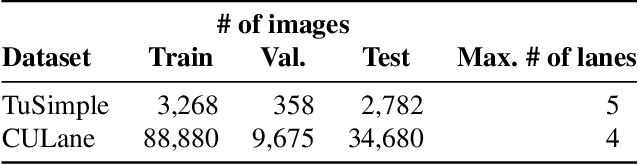
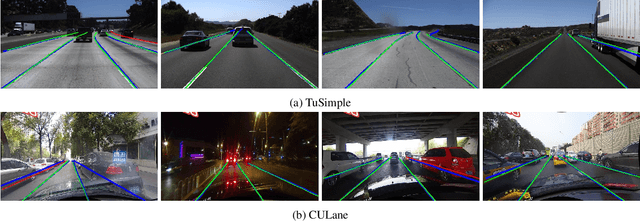
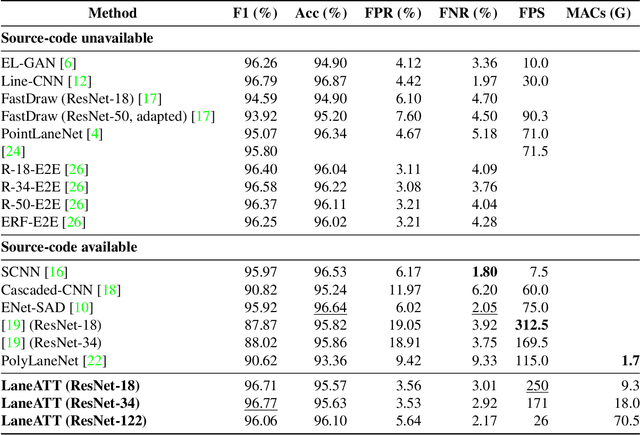
Modern lane detection methods have achieved remarkable performances in complex real-world scenarios, but many have issues maintaining real-time efficiency, which is important for autonomous vehicles. In this work, we propose LaneATT: an anchor-based deep lane detection model, which, akin to other generic deep object detectors, uses the anchors for the feature pooling step. Since lanes follow a regular pattern and are highly correlated, we hypothesize that in some cases global information may be crucial to infer their positions, especially in conditions such as occlusion, missing lane markers, and others. Thus, we propose a novel anchor-based attention mechanism that aggregates global information. The model was evaluated extensively on two of the most widely used datasets in the literature. The results show that our method outperforms the current state-of-the-art methods showing both a higher efficacy and efficiency. Moreover, we perform an ablation study and discuss efficiency trade-off options that are useful in practice. To reproduce our findings, source code and pretrained models are available at https://github.com/lucastabelini/LaneATT
Emformer: Efficient Memory Transformer Based Acoustic Model For Low Latency Streaming Speech Recognition
Oct 22, 2020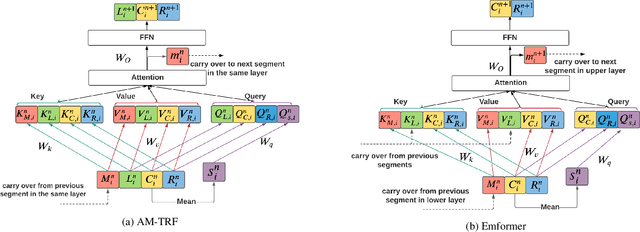
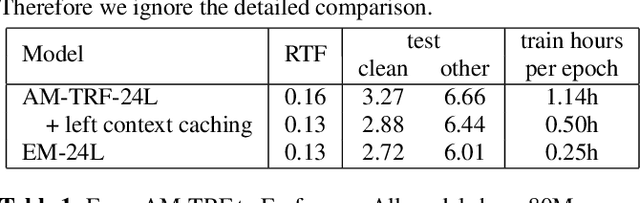
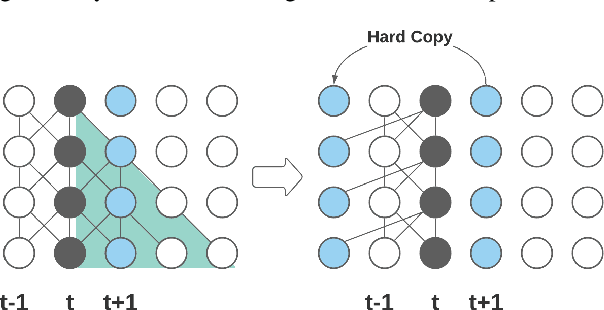
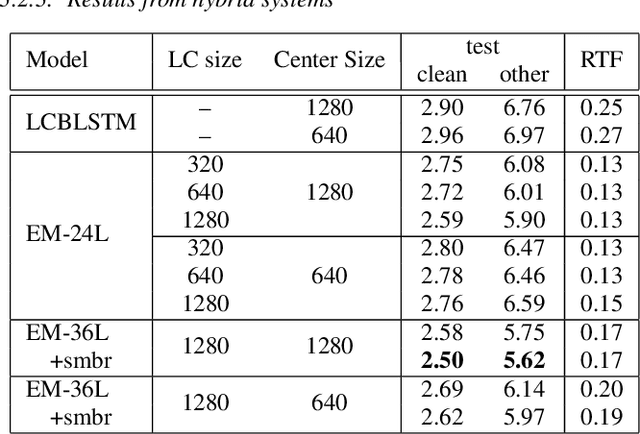
This paper proposes an efficient memory transformer Emformer for low latency streaming speech recognition. In Emformer, the long-range history context is distilled into an augmented memory bank to reduce self-attention's computation complexity. A cache mechanism saves the computation for the key and value in self-attention for the left context. Emformer applies a parallelized block processing in training to support low latency models. We carry out experiments on benchmark LibriSpeech data. Under average latency of 960 ms, Emformer gets WER $2.50\%$ on test-clean and $5.62\%$ on test-other. Comparing with a strong baseline augmented memory transformer (AM-TRF), Emformer gets $4.6$ folds training speedup and $18\%$ relative real-time factor (RTF) reduction in decoding with relative WER reduction $17\%$ on test-clean and $9\%$ on test-other. For a low latency scenario with an average latency of 80 ms, Emformer achieves WER $3.01\%$ on test-clean and $7.09\%$ on test-other. Comparing with the LSTM baseline with the same latency and model size, Emformer gets relative WER reduction $9\%$ and $16\%$ on test-clean and test-other, respectively.
Pairwise Learning for Name Disambiguation in Large-Scale Heterogeneous Academic Networks
Aug 30, 2020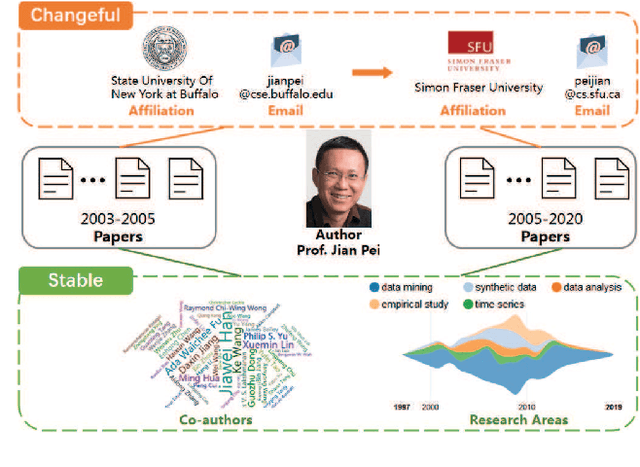
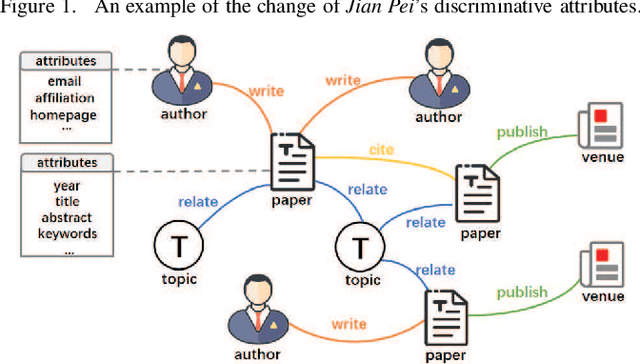
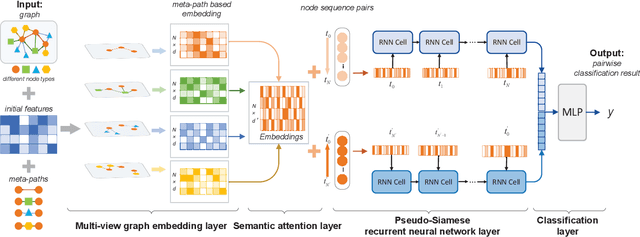
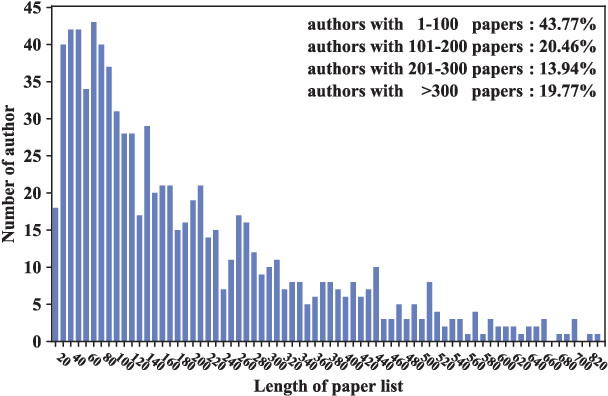
Name disambiguation aims to identify unique authors with the same name. Existing name disambiguation methods always exploit author attributes to enhance disambiguation results. However, some discriminative author attributes (e.g., email and affiliation) may change because of graduation or job-hopping, which will result in the separation of the same author's papers in digital libraries. Although these attributes may change, an author's co-authors and research topics do not change frequently with time, which means that papers within a period have similar text and relation information in the academic network. Inspired by this idea, we introduce Multi-view Attention-based Pairwise Recurrent Neural Network (\projtitle) to solve the name disambiguation problem. We divided papers into small blocks based on discriminative author attributes and blocks of the same author will be merged according to pairwise classification results of \projtitle. \projtitle combines heterogeneous graph embedding learning and pairwise similarity learning into a framework. In addition to attribute and structure information, \projtitle also exploits semantic information by meta-path and generates node representation in an inductive way, which is scalable to large graphs. Furthermore, a semantic-level attention mechanism is adopted to fuse multiple meta-path based representations. A Pseudo-Siamese network consisting of two RNNs takes two paper sequences in publication time order as input and outputs their similarity. Results on two real-world datasets demonstrate that our framework has a significant and consistent improvement of performance on the name disambiguation task. It was also demonstrated that \projtitle can perform well with a small amount of training data and have better generalization ability across different research areas.
MTGAT: Multimodal Temporal Graph Attention Networks for Unaligned Human Multimodal Language Sequences
Oct 22, 2020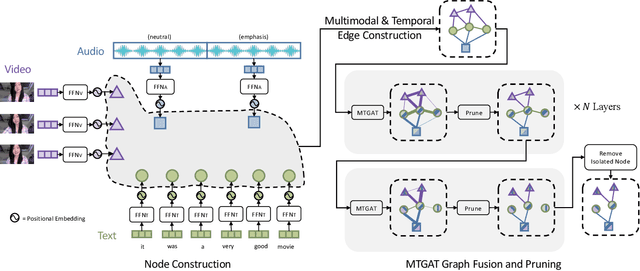
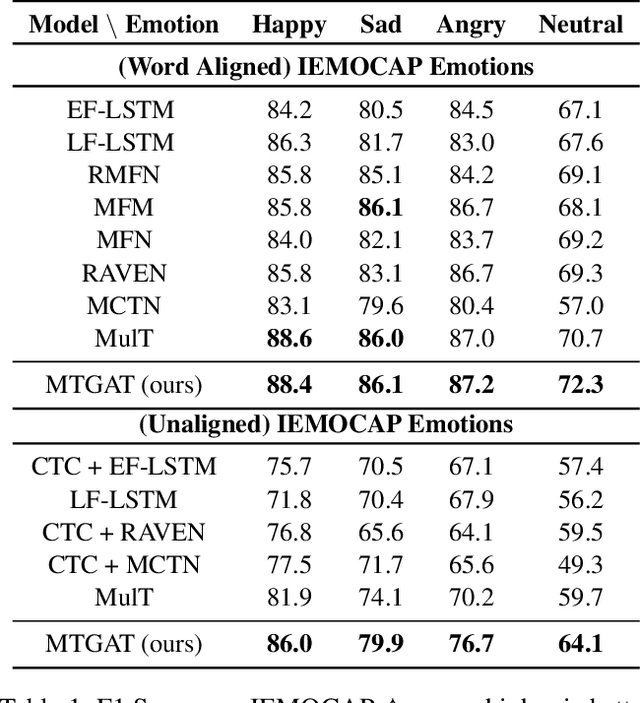
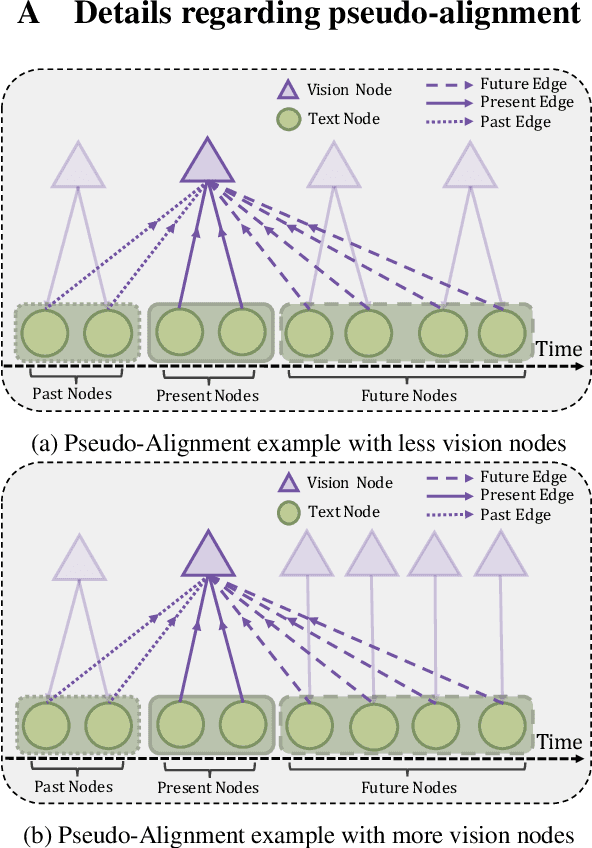
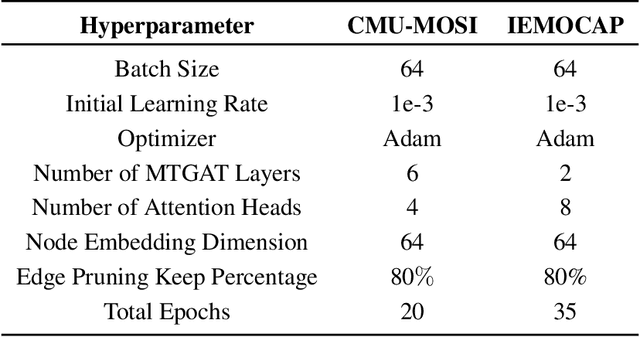
Human communication is multimodal in nature; it is through multiple modalities, i.e., language, voice, and facial expressions, that opinions and emotions are expressed. Data in this domain exhibits complex multi-relational and temporal interactions. Learning from this data is a fundamentally challenging research problem. In this paper, we propose Multimodal Temporal Graph Attention Networks (MTGAT). MTGAT is an interpretable graph-based neural model that provides a suitable framework for analyzing this type of multimodal sequential data. We first introduce a procedure to convert unaligned multimodal sequence data into a graph with heterogeneous nodes and edges that captures the rich interactions between different modalities through time. Then, a novel graph operation, called Multimodal Temporal Graph Attention, along with a dynamic pruning and read-out technique is designed to efficiently process this multimodal temporal graph. By learning to focus only on the important interactions within the graph, our MTGAT is able to achieve state-of-the-art performance on multimodal sentiment analysis and emotion recognition benchmarks including IEMOCAP and CMU-MOSI, while utilizing significantly fewer computations.
Autoregressive Modeling is Misspecified for Some Sequence Distributions
Oct 22, 2020
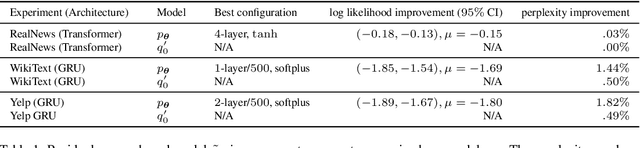
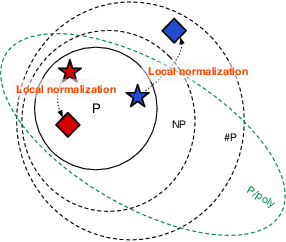
Should sequences be modeled autoregressively---one symbol at a time? How much computation is needed to predict the next symbol? While local normalization is cheap, this also limits its power. We point out that some probability distributions over discrete sequences cannot be well-approximated by any autoregressive model whose runtime and parameter size grow polynomially in the sequence length---even though their unnormalized sequence probabilities are efficient to compute exactly. Intuitively, the probability of the next symbol can be expensive to compute or approximate (even via randomized algorithms) when it marginalizes over exponentially many possible futures, which is in general $\mathrm{NP}$-hard. Our result is conditional on the widely believed hypothesis that $\mathrm{NP} \nsubseteq \mathrm{P/poly}$ (without which the polynomial hierarchy would collapse at the second level). This theoretical observation serves as a caution to the viewpoint that pumping up parameter size is a straightforward way to improve autoregressive models (e.g., in language modeling). It also suggests that globally normalized (energy-based) models may sometimes outperform locally normalized (autoregressive) models, as we demonstrate experimentally for language modeling.
Brain-Inspired Learning on Neuromorphic Substrates
Oct 22, 2020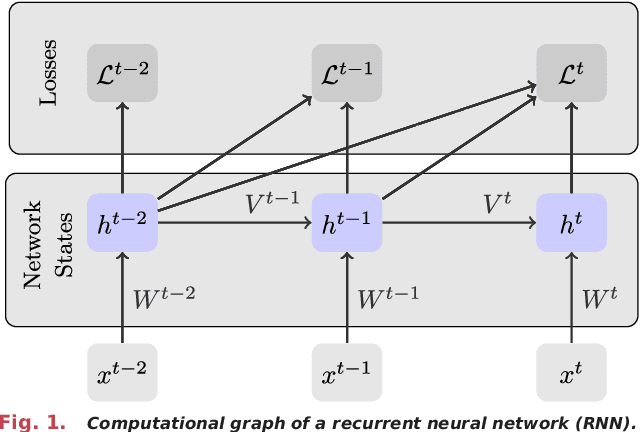
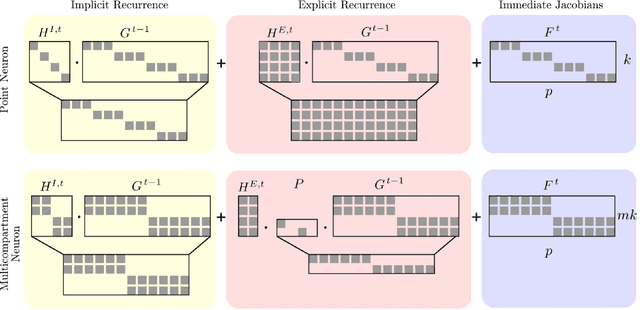
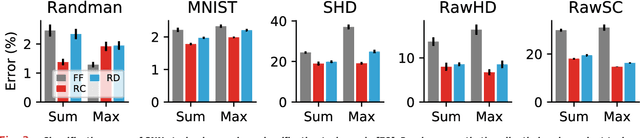
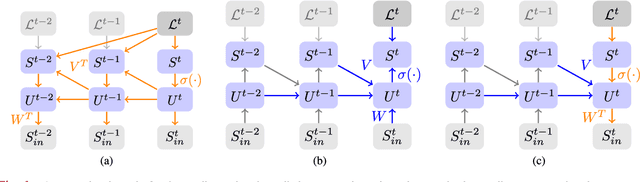
Neuromorphic hardware strives to emulate brain-like neural networks and thus holds the promise for scalable, low-power information processing on temporal data streams. Yet, to solve real-world problems, these networks need to be trained. However, training on neuromorphic substrates creates significant challenges due to the offline character and the required non-local computations of gradient-based learning algorithms. This article provides a mathematical framework for the design of practical online learning algorithms for neuromorphic substrates. Specifically, we show a direct connection between Real-Time Recurrent Learning (RTRL), an online algorithm for computing gradients in conventional Recurrent Neural Networks (RNNs), and biologically plausible learning rules for training Spiking Neural Networks (SNNs). Further, we motivate a sparse approximation based on block-diagonal Jacobians, which reduces the algorithm's computational complexity, diminishes the non-local information requirements, and empirically leads to good learning performance, thereby improving its applicability to neuromorphic substrates. In summary, our framework bridges the gap between synaptic plasticity and gradient-based approaches from deep learning and lays the foundations for powerful information processing on future neuromorphic hardware systems.