 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Compressive Shack-Hartmann Wavefront Sensing based on Deep Neural Networks
Nov 20, 2020
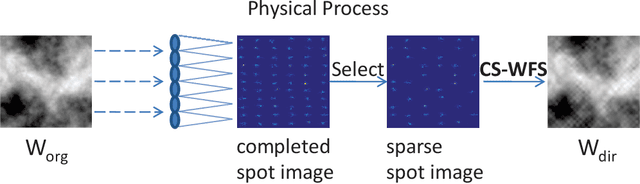

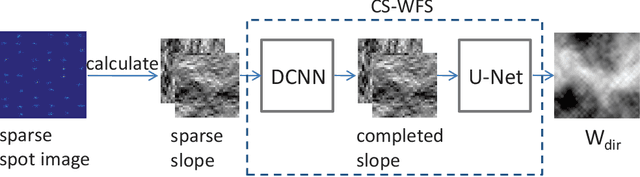
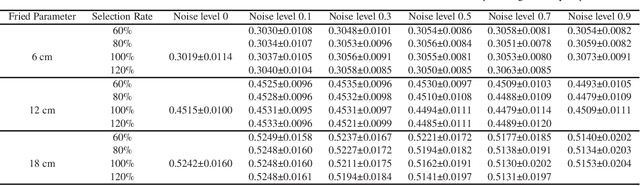
The Shack-Hartmann wavefront sensor is widely used to measure aberrations induced by atmospheric turbulence in adaptive optics systems. However if there exists strong atmospheric turbulence or the brightness of guide stars is low, the accuracy of wavefront measurements will be affected. In this paper, we propose a compressive Shack-Hartmann wavefront sensing method. Instead of reconstructing wavefronts with slope measurements of all sub-apertures, our method reconstructs wavefronts with slope measurements of sub-apertures which have spot images with high signal to noise ratio. Besides, we further propose to use a deep neural network to accelerate wavefront reconstruction speed. During the training stage of the deep neural network, we propose to add a drop-out layer to simulate the compressive sensing process, which could increase development speed of our method. After training, the compressive Shack-Hartmann wavefront sensing method can reconstruct wavefronts in high spatial resolution with slope measurements from only a small amount of sub-apertures. We integrate the straightforward compressive Shack-Hartmann wavefront sensing method with image deconvolution algorithm to develop a high-order image restoration method. We use images restored by the high-order image restoration method to test the performance of our the compressive Shack-Hartmann wavefront sensing method. The results show that our method can improve the accuracy of wavefront measurements and is suitable for real-time applications.
Sparse Quadratic Logistic Regression in Sub-quadratic Time
Mar 08, 2017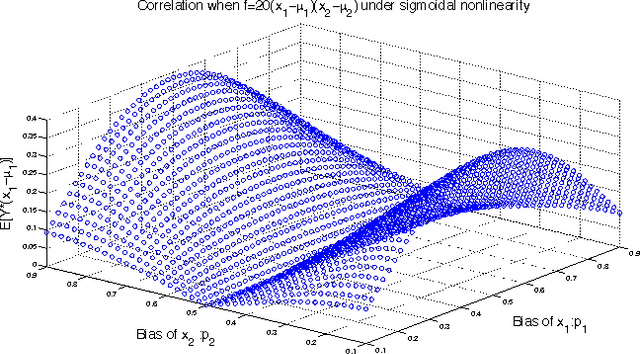

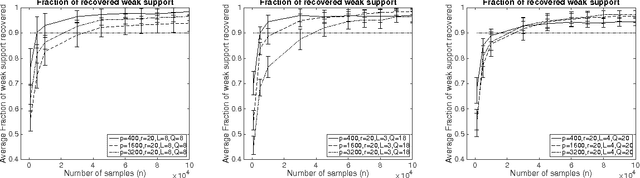

We consider support recovery in the quadratic logistic regression setting - where the target depends on both p linear terms $x_i$ and up to $p^2$ quadratic terms $x_i x_j$. Quadratic terms enable prediction/modeling of higher-order effects between features and the target, but when incorporated naively may involve solving a very large regression problem. We consider the sparse case, where at most $s$ terms (linear or quadratic) are non-zero, and provide a new faster algorithm. It involves (a) identifying the weak support (i.e. all relevant variables) and (b) standard logistic regression optimization only on these chosen variables. The first step relies on a novel insight about correlation tests in the presence of non-linearity, and takes $O(pn)$ time for $n$ samples - giving potentially huge computational gains over the naive approach. Motivated by insights from the boolean case, we propose a non-linear correlation test for non-binary finite support case that involves hashing a variable and then correlating with the output variable. We also provide experimental results to demonstrate the effectiveness of our methods.
Knowledge Graph Embedding with Atrous Convolution and Residual Learning
Oct 23, 2020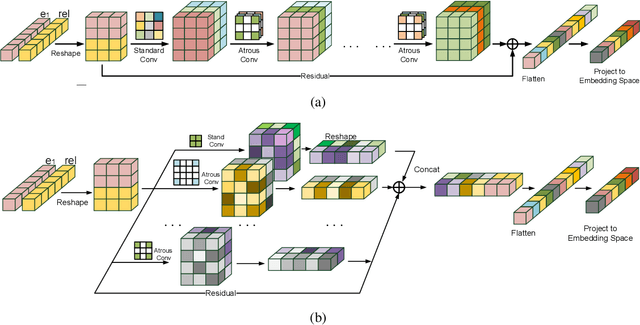
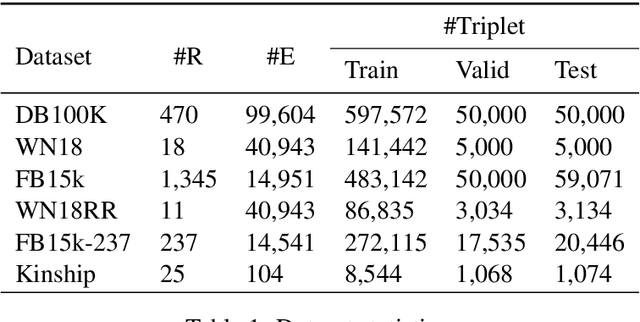
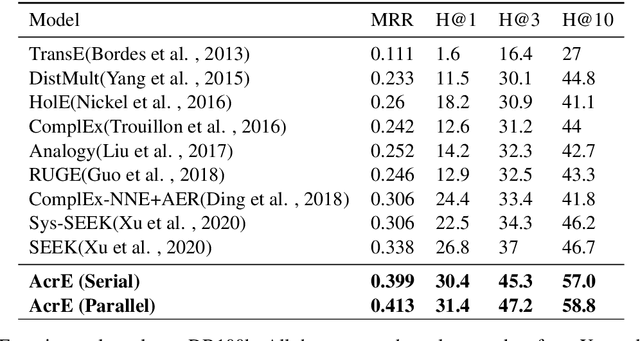
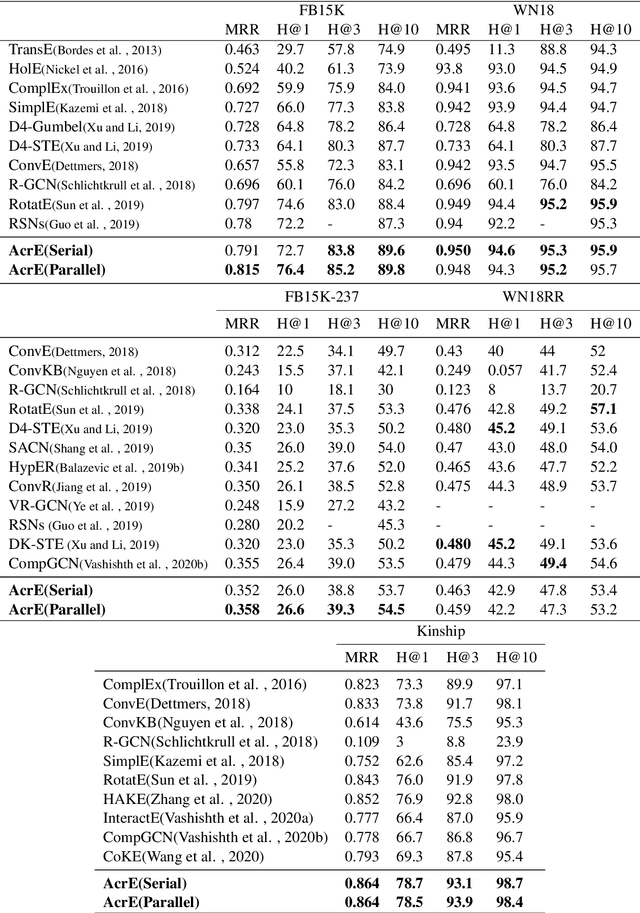
Knowledge graph embedding is an important task and it will benefit lots of downstream applications. Currently, deep neural networks based methods achieve state-of-the-art performance. However, most of these existing methods are very complex and need much time for training and inference. To address this issue, we propose a simple but effective atrous convolution based knowledge graph embedding method. Compared with existing state-of-the-art methods, our method has following main characteristics. First, it effectively increases feature interactions by using atrous convolutions. Second, to address the original information forgotten issue and vanishing/exploding gradient issue, it uses the residual learning method. Third, it has simpler structure but much higher parameter efficiency. We evaluate our method on six benchmark datasets with different evaluation metrics. Extensive experiments show that our model is very effective. On these diverse datasets, it achieves better results than the compared state-of-the-art methods on most of evaluation metrics. The source codes of our model could be found at https://github.com/neukg/AcrE.
A Low Complexity Decentralized Neural Net with Centralized Equivalence using Layer-wise Learning
Sep 29, 2020
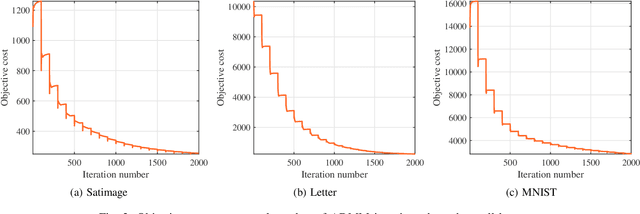
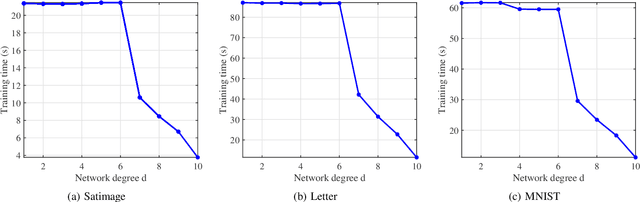
We design a low complexity decentralized learning algorithm to train a recently proposed large neural network in distributed processing nodes (workers). We assume the communication network between the workers is synchronized and can be modeled as a doubly-stochastic mixing matrix without having any master node. In our setup, the training data is distributed among the workers but is not shared in the training process due to privacy and security concerns. Using alternating-direction-method-of-multipliers (ADMM) along with a layerwise convex optimization approach, we propose a decentralized learning algorithm which enjoys low computational complexity and communication cost among the workers. We show that it is possible to achieve equivalent learning performance as if the data is available in a single place. Finally, we experimentally illustrate the time complexity and convergence behavior of the algorithm.
Human-in-the-Loop Methods for Data-Driven and Reinforcement Learning Systems
Aug 30, 2020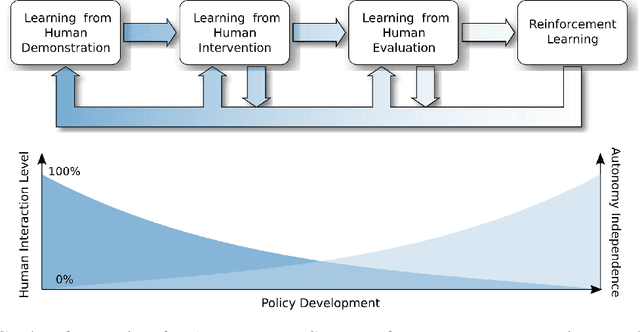

Recent successes combine reinforcement learning algorithms and deep neural networks, despite reinforcement learning not being widely applied to robotics and real world scenarios. This can be attributed to the fact that current state-of-the-art, end-to-end reinforcement learning approaches still require thousands or millions of data samples to converge to a satisfactory policy and are subject to catastrophic failures during training. Conversely, in real world scenarios and after just a few data samples, humans are able to either provide demonstrations of the task, intervene to prevent catastrophic actions, or simply evaluate if the policy is performing correctly. This research investigates how to integrate these human interaction modalities to the reinforcement learning loop, increasing sample efficiency and enabling real-time reinforcement learning in robotics and real world scenarios. This novel theoretical foundation is called Cycle-of-Learning, a reference to how different human interaction modalities, namely, task demonstration, intervention, and evaluation, are cycled and combined to reinforcement learning algorithms. Results presented in this work show that the reward signal that is learned based upon human interaction accelerates the rate of learning of reinforcement learning algorithms and that learning from a combination of human demonstrations and interventions is faster and more sample efficient when compared to traditional supervised learning algorithms. Finally, Cycle-of-Learning develops an effective transition between policies learned using human demonstrations and interventions to reinforcement learning. The theoretical foundation developed by this research opens new research paths to human-agent teaming scenarios where autonomous agents are able to learn from human teammates and adapt to mission performance metrics in real-time and in real world scenarios.
Proceedings of the AI-HRI Symposium at AAAI-FSS 2020
Nov 11, 2020The Artificial Intelligence (AI) for Human-Robot Interaction (HRI) Symposium has been a successful venue of discussion and collaboration since 2014. In that time, the related topic of trust in robotics has been rapidly growing, with major research efforts at universities and laboratories across the world. Indeed, many of the past participants in AI-HRI have been or are now involved with research into trust in HRI. While trust has no consensus definition, it is regularly associated with predictability, reliability, inciting confidence, and meeting expectations. Furthermore, it is generally believed that trust is crucial for adoption of both AI and robotics, particularly when transitioning technologies from the lab to industrial, social, and consumer applications. However, how does trust apply to the specific situations we encounter in the AI-HRI sphere? Is the notion of trust in AI the same as that in HRI? We see a growing need for research that lives directly at the intersection of AI and HRI that is serviced by this symposium. Over the course of the two-day meeting, we propose to create a collaborative forum for discussion of current efforts in trust for AI-HRI, with a sub-session focused on the related topic of explainable AI (XAI) for HRI.
Deep Voice: Real-time Neural Text-to-Speech
Mar 07, 2017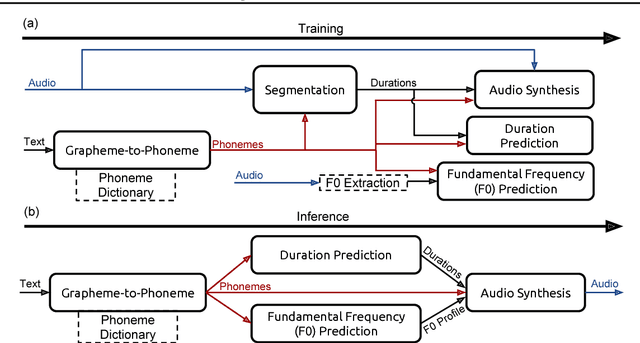
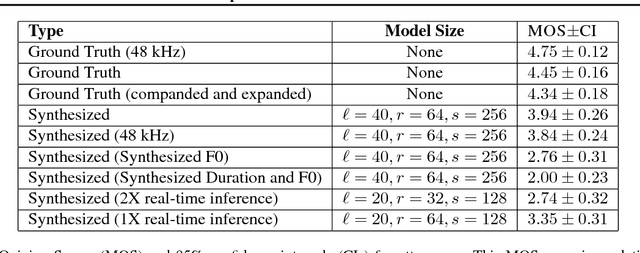
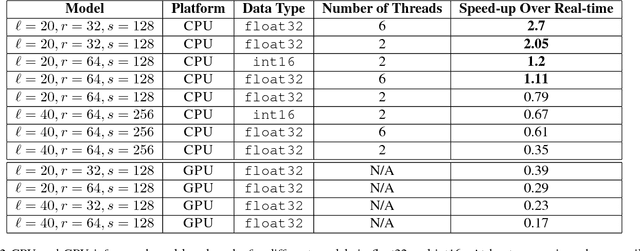
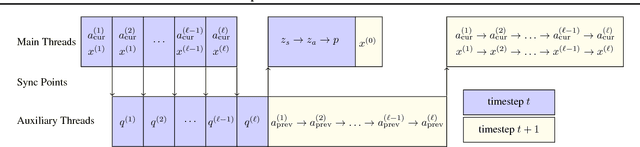
We present Deep Voice, a production-quality text-to-speech system constructed entirely from deep neural networks. Deep Voice lays the groundwork for truly end-to-end neural speech synthesis. The system comprises five major building blocks: a segmentation model for locating phoneme boundaries, a grapheme-to-phoneme conversion model, a phoneme duration prediction model, a fundamental frequency prediction model, and an audio synthesis model. For the segmentation model, we propose a novel way of performing phoneme boundary detection with deep neural networks using connectionist temporal classification (CTC) loss. For the audio synthesis model, we implement a variant of WaveNet that requires fewer parameters and trains faster than the original. By using a neural network for each component, our system is simpler and more flexible than traditional text-to-speech systems, where each component requires laborious feature engineering and extensive domain expertise. Finally, we show that inference with our system can be performed faster than real time and describe optimized WaveNet inference kernels on both CPU and GPU that achieve up to 400x speedups over existing implementations.
Human-Robot Team Coordination with Dynamic and Latent Human Task Proficiencies: Scheduling with Learning Curves
Jul 03, 2020
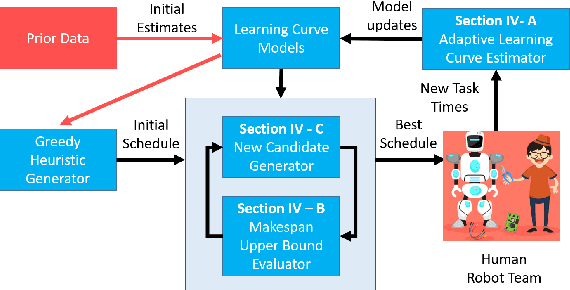
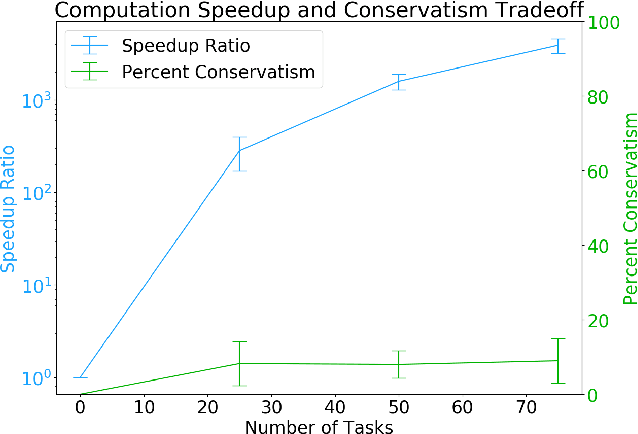
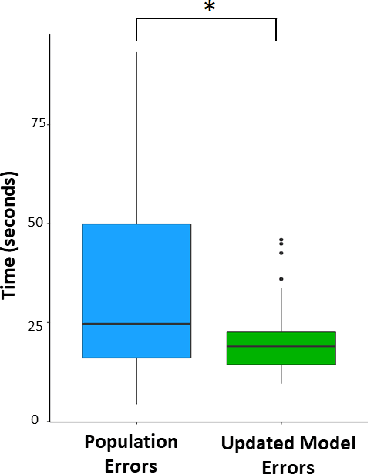
As robots become ubiquitous in the workforce, it is essential that human-robot collaboration be both intuitive and adaptive. A robot's quality improves based on its ability to explicitly reason about the time-varying (i.e. learning curves) and stochastic capabilities of its human counterparts, and adjust the joint workload to improve efficiency while factoring human preferences. We introduce a novel resource coordination algorithm that enables robots to explore the relative strengths and learning abilities of their human teammates, by constructing schedules that are robust to stochastic and time-varying human task performance. We first validate our algorithmic approach using data we collected from a user study (n = 20), showing we can quickly generate and evaluate a robust schedule while discovering the latest individual worker proficiency. Second, we conduct a between-subjects experiment (n = 90) to validate the efficacy of our coordinating algorithm. Results from the human-subjects experiment indicate that scheduling strategies favoring exploration tend to be beneficial for human-robot collaboration as it improves team fluency (p = 0.0438), while also maximizing team efficiency (p < 0.001).
MIRA: Leveraging Multi-Intention Co-click Information in Web-scale Document Retrieval using Deep Neural Networks
Jul 03, 2020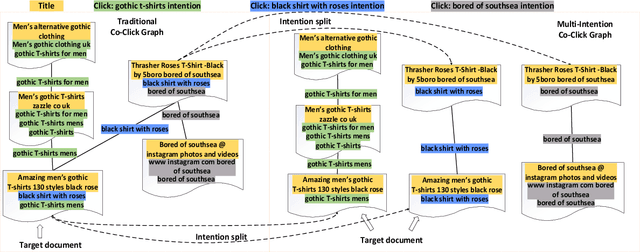
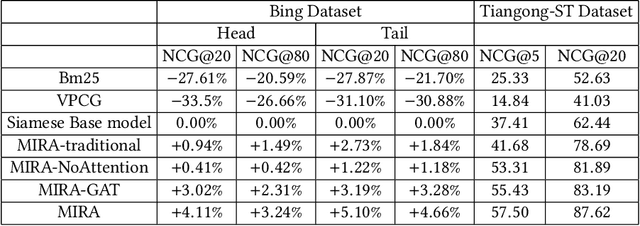
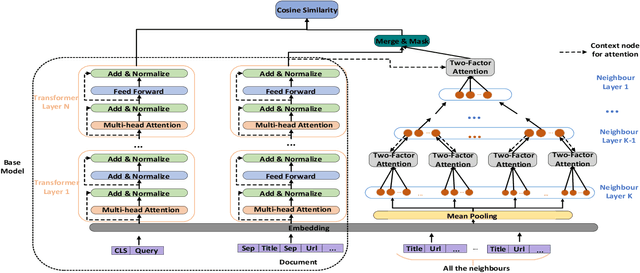
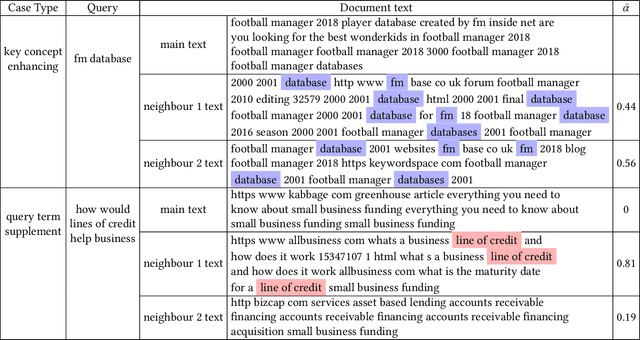
We study the problem of deep recall model in industrial web search, which is, given a user query, retrieve hundreds of most relevance documents from billions of candidates. The common framework is to train two encoding models based on neural embedding which learn the distributed representations of queries and documents separately and match them in the latent semantic space. However, all the exiting encoding models only leverage the information of the document itself, which is often not sufficient in practice when matching with query terms, especially for the hard tail queries. In this work we aim to leverage the additional information for each document from its co-click neighbour to help document retrieval. The challenges include how to effectively extract information and eliminate noise when involving co-click information in deep model while meet the demands of billion-scale data size for real time online inference. To handle the noise in co-click relations, we firstly propose a web-scale Multi-Intention Co-click document Graph(MICG) which builds the co-click connections between documents on click intention level but not on document level. Then we present an encoding framework MIRA based on Bert and graph attention networks which leverages a two-factor attention mechanism to aggregate neighbours. To meet the online latency requirements, we only involve neighbour information in document side, which can save the time-consuming query neighbor search in real time serving. We conduct extensive offline experiments on both public dataset and private web-scale dataset from two major commercial search engines demonstrating the effectiveness and scalability of the proposed method compared with several baselines. And a further case study reveals that co-click relations mainly help improve web search quality from two aspects: key concept enhancing and query term complementary.
A Comparative Study of Deep Learning Loss Functions for Multi-Label Remote Sensing Image Classification
Sep 29, 2020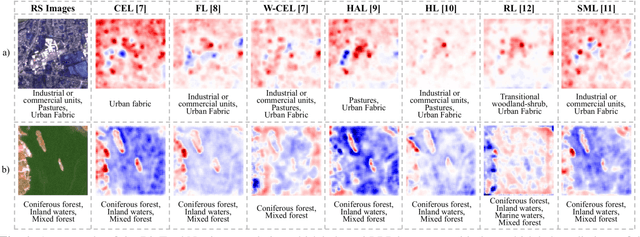
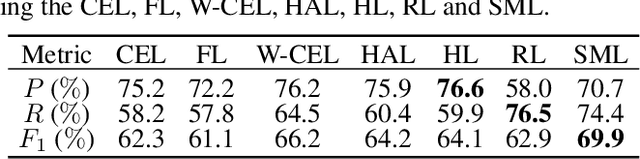
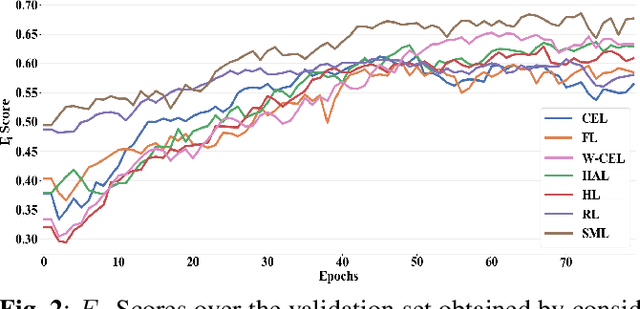
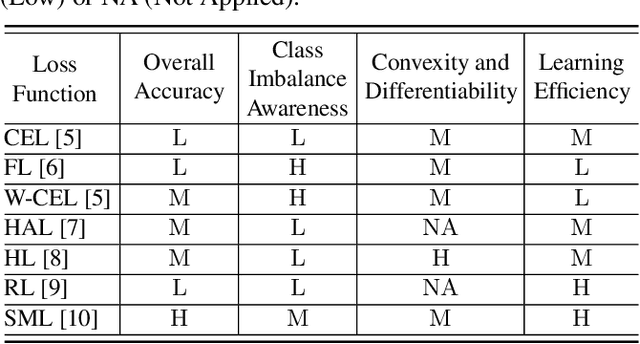
This paper analyzes and compares different deep learning loss functions in the framework of multi-label remote sensing (RS) image scene classification problems. We consider seven loss functions: 1) cross-entropy loss; 2) focal loss; 3) weighted cross-entropy loss; 4) Hamming loss; 5) Huber loss; 6) ranking loss; and 7) sparseMax loss. All the considered loss functions are analyzed for the first time in RS. After a theoretical analysis, an experimental analysis is carried out to compare the considered loss functions in terms of their: 1) overall accuracy; 2) class imbalance awareness (for which the number of samples associated to each class significantly varies); 3) convexibility and differentiability; and 4) learning efficiency (i.e., convergence speed). On the basis of our analysis, some guidelines are derived for a proper selection of a loss function in multi-label RS scene classification problems.