 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Nonconvex Regularized Robust Regression with Oracle Properties in Polynomial Time
Jul 09, 2019
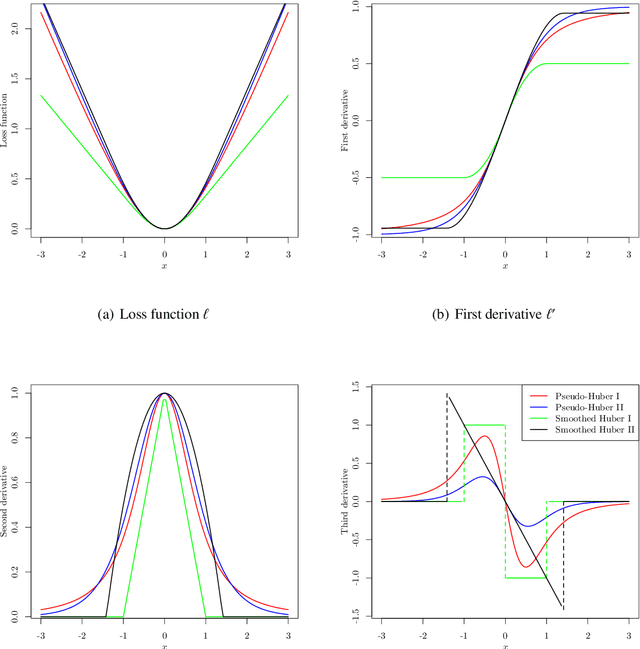
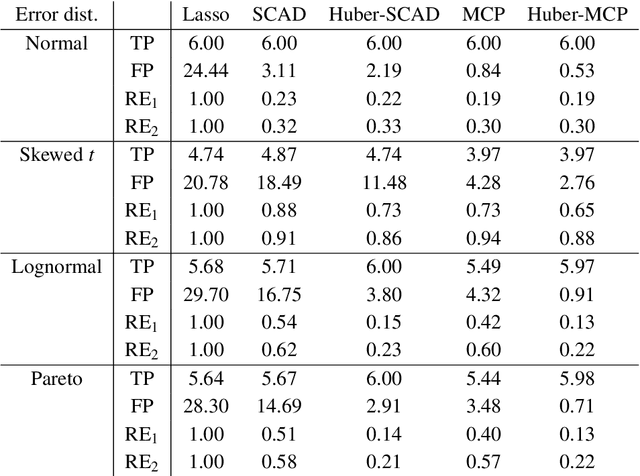
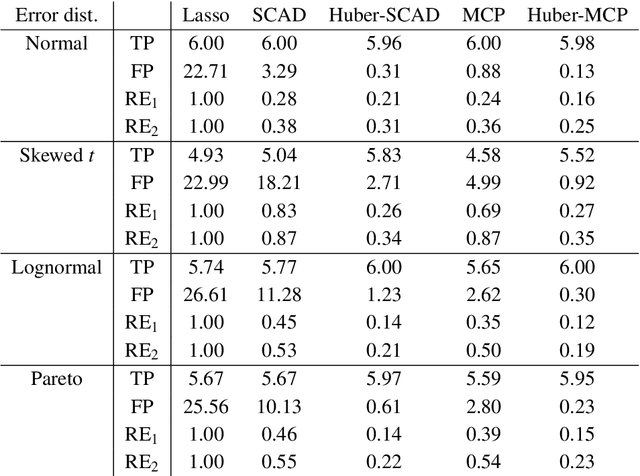
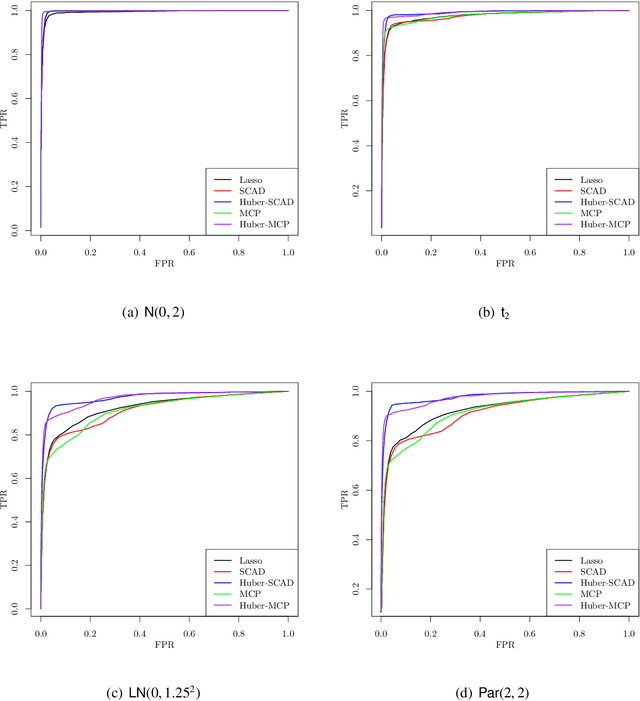
This paper investigates tradeoffs among optimization errors, statistical rates of convergence and the effect of heavy-tailed random errors for high-dimensional adaptive Huber regression with nonconvex regularization. When the additive errors in linear models have only bounded second moment, our results suggest that adaptive Huber regression with nonconvex regularization yields statistically optimal estimators that satisfy oracle properties as if the true underlying support set were known beforehand. Computationally, we need as many as O(log s + log log d) convex relaxations to reach such oracle estimators, where s and d denote the sparsity and ambient dimension, respectively. Numerical studies lend strong support to our methodology and theory.
Learning in the Wild with Incremental Skeptical Gaussian Processes
Nov 02, 2020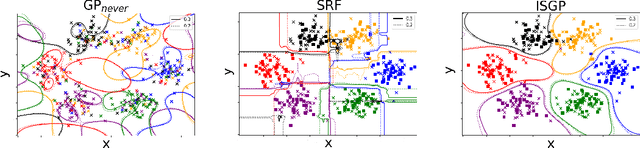
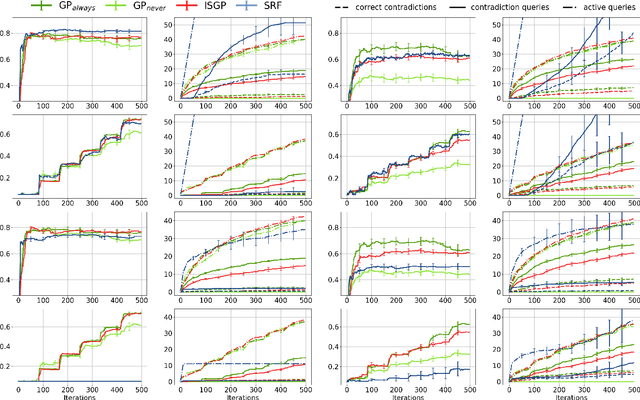

The ability to learn from human supervision is fundamental for personal assistants and other interactive applications of AI. Two central challenges for deploying interactive learners in the wild are the unreliable nature of the supervision and the varying complexity of the prediction task. We address a simple but representative setting, incremental classification in the wild, where the supervision is noisy and the number of classes grows over time. In order to tackle this task, we propose a redesign of skeptical learning centered around Gaussian Processes (GPs). Skeptical learning is a recent interactive strategy in which, if the machine is sufficiently confident that an example is mislabeled, it asks the annotator to reconsider her feedback. In many cases, this is often enough to obtain clean supervision. Our redesign, dubbed ISGP, leverages the uncertainty estimates supplied by GPs to better allocate labeling and contradiction queries, especially in the presence of noise. Our experiments on synthetic and real-world data show that, as a result, while the original formulation of skeptical learning produces over-confident models that can fail completely in the wild, ISGP works well at varying levels of noise and as new classes are observed.
* 7 pages, 3 figures, code: https://gitlab.com/abonte/incremental-skeptical-gp
A Ranking-based, Balanced Loss Function Unifying Classification and Localisation in Object Detection
Oct 23, 2020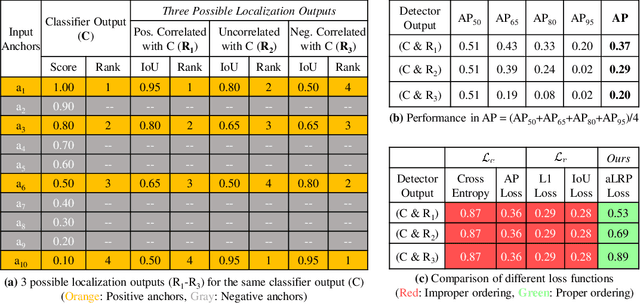

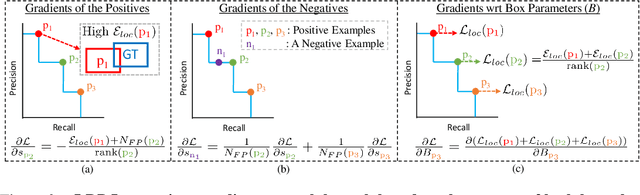

We propose \textit{average Localisation-Recall-Precision} (aLRP), a unified, bounded, balanced and ranking-based loss function for both classification and localisation tasks in object detection. aLRP extends the Localisation-Recall-Precision (LRP) performance metric (Oksuz et al., 2018) inspired from how Average Precision (AP) Loss extends precision to a ranking-based loss function for classification (Chen et al., 2020). aLRP has the following distinct advantages: (i) aLRP is the first ranking-based loss function for both classification and localisation tasks. (ii) Thanks to using ranking for both tasks, aLRP naturally enforces high-quality localisation for high-precision classification. (iii) aLRP provides provable balance between positives and negatives. (iv) Compared to on average $\sim$6 hyperparameters in the loss functions of state-of-the-art detectors, aLRP Loss has only one hyperparameter, which we did not tune in practice. On the COCO dataset, aLRP Loss improves its ranking-based predecessor, AP Loss, up to around $5$ AP points, achieves $48.9$ AP without test time augmentation and outperforms all one-stage detectors. Code available at: https://github.com/kemaloksuz/aLRPLoss .
Do Not Mask What You Do Not Need to Mask: a Parser-Free Virtual Try-On
Jul 03, 2020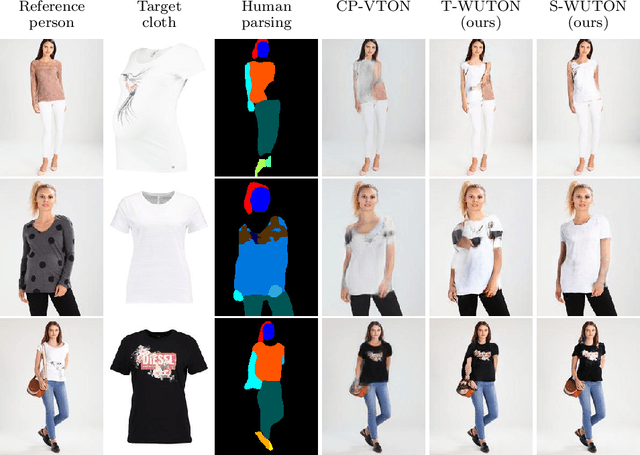
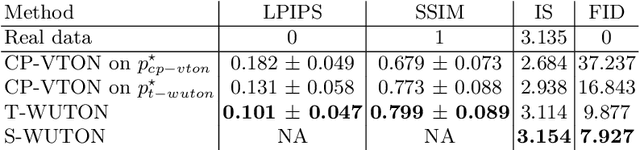
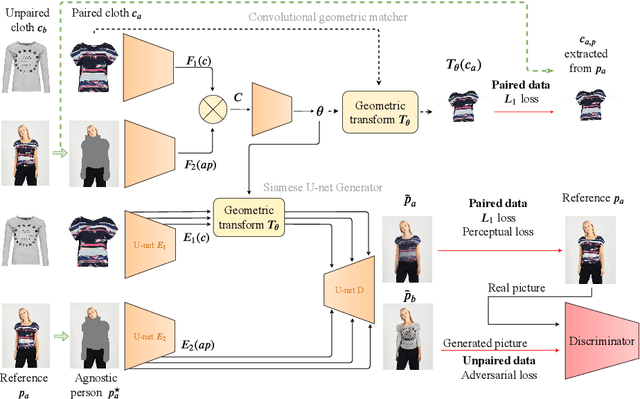

The 2D virtual try-on task has recently attracted a great interest from the research community, for its direct potential applications in online shopping as well as for its inherent and non-addressed scientific challenges. This task requires fitting an in-shop cloth image on the image of a person, which is highly challenging because it involves cloth warping, image compositing, and synthesizing. Casting virtual try-on into a supervised task faces a difficulty: available datasets are composed of pairs of pictures (cloth, person wearing the cloth). Thus, we have no access to ground-truth when the cloth on the person changes. State-of-the-art models solve this by masking the cloth information on the person with both a human parser and a pose estimator. Then, image synthesis modules are trained to reconstruct the person image from the masked person image and the cloth image. This procedure has several caveats: firstly, human parsers are prone to errors; secondly, it is a costly pre-processing step, which also has to be applied at inference time; finally, it makes the task harder than it is since the mask covers information that should be kept such as hands or accessories. In this paper, we propose a novel student-teacher paradigm where the teacher is trained in the standard way (reconstruction) before guiding the student to focus on the initial task (changing the cloth). The student additionally learns from an adversarial loss, which pushes it to follow the distribution of the real images. Consequently, the student exploits information that is masked to the teacher. A student trained without the adversarial loss would not use this information. Also, getting rid of both human parser and pose estimator at inference time allows obtaining a real-time virtual try-on.
Providing Actionable Feedback in Hiring Marketplaces using Generative Adversarial Networks
Oct 06, 2020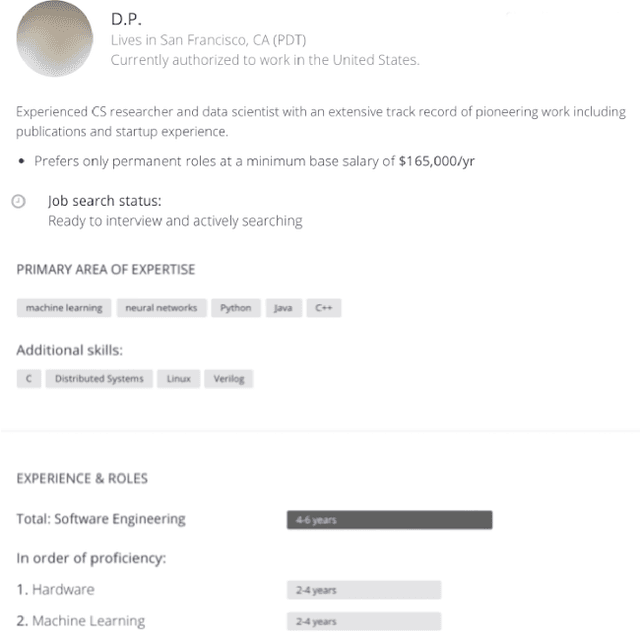

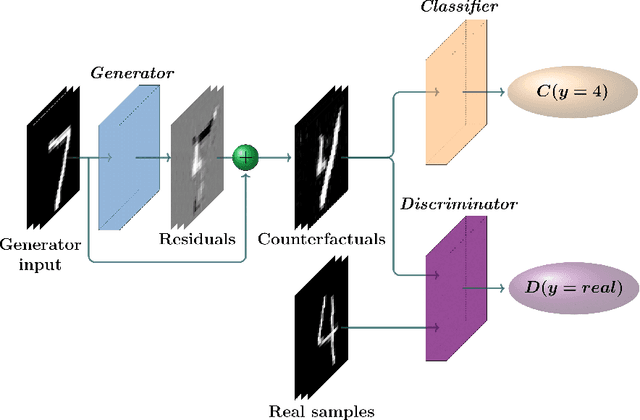
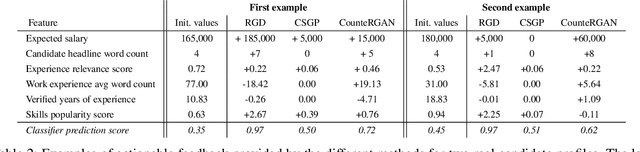
Machine learning predictors have been increasingly applied in production settings, including in one of the world's largest hiring platforms, Hired, to provide a better candidate and recruiter experience. The ability to provide actionable feedback is desirable for candidates to improve their chances of achieving success in the marketplace. Until recently, however, methods aimed at providing actionable feedback have been limited in terms of realism and latency. In this work, we demonstrate how, by applying a newly introduced method based on Generative Adversarial Networks (GANs), we are able to overcome these limitations and provide actionable feedback in real-time to candidates in production settings. Our experimental results highlight the significant benefits of utilizing a GAN-based approach on our dataset relative to two other state-of-the-art approaches (including over 1000x latency gains). We also illustrate the potential impact of this approach in detail on two real candidate profile examples.
Compressive Shack-Hartmann Wavefront Sensing based on Deep Neural Networks
Nov 20, 2020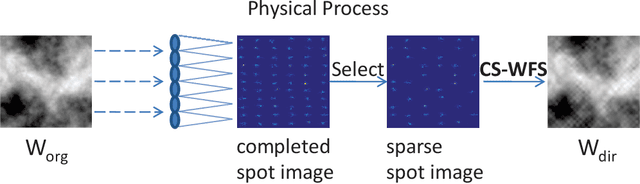

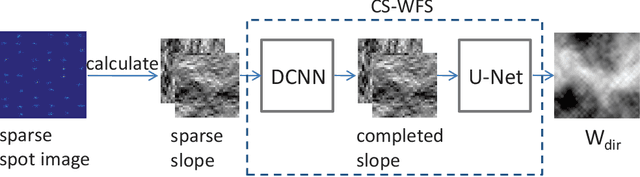
The Shack-Hartmann wavefront sensor is widely used to measure aberrations induced by atmospheric turbulence in adaptive optics systems. However if there exists strong atmospheric turbulence or the brightness of guide stars is low, the accuracy of wavefront measurements will be affected. In this paper, we propose a compressive Shack-Hartmann wavefront sensing method. Instead of reconstructing wavefronts with slope measurements of all sub-apertures, our method reconstructs wavefronts with slope measurements of sub-apertures which have spot images with high signal to noise ratio. Besides, we further propose to use a deep neural network to accelerate wavefront reconstruction speed. During the training stage of the deep neural network, we propose to add a drop-out layer to simulate the compressive sensing process, which could increase development speed of our method. After training, the compressive Shack-Hartmann wavefront sensing method can reconstruct wavefronts in high spatial resolution with slope measurements from only a small amount of sub-apertures. We integrate the straightforward compressive Shack-Hartmann wavefront sensing method with image deconvolution algorithm to develop a high-order image restoration method. We use images restored by the high-order image restoration method to test the performance of our the compressive Shack-Hartmann wavefront sensing method. The results show that our method can improve the accuracy of wavefront measurements and is suitable for real-time applications.
Predicting the Future Behavior of a Time-Varying Probability Distribution
Nov 20, 2014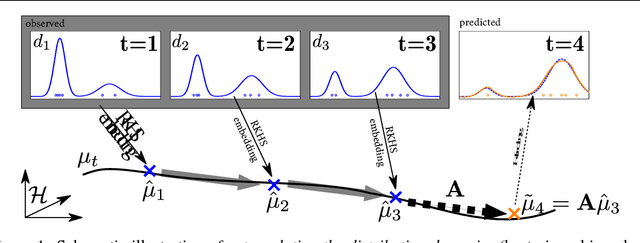


We study the problem of predicting the future, though only in the probabilistic sense of estimating a future state of a time-varying probability distribution. This is not only an interesting academic problem, but solving this extrapolation problem also has many practical application, e.g. for training classifiers that have to operate under time-varying conditions. Our main contribution is a method for predicting the next step of the time-varying distribution from a given sequence of sample sets from earlier time steps. For this we rely on two recent machine learning techniques: embedding probability distributions into a reproducing kernel Hilbert space, and learning operators by vector-valued regression. We illustrate the working principles and the practical usefulness of our method by experiments on synthetic and real data. We also highlight an exemplary application: training a classifier in a domain adaptation setting without having access to examples from the test time distribution at training time.
Proceedings of the AI-HRI Symposium at AAAI-FSS 2020
Nov 11, 2020The Artificial Intelligence (AI) for Human-Robot Interaction (HRI) Symposium has been a successful venue of discussion and collaboration since 2014. In that time, the related topic of trust in robotics has been rapidly growing, with major research efforts at universities and laboratories across the world. Indeed, many of the past participants in AI-HRI have been or are now involved with research into trust in HRI. While trust has no consensus definition, it is regularly associated with predictability, reliability, inciting confidence, and meeting expectations. Furthermore, it is generally believed that trust is crucial for adoption of both AI and robotics, particularly when transitioning technologies from the lab to industrial, social, and consumer applications. However, how does trust apply to the specific situations we encounter in the AI-HRI sphere? Is the notion of trust in AI the same as that in HRI? We see a growing need for research that lives directly at the intersection of AI and HRI that is serviced by this symposium. Over the course of the two-day meeting, we propose to create a collaborative forum for discussion of current efforts in trust for AI-HRI, with a sub-session focused on the related topic of explainable AI (XAI) for HRI.
Knowledge Graph Embedding with Atrous Convolution and Residual Learning
Oct 23, 2020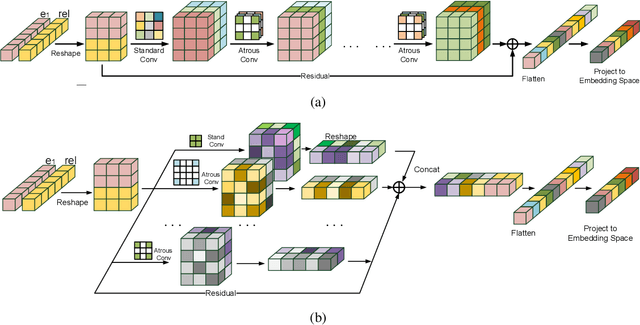
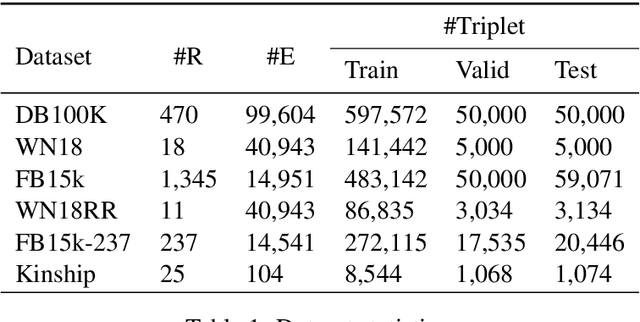
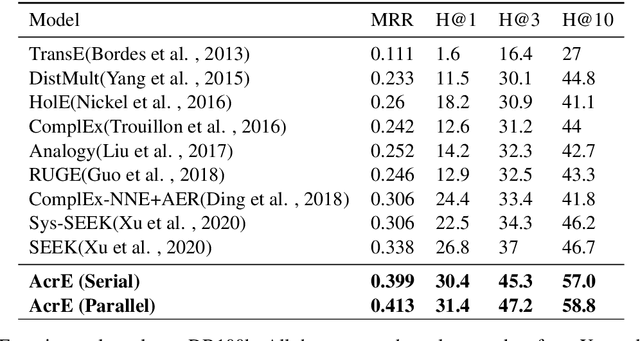
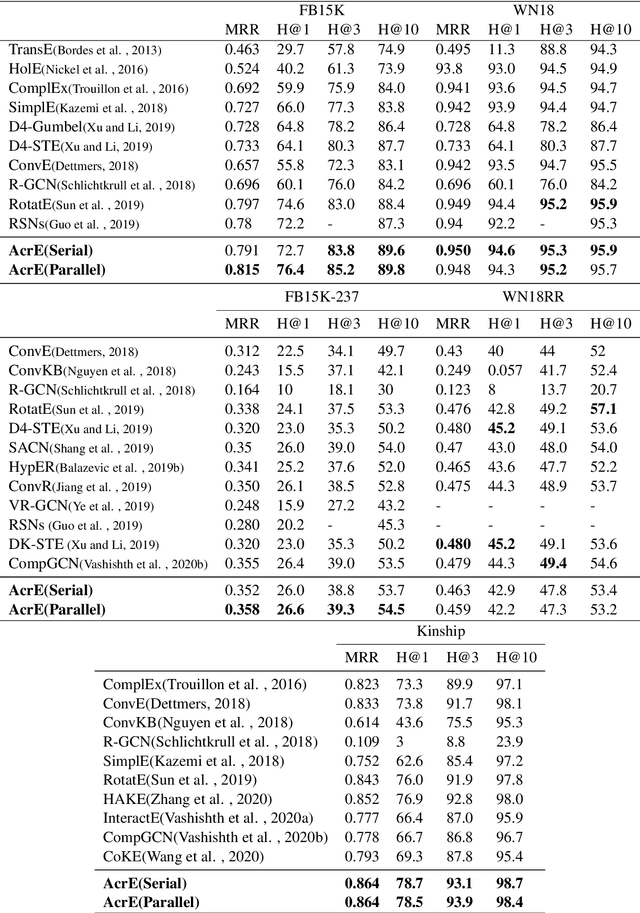
Knowledge graph embedding is an important task and it will benefit lots of downstream applications. Currently, deep neural networks based methods achieve state-of-the-art performance. However, most of these existing methods are very complex and need much time for training and inference. To address this issue, we propose a simple but effective atrous convolution based knowledge graph embedding method. Compared with existing state-of-the-art methods, our method has following main characteristics. First, it effectively increases feature interactions by using atrous convolutions. Second, to address the original information forgotten issue and vanishing/exploding gradient issue, it uses the residual learning method. Third, it has simpler structure but much higher parameter efficiency. We evaluate our method on six benchmark datasets with different evaluation metrics. Extensive experiments show that our model is very effective. On these diverse datasets, it achieves better results than the compared state-of-the-art methods on most of evaluation metrics. The source codes of our model could be found at https://github.com/neukg/AcrE.
COT-GAN: Generating Sequential Data via Causal Optimal Transport
Jun 15, 2020
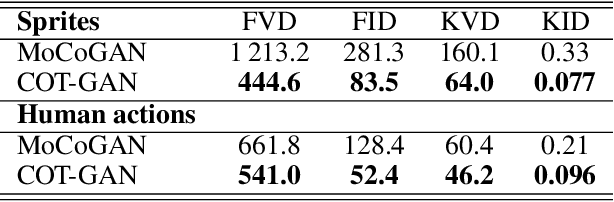
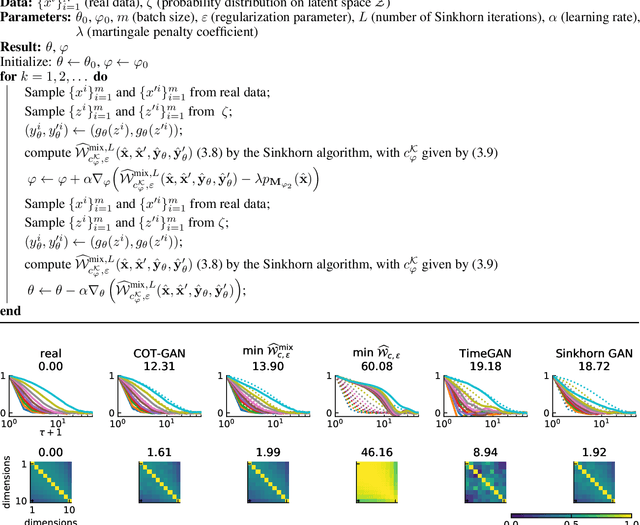
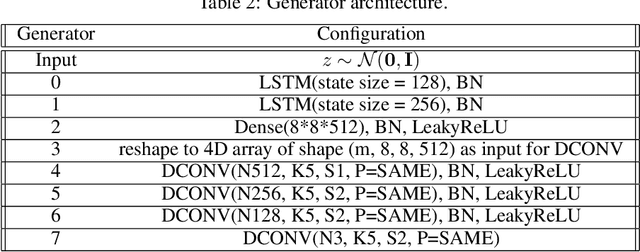
We introduce COT-GAN, an adversarial algorithm to train implicit generative models optimized for producing sequential data. The loss function of this algorithm is formulated using ideas from Causal Optimal Transport (COT), which combines classic optimal transport methods with an additional temporal causality constraint. Remarkably, we find that this causality condition provides a natural framework to parameterize the cost function that is learned by the discriminator as a robust (worst-case) distance, and an ideal mechanism for learning time dependent data distributions. Following Genevay et al.\ (2018), we also include an entropic penalization term which allows for the use of the Sinkhorn algorithm when computing the optimal transport cost. Our experiments show effectiveness and stability of COT-GAN when generating both low- and high-dimensional time series data. The success of the algorithm also relies on a new, improved version of the Sinkhorn divergence which demonstrates less bias in learning.