 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time Series Classification using the Hidden-Unit Logistic Model
Jan 19, 2016
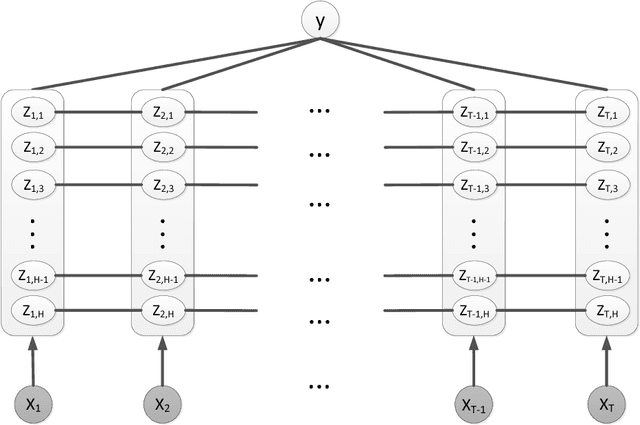
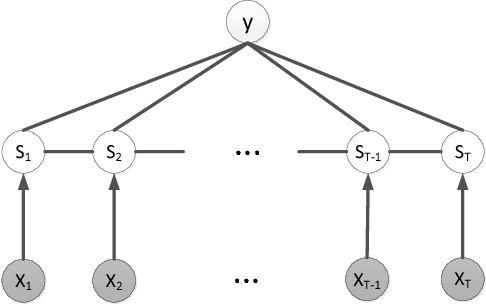
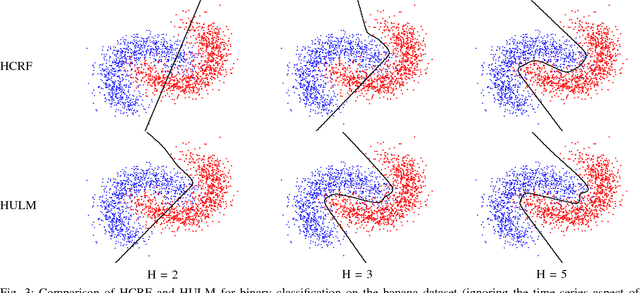
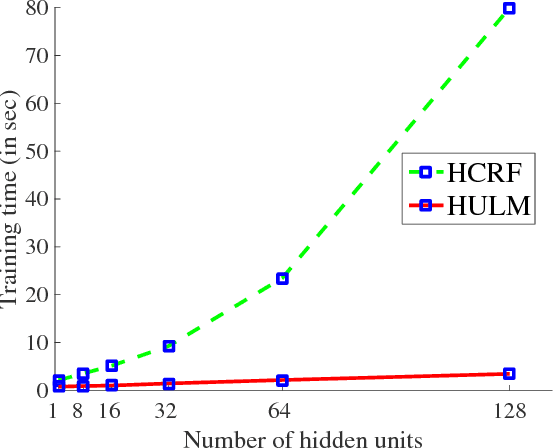
We present a new model for time series classification, called the hidden-unit logistic model, that uses binary stochastic hidden units to model latent structure in the data. The hidden units are connected in a chain structure that models temporal dependencies in the data. Compared to the prior models for time series classification such as the hidden conditional random field, our model can model very complex decision boundaries because the number of latent states grows exponentially with the number of hidden units. We demonstrate the strong performance of our model in experiments on a variety of (computer vision) tasks, including handwritten character recognition, speech recognition, facial expression, and action recognition. We also present a state-of-the-art system for facial action unit detection based on the hidden-unit logistic model.
Model-Based Reinforcement Learning for Type 1Diabetes Blood Glucose Control
Oct 13, 2020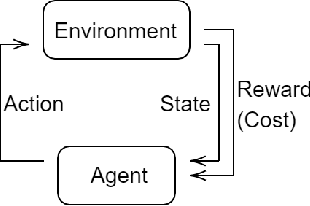
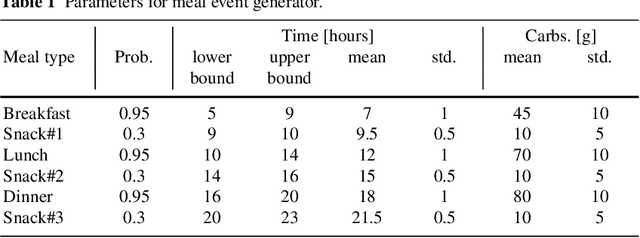
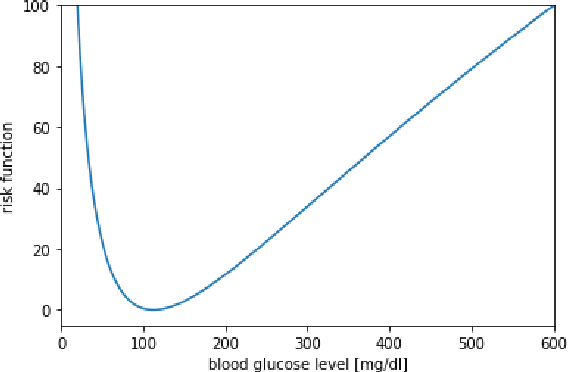
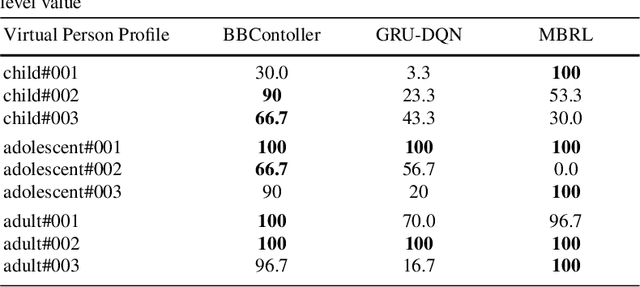
In this paper we investigate the use of model-based reinforcement learning to assist people with Type 1 Diabetes with insulin dose decisions. The proposed architecture consists of multiple Echo State Networks to predict blood glucose levels combined with Model Predictive Controller for planning. Echo State Network is a version of recurrent neural networks which allows us to learn long term dependencies in the input of time series data in an online manner. Additionally, we address the quantification of uncertainty for a more robust control. Here, we used ensembles of Echo State Networks to capture model (epistemic) uncertainty. We evaluated the approach with the FDA-approved UVa/Padova Type 1 Diabetes simulator and compared the results against baseline algorithms such as Basal-Bolus controller and Deep Q-learning. The results suggest that the model-based reinforcement learning algorithm can perform equally or better than the baseline algorithms for the majority of virtual Type 1 Diabetes person profiles tested.
Latent Compass: Creation by Navigation
Dec 20, 2020In Marius von Senden's Space and Sight, a newly sighted blind patient describes the experience of a corner as lemon-like, because corners "prick" sight like lemons prick the tongue. Prickliness, here, is a dimension in the feature space of sensory experience, an effect of the perceived on the perceiver that arises where the two interact. In the account of the newly sighted, an effect familiar from one interaction translates to a novel context. Perception serves as the vehicle for generalization, in that an effect shared across different experiences produces a concrete abstraction grounded in those experiences. Cezanne and the post-impressionists, fluent in the language of experience translation, realized that the way to paint a concrete form that best reflected reality was to paint not what they saw, but what it was like to see. We envision a future of creation using AI where what it is like to see is replicable, transferrable, manipulable - part of the artist's palette that is both grounded in a particular context, and generalizable beyond it. An active line of research maps human-interpretable features onto directions in GAN latent space. Supervised and self-supervised approaches that search for anticipated directions or use off-the-shelf classifiers to drive image manipulation in embedding space are limited in the variety of features they can uncover. Unsupervised approaches that discover useful new directions show that the space of perceptually meaningful directions is nowhere close to being fully mapped. As this space is broad and full of creative potential, we want tools for direction discovery that capture the richness and generalizability of human perception. Our approach puts creators in the discovery loop during real-time tool use, in order to identify directions that are perceptually meaningful to them, and generate interpretable image translations along those directions.
Evorus: A Crowd-powered Conversational Assistant Built to Automate Itself Over Time
Jan 10, 2018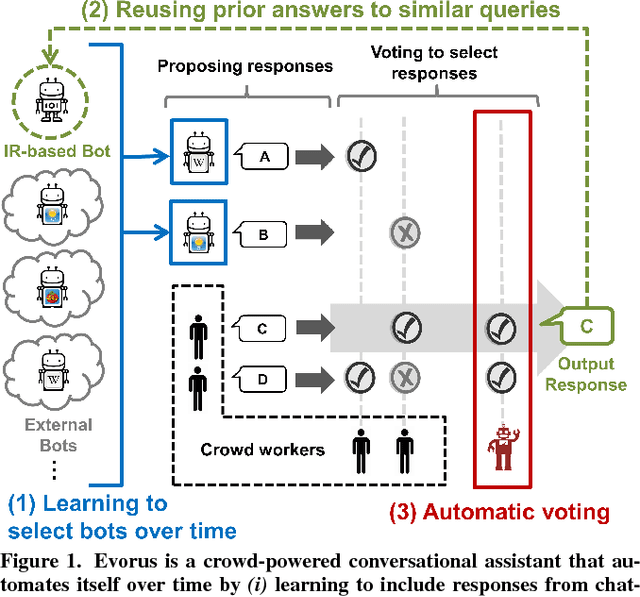
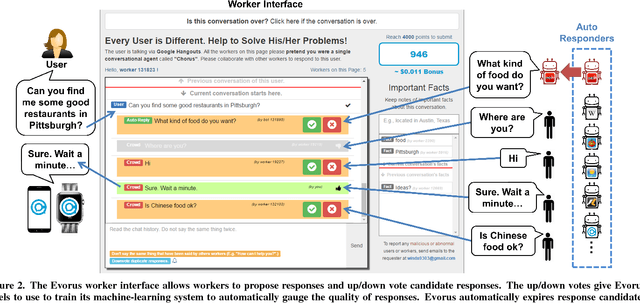
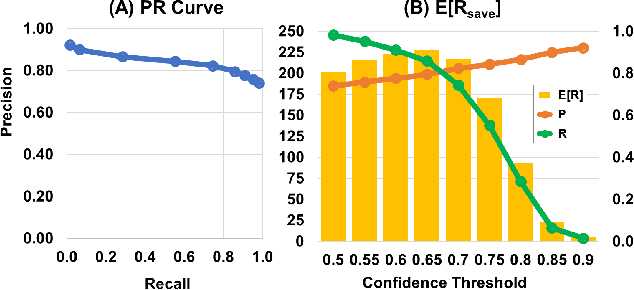
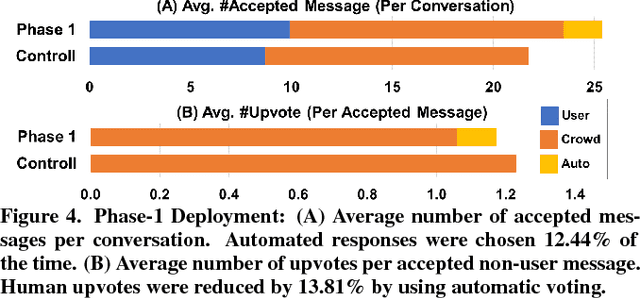
Crowd-powered conversational assistants have been shown to be more robust than automated systems, but do so at the cost of higher response latency and monetary costs. A promising direction is to combine the two approaches for high quality, low latency, and low cost solutions. In this paper, we introduce Evorus, a crowd-powered conversational assistant built to automate itself over time by (i) allowing new chatbots to be easily integrated to automate more scenarios, (ii) reusing prior crowd answers, and (iii) learning to automatically approve response candidates. Our 5-month-long deployment with 80 participants and 281 conversations shows that Evorus can automate itself without compromising conversation quality. Crowd-AI architectures have long been proposed as a way to reduce cost and latency for crowd-powered systems; Evorus demonstrates how automation can be introduced successfully in a deployed system. Its architecture allows future researchers to make further innovation on the underlying automated components in the context of a deployed open domain dialog system.
Enabling certification of verification-agnostic networks via memory-efficient semidefinite programming
Nov 03, 2020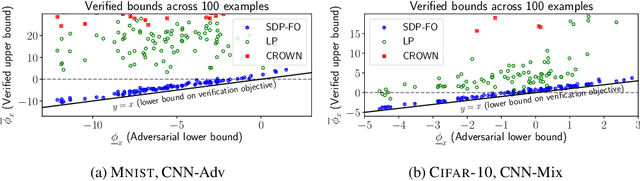
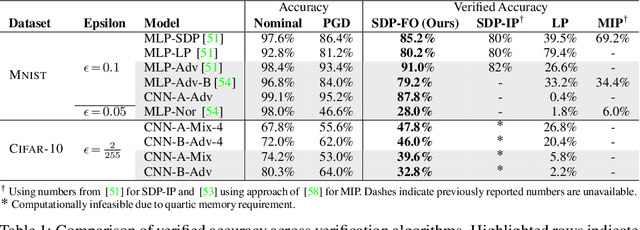
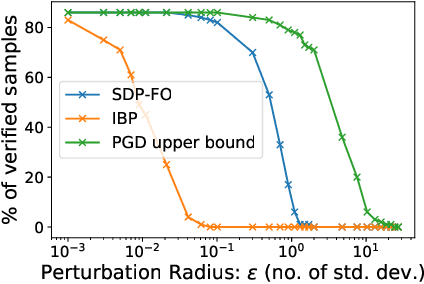

Convex relaxations have emerged as a promising approach for verifying desirable properties of neural networks like robustness to adversarial perturbations. Widely used Linear Programming (LP) relaxations only work well when networks are trained to facilitate verification. This precludes applications that involve verification-agnostic networks, i.e., networks not specially trained for verification. On the other hand, semidefinite programming (SDP) relaxations have successfully be applied to verification-agnostic networks, but do not currently scale beyond small networks due to poor time and space asymptotics. In this work, we propose a first-order dual SDP algorithm that (1) requires memory only linear in the total number of network activations, (2) only requires a fixed number of forward/backward passes through the network per iteration. By exploiting iterative eigenvector methods, we express all solver operations in terms of forward and backward passes through the network, enabling efficient use of hardware like GPUs/TPUs. For two verification-agnostic networks on MNIST and CIFAR-10, we significantly improve L-inf verified robust accuracy from 1% to 88% and 6% to 40% respectively. We also demonstrate tight verification of a quadratic stability specification for the decoder of a variational autoencoder.
Less is more: Faster and better music version identification with embedding distillation
Oct 07, 2020
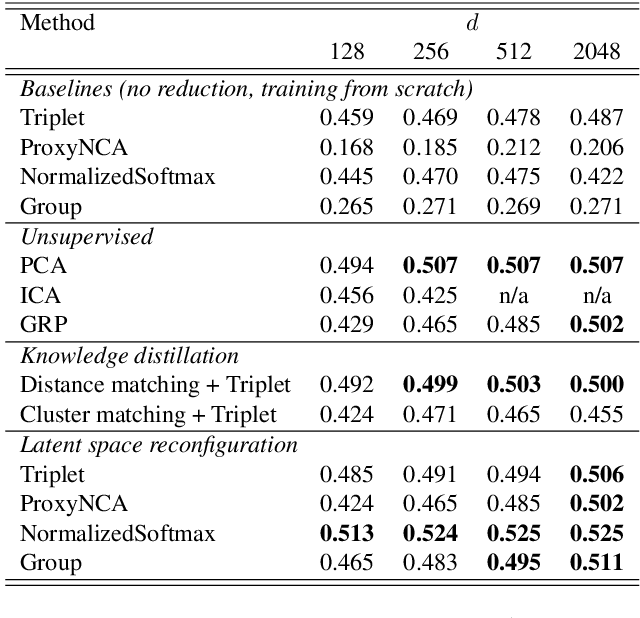
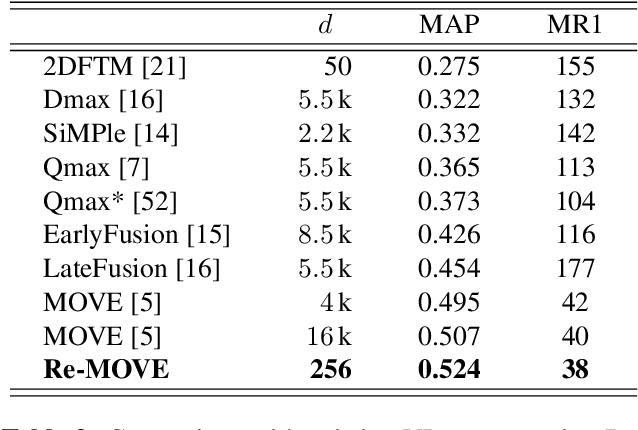
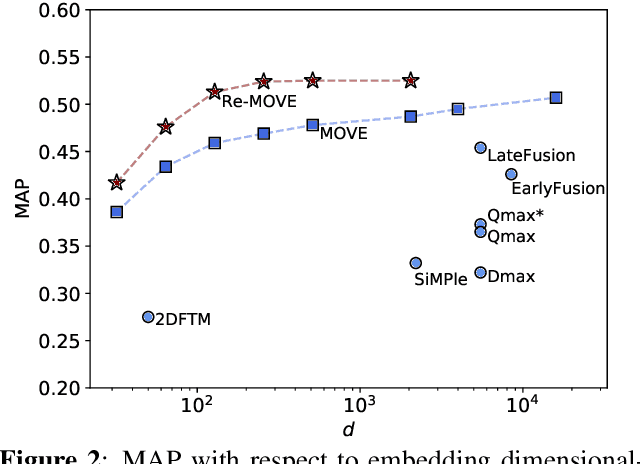
Version identification systems aim to detect different renditions of the same underlying musical composition (loosely called cover songs). By learning to encode entire recordings into plain vector embeddings, recent systems have made significant progress in bridging the gap between accuracy and scalability, which has been a key challenge for nearly two decades. In this work, we propose to further narrow this gap by employing a set of data distillation techniques that reduce the embedding dimensionality of a pre-trained state-of-the-art model. We compare a wide range of techniques and propose new ones, from classical dimensionality reduction to more sophisticated distillation schemes. With those, we obtain 99% smaller embeddings that, moreover, yield up to a 3% accuracy increase. Such small embeddings can have an important impact in retrieval time, up to the point of making a real-world system practical on a standalone laptop.
Deep learning for gravitational-wave data analysis: A resampling white-box approach
Sep 09, 2020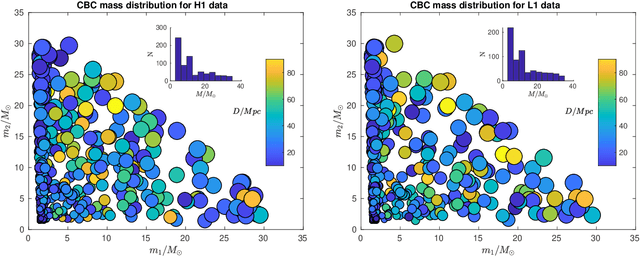
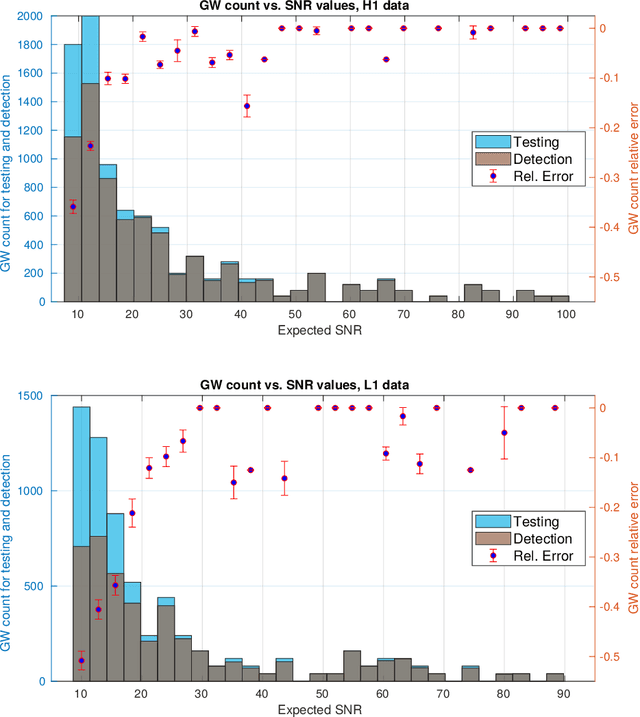
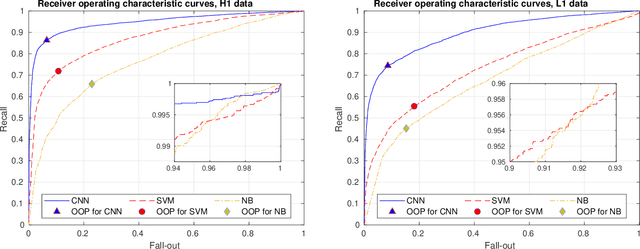
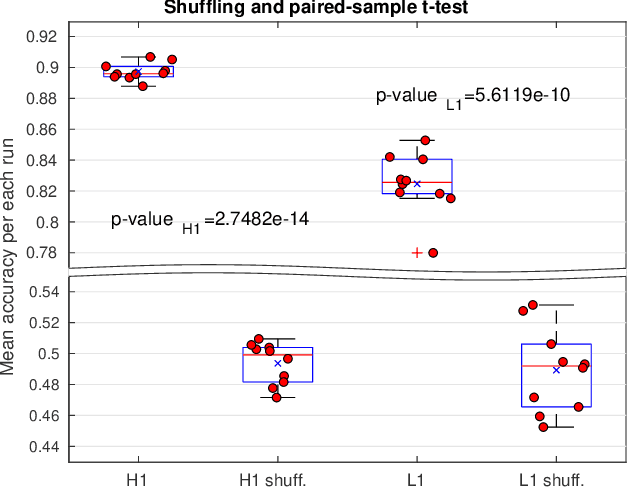
In this work, we apply Convolutional Neural Networks (CNNs) to detect gravitational wave (GW) signals of compact binary coalescences, using single-interferometer data from LIGO detectors. As novel contribution, we adopted a resampling white-box approach to advance towards a statistical understanding of uncertainties intrinsic to CNNs in GW data analysis. Resampling is performed by repeated $k$-fold cross-validation experiments, and for a white-box approach, behavior of CNNs is mathematically described in detail. Through a Morlet wavelet transform, strain time series are converted to time-frequency images, which in turn are reduced before generating input datasets. Moreover, to reproduce more realistic experimental conditions, we worked only with data of non-Gaussian noise and hardware injections, removing freedom to set signal-to-noise ratio (SNR) values in GW templates by hand. After hyperparameter adjustments, we found that resampling smooths stochasticity of mini-batch stochastic gradient descend by reducing mean accuracy perturbations in a factor of $3.6$. CNNs were quite precise to detect noise but not sensitive enough to recall GW signals, meaning that CNNs are better for noise reduction than generation of GW triggers. However, applying a post-analysis, we found that for GW signals of SNR $\geq 21.80$ with H1 data and SNR $\geq 26.80$ with L1 data, CNNs could remain as tentative alternatives for detecting GW signals. Besides, with receiving operating characteristic curves we found that CNNs show much better performances than those of Naive Bayes and Support Vector Machines models and, with a significance level of $5\%$, we estimated that predictions of CNNs are significant different from those of a random classifier. Finally, we elucidated that performance of CNNs is highly class dependent because of the distribution of probabilistic scores outputted by the softmax layer.
Brain Tumor Segmentation using 3D-CNNs with Uncertainty Estimation
Sep 24, 2020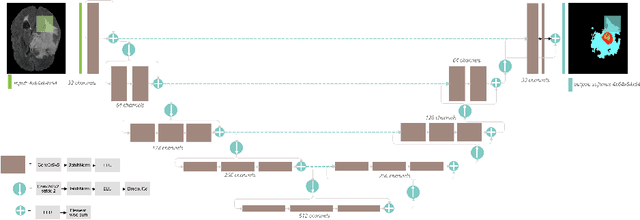
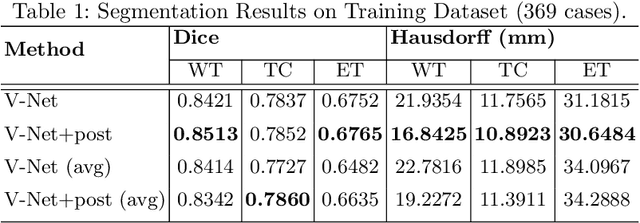

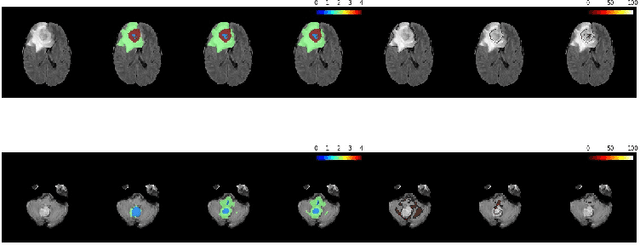
Automation of brain tumors in 3D magnetic resonance images (MRIs) is key to assess the diagnostic and treatment of the disease. In recent years, convolutional neural networks (CNNs) have shown improved results in the task. However, high memory consumption is still a problem in 3D-CNNs. Moreover, most methods do not include uncertainty information, which is specially critical in medical diagnosis. This work proposes a 3D encoder-decoder architecture, based on V-Net \cite{vnet} which is trained with patching techniques to reduce memory consumption and decrease the effect of unbalanced data. We also introduce voxel-wise uncertainty, both epistemic and aleatoric using test-time dropout and data-augmentation respectively. Uncertainty maps can provide extra information to expert neurologists, useful for detecting when the model is not confident on the provided segmentation.
Reflection Backdoor: A Natural Backdoor Attack on Deep Neural Networks
Jul 05, 2020



Recent studies have shown that DNNs can be compromised by backdoor attacks crafted at training time. A backdoor attack installs a backdoor into the victim model by injecting a backdoor pattern into a small proportion of the training data. At test time, the victim model behaves normally on clean test data, yet consistently predicts a specific (likely incorrect) target class whenever the backdoor pattern is present in a test example. While existing backdoor attacks are effective, they are not stealthy. The modifications made on training data or labels are often suspicious and can be easily detected by simple data filtering or human inspection. In this paper, we present a new type of backdoor attack inspired by an important natural phenomenon: reflection. Using mathematical modeling of physical reflection models, we propose reflection backdoor (Refool) to plant reflections as backdoor into a victim model. We demonstrate on 3 computer vision tasks and 5 datasets that, Refool can attack state-of-the-art DNNs with high success rate, and is resistant to state-of-the-art backdoor defenses.
Deep Reservoir Computing with Learned Hidden Reservoir Weights using Direct Feedback Alignment
Oct 13, 2020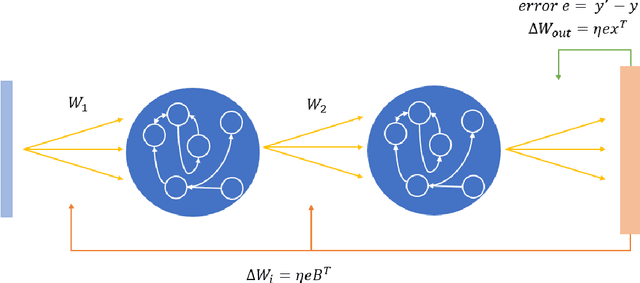

Deep Reservoir Computing has emerged as a new paradigm for deep learning, which is based around the reservoir computing principle of maintaining random pools of neurons. The reservoir paradigm reflects and respects the high degree of recurrence in biological brains, and the role that neuronal dynamics play in learning. However, one issue hampering deep reservoir development is that one cannot backpropagate through the reservoir layers. Recent deep reservoir architectures do not learn hidden or hierarchical representations in the same manner as deep artifical neural neteworks (ANNs), but rather concatenate all hidden reservoirs together to perform traditional regression. Here we present a novel Deep Reservoir Computer for time series prediction and classification that learns through the non-differentiable hidden reservoir layers using a biologically-inspired backpropagation alternative called Direct Feedback Alignment, which resembles global dopamine signal broadcasting in the brain. The hope is that this will enable future deep reservoir architectures to learn hidden temporal representations.