 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Red Blood Cell Segmentation with Overlapping Cell Separation and Classification on Imbalanced Dataset
Dec 09, 2020
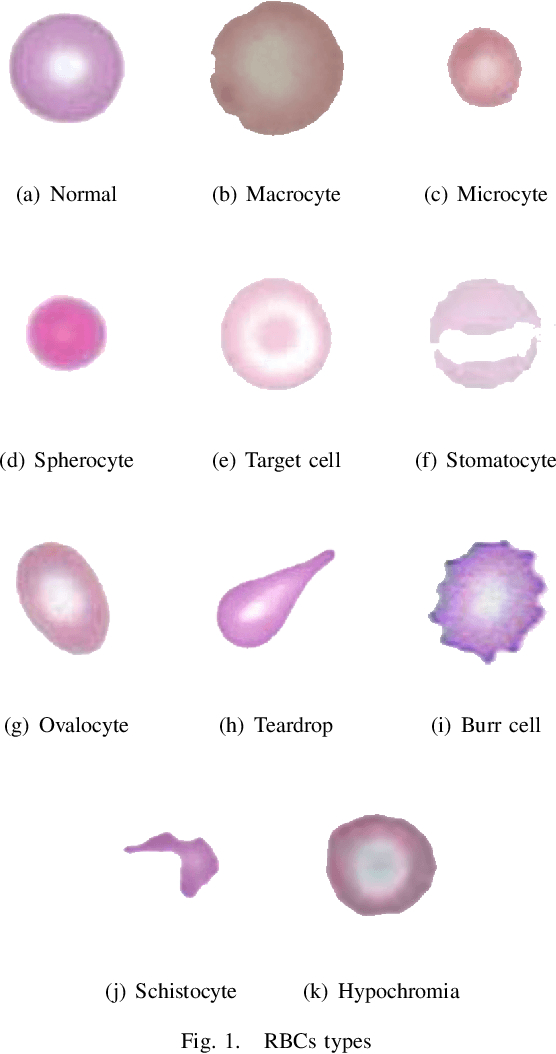
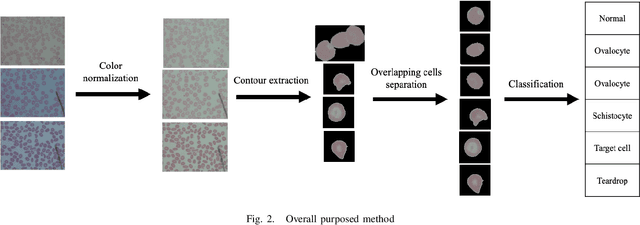


Automated red blood cell classification on blood smear images helps hematologist to analyze RBC lab results in less time and cost. Overlapping cells can cause incorrect predicted results that have to separate into multiple single RBCs before classifying. To classify multiple classes with deep learning, imbalance problems are common in medical imaging because normal samples are always higher than rare disease samples. This paper presents a new method to segment and classify red blood cells from blood smear images, specifically to tackle cell overlapping and data imbalance problems. Focusing on overlapping cell separation, our segmentation process first estimates ellipses to represent red blood cells. The method detects the concave points and then finds the ellipses using directed ellipse fitting. The accuracy is 0.889 on 20 blood smear images. Classification requires balanced training datasets. However, some RBC types are rare. The imbalance ratio is 34.538 on 12 classes with 20,875 individual red blood cell samples. The use of machine learning for RBC classification with an imbalance dataset is hence more challenging than many other applications. We analyze techniques to deal with this problem. The best accuracy and f1 score are 0.921 and 0.8679 on EfficientNet-b1 with augmentation. Experimental results show that the weight balancing technique with augmentation has the potential to deal with imbalance problems by improving the f1 score on minority classes while data augmentation significantly improves the overall classification performance.
Formation of Regression Model for Analysis of Complex Systems Using Methodology of Genetic Algorithms
Nov 13, 2020
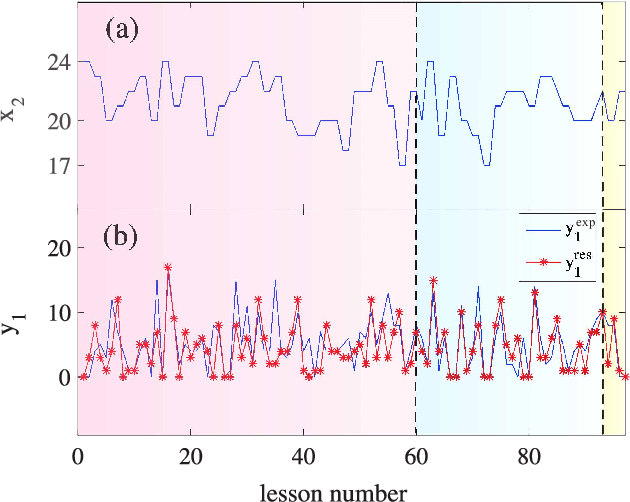
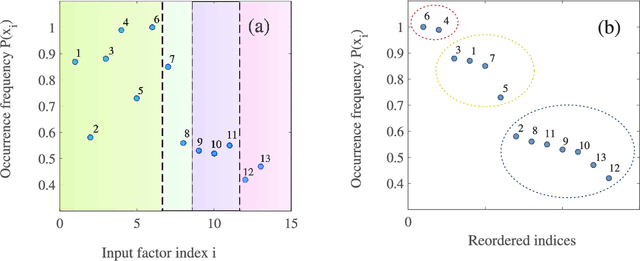

This study presents the approach to analyzing the evolution of an arbitrary complex system whose behavior is characterized by a set of different time-dependent factors. The key requirement for these factors is only that they must contain an information about the system; it does not matter at all what the nature (physical, biological, social, economic, etc.) of a complex system is. Within the framework of the presented theoretical approach, the problem of searching for non-linear regression models that express the relationship between these factors for a complex system under study is solved. It will be shown that this problem can be solved using the methodology of \emph{genetic (evolutionary)} algorithms. The resulting regression models make it possible to predict the most probable evolution of the considered system, as well as to determine the significance of some factors and, thereby, to formulate some recommendations to drive by this system. It will be shown that the presented theoretical approach can be used to analyze the data (information) characterizing the educational process in the discipline "Physics" in the secondary school, and to develop the strategies for improving academic performance in this discipline.
* 8 pages, 3 figures, 1 table
Attention, please: A Spatio-temporal Transformer for 3D Human Motion Prediction
Apr 18, 2020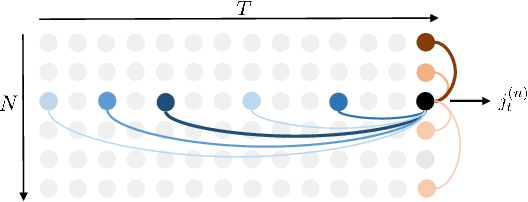
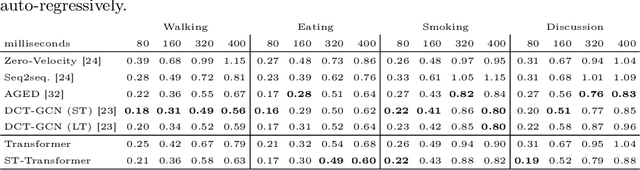
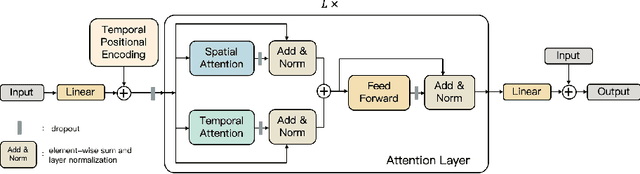

In this paper, we propose a novel architecture for the task of 3D human motion modelling. We argue that the problem can be interpreted as a generative modelling task: A network learns the conditional synthesis of human poses where the model is conditioned on a seed sequence. Our focus lies on the generation of plausible future developments over longer time horizons, whereas previous work considered shorter time frames of up to 1 second. To mitigate the issue of convergence to a static pose, we propose a novel architecture that leverages the recently proposed self-attention concept. The task of 3D motion prediction is inherently spatio-temporal and thus the proposed model learns high dimensional joint embeddings followed by a decoupled temporal and spatial self-attention mechanism. The two attention blocks operate in parallel to aggregate the most informative components of the sequence to update the joint representation. This allows the model to access past information directly and to capture spatio-temporal dependencies explicitly. We show empirically that this reduces error accumulation over time and allows for the generation of perceptually plausible motion sequences over long time horizons as well as accurate short-term predictions. Accompanying video available at https://youtu.be/yF0cdt2yCNE .
Learning to Run with Potential-Based Reward Shaping and Demonstrations from Video Data
Dec 16, 2020
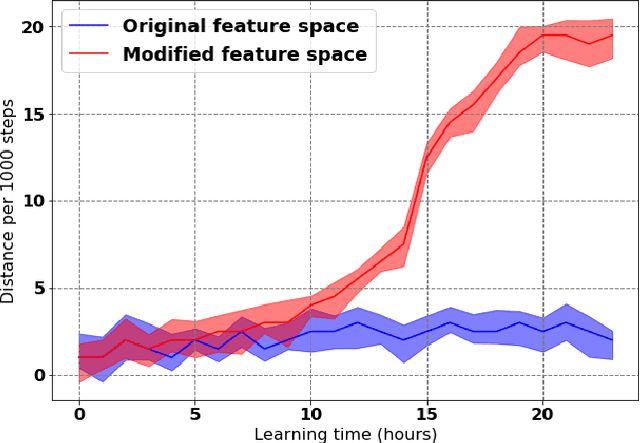
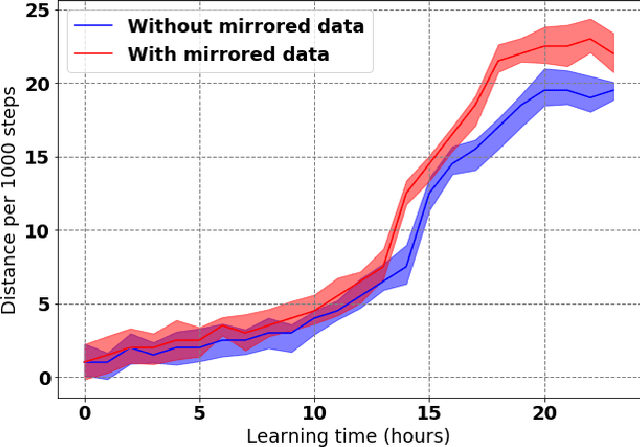
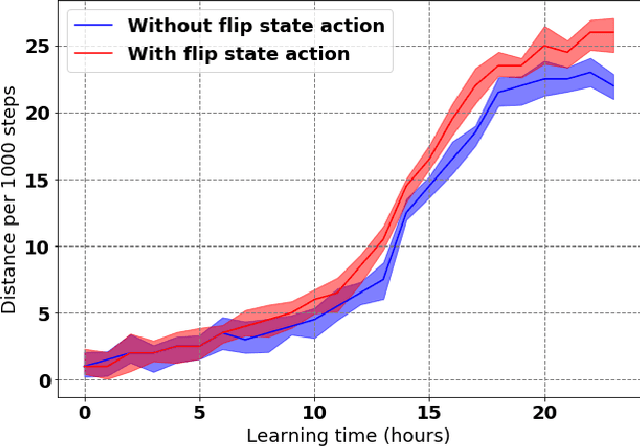
Learning to produce efficient movement behaviour for humanoid robots from scratch is a hard problem, as has been illustrated by the "Learning to run" competition at NIPS 2017. The goal of this competition was to train a two-legged model of a humanoid body to run in a simulated race course with maximum speed. All submissions took a tabula rasa approach to reinforcement learning (RL) and were able to produce relatively fast, but not optimal running behaviour. In this paper, we demonstrate how data from videos of human running (e.g. taken from YouTube) can be used to shape the reward of the humanoid learning agent to speed up the learning and produce a better result. Specifically, we are using the positions of key body parts at regular time intervals to define a potential function for potential-based reward shaping (PBRS). Since PBRS does not change the optimal policy, this approach allows the RL agent to overcome sub-optimalities in the human movements that are shown in the videos. We present experiments in which we combine selected techniques from the top ten approaches from the NIPS competition with further optimizations to create an high-performing agent as a baseline. We then demonstrate how video-based reward shaping improves the performance further, resulting in an RL agent that runs twice as fast as the baseline in 12 hours of training. We furthermore show that our approach can overcome sub-optimal running behaviour in videos, with the learned policy significantly outperforming that of the running agent from the video.
Zero-Shot Learning from scratch (ZFS): leveraging local compositional representations
Oct 22, 2020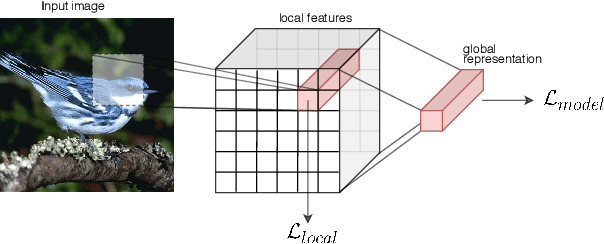
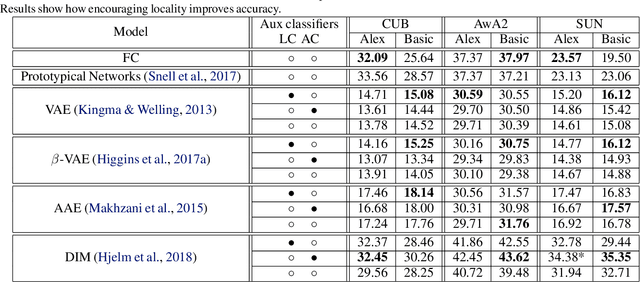
Zero-shot classification is a generalization task where no instance from the target classes is seen during training. To allow for test-time transfer, each class is annotated with semantic information, commonly in the form of attributes or text descriptions. While classical zero-shot learning does not explicitly forbid using information from other datasets, the approaches that achieve the best absolute performance on image benchmarks rely on features extracted from encoders pretrained on Imagenet. This approach relies on hyper-optimized Imagenet-relevant parameters from the supervised classification setting, entangling important questions about the suitability of those parameters and how they were learned with more fundamental questions about representation learning and generalization. To remove these distractors, we propose a more challenging setting: Zero-Shot Learning from scratch (ZFS), which explicitly forbids the use of encoders fine-tuned on other datasets. Our analysis on this setting highlights the importance of local information, and compositional representations.
RONELD: Robust Neural Network Output Enhancement for Active Lane Detection
Nov 03, 2020

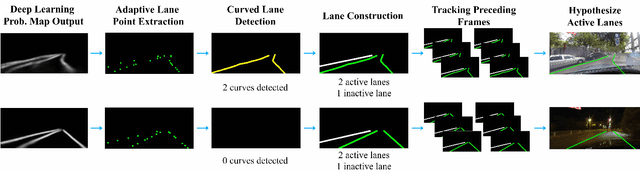
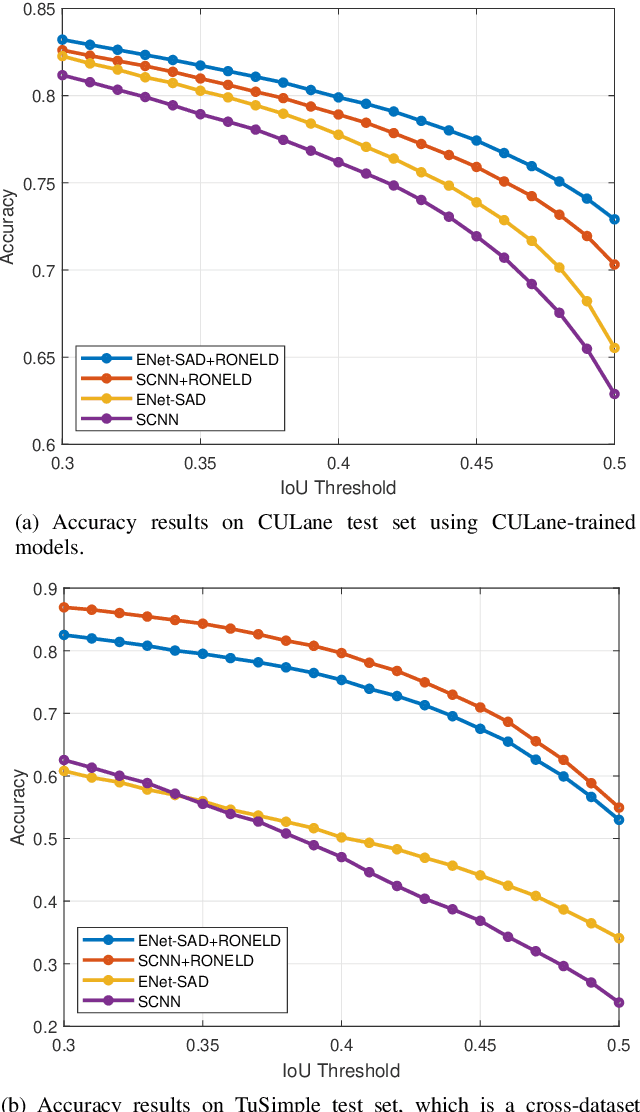
Accurate lane detection is critical for navigation in autonomous vehicles, particularly the active lane which demarcates the single road space that the vehicle is currently traveling on. Recent state-of-the-art lane detection algorithms utilize convolutional neural networks (CNNs) to train deep learning models on popular benchmarks such as TuSimple and CULane. While each of these models works particularly well on train and test inputs obtained from the same dataset, the performance drops significantly on unseen datasets of different environments. In this paper, we present a real-time robust neural network output enhancement for active lane detection (RONELD) method to identify, track, and optimize active lanes from deep learning probability map outputs. We first adaptively extract lane points from the probability map outputs, followed by detecting curved and straight lanes before using weighted least squares linear regression on straight lanes to fix broken lane edges resulting from fragmentation of edge maps in real images. Lastly, we hypothesize true active lanes through tracking preceding frames. Experimental results demonstrate an up to two-fold increase in accuracy using RONELD on cross-dataset validation tests.
Adversarial Robustness of Supervised Sparse Coding
Oct 22, 2020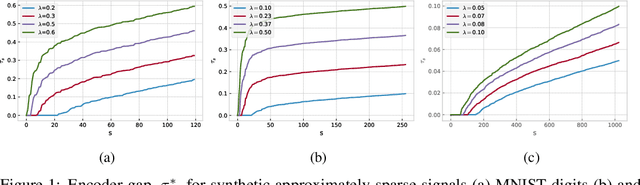
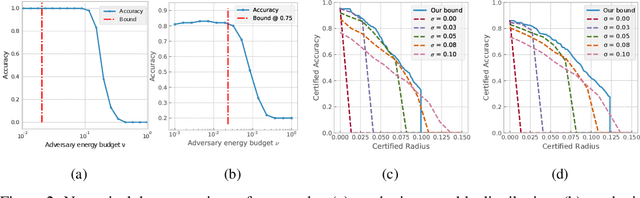
Several recent results provide theoretical insights into the phenomena of adversarial examples. Existing results, however, are often limited due to a gap between the simplicity of the models studied and the complexity of those deployed in practice. In this work, we strike a better balance by considering a model that involves learning a representation while at the same time giving a precise generalization bound and a robustness certificate. We focus on the hypothesis class obtained by combining a sparsity-promoting encoder coupled with a linear classifier, and show an interesting interplay between the expressivity and stability of the (supervised) representation map and a notion of margin in the feature space. We bound the robust risk (to $\ell_2$-bounded perturbations) of hypotheses parameterized by dictionaries that achieve a mild encoder gap on training data. Furthermore, we provide a robustness certificate for end-to-end classification. We demonstrate the applicability of our analysis by computing certified accuracy on real data, and compare with other alternatives for certified robustness.
"Closed Proportional-Integral-Derivative-Loop Model" Following Control
May 30, 2020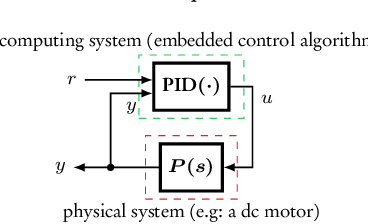
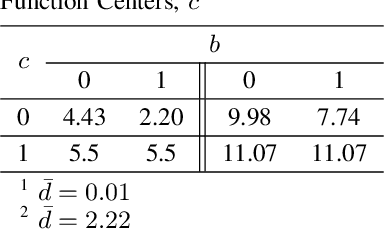
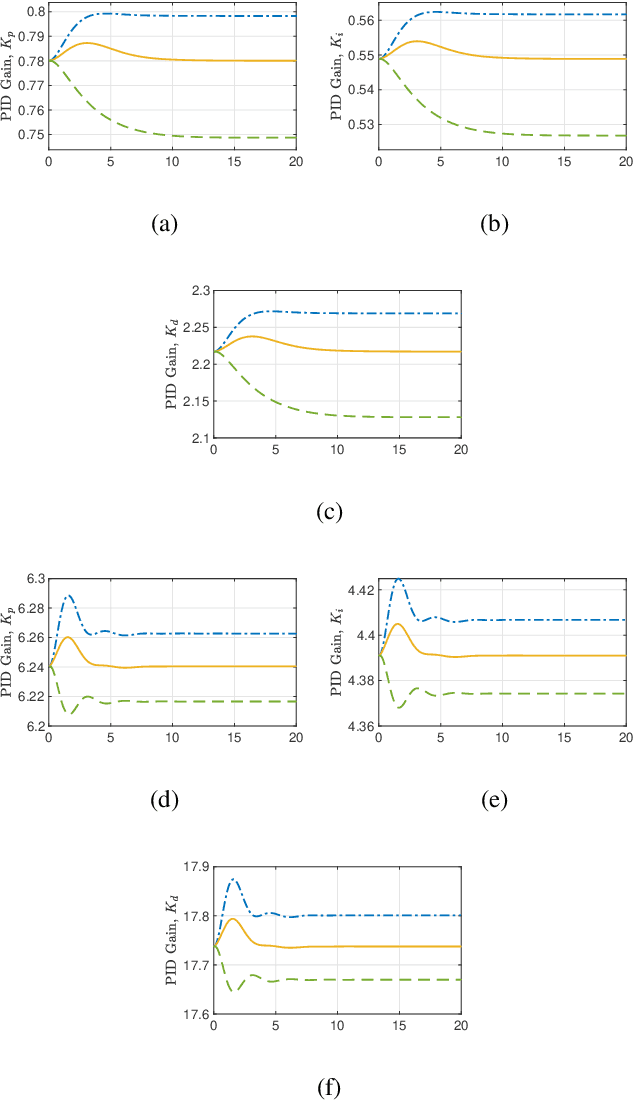
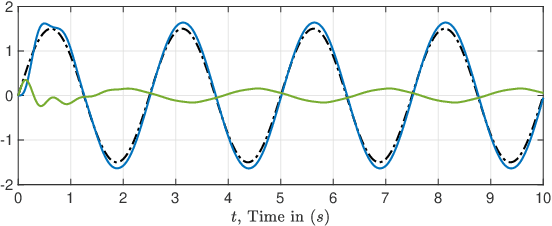
The proportional-integral-derivative (PID) control law is often overlooked as a computational imitation of the critic control in human decision. This paper provides a formulation to remedy this problem. Further, based on the characteristic settling-behaviour of dynamical systems, the "closed PID-loop model" following control (CPLMFC) method is introduced for automatic PID design. Also, a method for closed-loop settling-time identification is provided. The CPLMFC algorithm and some recommended guidelines are given for setting the critic weights of the PID. Finally, two representative case-studies are simulated. Both the theoretical results and simulation results (via performance indices) illustrate that the CPLMFC can guarantee both accurate and stable closed-loop adaptive PID control performance in real-time
A Data-Driven Analytical Framework of Estimating Multimodal Travel Demand Patterns using Mobile Device Location Data
Dec 08, 2020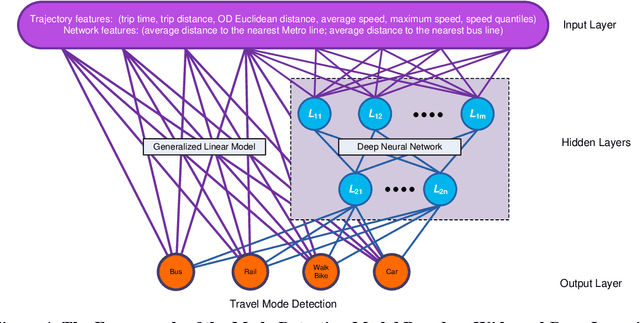

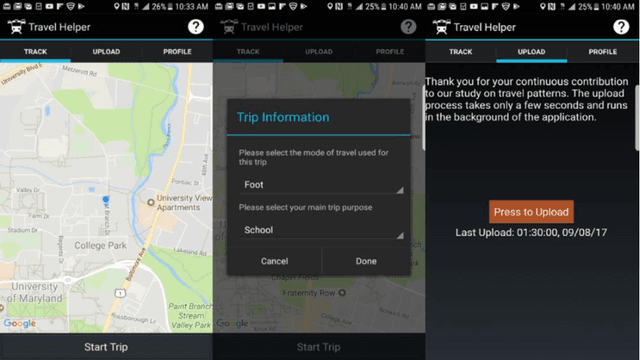
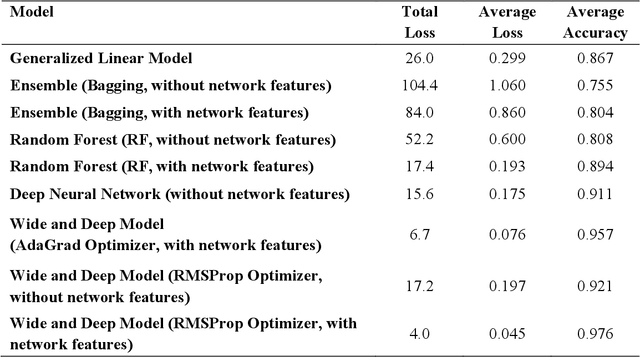
While benefiting people's daily life in so many ways, smartphones and their location-based services are generating massive mobile device location data that has great potential to help us understand travel demand patterns and make transportation planning for the future. While recent studies have analyzed human travel behavior using such new data sources, limited research has been done to extract multimodal travel demand patterns out of them. This paper presents a data-driven analytical framework to bridge the gap. To be able to successfully detect travel modes using the passively collected location information, we conduct a smartphone-based GPS survey to collect ground truth observations. Then a jointly trained single-layer model and deep neural network for travel mode imputation is developed. Being "wide" and "deep" at the same time, this model combines the advantages of both types of models. The framework also incorporates the multimodal transportation network in order to evaluate the closeness of trip routes to the nearby rail, metro, highway and bus lines and therefore enhance the imputation accuracy. To showcase the applications of the introduced framework in answering real-world planning needs, a separate mobile device location data is processed through trip end identification and attribute generation, in a way that the travel mode imputation can be directly applied. The estimated multimodal travel demand patterns are then validated against typical household travel surveys in the same Washington D.C. and Baltimore Metropolitan Regions.
Channel Estimation for Full-Duplex RIS-assisted HAPS Backhauling with Graph Attention Networks
Oct 22, 2020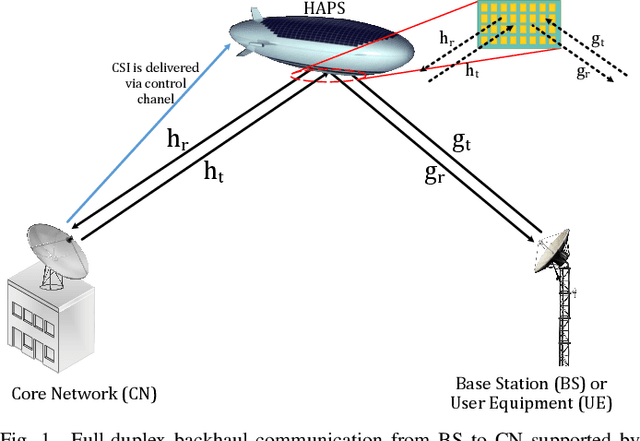
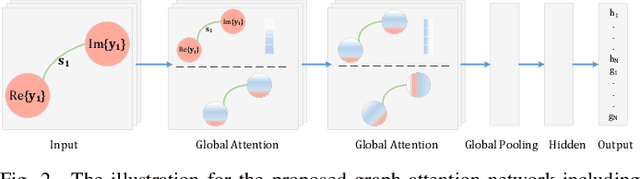
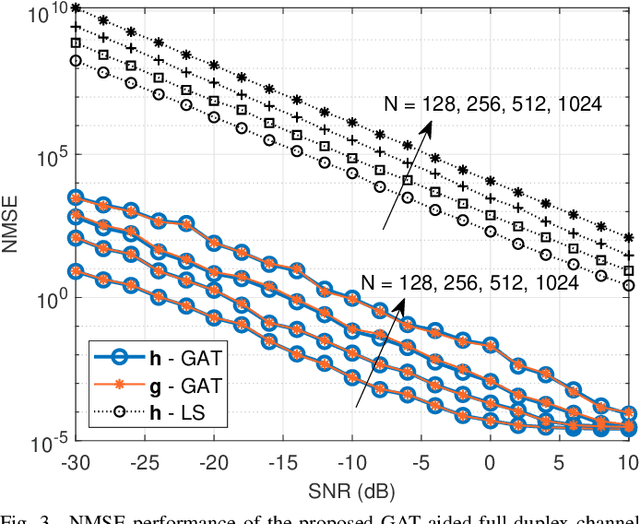
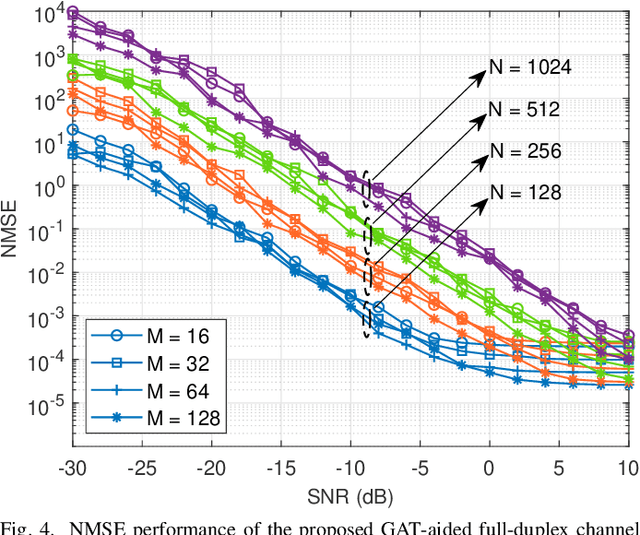
In this paper, the graph attention network (GAT) is firstly utilized for the channel estimation. In accordance with the 6G expectations, we consider a high-altitude platform station (HAPS) mounted reconfigurable intelligent surface-assisted two-way communications and obtain a low overhead and a high normalized mean square error performance. The performance of the proposed method is investigated on the two-way backhauling link over the RIS-integrated HAPS. The simulation results denote that the GAT estimator overperforms the least square in full-duplex channel estimation. Contrary to the previously introduced methods, GAT at one of the nodes can separately estimate the cascaded channel coefficients. Thus, there is no need to use time-division duplex mode during pilot signaling in full-duplex communication. Moreover, it is shown that the GAT estimator is robust to hardware imperfections and changes in small scale fading characteristics even if the training data do not include all these variations.