 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Reverberant Sound Localization with a Robot Head Based on Direct-Path Relative Transfer Function
Dec 07, 2020


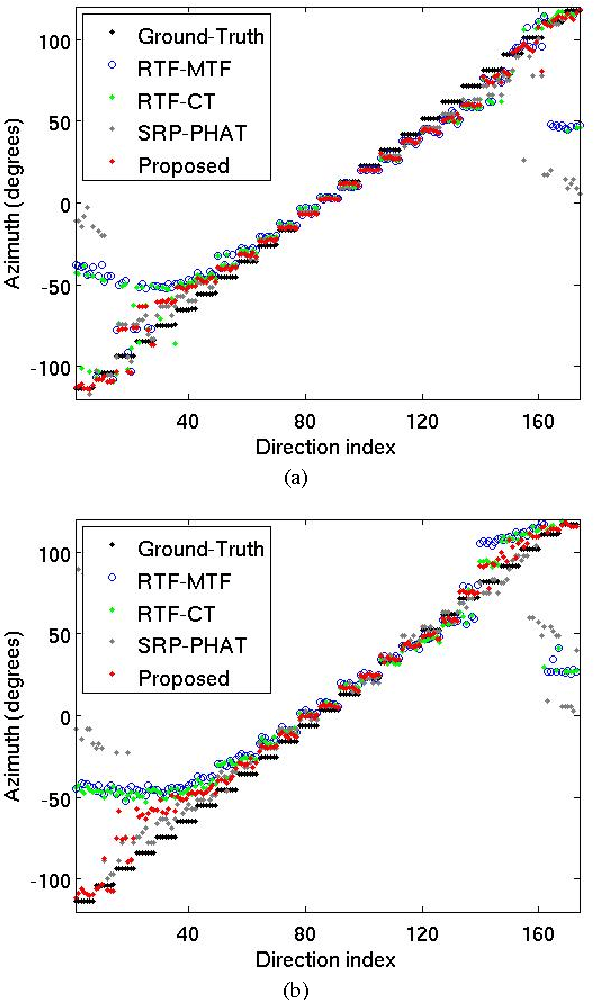
This paper addresses the problem of sound-source localization (SSL) with a robot head, which remains a challenge in real-world environments. In particular we are interested in locating speech sources, as they are of high interest for human-robot interaction. The microphone-pair response corresponding to the direct-path sound propagation is a function of the source direction. In practice, this response is contaminated by noise and reverberations. The direct-path relative transfer function (DP-RTF) is defined as the ratio between the direct-path acoustic transfer function (ATF) of the two microphones, and it is an important feature for SSL. We propose a method to estimate the DP-RTF from noisy and reverberant signals in the short-time Fourier transform (STFT) domain. First, the convolutive transfer function (CTF) approximation is adopted to accurately represent the impulse response of the microphone array, and the first coefficient of the CTF is mainly composed of the direct-path ATF. At each frequency, the frame-wise speech auto- and cross-power spectral density (PSD) are obtained by spectral subtraction. Then a set of linear equations is constructed by the speech auto- and cross-PSD of multiple frames, in which the DP-RTF is an unknown variable, and is estimated by solving the equations. Finally, the estimated DP-RTFs are concatenated across frequencies and used as a feature vector for SSL. Experiments with a robot, placed in various reverberant environments, show that the proposed method outperforms two state-of-the-art methods.
We don't Need Thousand Proposals$\colon$ Single Shot Actor-Action Detection in Videos
Nov 22, 2020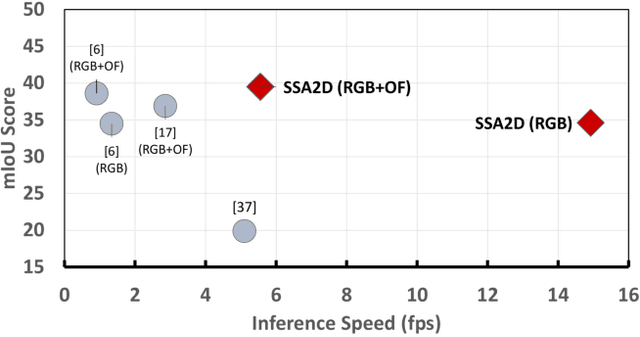
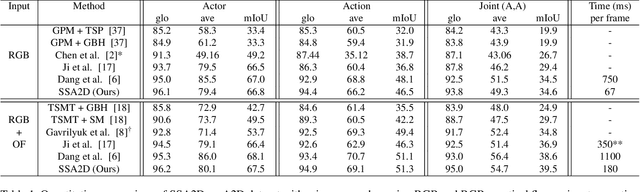
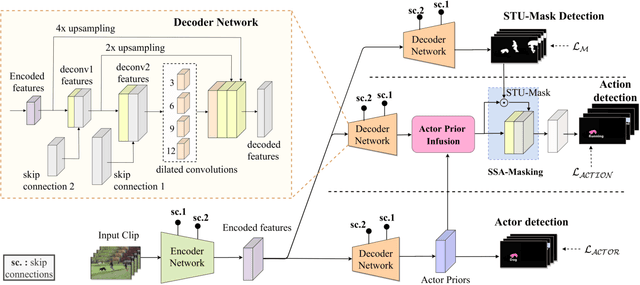
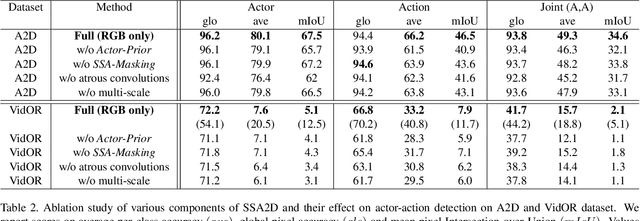
We propose SSA2D, a simple yet effective end-to-end deep network for actor-action detection in videos. The existing methods take a top-down approach based on region-proposals (RPN), where the action is estimated based on the detected proposals followed by post-processing such as non-maximal suppression. While effective in terms of performance, these methods pose limitations in scalability for dense video scenes with a high memory requirement for thousands of proposals. We propose to solve this problem from a different perspective where we don't need any proposals. SSA2D is a unified network, which performs pixel level joint actor-action detection in a single-shot, where every pixel of the detected actor is assigned an action label. SSA2D has two main advantages: 1) It is a fully convolutional network which does not require any proposals and post-processing making it memory as well as time efficient, 2) It is easily scalable to dense video scenes as its memory requirement is independent of the number of actors present in the scene. We evaluate the proposed method on the Actor-Action dataset (A2D) and Video Object Relation (VidOR) dataset, demonstrating its effectiveness in multiple actors and action detection in a video. SSA2D is 11x faster during inference with comparable (sometimes better) performance and fewer network parameters when compared with the prior works.
Online Object-Oriented Semantic Mapping and Map Updating with Modular Representations
Nov 13, 2020
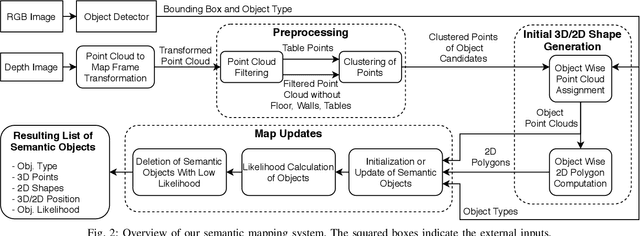

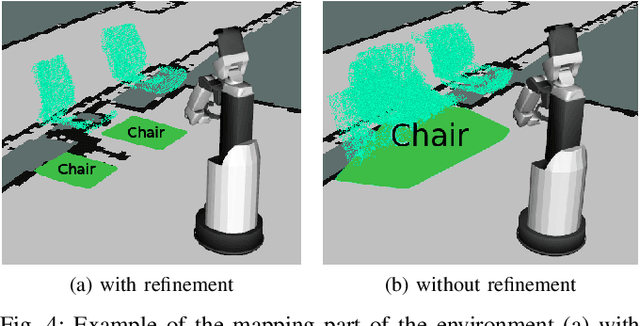
Creating and maintaining an accurate representation of the environment is an essential capability for every service robot. Especially semantic information is important for household robots acting in indoor environments. In this paper, we present a semantic mapping framework with modular map representations. Our system is capable of online mapping and object updating given object detections from RGB-D~data and provides various 2D and 3D~representations of the mapped objects. To undo wrong data association, we perform a refinement step when updating object shapes. Furthermore, we maintain a likelihood for each object to deal with false positive and false negative detections and keep the map updated. Our mapping system is highly efficient and achieves a run time of more than 10 Hz. We evaluated our approach in various environments using two different robots, i.e., a HSR by Toyota and a \mbox{Care-O-Bot-4} by Fraunhofer. As the experimental results demonstrate, our system is able to generate maps that are close to the ground truth and outperforms an existing approach in terms of intersection over union, different distance metrics, and the number of correct object mappings. We plan to publish the code of our system for the final submission.
High Quality Remote Sensing Image Super-Resolution Using Deep Memory Connected Network
Oct 01, 2020
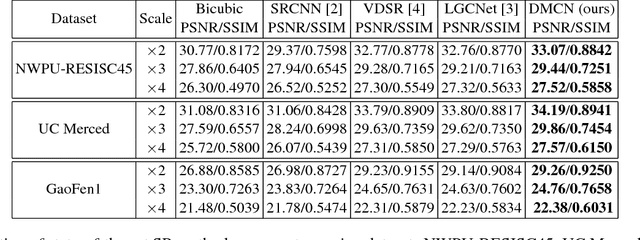
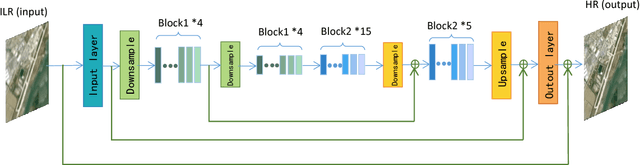

Single image super-resolution is an effective way to enhance the spatial resolution of remote sensing image, which is crucial for many applications such as target detection and image classification. However, existing methods based on the neural network usually have small receptive fields and ignore the image detail. We propose a novel method named deep memory connected network (DMCN) based on a convolutional neural network to reconstruct high-quality super-resolution images. We build local and global memory connections to combine image detail with environmental information. To further reduce parameters and ease time-consuming, we propose downsampling units, shrinking the spatial size of feature maps. We test DMCN on three remote sensing datasets with different spatial resolution. Experimental results indicate that our method yields promising improvements in both accuracy and visual performance over the current state-of-the-art.
Discriminative Nearest Neighbor Few-Shot Intent Detection by Transferring Natural Language Inference
Oct 25, 2020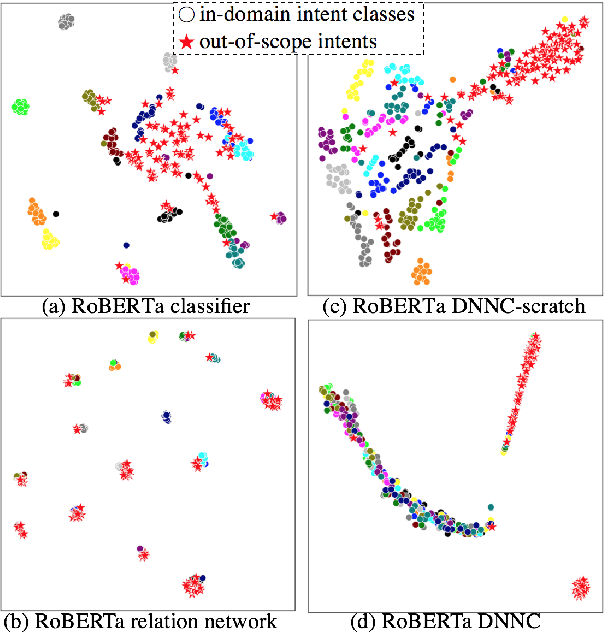

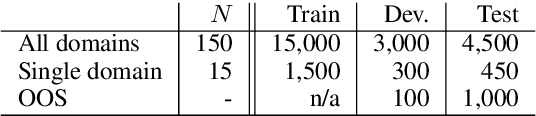
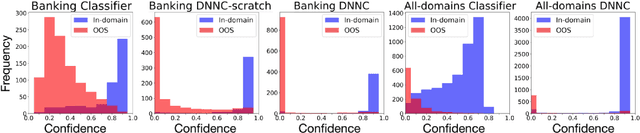
Intent detection is one of the core components of goal-oriented dialog systems, and detecting out-of-scope (OOS) intents is also a practically important skill. Few-shot learning is attracting much attention to mitigate data scarcity, but OOS detection becomes even more challenging. In this paper, we present a simple yet effective approach, discriminative nearest neighbor classification with deep self-attention. Unlike softmax classifiers, we leverage BERT-style pairwise encoding to train a binary classifier that estimates the best matched training example for a user input. We propose to boost the discriminative ability by transferring a natural language inference (NLI) model. Our extensive experiments on a large-scale multi-domain intent detection task show that our method achieves more stable and accurate in-domain and OOS detection accuracy than RoBERTa-based classifiers and embedding-based nearest neighbor approaches. More notably, the NLI transfer enables our 10-shot model to perform competitively with 50-shot or even full-shot classifiers, while we can keep the inference time constant by leveraging a faster embedding retrieval model.
Machine learning modeling for time series problem: Predicting flight ticket prices
Feb 04, 2018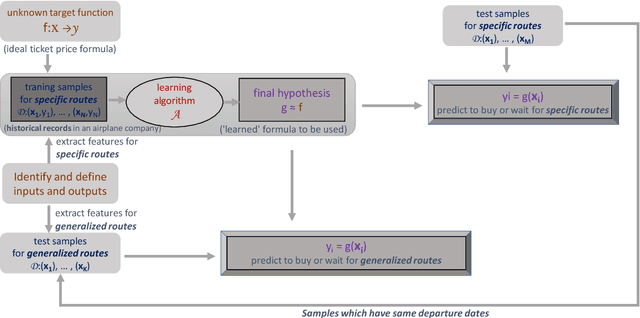
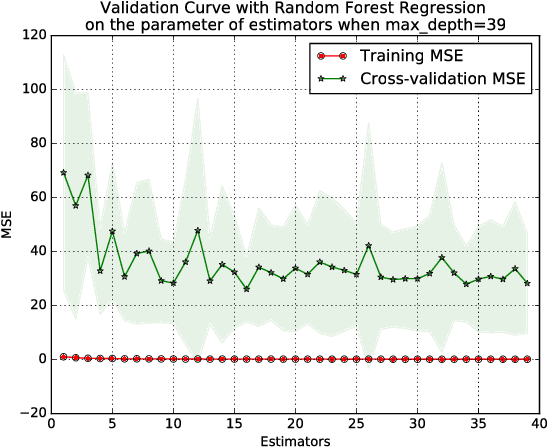
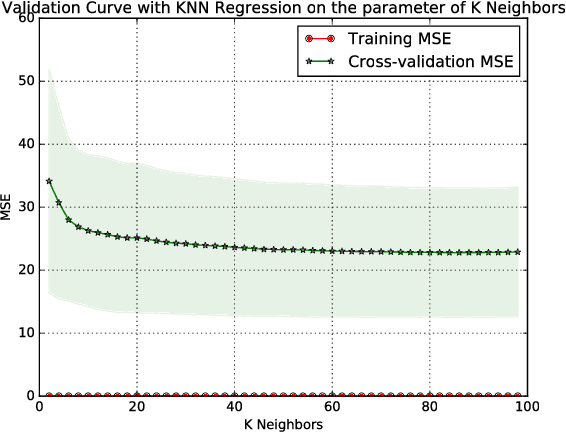
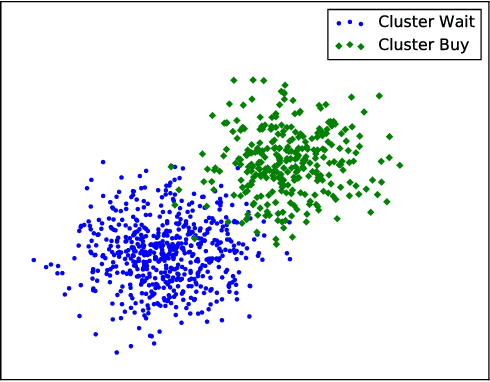
Machine learning has been used in all kinds of fields. In this article, we introduce how machine learning can be applied into time series problem. Especially, we use the airline ticket prediction problem as our specific problem. Airline companies use many different variables to determine the flight ticket prices: indicator whether the travel is during the holidays, the number of free seats in the plane etc. Some of the variables are observed, but some of them are hidden. Based on the data over a 103 day period, we trained our models, getting the best model - which is AdaBoost-Decision Tree Classification. This algorithm has best performance over the observed 8 routes which has 61.35$\%$ better performance than the random purchase strategy, and relatively small variance over these routes. And we also considered the situation that we cannot get too much historical datas for some routes (for example the route is new and does not have historical data) or we do not want to train historical data to predict to buy or wait quickly, in which problem, we used HMM Sequence Classification based AdaBoost-Decision Tree Classification to perform our prediction on 12 new routes. Finally, we got 31.71$\%$ better performance than the random purchase strategy.
A Probabilistic Model with Commonsense Constraints for Pattern-based Temporal Fact Extraction
Jun 11, 2020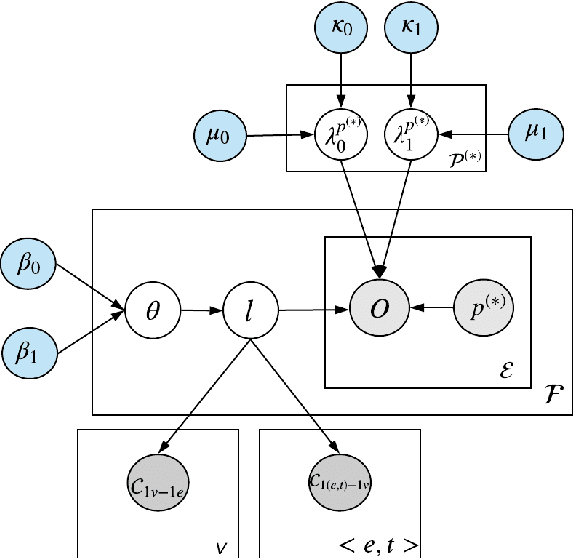
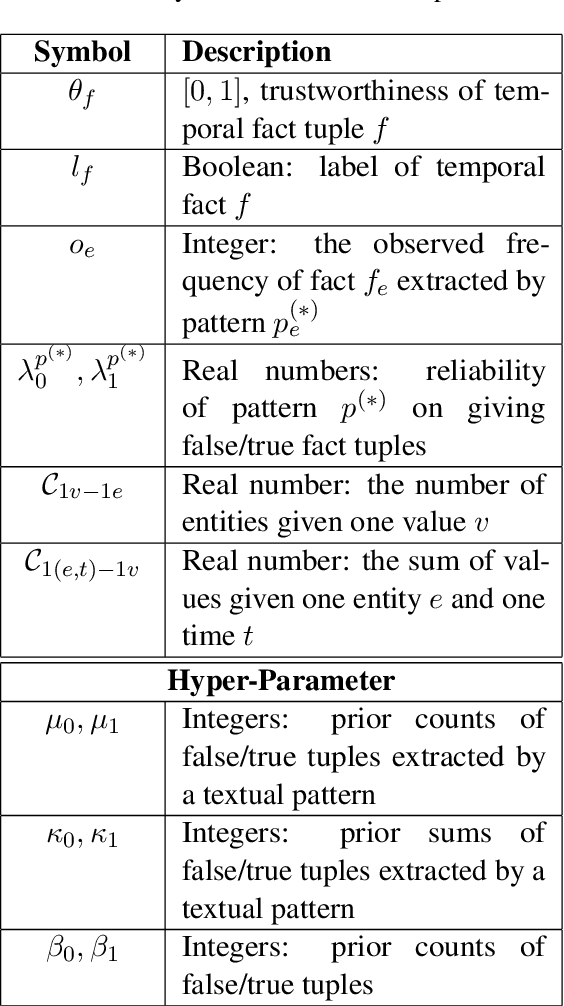
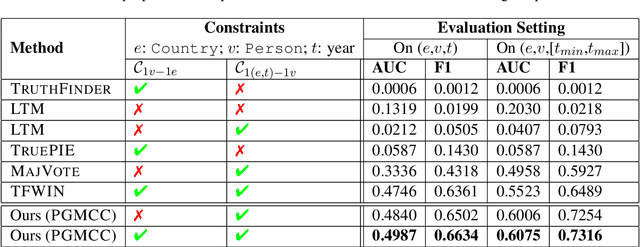
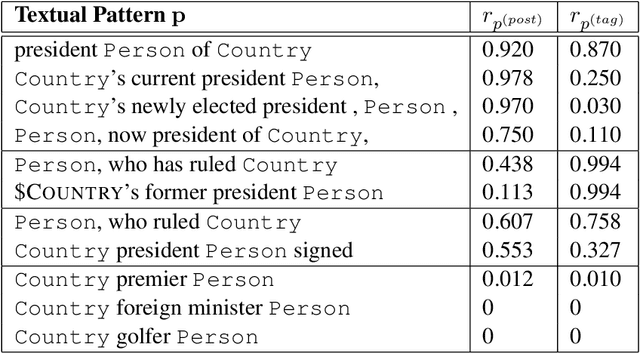
Textual patterns (e.g., Country's president Person) are specified and/or generated for extracting factual information from unstructured data. Pattern-based information extraction methods have been recognized for their efficiency and transferability. However, not every pattern is reliable: A major challenge is to derive the most complete and accurate facts from diverse and sometimes conflicting extractions. In this work, we propose a probabilistic graphical model which formulates fact extraction in a generative process. It automatically infers true facts and pattern reliability without any supervision. It has two novel designs specially for temporal facts: (1) it models pattern reliability on two types of time signals, including temporal tag in text and text generation time; (2) it models commonsense constraints as observable variables. Experimental results demonstrate that our model significantly outperforms existing methods on extracting true temporal facts from news data.
A New Mathematical Model for Controlled Pandemics Like COVID-19 : AI Implemented Predictions
Aug 24, 2020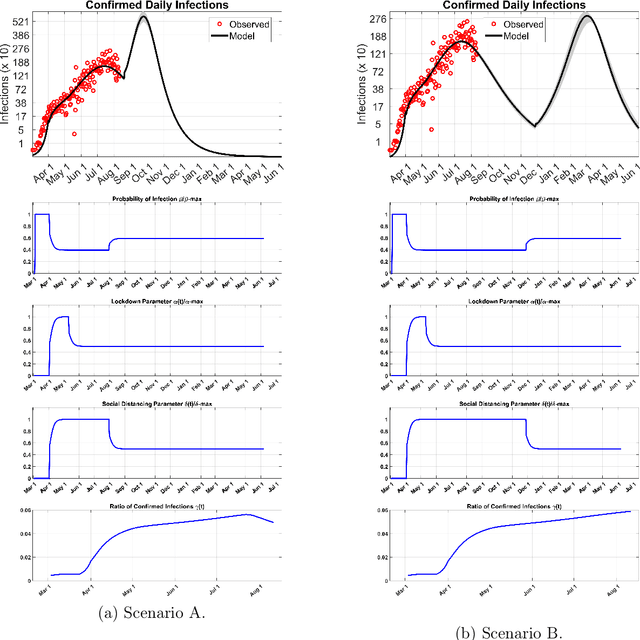
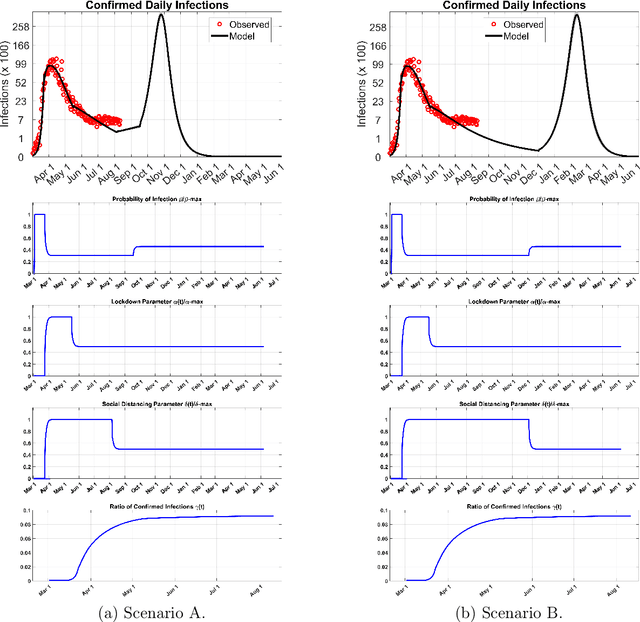
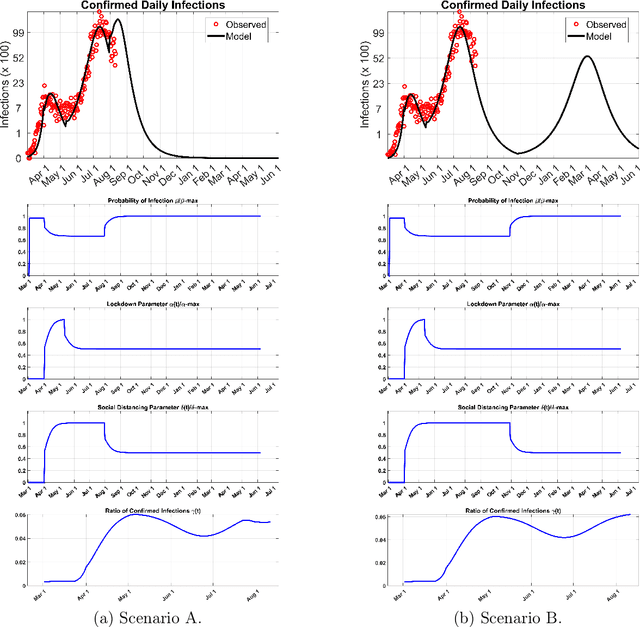
We present a new mathematical model to explicitly capture the effects that the three restriction measures: the lockdown date and duration, social distancing and masks, and, schools and border closing, have in controlling the spread of COVID-19 infections $i(r, t)$. Before restrictions were introduced, the random spread of infections as described by the SEIR model grew exponentially. The addition of control measures introduces a mixing of order and disorder in the system's evolution which fall under a different mathematical class of models that can eventually lead to critical phenomena. A generic analytical solution is hard to obtain. We use machine learning to solve the new equations for $i(r,t)$, the infections $i$ in any region $r$ at time $t$ and derive predictions for the spread of infections over time as a function of the strength of the specific measure taken and their duration. The machine is trained in all of the COVID-19 published data for each region, county, state, and country in the world. It utilizes optimization to learn the best-fit values of the model's parameters from past data in each region in the world, and it updates the predicted infections curves for any future restrictions that may be added or relaxed anywhere. We hope this interdisciplinary effort, a new mathematical model that predicts the impact of each measure in slowing down infection spread combined with the solving power of machine learning, is a useful tool in the fight against the current pandemic and potentially future ones.
Experimental Assessment of Human-Robot Teaming for Multi-Step Remote Manipulation with Expert Operators
Nov 22, 2020
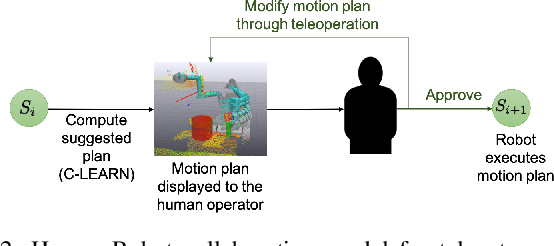

Remote robot manipulation with human control enables applications where safety and environmental constraints are adverse to humans (e.g. underwater, space robotics and disaster response) or the complexity of the task demands human-level cognition and dexterity (e.g. robotic surgery and manufacturing). These systems typically use direct teleoperation at the motion level, and are usually limited to low-DOF arms and 2D perception. Improving dexterity and situational awareness demands new interaction and planning workflows. We explore the use of human-robot teaming through teleautonomy with assisted planning for remote control of a dual-arm dexterous robot for multi-step manipulation tasks, and conduct a within-subjects experimental assessment (n=12 expert users) to compare it with other methods, resulting in the following four conditions: (A) Direct teleoperation with imitation controller + 2D perception, (B) Condition A + 3D perception, (C) Teleautonomy interface teleoperation + 2D & 3D perception, (D) Condition C + assisted planning. The results indicate that this approach (D) achieves task times comparable with direct teleoperation (A,B) while improving a number of other objective and subjective metrics, including re-grasps, collisions, and TLX workload metrics. When compared to a similar interface but removing the assisted planning (C), D reduces the task time and removes a significant interaction with the level of expertise of the operator, resulting in a performance equalizer across users.
An efficient representation of chronological events in medical texts
Oct 24, 2020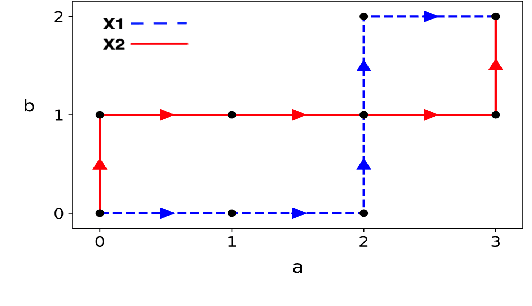
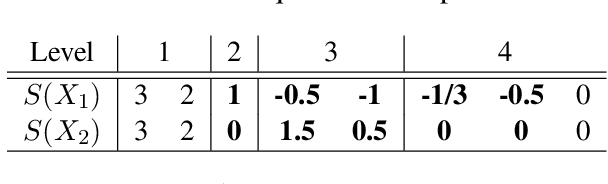

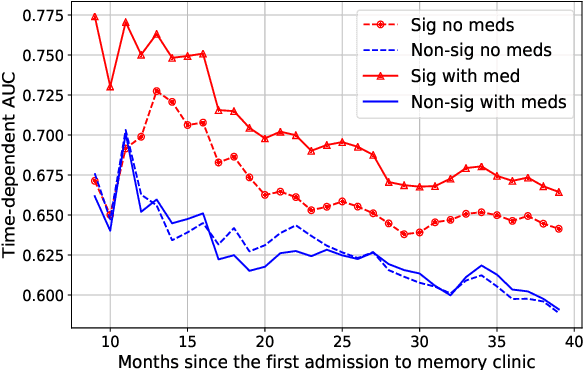
In this work we addressed the problem of capturing sequential information contained in longitudinal electronic health records (EHRs). Clinical notes, which is a particular type of EHR data, are a rich source of information and practitioners often develop clever solutions how to maximise the sequential information contained in free-texts. We proposed a systematic methodology for learning from chronological events available in clinical notes. The proposed methodological {\it path signature} framework creates a non-parametric hierarchical representation of sequential events of any type and can be used as features for downstream statistical learning tasks. The methodology was developed and externally validated using the largest in the UK secondary care mental health EHR data on a specific task of predicting survival risk of patients diagnosed with Alzheimer's disease. The signature-based model was compared to a common survival random forest model. Our results showed a 15.4$\%$ increase of risk prediction AUC at the time point of 20 months after the first admission to a specialist memory clinic and the signature method outperformed the baseline mixed-effects model by 13.2 $\%$.