 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On the Feasibility of Real-Time 3D Hand Tracking using Edge GPGPU Acceleration
Apr 30, 2018


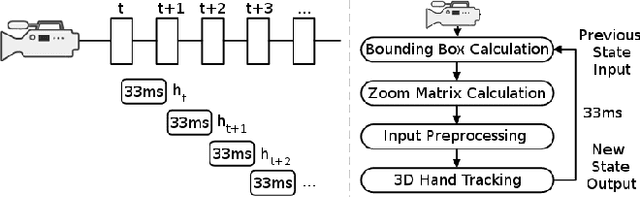
This paper presents the case study of a non-intrusive porting of a monolithic C++ library for real-time 3D hand tracking, to the domain of edge-based computation. Towards a proof of concept, the case study considers a pair of workstations, a computationally powerful and a computationally weak one. By wrapping the C++ library in Java container and by capitalizing on a Java-based offloading infrastructure that supports both CPU and GPGPU computations, we are able to establish automatically the required server-client workflow that best addresses the resource allocation problem in the effort to execute from the weak workstation. As a result, the weak workstation can perform well at the task, despite lacking the sufficient hardware to do the required computations locally. This is achieved by offloading computations which rely on GPGPU, to the powerful workstation, across the network that connects them. We show the edge-based computation challenges associated with the information flow of the ported algorithm, demonstrate how we cope with them, and identify what needs to be improved for achieving even better performance.
Scattering Transform Based Image Clustering using Projection onto Orthogonal Complement
Nov 23, 2020

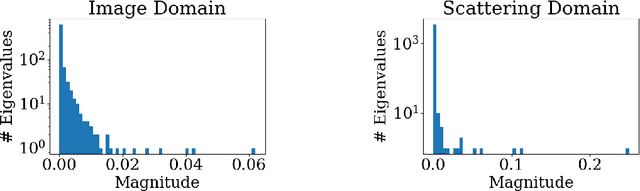
In the last few years, large improvements in image clustering have been driven by the recent advances in deep learning. However, due to the architectural complexity of deep neural networks, there is no mathematical theory that explains the success of deep clustering techniques. In this work we introduce Projected-Scattering Spectral Clustering (PSSC), a state-of-the-art, stable, and fast algorithm for image clustering, which is also mathematically interpretable. PSSC includes a novel method to exploit the geometric structure of the scattering transform of small images. This method is inspired by the observation that, in the scattering transform domain, the subspaces formed by the eigenvectors corresponding to the few largest eigenvalues of the data matrices of individual classes are nearly shared among different classes. Therefore, projecting out those shared subspaces reduces the intra-class variability, substantially increasing the clustering performance. We call this method Projection onto Orthogonal Complement (POC). Our experiments demonstrate that PSSC obtains the best results among all shallow clustering algorithms. Moreover, it achieves comparable clustering performance to that of recent state-of-the-art clustering techniques, while reducing the execution time by more than one order of magnitude. In the spirit of reproducible research, we publish a high quality code repository along with the paper.
Treebank Embedding Vectors for Out-of-domain Dependency Parsing
May 02, 2020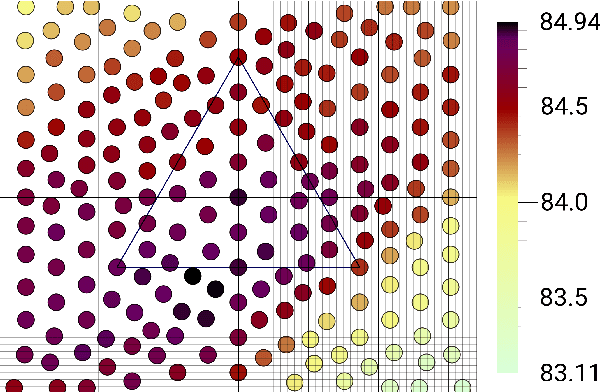
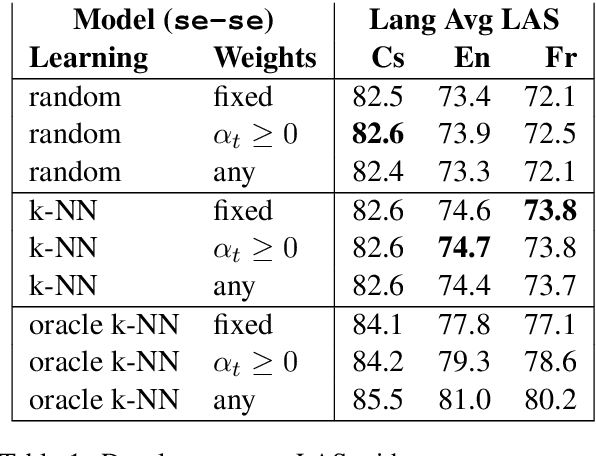
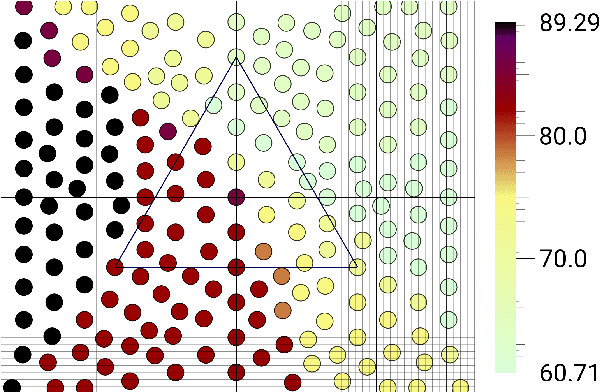
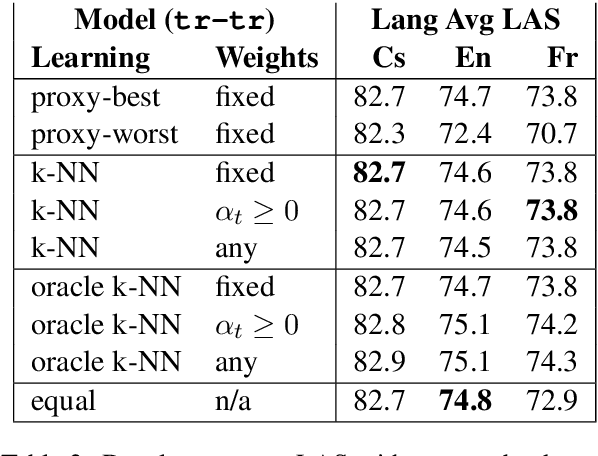
A recent advance in monolingual dependency parsing is the idea of a treebank embedding vector, which allows all treebanks for a particular language to be used as training data while at the same time allowing the model to prefer training data from one treebank over others and to select the preferred treebank at test time. We build on this idea by 1) introducing a method to predict a treebank vector for sentences that do not come from a treebank used in training, and 2) exploring what happens when we move away from predefined treebank embedding vectors during test time and instead devise tailored interpolations. We show that 1) there are interpolated vectors that are superior to the predefined ones, and 2) treebank vectors can be predicted with sufficient accuracy, for nine out of ten test languages, to match the performance of an oracle approach that knows the most suitable predefined treebank embedding for the test set.
CoT-AMFlow: Adaptive Modulation Network with Co-Teaching Strategy for Unsupervised Optical Flow Estimation
Nov 04, 2020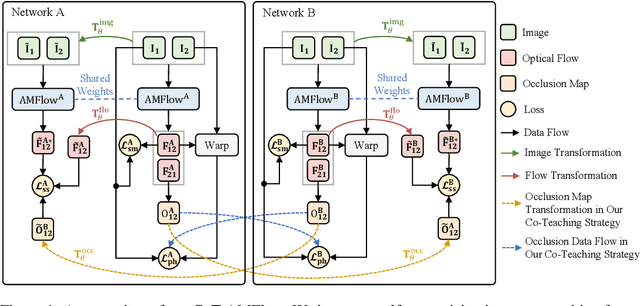
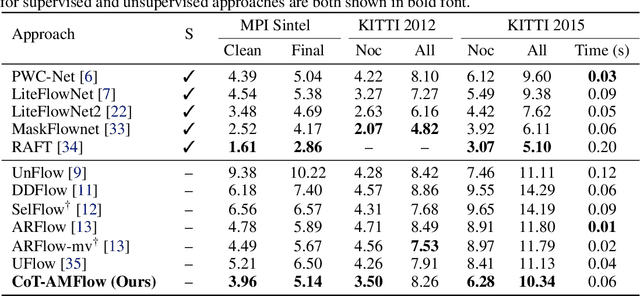
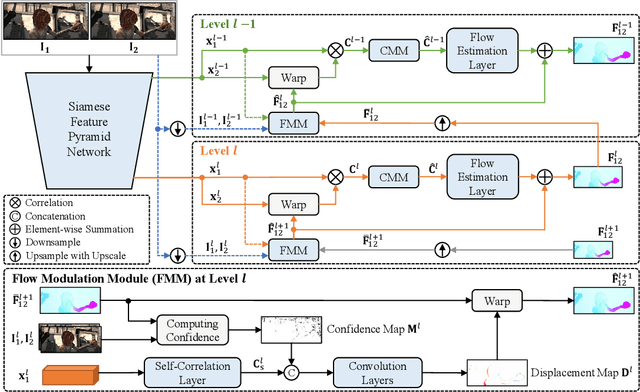

The interpretation of ego motion and scene change is a fundamental task for mobile robots. Optical flow information can be employed to estimate motion in the surroundings. Recently, unsupervised optical flow estimation has become a research hotspot. However, unsupervised approaches are often easy to be unreliable on partially occluded or texture-less regions. To deal with this problem, we propose CoT-AMFlow in this paper, an unsupervised optical flow estimation approach. In terms of the network architecture, we develop an adaptive modulation network that employs two novel module types, flow modulation modules (FMMs) and cost volume modulation modules (CMMs), to remove outliers in challenging regions. As for the training paradigm, we adopt a co-teaching strategy, where two networks simultaneously teach each other about challenging regions to further improve accuracy. Experimental results on the MPI Sintel, KITTI Flow and Middlebury Flow benchmarks demonstrate that our CoT-AMFlow outperforms all other state-of-the-art unsupervised approaches, while still running in real time. Our project page is available at https://sites.google.com/view/cot-amflow.
RobustPointSet: A Dataset for Benchmarking Robustness of Point Cloud Classifiers
Nov 23, 2020
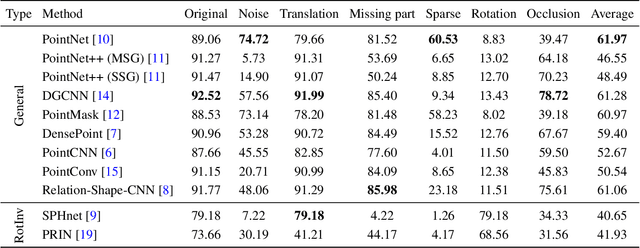

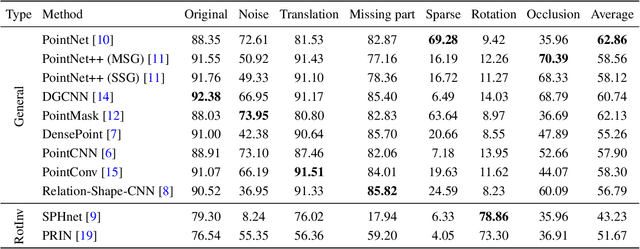
The 3D deep learning community has seen significant strides in pointcloud processing over the last few years. However, the datasets on which deep models have been trained have largely remained the same. Most datasets comprise clean, clutter-free pointclouds canonicalized for pose. Models trained on these datasets fail in uninterpretible and unintuitive ways when presented with data that contains transformations "unseen" at train time. While data augmentation enables models to be robust to "previously seen" input transformations, 1) we show that this does not work for unseen transformations during inference, and 2) data augmentation makes it difficult to analyze a model's inherent robustness to transformations. To this end, we create a publicly available dataset for robustness analysis of point cloud classification models (independent of data augmentation) to input transformations, called \textbf{RobustPointSet}. Our experiments indicate that despite all the progress in the point cloud classification, PointNet (the very first multi-layered perceptron-based approach) outperforms other methods (e.g., graph and neighbor based methods) when evaluated on transformed test sets. We also find that most of the current point cloud models are not robust to unseen transformations even if they are trained with extensive data augmentation. RobustPointSet can be accessed through https://github.com/AutodeskAILab/RobustPointSet.
Inverse Dynamics vs. Forward Dynamics in Direct Transcription Formulations for Trajectory Optimization
Oct 11, 2020

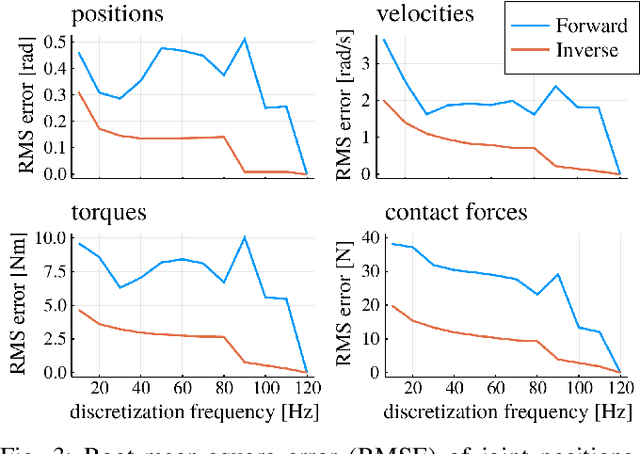

Benchmarks of state-of-the-art rigid-body dynamics libraries have reported better performance for solving the inverse dynamics problem than the forward alternative. Those benchmarks encouraged us to question whether this computational advantage translates to direct transcription formulations, where calculating the rigid-body dynamics and their derivatives often accounts for a significant share of computation time. In this work, we implement an optimization framework where both approaches for enforcing the system dynamics are available. We evaluate the performance of each approach for systems of varying complexity, and for domains with rigid contacts. Our tests revealed that formulations employing inverse dynamics converge faster, require less iterations, and are more robust to coarse problem discretization. These results suggest that inverse dynamics should be the preferred approach to enforce nonlinear system dynamics in simultaneous methods, such as direct transcription.
A Knowledge-Driven Approach to Classifying Object and Attribute Coreferences in Opinion Mining
Oct 11, 2020
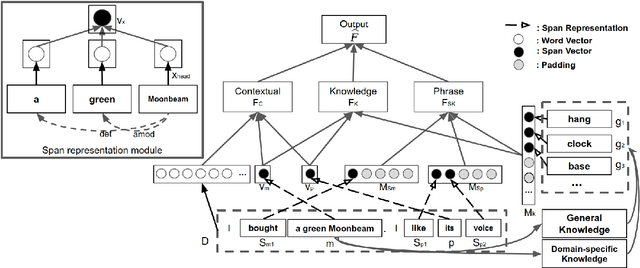

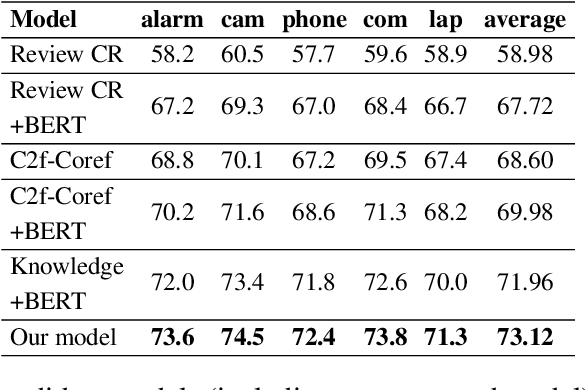
Classifying and resolving coreferences of objects (e.g., product names) and attributes (e.g., product aspects) in opinionated reviews is crucial for improving the opinion mining performance. However, the task is challenging as one often needs to consider domain-specific knowledge (e.g., iPad is a tablet and has aspect resolution) to identify coreferences in opinionated reviews. Also, compiling a handcrafted and curated domain-specific knowledge base for each domain is very time consuming and arduous. This paper proposes an approach to automatically mine and leverage domain-specific knowledge for classifying objects and attribute coreferences. The approach extracts domain-specific knowledge from unlabeled review data and trains a knowledgeaware neural coreference classification model to leverage (useful) domain knowledge together with general commonsense knowledge for the task. Experimental evaluation on realworld datasets involving five domains (product types) shows the effectiveness of the approach.
Deep Image Compositing
Nov 04, 2020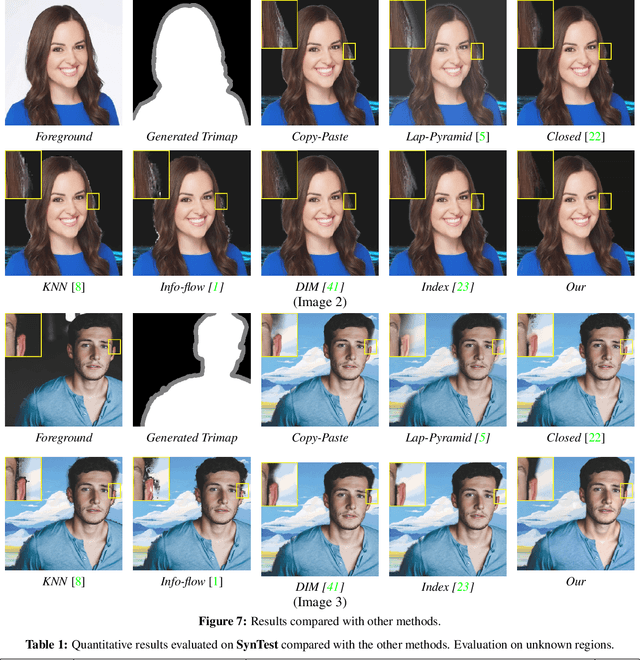

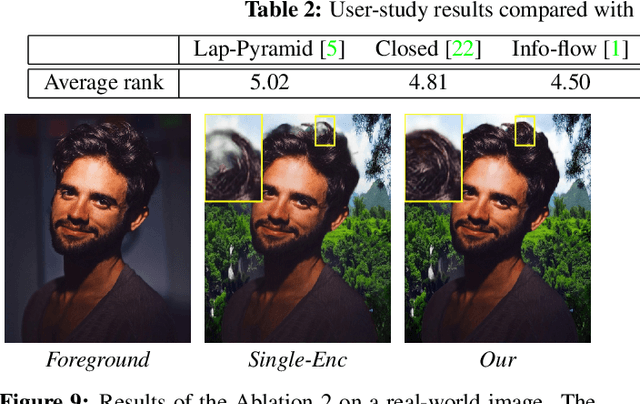
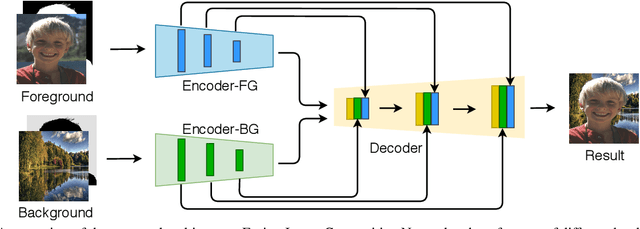
Image compositing is a task of combining regions from different images to compose a new image. A common use case is background replacement of portrait images. To obtain high quality composites, professionals typically manually perform multiple editing steps such as segmentation, matting and foreground color decontamination, which is very time consuming even with sophisticated photo editing tools. In this paper, we propose a new method which can automatically generate high-quality image compositing without any user input. Our method can be trained end-to-end to optimize exploitation of contextual and color information of both foreground and background images, where the compositing quality is considered in the optimization. Specifically, inspired by Laplacian pyramid blending, a dense-connected multi-stream fusion network is proposed to effectively fuse the information from the foreground and background images at different scales. In addition, we introduce a self-taught strategy to progressively train from easy to complex cases to mitigate the lack of training data. Experiments show that the proposed method can automatically generate high-quality composites and outperforms existing methods both qualitatively and quantitatively.
Online Service Migration in Edge Computing with Incomplete Information: A Deep Recurrent Actor-Critic Method
Dec 17, 2020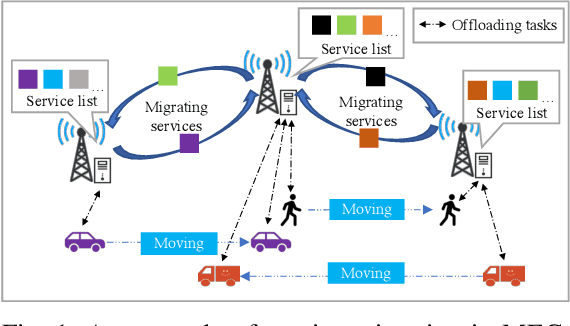
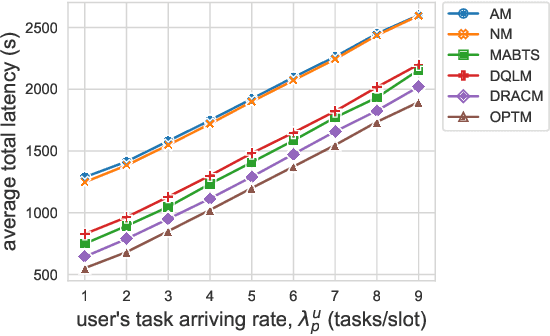
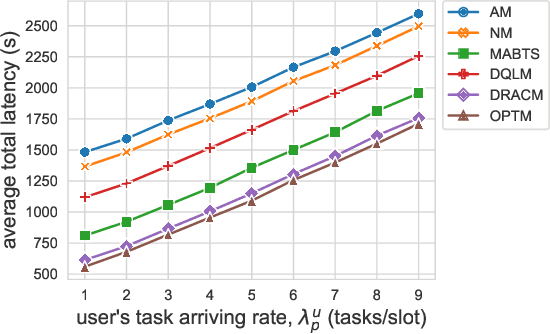
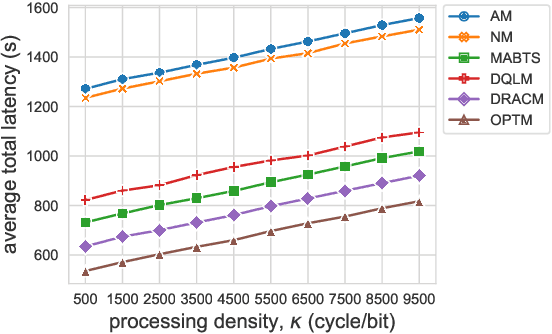
Multi-access Edge Computing (MEC) is a key technology in the fifth-generation (5G) network and beyond. MEC extends cloud computing to the network edge (e.g., base stations, MEC servers) to support emerging resource-intensive applications on mobile devices. As a crucial problem in MEC, service migration needs to decide where to migrate user services for maintaining high Quality-of-Service (QoS), when users roam between MEC servers with limited coverage and capacity. However, finding an optimal migration policy is intractable due to the highly dynamic MEC environment and user mobility. Many existing works make centralized migration decisions based on complete system-level information, which can be time-consuming and suffer from the scalability issue with the rapidly increasing number of mobile users. To address these challenges, we propose a new learning-driven method, namely Deep Recurrent Actor-Critic based service Migration (DRACM), which is user-centric and can make effective online migration decisions given incomplete system-level information. Specifically, the service migration problem is modeled as a Partially Observable Markov Decision Process (POMDP). To solve the POMDP, we design an encoder network that combines a Long Short-Term Memory (LSTM) and an embedding matrix for effective extraction of hidden information. We then propose a tailored off-policy actor-critic algorithm with a clipped surrogate objective for efficient training. Results from extensive experiments based on real-world mobility traces demonstrate that our method consistently outperforms both the heuristic and state-of-the-art learning-driven algorithms, and achieves near-optimal results on various MEC scenarios.
Parsimonious neural networks learn classical mechanics and can teach it
May 08, 2020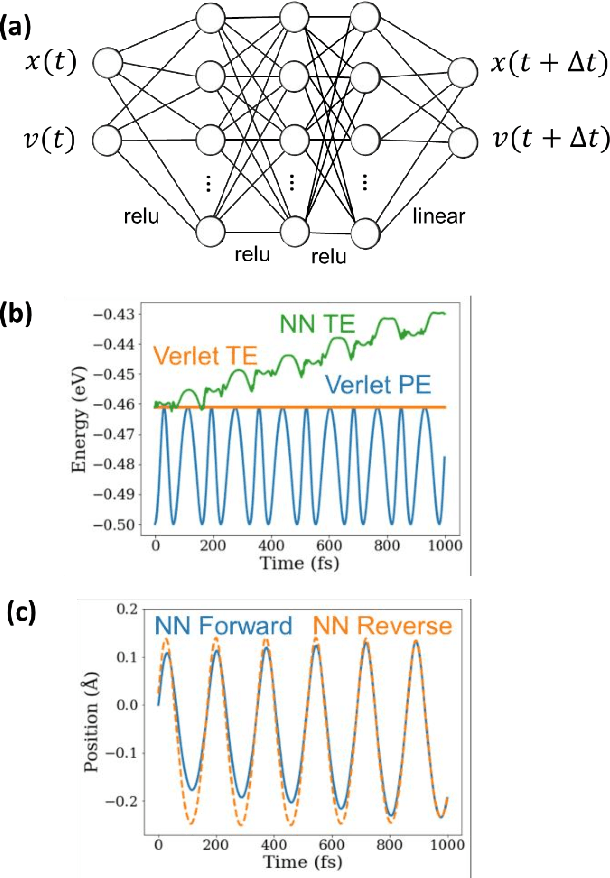
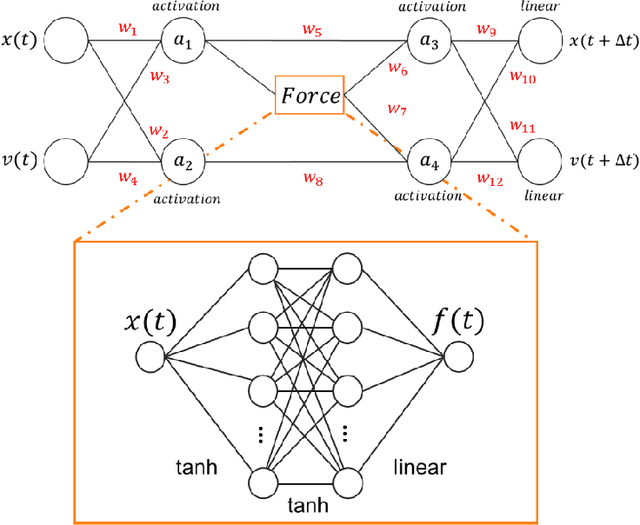
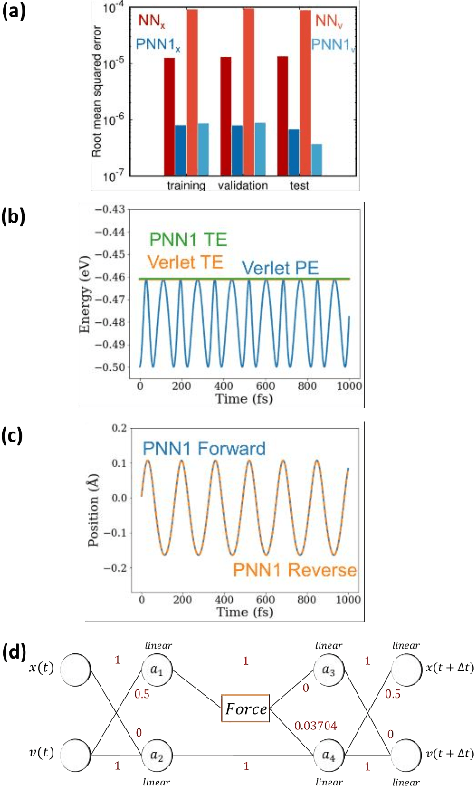
We combine neural networks with genetic algorithms to find parsimonious models that describe the time evolution of a point particle subjected to an external potential. The genetic algorithm is designed to find the simplest, most interpretable network compatible with the training data. The parsimonious neural network (PNN) can numerically integrate classical equations of motion with negligible energy drifts and good time reversibility, significantly outperforming a generic feed-forward neural network. Our PNN is immediately interpretable as the position Verlet algorithm, a non-trivial integrator whose justification originates from Trotter's theorem.