 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MorphEyes: Variable Baseline Stereo For Quadrotor Navigation
Nov 05, 2020

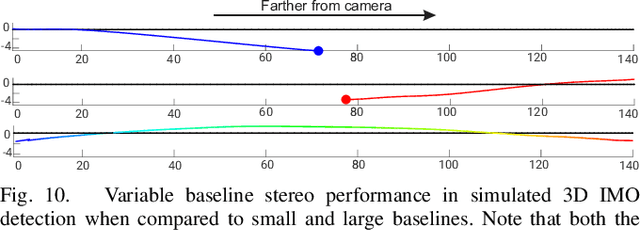
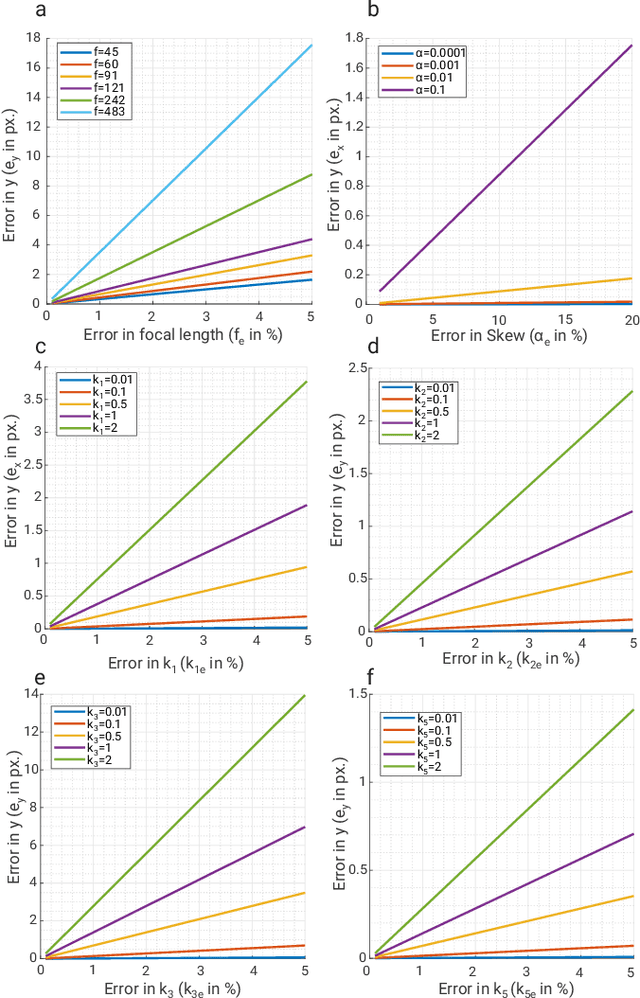
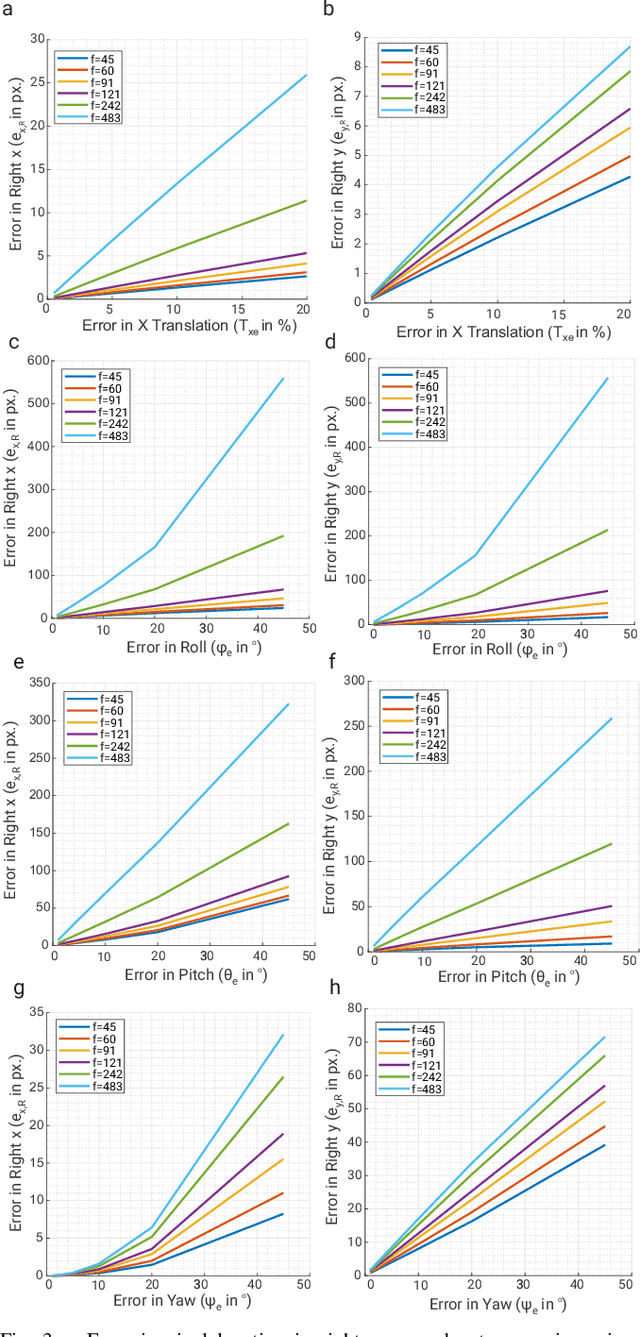
Morphable design and depth-based visual control are two upcoming trends leading to advancements in the field of quadrotor autonomy. Stereo-cameras have struck the perfect balance of weight and accuracy of depth estimation but suffer from the problem of depth range being limited and dictated by the baseline chosen at design time. In this paper, we present a framework for quadrotor navigation based on a stereo camera system whose baseline can be adapted on-the-fly. We present a method to calibrate the system at a small number of discrete baselines and interpolate the parameters for the entire baseline range. We present an extensive theoretical analysis of calibration and synchronization errors. We showcase three different applications of such a system for quadrotor navigation: (a) flying through a forest, (b) flying through an unknown shaped/location static/dynamic gap, and (c) accurate 3D pose detection of an independently moving object. We show that our variable baseline system is more accurate and robust in all three scenarios. To our knowledge, this is the first work that applies the concept of morphable design to achieve a variable baseline stereo vision system on a quadrotor.
On Two-Handed Planar Assembly Partitioning
Sep 25, 2020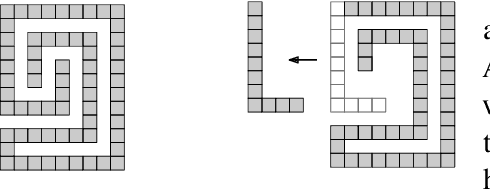
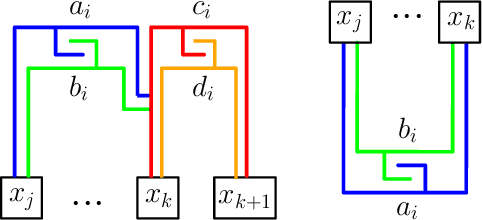
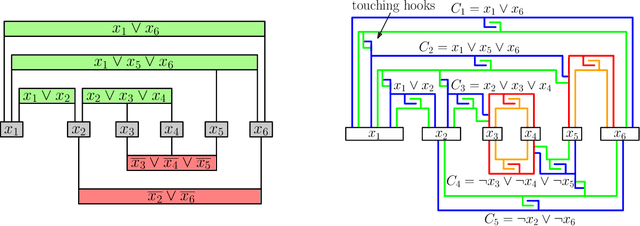
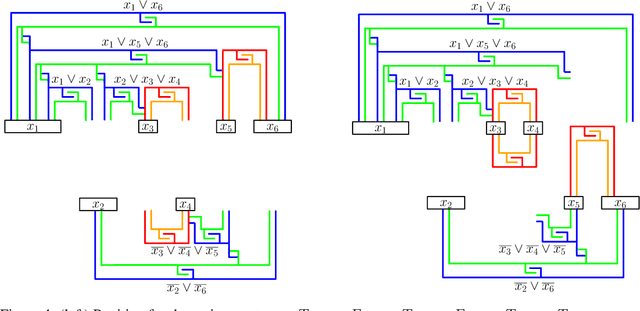
Assembly planning, which is a fundamental problem in robotics and automation, aims to design a sequence of motions that will bring the separate constituent parts of a product into their final placement in the product. It is convenient to study assembly planning in reverse order, where the following key problem, assembly partitioning, arises: Given a set of parts in their final placement in a product, partition them into two sets, each regarded as a rigid body, which we call a subassembly, such that these two subassemblies can be moved sufficiently far away from each other, without colliding with one another. The basic assembly planning problem is further complicated by practical consideration such as how to hold the parts in a subassembly together. Therefore, a desired property of a valid assembly partition is that each of the two subassemblies will be connected. We show that even an utterly simple case of the connected-assembly-partitioning problem is hard: Given a connected set $A$ of unit squares in the plane, each forming a distinct cell of the uniform integer grid, find a subset $S\subset A$ such that $S$ can be rigidly translated to infinity along a prescribed direction without colliding with $A\setminus S$, and both subassemblies $S$ and $A\setminus S$ are each connected. We show that this problem is NP-Complete, and by that settle an open problem posed by Wilson et al. (1995) a quarter of a century ago. We complement the hardness result with two positive results for the aforementioned problem variant of grid squares. First, we show that it is fixed parameter tractable and give an $O(2^k n^2)$-time algorithm, where $n=|A|$ and $k=|S|$. Second, we describe a special case of this variant where a connected partition can always be found in linear time. Each of the positive results sheds further light on the special geometric structure of the problem at hand.
Exploiting Neural Query Translation into Cross Lingual Information Retrieval
Oct 26, 2020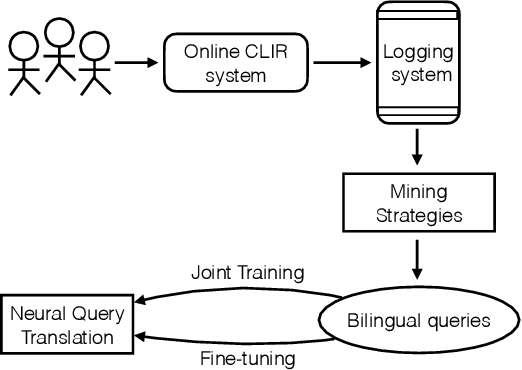
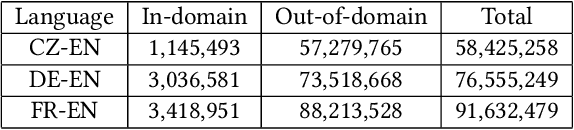
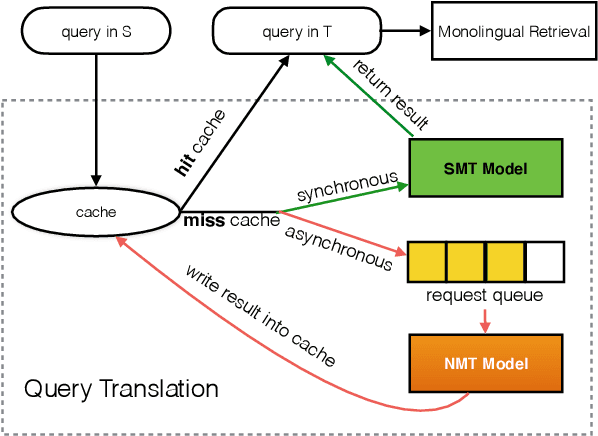

As a crucial role in cross-language information retrieval (CLIR), query translation has three main challenges: 1) the adequacy of translation; 2) the lack of in-domain parallel training data; and 3) the requisite of low latency. To this end, existing CLIR systems mainly exploit statistical-based machine translation (SMT) rather than the advanced neural machine translation (NMT), limiting the further improvements on both translation and retrieval quality. In this paper, we investigate how to exploit neural query translation model into CLIR system. Specifically, we propose a novel data augmentation method that extracts query translation pairs according to user clickthrough data, thus to alleviate the problem of domain-adaptation in NMT. Then, we introduce an asynchronous strategy which is able to leverage the advantages of the real-time in SMT and the veracity in NMT. Experimental results reveal that the proposed approach yields better retrieval quality than strong baselines and can be well applied into a real-world CLIR system, i.e. Aliexpress e-Commerce search engine. Readers can examine and test their cases on our website: https://aliexpress.com .
Theory and Algorithms for Shapelet-based Multiple-Instance Learning
Jun 12, 2020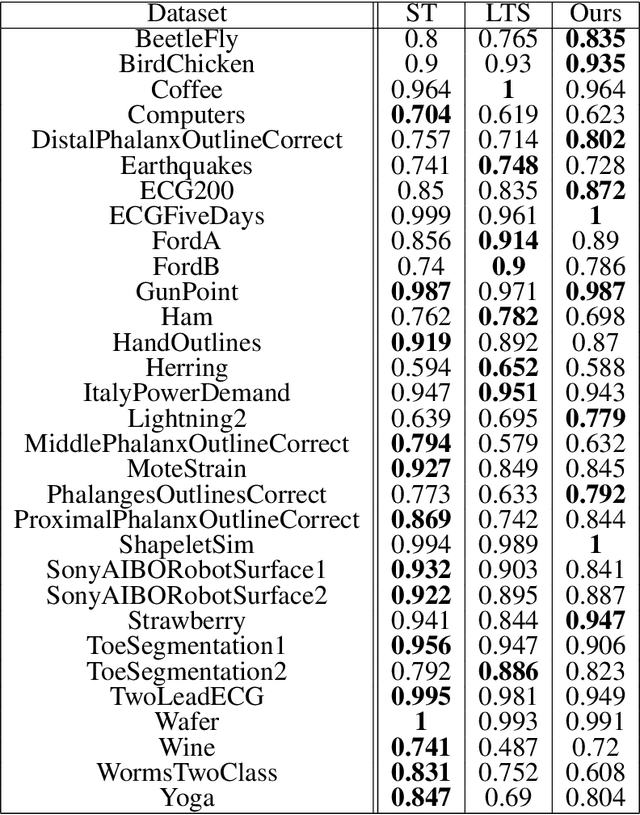
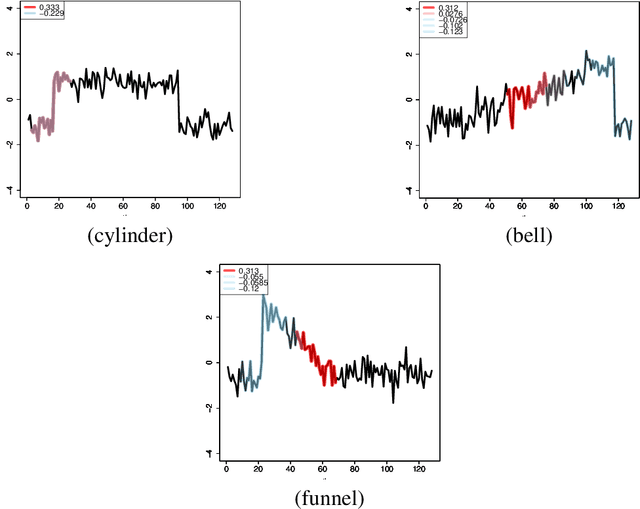
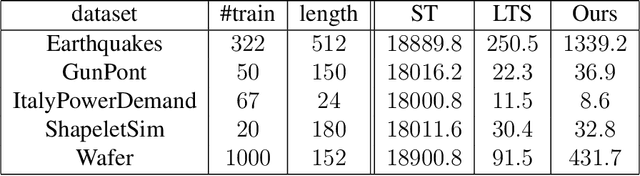
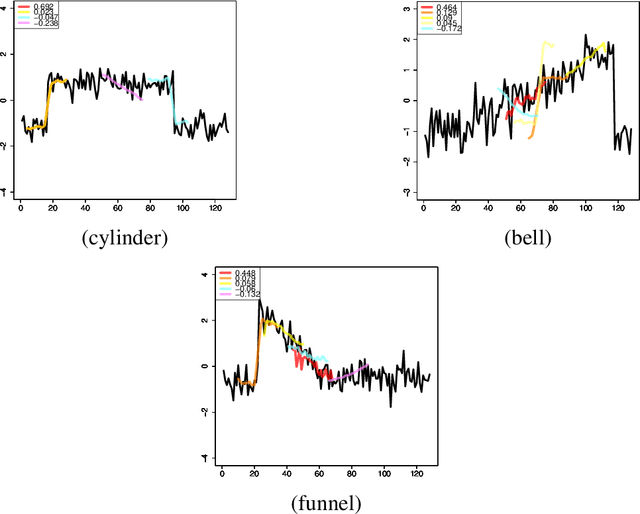
We propose a new formulation of Multiple-Instance Learning (MIL), in which a unit of data consists of a set of instances called a bag. The goal is to find a good classifier of bags based on the similarity with a "shapelet" (or pattern), where the similarity of a bag with a shapelet is the maximum similarity of instances in the bag. In previous work, some of the training instances are chosen as shapelets with no theoretical justification. In our formulation, we use all possible, and thus infinitely many shapelets, resulting in a richer class of classifiers. We show that the formulation is tractable, that is, it can be reduced through Linear Programming Boosting (LPBoost) to Difference of Convex (DC) programs of finite (actually polynomial) size. Our theoretical result also gives justification to the heuristics of some of the previous work. The time complexity of the proposed algorithm highly depends on the size of the set of all instances in the training sample. To apply to the data containing a large number of instances, we also propose a heuristic option of the algorithm without the loss of the theoretical guarantee. Our empirical study demonstrates that our algorithm uniformly works for Shapelet Learning tasks on time-series classification and various MIL tasks with comparable accuracy to the existing methods. Moreover, we show that the proposed heuristics allow us to achieve the result with reasonable computational time.
Multi-Agent Coverage in Urban Environments
Aug 17, 2020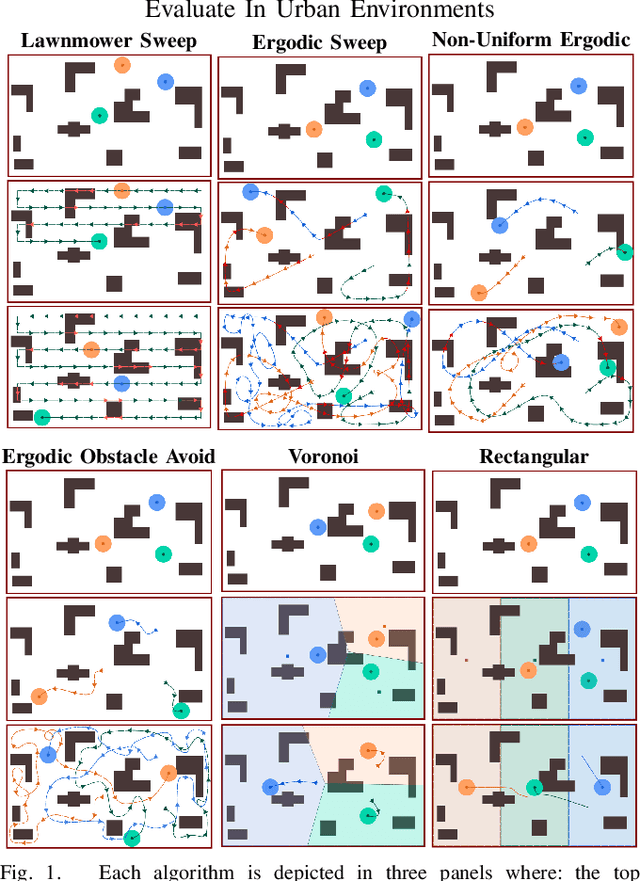
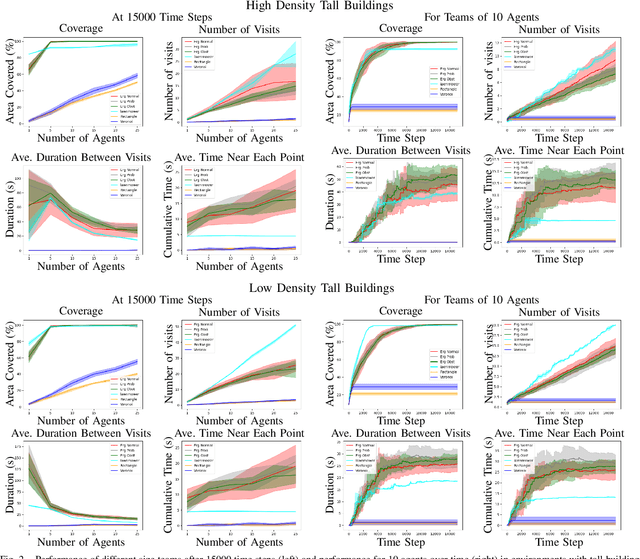
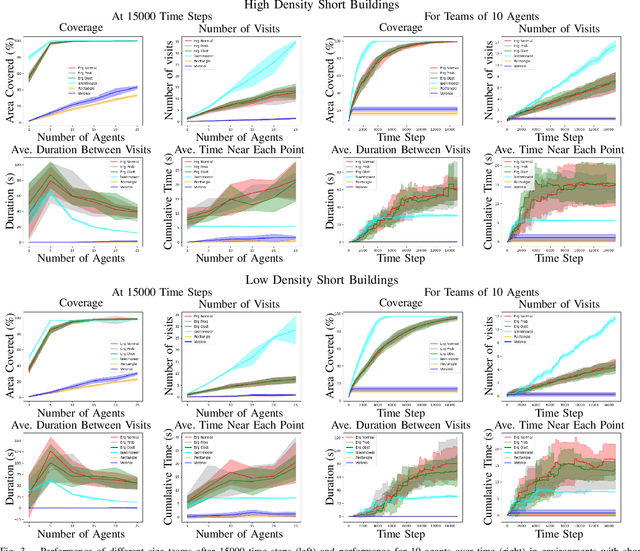
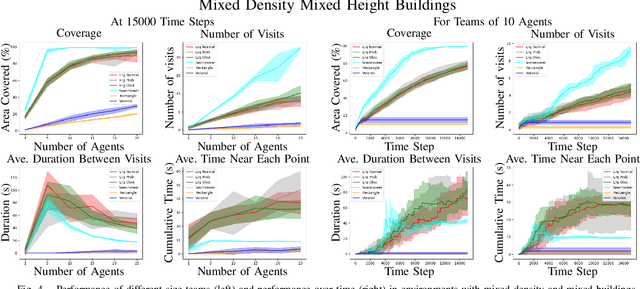
We study multi-agent coverage algorithms for autonomous monitoring and patrol in urban environments. We consider scenarios in which a team of flying agents uses downward facing cameras (or similar sensors) to observe the environment outside of buildings at street-level. Buildings are considered obstacles that impede movement, and cameras are assumed to be ineffective above a maximum altitude. We study multi-agent urban coverage problems related to this scenario, including: (1) static multi-agent urban coverage, in which agents are expected to observe the environment from static locations, and (2) dynamic multi-agent urban coverage where agents move continuously through the environment. We experimentally evaluate six different multi-agent coverage methods, including: three types of ergodic coverage (that avoid buildings in different ways), lawn-mower sweep, voronoi region based control, and a naive grid method. We evaluate all algorithms with respect to four performance metrics (percent coverage, revist count, revist time, and the integral of area viewed over time), across four types of urban environments [low density, high density] x [short buildings, tall buildings], and for team sizes ranging from 2 to 25 agents. We believe this is the first extensive comparison of these methods in an urban setting. Our results highlight how the relative performance of static and dynamic methods changes based on the ratio of team size to search area, as well the relative effects that different characteristics of urban environments (tall, short, dense, sparse, mixed) have on each algorithm.
Deep Learning Based Classification of Unsegmented Phonocardiogram Spectrograms Leveraging Transfer Learning
Dec 15, 2020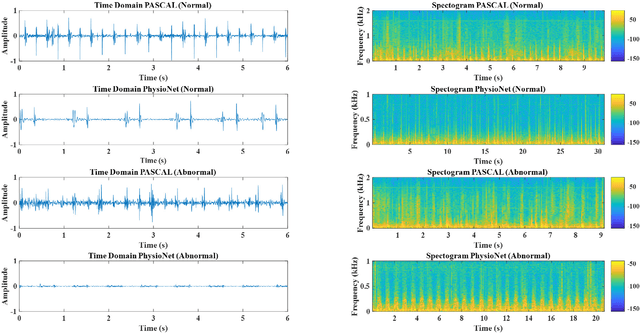
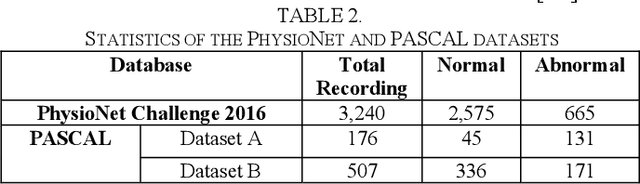
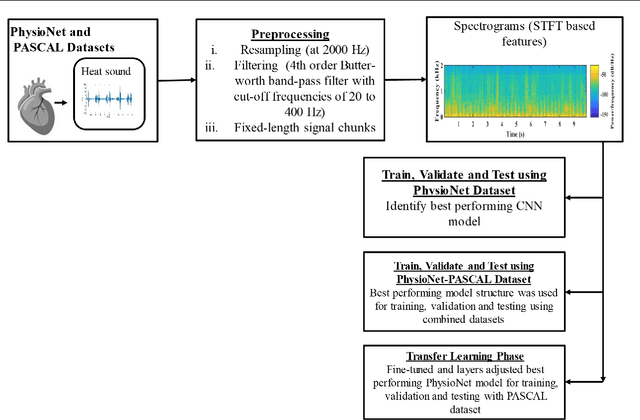
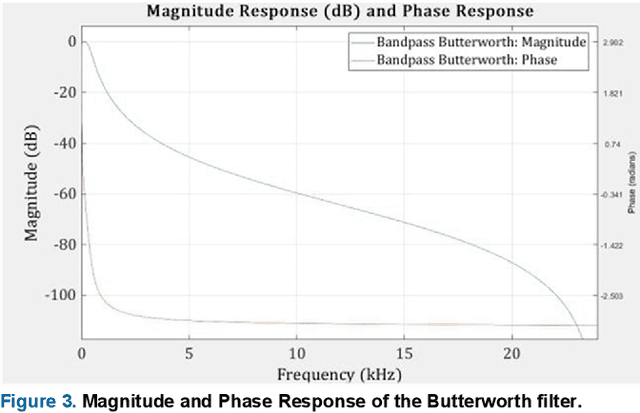
Cardiovascular diseases (CVDs) are the main cause of deaths all over the world. Heart murmurs are the most common abnormalities detected during the auscultation process. The two widely used publicly available phonocardiogram (PCG) datasets are from the PhysioNet/CinC (2016) and PASCAL (2011) challenges. The datasets are significantly different in terms of the tools used for data acquisition, clinical protocols, digital storages and signal qualities, making it challenging to process and analyze. In this work, we have used short-time Fourier transform (STFT) based spectrograms to learn the representative patterns of the normal and abnormal PCG signals. Spectrograms generated from both the datasets are utilized to perform three different studies: (i) train, validate and test different variants of convolutional neural network (CNN) models with PhysioNet dataset, (ii) train, validate and test the best performing CNN structure on combined PhysioNet-PASCAL dataset and (iii) finally, transfer learning technique is employed to train the best performing pre-trained network from the first study with PASCAL dataset. We propose a novel, less complex and relatively light custom CNN model for the classification of PhysioNet, combined and PASCAL datasets. The first study achieves an accuracy, sensitivity, specificity, precision and F1 score of 95.4%, 96.3%, 92.4%, 97.6% and 96.98% respectively while the second study shows accuracy, sensitivity, specificity, precision and F1 score of 94.2%, 95.5%, 90.3%, 96.8% and 96.1% respectively. Finally, the third study shows a precision of 98.29% on the noisy PASCAL dataset with transfer learning approach. All the three proposed approaches outperform most of the recent competing studies by achieving comparatively high classification accuracy and precision, which make them suitable for screening CVDs using PCG signals.
Competence-Level Prediction and Resume & Job Description Matching Using Context-Aware Transformer Models
Nov 05, 2020
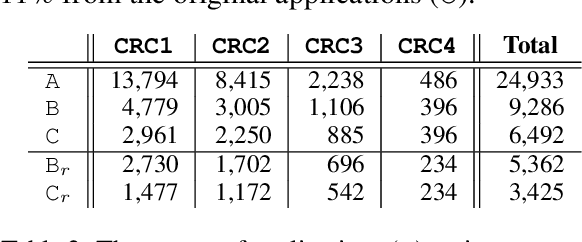
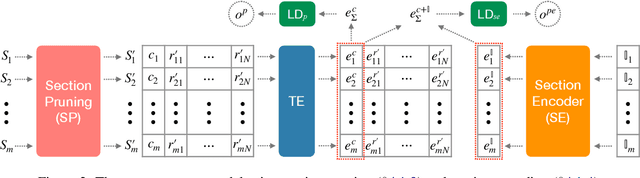
This paper presents a comprehensive study on resume classification to reduce the time and labor needed to screen an overwhelming number of applications significantly, while improving the selection of suitable candidates. A total of 6,492 resumes are extracted from 24,933 job applications for 252 positions designated into four levels of experience for Clinical Research Coordinators (CRC). Each resume is manually annotated to its most appropriate CRC position by experts through several rounds of triple annotation to establish guidelines. As a result, a high Kappa score of 61% is achieved for inter-annotator agreement. Given this dataset, novel transformer-based classification models are developed for two tasks: the first task takes a resume and classifies it to a CRC level (T1), and the second task takes both a resume and a job description to apply and predicts if the application is suited to the job T2. Our best models using section encoding and multi-head attention decoding give results of 73.3% to T1 and 79.2% to T2. Our analysis shows that the prediction errors are mostly made among adjacent CRC levels, which are hard for even experts to distinguish, implying the practical value of our models in real HR platforms.
Simple and optimal methods for stochastic variational inequalities, I: operator extrapolation
Nov 05, 2020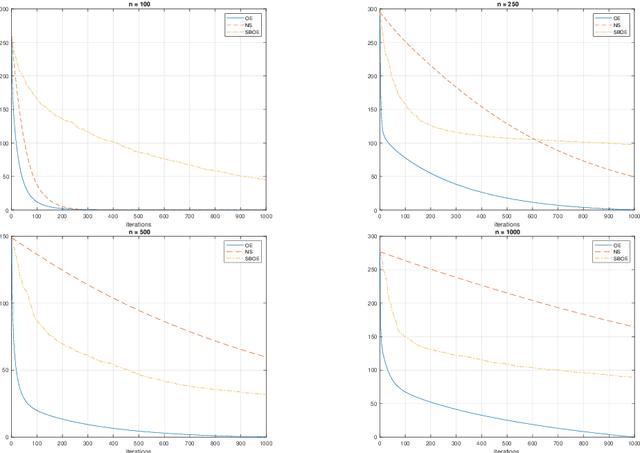
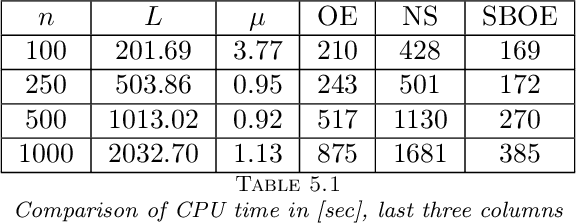

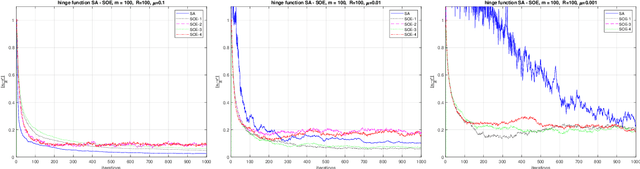
In this paper we first present a novel operator extrapolation (OE) method for solving deterministic variational inequality (VI) problems. Similar to the gradient (operator) projection method, OE updates one single search sequence by solving a single projection subproblem in each iteration. We show that OE can achieve the optimal rate of convergence for solving a variety of VI problems in a much simpler way than existing approaches. We then introduce the stochastic operator extrapolation (SOE) method and establish its optimal convergence behavior for solving different stochastic VI problems. In particular, SOE achieves the optimal complexity for solving a fundamental problem, i.e., stochastic smooth and strongly monotone VI, for the first time in the literature. We also present a stochastic block operator extrapolations (SBOE) method to further reduce the iteration cost for the OE method applied to large-scale deterministic VIs with a certain block structure. Numerical experiments have been conducted to demonstrate the potential advantages of the proposed algorithms. In fact, all these algorithms are applied to solve generalized monotone variational inequality (GMVI) problems whose operator is not necessarily monotone. We will also discuss optimal OE-based policy evaluation methods for reinforcement learning in a companion paper.
KrigHedge: GP Surrogates for Delta Hedging
Oct 26, 2020



We investigate a machine learning approach to option Greeks approximation based on Gaussian process (GP) surrogates. The method takes in noisily observed option prices, fits a nonparametric input-output map and then analytically differentiates the latter to obtain the various price sensitivities. Our motivation is to compute Greeks in cases where direct computation is expensive, such as in local volatility models, or can only ever be done approximately. We provide a detailed analysis of numerous aspects of GP surrogates, including choice of kernel family, simulation design, choice of trend function and impact of noise. We further discuss the application to Delta hedging, including a new Lemma that relates quality of the Delta approximation to discrete-time hedging loss. Results are illustrated with two extensive case studies that consider estimation of Delta, Theta and Gamma and benchmark approximation quality and uncertainty quantification using a variety of statistical metrics. Among our key take-aways are the recommendation to use Matern kernels, the benefit of including virtual training points to capture boundary conditions, and the significant loss of fidelity when training on stock-path-based datasets.
HeteroFL: Computation and Communication Efficient Federated Learning for Heterogeneous Clients
Oct 03, 2020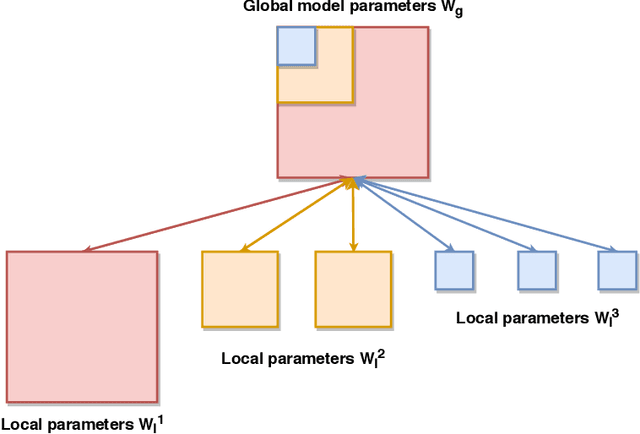
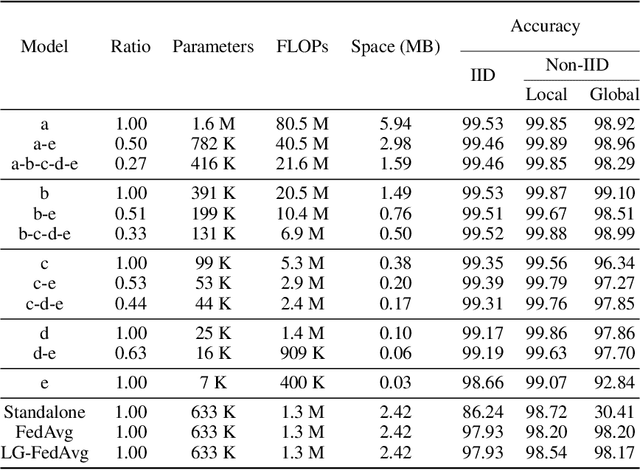
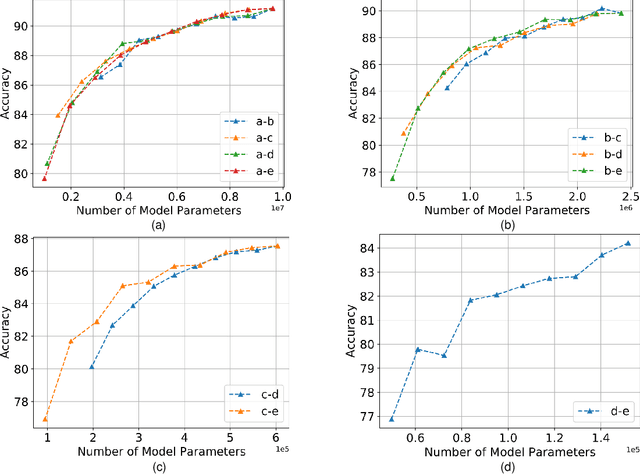
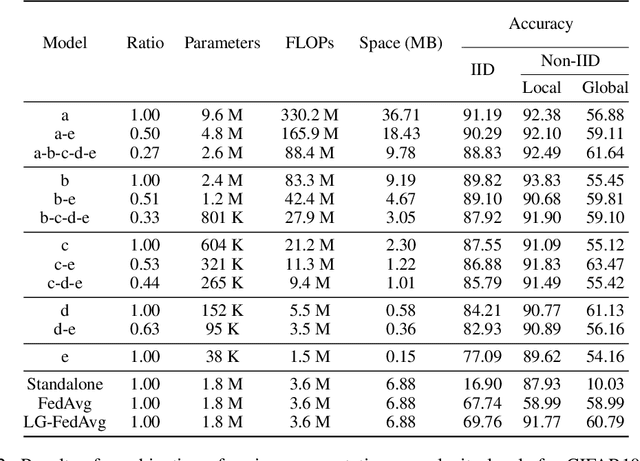
Federated Learning (FL) is a method of training machine learning models on private data distributed over a large number of possibly heterogeneous clients such as mobile phones and IoT devices. In this work, we propose a new federated learning framework named HeteroFL to address heterogeneous clients equipped with very different computation and communication capabilities. Our solution can enable the training of heterogeneous local models with varying computation complexities and still produce a single global inference model. For the first time, our method challenges the underlying assumption of existing work that local models have to share the same architecture as the global model. We demonstrate several strategies to enhance FL training and conduct extensive empirical evaluations, including five computation complexity levels of three model architecture on three datasets. We show that adaptively distributing subnetworks according to clients' capabilities is both computation and communication efficient.