 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LAP-Net: Adaptive Features Sampling via Learning Action Progression for Online Action Detection
Nov 16, 2020
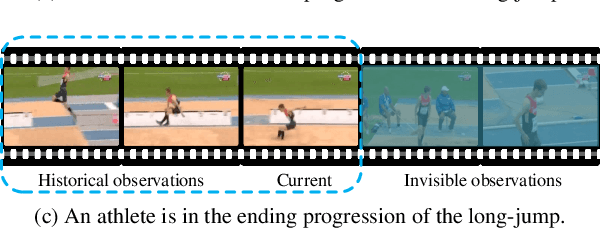

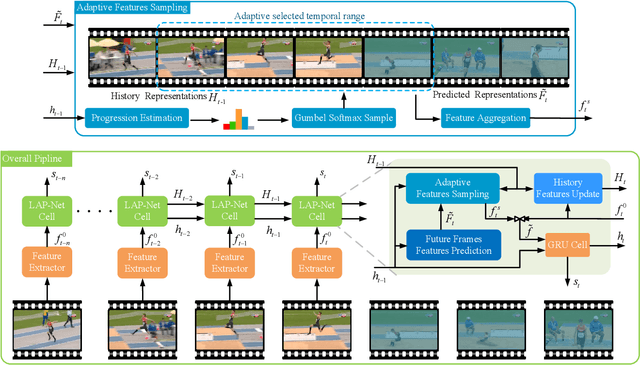

Online action detection is a task with the aim of identifying ongoing actions from streaming videos without any side information or access to future frames. Recent methods proposed to aggregate fixed temporal ranges of invisible but anticipated future frames representations as supplementary features and achieved promising performance. They are based on the observation that human beings often detect ongoing actions by contemplating the future vision simultaneously. However, we observed that at different action progressions, the optimal supplementary features should be obtained from distinct temporal ranges instead of simply fixed future temporal ranges. To this end, we introduce an adaptive features sampling strategy to overcome the mentioned variable-ranges of optimal supplementary features. Specifically, in this paper, we propose a novel Learning Action Progression Network termed LAP-Net, which integrates an adaptive features sampling strategy. At each time step, this sampling strategy first estimates current action progression and then decide what temporal ranges should be used to aggregate the optimal supplementary features. We evaluated our LAP-Net on three benchmark datasets, TVSeries, THUMOS-14 and HDD. The extensive experiments demonstrate that with our adaptive feature sampling strategy, the proposed LAP-Net can significantly outperform current state-of-the-art methods with a large margin.
CoCoPIE: Making Mobile AI Sweet As PIE --Compression-Compilation Co-Design Goes a Long Way
Mar 25, 2020

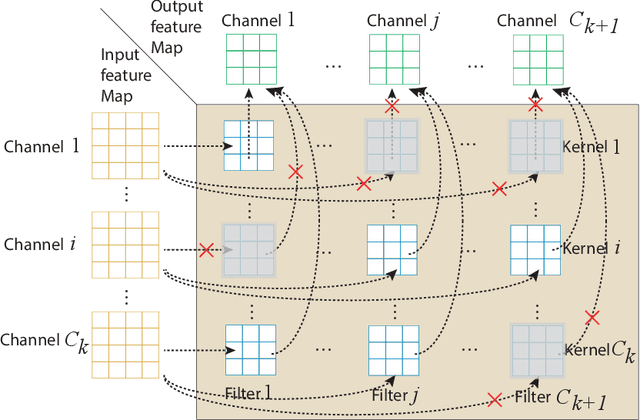
Assuming hardware is the major constraint for enabling real-time mobile intelligence, the industry has mainly dedicated their efforts to developing specialized hardware accelerators for machine learning and inference. This article challenges the assumption. By drawing on a recent real-time AI optimization framework CoCoPIE, it maintains that with effective compression-compiler co-design, it is possible to enable real-time artificial intelligence on mainstream end devices without special hardware. CoCoPIE is a software framework that holds numerous records on mobile AI: the first framework that supports all main kinds of DNNs, from CNNs to RNNs, transformer, language models, and so on; the fastest DNN pruning and acceleration framework, up to 180X faster compared with current DNN pruning on other frameworks such as TensorFlow-Lite; making many representative AI applications able to run in real-time on off-the-shelf mobile devices that have been previously regarded possible only with special hardware support; making off-the-shelf mobile devices outperform a number of representative ASIC and FPGA solutions in terms of energy efficiency and/or performance.
Prostate motion modelling using biomechanically-trained deep neural networks on unstructured nodes
Jul 09, 2020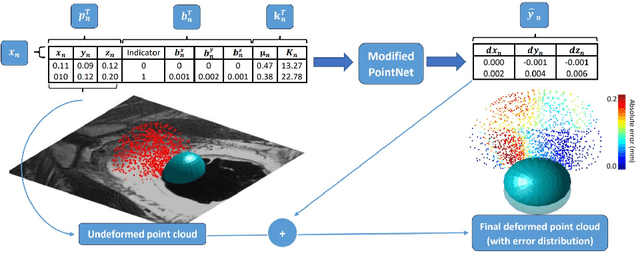
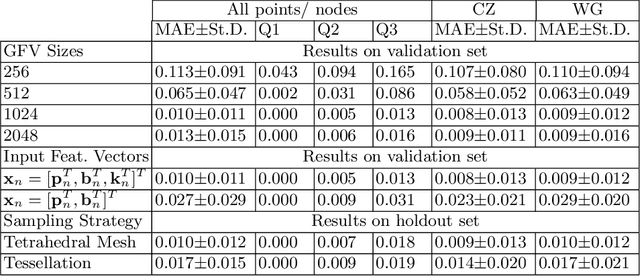
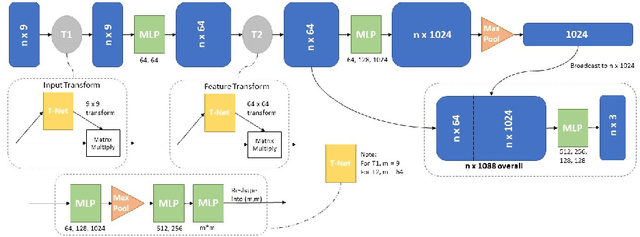
In this paper, we propose to train deep neural networks with biomechanical simulations, to predict the prostate motion encountered during ultrasound-guided interventions. In this application, unstructured points are sampled from segmented pre-operative MR images to represent the anatomical regions of interest. The point sets are then assigned with point-specific material properties and displacement loads, forming the un-ordered input feature vectors. An adapted PointNet can be trained to predict the nodal displacements, using finite element (FE) simulations as ground-truth data. Furthermore, a versatile bootstrap aggregating mechanism is validated to accommodate the variable number of feature vectors due to different patient geometries, comprised of a training-time bootstrap sampling and a model averaging inference. This results in a fast and accurate approximation to the FE solutions without requiring subject-specific solid meshing. Based on 160,000 nonlinear FE simulations on clinical imaging data from 320 patients, we demonstrate that the trained networks generalise to unstructured point sets sampled directly from holdout patient segmentation, yielding a near real-time inference and an expected error of 0.017 mm in predicted nodal displacement.
Solving Mixed Integer Programs Using Neural Networks
Dec 23, 2020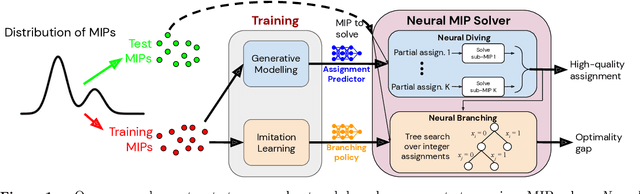
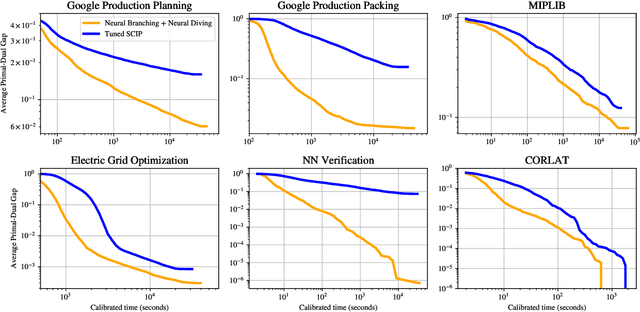
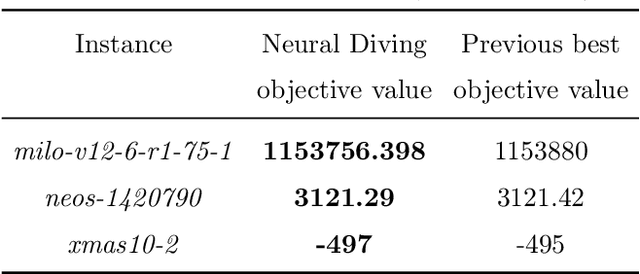
Mixed Integer Programming (MIP) solvers rely on an array of sophisticated heuristics developed with decades of research to solve large-scale MIP instances encountered in practice. Machine learning offers to automatically construct better heuristics from data by exploiting shared structure among instances in the data. This paper applies learning to the two key sub-tasks of a MIP solver, generating a high-quality joint variable assignment, and bounding the gap in objective value between that assignment and an optimal one. Our approach constructs two corresponding neural network-based components, Neural Diving and Neural Branching, to use in a base MIP solver such as SCIP. Neural Diving learns a deep neural network to generate multiple partial assignments for its integer variables, and the resulting smaller MIPs for un-assigned variables are solved with SCIP to construct high quality joint assignments. Neural Branching learns a deep neural network to make variable selection decisions in branch-and-bound to bound the objective value gap with a small tree. This is done by imitating a new variant of Full Strong Branching we propose that scales to large instances using GPUs. We evaluate our approach on six diverse real-world datasets, including two Google production datasets and MIPLIB, by training separate neural networks on each. Most instances in all the datasets combined have $10^3-10^6$ variables and constraints after presolve, which is significantly larger than previous learning approaches. Comparing solvers with respect to primal-dual gap averaged over a held-out set of instances, the learning-augmented SCIP is 2x to 10x better on all datasets except one on which it is $10^5$x better, at large time limits. To the best of our knowledge, ours is the first learning approach to demonstrate such large improvements over SCIP on both large-scale real-world application datasets and MIPLIB.
A Reference Software Architecture for Social Robots
Jul 09, 2020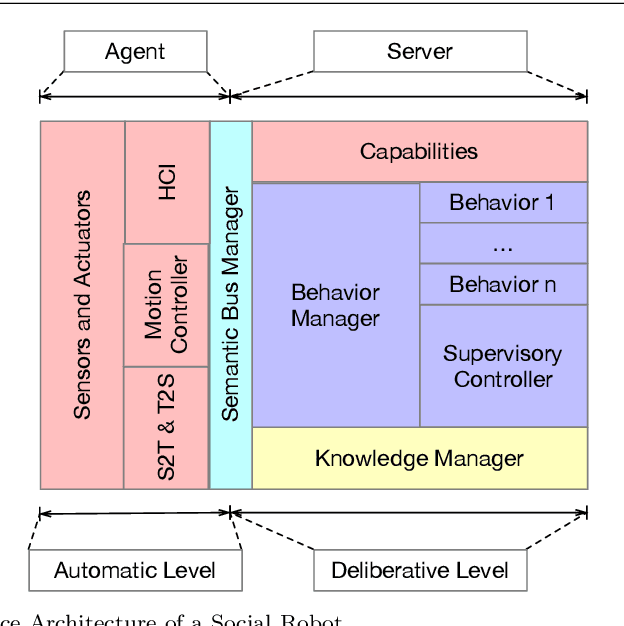
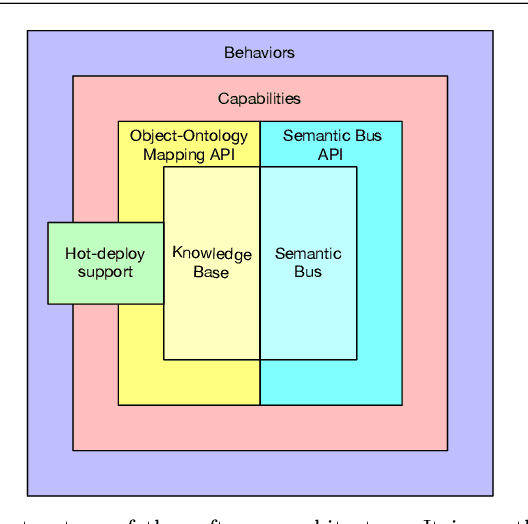
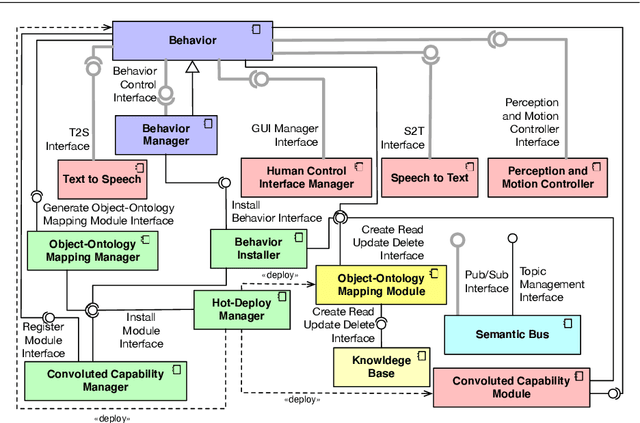
Social Robotics poses tough challenges to software designers who are required to take care of difficult architectural drivers like acceptability, trust of robots as well as to guarantee that robots establish a personalised interaction with their users. Moreover, in this context recurrent software design issues such as ensuring interoperability, improving reusability and customizability of software components also arise. Designing and implementing social robotic software architectures is a time-intensive activity requiring multi-disciplinary expertise: this makes difficult to rapidly develop, customise, and personalise robotic solutions. These challenges may be mitigated at design time by choosing certain architectural styles, implementing specific architectural patterns and using particular technologies. Leveraging on our experience in the MARIO project, in this paper we propose a series of principles that social robots may benefit from. These principles lay also the foundations for the design of a reference software architecture for Social Robots. The ultimate goal of this work is to establish a common ground based on a reference software architecture to allow to easily reuse robotic software components in order to rapidly develop, implement, and personalise Social Robots.
No-Regret Reinforcement Learning with Value Function Approximation: a Kernel Embedding Approach
Nov 16, 2020We consider the regret minimisation problem in reinforcement learning (RL) in the episodic setting. In many real-world RL environments, the state and action spaces are continuous or very large. Existing approaches establish regret guarantees by either a low-dimensional representation of the probability transition model or a functional approximation of Q functions. However, the understanding of function approximation schemes for state value functions largely remains missing. In this paper, we propose an online model-based RL algorithm, namely the CME-RL, that learns representations of transition distributions as embeddings in a reproducing kernel Hilbert space while carefully balancing the exploitation-exploration tradeoff. We demonstrate the efficiency of our algorithm by proving a frequentist (worst-case) regret bound that is of order $\tilde{O}\big(H\gamma_N\sqrt{N}\big)$\footnote{ $\tilde{O}(\cdot)$ hides only absolute constant and poly-logarithmic factors}, where $H$ is the episode length, $N$ is the total number of time steps and $\gamma_N$ is an information theoretic quantity relating the effective dimension of the state-action feature space. Our method bypasses the need for estimating transition probabilities and applies to any domain on which kernels can be defined. It also brings new insights into the general theory of kernel methods for approximate inference and RL regret minimization.
Inter-Homines: Distance-Based Risk Estimation for Human Safety
Jul 20, 2020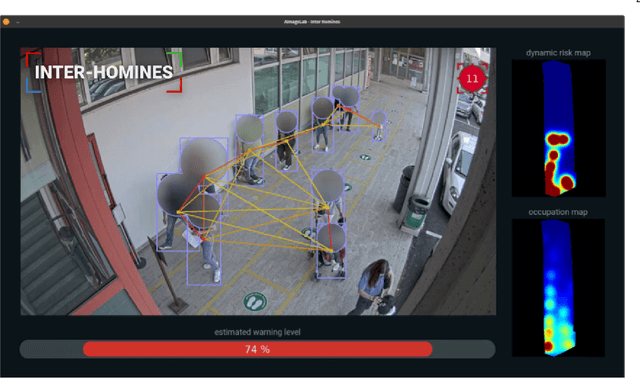
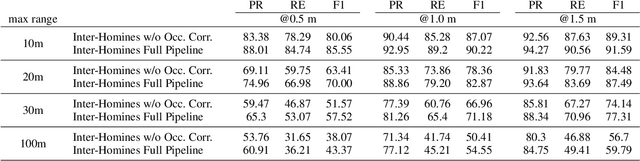
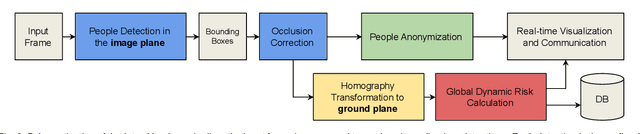

In this document, we report our proposal for modeling the risk of possible contagiousity in a given area monitored by RGB cameras where people freely move and interact. Our system, called Inter-Homines, evaluates in real-time the contagion risk in a monitored area by analyzing video streams: it is able to locate people in 3D space, calculate interpersonal distances and predict risk levels by building dynamic maps of the monitored area. Inter-Homines works both indoor and outdoor, in public and private crowded areas. The software is applicable to already installed cameras or low-cost cameras on industrial PCs, equipped with an additional embedded edge-AI system for temporary measurements. From the AI-side, we exploit a robust pipeline for real-time people detection and localization in the ground plane by homographic transformation based on state-of-the-art computer vision algorithms; it is a combination of a people detector and a pose estimator. From the risk modeling side, we propose a parametric model for a spatio-temporal dynamic risk estimation, that, validated by epidemiologists, could be useful for safety monitoring the acceptance of social distancing prevention measures by predicting the risk level of the scene.
Learning to Generate Cost-to-Go Functions for Efficient Motion Planning
Oct 27, 2020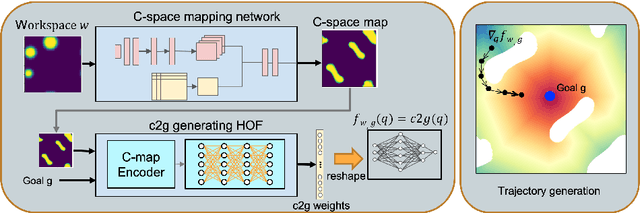
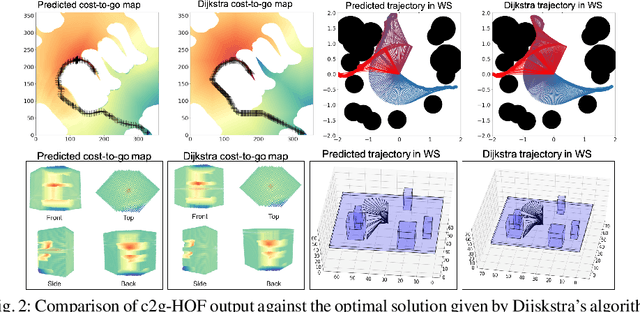
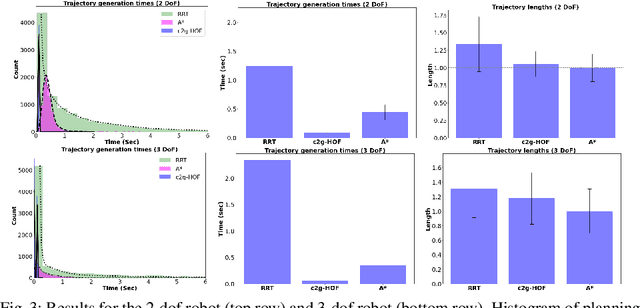

Traditional motion planning is computationally burdensome for practical robots, involving extensive collision checking and considerable iterative propagation of cost values. We present a novel neural network architecture which can directly generate the cost-to-go (c2g) function for a given configuration space and a goal configuration. The output of the network is a continuous function whose gradient in configuration space can be directly used to generate trajectories in motion planning without the need for protracted iterations or extensive collision checking. This higher order function (i.e. a function generating another function) representation lies at the core of our motion planning architecture, c2g-HOF, which can take a workspace as input, and generate the cost-to-go function over the configuration space map (C-map). Simulation results for 2D and 3D environments show that c2g-HOF can be orders of magnitude faster at execution time than methods which explore the configuration space during execution. We also present an implementation of c2g-HOF which generates trajectories for robot manipulators directly from an overhead image of the workspace.
Dependent Matérn Processes for Multivariate Time Series
Feb 11, 2015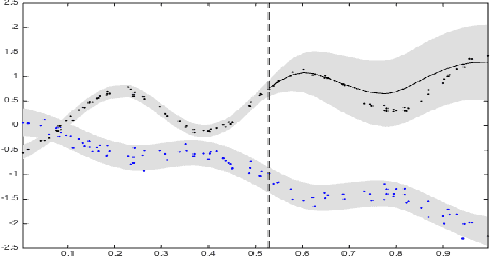
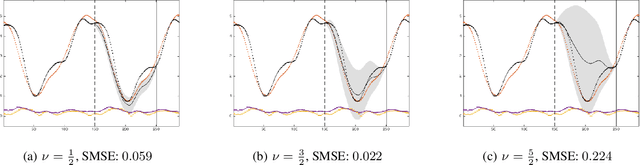
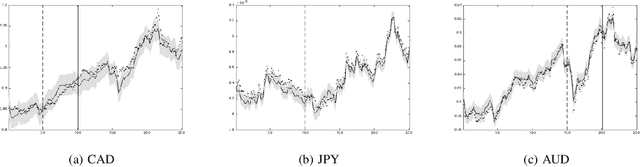
For the challenging task of modeling multivariate time series, we propose a new class of models that use dependent Mat\'ern processes to capture the underlying structure of data, explain their interdependencies, and predict their unknown values. Although similar models have been proposed in the econometric, statistics, and machine learning literature, our approach has several advantages that distinguish it from existing methods: 1) it is flexible to provide high prediction accuracy, yet its complexity is controlled to avoid overfitting; 2) its interpretability separates it from black-box methods; 3) finally, its computational efficiency makes it scalable for high-dimensional time series. In this paper, we use several simulated and real data sets to illustrate these advantages. We will also briefly discuss some extensions of our model.
A Free Lunch for Unsupervised Domain Adaptive Object Detection without Source Data
Dec 10, 2020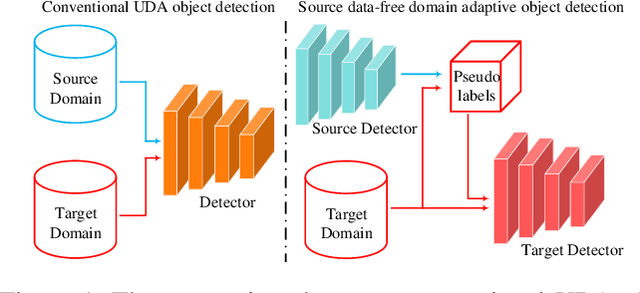
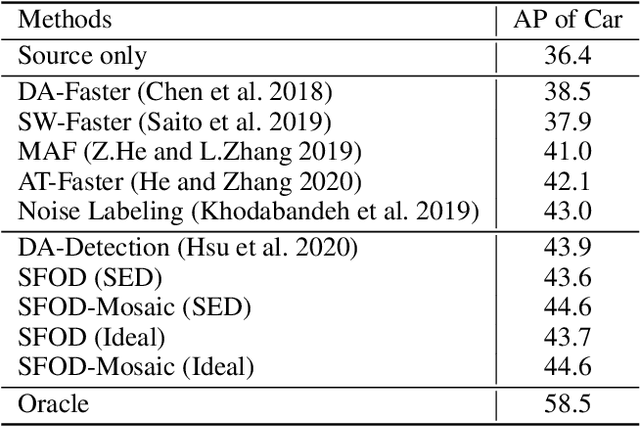
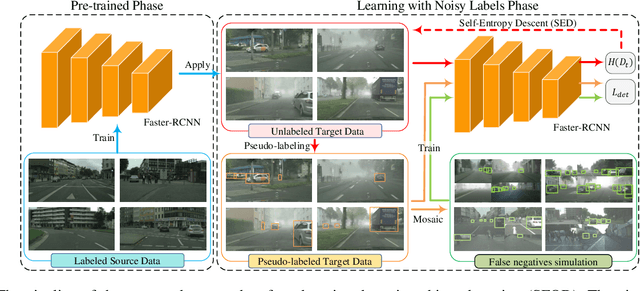
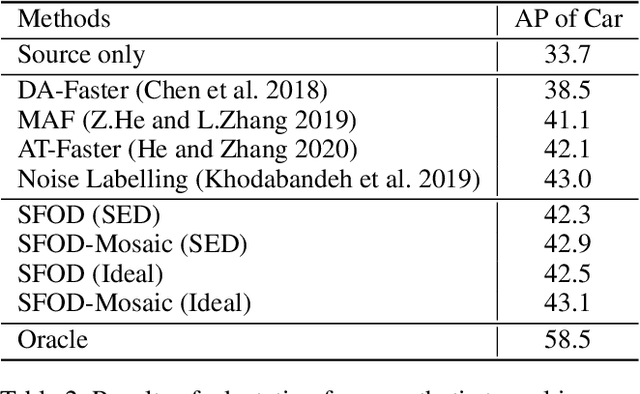
Unsupervised domain adaptation (UDA) assumes that source and target domain data are freely available and usually trained together to reduce the domain gap. However, considering the data privacy and the inefficiency of data transmission, it is impractical in real scenarios. Hence, it draws our eyes to optimize the network in the target domain without accessing labeled source data. To explore this direction in object detection, for the first time, we propose a source data-free domain adaptive object detection (SFOD) framework via modeling it into a problem of learning with noisy labels. Generally, a straightforward method is to leverage the pre-trained network from the source domain to generate the pseudo labels for target domain optimization. However, it is difficult to evaluate the quality of pseudo labels since no labels are available in target domain. In this paper, self-entropy descent (SED) is a metric proposed to search an appropriate confidence threshold for reliable pseudo label generation without using any handcrafted labels. Nonetheless, completely clean labels are still unattainable. After a thorough experimental analysis, false negatives are found to dominate in the generated noisy labels. Undoubtedly, false negatives mining is helpful for performance improvement, and we ease it to false negatives simulation through data augmentation like Mosaic. Extensive experiments conducted in four representative adaptation tasks have demonstrated that the proposed framework can easily achieve state-of-the-art performance. From another view, it also reminds the UDA community that the labeled source data are not fully exploited in the existing methods.