 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Joint Blind Room Acoustic Characterization From Speech And Music Signals Using Convolutional Recurrent Neural Networks
Oct 21, 2020
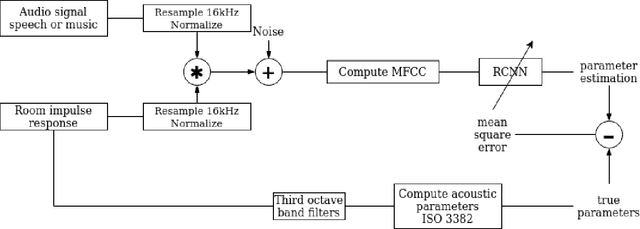
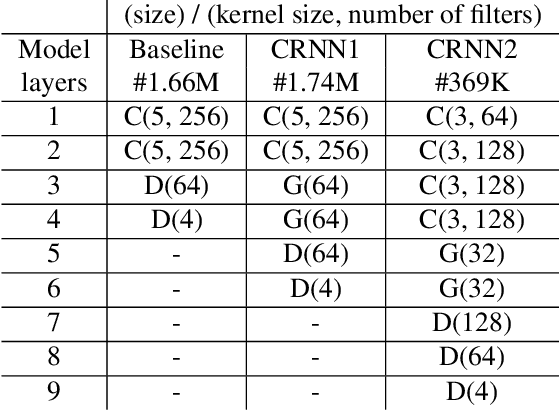
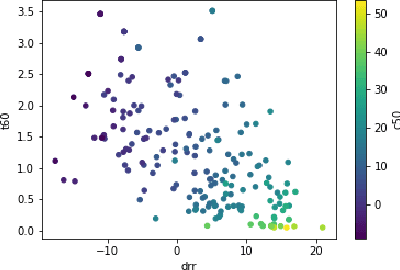
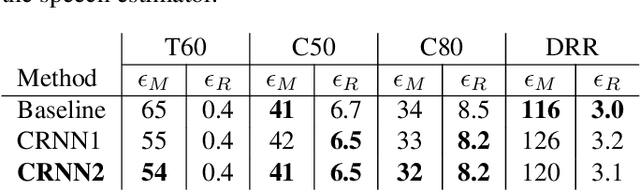
Acoustic environment characterization opens doors for sound reproduction innovations, smart EQing, speech enhancement, hearing aids, and forensics. Reverberation time, clarity, and direct-to-reverberant ratio are acoustic parameters that have been defined to describe reverberant environments. They are closely related to speech intelligibility and sound quality. As explained in the ISO3382 standard, they can be derived from a room measurement called the Room Impulse Response (RIR). However, measuring RIRs requires specific equipment and intrusive sound to be played. The recent audio combined with machine learning suggests that one could estimate those parameters blindly using speech or music signals. We follow these advances and propose a robust end-to-end method to achieve blind joint acoustic parameter estimation using speech and/or music signals. Our results indicate that convolutional recurrent neural networks perform best for this task, and including music in training also helps improve inference from speech.
HiResCAM: Explainable Multi-Organ Multi-Abnormality Prediction in 3D Medical Images
Nov 17, 2020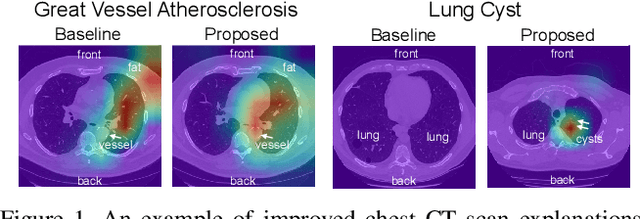
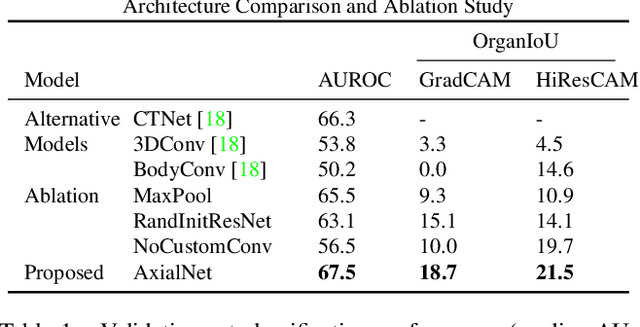
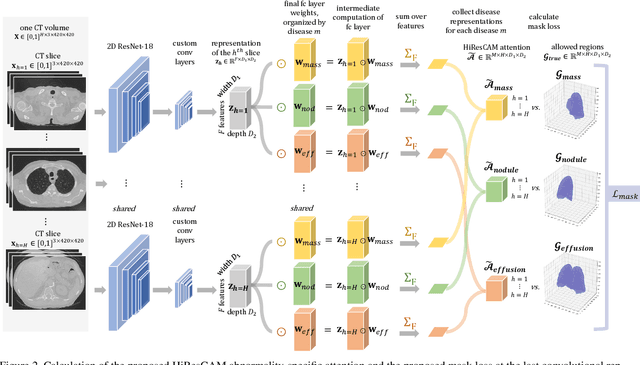
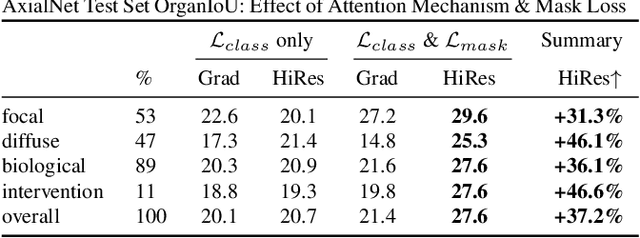
Understanding model predictions is critical in healthcare, to facilitate rapid real-time verification of model correctness and to guard against the use of models that exploit confounding variables. Motivated by the need for explainable models, we address the challenging task of explainable multiple abnormality classification in volumetric medical images. We propose a novel attention mechanism, HiResCAM, that highlights relevant regions within each volume for each abnormality queried. We investigate the relationship between HiResCAM and the popular model explanation method Grad-CAM, and demonstrate that HiResCAM yields better performance on abnormality localization and produces explanations that are more faithful to the underlying model. Finally, we introduce a mask loss that leverages HiResCAM to require the model to predict abnormalities based on only the organs in which those abnormalities appear. Our innovations achieve a 37% improvement in explanation quality, resulting in state-of-the-art weakly supervised organ localization of abnormalities in the RAD-ChestCT data set of 36,316 CT volumes. We also demonstrate on PASCAL VOC 2012 the different properties of HiResCAM and Grad-CAM on natural images. Overall, this work advances convolutional neural network explanation approaches and the clinical applicability of multi-abnormality modeling in volumetric medical images.
Novel Keyword Extraction and Language Detection Approaches
Sep 24, 2020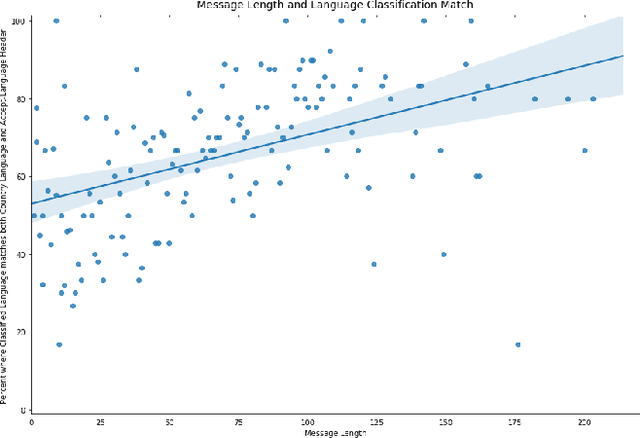
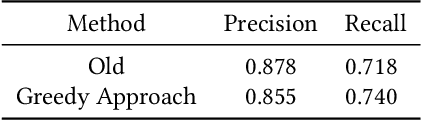
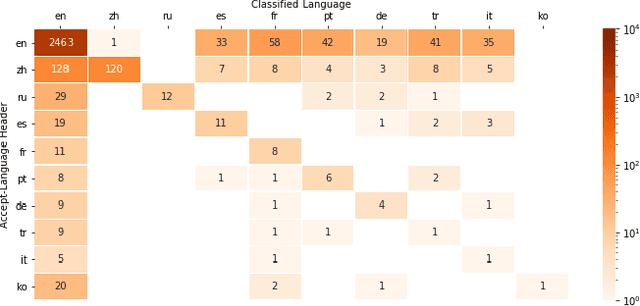
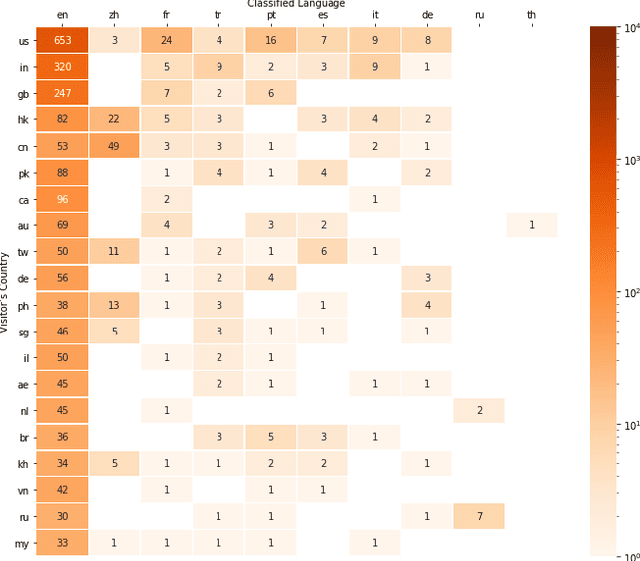
Fuzzy string matching and language classification are important tools in Natural Language Processing pipelines, this paper provides advances in both areas. We propose a fast novel approach to string tokenisation for fuzzy language matching and experimentally demonstrate an 83.6% decrease in processing time with an estimated improvement in recall of 3.1% at the cost of a 2.6% decrease in precision. This approach is able to work even where keywords are subdivided into multiple words, without needing to scan character-to-character. So far there has been little work considering using metadata to enhance language classification algorithms. We provide observational data and find the Accept-Language header is 14% more likely to match the classification than the IP Address.
Generalized Insider Attack Detection Implementation using NetFlow Data
Oct 27, 2020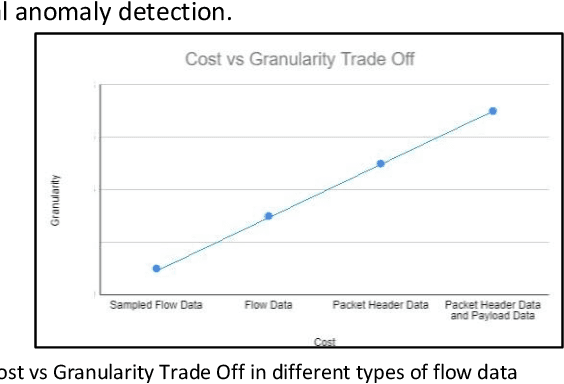
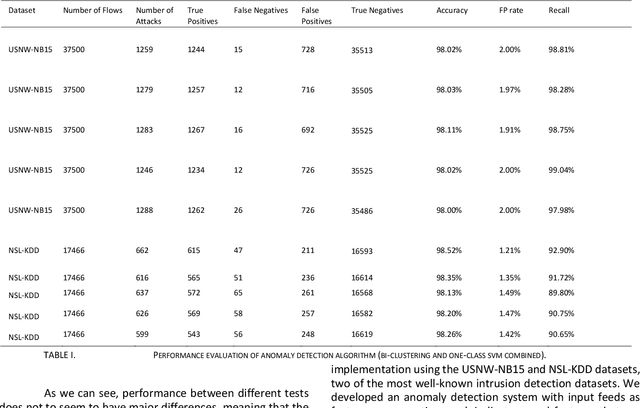
Insider Attack Detection in commercial networks is a critical problem that does not have any good solutions at this current time. The problem is challenging due to the lack of visibility into live networks and a lack of a standard feature set to distinguish between different attacks. In this paper, we study an approach centered on using network data to identify attacks. Our work builds on unsupervised machine learning techniques such as One-Class SVM and bi-clustering as weak indicators of insider network attacks. We combine these techniques to limit the number of false positives to an acceptable level required for real-world deployments by using One-Class SVM to check for anomalies detected by the proposed Bi-clustering algorithm. We present a prototype implementation in Python and associated results for two different real-world representative data sets. We show that our approach is a promising tool for insider attack detection in realistic settings.
On Explaining Decision Trees
Oct 21, 2020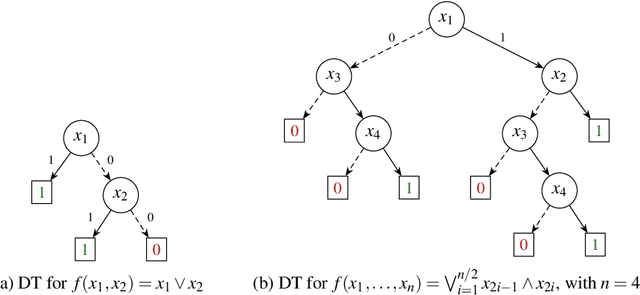
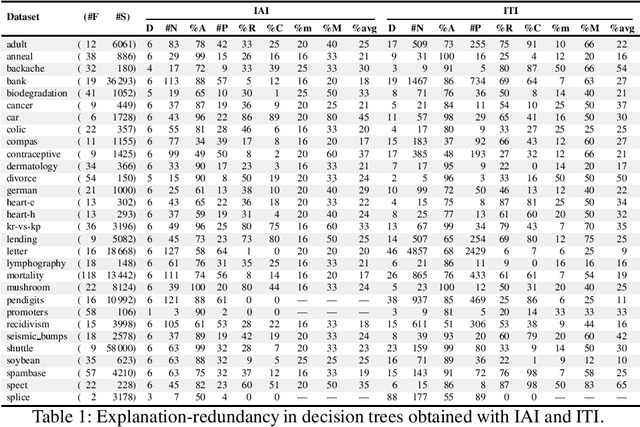

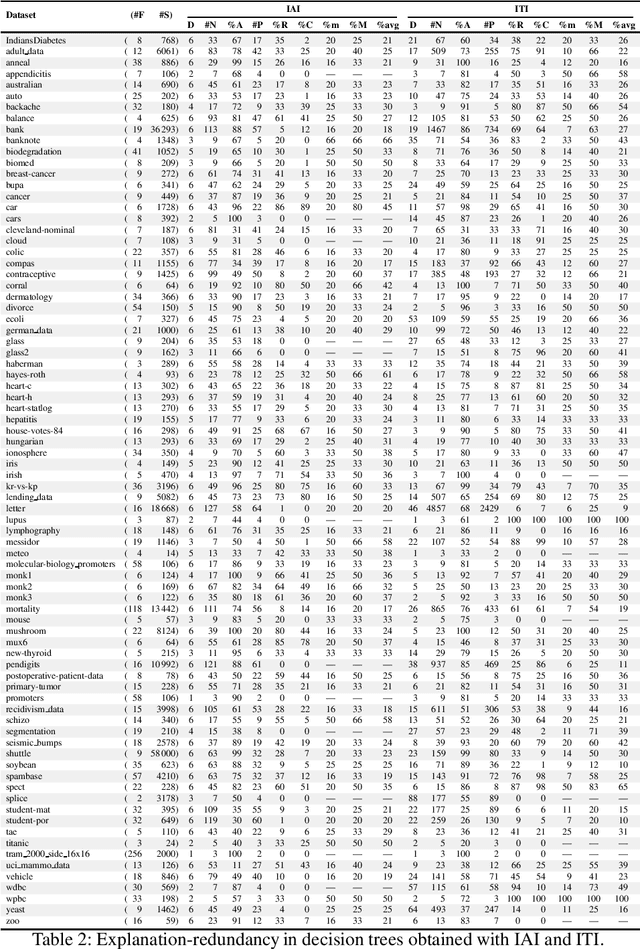
Decision trees (DTs) epitomize what have become to be known as interpretable machine learning (ML) models. This is informally motivated by paths in DTs being often much smaller than the total number of features. This paper shows that in some settings DTs can hardly be deemed interpretable, with paths in a DT being arbitrarily larger than a PI-explanation, i.e. a subset-minimal set of feature values that entails the prediction. As a result, the paper proposes a novel model for computing PI-explanations of DTs, which enables computing one PI-explanation in polynomial time. Moreover, it is shown that enumeration of PI-explanations can be reduced to the enumeration of minimal hitting sets. Experimental results were obtained on a wide range of publicly available datasets with well-known DT-learning tools, and confirm that in most cases DTs have paths that are proper supersets of PI-explanations.
Concentric mixtures of Mallows models for top-$k$ rankings: sampling and identifiability
Oct 27, 2020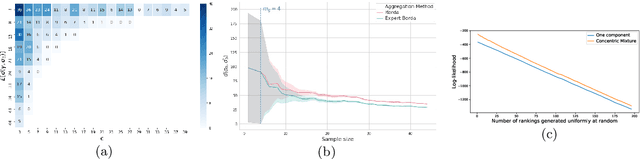
In this paper, we consider mixtures of two Mallows models for top-$k$ rankings, both with the same location parameter but with different scale parameters, i.e., a mixture of concentric Mallows models. This situation arises when we have a heterogeneous population of voters formed by two homogeneous populations, one of which is a subpopulation of expert voters while the other includes the non-expert voters. We propose efficient sampling algorithms for Mallows top-$k$ rankings. We show the identifiability of both components, and the learnability of their respective parameters in this setting by, first, bounding the sample complexity for the Borda algorithm with top-$k$ rankings and second, proposing polynomial time algorithm for the separation of the rankings in each component. Finally, since the rank aggregation will suffer from a large amount of noise introduced by the non-expert voters, we adapt the Borda algorithm to be able to recover the ground truth consensus ranking which is especially consistent with the expert rankings.
Measuring the Novelty of Natural Language Text Using the Conjunctive Clauses of a Tsetlin Machine Text Classifier
Nov 17, 2020Most supervised text classification approaches assume a closed world, counting on all classes being present in the data at training time. This assumption can lead to unpredictable behaviour during operation, whenever novel, previously unseen, classes appear. Although deep learning-based methods have recently been used for novelty detection, they are challenging to interpret due to their black-box nature. This paper addresses \emph{interpretable} open-world text classification, where the trained classifier must deal with novel classes during operation. To this end, we extend the recently introduced Tsetlin machine (TM) with a novelty scoring mechanism. The mechanism uses the conjunctive clauses of the TM to measure to what degree a text matches the classes covered by the training data. We demonstrate that the clauses provide a succinct interpretable description of known topics, and that our scoring mechanism makes it possible to discern novel topics from the known ones. Empirically, our TM-based approach outperforms seven other novelty detection schemes on three out of five datasets, and performs second and third best on the remaining, with the added benefit of an interpretable propositional logic-based representation.
Noise-Resilient Automatic Interpretation of Holter ECG Recordings
Nov 17, 2020
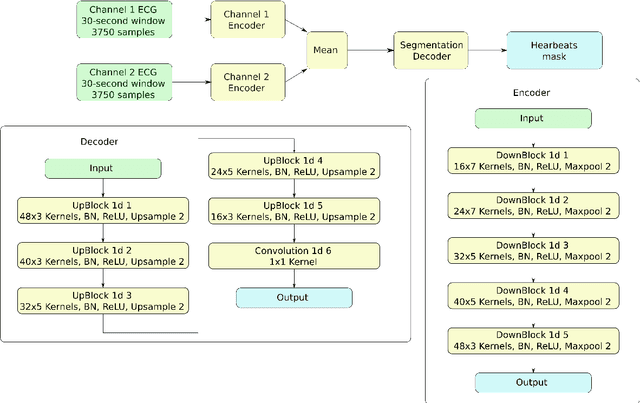
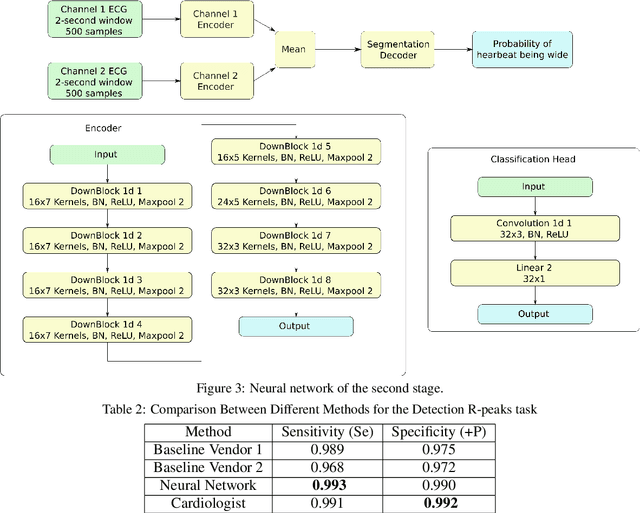
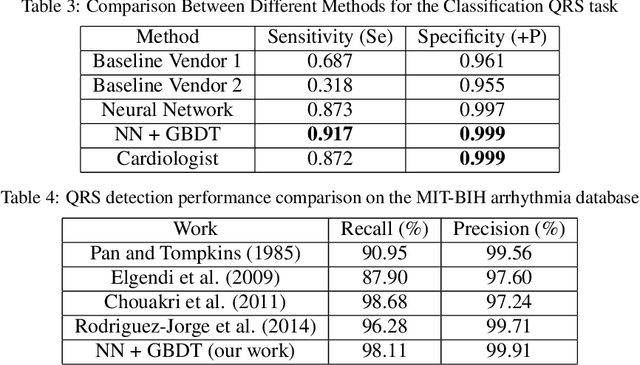
Holter monitoring, a long-term ECG recording (24-hours and more), contains a large amount of valuable diagnostic information about the patient. Its interpretation becomes a difficult and time-consuming task for the doctor who analyzes them because every heartbeat needs to be classified, thus requiring highly accurate methods for automatic interpretation. In this paper, we present a three-stage process for analysing Holter recordings with robustness to noisy signal. First stage is a segmentation neural network (NN) with encoderdecoder architecture which detects positions of heartbeats. Second stage is a classification NN which will classify heartbeats as wide or narrow. Third stage in gradient boosting decision trees (GBDT) on top of NN features that incorporates patient-wise features and further increases performance of our approach. As a part of this work we acquired 5095 Holter recordings of patients annotated by an experienced cardiologist. A committee of three cardiologists served as a ground truth annotators for the 291 examples in the test set. We show that the proposed method outperforms the selected baselines, including two commercial-grade software packages and some methods previously published in the literature.
Comparison Analysis of Tree Based and Ensembled Regression Algorithms for Traffic Accident Severity Prediction
Oct 27, 2020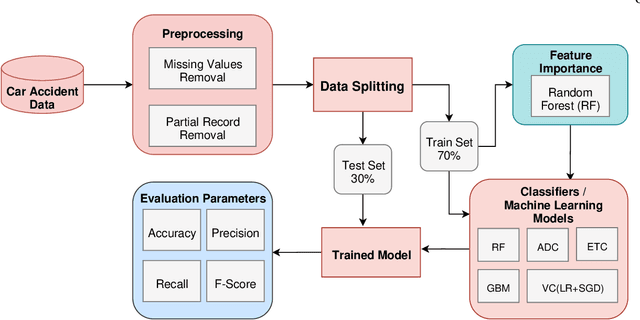

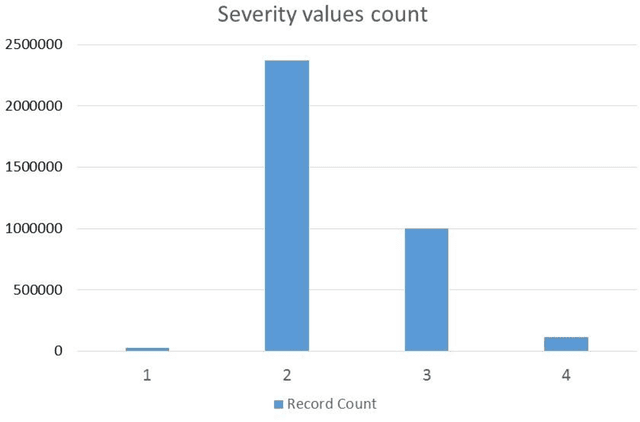
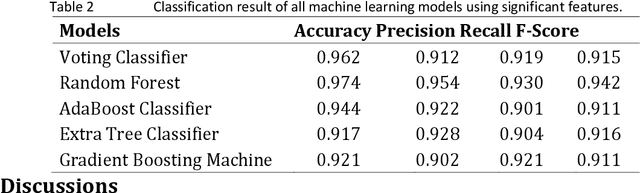
Rapid increase of traffic volume on urban roads over time has changed the traffic scenario globally. It has also increased the ratio of road accidents that can be severe and fatal in the worst case. To improve traffic safety and its management on urban roads, there is a need for prediction of severity level of accidents. Various machine learning models are being used for accident prediction. In this study, tree based ensemble models (Random Forest, AdaBoost, Extra Tree, and Gradient Boosting) and ensemble of two statistical models (Logistic Regression Stochastic Gradient Descent) as voting classifiers are compared for prediction of road accident severity. Significant features that are strongly correlated with the accident severity are identified by Random Forest. Analysis proved Random Forest as the best performing model with highest classification results with 0.974 accuracy, 0.954 precision, 0.930 recall and 0.942 F-score using 20 most significant features as compared to other techniques classification of road accidents severity.
Multi-Interactive Attention Network for Fine-grained Feature Learning in CTR Prediction
Dec 13, 2020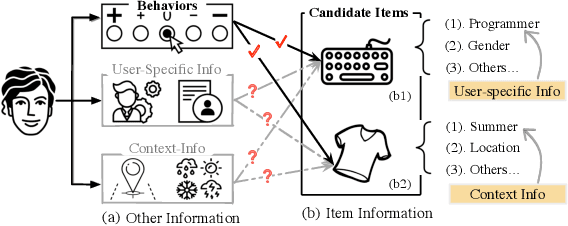
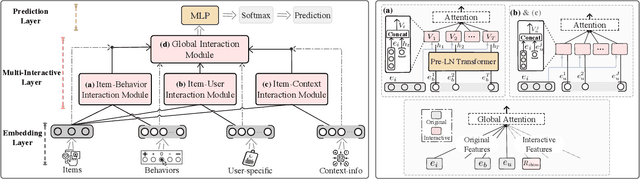
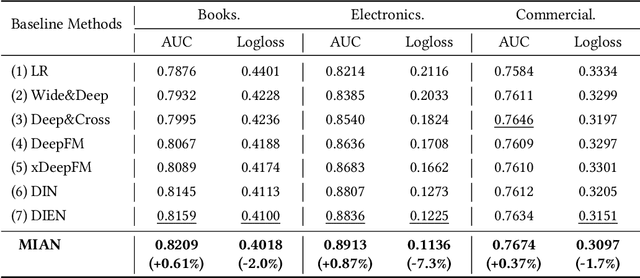
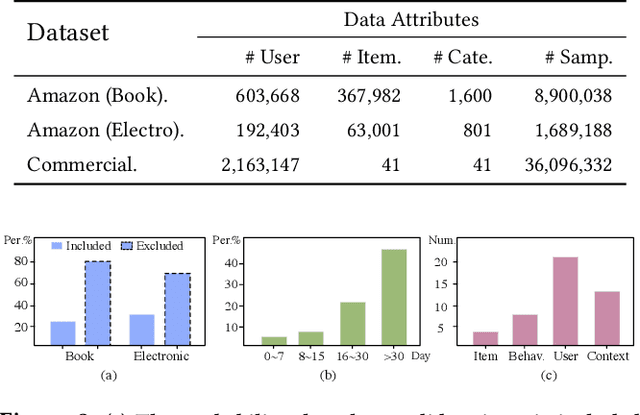
In the Click-Through Rate (CTR) prediction scenario, user's sequential behaviors are well utilized to capture the user interest in the recent literature. However, despite being extensively studied, these sequential methods still suffer from three limitations. First, existing methods mostly utilize attention on the behavior of users, which is not always suitable for CTR prediction, because users often click on new products that are irrelevant to any historical behaviors. Second, in the real scenario, there exist numerous users that have operations a long time ago, but turn relatively inactive in recent times. Thus, it is hard to precisely capture user's current preferences through early behaviors. Third, multiple representations of user's historical behaviors in different feature subspaces are largely ignored. To remedy these issues, we propose a Multi-Interactive Attention Network (MIAN) to comprehensively extract the latent relationship among all kinds of fine-grained features (e.g., gender, age and occupation in user-profile). Specifically, MIAN contains a Multi-Interactive Layer (MIL) that integrates three local interaction modules to capture multiple representations of user preference through sequential behaviors and simultaneously utilize the fine-grained user-specific as well as context information. In addition, we design a Global Interaction Module (GIM) to learn the high-order interactions and balance the different impacts of multiple features. Finally, Offline experiment results from three datasets, together with an Online A/B test in a large-scale recommendation system, demonstrate the effectiveness of our proposed approach.