 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time-dependent Hierarchical Dirichlet Model for Timeline Generation
Mar 14, 2017

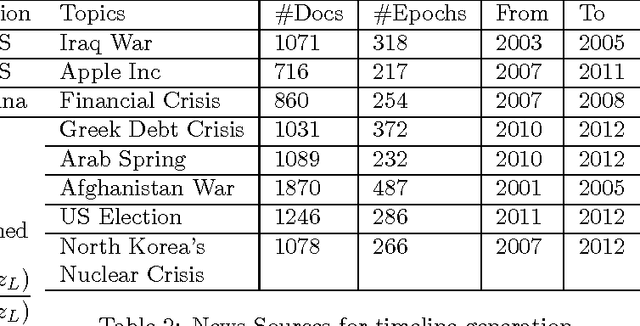
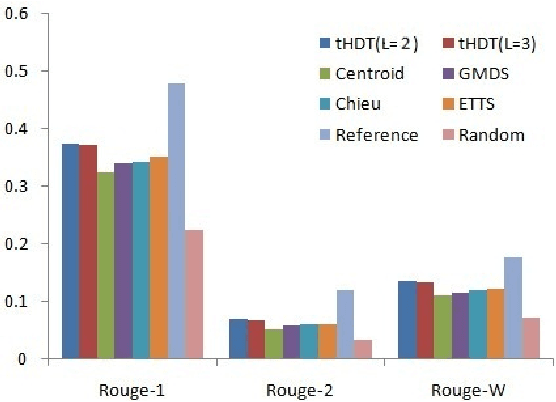
Timeline Generation aims at summarizing news from different epochs and telling readers how an event evolves. It is a new challenge that combines salience ranking with novelty detection. For long-term public events, the main topic usually includes various aspects across different epochs and each aspect has its own evolving pattern. Existing approaches neglect such hierarchical topic structure involved in the news corpus in timeline generation. In this paper, we develop a novel time-dependent Hierarchical Dirichlet Model (HDM) for timeline generation. Our model can aptly detect different levels of topic information across corpus and such structure is further used for sentence selection. Based on the topic mined fro HDM, sentences are selected by considering different aspects such as relevance, coherence and coverage. We develop experimental systems to evaluate 8 long-term events that public concern. Performance comparison between different systems demonstrates the effectiveness of our model in terms of ROUGE metrics.
CompRess: Self-Supervised Learning by Compressing Representations
Oct 28, 2020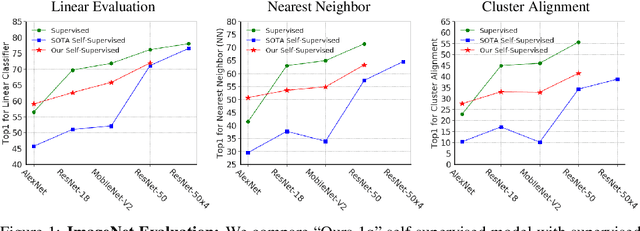
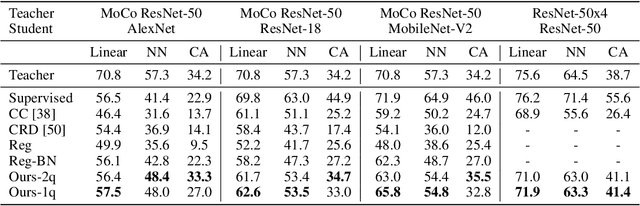
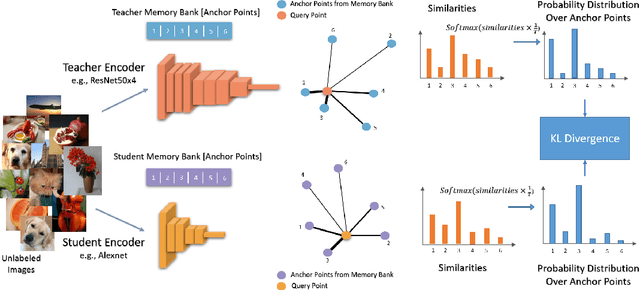

Self-supervised learning aims to learn good representations with unlabeled data. Recent works have shown that larger models benefit more from self-supervised learning than smaller models. As a result, the gap between supervised and self-supervised learning has been greatly reduced for larger models. In this work, instead of designing a new pseudo task for self-supervised learning, we develop a model compression method to compress an already learned, deep self-supervised model (teacher) to a smaller one (student). We train the student model so that it mimics the relative similarity between the data points in the teacher's embedding space. For AlexNet, our method outperforms all previous methods including the fully supervised model on ImageNet linear evaluation (59.0% compared to 56.5%) and on nearest neighbor evaluation (50.7% compared to 41.4%). To the best of our knowledge, this is the first time a self-supervised AlexNet has outperformed supervised one on ImageNet classification. Our code is available here: https://github.com/UMBCvision/CompRess
Visibility Interpolation in Solar Hard X-ray Imaging: Application to RHESSI and STIX
Dec 27, 2020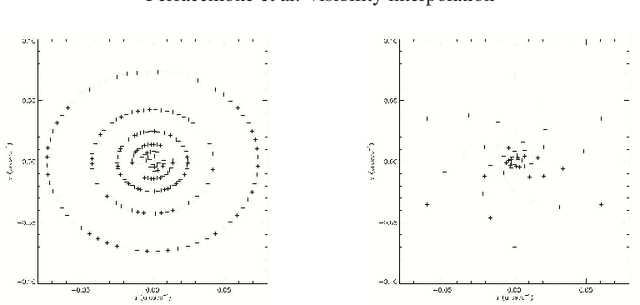
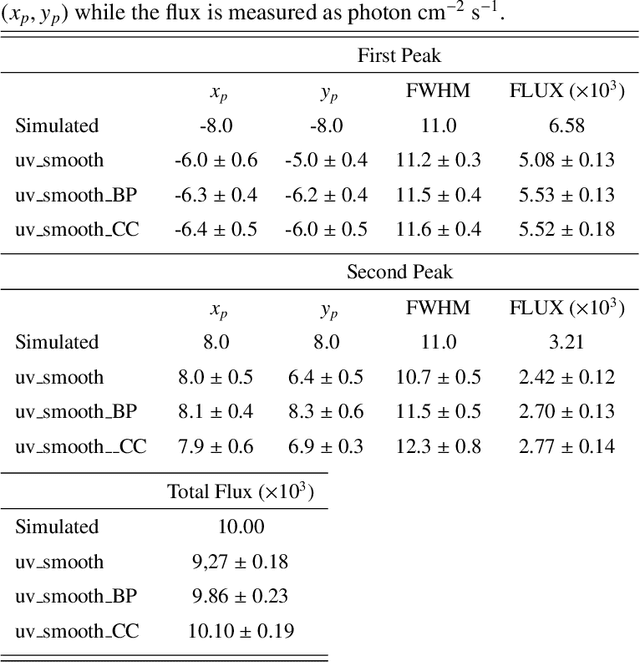
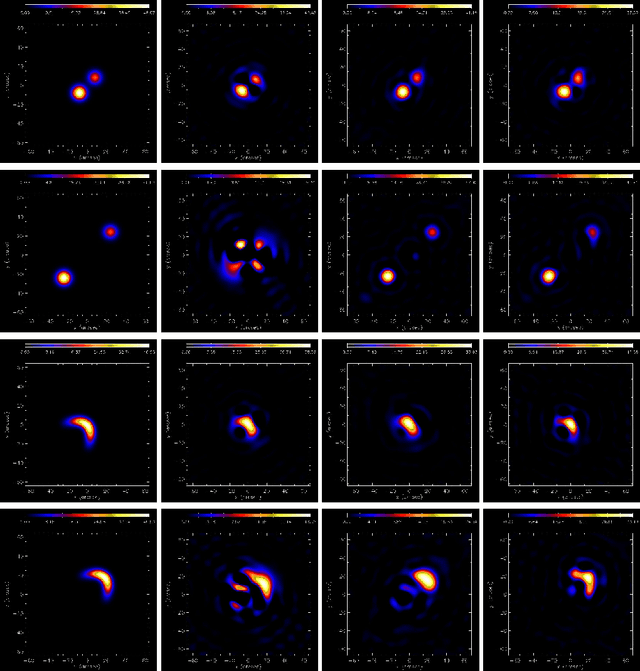
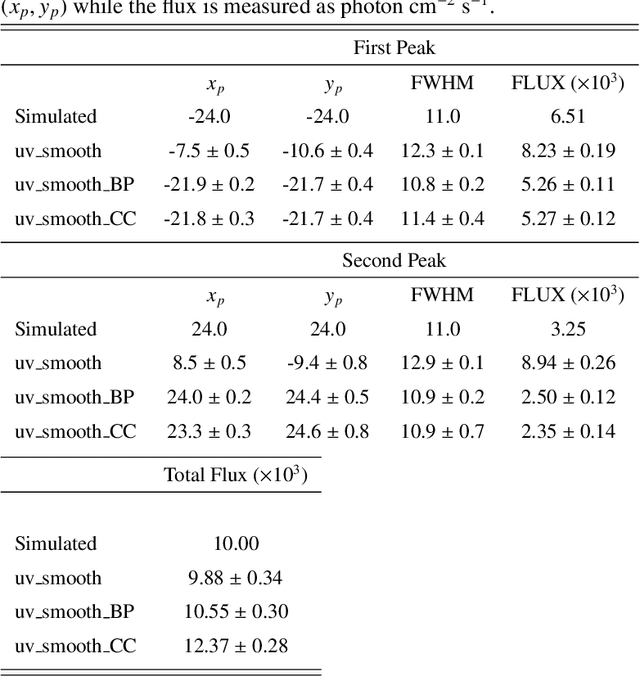
Space telescopes for solar hard X-ray imaging provide observations made of sampled Fourier components of the incoming photon flux. The aim of this study is to design an image reconstruction method relying on enhanced visibility interpolation in the Fourier domain. % methods heading (mandatory) The interpolation-based method is applied on synthetic visibilities generated by means of the simulation software implemented within the framework of the Spectrometer/Telescope for Imaging X-rays (STIX) mission on board Solar Orbiter. An application to experimental visibilities observed by the Reuven Ramaty High Energy Solar Spectroscopic Imager (RHESSI) is also considered. In order to interpolate these visibility data we have utilized an approach based on Variably Scaled Kernels (VSKs), which are able to realize feature augmentation by exploiting prior information on the flaring source and which are used here, for the first time, for image reconstruction purposes.} % results heading (mandatory) When compared to an interpolation-based reconstruction algorithm previously introduced for RHESSI, VSKs offer significantly better performances, particularly in the case of STIX imaging, which is characterized by a notably sparse sampling of the Fourier domain. In the case of RHESSI data, this novel approach is particularly reliable when either the flaring sources are characterized by narrow, ribbon-like shapes or high-resolution detectors are utilized for observations. % conclusions heading (optional), leave it empty if necessary The use of VSKs for interpolating hard X-ray visibilities allows a notable image reconstruction accuracy when the information on the flaring source is encoded by a small set of scattered Fourier data and when the visibility surface is affected by significant oscillations in the frequency domain.
Learning Temporal Transformations From Time-Lapse Videos
Aug 27, 2016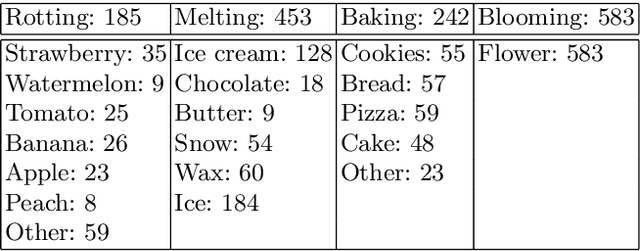

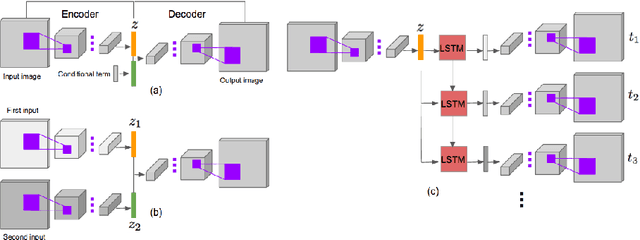

Based on life-long observations of physical, chemical, and biologic phenomena in the natural world, humans can often easily picture in their minds what an object will look like in the future. But, what about computers? In this paper, we learn computational models of object transformations from time-lapse videos. In particular, we explore the use of generative models to create depictions of objects at future times. These models explore several different prediction tasks: generating a future state given a single depiction of an object, generating a future state given two depictions of an object at different times, and generating future states recursively in a recurrent framework. We provide both qualitative and quantitative evaluations of the generated results, and also conduct a human evaluation to compare variations of our models.
Deep learning of thermodynamics-aware reduced-order models from data
Jul 03, 2020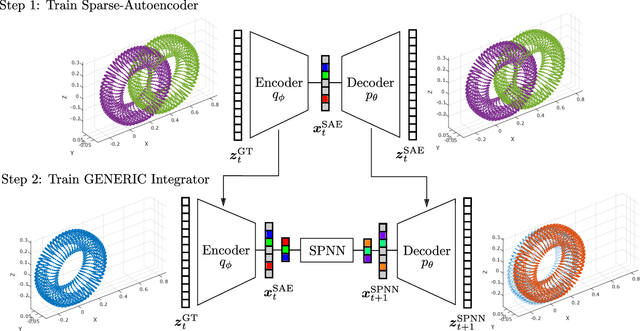
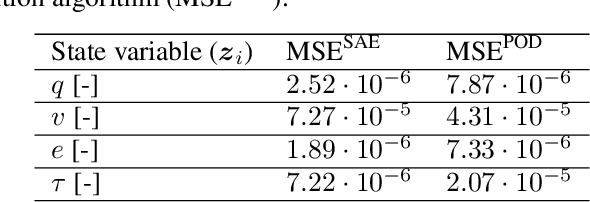
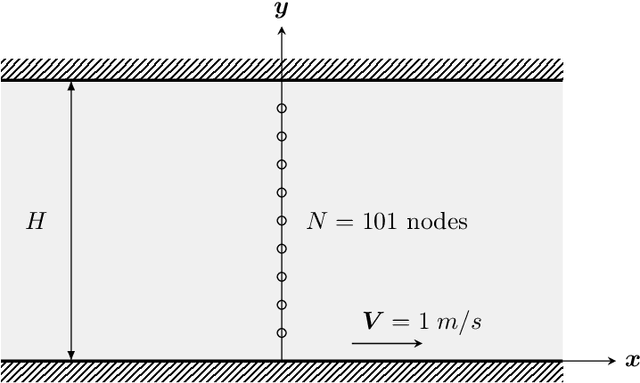
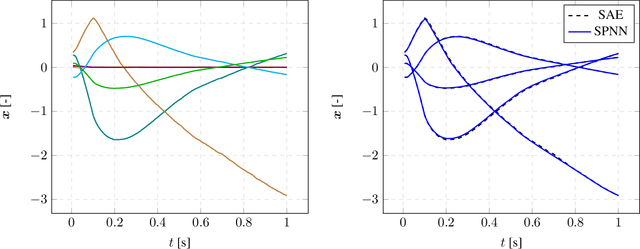
We present an algorithm to learn the relevant latent variables of a large-scale discretized physical system and predict its time evolution using thermodynamically-consistent deep neural networks. Our method relies on sparse autoencoders, which reduce the dimensionality of the full order model to a set of sparse latent variables with no prior knowledge of the coded space dimensionality. Then, a second neural network is trained to learn the metriplectic structure of those reduced physical variables and predict its time evolution with a so-called structure-preserving neural network. This data-based integrator is guaranteed to conserve the total energy of the system and the entropy inequality, and can be applied to both conservative and dissipative systems. The integrated paths can then be decoded to the original full-dimensional manifold and be compared to the ground truth solution. This method is tested with two examples applied to fluid and solid mechanics.
Point-of-Interest Type Inference from Social Media Text
Oct 02, 2020
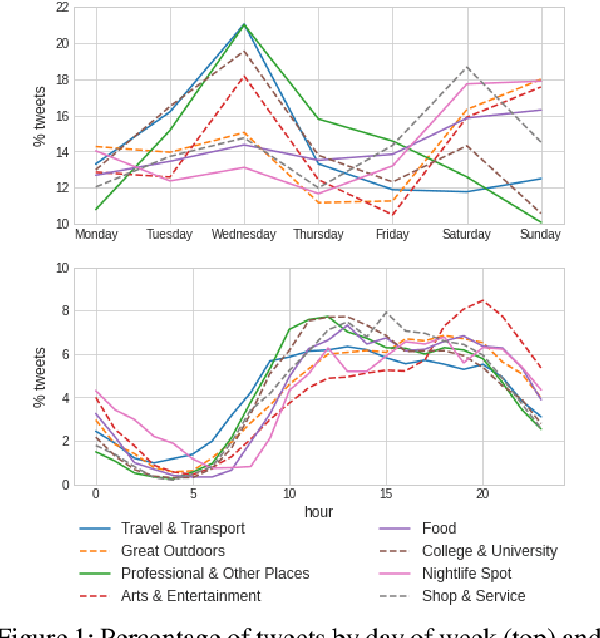
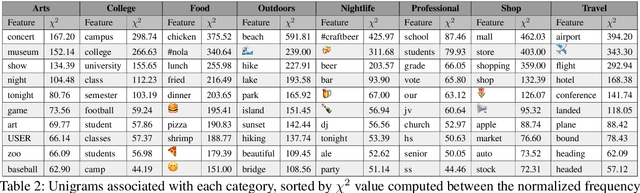
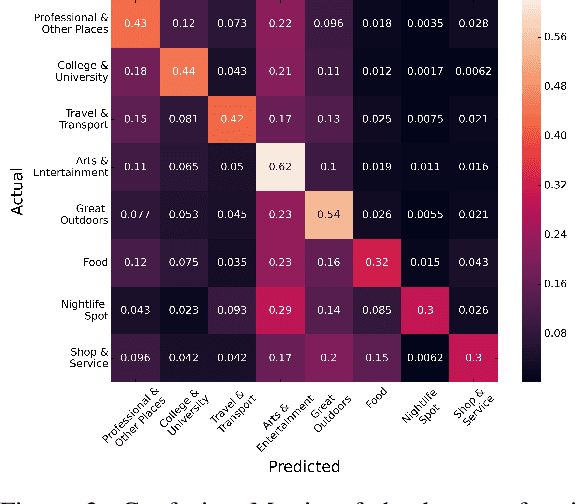
Physical places help shape how we perceive the experiences we have there. For the first time, we study the relationship between social media text and the type of the place from where it was posted, whether a park, restaurant, or someplace else. To facilitate this, we introduce a novel data set of $\sim$200,000 English tweets published from 2,761 different points-of-interest in the U.S., enriched with place type information. We train classifiers to predict the type of the location a tweet was sent from that reach a macro F1 of 43.67 across eight classes and uncover the linguistic markers associated with each type of place. The ability to predict semantic place information from a tweet has applications in recommendation systems, personalization services and cultural geography.
Learning Graph-Based Priors for Generalized Zero-Shot Learning
Oct 22, 2020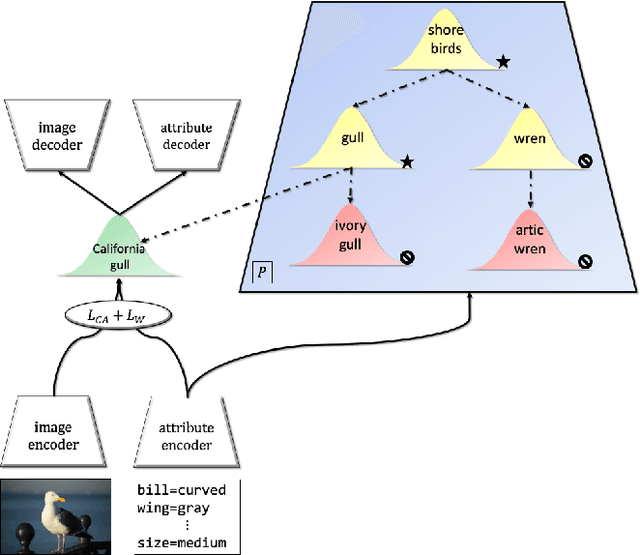

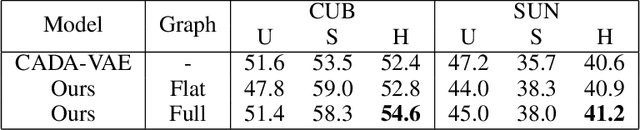
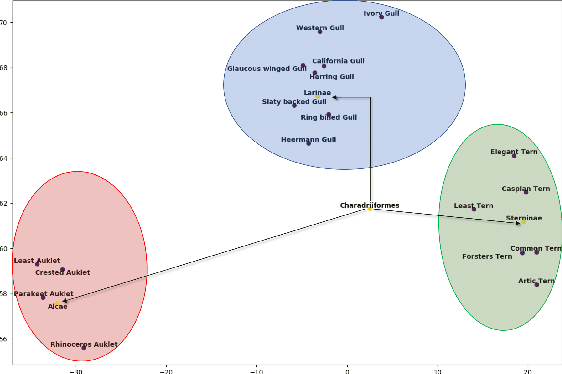
The task of zero-shot learning (ZSL) requires correctly predicting the label of samples from classes which were unseen at training time. This is achieved by leveraging side information about class labels, such as label attributes or word embeddings. Recently, attention has shifted to the more realistic task of generalized ZSL (GZSL) where test sets consist of seen and unseen samples. Recent approaches to GZSL have shown the value of generative models, which are used to generate samples from unseen classes. In this work, we incorporate an additional source of side information in the form of a relation graph over labels. We leverage this graph in order to learn a set of prior distributions, which encourage an aligned variational autoencoder (VAE) model to learn embeddings which respect the graph structure. Using this approach we are able to achieve improved performance on the CUB and SUN benchmarks over a strong baseline.
SST-BERT at SemEval-2020 Task 1: Semantic Shift Tracing by Clustering in BERT-based Embedding Spaces
Oct 02, 2020
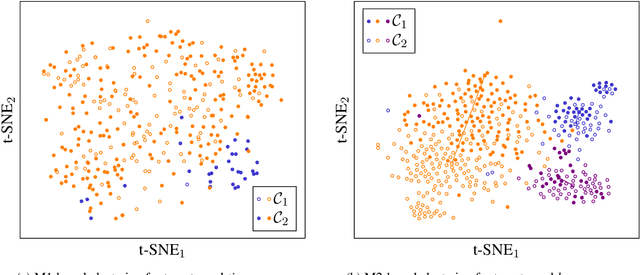
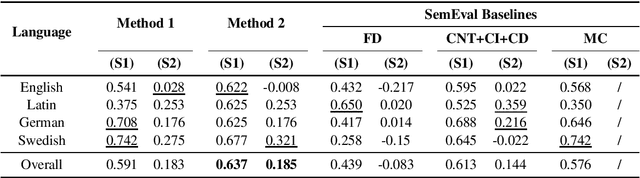
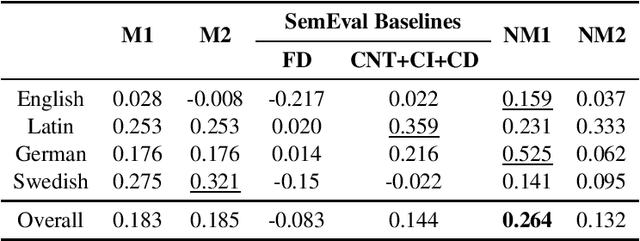
Lexical semantic change detection (also known as semantic shift tracing) is a task of identifying words that have changed their meaning over time. Unsupervised semantic shift tracing, focal point of SemEval2020, is particularly challenging. Given the unsupervised setup, in this work, we propose to identify clusters among different occurrences of each target word, considering these as representatives of different word meanings. As such, disagreements in obtained clusters naturally allow to quantify the level of semantic shift per each target word in four target languages. To leverage this idea, clustering is performed on contextualized (BERT-based) embeddings of word occurrences. The obtained results show that our approach performs well both measured separately (per language) and overall, where we surpass all provided SemEval baselines.
Data-driven Accelerogram Synthesis using Deep Generative Models
Nov 18, 2020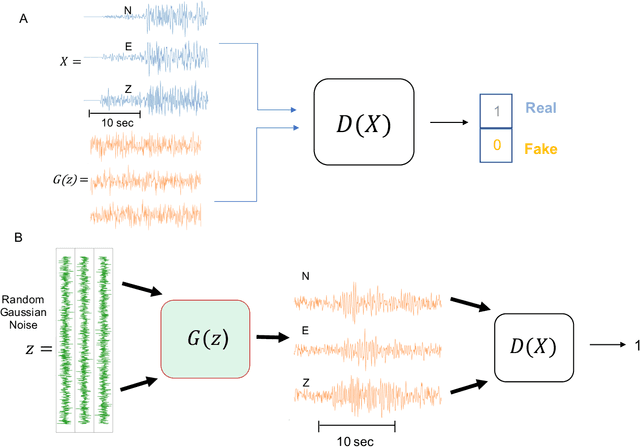
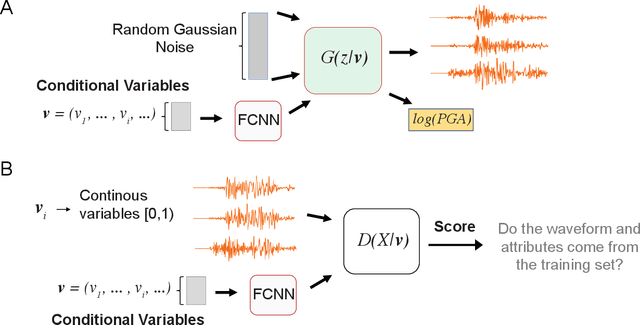
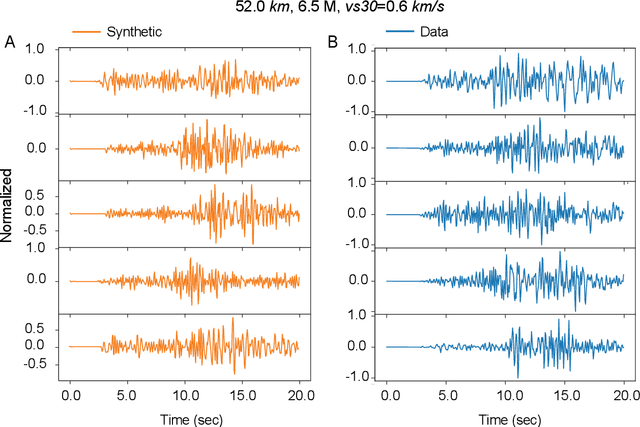
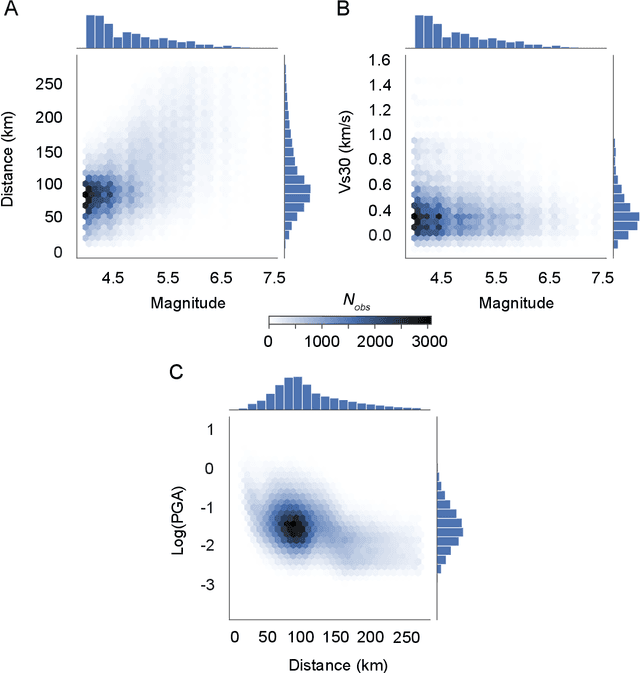
Robust estimation of ground motions generated by scenario earthquakes is critical for many engineering applications. We leverage recent advances in Generative Adversarial Networks (GANs) to develop a new framework for synthesizing earthquake acceleration time histories. Our approach extends the Wasserstein GAN formulation to allow for the generation of ground-motions conditioned on a set of continuous physical variables. Our model is trained to approximate the intrinsic probability distribution of a massive set of strong-motion recordings from Japan. We show that the trained generator model can synthesize realistic 3-Component accelerograms conditioned on magnitude, distance, and $V_{s30}$. Our model captures the expected statistical features of the acceleration spectra and waveform envelopes. The output seismograms display clear P and S-wave arrivals with the appropriate energy content and relative onset timing. The synthesized Peak Ground Acceleration (PGA) estimates are also consistent with observations. We develop a set of metrics that allow us to assess the training process's stability and tune model hyperparameters. We further show that the trained generator network can interpolate to conditions where no earthquake ground motion recordings exist. Our approach allows the on-demand synthesis of accelerograms for engineering purposes.
Room-Across-Room: Multilingual Vision-and-Language Navigation with Dense Spatiotemporal Grounding
Oct 15, 2020
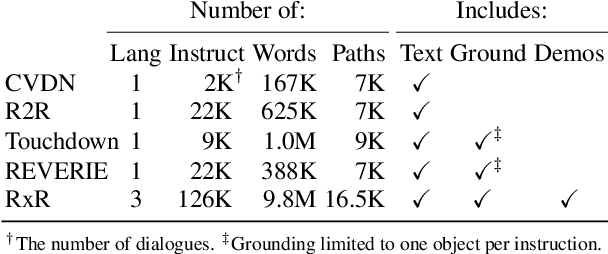
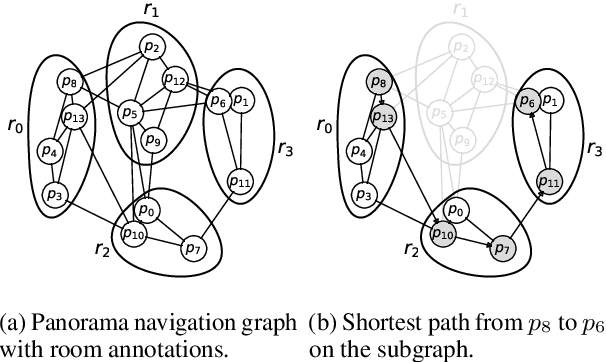
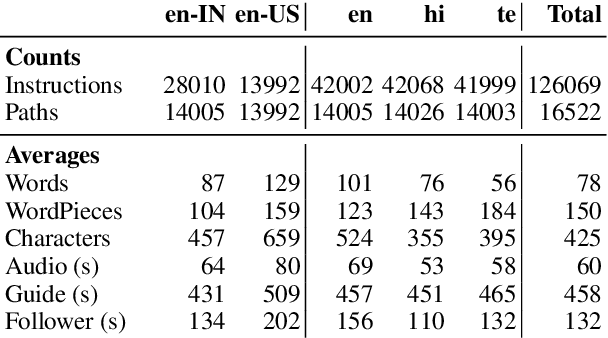
We introduce Room-Across-Room (RxR), a new Vision-and-Language Navigation (VLN) dataset. RxR is multilingual (English, Hindi, and Telugu) and larger (more paths and instructions) than other VLN datasets. It emphasizes the role of language in VLN by addressing known biases in paths and eliciting more references to visible entities. Furthermore, each word in an instruction is time-aligned to the virtual poses of instruction creators and validators. We establish baseline scores for monolingual and multilingual settings and multitask learning when including Room-to-Room annotations. We also provide results for a model that learns from synchronized pose traces by focusing only on portions of the panorama attended to in human demonstrations. The size, scope and detail of RxR dramatically expands the frontier for research on embodied language agents in simulated, photo-realistic environments.