 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On (Emergent) Systematic Generalisation and Compositionality in Visual Referential Games with Straight-Through Gumbel-Softmax Estimator
Dec 19, 2020
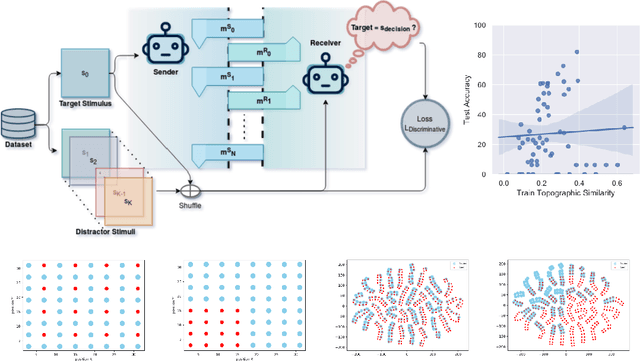

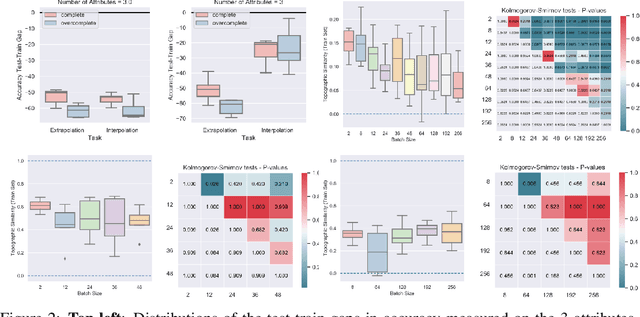
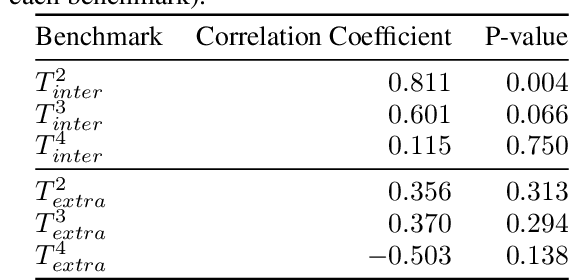
The drivers of compositionality in artificial languages that emerge when two (or more) agents play a non-visual referential game has been previously investigated using approaches based on the REINFORCE algorithm and the (Neural) Iterated Learning Model. Following the more recent introduction of the \textit{Straight-Through Gumbel-Softmax} (ST-GS) approach, this paper investigates to what extent the drivers of compositionality identified so far in the field apply in the ST-GS context and to what extent do they translate into (emergent) systematic generalisation abilities, when playing a visual referential game. Compositionality and the generalisation abilities of the emergent languages are assessed using topographic similarity and zero-shot compositional tests. Firstly, we provide evidence that the test-train split strategy significantly impacts the zero-shot compositional tests when dealing with visual stimuli, whilst it does not when dealing with symbolic ones. Secondly, empirical evidence shows that using the ST-GS approach with small batch sizes and an overcomplete communication channel improves compositionality in the emerging languages. Nevertheless, while shown robust with symbolic stimuli, the effect of the batch size is not so clear-cut when dealing with visual stimuli. Our results also show that not all overcomplete communication channels are created equal. Indeed, while increasing the maximum sentence length is found to be beneficial to further both compositionality and generalisation abilities, increasing the vocabulary size is found detrimental. Finally, a lack of correlation between the language compositionality at training-time and the agents' generalisation abilities is observed in the context of discriminative referential games with visual stimuli. This is similar to previous observations in the field using the generative variant with symbolic stimuli.
Efficient sampling from the Bingham distribution
Sep 30, 2020We give a algorithm for exact sampling from the Bingham distribution $p(x)\propto \exp(x^\top A x)$ on the sphere $\mathcal S^{d-1}$ with expected runtime of $\operatorname{poly}(d, \lambda_{\max}(A)-\lambda_{\min}(A))$. The algorithm is based on rejection sampling, where the proposal distribution is a polynomial approximation of the pdf, and can be sampled from by explicitly evaluating integrals of polynomials over the sphere. Our algorithm gives exact samples, assuming exact computation of an inverse function of a polynomial. This is in contrast with Markov Chain Monte Carlo algorithms, which are not known to enjoy rapid mixing on this problem, and only give approximate samples. As a direct application, we use this to sample from the posterior distribution of a rank-1 matrix inference problem in polynomial time.
Fantastic Features and Where to Find Them: Detecting Cognitive Impairment with a Subsequence Classification Guided Approach
Oct 13, 2020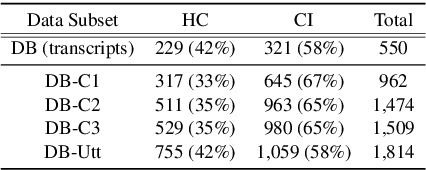

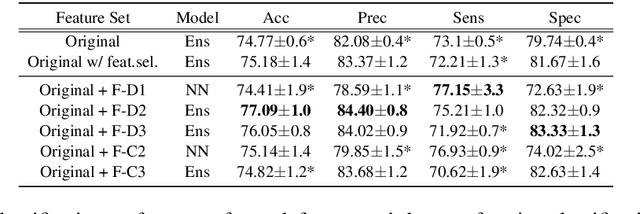

Despite the widely reported success of embedding-based machine learning methods on natural language processing tasks, the use of more easily interpreted engineered features remains common in fields such as cognitive impairment (CI) detection. Manually engineering features from noisy text is time and resource consuming, and can potentially result in features that do not enhance model performance. To combat this, we describe a new approach to feature engineering that leverages sequential machine learning models and domain knowledge to predict which features help enhance performance. We provide a concrete example of this method on a standard data set of CI speech and demonstrate that CI classification accuracy improves by 2.3% over a strong baseline when using features produced by this method. This demonstration provides an ex-ample of how this method can be used to assist classification in fields where interpretability is important, such as health care.
Model Robustness with Text Classification: Semantic-preserving adversarial attacks
Aug 14, 2020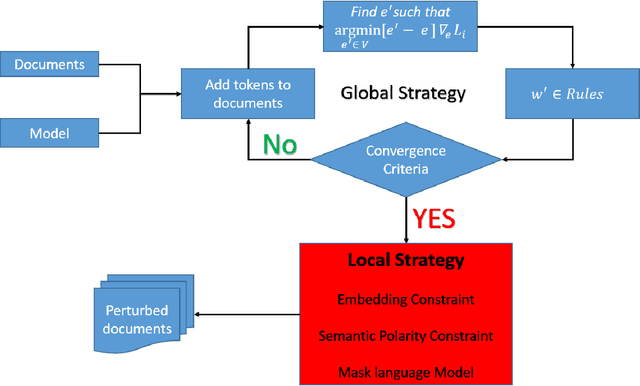



We propose algorithms to create adversarial attacks to assess model robustness in text classification problems. They can be used to create white box attacks and black box attacks while at the same time preserving the semantics and syntax of the original text. The attacks cause significant number of flips in white-box setting and same rule based can be used in black-box setting. In a black-box setting, the attacks created are able to reverse decisions of transformer based architectures.
Smart Attendance System Usign CNN
Apr 22, 2020The research on the attendance system has been going for a very long time, numerous arrangements have been proposed in the last decade to make this system efficient and less time consuming, but all those systems have several flaws. In this paper, we are introducing a smart and efficient system for attendance using face detection and face recognition. This system can be used to take attendance in colleges or offices using real-time face recognition with the help of the Convolution Neural Network(CNN). The conventional methods like Eigenfaces and Fisher faces are sensitive to lighting, noise, posture, obstruction, illumination etc. Hence, we have used CNN to recognize the face and overcome such difficulties. The attendance records will be updated automatically and stored in an excel sheet as well as in a database. We have used MongoDB as a backend database for attendance records.
Faster Convergence of Stochastic Gradient Langevin Dynamics for Non-Log-Concave Sampling
Oct 19, 2020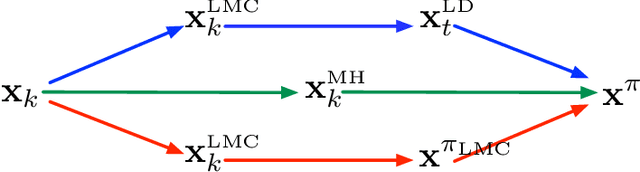
We establish a new convergence analysis of stochastic gradient Langevin dynamics (SGLD) for sampling from a class of distributions that can be non-log-concave. At the core of our approach is a novel conductance analysis of SGLD using an auxiliary time-reversible Markov Chain. Under certain conditions on the target distribution, we prove that $\tilde O(d^4\epsilon^{-2})$ stochastic gradient evaluations suffice to guarantee $\epsilon$-sampling error in terms of the total variation distance, where $d$ is the problem dimension, which improves existing results on the convergence rate of SGLD (Raginsky et al., 2017; Xu et al., 2018). We further show that provided an additional Hessian Lipschitz condition on the log-density function, SGLD is guaranteed to achieve $\epsilon$-sampling error within $\tilde O(d^{15/4}\epsilon^{-3/2})$ stochastic gradient evaluations. Our proof technique provides a new way to study the convergence of Langevin based algorithms, and sheds some light on the design of fast stochastic gradient based sampling algorithms.
Calibrating Self-supervised Monocular Depth Estimation
Sep 16, 2020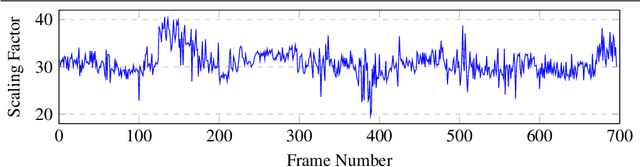

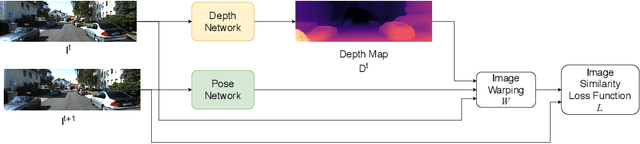
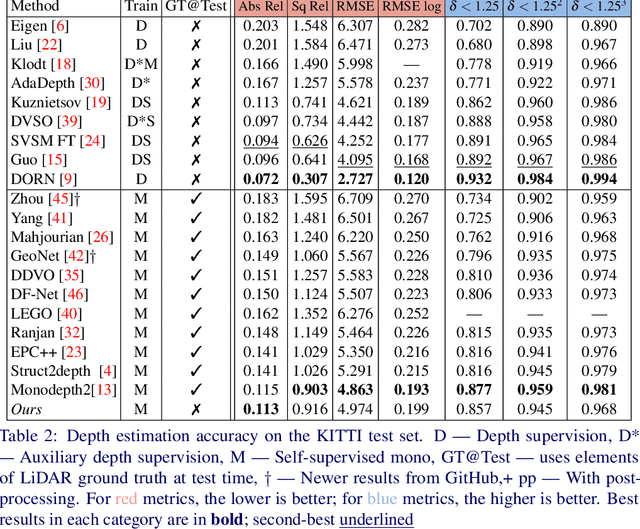
In the recent years, many methods demonstrated the ability of neural networks tolearn depth and pose changes in a sequence of images, using only self-supervision as thetraining signal. Whilst the networks achieve good performance, the often over-lookeddetail is that due to the inherent ambiguity of monocular vision they predict depth up to aunknown scaling factor. The scaling factor is then typically obtained from the LiDARground truth at test time, which severely limits practical applications of these methods.In this paper, we show that incorporating prior information about the camera configu-ration and the environment, we can remove the scale ambiguity and predict depth directly,still using the self-supervised formulation and not relying on any additional sensors.
A Temporal Neural Network Architecture for Online Learning
Nov 27, 2020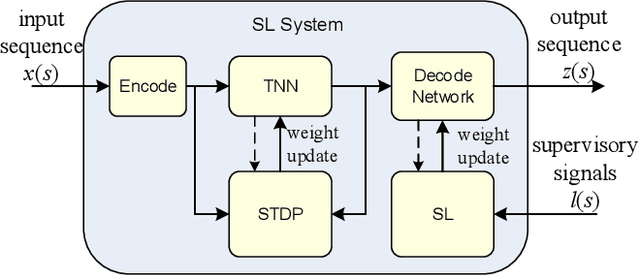

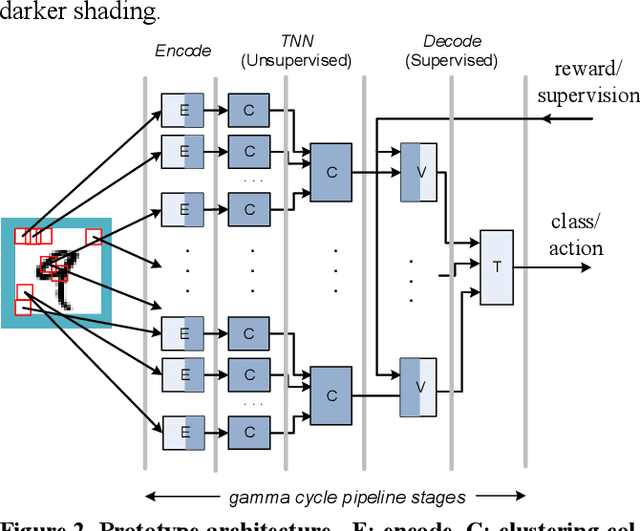

A long-standing proposition is that by emulating the operation of the brain's neocortex, a spiking neural network (SNN) can achieve similar desirable features: flexible learning, speed, and efficiency. Temporal neural networks (TNNs) are SNNs that communicate and process information encoded as relative spike times (in contrast to spike rates). A TNN architecture is proposed, and, as a proof-of-concept, TNN operation is demonstrated within the larger context of online supervised classification. First, through unsupervised learning, a TNN partitions input patterns into clusters based on similarity. The TNN then passes a cluster identifier to a simple online supervised decoder which finishes the classification task. The TNN learning process adjusts synaptic weights by using only signals local to each synapse, and clustering behavior emerges globally. The system architecture is described at an abstraction level analogous to the gate and register transfer levels in conventional digital design. Besides features of the overall architecture, several TNN components are new to this work. Although not addressed directly, the overall research objective is a direct hardware implementation of TNNs. Consequently, all the architecture elements are simple, and processing is done at very low precision. Importantly, low precision leads to very fast learning times. Simulation results using the time-honored MNIST dataset demonstrate learning times at least an order of magnitude faster than other online approaches while providing similar error rates.
Multilayer Network Analysis for Improved Credit Risk Prediction
Oct 19, 2020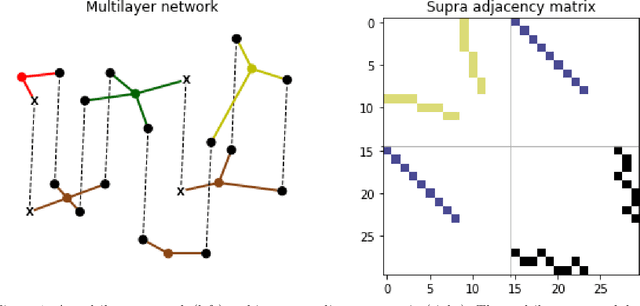
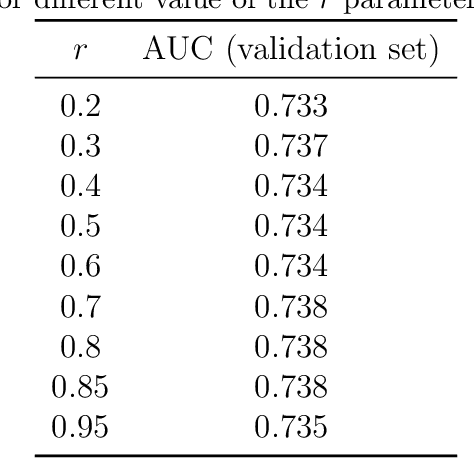
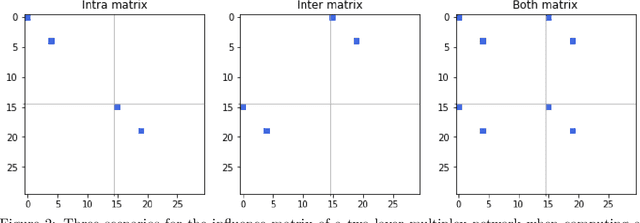
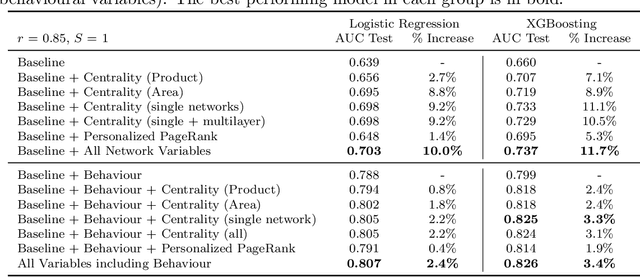
We present a multilayer network model for credit risk assessment. Our model accounts for multiple connections between borrowers (such as their geographic location and their economic activity) and allows for explicitly modelling the interaction between connected borrowers. We develop a multilayer personalized PageRank algorithm that allows quantifying the strength of the default exposure of any borrower in the network. We test our methodology in an agricultural lending framework, where it has been suspected for a long time default correlates between borrowers when they are subject to the same structural risks. Our results show there are significant predictive gains just by including centrality multilayer network information to the model, and this gains are increased by more complex information such as the multilayer PageRank variables. The results suggest default risk is highest when an individual is connected to many defaulters, but this risk is mitigated by the size of the neighbourhood of the individual, showing both default risk and financial stability propagate throughout the network.
CLAR: Contrastive Learning of Auditory Representations
Oct 19, 2020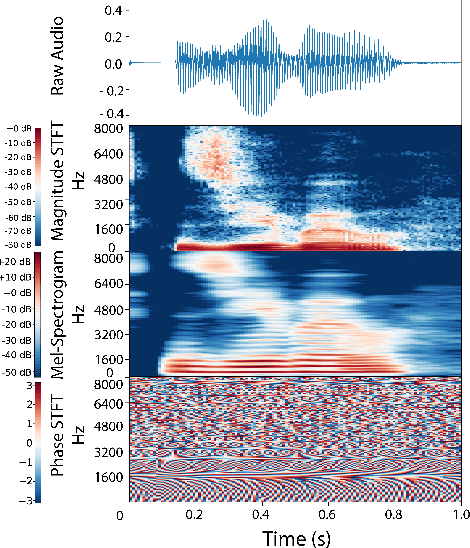
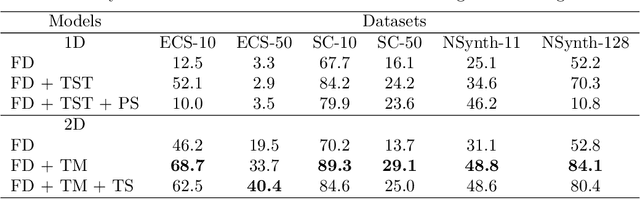
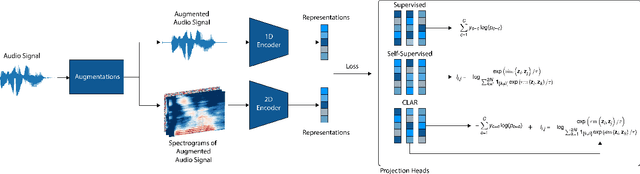
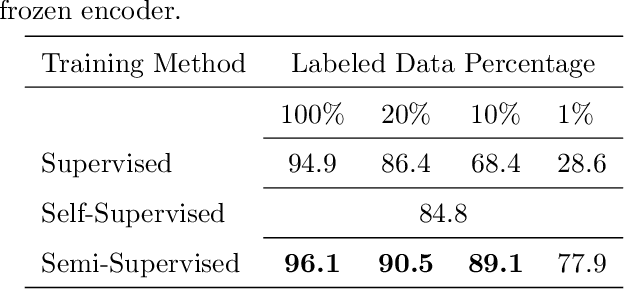
Learning rich visual representations using contrastive self-supervised learning has been extremely successful. However, it is still a major question whether we could use a similar approach to learn superior auditory representations. In this paper, we expand on prior work (SimCLR) to learn better auditory representations. We (1) introduce various data augmentations suitable for auditory data and evaluate their impact on predictive performance, (2) show that training with time-frequency audio features substantially improves the quality of the learned representations compared to raw signals, and (3) demonstrate that training with both supervised and contrastive losses simultaneously improves the learned representations compared to self-supervised pre-training followed by supervised fine-tuning. We illustrate that by combining all these methods and with substantially less labeled data, our framework (CLAR) achieves significant improvement on prediction performance compared to supervised approach. Moreover, compared to self-supervised approach, our framework converges faster with significantly better representations.