 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Attention, please: A Spatio-temporal Transformer for 3D Human Motion Prediction
Apr 18, 2020
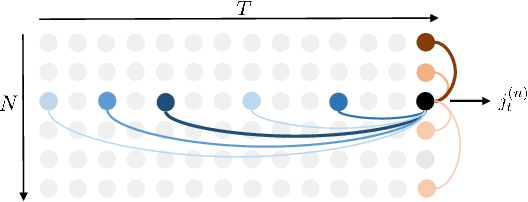
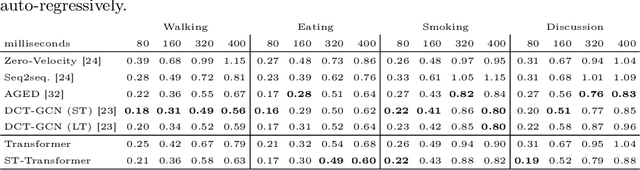
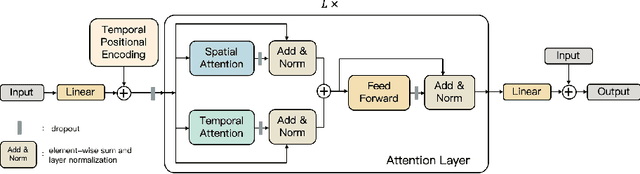

In this paper, we propose a novel architecture for the task of 3D human motion modelling. We argue that the problem can be interpreted as a generative modelling task: A network learns the conditional synthesis of human poses where the model is conditioned on a seed sequence. Our focus lies on the generation of plausible future developments over longer time horizons, whereas previous work considered shorter time frames of up to 1 second. To mitigate the issue of convergence to a static pose, we propose a novel architecture that leverages the recently proposed self-attention concept. The task of 3D motion prediction is inherently spatio-temporal and thus the proposed model learns high dimensional joint embeddings followed by a decoupled temporal and spatial self-attention mechanism. The two attention blocks operate in parallel to aggregate the most informative components of the sequence to update the joint representation. This allows the model to access past information directly and to capture spatio-temporal dependencies explicitly. We show empirically that this reduces error accumulation over time and allows for the generation of perceptually plausible motion sequences over long time horizons as well as accurate short-term predictions. Accompanying video available at https://youtu.be/yF0cdt2yCNE .
Incorporating Machine Learning to Evaluate Solutions to the University Course Timetabling Problem
Oct 02, 2020


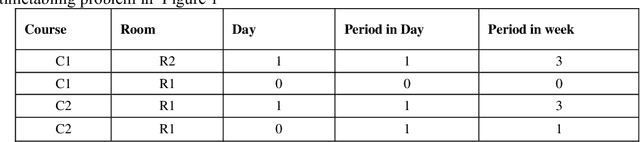
Evaluating solutions to optimization problems is arguably the most important step for heuristic algorithms, as it is used to guide the algorithms towards the optimal solution in the solution search space. Research has shown evaluation functions to some optimization problems to be impractical to compute and have thus found surrogate less expensive evaluation functions to those problems. This study investigates the extent to which supervised learning algorithms can be used to find approximations to evaluation functions for the university course timetabling problem. Up to 97 percent of the time, the traditional evaluation function agreed with the supervised learning regression model on the result of comparison of the quality of pair of solutions to the university course timetabling problem, suggesting that supervised learning regression models can be suitable alternatives for optimization problems' evaluation functions.
Public Announcement Logic in HOL
Oct 02, 2020A shallow semantical embedding for public announcement logic with relativized common knowledge is presented. This embedding enables the first-time automation of this logic with off-the-shelf theorem provers for classical higher-order logic. It is demonstrated (i) how meta-theoretical studies can be automated this way, and (ii) how non-trivial reasoning in the target logic (public announcement logic), required e.g. to obtain a convincing encoding and automation of the wise men puzzle, can be realized. Key to the presented semantical embedding -- in contrast, e.g., to related work on the semantical embedding of normal modal logics -- is that evaluation domains are modeled explicitly and treated as additional parameter in the encodings of the constituents of the embedded target logic, while they were previously implicitly shared between meta logic and target logic.
Multi-Label Classification Using Link Prediction
Nov 11, 2020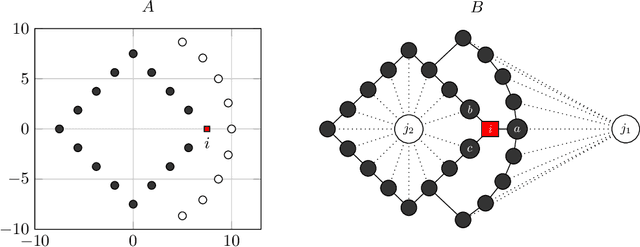
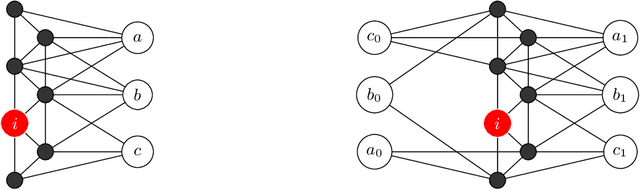

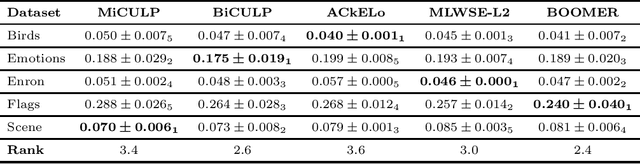
Solving classification with graph methods has gained huge popularity in recent years. This is due to the fact that the data can be intuitively modeled with graphs to utilize high level features to aid in solving the classification problem. CULP which is short for Classification Using Link Prediction is a graph-based classifier. This classifier utilizes the graph representation of the data and transforms the problem to that of link prediction where we try to find the link between an unlabeled node and the proper class node for it. CULP proved to be highly accurate classifier and it has the power to predict the labels in near constant time. A variant of the classification problem is multi-label classification which tackles this problem for multi-label data where an instance can have multiple labels associated to it. In this work, we extend the CULP algorithm to address this problem. Our proposed extensions conveys the powers of CULP and its intuitive representation of the data in to the multi-label domain and in comparison to some of the cutting edge multi-label classifiers, yield competitive results.
Deep Learning to Detect Bacterial Colonies for the Production of Vaccines
Sep 02, 2020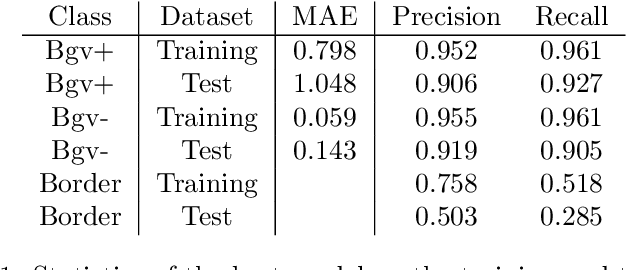
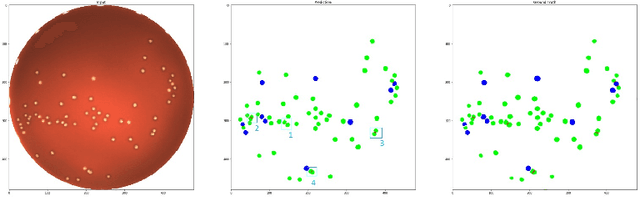
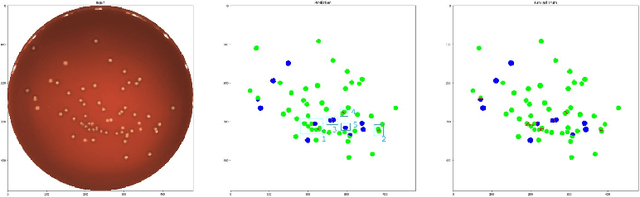
During the development of vaccines, bacterial colony forming units (CFUs) are counted in order to quantify the yield in the fermentation process. This manual task is time-consuming and error-prone. In this work we test multiple segmentation algorithms based on the U-Net CNN architecture and show that these offer robust, automated CFU counting. We show that the multiclass generalisation with a bespoke loss function allows distinguishing virulent and avirulent colonies with acceptable accuracy. While many possibilities are left to explore, our results show the potential of deep learning for separating and classifying bacterial colonies.
The polysemy of the words that children learn over time
Nov 27, 2016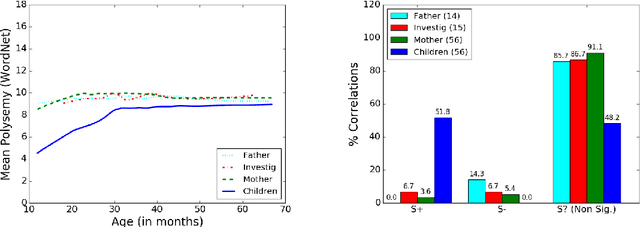
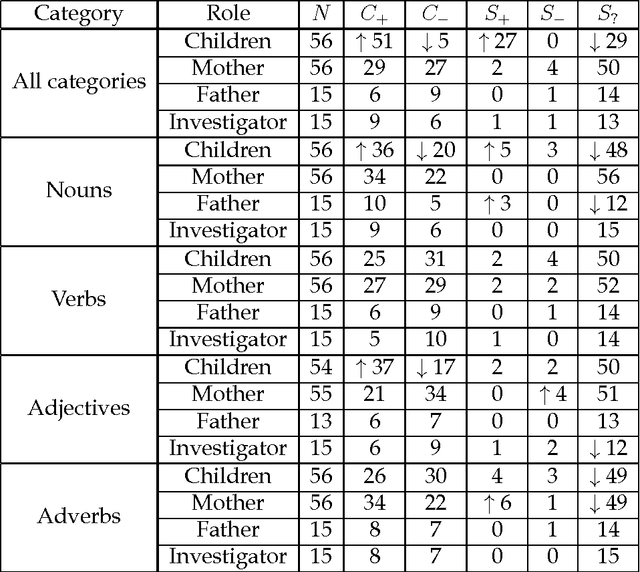
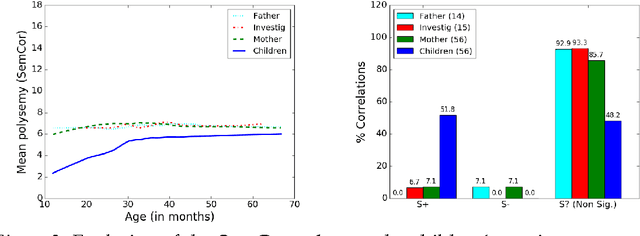
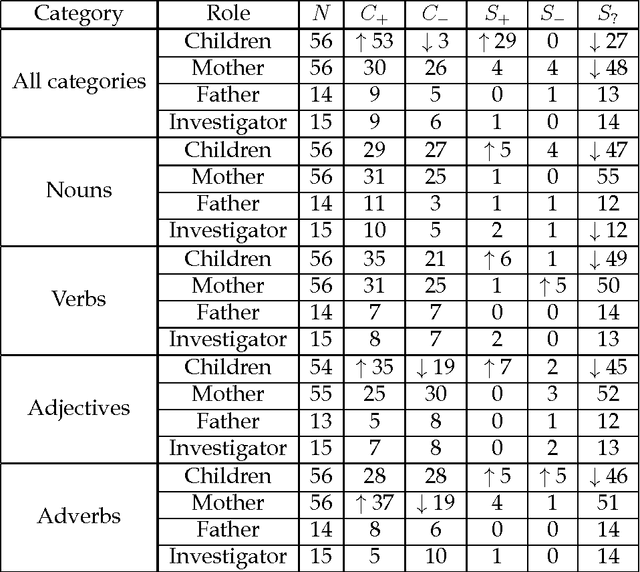
Here we study polysemy as a potential learning bias in vocabulary learning in children. We employ a massive set of transcriptions of conversations between children and adults in English, to analyze the evolution of mean polysemy in the words produced by children whose ages range between 10 and 60 months. Our results show that mean polysemy in children increases over time in two phases, i.e. a fast growth till the 31st month followed by a slower tendency towards adult speech. In contrast, no dependency with time is found in adults. This suggests that children have a preference for non-polysemous words in their early stages of vocabulary acquisition. Our hypothesis is twofold: (a) polysemy is a standalone bias or (b) polysemy is a side-effect of other biases. Interestingly, the bias for low polysemy described above weakens when controlling for syntactic category (noun, verb, adjective or adverb). The pattern of the evolution of polysemy suggests that both hypotheses may apply to some extent, and that (b) would originate from a combination of the well-known preference for nouns and the lower polysemy of nouns with respect to other syntactic categories.
CharacterBERT: Reconciling ELMo and BERT for Word-Level Open-Vocabulary Representations From Characters
Oct 31, 2020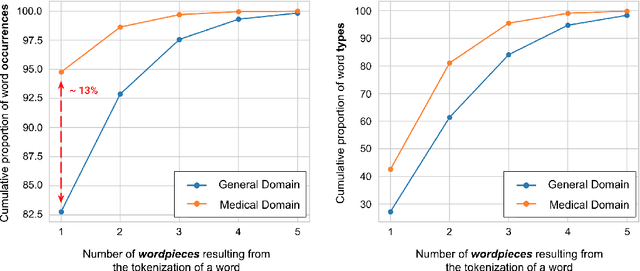

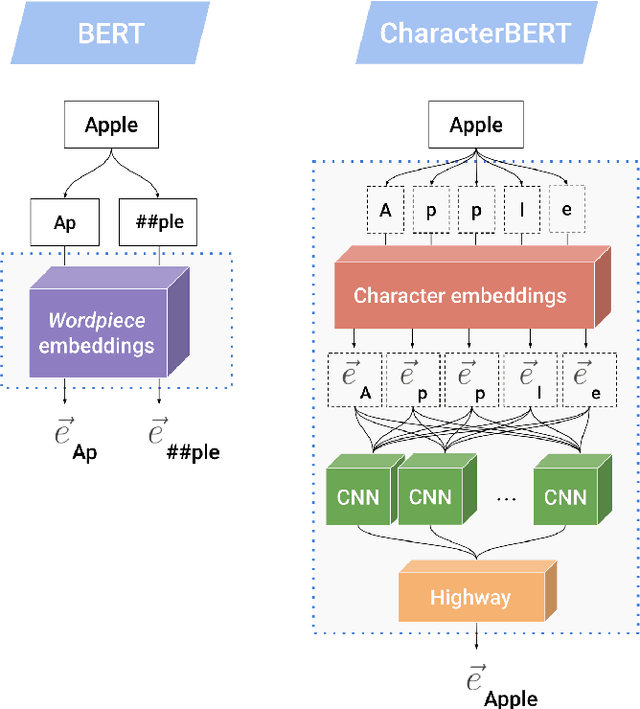
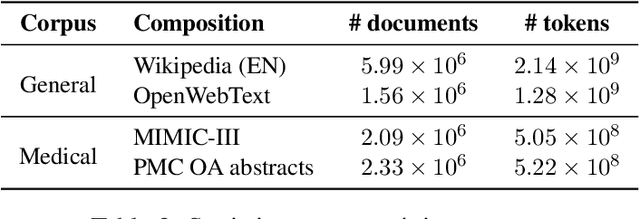
Due to the compelling improvements brought by BERT, many recent representation models adopted the Transformer architecture as their main building block, consequently inheriting the wordpiece tokenization system despite it not being intrinsically linked to the notion of Transformers. While this system is thought to achieve a good balance between the flexibility of characters and the efficiency of full words, using predefined wordpiece vocabularies from the general domain is not always suitable, especially when building models for specialized domains (e.g., the medical domain). Moreover, adopting a wordpiece tokenization shifts the focus from the word level to the subword level, making the models conceptually more complex and arguably less convenient in practice. For these reasons, we propose CharacterBERT, a new variant of BERT that drops the wordpiece system altogether and uses a Character-CNN module instead to represent entire words by consulting their characters. We show that this new model improves the performance of BERT on a variety of medical domain tasks while at the same time producing robust, word-level and open-vocabulary representations.
CLIPPER: A Graph-Theoretic Framework for Robust Data Association
Nov 20, 2020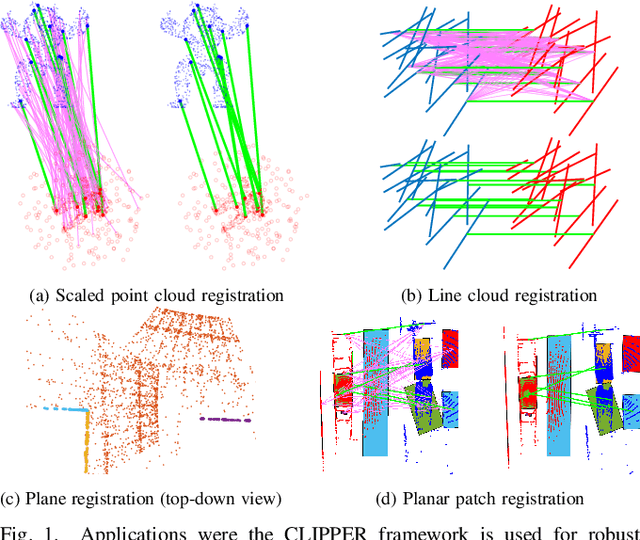

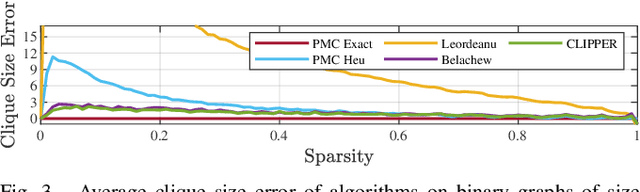
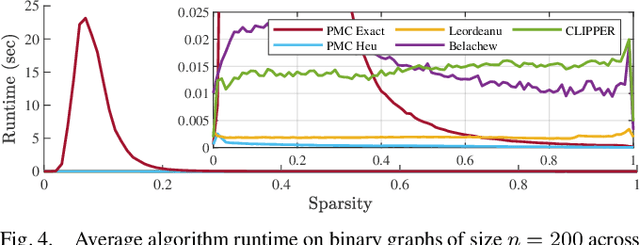
We present CLIPPER (Consistent LInking, Pruning, and Pairwise Error Rectification), a framework for robust data association in the presence of noise and outliers. We formulate the problem in a graph-theoretic framework using the notion of geometric consistency. State-of-the-art techniques that use this framework utilize either combinatorial optimization techniques that do not scale well to large-sized problems, or use heuristic approximations that yield low accuracy in high-noise, high-outlier regimes. In contrast, CLIPPER uses a relaxation of the combinatorial problem and returns solutions that are guaranteed to correspond to the optima of the original problem. Low time complexity is achieved with an efficient projected gradient ascent approach. Experiments indicate that CLIPPER maintains a consistently low runtime of 15 ms where exact methods can require up to 24 s at their peak, even on small-sized problems with 200 associations. When evaluated on noisy point cloud registration problems, CLIPPER achieves 100% precision and 98% recall in 90% outlier regimes while competing algorithms begin degrading by 70% outliers. In an instance of associating noisy points of the Stanford Bunny with 990 outlier associations and only 10 inlier associations, CLIPPER successfully returns 8 inlier associations with 100% precision in 138 ms.
An Ordered Lasso and Sparse Time-Lagged Regression
Jun 03, 2014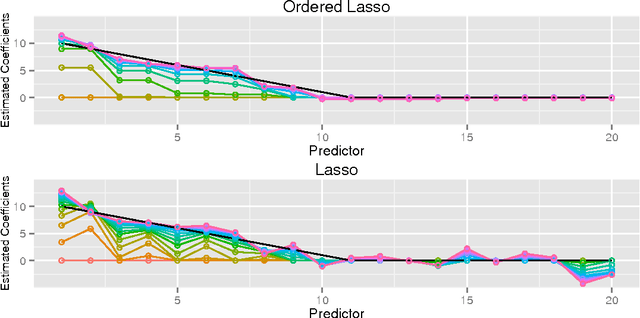
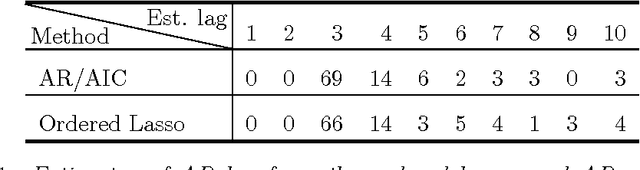
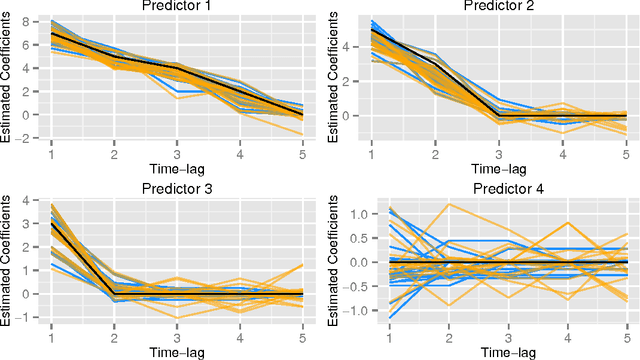
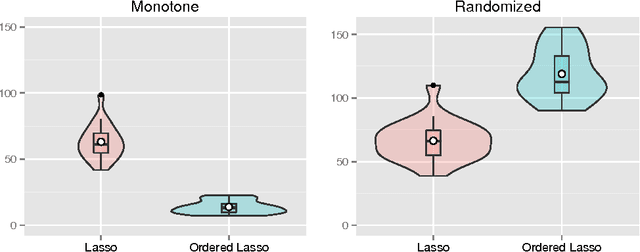
We consider regression scenarios where it is natural to impose an order constraint on the coefficients. We propose an order-constrained version of L1-regularized regression for this problem, and show how to solve it efficiently using the well-known Pool Adjacent Violators Algorithm as its proximal operator. The main application of this idea is time-lagged regression, where we predict an outcome at time t from features at the previous K time points. In this setting it is natural to assume that the coefficients decay as we move farther away from t, and hence the order constraint is reasonable. Potential applications include financial time series and prediction of dynamic patient out- comes based on clinical measurements. We illustrate this idea on real and simulated data.
Deep Learning Towards Edge Computing: Neural Networks Straight from Compressed Data
Dec 26, 2020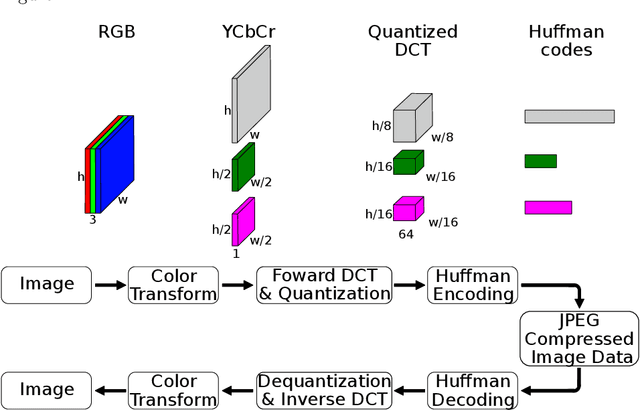
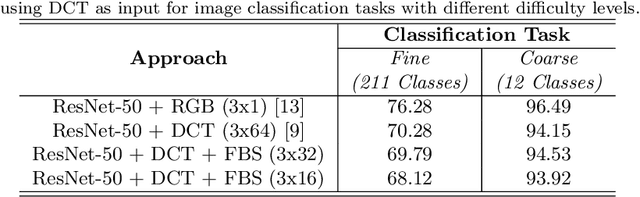
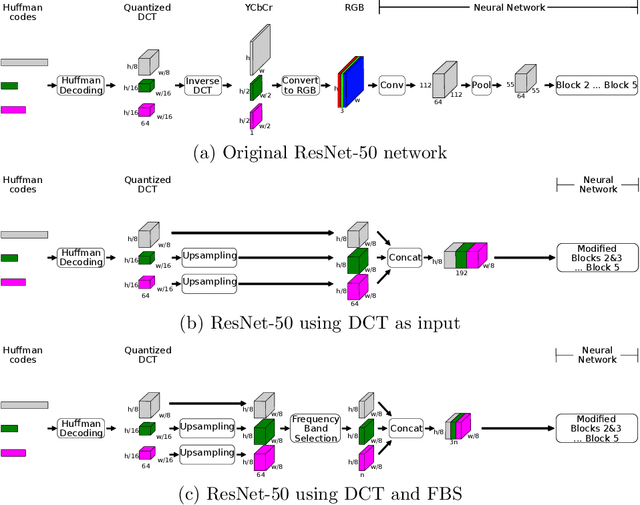
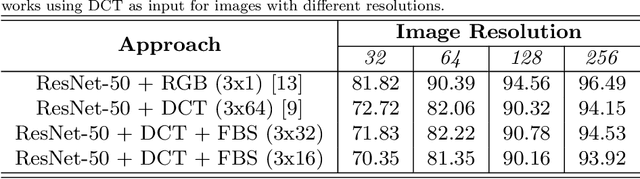
Due to the popularization and grow in computational power of mobile phones, as well as advances in artificial intelligence, many intelligent applications have been developed, meaningfully enriching people's life. For this reason, there is a growing interest in the area of edge intelligence, that aims to push the computation of data to the edges of the network, in order to make those applications more efficient and secure. Many intelligent applications rely on deep learning models, like convolutional neural networks (CNNs). Over the past decade, they have achieved state-of-the-art performance in many computer vision tasks. To increase the performance of these methods, the trend has been to use increasingly deeper architectures and with more parameters, leading to a high computational cost. Indeed, this is one of the main problems faced by deep architectures, limiting their applicability in domains with limited computational resources, like edge devices. To alleviate the computational complexity, we propose a deep neural network capable of learning straight from the relevant information pertaining to visual content readily available in the compressed representation used for image and video storage and transmission. The novelty of our approach is that it was designed to operate directly on frequency domain data, learning with DCT coefficients rather than RGB pixels. This enables to save high computational load in full decoding the data stream and therefore greatly speed up the processing time, which has become a big bottleneck of deep learning. We evaluated our network on two challenging tasks: (1) image classification on the ImageNet dataset and (2) video classification on the UCF-101 and HMDB-51 datasets. Our results demonstrate comparable effectiveness to the state-of-the-art methods in terms of accuracy, with the advantage of being more computationally efficient.