 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
LMB Filter Based Tracking Allowing for Multiple Hypotheses in Object Reference Point Association*
Nov 11, 2020

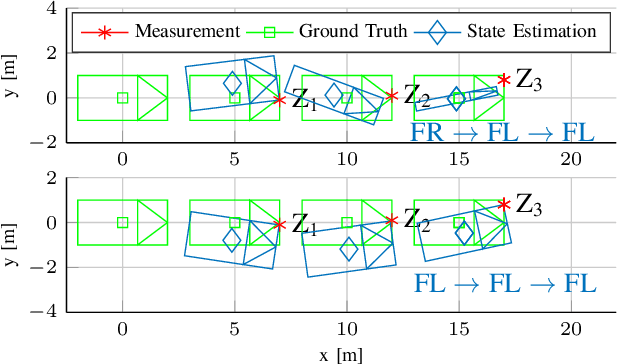
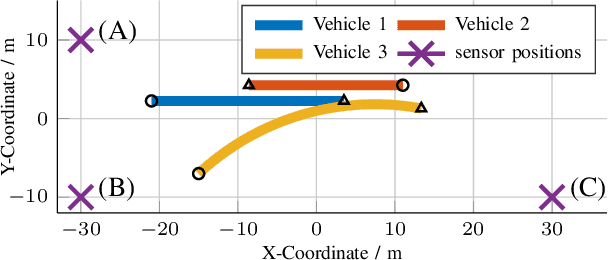
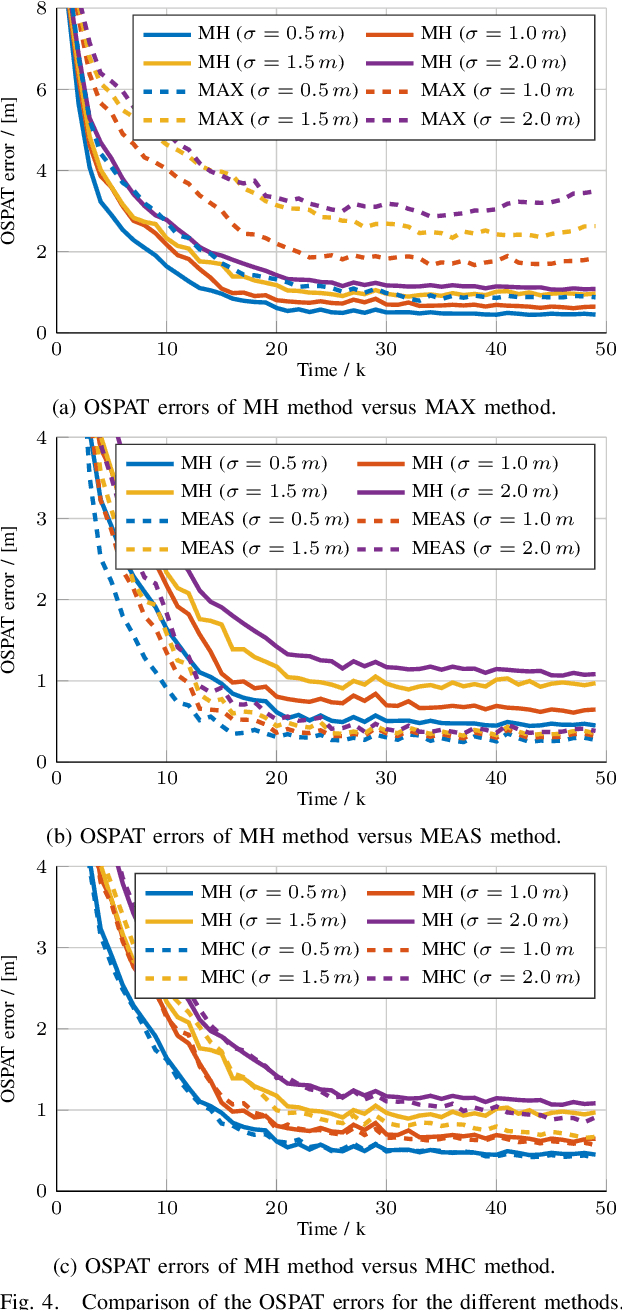
Autonomous vehicles need precise knowledge on dynamic objects in their surroundings. Especially in urban areas with many objects and possible occlusions, an infrastructure system based on a multi-sensor setup can provide the required environment model for the vehicles. Previously, we have published a concept of object reference points (e.g. the corners of an object), which allows for generic sensor "plug and play" interfaces and relatively cheap sensors. This paper describes a novel method to additionally incorporate multiple hypotheses for fusing the measurements of the object reference points using an extension to the previously presented Labeled Multi-Bernoulli (LMB) filter. In contrast to the previous work, this approach improves the tracking quality in the cases where the correct association of the measurement and the object reference point is unknown. Furthermore, this paper identifies options based on physical models to sort out inconsistent and unfeasible associations at an early stage in order to keep the method computationally tractable for real-time applications. The method is evaluated on simulations as well as on real scenarios. In comparison to comparable methods, the proposed approach shows a considerable performance increase, especially the number of non-continuous tracks is decreased significantly.
Efficient Neural Architecture Search for End-to-end Speech Recognition via Straight-Through Gradients
Nov 11, 2020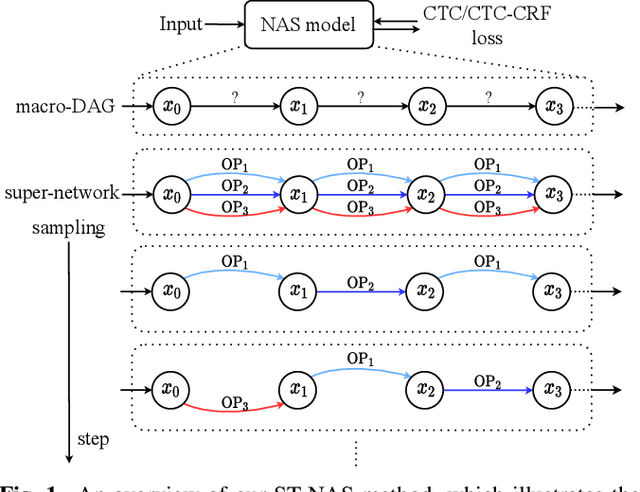
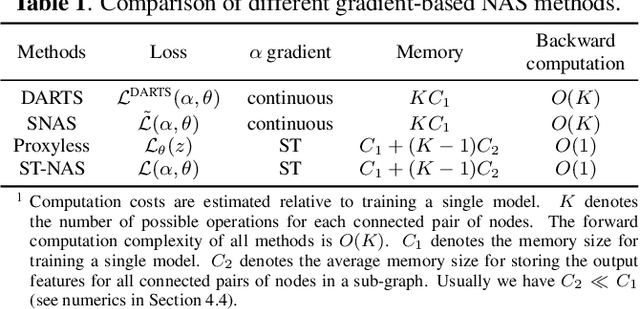
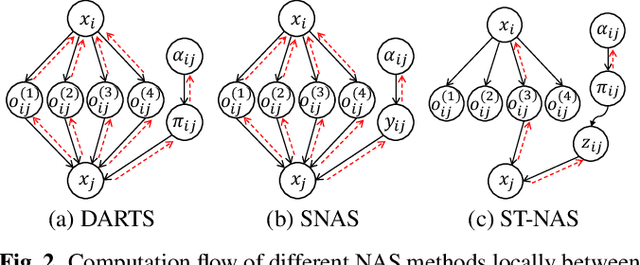
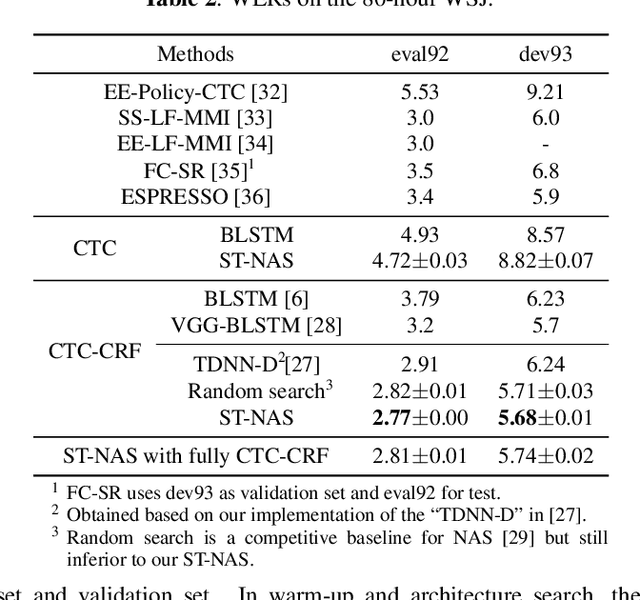
Neural Architecture Search (NAS), the process of automating architecture engineering, is an appealing next step to advancing end-to-end Automatic Speech Recognition (ASR), replacing expert-designed networks with learned, task-specific architectures. In contrast to early computational-demanding NAS methods, recent gradient-based NAS methods, e.g., DARTS (Differentiable ARchiTecture Search), SNAS (Stochastic NAS) and ProxylessNAS, significantly improve the NAS efficiency. In this paper, we make two contributions. First, we rigorously develop an efficient NAS method via Straight-Through (ST) gradients, called ST-NAS. Basically, ST-NAS uses the loss from SNAS but uses ST to back-propagate gradients through discrete variables to optimize the loss, which is not revealed in ProxylessNAS. Using ST gradients to support sub-graph sampling is a core element to achieve efficient NAS beyond DARTS and SNAS. Second, we successfully apply ST-NAS to end-to-end ASR. Experiments over the widely benchmarked 80-hour WSJ and 300-hour Switchboard datasets show that the ST-NAS induced architectures significantly outperform the human-designed architecture across the two datasets. Strengths of ST-NAS such as architecture transferability and low computation cost in memory and time are also reported.
Conjunctive Queries: Unique Characterizations and Exact Learnability
Aug 16, 2020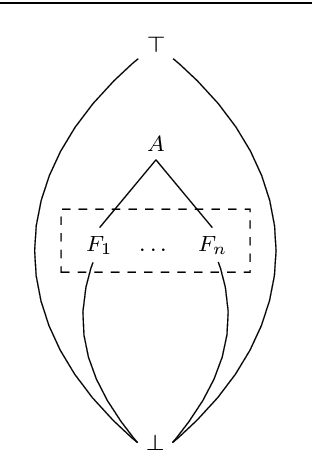
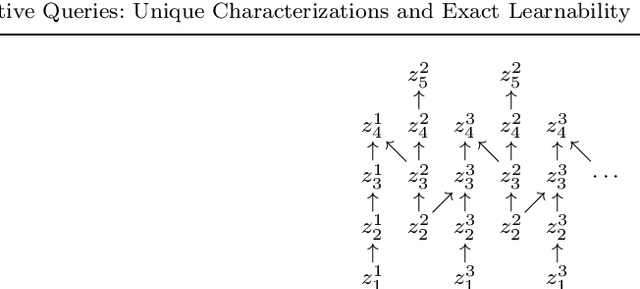
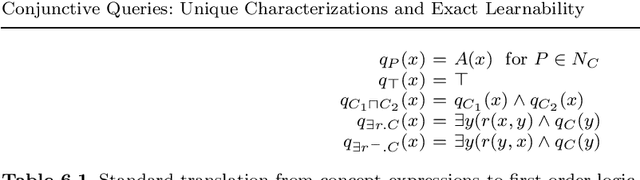

We answer the question which conjunctive queries are uniquely characterized by polynomially many positive and negative examples, and how to construct such examples efficiently. As a consequence, we obtain a new efficient exact learning algorithm for a class of conjunctive queries. At the core of our contributions lie two new polynomial-time algorithms for constructing frontiers in the homomorphism lattice of finite structures. We also discuss implications for the unique characterizability and learnability of schema mappings and of description logic concepts.
DATE: Defense Against TEmperature Side-Channel Attacks in DVFS Enabled MPSoCs
Jul 02, 2020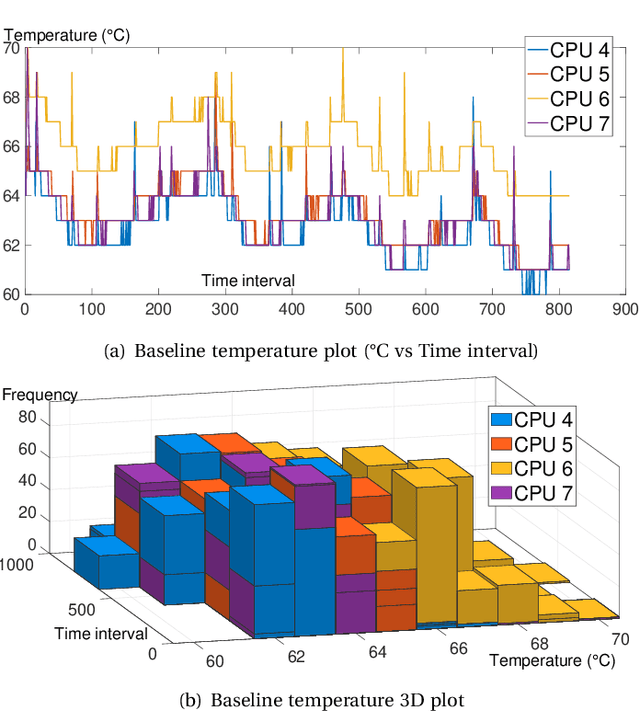
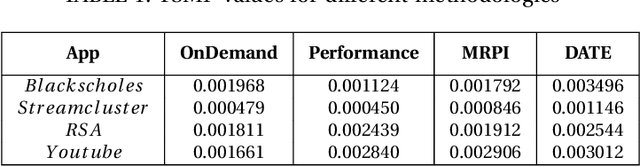
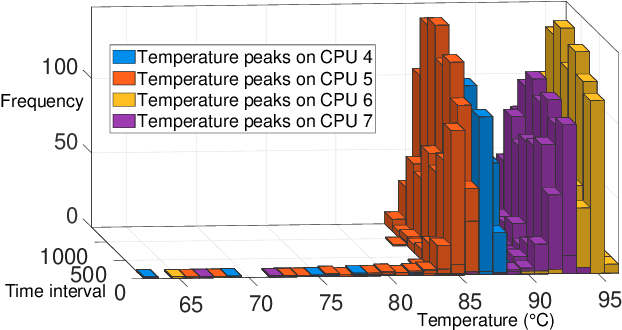
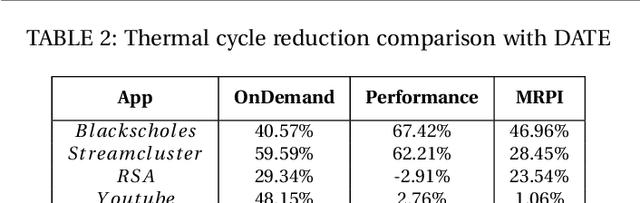
Given the constant rise in utilizing embedded devices in daily life, side channels remain a challenge to information flow control and security in such systems. One such important security flaw could be exploited through temperature side-channel attacks, where heat dissipation and propagation from the processing elements are observed over time in order to deduce security flaws. In our proposed methodology, DATE: Defense Against TEmperature side-channel attacks, we propose a novel approach of reducing spatial and temporal thermal gradient, which makes the system more secure against temperature side-channel attacks, and at the same time increases the reliability of the device in terms of lifespan. In this paper, we have also introduced a new metric, Thermal-Security-in-Multi-Processors (TSMP), which is capable of quantifying the security against temperature side-channel attacks on computing systems, and DATE is evaluated to be 139.24% more secure at the most for certain applications than the state-of-the-art, while reducing thermal cycle by 67.42% at the most.
Attention, please: A Spatio-temporal Transformer for 3D Human Motion Prediction
Apr 18, 2020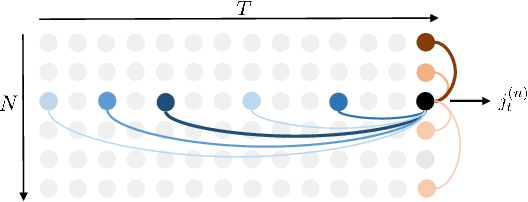
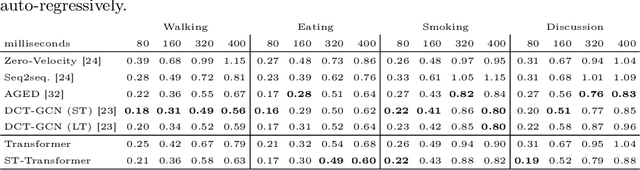
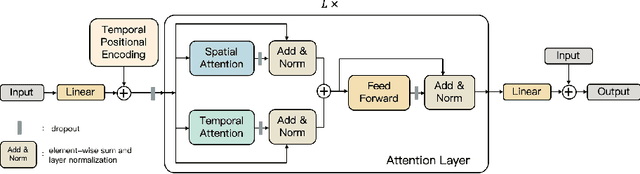

In this paper, we propose a novel architecture for the task of 3D human motion modelling. We argue that the problem can be interpreted as a generative modelling task: A network learns the conditional synthesis of human poses where the model is conditioned on a seed sequence. Our focus lies on the generation of plausible future developments over longer time horizons, whereas previous work considered shorter time frames of up to 1 second. To mitigate the issue of convergence to a static pose, we propose a novel architecture that leverages the recently proposed self-attention concept. The task of 3D motion prediction is inherently spatio-temporal and thus the proposed model learns high dimensional joint embeddings followed by a decoupled temporal and spatial self-attention mechanism. The two attention blocks operate in parallel to aggregate the most informative components of the sequence to update the joint representation. This allows the model to access past information directly and to capture spatio-temporal dependencies explicitly. We show empirically that this reduces error accumulation over time and allows for the generation of perceptually plausible motion sequences over long time horizons as well as accurate short-term predictions. Accompanying video available at https://youtu.be/yF0cdt2yCNE .
Learning Efficient Representations of Mouse Movements to Predict User Attention
May 30, 2020
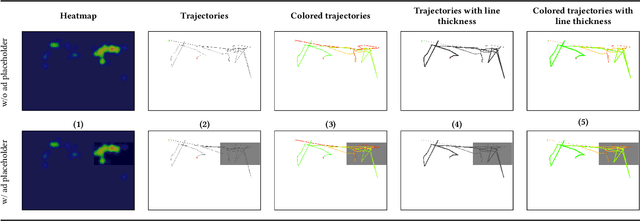
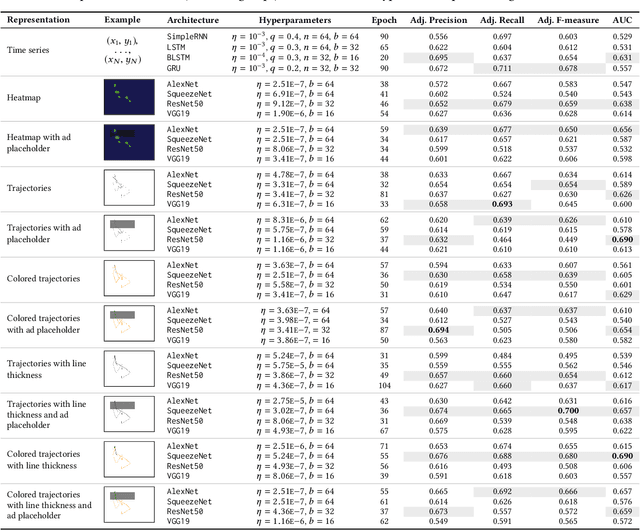
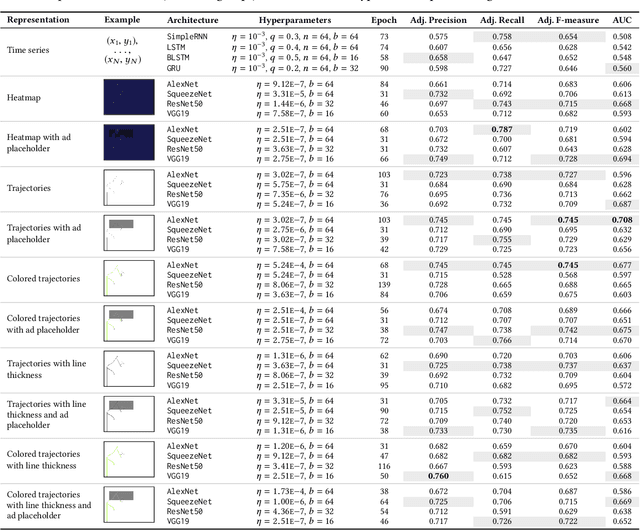
Tracking mouse cursor movements can be used to predict user attention on heterogeneous page layouts like SERPs. So far, previous work has relied heavily on handcrafted features, which is a time-consuming approach that often requires domain expertise. We investigate different representations of mouse cursor movements, including time series, heatmaps, and trajectory-based images, to build and contrast both recurrent and convolutional neural networks that can predict user attention to direct displays, such as SERP advertisements. Our models are trained over raw mouse cursor data and achieve competitive performance. We conclude that neural network models should be adopted for downstream tasks involving mouse cursor movements, since they can provide an invaluable implicit feedback signal for re-ranking and evaluation.
* arXiv admin note: text overlap with arXiv:2001.07803
A Visual Language for Composable Inductive Programming
Sep 18, 2020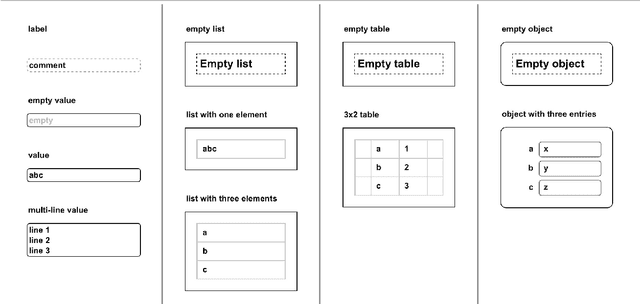

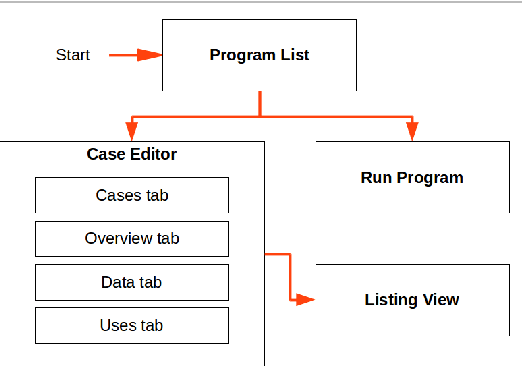
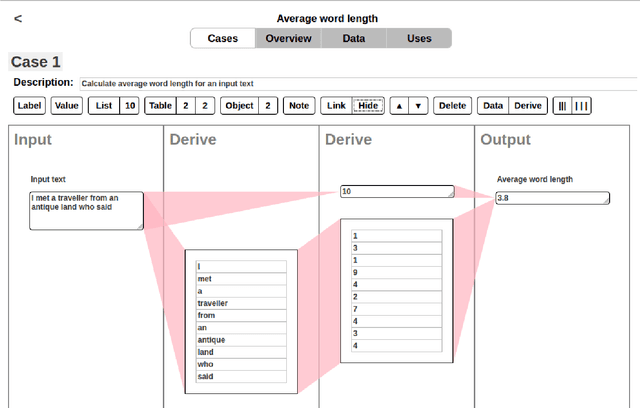
We present Zoea Visual which is a visual programming language based on the Zoea composable inductive programming language. Zoea Visual allows users to create software directly from a specification that resembles a set of functional test cases. Programming with Zoea Visual involves the definition of a data flow model of test case inputs, optional intermediate values, and outputs. Data elements are represented visually and can be combined to create structures of any complexity. Data flows between elements provide additional information that allows the Zoea compiler to generate larger programs in less time. This paper includes an overview of the language. The benefits of the approach and some possible future enhancements are also discussed.
Non-Attentive Tacotron: Robust and Controllable Neural TTS Synthesis Including Unsupervised Duration Modeling
Oct 08, 2020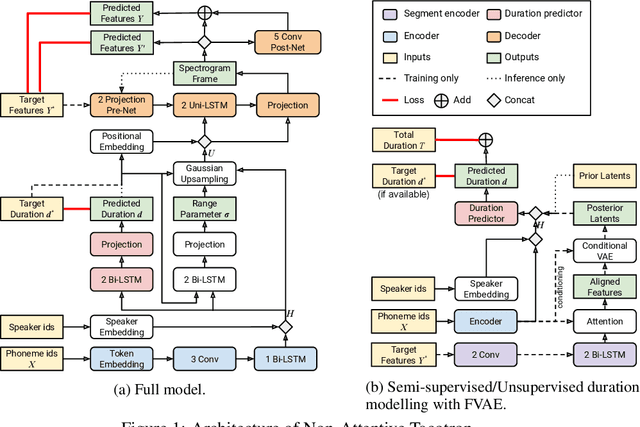

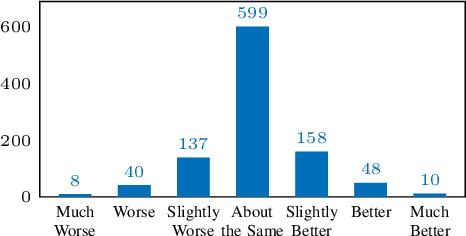

This paper presents Non-Attentive Tacotron based on the Tacotron 2 text-to-speech model, replacing the attention mechanism with an explicit duration predictor. This improves robustness significantly as measured by unaligned duration ratio and word deletion rate, two metrics introduced in this paper for large-scale robustness evaluation using a pre-trained speech recognition model. With the use of Gaussian upsampling, Non-Attentive Tacotron achieves a 5-scale mean opinion score for naturalness of 4.41, slightly outperforming Tacotron 2. The duration predictor enables both utterance-wide and per-phoneme control of duration at inference time. When accurate target durations are scarce or unavailable in the training data, we propose a method using a fine-grained variational auto-encoder to train the duration predictor in a semi-supervised or unsupervised manner, with results almost as good as supervised training.
Accelerating Probabilistic Volumetric Mapping using Ray-Tracing Graphics Hardware
Nov 20, 2020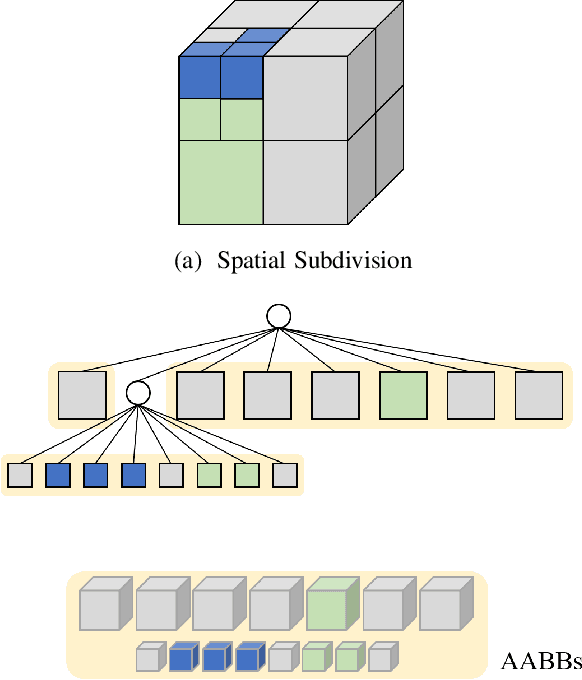
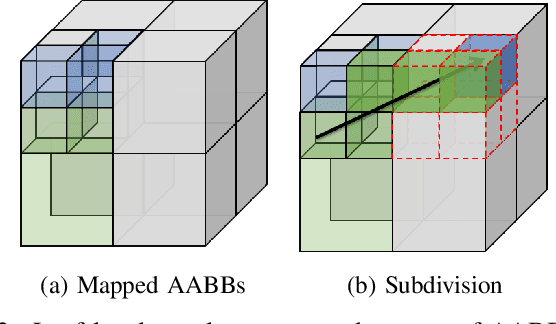
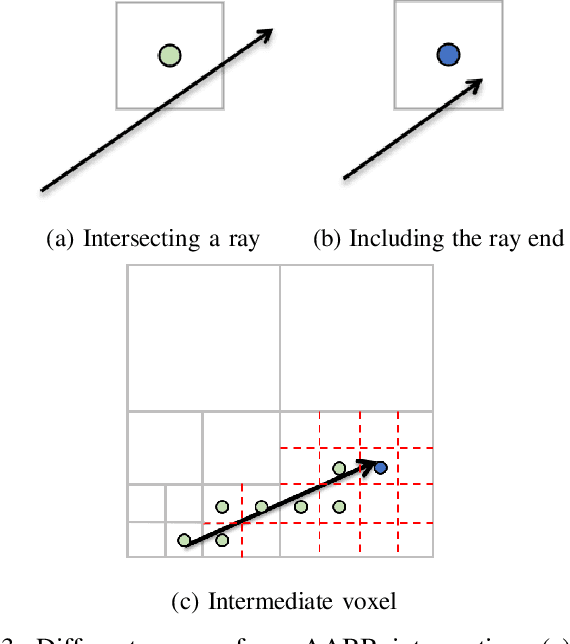
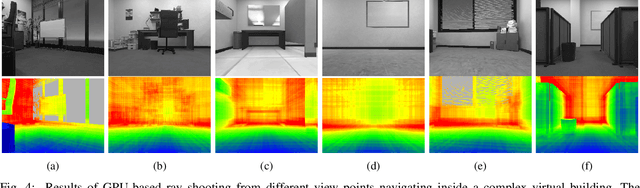
Probabilistic volumetric mapping (PVM) represents a 3D environmental map for an autonomous robotic navigational task. A popular implementation such as Octomap is widely used in the robotics community for such a purpose. The Octomap relies on octree to represent a PVM and its main bottleneck lies in massive ray-shooting to determine the occupancy of the underlying volumetric voxel grids. In this paper, we propose GPU-based ray shooting to drastically improve the ray shooting performance in Octomap. Our main idea is based on the use of recent ray-tracing RTX GPU, mainly designed for real-time photo-realistic computer graphics and the accompanying graphics API, known as DXR. Our ray-shooting first maps leaf-level voxels in the given octree to a set of axis-aligned bounding boxes (AABBs) and employ massively parallel ray shooting on them using GPUs to find free and occupied voxels. These are fed back into CPU to update the voxel occupancy and restructure the octree. In our experiments, we have observed more than three-orders-of-magnitude performance improvement in terms of ray shooting using ray-tracing RTX GPU over a state-of-the-art Octomap CPU implementation, where the benchmarking environments consist of more than 77K points and 25K~34K voxel grids.
Identifying Properties of Real-World Optimisation Problems through a Questionnaire
Nov 11, 2020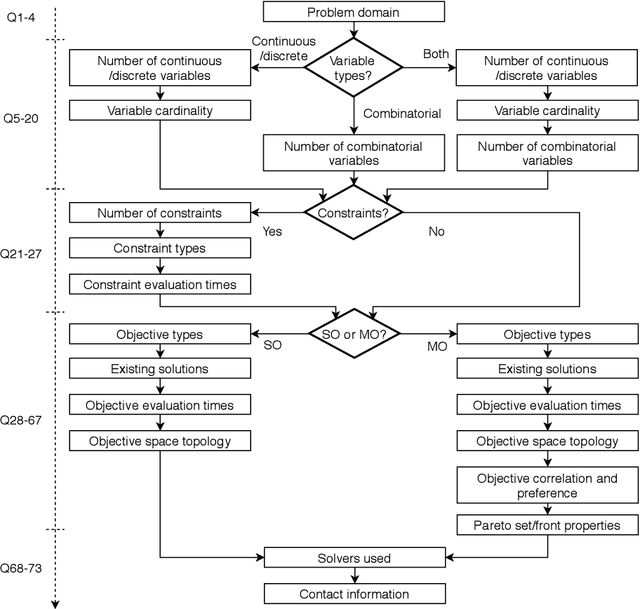
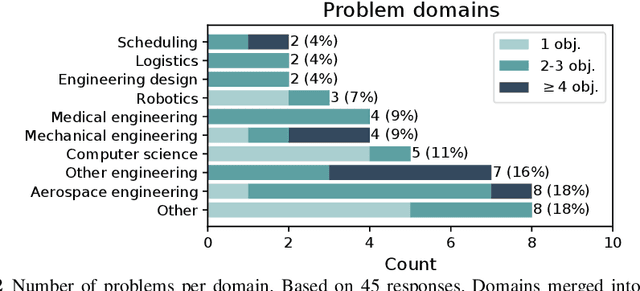
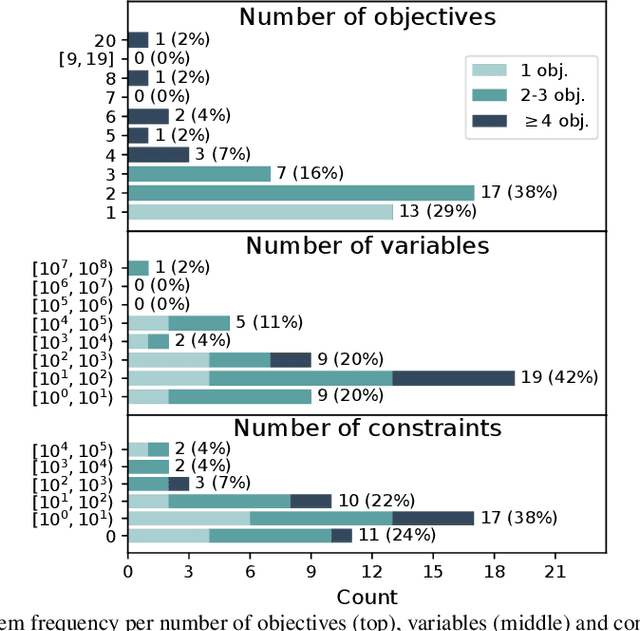
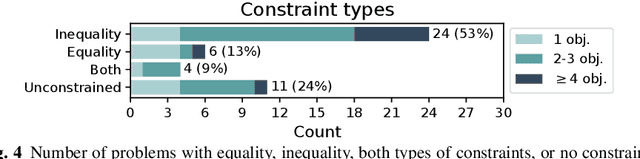
Optimisation algorithms are commonly compared on benchmarks to get insight into performance differences. However, it is not clear how closely benchmarks match the properties of real-world problems because these properties are largely unknown. This work investigates the properties of real-world problems through a questionnaire to enable the design of future benchmark problems that more closely resemble those found in the real world. The results, while not representative, show that many problems possess at least one of the following properties: they are constrained, deterministic, have only continuous variables, require substantial computation times for both the objectives and the constraints, or allow a limited number of evaluations. Properties like known optimal solutions and analytical gradients are rarely available, limiting the options in guiding the optimisation process. These are all important aspects to consider when designing realistic benchmark problems. At the same time, objective functions are often reported to be black-box and since many problem properties are unknown the design of realistic benchmarks is difficult. To further improve the understanding of real-world problems, readers working on a real-world optimisation problem are encouraged to fill out the questionnaire: https://tinyurl.com/opt-survey