 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
IIRC: Incremental Implicitly-Refined Classification
Dec 23, 2020
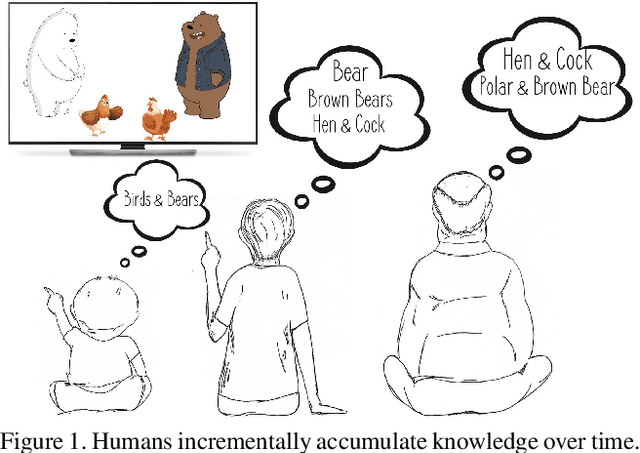

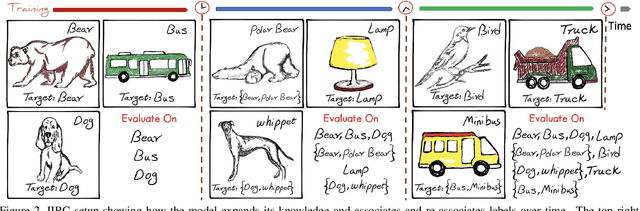

We introduce the "Incremental Implicitly-Refined Classi-fication (IIRC)" setup, an extension to the class incremental learning setup where the incoming batches of classes have two granularity levels. i.e., each sample could have a high-level (coarse) label like "bear" and a low-level (fine) label like "polar bear". Only one label is provided at a time, and the model has to figure out the other label if it has already learnfed it. This setup is more aligned with real-life scenarios, where a learner usually interacts with the same family of entities multiple times, discovers more granularity about them, while still trying not to forget previous knowledge. Moreover, this setup enables evaluating models for some important lifelong learning challenges that cannot be easily addressed under the existing setups. These challenges can be motivated by the example "if a model was trained on the class bear in one task and on polar bear in another task, will it forget the concept of bear, will it rightfully infer that a polar bear is still a bear? and will it wrongfully associate the label of polar bear to other breeds of bear?". We develop a standardized benchmark that enables evaluating models on the IIRC setup. We evaluate several state-of-the-art lifelong learning algorithms and highlight their strengths and limitations. For example, distillation-based methods perform relatively well but are prone to incorrectly predicting too many labels per image. We hope that the proposed setup, along with the benchmark, would provide a meaningful problem setting to the practitioners
Online Learning Demands in Max-min Fairness
Dec 15, 2020

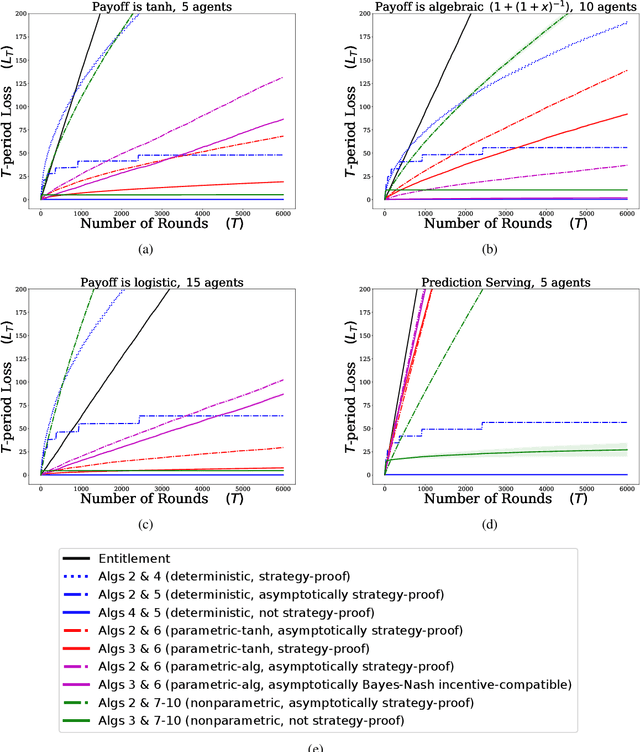
We describe mechanisms for the allocation of a scarce resource among multiple users in a way that is efficient, fair, and strategy-proof, but when users do not know their resource requirements. The mechanism is repeated for multiple rounds and a user's requirements can change on each round. At the end of each round, users provide feedback about the allocation they received, enabling the mechanism to learn user preferences over time. Such situations are common in the shared usage of a compute cluster among many users in an organisation, where all teams may not precisely know the amount of resources needed to execute their jobs. By understating their requirements, users will receive less than they need and consequently not achieve their goals. By overstating them, they may siphon away precious resources that could be useful to others in the organisation. We formalise this task of online learning in fair division via notions of efficiency, fairness, and strategy-proofness applicable to this setting, and study this problem under three types of feedback: when the users' observations are deterministic, when they are stochastic and follow a parametric model, and when they are stochastic and nonparametric. We derive mechanisms inspired by the classical max-min fairness procedure that achieve these requisites, and quantify the extent to which they are achieved via asymptotic rates. We corroborate these insights with an experimental evaluation on synthetic problems and a web-serving task.
Exploring Deep 3D Spatial Encodings for Large-Scale 3D Scene Understanding
Nov 29, 2020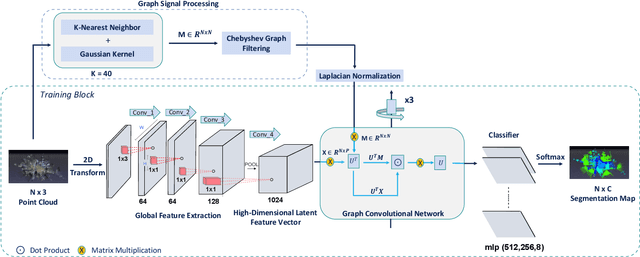
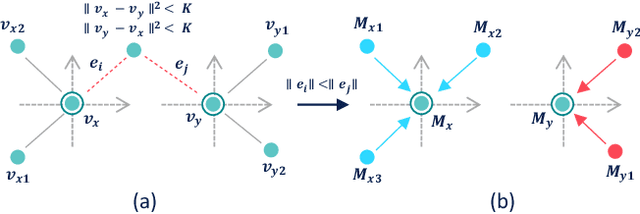
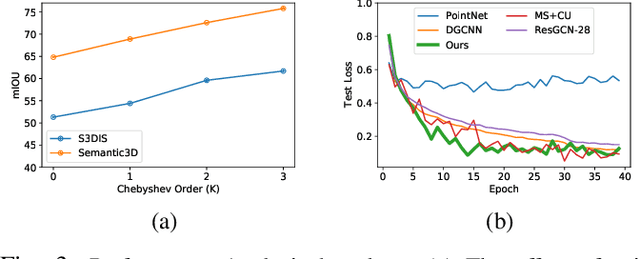
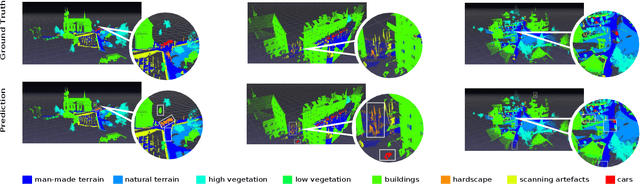
Semantic segmentation of raw 3D point clouds is an essential component in 3D scene analysis, but it poses several challenges, primarily due to the non-Euclidean nature of 3D point clouds. Although, several deep learning based approaches have been proposed to address this task, but almost all of them emphasized on using the latent (global) feature representations from traditional convolutional neural networks (CNN), resulting in severe loss of spatial information, thus failing to model the geometry of the underlying 3D objects, that plays an important role in remote sensing 3D scenes. In this letter, we have proposed an alternative approach to overcome the limitations of CNN based approaches by encoding the spatial features of raw 3D point clouds into undirected symmetrical graph models. These encodings are then combined with a high-dimensional feature vector extracted from a traditional CNN into a localized graph convolution operator that outputs the required 3D segmentation map. We have performed experiments on two standard benchmark datasets (including an outdoor aerial remote sensing dataset and an indoor synthetic dataset). The proposed method achieves on par state-of-the-art accuracy with improved training time and model stability thus indicating strong potential for further research towards a generalized state-of-the-art method for 3D scene understanding.
Minimax Regret for Stochastic Shortest Path with Adversarial Costs and Known Transition
Dec 07, 2020
We study the stochastic shortest path problem with adversarial costs and known transition, and show that the minimax regret is $\widetilde{O}(\sqrt{DT^\star K})$ and $\widetilde{O}(\sqrt{DT^\star SA K})$ for the full-information setting and the bandit feedback setting respectively, where $D$ is the diameter, $T^\star$ is the expected hitting time of the optimal policy, $S$ is the number of states, $A$ is the number of actions, and $K$ is the number of episodes. Our results significantly improve upon the existing work of (Rosenberg and Mansour, 2020) which only considers the full-information setting and achieves suboptimal regret. Our work is also the first to consider bandit feedback with adversarial costs. Our algorithms are built on top of the Online Mirror Descent framework with a variety of new techniques that might be of independent interest, including an improved multi-scale expert algorithm, a reduction from general stochastic shortest path to a special loop-free case, a skewed occupancy measure space, %the usage of log-barrier with an increasing learning rate schedule, and a novel correction term added to the cost estimators. Interestingly, the last two elements reduce the variance of the learner via positive bias and the variance of the optimal policy via negative bias respectively, and having them simultaneously is critical for obtaining the optimal high-probability bound in the bandit feedback setting.
On Efficient and Robust Metrics for RANSAC Hypotheses and 3D Rigid Registration
Nov 10, 2020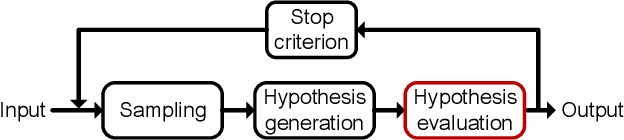
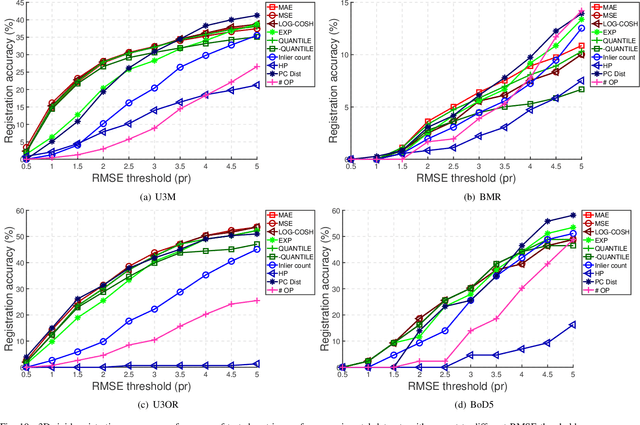

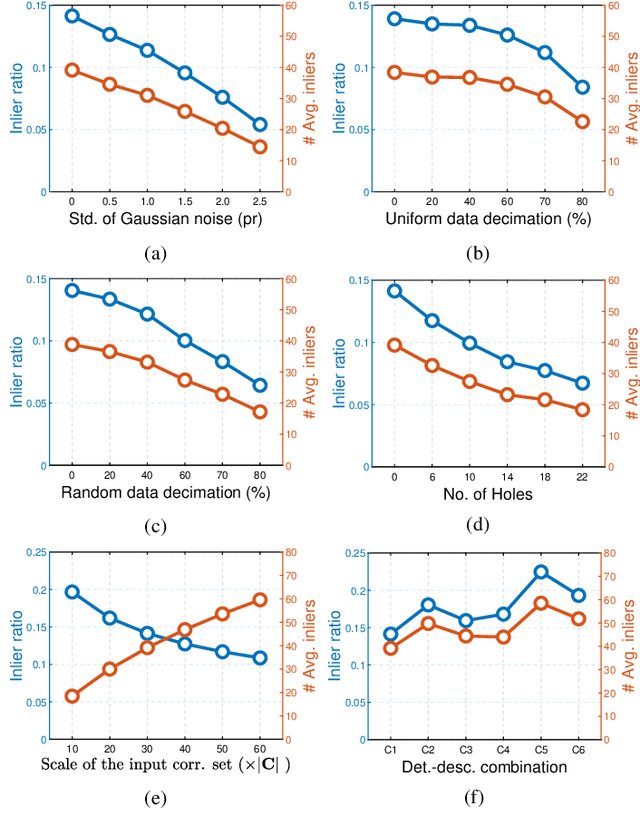
This paper focuses on developing efficient and robust evaluation metrics for RANSAC hypotheses to achieve accurate 3D rigid registration. Estimating six-degree-of-freedom (6-DoF) pose from feature correspondences remains a popular approach to 3D rigid registration, where random sample consensus (RANSAC) is a de-facto choice to this problem. However, existing metrics for RANSAC hypotheses are either time-consuming or sensitive to common nuisances, parameter variations, and different application scenarios, resulting in performance deterioration in overall registration accuracy and speed. We alleviate this problem by first analyzing the contributions of inliers and outliers, and then proposing several efficient and robust metrics with different designing motivations for RANSAC hypotheses. Comparative experiments on four standard datasets with different nuisances and application scenarios verify that the proposed metrics can significantly improve the registration performance and are more robust than several state-of-the-art competitors, making them good gifts to practical applications. This work also draws an interesting conclusion, i.e., not all inliers are equal while all outliers should be equal, which may shed new light on this research problem.
From Plants to Landmarks: Time-invariant Plant Localization that uses Deep Pose Regression in Agricultural Fields
Sep 14, 2017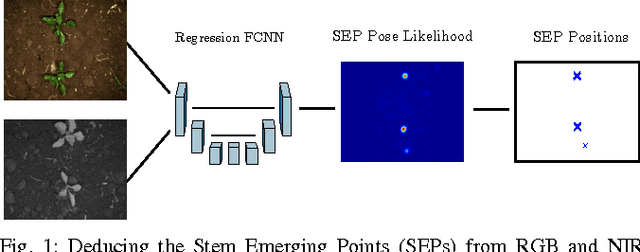



Agricultural robots are expected to increase yields in a sustainable way and automate precision tasks, such as weeding and plant monitoring. At the same time, they move in a continuously changing, semi-structured field environment, in which features can hardly be found and reproduced at a later time. Challenges for Lidar and visual detection systems stem from the fact that plants can be very small, overlapping and have a steadily changing appearance. Therefore, a popular way to localize vehicles with high accuracy is based on ex- pensive global navigation satellite systems and not on natural landmarks. The contribution of this work is a novel image- based plant localization technique that uses the time-invariant stem emerging point as a reference. Our approach is based on a fully convolutional neural network that learns landmark localization from RGB and NIR image input in an end-to-end manner. The network performs pose regression to generate a plant location likelihood map. Our approach allows us to cope with visual variances of plants both for different species and different growth stages. We achieve high localization accuracies as shown in detailed evaluations of a sugar beet cultivation phase. In experiments with our BoniRob we demonstrate that detections can be robustly reproduced with centimeter accuracy.
Deeply-Supervised Density Regression for Automatic Cell Counting in Microscopy Images
Nov 10, 2020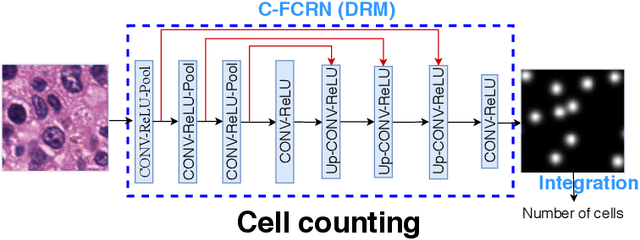
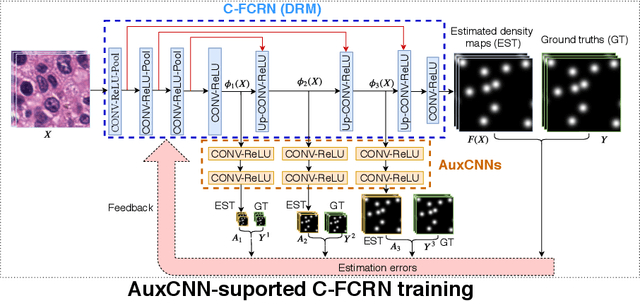
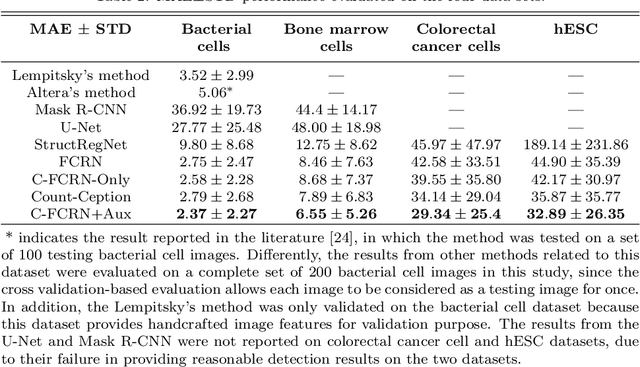
Accurately counting the number of cells in microscopy images is required in many medical diagnosis and biological studies. This task is tedious, time-consuming, and prone to subjective errors. However, designing automatic counting methods remains challenging due to low image contrast, complex background, large variance in cell shapes and counts, and significant cell occlusions in two-dimensional microscopy images. In this study, we proposed a new density regression-based method for automatically counting cells in microscopy images. The proposed method processes two innovations compared to other state-of-the-art density regression-based methods. First, the density regression model (DRM) is designed as a concatenated fully convolutional regression network (C-FCRN) to employ multi-scale image features for the estimation of cell density maps from given images. Second, auxiliary convolutional neural networks (AuxCNNs) are employed to assist in the training of intermediate layers of the designed C-FCRN to improve the DRM performance on unseen datasets. Experimental studies evaluated on four datasets demonstrate the superior performance of the proposed method.
ConvTransformer: A Convolutional Transformer Network for Video Frame Synthesis
Nov 20, 2020
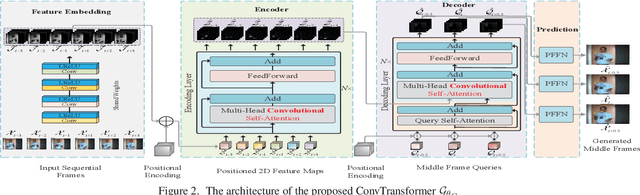
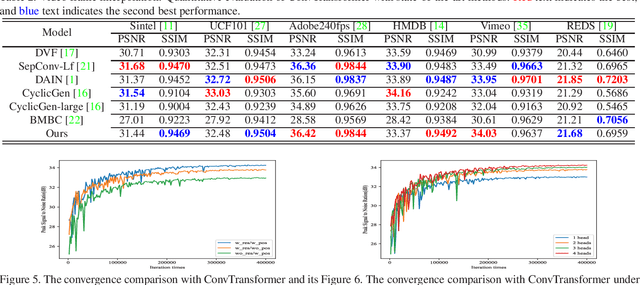
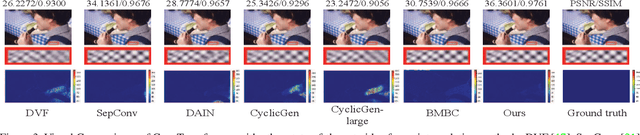
Deep Convolutional Neural Networks (CNNs) are powerful models that have achieved excellent performance on difficult computer vision tasks. Although CNNS perform well whenever large labeled training samples are available, they work badly on video frame synthesis due to objects deforming and moving, scene lighting changes, and cameras moving in video sequence. In this paper, we present a novel and general end-to-end architecture, called convolutional Transformer or ConvTransformer, for video frame sequence learning and video frame synthesis. The core ingredient of ConvTransformer is the proposed attention layer, i.e., multi-head convolutional self-attention, that learns the sequential dependence of video sequence. Our method ConvTransformer uses an encoder, built upon multi-head convolutional self-attention layers, to map the input sequence to a feature map sequence, and then another deep networks, incorporating multi-head convolutional self-attention layers, decode the target synthesized frames from the feature maps sequence. Experiments on video future frame extrapolation task show ConvTransformer to be superior in quality while being more parallelizable to recent approaches built upon convoltuional LSTM (ConvLSTM). To the best of our knowledge, this is the first time that ConvTransformer architecture is proposed and applied to video frame synthesis.
Battery Model Calibration with Deep Reinforcement Learning
Dec 07, 2020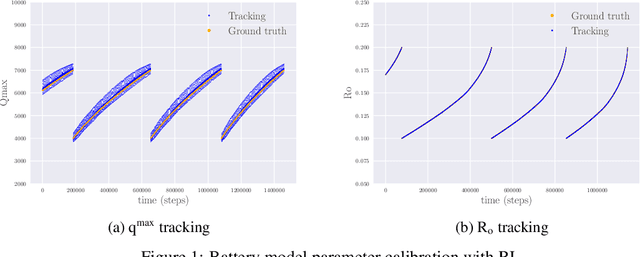
Lithium-Ion (Li-I) batteries have recently become pervasive and are used in many physical assets. To enable a good prediction of the end of discharge of batteries, detailed electrochemical Li-I battery models have been developed. Their parameters are typically calibrated before they are taken into operation and are typically not re-calibrated during operation. However, since battery performance is affected by aging, the reality gap between the computational battery models and the real physical systems leads to inaccurate predictions. A supervised machine learning algorithm would require an extensive representative training dataset mapping the observation to the ground truth calibration parameters. This may be infeasible for many practical applications. In this paper, we implement a Reinforcement Learning-based framework for reliably and efficiently inferring calibration parameters of battery models. The framework enables real-time inference of the computational model parameters in order to compensate the reality-gap from the observations. Most importantly, the proposed methodology does not need any labeled data samples, (samples of observations and the ground truth calibration parameters). Furthermore, the framework does not require any information on the underlying physical model. The experimental results demonstrate that the proposed methodology is capable of inferring the model parameters with high accuracy and high robustness. While the achieved results are comparable to those obtained with supervised machine learning, they do not rely on the ground truth information during training.
An extension of the angular synchronization problem to the heterogeneous setting
Jan 04, 2021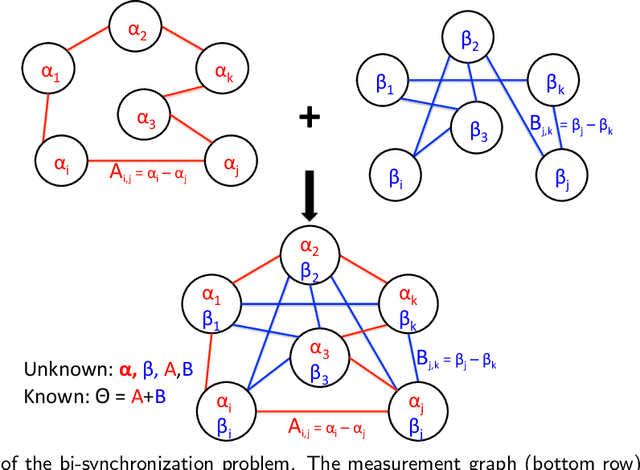
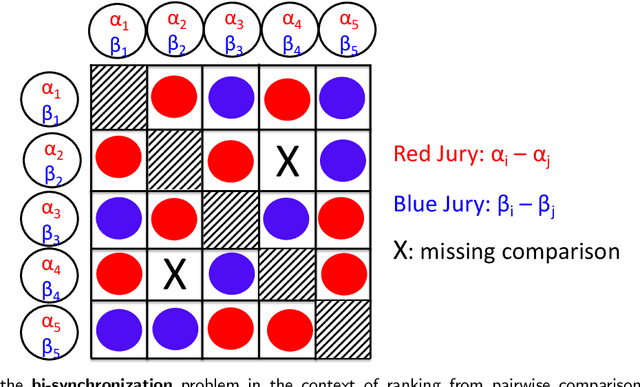
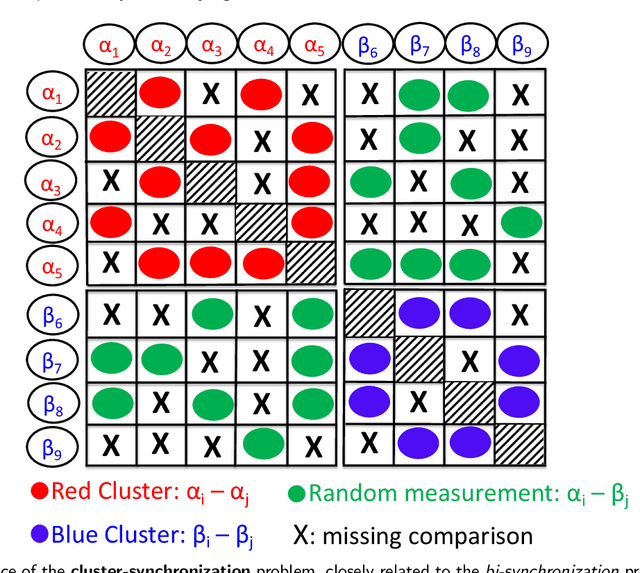
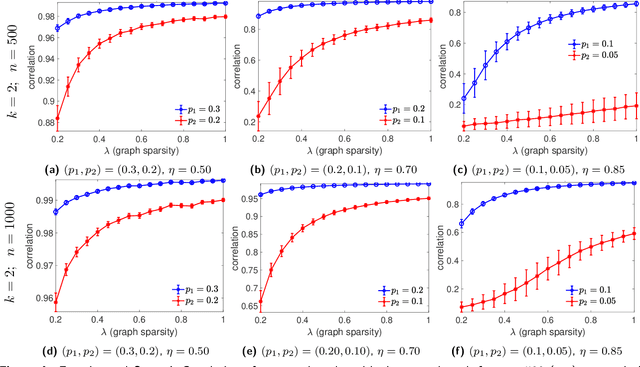
Given an undirected measurement graph $G = ([n], E)$, the classical angular synchronization problem consists of recovering unknown angles $\theta_1,\dots,\theta_n$ from a collection of noisy pairwise measurements of the form $(\theta_i - \theta_j) \mod 2\pi$, for each $\{i,j\} \in E$. This problem arises in a variety of applications, including computer vision, time synchronization of distributed networks, and ranking from preference relationships. In this paper, we consider a generalization to the setting where there exist $k$ unknown groups of angles $\theta_{l,1}, \dots,\theta_{l,n}$, for $l=1,\dots,k$. For each $ \{i,j\} \in E$, we are given noisy pairwise measurements of the form $\theta_{\ell,i} - \theta_{\ell,j}$ for an unknown $\ell \in \{1,2,\ldots,k\}$. This can be thought of as a natural extension of the angular synchronization problem to the heterogeneous setting of multiple groups of angles, where the measurement graph has an unknown edge-disjoint decomposition $G = G_1 \cup G_2 \ldots \cup G_k$, where the $G_i$'s denote the subgraphs of edges corresponding to each group. We propose a probabilistic generative model for this problem, along with a spectral algorithm for which we provide a detailed theoretical analysis in terms of robustness against both sampling sparsity and noise. The theoretical findings are complemented by a comprehensive set of numerical experiments, showcasing the efficacy of our algorithm under various parameter regimes. Finally, we consider an application of bi-synchronization to the graph realization problem, and provide along the way an iterative graph disentangling procedure that uncovers the subgraphs $G_i$, $i=1,\ldots,k$ which is of independent interest, as it is shown to improve the final recovery accuracy across all the experiments considered.