 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Hardware Acceleration of Monte-Carlo Sampling for Energy Efficient Robust Robot Manipulation
Jul 15, 2020
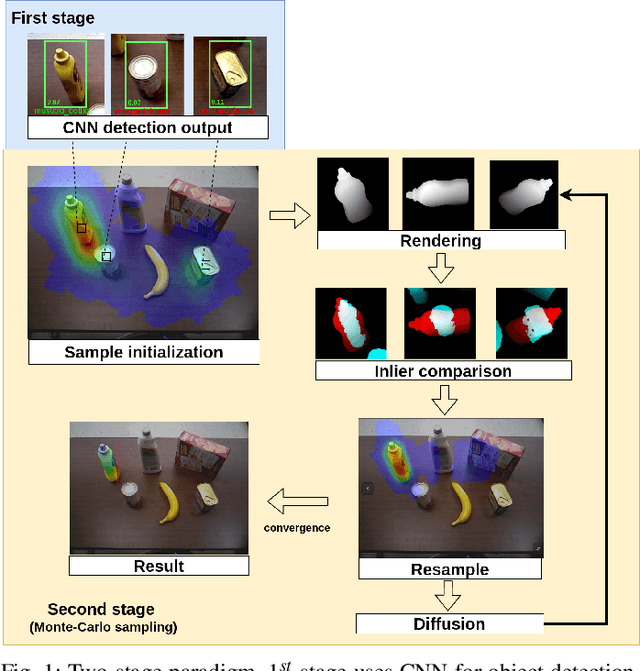
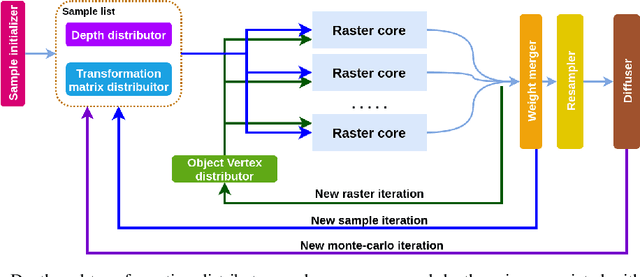
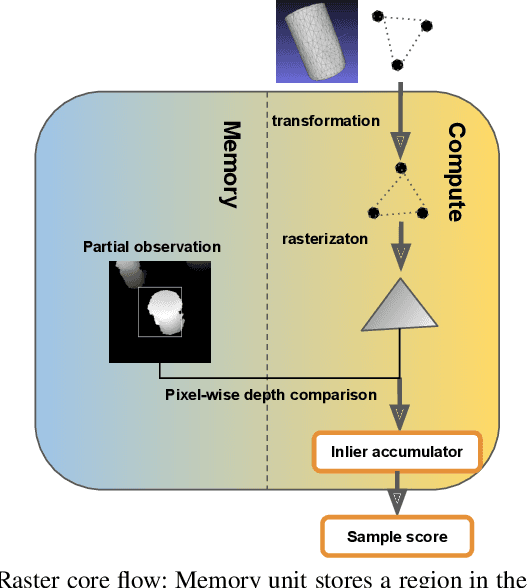

Algorithms based on Monte-Carlo sampling have been widely adapted in robotics and other areas of engineering due to their performance robustness. However, these sampling-based approaches have high computational requirements, making them unsuitable for real-time applications with tight energy constraints. In this paper, we investigate 6 degree-of-freedom (6DoF) pose estimation for robot manipulation using this method, which uses rendering combined with sequential Monte-Carlo sampling. While potentially very accurate, the significant computational complexity of the algorithm makes it less attractive for mobile robots, where runtime and energy consumption are tightly constrained. To address these challenges, we develop a novel hardware implementation of Monte-Carlo sampling on an FPGA with lower computational complexity and memory usage, while achieving high parallelism and modularization. Our results show 12X-21X improvements in energy efficiency over low-power and high-end GPU implementations, respectively. Moreover, we achieve real time performance without compromising accuracy.
Wavelet Flow: Fast Training of High Resolution Normalizing Flows
Oct 26, 2020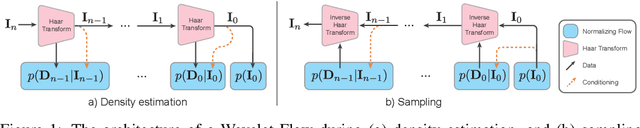


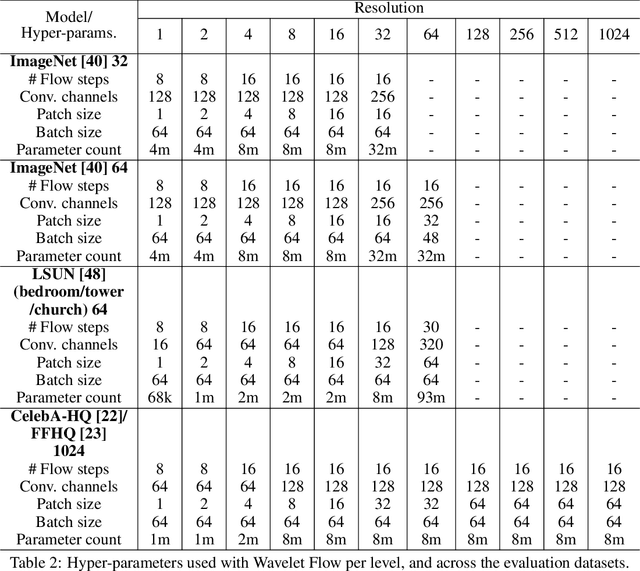
Normalizing flows are a class of probabilistic generative models which allow for both fast density computation and efficient sampling and are effective at modelling complex distributions like images. A drawback among current methods is their significant training cost, sometimes requiring months of GPU training time to achieve state-of-the-art results. This paper introduces Wavelet Flow, a multi-scale, normalizing flow architecture based on wavelets. A Wavelet Flow has an explicit representation of signal scale that inherently includes models of lower resolution signals and conditional generation of higher resolution signals, i.e., super resolution. A major advantage of Wavelet Flow is the ability to construct generative models for high resolution data (e.g., 1024 x 1024 images) that are impractical with previous models. Furthermore, Wavelet Flow is competitive with previous normalizing flows in terms of bits per dimension on standard (low resolution) benchmarks while being up to 15x faster to train.
Neural Star Domain as Primitive Representation
Nov 12, 2020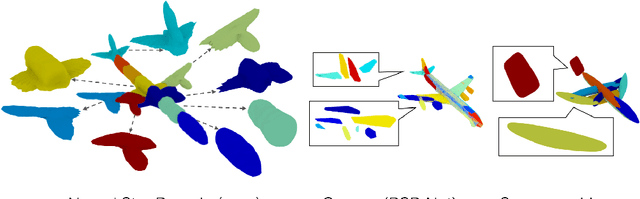

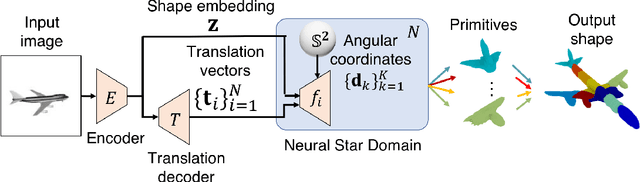
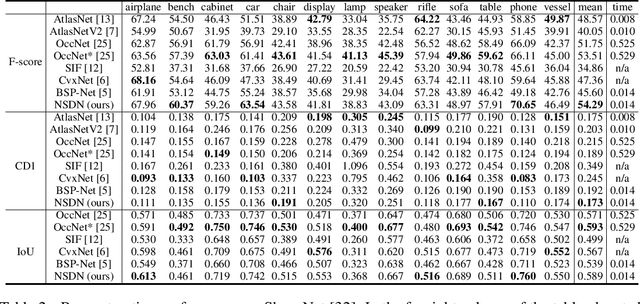
Reconstructing 3D objects from 2D images is a fundamental task in computer vision. Accurate structured reconstruction by parsimonious and semantic primitive representation further broadens its application. When reconstructing a target shape with multiple primitives, it is preferable that one can instantly access the union of basic properties of the shape such as collective volume and surface, treating the primitives as if they are one single shape. This becomes possible by primitive representation with unified implicit and explicit representations. However, primitive representations in current approaches do not satisfy all of the above requirements at the same time. To solve this problem, we propose a novel primitive representation named neural star domain (NSD) that learns primitive shapes in the star domain. We show that NSD is a universal approximator of the star domain and is not only parsimonious and semantic but also an implicit and explicit shape representation. We demonstrate that our approach outperforms existing methods in image reconstruction tasks, semantic capabilities, and speed and quality of sampling high-resolution meshes.
Joint reconstruction and bias field correction for undersampled MR imaging
Jul 26, 2020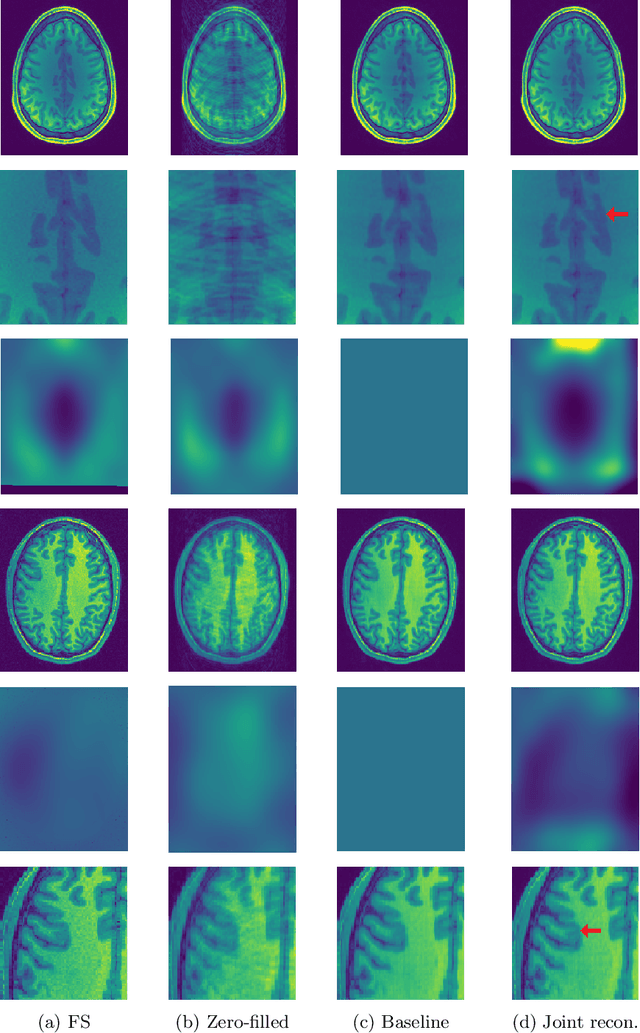
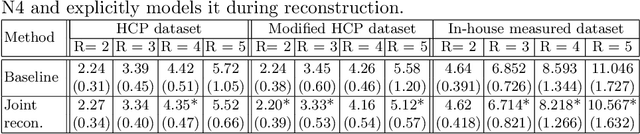
Undersampling the k-space in MRI allows saving precious acquisition time, yet results in an ill-posed inversion problem. Recently, many deep learning techniques have been developed, addressing this issue of recovering the fully sampled MR image from the undersampled data. However, these learning based schemes are susceptible to differences between the training data and the image to be reconstructed at test time. One such difference can be attributed to the bias field present in MR images, caused by field inhomogeneities and coil sensitivities. In this work, we address the sensitivity of the reconstruction problem to the bias field and propose to model it explicitly in the reconstruction, in order to decrease this sensitivity. To this end, we use an unsupervised learning based reconstruction algorithm as our basis and combine it with a N4-based bias field estimation method, in a joint optimization scheme. We use the HCP dataset as well as in-house measured images for the evaluations. We show that the proposed method improves the reconstruction quality, both visually and in terms of RMSE.
Image Generation for Efficient Neural Network Training in Autonomous Drone Racing
Aug 06, 2020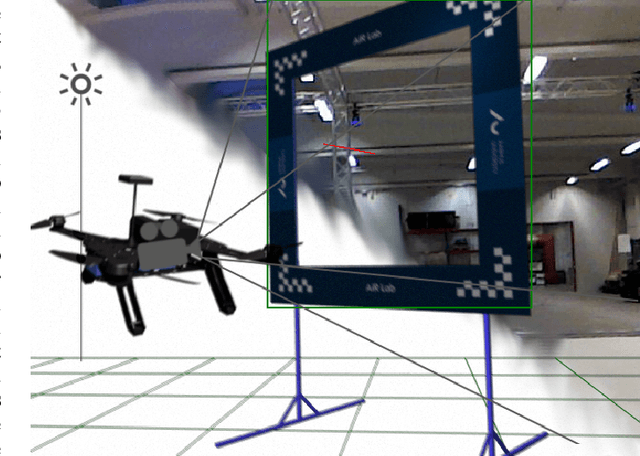
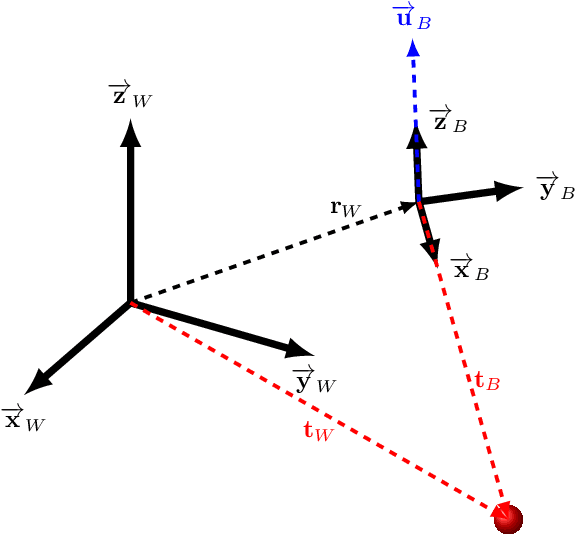
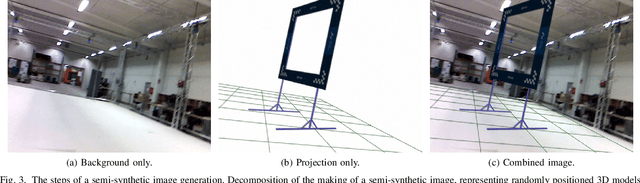

Drone racing is a recreational sport in which the goal is to pass through a sequence of gates in a minimum amount of time while avoiding collisions. In autonomous drone racing, one must accomplish this task by flying fully autonomously in an unknown environment by relying only on computer vision methods for detecting the target gates. Due to the challenges such as background objects and varying lighting conditions, traditional object detection algorithms based on colour or geometry tend to fail. Convolutional neural networks offer impressive advances in computer vision but require an immense amount of data to learn. Collecting this data is a tedious process because the drone has to be flown manually, and the data collected can suffer from sensor failures. In this work, a semi-synthetic dataset generation method is proposed, using a combination of real background images and randomised 3D renders of the gates, to provide a limitless amount of training samples that do not suffer from those drawbacks. Using the detection results, a line-of-sight guidance algorithm is used to cross the gates. In several experimental real-time tests, the proposed framework successfully demonstrates fast and reliable detection and navigation.
Particle Swarm Based Hyper-Parameter Optimization for Machine Learned Interatomic Potentials
Dec 31, 2020
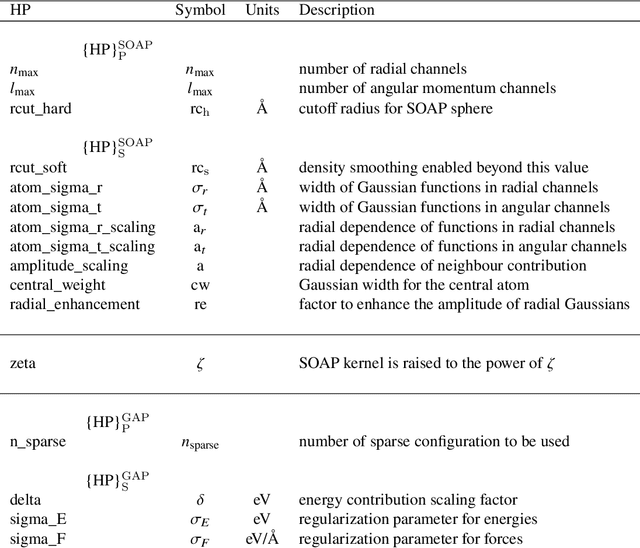
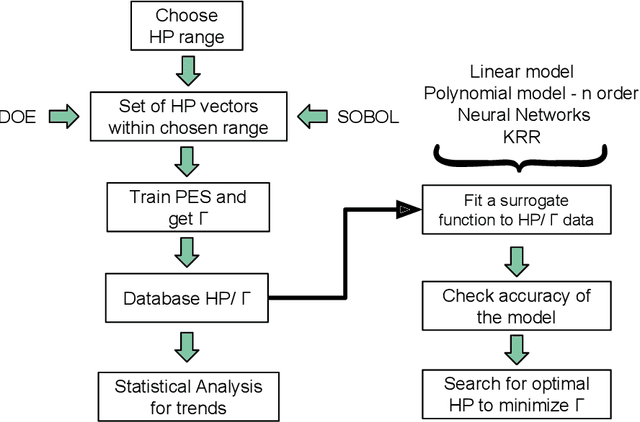
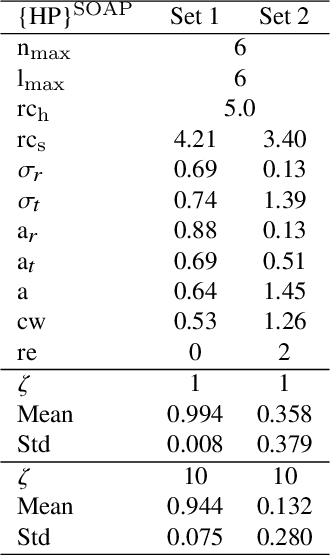
Modeling non-empirical and highly flexible interatomic potential energy surfaces (PES) using machine learning (ML) approaches is becoming popular in molecular and materials research. Training an ML-PES is typically performed in two stages: feature extraction and structure-property relationship modeling. The feature extraction stage transforms atomic positions into a symmetry-invariant mathematical representation. This representation can be fine-tuned by adjusting on a set of so-called "hyper-parameters" (HPs). Subsequently, an ML algorithm such as neural networks or Gaussian process regression (GPR) is used to model the structure-PES relationship based on another set of HPs. Choosing optimal values for the two sets of HPs is critical to ensure the high quality of the resulting ML-PES model. In this paper, we explore HP optimization strategies tailored for ML-PES generation using a custom-coded parallel particle swarm optimizer (available freely at https://github.com/suresh0807/PPSO.git). We employ the smooth overlap of atomic positions (SOAP) descriptor in combination with GPR-based Gaussian approximation potentials (GAP) and optimize HPs for four distinct systems: a toy C dimer, amorphous carbon, $\alpha$-Fe, and small organic molecules (QM9 dataset). We propose a two-step optimization strategy in which the HPs related to the feature extraction stage are optimized first, followed by the optimization of the HPs in the training stage. This strategy is computationally more efficient than optimizing all HPs at the same time by means of significantly reducing the number of ML models needed to be trained to obtain the optimal HPs. This approach can be trivially extended to other combinations of descriptor and ML algorithm and brings us another step closer to fully automated ML-PES generation.
A Deep Learning Approach for Low-Latency Packet Loss Concealment of Audio Signals in Networked Music Performance Applications
Jul 14, 2020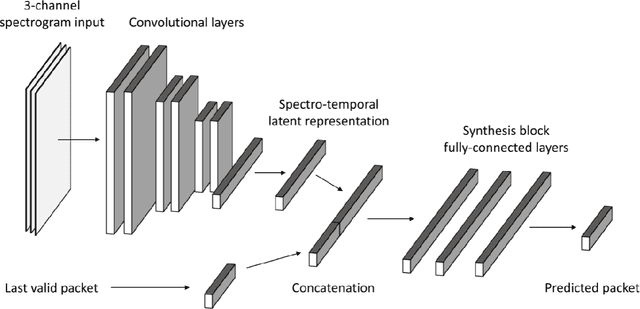
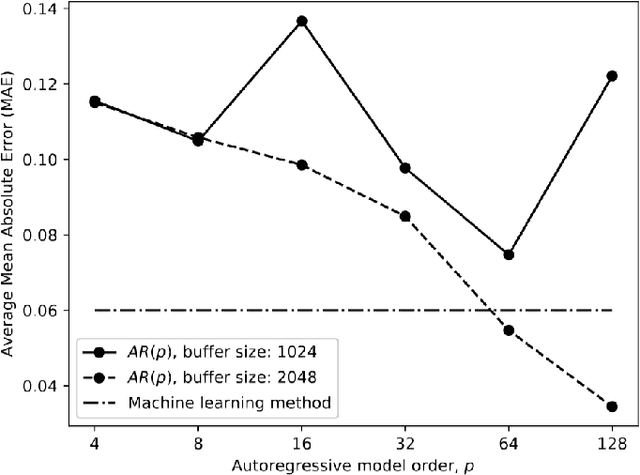
Networked Music Performance (NMP) is envisioned as a potential game changer among Internet applications: it aims at revolutionizing the traditional concept of musical interaction by enabling remote musicians to interact and perform together through a telecommunication network. Ensuring realistic conditions for music performance, however, constitutes a significant engineering challenge due to extremely strict requirements in terms of audio quality and, most importantly, network delay. To minimize the end-to-end delay experienced by the musicians, typical implementations of NMP applications use un-compressed, bidirectional audio streams and leverage UDP as transport protocol. Being connection less and unreliable,audio packets transmitted via UDP which become lost in transit are not re-transmitted and thus cause glitches in the receiver audio playout. This article describes a technique for predicting lost packet content in real-time using a deep learning approach. The ability of concealing errors in real time can help mitigate audio impairments caused by packet losses, thus improving the quality of audio playout in real-world scenarios.
Tracking from Patterns: Learning Corresponding Patterns in Point Clouds for 3D Object Tracking
Oct 20, 2020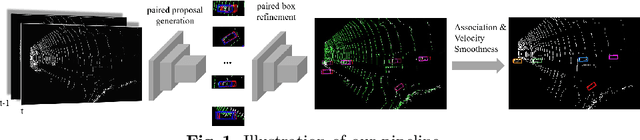


A robust 3D object tracker which continuously tracks surrounding objects and estimates their trajectories is key for self-driving vehicles. Most existing tracking methods employ a tracking-by-detection strategy, which usually requires complex pair-wise similarity computation and neglects the nature of continuous object motion. In this paper, we propose to directly learn 3D object correspondences from temporal point cloud data and infer the motion information from correspondence patterns. We modify the standard 3D object detector to process two lidar frames at the same time and predict bounding box pairs for the association and motion estimation tasks. We also equip our pipeline with a simple yet effective velocity smoothing module to estimate consistent object motion. Benifiting from the learned correspondences and motion refinement, our method exceeds the existing 3D tracking methods on both the KITTI and larger scale Nuscenes dataset.
* 4 pages, ECCV2020 Workshop on Perception for Autonomous Driving(PAD2020)
Voxel R-CNN: Towards High Performance Voxel-based 3D Object Detection
Dec 31, 2020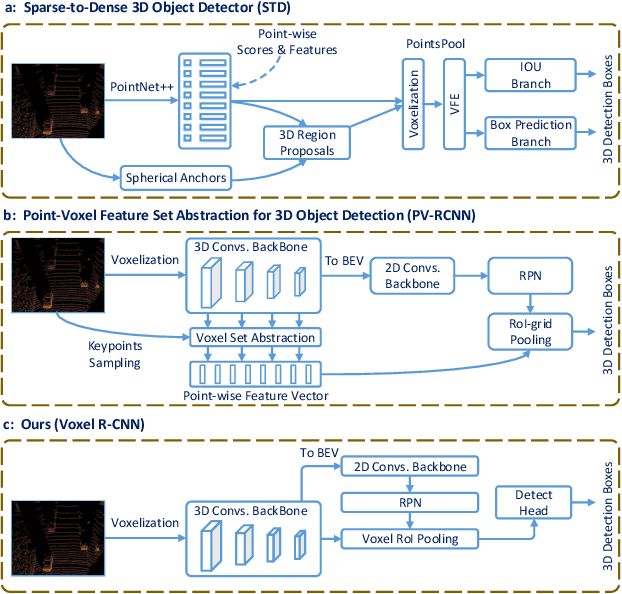


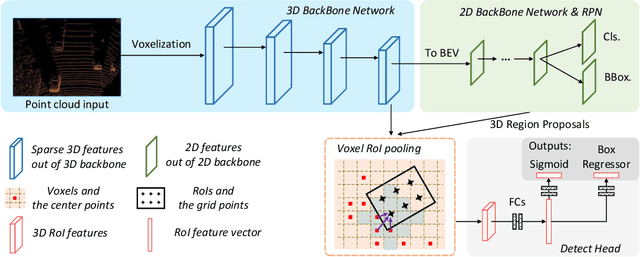
Recent advances on 3D object detection heavily rely on how the 3D data are represented, \emph{i.e.}, voxel-based or point-based representation. Many existing high performance 3D detectors are point-based because this structure can better retain precise point positions. Nevertheless, point-level features lead to high computation overheads due to unordered storage. In contrast, the voxel-based structure is better suited for feature extraction but often yields lower accuracy because the input data are divided into grids. In this paper, we take a slightly different viewpoint -- we find that precise positioning of raw points is not essential for high performance 3D object detection and that the coarse voxel granularity can also offer sufficient detection accuracy. Bearing this view in mind, we devise a simple but effective voxel-based framework, named Voxel R-CNN. By taking full advantage of voxel features in a two stage approach, our method achieves comparable detection accuracy with state-of-the-art point-based models, but at a fraction of the computation cost. Voxel R-CNN consists of a 3D backbone network, a 2D bird-eye-view (BEV) Region Proposal Network and a detect head. A voxel RoI pooling is devised to extract RoI features directly from voxel features for further refinement. Extensive experiments are conducted on the widely used KITTI Dataset and the more recent Waymo Open Dataset. Our results show that compared to existing voxel-based methods, Voxel R-CNN delivers a higher detection accuracy while maintaining a real-time frame processing rate, \emph{i.e}., at a speed of 25 FPS on an NVIDIA RTX 2080 Ti GPU. The code will be make available soon.
metricDTW: local distance metric learning in Dynamic Time Warping
Jun 11, 2016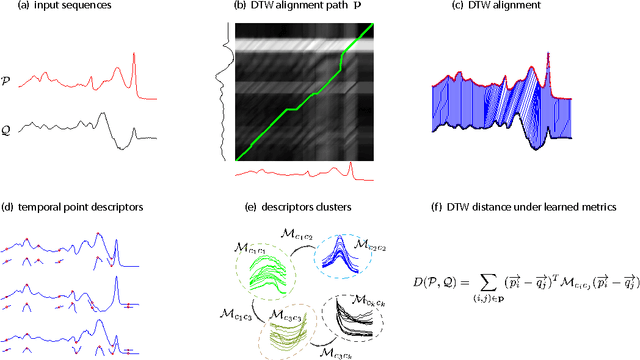
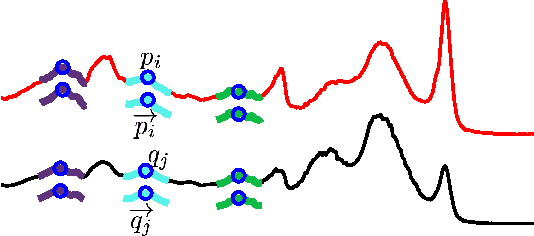
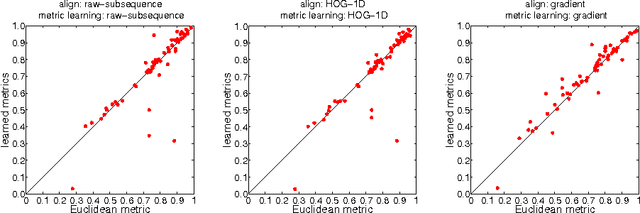
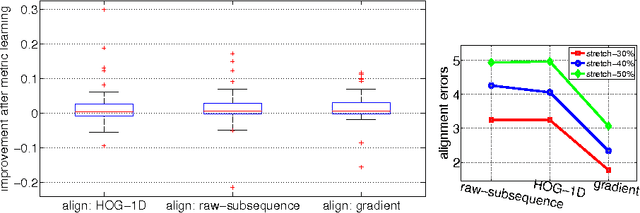
We propose to learn multiple local Mahalanobis distance metrics to perform k-nearest neighbor (kNN) classification of temporal sequences. Temporal sequences are first aligned by dynamic time warping (DTW); given the alignment path, similarity between two sequences is measured by the DTW distance, which is computed as the accumulated distance between matched temporal point pairs along the alignment path. Traditionally, Euclidean metric is used for distance computation between matched pairs, which ignores the data regularities and might not be optimal for applications at hand. Here we propose to learn multiple Mahalanobis metrics, such that DTW distance becomes the sum of Mahalanobis distances. We adapt the large margin nearest neighbor (LMNN) framework to our case, and formulate multiple metric learning as a linear programming problem. Extensive sequence classification results show that our proposed multiple metrics learning approach is effective, insensitive to the preceding alignment qualities, and reaches the state-of-the-art performances on UCR time series datasets.