 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A real-time decision support system for bridge management based on the rules generalized by CART decision tree and SMO algorithms
Jun 30, 2018
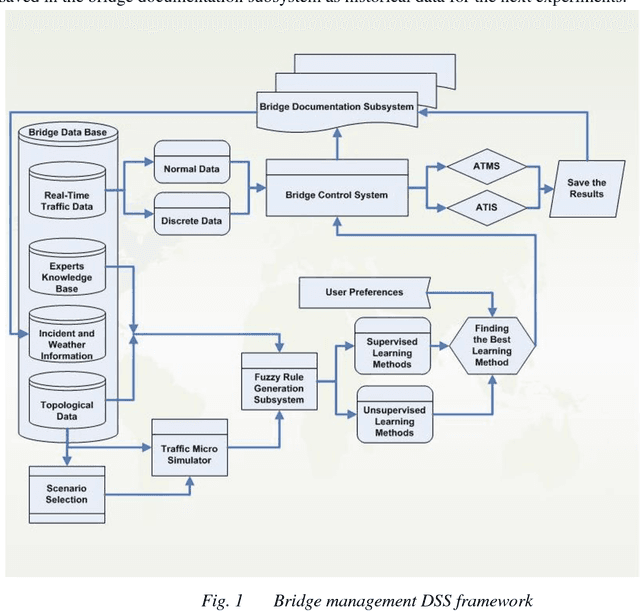
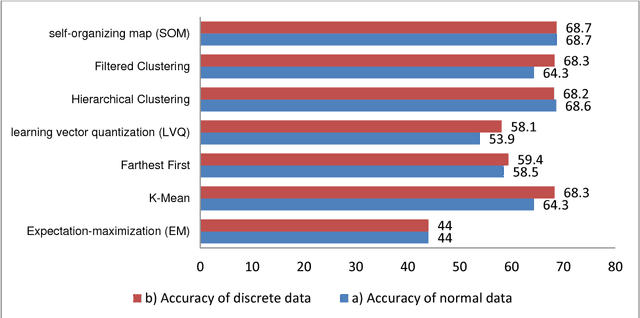
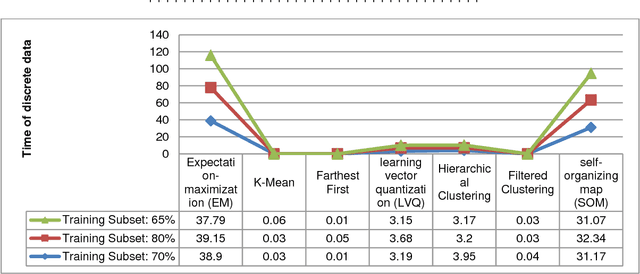
Under dynamic conditions on bridges, we need a real-time management. To this end, this paper presents a rule-based decision support system in which the necessary rules are extracted from simulation results made by Aimsun traffic micro-simulation software. Then, these rules are generalized by the aid of fuzzy rule generation algorithms. Then, they are trained by a set of supervised and the unsupervised learning algorithms to get an ability to make decision in real cases. As a pilot case study, Nasr Bridge in Tehran is simulated in Aimsun and WEKA data mining software is used to execute the learning algorithms. Based on this experiment, the accuracy of the supervised algorithms to generalize the rules is greater than 80%. In addition, CART decision tree and sequential minimal optimization (SMO) provides 100% accuracy for normal data and these algorithms are so reliable for crisis management on bridge. This means that, it is possible to use such machine learning methods to manage bridges in the real-time conditions.
StarCraft II Build Order Optimization using Deep Reinforcement Learning and Monte-Carlo Tree Search
Jun 12, 2020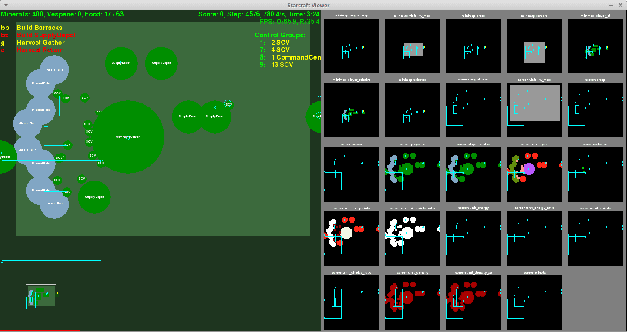


The real-time strategy game of StarCraft II has been posed as a challenge for reinforcement learning by Google's DeepMind. This study examines the use of an agent based on the Monte-Carlo Tree Search algorithm for optimizing the build order in StarCraft II, and discusses how its performance can be improved even further by combining it with a deep reinforcement learning neural network. The experimental results accomplished using Monte-Carlo Tree Search achieves a score similar to a novice human player by only using very limited time and computational resources, which paves the way to achieving scores comparable to those of a human expert by combining it with the use of deep reinforcement learning.
Overlapping Schwarz Decomposition for Nonlinear Optimal Control
May 14, 2020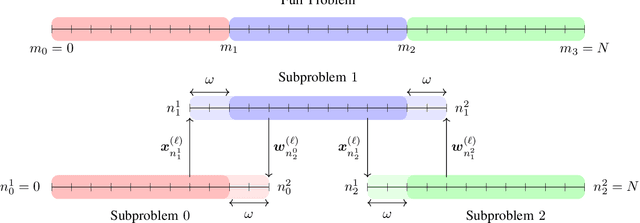
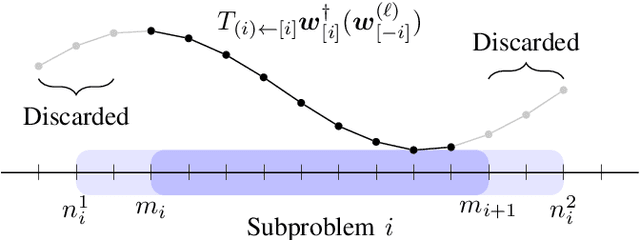
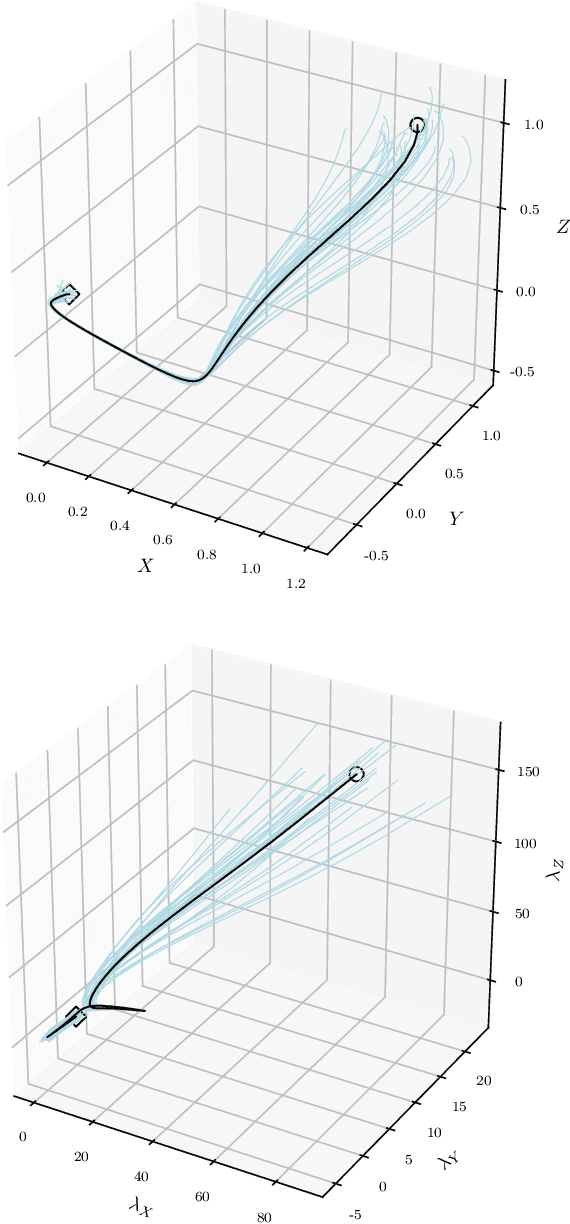
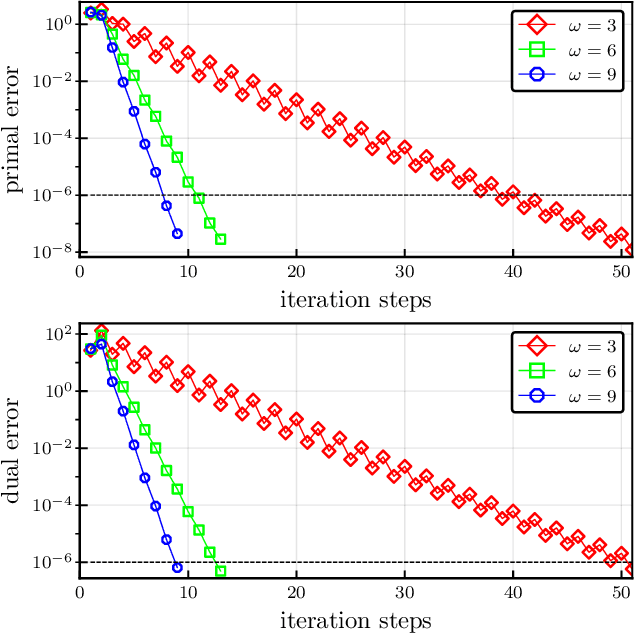
We present an overlapping Schwarz decomposition algorithm for solving nonlinear optimal control problems (OCPs). Our approach decomposes the time domain into a set of overlapping subdomains and solves subproblems defined over such subdomains in parallel. Convergence is attained by updating primal-dual information at the boundaries of the overlapping regions. We show that the algorithm exhibits local convergence and that the convergence rate improves exponentially with the size of the overlap. Our convergence results rely on a sensitivity result for OCPs that we call "asymptotic decay of sensitivity." Intuitively, this result states that impact of parametric perturbations at the boundaries of the time domain (initial and final time) decays exponentially as one moves away from the perturbation points. We show that this condition holds for nonlinear OCPs under a uniform second-order sufficient condition, a controllability condition, and a uniform boundedness condition. The approach is demonstrated by using a highly nonlinear quadrotor motion planning problem.
Self-supervised Wearable-based Activity Recognition by Learning to Forecast Motion
Oct 21, 2020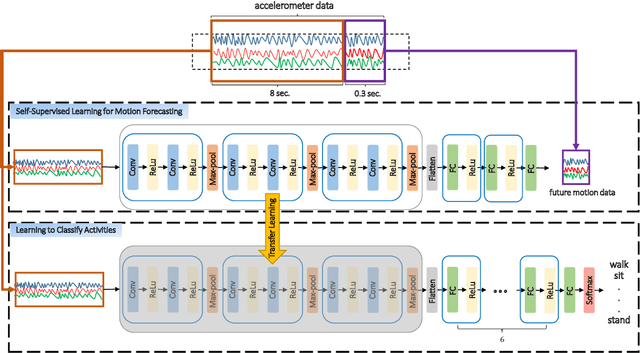
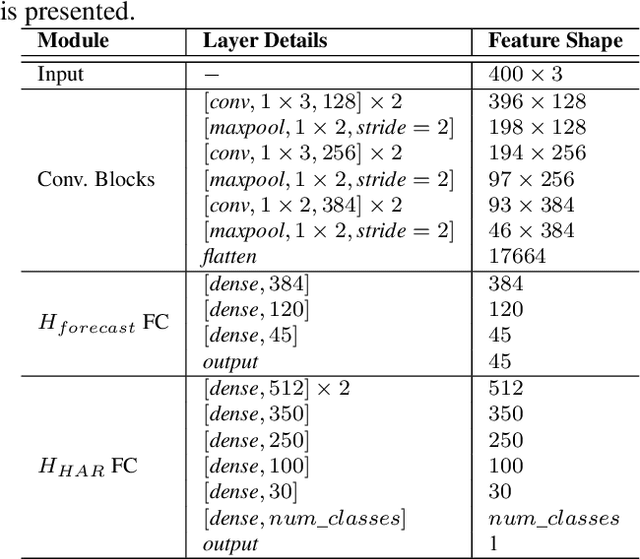
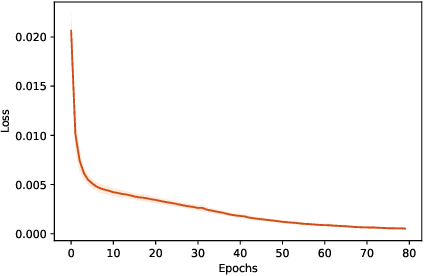
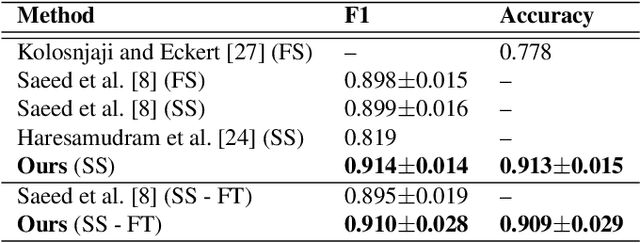
We propose the use of self-supervised learning for human activity recognition. Our proposed solution consists of two steps. First, the representations of unlabeled input signals are learned by training a deep convolutional neural network to predict the values of accelerometer signals in future time-steps. Then, we freeze the convolution blocks of this network and transfer the weights to our next network aimed at human activity recognition. For this task, we add a number of fully connected layers to the end of the frozen network and train the added layers with labeled accelerometer signals to learn to classify human activities. We evaluate the performance of our method on two publicly available human activity datasets: UCI HAR and MotionSense. The results show that our self-supervised approach outperforms the existing supervised and self-supervised methods to set new state-of-the-art values.
RotNet: Fast and Scalable Estimation of Stellar Rotation Periods Using Convolutional Neural Networks
Dec 02, 2020
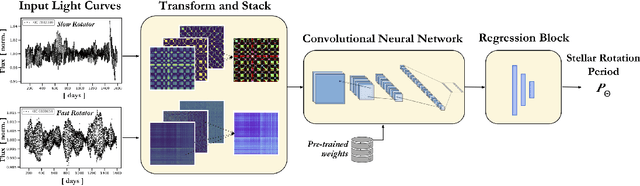
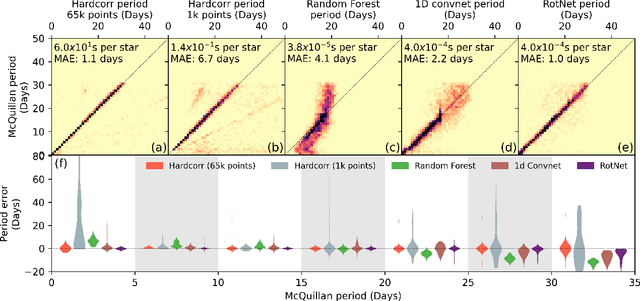
Magnetic activity in stars manifests as dark spots on their surfaces that modulate the brightness observed by telescopes. These light curves contain important information on stellar rotation. However, the accurate estimation of rotation periods is computationally expensive due to scarce ground truth information, noisy data, and large parameter spaces that lead to degenerate solutions. We harness the power of deep learning and successfully apply Convolutional Neural Networks to regress stellar rotation periods from Kepler light curves. Geometry-preserving time-series to image transformations of the light curves serve as inputs to a ResNet-18 based architecture which is trained through transfer learning. The McQuillan catalog of published rotation periods is used as ansatz to groundtruth. We benchmark the performance of our method against a random forest regressor, a 1D CNN, and the Auto-Correlation Function (ACF) - the current standard to estimate rotation periods. Despite limiting our input to fewer data points (1k), our model yields more accurate results and runs 350 times faster than ACF runs on the same number of data points and 10,000 times faster than ACF runs on 65k data points. With only minimal feature engineering our approach has impressive accuracy, motivating the application of deep learning to regress stellar parameters on an even larger scale
Learning to Compress Videos without Computing Motion
Sep 29, 2020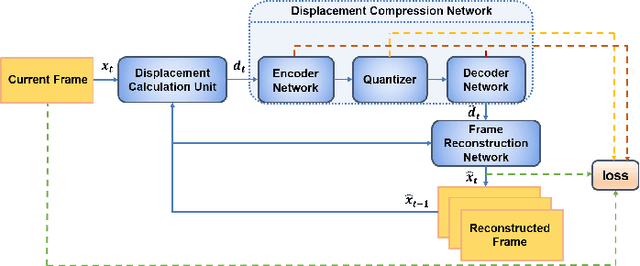
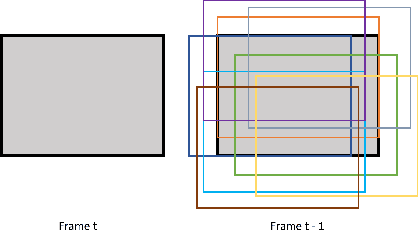
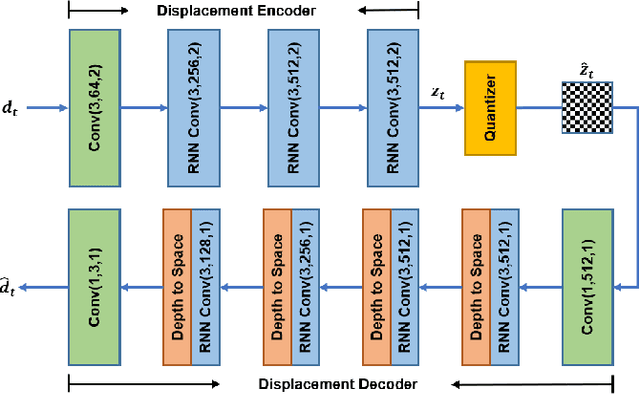
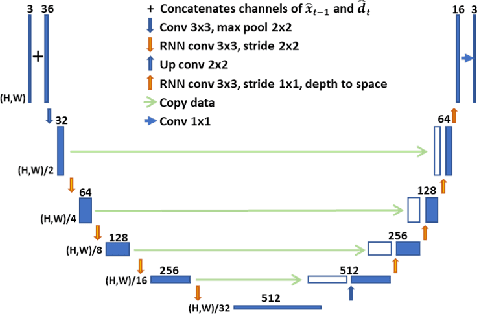
With the development of higher resolution contents and displays, its significant volume poses significant challenges to the goals of acquiring, transmitting, compressing and displaying high quality video content. In this paper, we propose a new deep learning video compression architecture that does not require motion estimation, which is the most expensive element of modern hybrid video compression codecs like H.264 and HEVC. Our framework exploits the regularities inherent to video motion, which we capture by using displaced frame differences as video representations to train the neural network. In addition, we propose a new space-time reconstruction network based on both an LSTM model and a UNet model, which we call LSTM-UNet. The combined network is able to efficiently capture both temporal and spatial video information, making it highly amenable for our purposes. The new video compression framework has three components: a Displacement Calculation Unit (DCU), a Displacement Compression Network (DCN), and a Frame Reconstruction Network (FRN), all of which are jointly optimized against a single perceptual loss function. The DCU obviates the need for motion estimation as in hybrid codecs, and is less expensive. In the DCN, an RNN-based network is utilized to conduct variable bit-rate encoding based on a single round of training. The LSTM-UNet is used in the FRN to learn space time differential representations of videos. Our experimental results show that our compression model, which we call the MOtionless VIdeo Codec (MOVI-Codec), learns how to efficiently compress videos without computing motion. Our experiments show that MOVI-Codec outperforms the video coding standard H.264, and is highly competitive with, and sometimes exceeds the performance of the modern global standard HEVC codec, as measured by MS-SSIM.
Deep Inverse Sensor Models as Priors for evidential Occupancy Mapping
Dec 02, 2020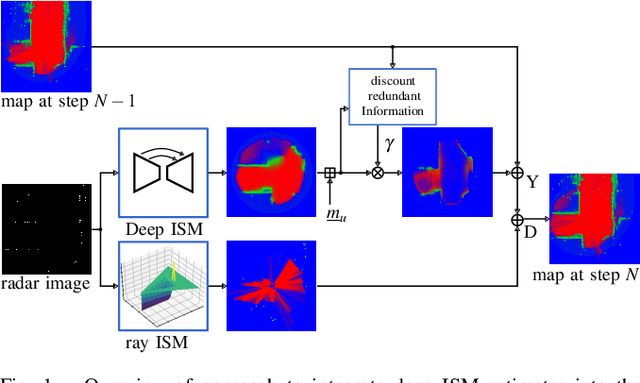
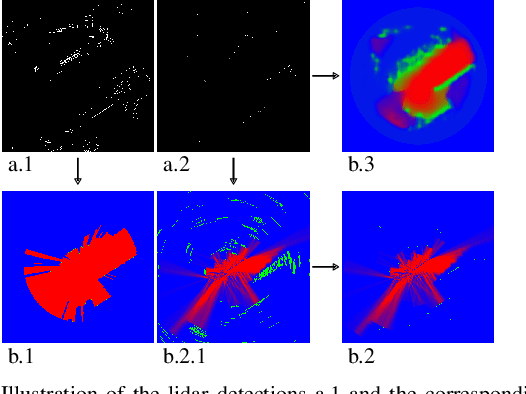
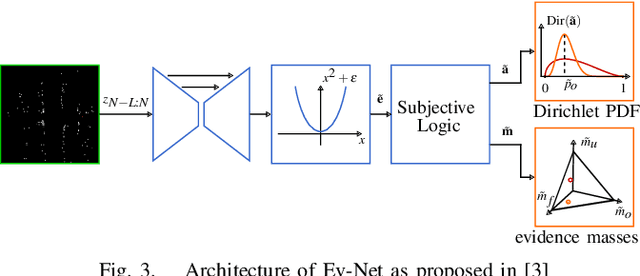

With the recent boost in autonomous driving, increased attention has been paid on radars as an input for occupancy mapping. Besides their many benefits, the inference of occupied space based on radar detections is notoriously difficult because of the data sparsity and the environment dependent noise (e.g. multipath reflections). Recently, deep learning-based inverse sensor models, from here on called deep ISMs, have been shown to improve over their geometric counterparts in retrieving occupancy information. Nevertheless, these methods perform a data-driven interpolation which has to be verified later on in the presence of measurements. In this work, we describe a novel approach to integrate deep ISMs together with geometric ISMs into the evidential occupancy mapping framework. Our method leverages both the capabilities of the data-driven approach to initialize cells not yet observable for the geometric model effectively enhancing the perception field and convergence speed, while at the same time use the precision of the geometric ISM to converge to sharp boundaries. We further define a lower limit on the deep ISM estimate's certainty together with analytical proofs of convergence which we use to distinguish cells that are solely allocated by the deep ISM from cells already verified using the geometric approach.
Bew: Towards Answering Business-Entity-Related Web Questions
Dec 10, 2020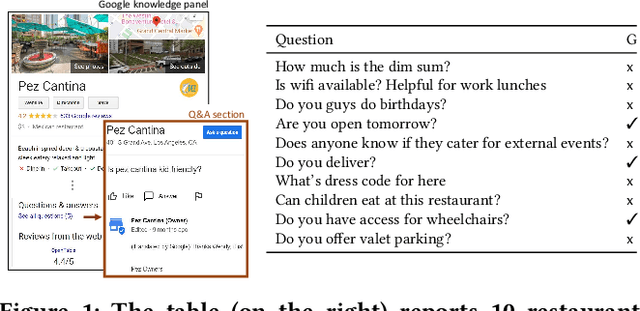
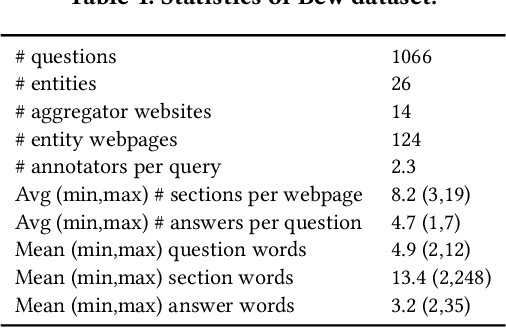
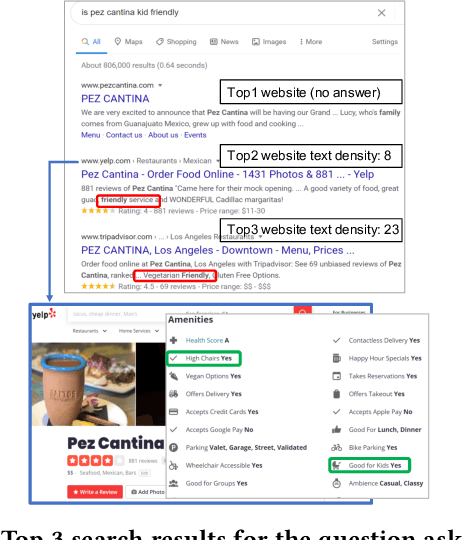
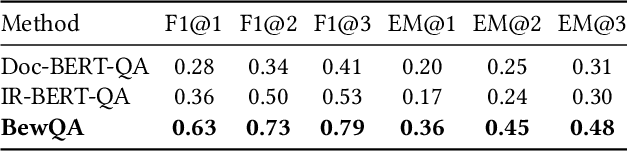
We present BewQA, a system specifically designed to answer a class of questions that we call Bew questions. Bew questions are related to businesses/services such as restaurants, hotels, and movie theaters; for example, "Until what time is happy hour?". These questions are challenging to answer because the answers are found in open-domain Web, are present in short sentences without surrounding context, and are dynamic since the webpage information can be updated frequently. Under these conditions, existing QA systems perform poorly. We present a practical approach, called BewQA, that can answer Bew queries by mining a template of the business-related webpages and using the template to guide the search. We show how we can extract the template automatically by leveraging aggregator websites that aggregate information about business entities in a domain (e.g., restaurants). We answer a given question by identifying the section from the extracted template that is most likely to contain the answer. By doing so we can extract the answers even when the answer span does not have sufficient context. Importantly, BewQA does not require any training. We crowdsource a new dataset of 1066 Bew questions and ground-truth answers in the restaurant domain. Compared to state-of-the-art QA models, BewQA has a 27 percent point improvement in F1 score. Compared to a commercial search engine, BewQA answered correctly 29% more Bew questions.
Accelerating Probabilistic Volumetric Mapping using Ray-Tracing Graphics Hardware
Dec 02, 2020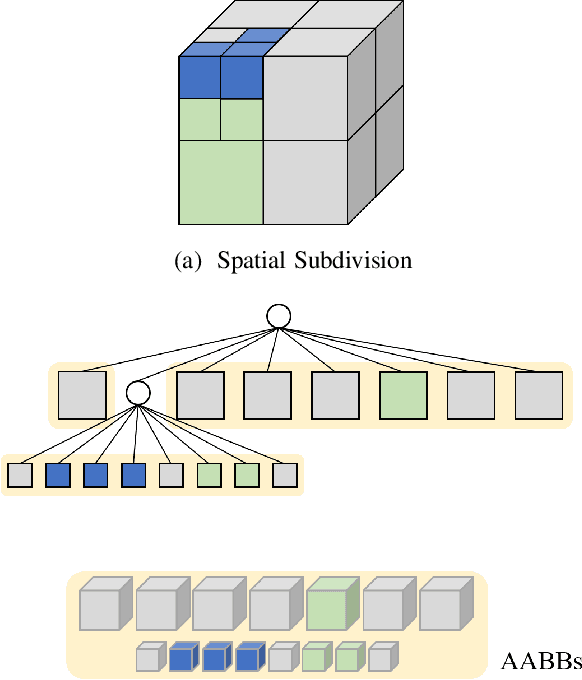
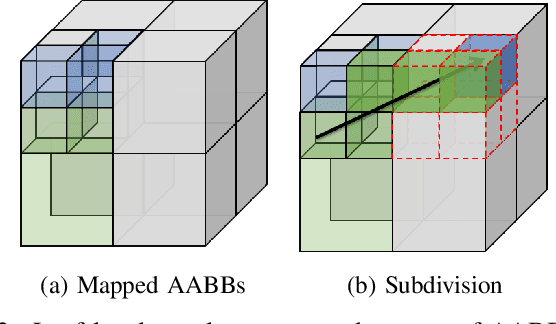
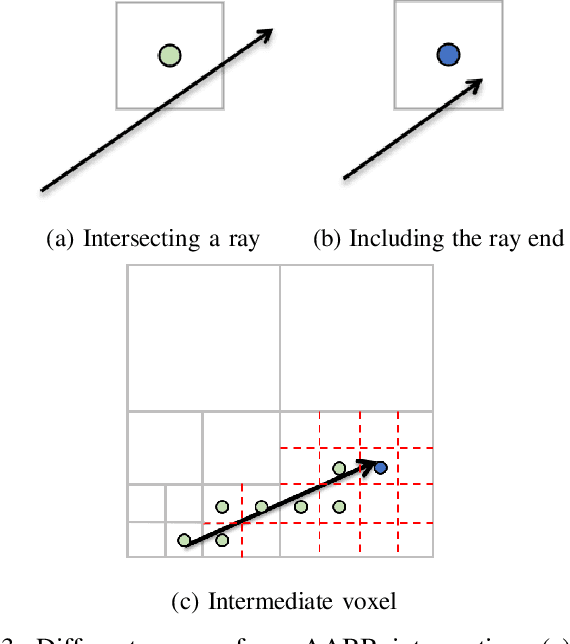
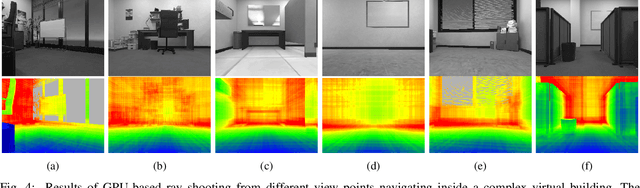
Probabilistic volumetric mapping (PVM) represents a 3D environmental map for an autonomous robotic navigational task. A popular implementation such as Octomap is widely used in the robotics community for such a purpose. The Octomap relies on octree to represent a PVM and its main bottleneck lies in massive ray-shooting to determine the occupancy of the underlying volumetric voxel grids. In this paper, we propose GPU-based ray shooting to drastically improve the ray shooting performance in Octomap. Our main idea is based on the use of recent ray-tracing RTX GPU, mainly designed for real-time photo-realistic computer graphics and the accompanying graphics API, known as DXR. Our ray-shooting first maps leaf-level voxels in the given octree to a set of axis-aligned bounding boxes (AABBs) and employ massively parallel ray shooting on them using GPUs to find free and occupied voxels. These are fed back into CPU to update the voxel occupancy and restructure the octree. In our experiments, we have observed more than three-orders-of-magnitude performance improvement in terms of ray shooting using ray-tracing RTX GPU over a state-of-the-art Octomap CPU implementation, where the benchmarking environments consist of more than 77K points and 25K~34K voxel grids.
PWCLO-Net: Deep LiDAR Odometry in 3D Point Clouds Using Hierarchical Embedding Mask Optimization
Dec 02, 2020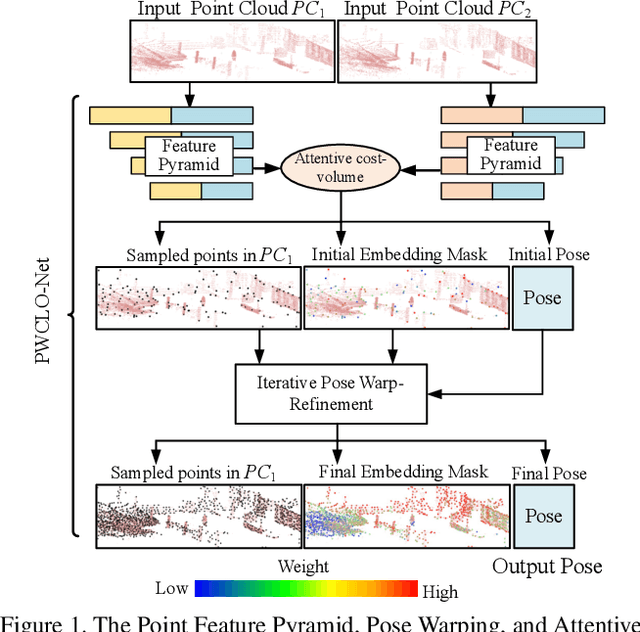
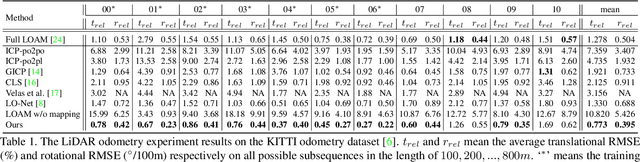
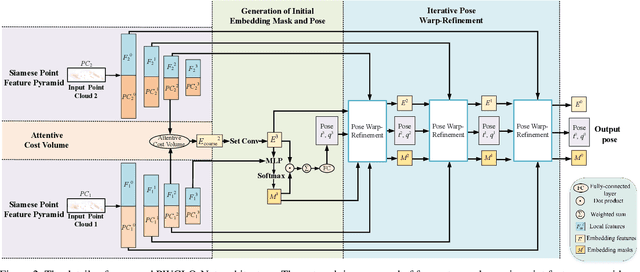

A novel 3D point cloud learning model for deep LiDAR odometry, named PWCLO-Net, using hierarchical embedding mask optimization is proposed in this paper. In this model, the Pyramid, Warping, and Cost volume (PWC) structure for the LiDAR Odometry task is built to hierarchically refine the estimated pose in a coarse-to-fine approach. An attentive cost volume is built to associate two point clouds and obtain the embedding motion information. Then, a novel trainable embedding mask is proposed to weight the cost volume of all points to the overall pose information and filter outlier points. The estimated current pose is used to warp the first point cloud to bridge the distance to the second point cloud, and then the cost volume of the residual motion is built. At the same time, the embedding mask is optimized hierarchically from coarse to fine to obtain more accurate filtering information for pose refinement. The pose warp-refinement process is repeatedly used to make the pose estimation more robust for outliers. The superior performance and effectiveness of our LiDAR odometry model are demonstrated on the KITTI odometry dataset. Our method outperforms all recent learning-based methods and outperforms the geometry-based approach, LOAM with mapping optimization, on most sequences of the KITTI odometry dataset.