 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TFPnP: Tuning-free Plug-and-Play Proximal Algorithm with Applications to Inverse Imaging Problems
Dec 11, 2020
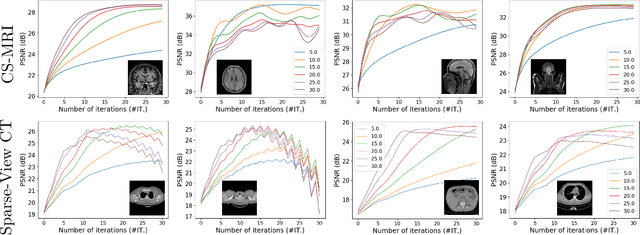
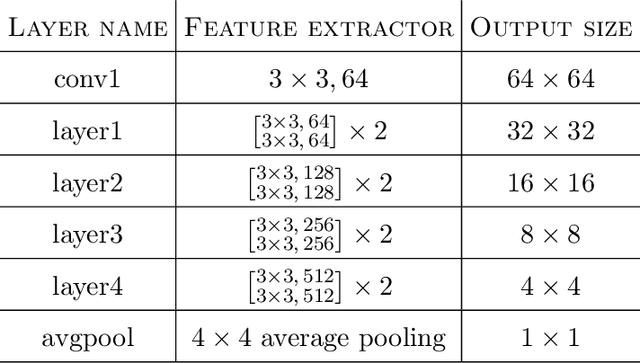
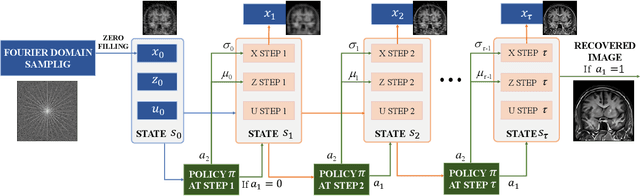
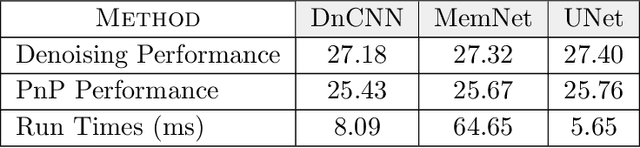
Plug-and-Play (PnP) is a non-convex framework that combines proximal algorithms, for example alternating direction method of multipliers (ADMM), with advanced denoiser priors. Over the past few years, great empirical success has been obtained by PnP algorithms, especially for the ones integrated with deep learning-based denoisers. However, a crucial issue of PnP approaches is the need of manual parameter tweaking. As it is essential to obtain high-quality results across the high discrepancy in terms of imaging conditions and varying scene content. In this work, we present a tuning-free PnP proximal algorithm, which can automatically determine the internal parameters including the penalty parameter, the denoising strength and the termination time. A core part of our approach is to develop a policy network for automatic search of parameters, which can be effectively learned via mixed model-free and model-based deep reinforcement learning. We demonstrate, through a set of numerical and visual experiments, that the learned policy can customize different parameters for different states, and often more efficient and effective than existing handcrafted criteria. Moreover, we discuss the practical considerations of the plugged denoisers, which together with our learned policy yield to state-of-the-art results. This is prevalent on both linear and nonlinear exemplary inverse imaging problems, and in particular, we show promising results on compressed sensing MRI, sparse-view CT and phase retrieval.
Controlled Perturbation-Induced Switching in Pulse-Coupled Oscillator Networks
Nov 02, 2020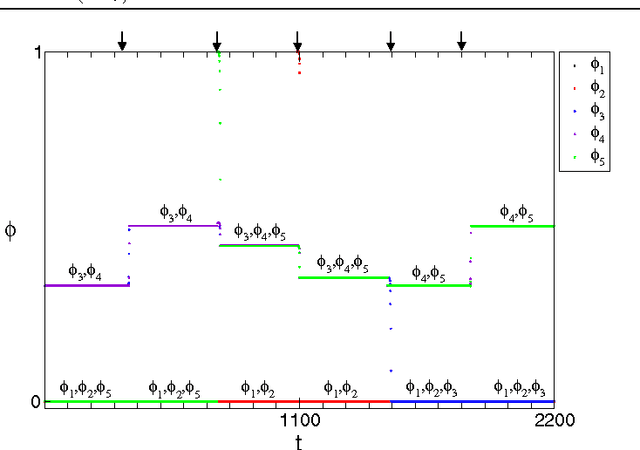
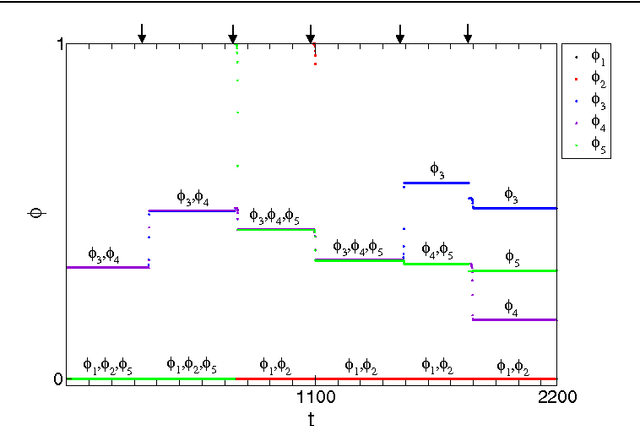
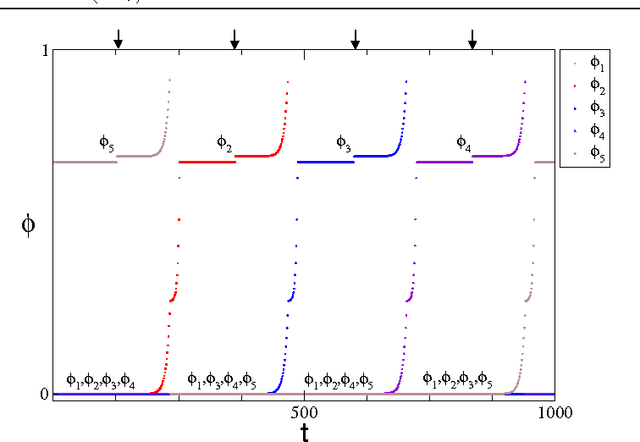
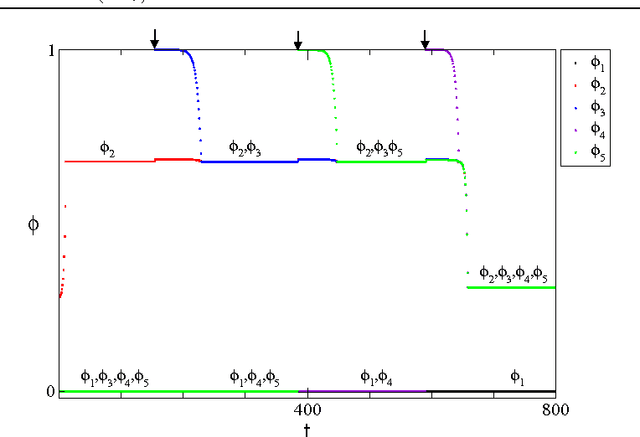
Pulse-coupled systems such as spiking neural networks exhibit nontrivial invariant sets in the form of attracting yet unstable saddle periodic orbits where units are synchronized into groups. Heteroclinic connections between such orbits may in principle support switching processes in those networks and enable novel kinds of neural computations. For small networks of coupled oscillators we here investigate under which conditions and how system symmetry enforces or forbids certain switching transitions that may be induced by perturbations. For networks of five oscillators we derive explicit transition rules that for two cluster symmetries deviate from those known from oscillators coupled continuously in time. A third symmetry yields heteroclinic networks that consist of sets of all unstable attractors with that symmetry and the connections between them. Our results indicate that pulse-coupled systems can reliably generate well-defined sets of complex spatiotemporal patterns that conform to specific transition rules. We briefly discuss possible implications for computation with spiking neural systems.
ShineOn: Illuminating Design Choices for Practical Video-based Virtual Clothing Try-on
Dec 18, 2020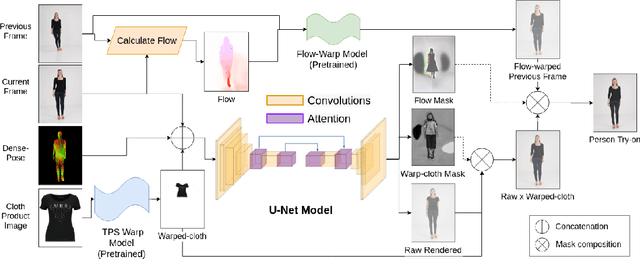

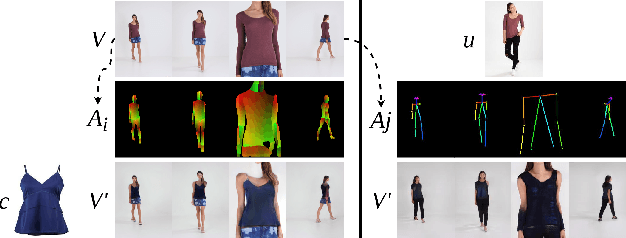
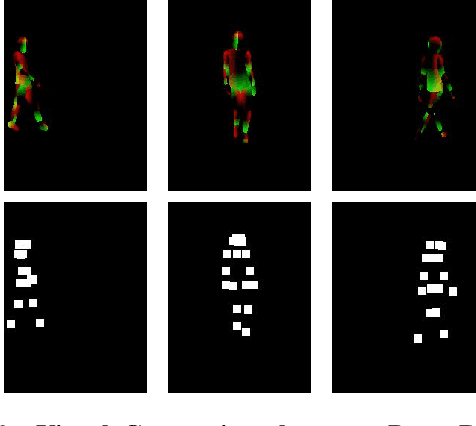
Virtual try-on has garnered interest as a neural rendering benchmark task to evaluate complex object transfer and scene composition. Recent works in virtual clothing try-on feature a plethora of possible architectural and data representation choices. However, they present little clarity on quantifying the isolated visual effect of each choice, nor do they specify the hyperparameter details that are key to experimental reproduction. Our work, ShineOn, approaches the try-on task from a bottom-up approach and aims to shine light on the visual and quantitative effects of each experiment. We build a series of scientific experiments to isolate effective design choices in video synthesis for virtual clothing try-on. Specifically, we investigate the effect of different pose annotations, self-attention layer placement, and activation functions on the quantitative and qualitative performance of video virtual try-on. We find that DensePose annotations not only enhance face details but also decrease memory usage and training time. Next, we find that attention layers improve face and neck quality. Finally, we show that GELU and ReLU activation functions are the most effective in our experiments despite the appeal of newer activations such as Swish and Sine. We will release a well-organized code base, hyperparameters, and model checkpoints to support the reproducibility of our results. We expect our extensive experiments and code to greatly inform future design choices in video virtual try-on. Our code may be accessed at https://github.com/andrewjong/ShineOn-Virtual-Tryon.
Weight Prediction for Variants of Weighted Directed Networks
Sep 29, 2020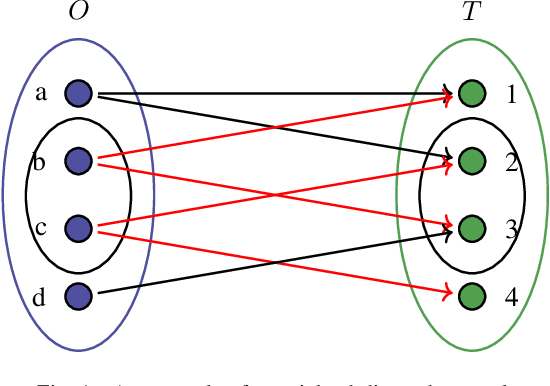

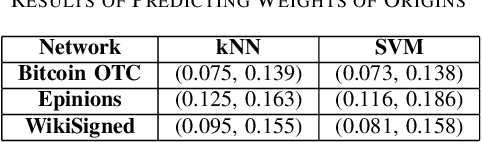
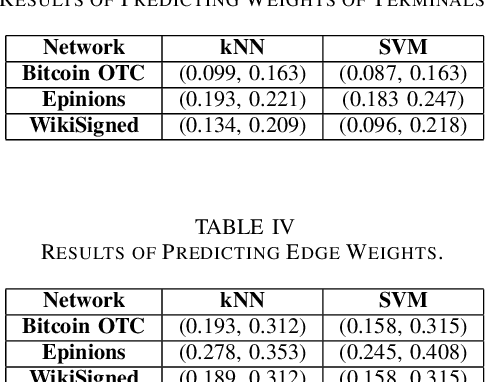
A weighted directed network (WDN) is a directed graph in which each edge is associated to a unique value called weight. These networks are very suitable for modeling real-world social networks in which there is an assessment of one vertex toward other vertices. One of the main problems studied in this paper is prediction of edge weights in such networks. We introduce, for the first time, a metric geometry approach to studying edge weight prediction in WDNs. We modify a usual notion of WDNs, and introduce a new type of WDNs which we coin the term \textit{almost-weighted directed networks} (AWDNs). AWDNs can capture the weight information of a network from a given training set. We then construct a class of metrics (or distances) for AWDNs which equips such networks with a metric space structure. Using the metric geometry structure of AWDNs, we propose modified $k$ nearest neighbors (kNN) methods and modified support-vector machine (SVM) methods which will then be used to predict edge weights in AWDNs. In many real-world datasets, in addition to edge weights, one can also associate weights to vertices which capture information of vertices; association of weights to vertices especially plays an important role in graph embedding problems. Adopting a similar approach, we introduce two new types of directed networks in which weights are associated to either a subset of origin vertices or a subset of terminal vertices . We, for the first time, construct novel classes of metrics on such networks, and based on these new metrics propose modified $k$NN and SVM methods for predicting weights of origins and terminals in these networks. We provide experimental results on several real-world datasets, using our geometric methodologies.
Shared Prior Learning of Energy-Based Models for Image Reconstruction
Nov 13, 2020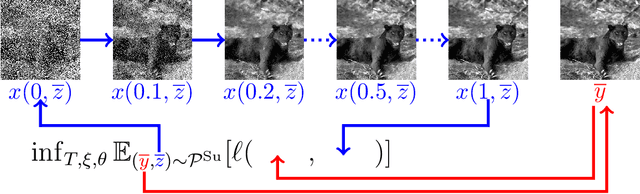
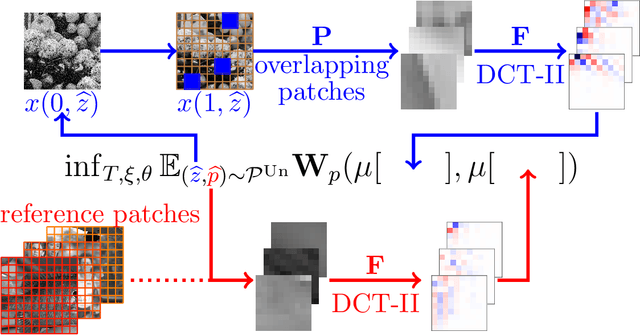
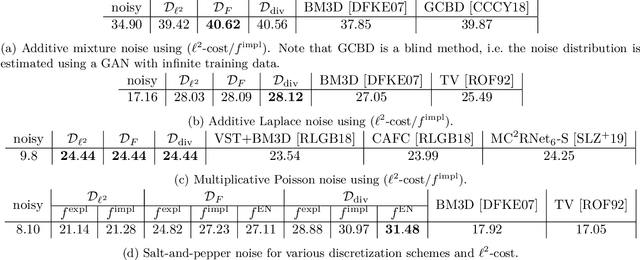
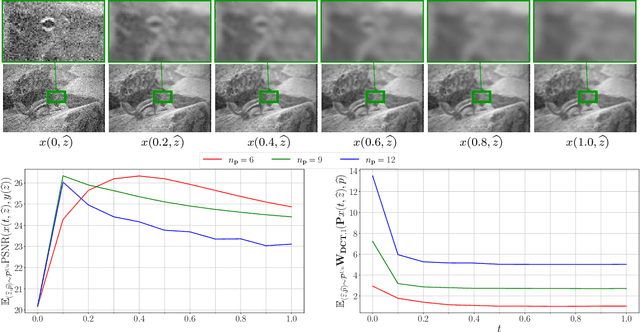
We propose a novel learning-based framework for image reconstruction particularly designed for training without ground truth data, which has three major building blocks: energy-based learning, a patch-based Wasserstein loss functional, and shared prior learning. In energy-based learning, the parameters of an energy functional composed of a learned data fidelity term and a data-driven regularizer are computed in a mean-field optimal control problem. In the absence of ground truth data, we change the loss functional to a patch-based Wasserstein functional, in which local statistics of the output images are compared to uncorrupted reference patches. Finally, in shared prior learning, both aforementioned optimal control problems are optimized simultaneously with shared learned parameters of the regularizer to further enhance unsupervised image reconstruction. We derive several time discretization schemes of the gradient flow and verify their consistency in terms of Mosco convergence. In numerous numerical experiments, we demonstrate that the proposed method generates state-of-the-art results for various image reconstruction applications--even if no ground truth images are available for training.
Overlapping Schwarz Decomposition for Nonlinear Optimal Control
May 14, 2020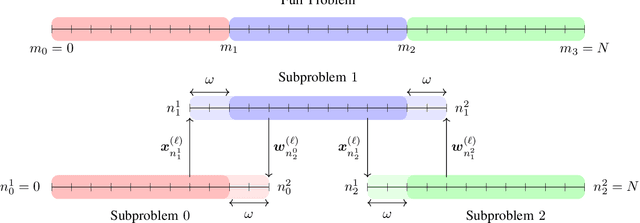
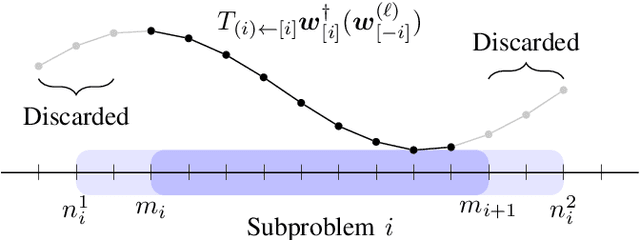
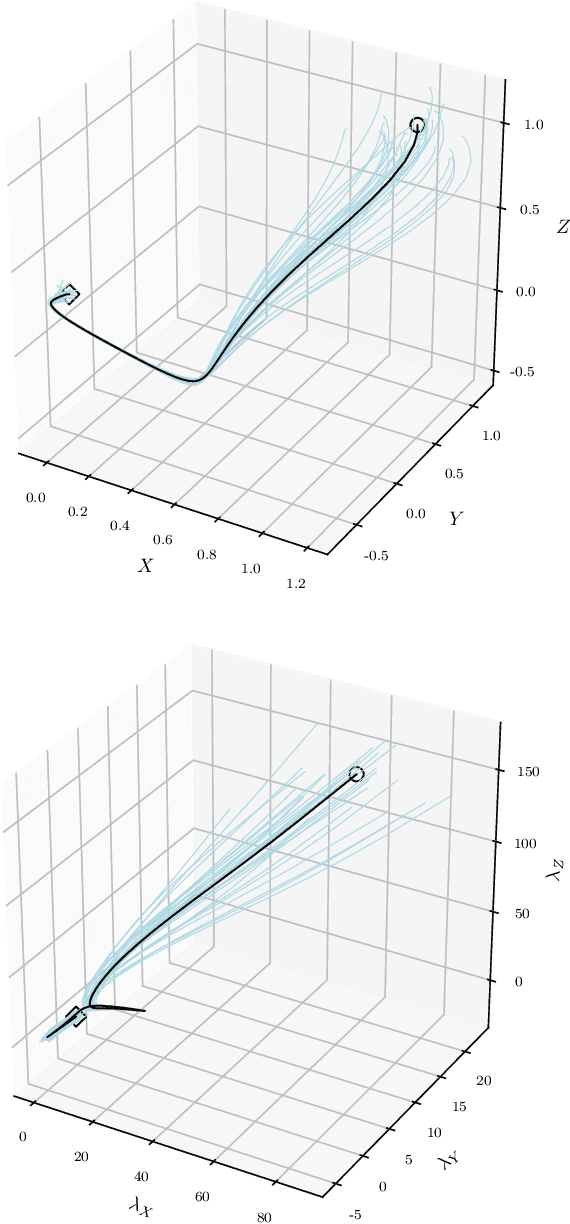
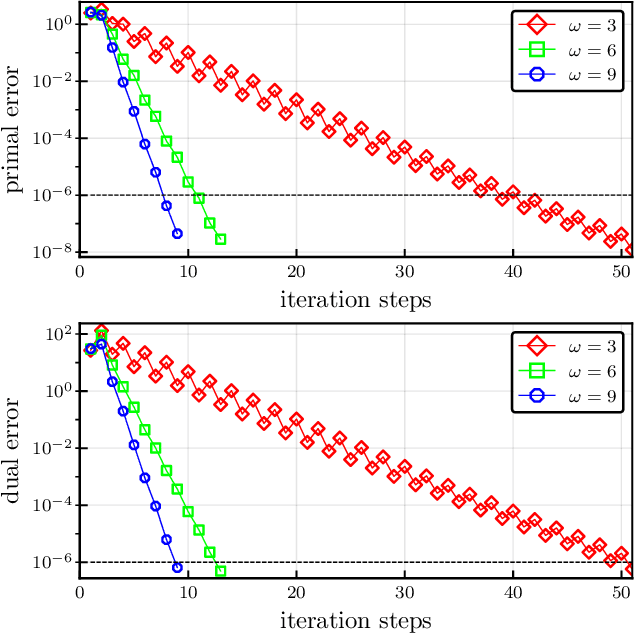
We present an overlapping Schwarz decomposition algorithm for solving nonlinear optimal control problems (OCPs). Our approach decomposes the time domain into a set of overlapping subdomains and solves subproblems defined over such subdomains in parallel. Convergence is attained by updating primal-dual information at the boundaries of the overlapping regions. We show that the algorithm exhibits local convergence and that the convergence rate improves exponentially with the size of the overlap. Our convergence results rely on a sensitivity result for OCPs that we call "asymptotic decay of sensitivity." Intuitively, this result states that impact of parametric perturbations at the boundaries of the time domain (initial and final time) decays exponentially as one moves away from the perturbation points. We show that this condition holds for nonlinear OCPs under a uniform second-order sufficient condition, a controllability condition, and a uniform boundedness condition. The approach is demonstrated by using a highly nonlinear quadrotor motion planning problem.
Sparse Multilevel Roadmaps on Fiber Bundles for High-Dimensional Motion Planning
Nov 02, 2020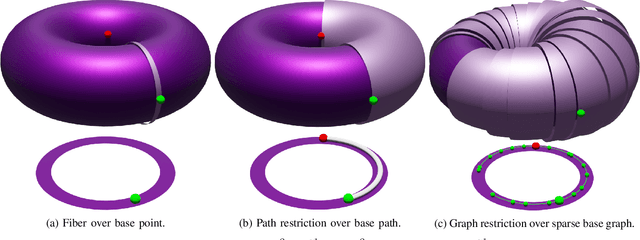
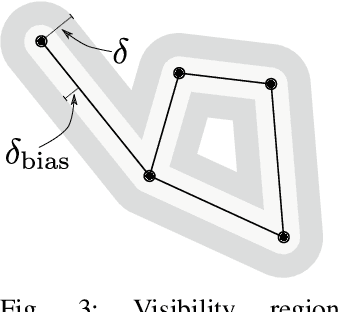
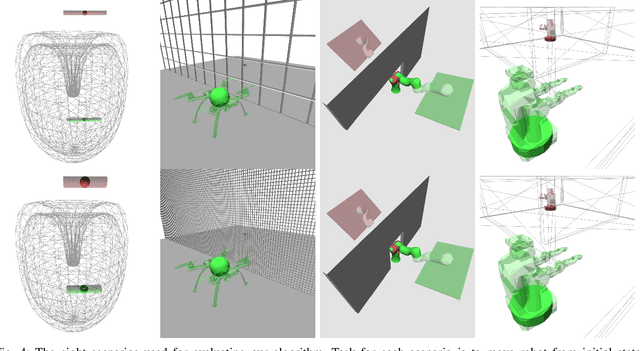
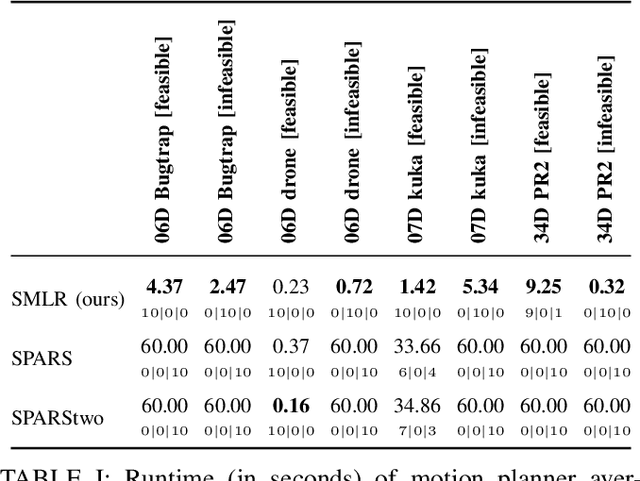
Sparse roadmaps are important to compactly represent state spaces, to determine problems to be infeasible and to terminate in finite time. However, sparse roadmaps do not scale well to high-dimensional planning problems. In prior work, we showed improved planning performance on high-dimensional planning problems by using multilevel abstractions to simplify state spaces. In this work, we generalize sparse roadmaps to multilevel abstractions by developing a novel algorithm, the sparse multilevel roadmap planner (SMLR). To this end, we represent multilevel abstractions using the language of fiber bundles, and generalize sparse roadmap planners by using the concept of restriction sampling with visibility regions. We argue SMLR to be probabilistically complete and asymptotically near-optimal by inheritance from sparse roadmap planners. In evaluations, we outperform sparse roadmap planners on challenging planning problems, in particular problems which are high-dimensional, contain narrow passages or are infeasible. We thereby demonstrate sparse multilevel roadmaps as an efficient tool for feasible and infeasible high-dimensional planning problems.
StarCraft II Build Order Optimization using Deep Reinforcement Learning and Monte-Carlo Tree Search
Jun 12, 2020

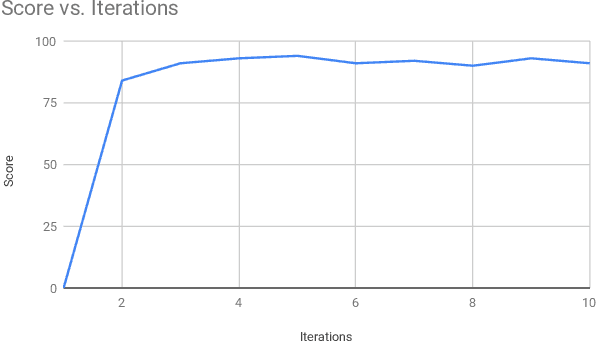

The real-time strategy game of StarCraft II has been posed as a challenge for reinforcement learning by Google's DeepMind. This study examines the use of an agent based on the Monte-Carlo Tree Search algorithm for optimizing the build order in StarCraft II, and discusses how its performance can be improved even further by combining it with a deep reinforcement learning neural network. The experimental results accomplished using Monte-Carlo Tree Search achieves a score similar to a novice human player by only using very limited time and computational resources, which paves the way to achieving scores comparable to those of a human expert by combining it with the use of deep reinforcement learning.
Data-free Knowledge Distillation for Segmentation using Data-Enriching GAN
Nov 02, 2020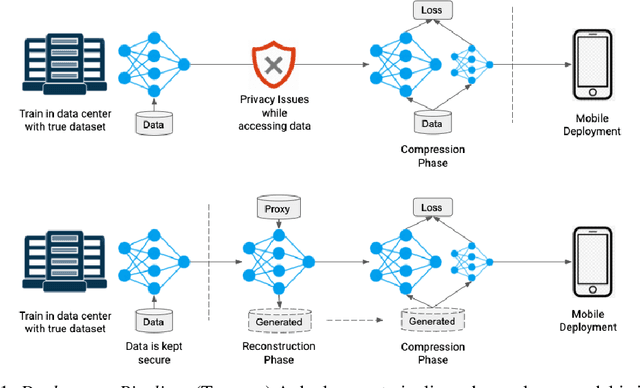
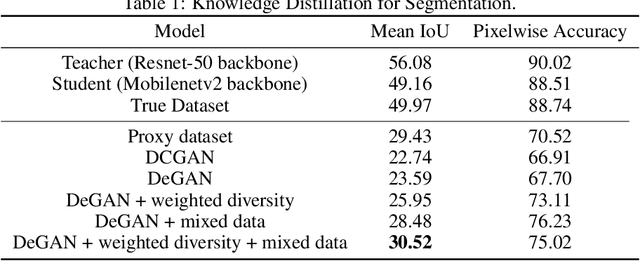
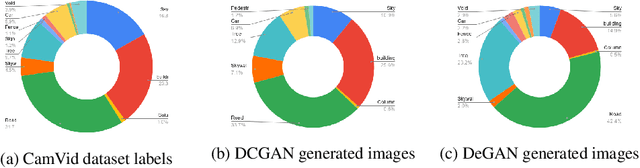
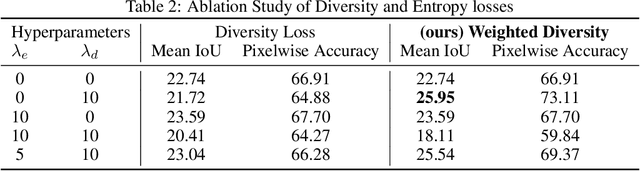
Distilling knowledge from huge pre-trained networks to improve the performance of tiny networks has favored deep learning models to be used in many real-time and mobile applications. Several approaches that demonstrate success in this field have made use of the true training dataset to extract relevant knowledge. In absence of the True dataset, however, extracting knowledge from deep networks is still a challenge. Recent works on data-free knowledge distillation demonstrate such techniques on classification tasks. To this end, we explore the task of data-free knowledge distillation for segmentation tasks. First, we identify several challenges specific to segmentation. We make use of the DeGAN training framework to propose a novel loss function for enforcing diversity in a setting where a few classes are underrepresented. Further, we explore a new training framework for performing knowledge distillation in a data-free setting. We get an improvement of 6.93% in Mean IoU over previous approaches.
Comparison of Attention-based Deep Learning Models for EEG Classification
Dec 02, 2020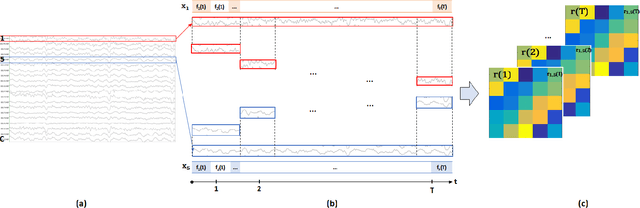
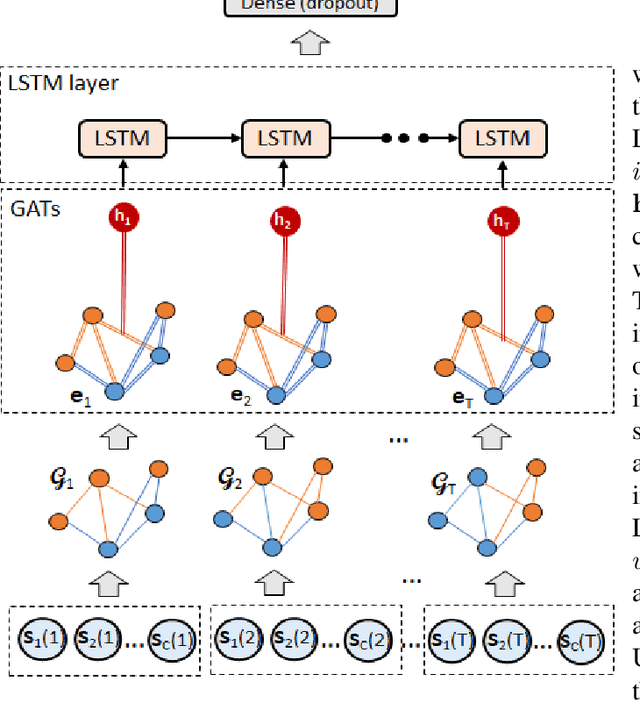
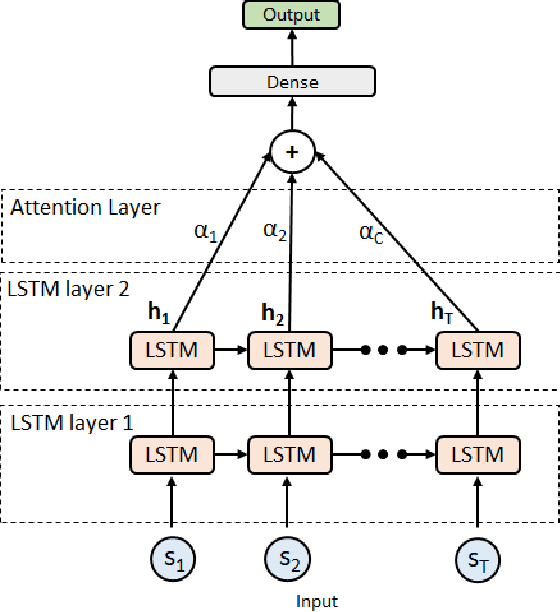
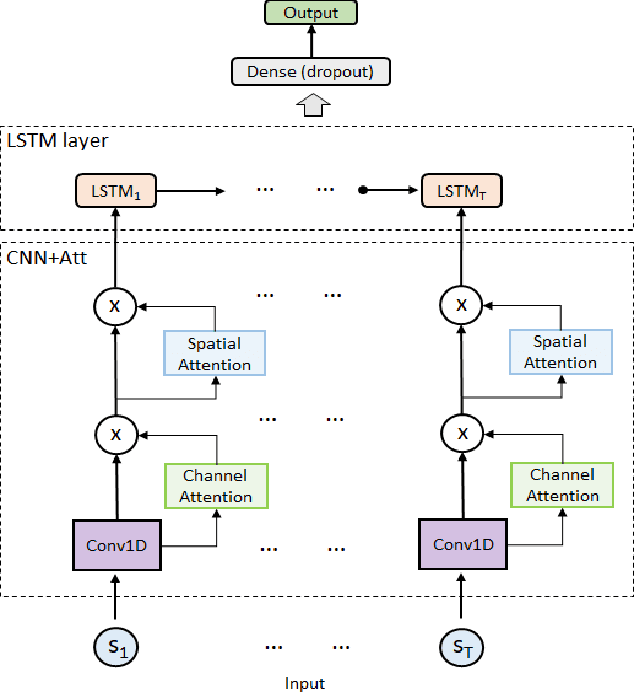
Objective: To evaluate the impact on Electroencephalography (EEG) classification of different kinds of attention mechanisms in Deep Learning (DL) models. Methods: We compared three attention-enhanced DL models, the brand-new InstaGATs, an LSTM with attention and a CNN with attention. We used these models to classify normal and abnormal (i.e., artifactual or pathological) EEG patterns. Results: We achieved the state of the art in all classification problems, regardless the large variability of the datasets and the simple architecture of the attention-enhanced models. We could also prove that, depending on how the attention mechanism is applied and where the attention layer is located in the model, we can alternatively leverage the information contained in the time, frequency or space domain of the dataset. Conclusions: with this work, we shed light over the role of different attention mechanisms in the classification of normal and abnormal EEG patterns. Moreover, we discussed how they can exploit the intrinsic relationships in the temporal, frequency and spatial domains of our brain activity. Significance: Attention represents a promising strategy to evaluate the quality of the EEG information, and its relevance, in different real-world scenarios. Moreover, it can make it easier to parallelize the computation and, thus, to speed up the analysis of big electrophysiological (e.g., EEG) datasets.