 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Deep Learning Approach for COVID-19 Trend Prediction
Aug 09, 2020
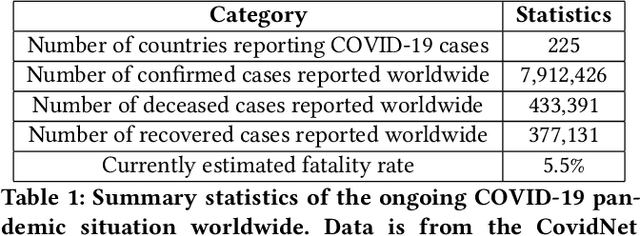
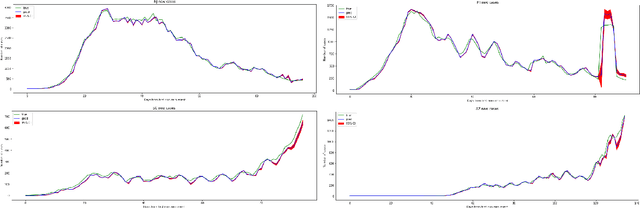
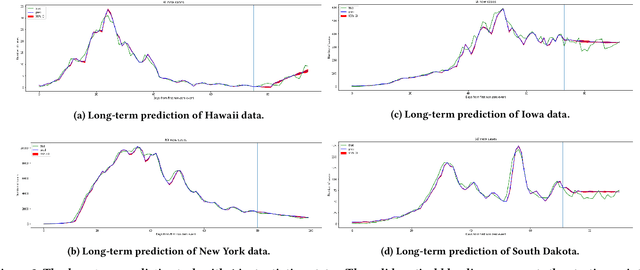
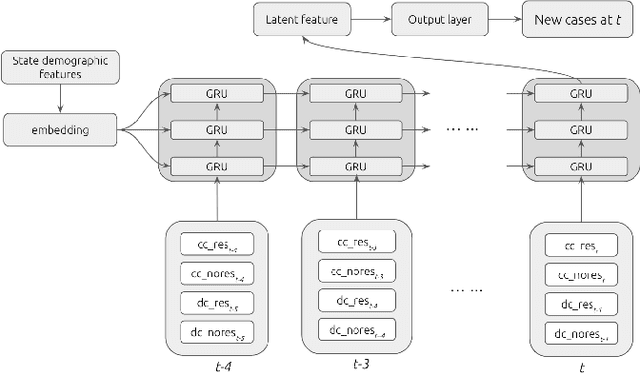
In this work, we developed a deep learning model-based approach to forecast the spreading trend of SARS-CoV-2 in the United States. We implemented the designed model using the United States to confirm cases and state demographic data and achieved promising trend prediction results. The model incorporates demographic information and epidemic time-series data through a Gated Recurrent Unit structure. The identification of dominating demographic factors is delivered in the end.
Human Engagement Providing Evaluative and Informative Advice for Interactive Reinforcement Learning
Sep 21, 2020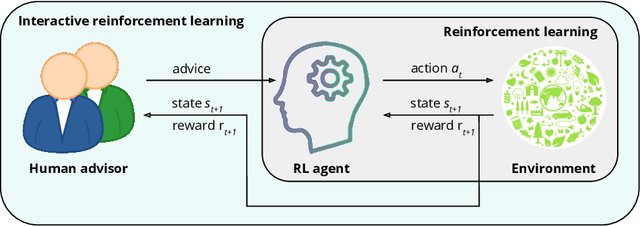

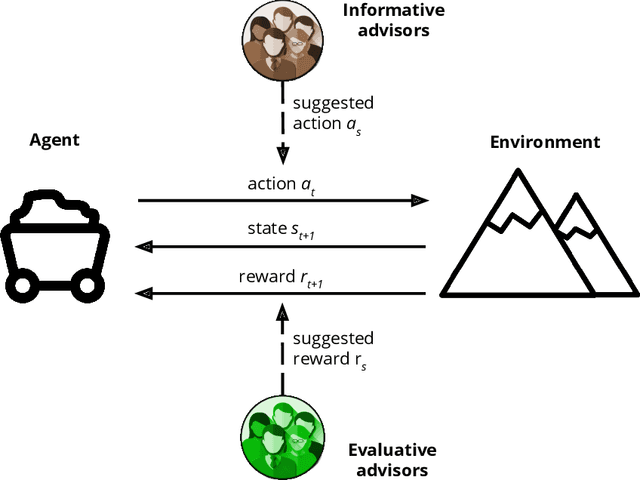
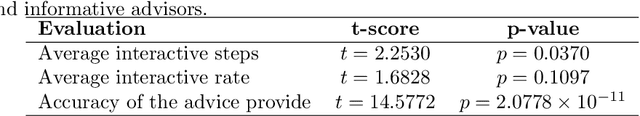
Reinforcement learning is an approach used by intelligent agents to autonomously learn new skills. Although reinforcement learning has been demonstrated to be an effective learning approach in several different contexts, a common drawback exhibited is the time needed in order to satisfactorily learn a task, especially in large state-action spaces. To address this issue, interactive reinforcement learning proposes the use of externally-sourced information in order to speed up the learning process. Up to now, different information sources have been used to give advice to the learner agent, among them human-sourced advice. When interacting with a learner agent, humans may provide either evaluative or informative advice. From the agent's perspective these styles of interaction are commonly referred to as reward-shaping and policy-shaping respectively. Evaluation requires the human to provide feedback on the prior action performed, while informative advice they provide advice on the best action to select for a given situation. Prior research has focused on the effect of human-sourced advice on the interactive reinforcement learning process, specifically aiming to improve the learning speed of the agent, while reducing the engagement with the human. This work presents an experimental setup for a human-trial designed to compare the methods people use to deliver advice in term of human engagement. Obtained results show that users giving informative advice to the learner agents provide more accurate advice, are willing to assist the learner agent for a longer time, and provide more advice per episode. Additionally, self-evaluation from participants using the informative approach has indicated that the agent's ability to follow the advice is higher, and therefore, they feel their own advice to be of higher accuracy when compared to people providing evaluative advice.
Learning Bayesian Networks Under Sparsity Constraints: A Parameterized Complexity Analysis
Apr 30, 2020
We study the problem of learning the structure of an optimal Bayesian network $D$ when additional constraints are posed on the DAG $D$ or on its moralized graph. More precisely, we consider the constraint that the moralized graph can be transformed to a graph from a sparse graph class $\Pi$ by at most $k$ vertex deletions. We show that for $\Pi$ being the graphs with maximum degree $1$, an optimal network can be computed in polynomial time when $k$ is constant, extending previous work that gave an algorithm with such a running time for $\Pi$ being the class of edgeless graphs [Korhonen & Parviainen, NIPS 2015]. We then show that further extensions or improvements are presumably impossible. For example, we show that when $\Pi$ is the set of graphs with maximum degree $2$ or when $\Pi$ is the set of graphs in which each component has size at most three, then learning an optimal network is NP-hard even if $k=0$. Finally, we show that learning an optimal network with at most $k$ edges in the moralized graph presumably has no $f(k)\cdot |I|^{\mathcal{O}(1)}$-time algorithm and that, in contrast, an optimal network with at most $k$ arcs in the DAG $D$ can be computed in $2^{\mathcal{O}(k)}\cdot |I|^{\mathcal{O}(1)}$ time where $|I|$ is the total input size.
Flow-based Generative Models for Learning Manifold to Manifold Mappings
Dec 18, 2020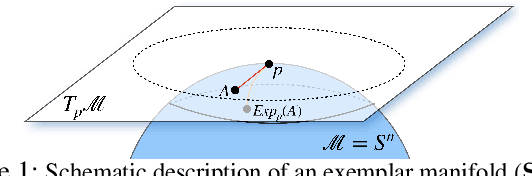
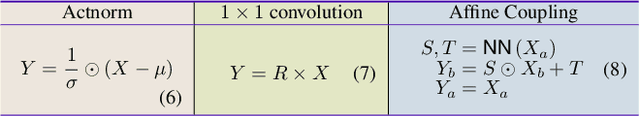
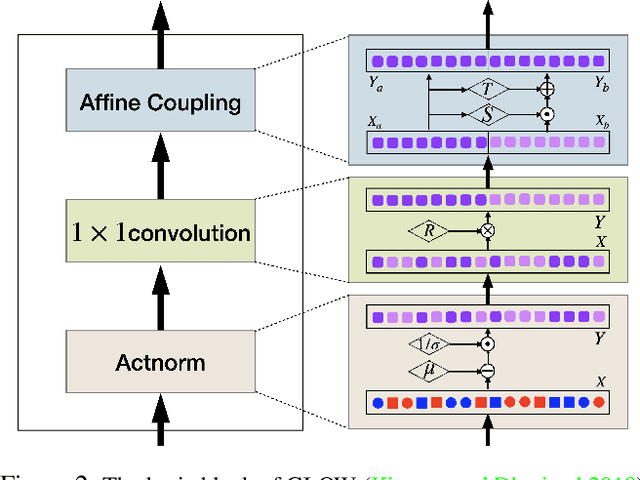

Many measurements or observations in computer vision and machine learning manifest as non-Euclidean data. While recent proposals (like spherical CNN) have extended a number of deep neural network architectures to manifold-valued data, and this has often provided strong improvements in performance, the literature on generative models for manifold data is quite sparse. Partly due to this gap, there are also no modality transfer/translation models for manifold-valued data whereas numerous such methods based on generative models are available for natural images. This paper addresses this gap, motivated by a need in brain imaging -- in doing so, we expand the operating range of certain generative models (as well as generative models for modality transfer) from natural images to images with manifold-valued measurements. Our main result is the design of a two-stream version of GLOW (flow-based invertible generative models) that can synthesize information of a field of one type of manifold-valued measurements given another. On the theoretical side, we introduce three kinds of invertible layers for manifold-valued data, which are not only analogous to their functionality in flow-based generative models (e.g., GLOW) but also preserve the key benefits (determinants of the Jacobian are easy to calculate). For experiments, on a large dataset from the Human Connectome Project (HCP), we show promising results where we can reliably and accurately reconstruct brain images of a field of orientation distribution functions (ODF) from diffusion tensor images (DTI), where the latter has a $5\times$ faster acquisition time but at the expense of worse angular resolution.
3D Probabilistic Segmentation and Volumetry from 2D projection images
Jun 23, 2020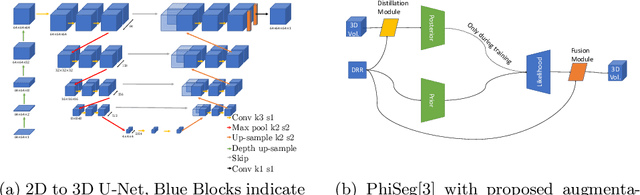
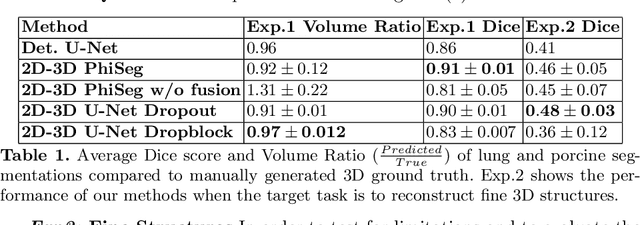

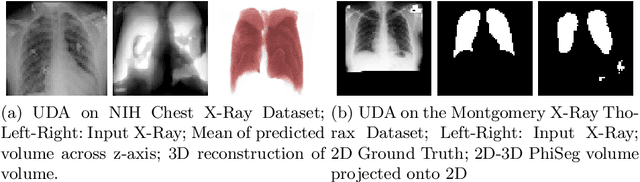
X-Ray imaging is quick, cheap and useful for front-line care assessment and intra-operative real-time imaging (e.g., C-Arm Fluoroscopy). However, it suffers from projective information loss and lacks vital volumetric information on which many essential diagnostic biomarkers are based on. In this paper we explore probabilistic methods to reconstruct 3D volumetric images from 2D imaging modalities and measure the models' performance and confidence. We show our models' performance on large connected structures and we test for limitations regarding fine structures and image domain sensitivity. We utilize fast end-to-end training of a 2D-3D convolutional networks, evaluate our method on 117 CT scans segmenting 3D structures from digitally reconstructed radiographs (DRRs) with a Dice score of $0.91 \pm 0.0013$. Source code will be made available by the time of the conference.
A Data-driven Understanding of COVID-19 Dynamics Using Sequential Genetic Algorithm Based Probabilistic Cellular Automata
Aug 27, 2020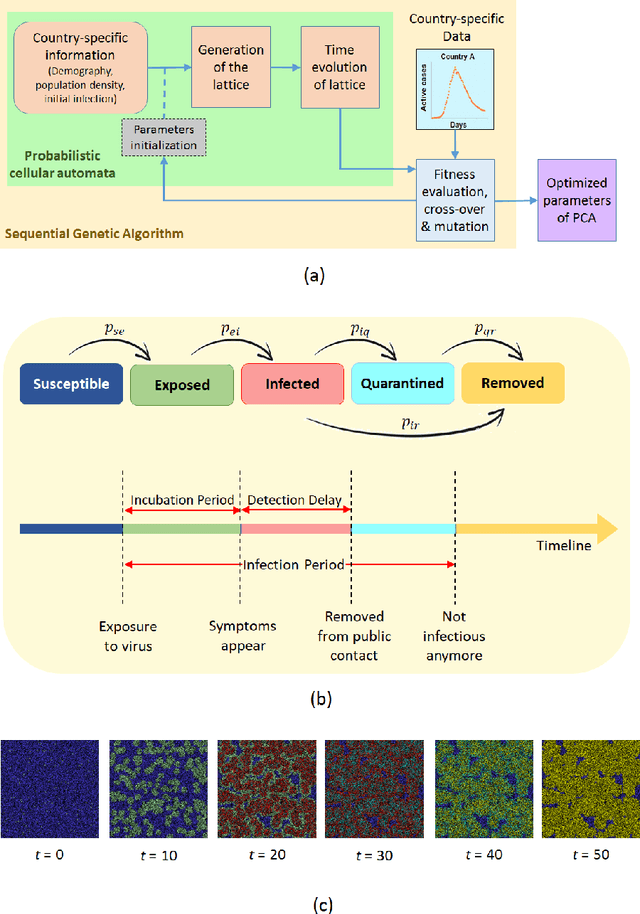

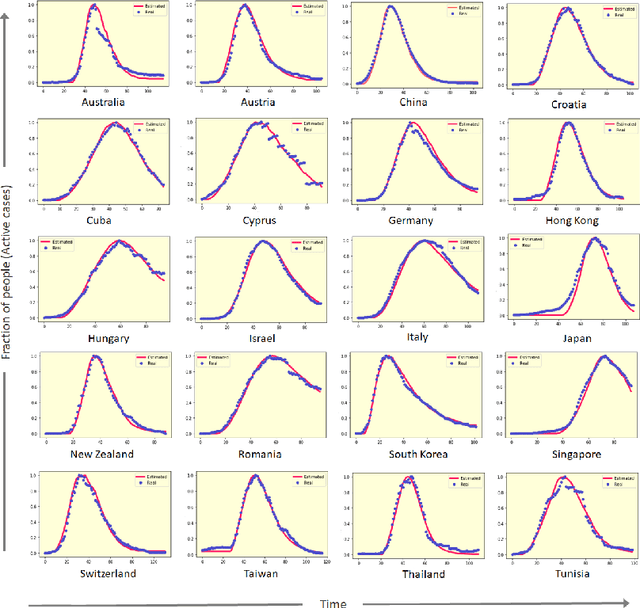
COVID-19 pandemic is severely impacting the lives of billions across the globe. Even after taking massive protective measures like nation-wide lockdowns, discontinuation of international flight services, rigorous testing etc., the infection spreading is still growing steadily, causing thousands of deaths and serious socio-economic crisis. Thus, the identification of the major factors of this infection spreading dynamics is becoming crucial to minimize impact and lifetime of COVID-19 and any future pandemic. In this work, a probabilistic cellular automata based method has been employed to model the infection dynamics for a significant number of different countries. This study proposes that for an accurate data-driven modeling of this infection spread, cellular automata provides an excellent platform, with a sequential genetic algorithm for efficiently estimating the parameters of the dynamics. To the best of our knowledge, this is the first attempt to understand and interpret COVID-19 data using optimized cellular automata, through genetic algorithm. It has been demonstrated that the proposed methodology can be flexible and robust at the same time, and can be used to model the daily active cases, total number of infected people and total death cases through systematic parameter estimation. Elaborate analyses for COVID-19 statistics of forty countries from different continents have been performed, with markedly divergent time evolution of the infection spreading because of demographic and socioeconomic factors. The substantial predictive power of this model has been established with conclusions on the key players in this pandemic dynamics.
Spatio-temporal Multi-task Learning for Cardiac MRI Left Ventricle Quantification
Dec 24, 2020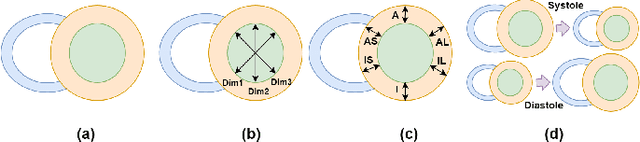
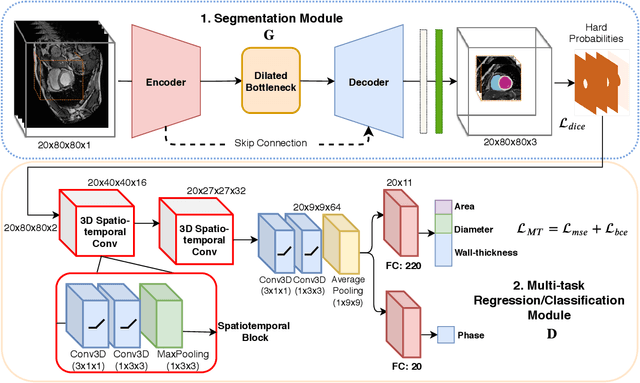
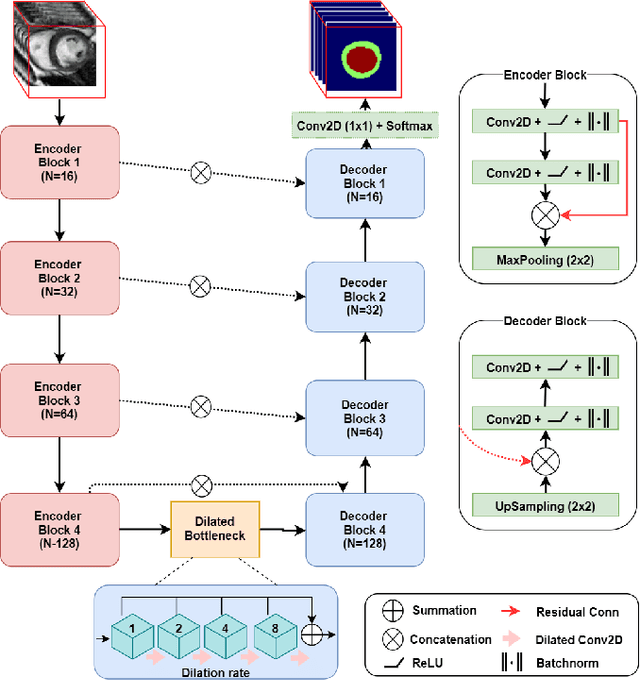
Quantitative assessment of cardiac left ventricle (LV) morphology is essential to assess cardiac function and improve the diagnosis of different cardiovascular diseases. In current clinical practice, LV quantification depends on the measurement of myocardial shape indices, which is usually achieved by manual contouring of the endo- and epicardial. However, this process subjected to inter and intra-observer variability, and it is a time-consuming and tedious task. In this paper, we propose a spatio-temporal multi-task learning approach to obtain a complete set of measurements quantifying cardiac LV morphology, regional-wall thickness (RWT), and additionally detecting the cardiac phase cycle (systole and diastole) for a given 3D Cine-magnetic resonance (MR) image sequence. We first segment cardiac LVs using an encoder-decoder network and then introduce a multitask framework to regress 11 LV indices and classify the cardiac phase, as parallel tasks during model optimization. The proposed deep learning model is based on the 3D spatio-temporal convolutions, which extract spatial and temporal features from MR images. We demonstrate the efficacy of the proposed method using cine-MR sequences of 145 subjects and comparing the performance with other state-of-the-art quantification methods. The proposed method obtained high prediction accuracy, with an average mean absolute error (MAE) of 129 $mm^2$, 1.23 $mm$, 1.76 $mm$, Pearson correlation coefficient (PCC) of 96.4%, 87.2%, and 97.5% for LV and myocardium (Myo) cavity regions, 6 RWTs, 3 LV dimensions, and an error rate of 9.0\% for phase classification. The experimental results highlight the robustness of the proposed method, despite varying degrees of cardiac morphology, image appearance, and low contrast in the cardiac MR sequences.
Bespoke Neural Networks for Score-Informed Source Separation
Sep 29, 2020In this paper, we introduce a simple method that can separate arbitrary musical instruments from an audio mixture. Given an unaligned MIDI transcription for a target instrument from an input mixture, we synthesize new mixtures from the midi transcription that sound similar to the mixture to be separated. This lets us create a labeled training set to train a network on the specific bespoke task. When this model applied to the original mixture, we demonstrate that this method can: 1) successfully separate out the desired instrument with access to only unaligned MIDI, 2) separate arbitrary instruments, and 3) get results in a fraction of the time of existing methods. We encourage readers to listen to the demos posted here: https://git.io/JUu5q.
A deep learning approach to real-time parking occupancy prediction in spatio-termporal networks incorporating multiple spatio-temporal data sources
Jan 28, 2019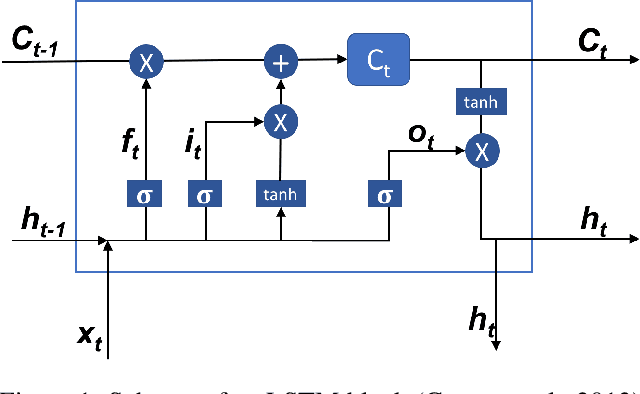
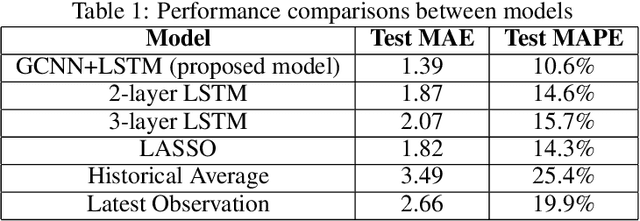
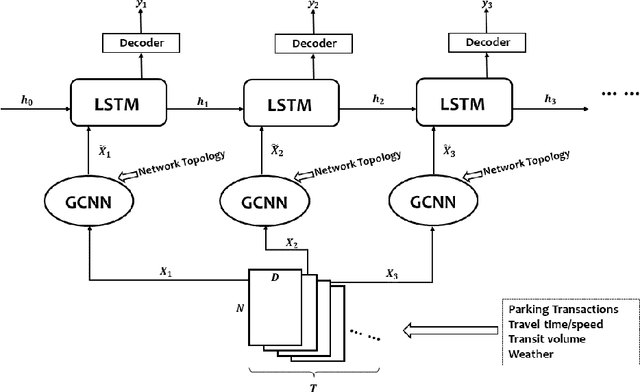
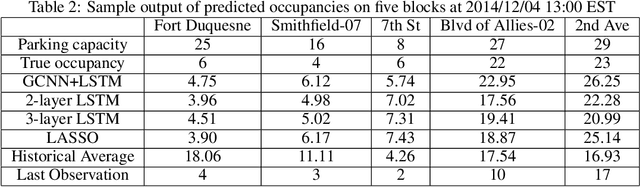
A deep learning model is proposed for predicting block-level parking occupancy in real time. The model leverages Graph-Convolutional Neural Networks (GCNN) to extract the spatial relations of traffic flow in large-scale networks, and utilizes Recurrent Neural Networks (RNN) with Long-Short Term Memory (LSTM) to capture the temporal features. In addition, the model is capable of taking multiple heterogeneously structured traffic data sources as input, such as parking meter transactions, traffic speed, and weather conditions. The model performance is evaluated through a case study in Pittsburgh downtown area. The proposed model outperforms other baseline methods including multi-layer LSTM and Lasso with an average testing MAPE of 12.0\% when predicting block-level parking occupancies 30 minutes in advance. The case study also shows that, in generally, the prediction model works better for business areas than for recreational locations. We found that incorporating traffic speed and weather information can significantly improve the prediction performance. Weather data is particularly useful for improving predicting accuracy in recreational areas.
Adversarial Attacks Against Deep Learning Systems for ICD-9 Code Assignment
Sep 29, 2020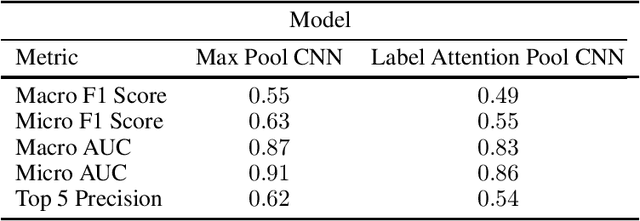
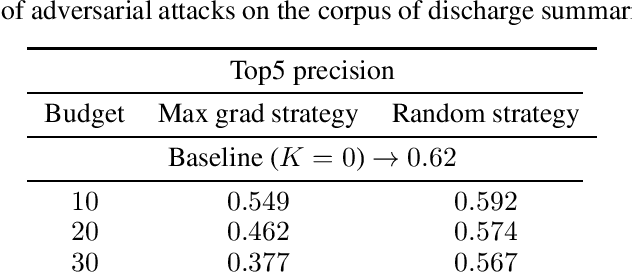

Manual annotation of ICD-9 codes is a time consuming and error-prone process. Deep learning based systems tackling the problem of automated ICD-9 coding have achieved competitive performance. Given the increased proliferation of electronic medical records, such automated systems are expected to eventually replace human coders. In this work, we investigate how a simple typo-based adversarial attack strategy can impact the performance of state-of-the-art models for the task of predicting the top 50 most frequent ICD-9 codes from discharge summaries. Preliminary results indicate that a malicious adversary, using gradient information, can craft specific perturbations, that appear as regular human typos, for less than 3% of words in the discharge summary to significantly affect the performance of the baseline model.