 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Some Algorithms on Exact, Approximate and Error-Tolerant Graph Matching
Dec 30, 2020
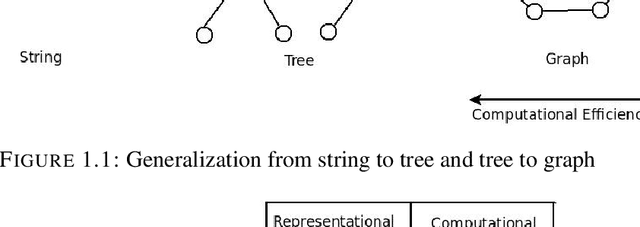
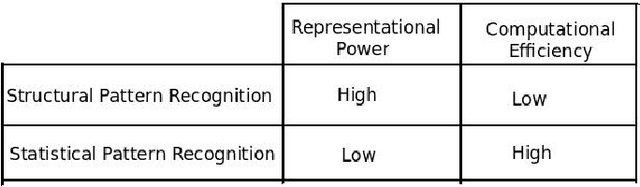
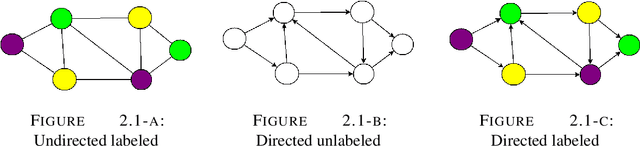
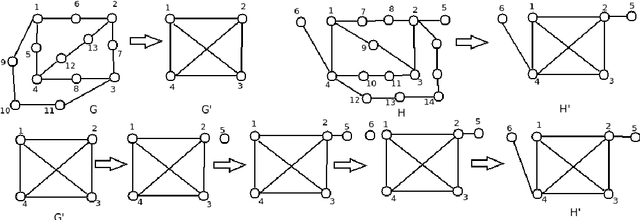
The graph is one of the most widely used mathematical structures in engineering and science because of its representational power and inherent ability to demonstrate the relationship between objects. The objective of this work is to introduce the novel graph matching techniques using the representational power of the graph and apply it to structural pattern recognition applications. We present an extensive survey of various exact and inexact graph matching techniques. Graph matching using the concept of homeomorphism is presented. A category of graph matching algorithms is presented, which reduces the graph size by removing the less important nodes using some measure of relevance. We present an approach to error-tolerant graph matching using node contraction where the given graph is transformed into another graph by contracting smaller degree nodes. We use this scheme to extend the notion of graph edit distance, which can be used as a trade-off between execution time and accuracy. We describe an approach to graph matching by utilizing the various node centrality information, which reduces the graph size by removing a fraction of nodes from both graphs based on a given centrality measure. The graph matching problem is inherently linked to the geometry and topology of graphs. We introduce a novel approach to measure graph similarity using geometric graphs. We define the vertex distance between two geometric graphs using the position of their vertices and show it to be a metric over the set of all graphs with vertices only. We define edge distance between two graphs based on the angular orientation, length and position of the edges. Then we combine the notion of vertex distance and edge distance to define the graph distance between two geometric graphs and show it to be a metric. Finally, we use the proposed graph similarity framework to perform exact and error-tolerant graph matching.
Random Walks: A Review of Algorithms and Applications
Aug 09, 2020
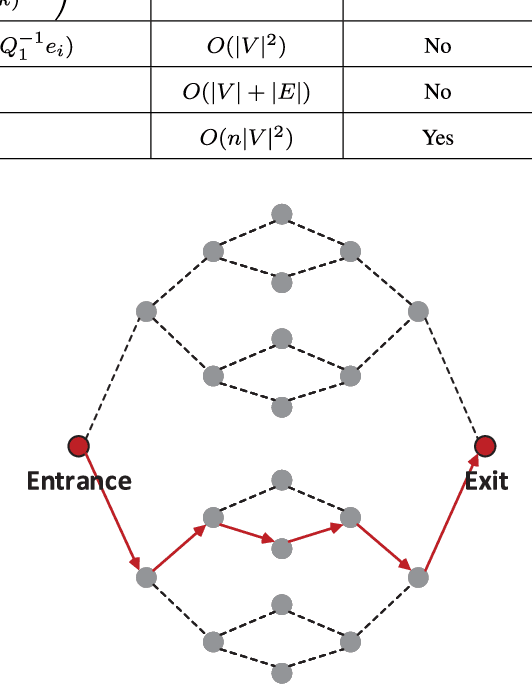
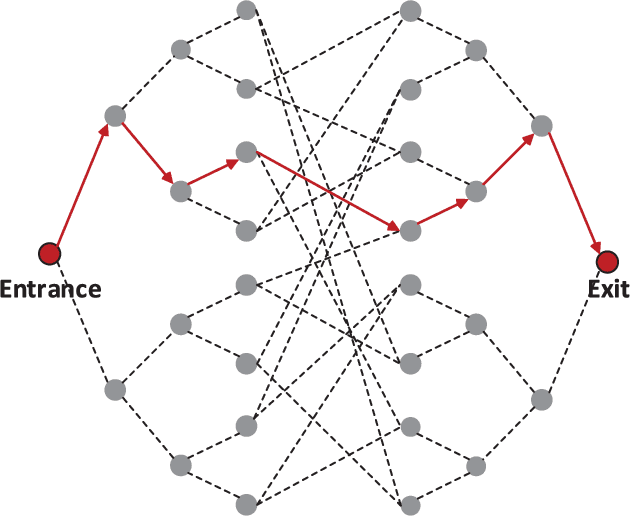
A random walk is known as a random process which describes a path including a succession of random steps in the mathematical space. It has increasingly been popular in various disciplines such as mathematics and computer science. Furthermore, in quantum mechanics, quantum walks can be regarded as quantum analogues of classical random walks. Classical random walks and quantum walks can be used to calculate the proximity between nodes and extract the topology in the network. Various random walk related models can be applied in different fields, which is of great significance to downstream tasks such as link prediction, recommendation, computer vision, semi-supervised learning, and network embedding. In this paper, we aim to provide a comprehensive review of classical random walks and quantum walks. We first review the knowledge of classical random walks and quantum walks, including basic concepts and some typical algorithms. We also compare the algorithms based on quantum walks and classical random walks from the perspective of time complexity. Then we introduce their applications in the field of computer science. Finally we discuss the open issues from the perspectives of efficiency, main-memory volume, and computing time of existing algorithms. This study aims to contribute to this growing area of research by exploring random walks and quantum walks together.
* 13 pages, 4 figures
Quick Question: Interrupting Users for Microtasks with Reinforcement Learning
Jul 18, 2020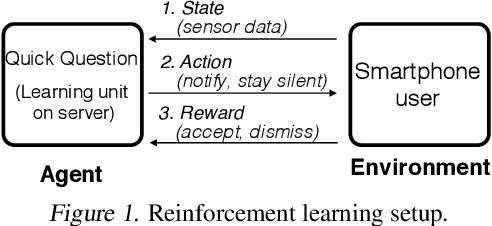
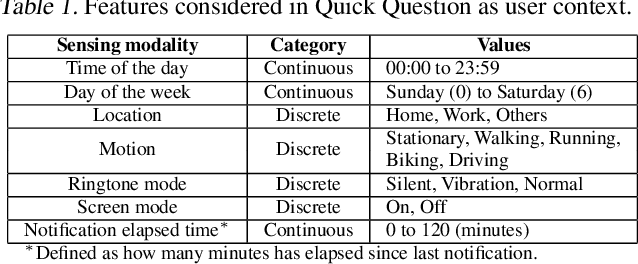
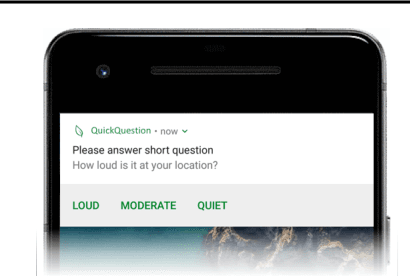

Human attention is a scarce resource in modern computing. A multitude of microtasks vie for user attention to crowdsource information, perform momentary assessments, personalize services, and execute actions with a single touch. A lot gets done when these tasks take up the invisible free moments of the day. However, an interruption at an inappropriate time degrades productivity and causes annoyance. Prior works have exploited contextual cues and behavioral data to identify interruptibility for microtasks with much success. With Quick Question, we explore use of reinforcement learning (RL) to schedule microtasks while minimizing user annoyance and compare its performance with supervised learning. We model the problem as a Markov decision process and use Advantage Actor Critic algorithm to identify interruptible moments based on context and history of user interactions. In our 5-week, 30-participant study, we compare the proposed RL algorithm against supervised learning methods. While the mean number of responses between both methods is commensurate, RL is more effective at avoiding dismissal of notifications and improves user experience over time.
Big Networks: A Survey
Aug 09, 2020


A network is a typical expressive form of representing complex systems in terms of vertices and links, in which the pattern of interactions amongst components of the network is intricate. The network can be static that does not change over time or dynamic that evolves through time. The complication of network analysis is different under the new circumstance of network size explosive increasing. In this paper, we introduce a new network science concept called big network. Big networks are generally in large-scale with a complicated and higher-order inner structure. This paper proposes a guideline framework that gives an insight into the major topics in the area of network science from the viewpoint of a big network. We first introduce the structural characteristics of big networks from three levels, which are micro-level, meso-level, and macro-level. We then discuss some state-of-the-art advanced topics of big network analysis. Big network models and related approaches, including ranking methods, partition approaches, as well as network embedding algorithms are systematically introduced. Some typical applications in big networks are then reviewed, such as community detection, link prediction, recommendation, etc. Moreover, we also pinpoint some critical open issues that need to be investigated further.
* 69 pages, 4 figures
Artificial Neural Variability for Deep Learning: On Overfitting, Noise Memorization, and Catastrophic Forgetting
Nov 24, 2020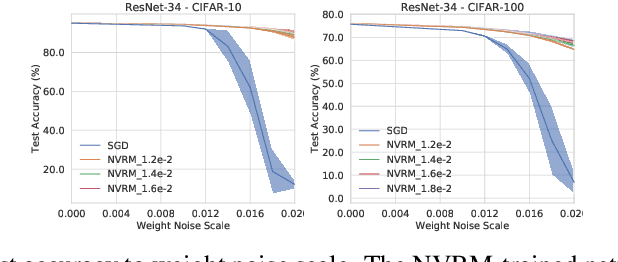
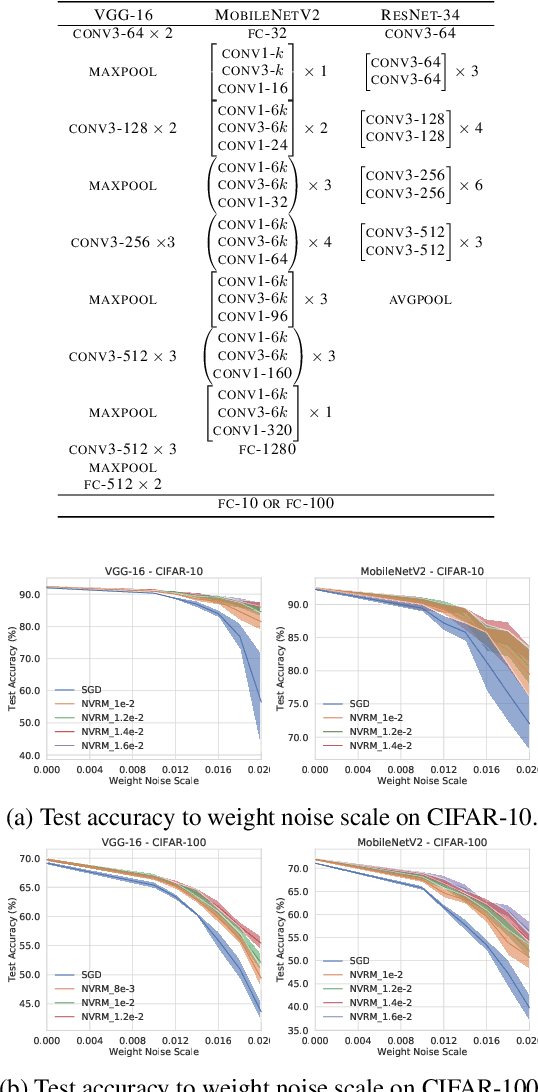
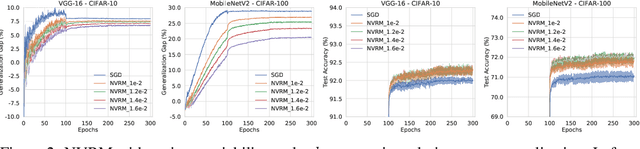
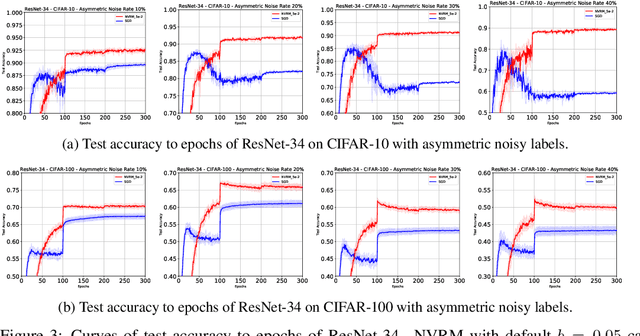
Deep learning is often criticized by two serious issues which rarely exist in natural nervous systems: overfitting and catastrophic forgetting. It can even memorize randomly labelled data, which has little knowledge behind the instance-label pairs. When a deep network continually learns over time by accommodating new tasks, it usually quickly overwrites the knowledge learned from previous tasks. Referred to as the neural variability, it is well-known in neuroscience that human brain reactions exhibit substantial variability even in response to the same stimulus. This mechanism balances accuracy and plasticity/flexibility in the motor learning of natural nervous systems. Thus it motivates us to design a similar mechanism named artificial neural variability (ANV), which helps artificial neural networks learn some advantages from "natural" neural networks. We rigorously prove that ANV plays as an implicit regularizer of the mutual information between the training data and the learned model. This result theoretically guarantees ANV a strictly improved generalizability, robustness to label noise, and robustness to catastrophic forgetting. We then devise a neural variable risk minimization (NVRM) framework and neural variable optimizers to achieve ANV for conventional network architectures in practice. The empirical studies demonstrate that NVRM can effectively relieve overfitting, label noise memorization, and catastrophic forgetting at negligible costs.
Gentlemen on the Road: Effect of Yielding Behavior of Autonomous Vehicle on Pedestrian Head Orientation
May 16, 2020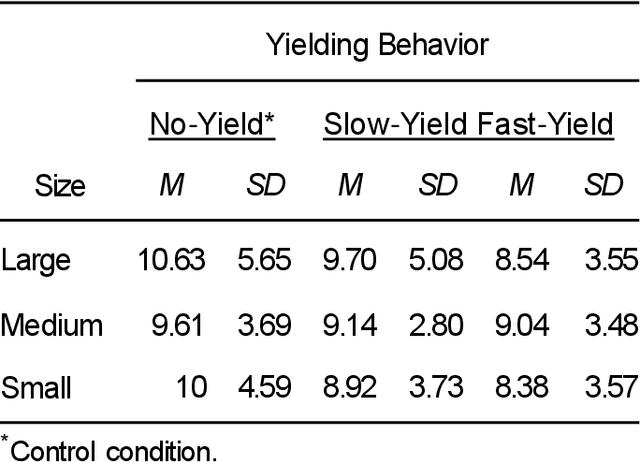

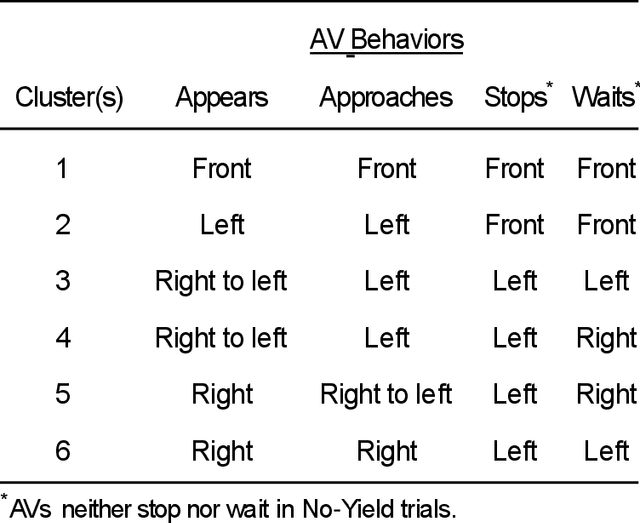
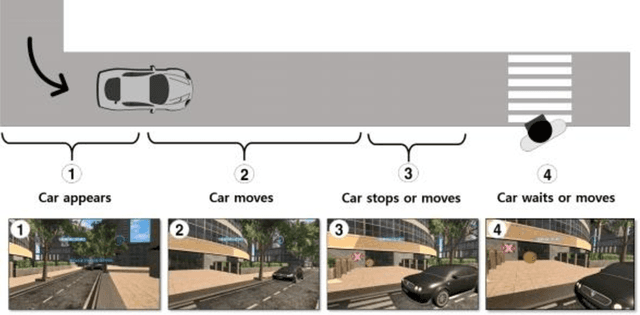
Autonomous vehicles can improve pedestrian safety by learning human-like social behaviors (e.g., yielding). We conducted a virtual reality experiment with 39 participants and measured crossing times (seconds) and head orientation (yaw degrees). We manipulated AV yielding behavior (no-yield, slow-yield, and fast-yield) and the AV size (small, medium, and large). Using Dynamic time warping and K-means clustering, we classified the head orientation change of pedestrians by time into 6 clusters of patterns. Results indicate that head orientation change of pedestrians was influenced by AV yielding behavior as well as the size of the AV. Participants fixated on the front most of the time even when the car approached near. Participants changed head orientation most frequently when a large size AV did not yield (no-yield). In post-experiment interviews, participants reported that yielding behavior and size affected their decision to cross and perceived safety. For autonomous vehicles to be perceived as more safe and trustful, vehicle-specific factors such as size and yielding behavior should be considered in the designing process.
11 TeraFLOPs per second photonic convolutional accelerator for deep learning optical neural networks
Nov 14, 2020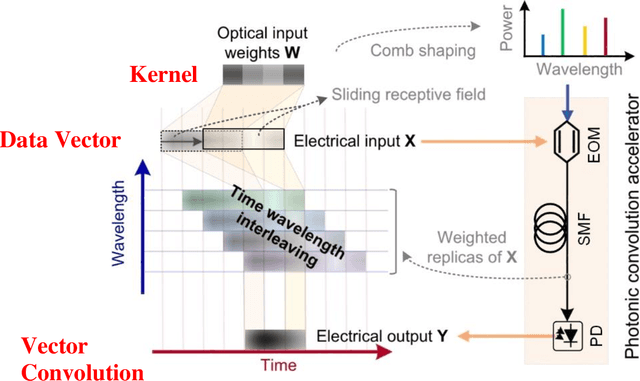
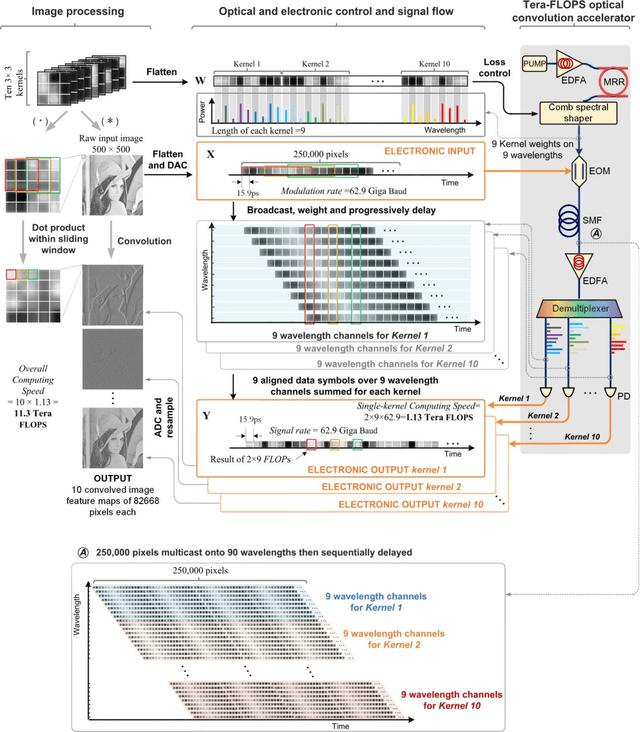
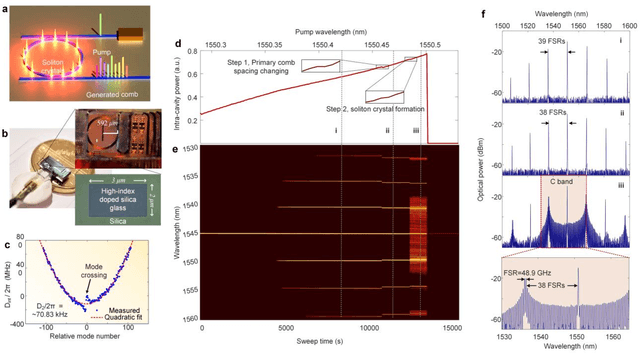
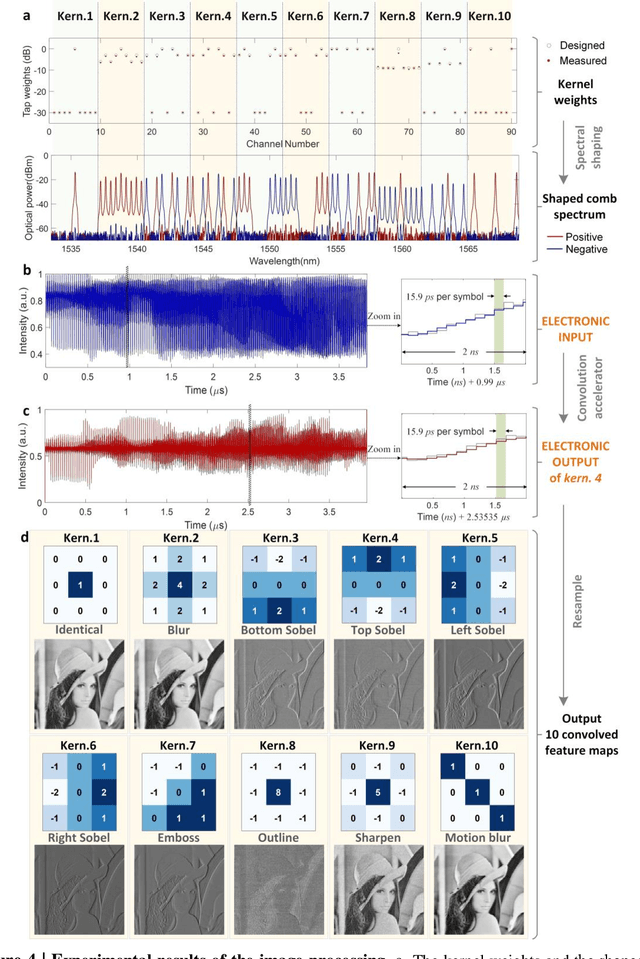
Convolutional neural networks (CNNs), inspired by biological visual cortex systems, are a powerful category of artificial neural networks that can extract the hierarchical features of raw data to greatly reduce the network parametric complexity and enhance the predicting accuracy. They are of significant interest for machine learning tasks such as computer vision, speech recognition, playing board games and medical diagnosis. Optical neural networks offer the promise of dramatically accelerating computing speed to overcome the inherent bandwidth bottleneck of electronics. Here, we demonstrate a universal optical vector convolutional accelerator operating beyond 10 TeraFLOPS (floating point operations per second), generating convolutions of images of 250,000 pixels with 8 bit resolution for 10 kernels simultaneously, enough for facial image recognition. We then use the same hardware to sequentially form a deep optical CNN with ten output neurons, achieving successful recognition of full 10 digits with 900 pixel handwritten digit images with 88% accuracy. Our results are based on simultaneously interleaving temporal, wavelength and spatial dimensions enabled by an integrated microcomb source. This approach is scalable and trainable to much more complex networks for demanding applications such as unmanned vehicle and real-time video recognition.
Discovery of the Hidden State in Ionic Models Using a Domain-Specific Recurrent Neural Network
Nov 14, 2020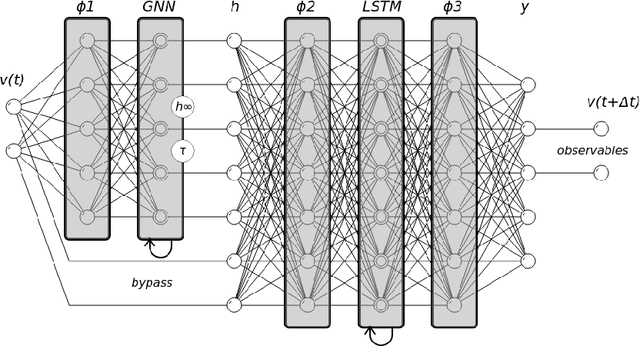
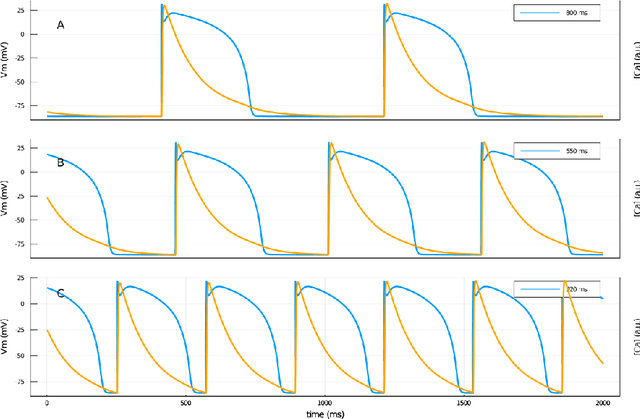
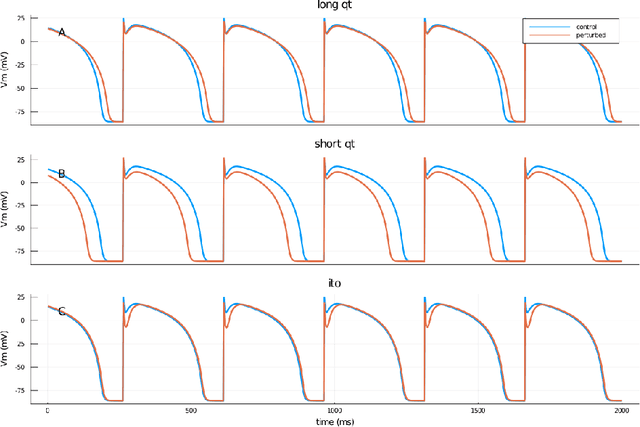
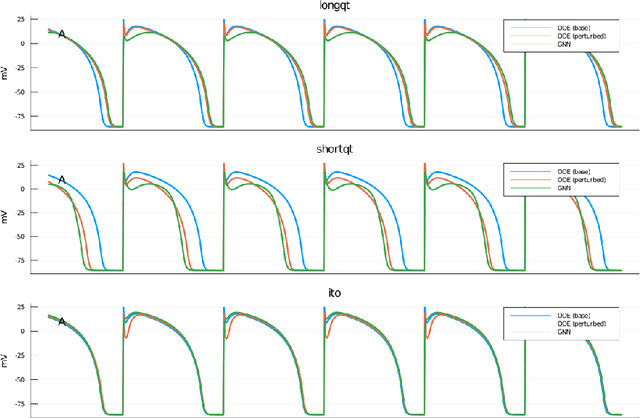
Ionic models, the set of ordinary differential equations (ODEs) describing the time evolution of the state of excitable cells, are the cornerstone of modeling in neuro- and cardiac electrophysiology. Modern ionic models can have tens of state variables and hundreds of tunable parameters. Fitting ionic models to experimental data, which usually covers only a limited subset of state variables, remains a challenging problem. In this paper, we describe a recurrent neural network architecture designed specifically to encode ionic models. The core of the model is a Gating Neural Network (GNN) layer, capturing the dynamics of classic (Hodgkin-Huxley) gating variables. The network is trained in two steps: first, it learns the theoretical model coded in a set of ODEs, and second, it is retrained on experimental data. The retrained network is interpretable, such that its results can be incorporated back into the model ODEs. We tested the GNN networks using simulated ventricular action potential signals and showed that it could deduce physiologically-feasible alterations of ionic currents. Such domain-specific neural networks can be employed in the exploratory phase of data assimilation before further fine-tuning using standard optimization techniques.
No Answer is Better Than Wrong Answer: A Reflection Model for Document Level Machine Reading Comprehension
Sep 29, 2020
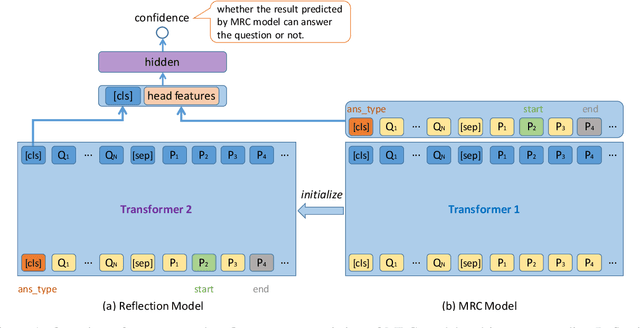

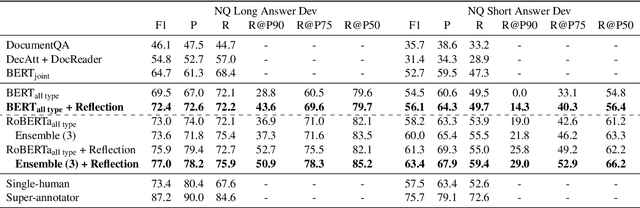
The Natural Questions (NQ) benchmark set brings new challenges to Machine Reading Comprehension: the answers are not only at different levels of granularity (long and short), but also of richer types (including no-answer, yes/no, single-span and multi-span). In this paper, we target at this challenge and handle all answer types systematically. In particular, we propose a novel approach called Reflection Net which leverages a two-step training procedure to identify the no-answer and wrong-answer cases. Extensive experiments are conducted to verify the effectiveness of our approach. At the time of paper writing (May.~20,~2020), our approach achieved the top 1 on both long and short answer leaderboard, with F1 scores of 77.2 and 64.1, respectively.
COVID-MTL: Multitask Learning with Shift3D and Random-weighted Loss for Diagnosis and Severity Assessment of COVID-19
Dec 10, 2020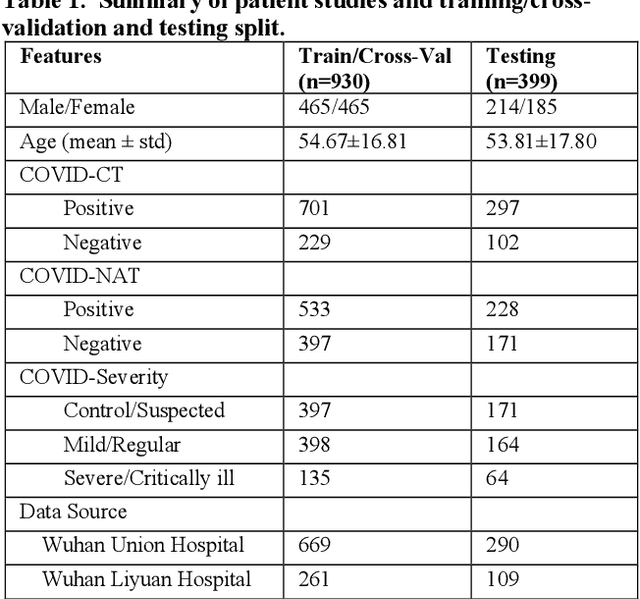
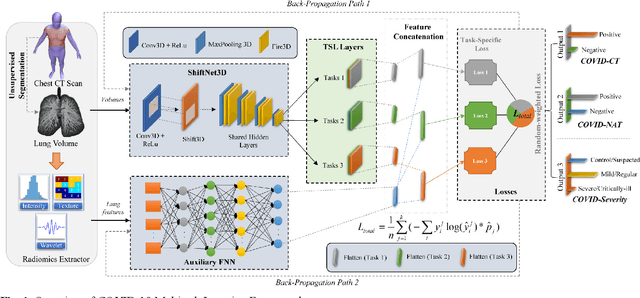
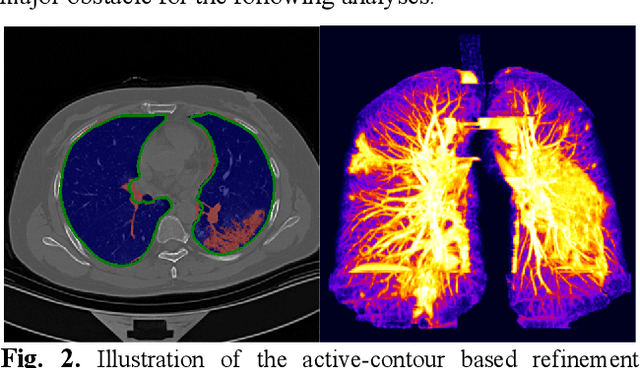
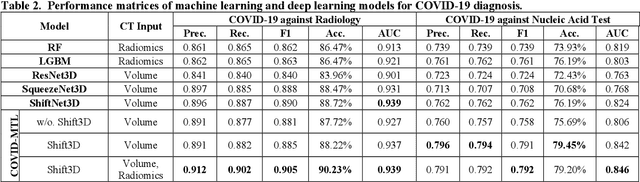
The outbreak of COVID-19 has resulted in over 67 million infections with over 1.5 million deaths worldwide so far. Both computer tomography (CT) diagnosis and nucleic acid test (NAT) have their pros and cons. Here we present a multitask-learning (MTL) framework, termed COVID-MTL, which is capable of simultaneously detecting COVID-19 against both radiology and NAT as well as assessing infection severity. We proposed an active-contour based method to refine lung segmentation results on COVID-19 CT scans and a Shift3D real-time 3D augmentation algorithm to improve the convergence and accuracy of state-of-the-art 3D CNNs. A random-weighted multitask loss function was then proposed, which made simultaneous learning of different COVID-19 tasks more stable and accurate. By only using CT data and extracting lung imaging features, COVID-MTL was trained on 930 CT scans and tested on another 399 cases, which yielded AUCs of 0.939 and 0.846, and accuracies of 90.23% and 79.20% for detection of COVID-19 against radiology and NAT, respectively, and outperformed state-of-the-art models. COVID-MTL yielded AUC of 0.800 $\pm$ 0.020 and 0.813 $\pm$ 0.021 (with transfer learning) for classifying control/suspected (AUC of 0.841), mild/regular (AUC of 0.808), and severe/critically-ill (AUC of 0.789) cases. Besides, we identified top imaging biomarkers that are significantly related (P < 0.001) to the positivity and severity of COVID-19.