 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Overlapping Schwarz Decomposition for Nonlinear Optimal Control
May 15, 2020
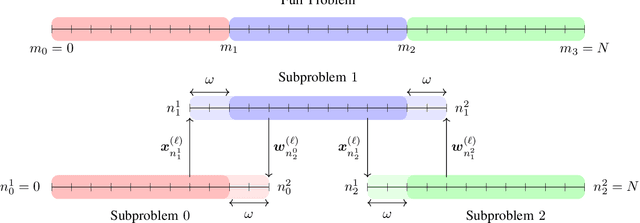
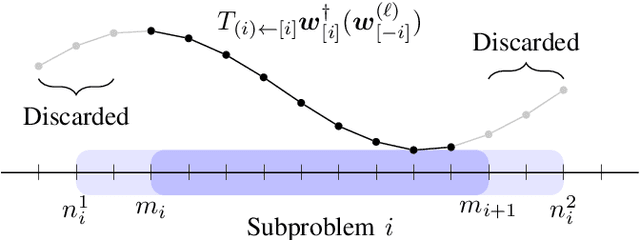
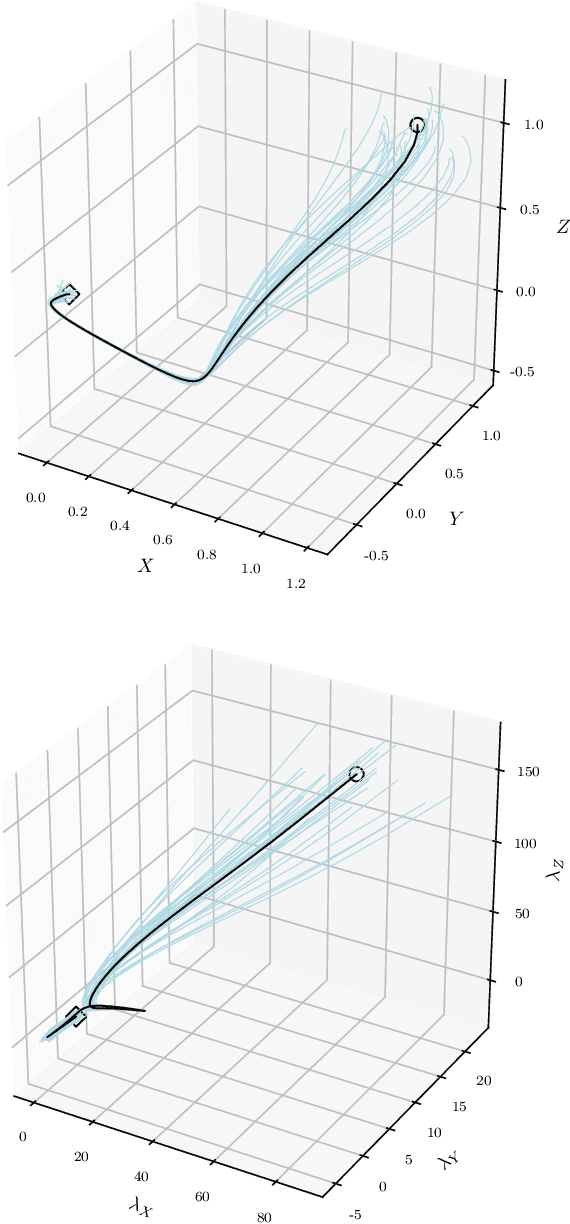
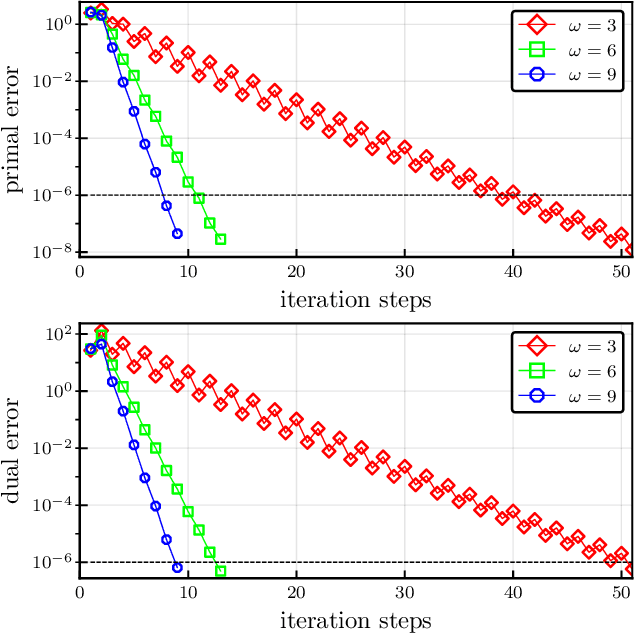
We present an overlapping Schwarz decomposition algorithm for solving nonlinear optimal control problems (OCPs). Our approach decomposes the time domain into a set of overlapping subdomains and solves subproblems defined over such subdomains in parallel. Convergence is attained by updating primal-dual information at the boundaries of the overlapping regions. We show that the algorithm exhibits local convergence and that the convergence rate improves exponentially with the size of the overlap. Our convergence results rely on a sensitivity result for OCPs that we call "asymptotic decay of sensitivity." Intuitively, this result states that impact of parametric perturbations at the boundaries of the time domain (initial and final time) decays exponentially as one moves away from the perturbation points. We show that this condition holds for nonlinear OCPs under a uniform second-order sufficient condition, a controllability condition, and a uniform boundedness condition. The approach is demonstrated by using a highly nonlinear quadrotor motion planning problem.
Recovering Trajectories of Unmarked Joints in 3D Human Actions Using Latent Space Optimization
Dec 03, 2020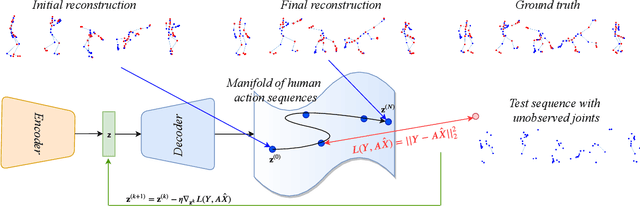
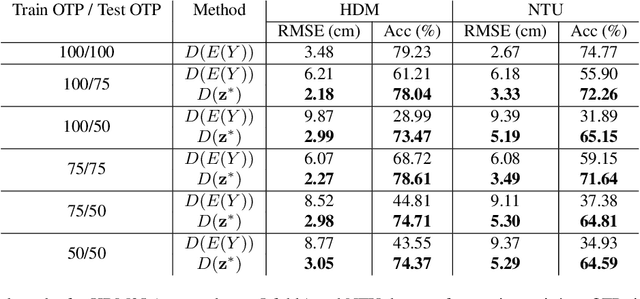
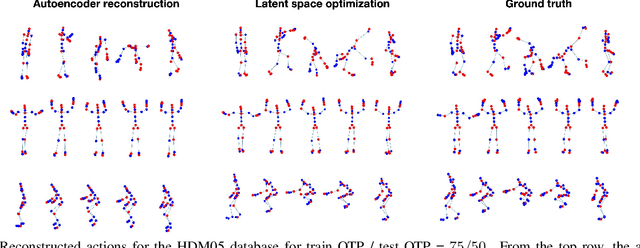
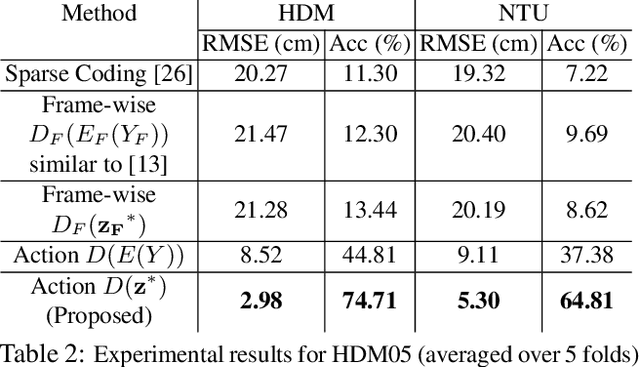
Motion capture (mocap) and time-of-flight based sensing of human actions are becoming increasingly popular modalities to perform robust activity analysis. Applications range from action recognition to quantifying movement quality for health applications. While marker-less motion capture has made great progress, in critical applications such as healthcare, marker-based systems, especially active markers, are still considered gold-standard. However, there are several practical challenges in both modalities such as visibility, tracking errors, and simply the need to keep marker setup convenient wherein movements are recorded with a reduced marker-set. This implies that certain joint locations will not even be marked-up, making downstream analysis of full body movement challenging. To address this gap, we first pose the problem of reconstructing the unmarked joint data as an ill-posed linear inverse problem. We recover missing joints for a given action by projecting it onto the manifold of human actions, this is achieved by optimizing the latent space representation of a deep autoencoder. Experiments on both mocap and Kinect datasets clearly demonstrate that the proposed method performs very well in recovering semantics of the actions and dynamics of missing joints. We will release all the code and models publicly.
Amortized Variational Deep Q Network
Nov 03, 2020
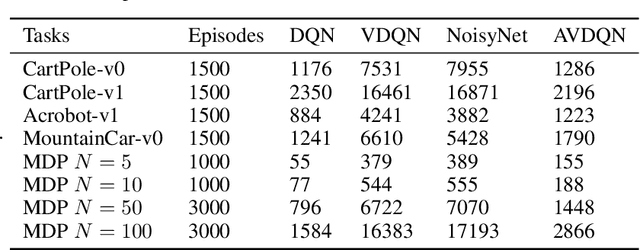
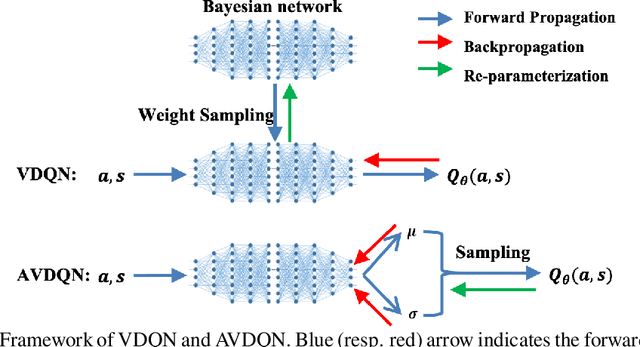
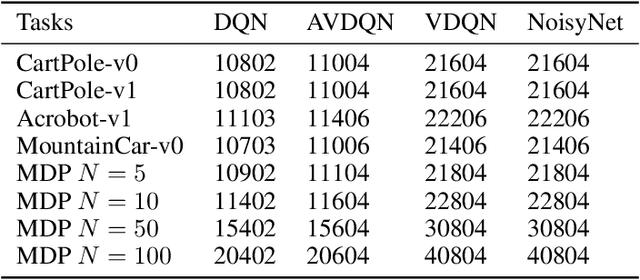
Efficient exploration is one of the most important issues in deep reinforcement learning. To address this issue, recent methods consider the value function parameters as random variables, and resort variational inference to approximate the posterior of the parameters. In this paper, we propose an amortized variational inference framework to approximate the posterior distribution of the action value function in Deep Q Network. We establish the equivalence between the loss of the new model and the amortized variational inference loss. We realize the balance of exploration and exploitation by assuming the posterior as Cauchy and Gaussian, respectively in a two-stage training process. We show that the amortized framework can results in significant less learning parameters than existing state-of-the-art method. Experimental results on classical control tasks in OpenAI Gym and chain Markov Decision Process tasks show that the proposed method performs significantly better than state-of-art methods and requires much less training time.
Graph Neural Network for Large-Scale Network Localization
Oct 22, 2020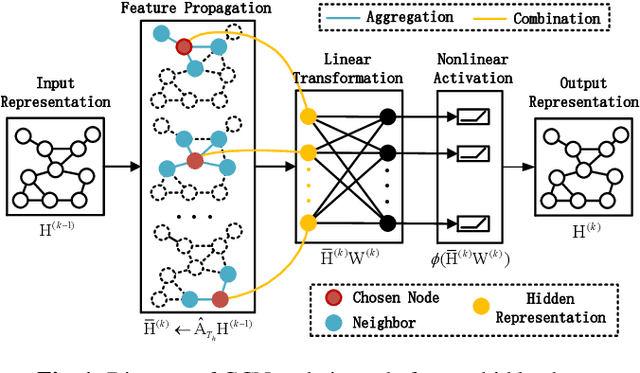
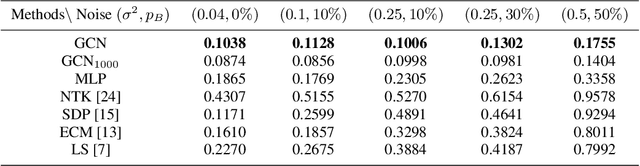
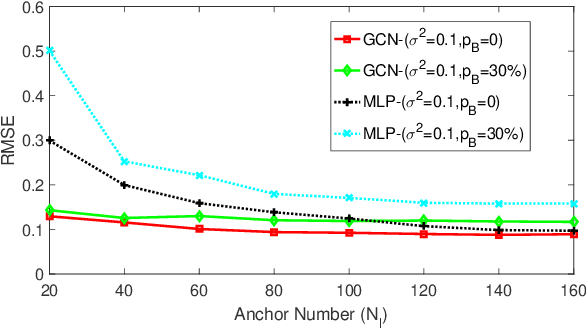

Graph neural networks (GNNs) are popular to use for classifying structured data in the context of machine learning. But surprisingly, they are rarely applied to regression problems. In this work, we adopt GNN for a classic but challenging nonlinear regression problem, namely the network localization. Our main findings are in order. First, GNN is potentially the best solution to large-scale network localization in terms of accuracy, robustness and computational time. Second, thresholding of the communication range is essential to its superior performance. Simulation results corroborate that the proposed GNN based method outperforms all benchmarks by far. Such inspiring results are further justified theoretically in terms of data aggregation, non-line-of-sight (NLOS) noise removal and lowpass filtering effect, all affected by the threshold for neighbor selection. Code is available at https://github.com/Yanzongzi/GNN-For-localization.
A Linearly Convergent Algorithm for Decentralized Optimization: Sending Less Bits for Free!
Nov 03, 2020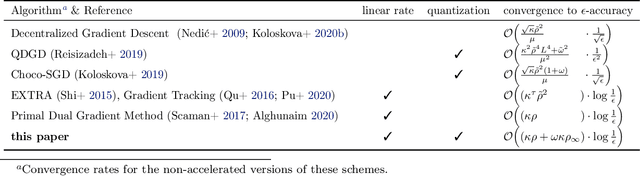
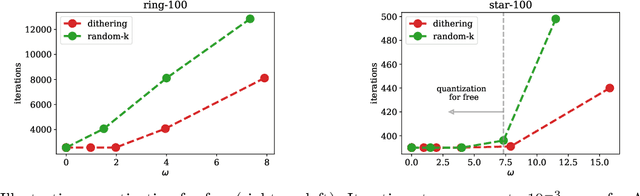

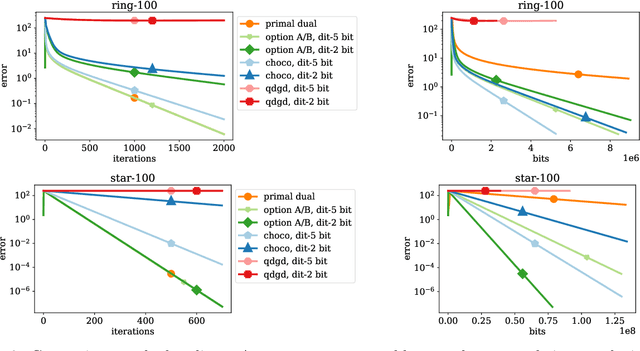
Decentralized optimization methods enable on-device training of machine learning models without a central coordinator. In many scenarios communication between devices is energy demanding and time consuming and forms the bottleneck of the entire system. We propose a new randomized first-order method which tackles the communication bottleneck by applying randomized compression operators to the communicated messages. By combining our scheme with a new variance reduction technique that progressively throughout the iterations reduces the adverse effect of the injected quantization noise, we obtain the first scheme that converges linearly on strongly convex decentralized problems while using compressed communication only. We prove that our method can solve the problems without any increase in the number of communications compared to the baseline which does not perform any communication compression while still allowing for a significant compression factor which depends on the conditioning of the problem and the topology of the network. Our key theoretical findings are supported by numerical experiments.
On Filter Generalization for Music Bandwidth Extension Using Deep Neural Networks
Nov 14, 2020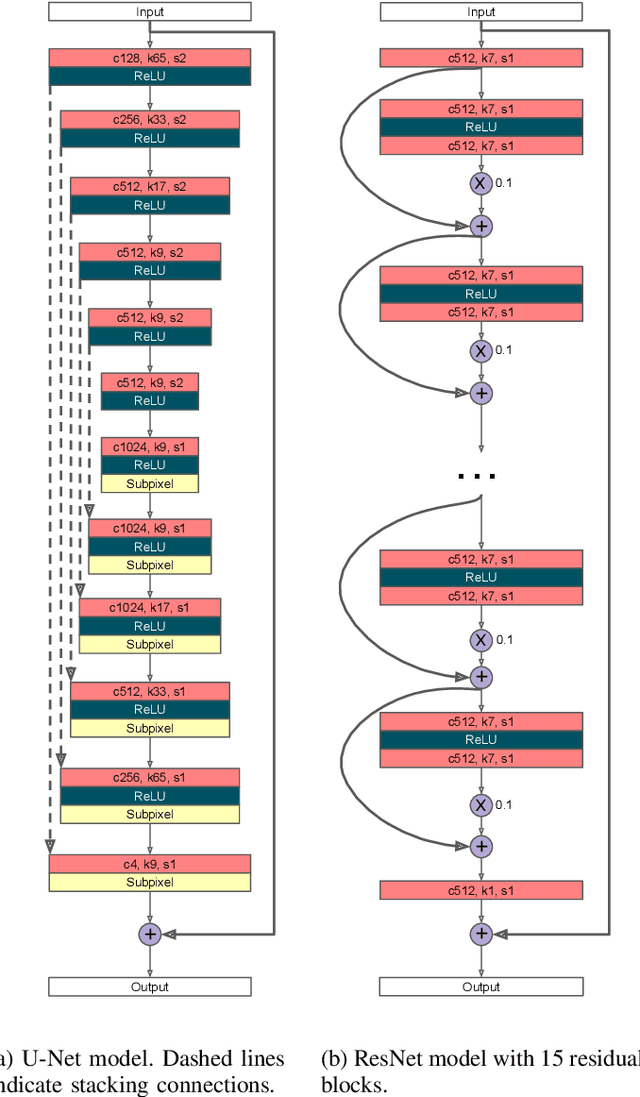
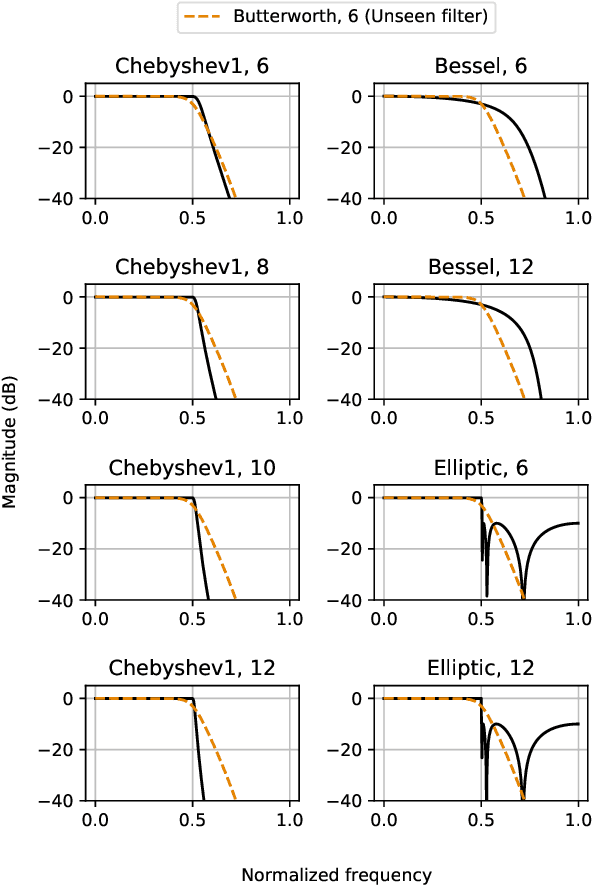
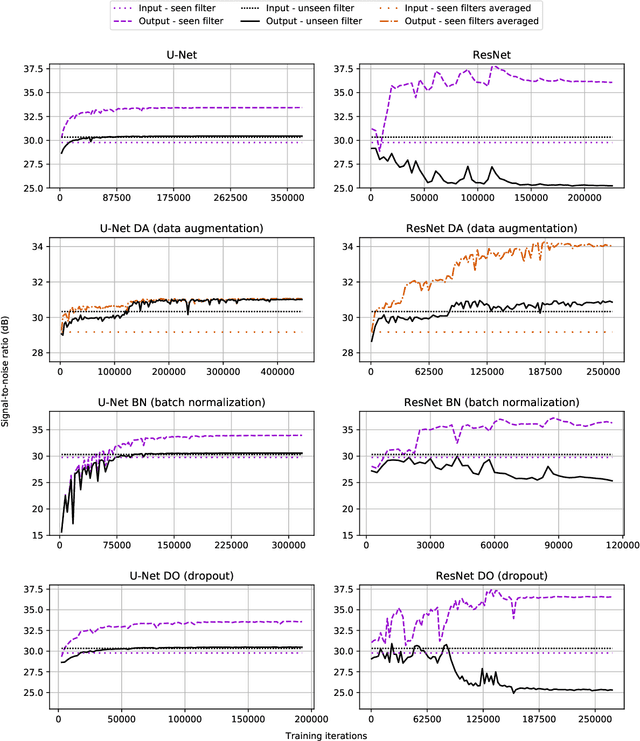
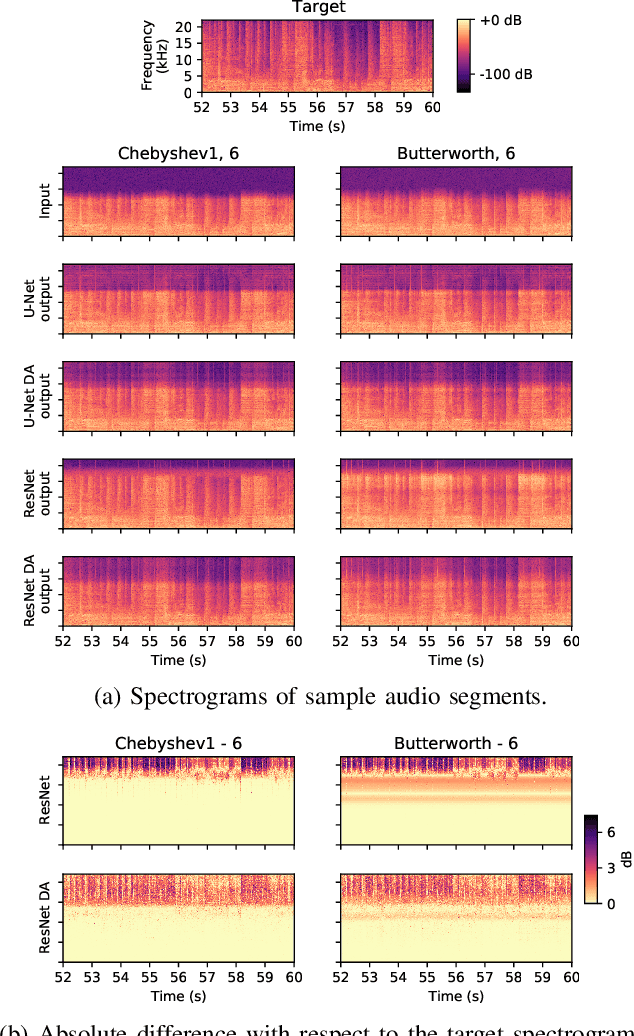
In this paper, we address a sub-topic of the broad domain of audio enhancement, namely musical audio bandwidth extension. We formulate the bandwidth extension problem using deep neural networks, where a band-limited signal is provided as input to the network, with the goal of reconstructing a full-bandwidth output. Our main contribution centers on the impact of the choice of low pass filter when training and subsequently testing the network. For two different state of the art deep architectures, ResNet and U-Net, we demonstrate that when the training and testing filters are matched, improvements in signal-to-noise ratio (SNR) of up to 7dB can be obtained. However, when these filters differ, the improvement falls considerably and under some training conditions results in a lower SNR than the band-limited input. To circumvent this apparent overfitting to filter shape, we propose a data augmentation strategy which utilizes multiple low pass filters during training and leads to improved generalization to unseen filtering conditions at test time.
Localization of Malaria Parasites and White Blood Cells in Thick Blood Smears
Dec 03, 2020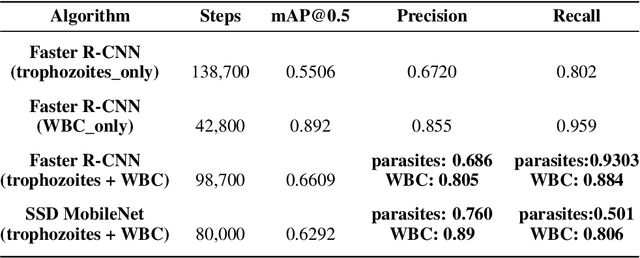
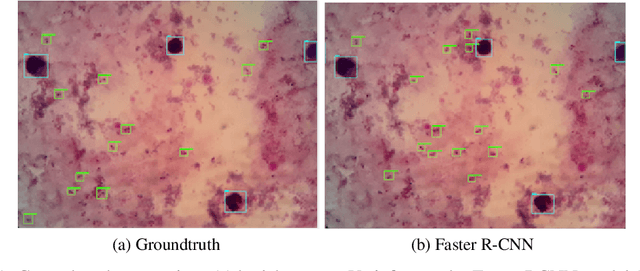
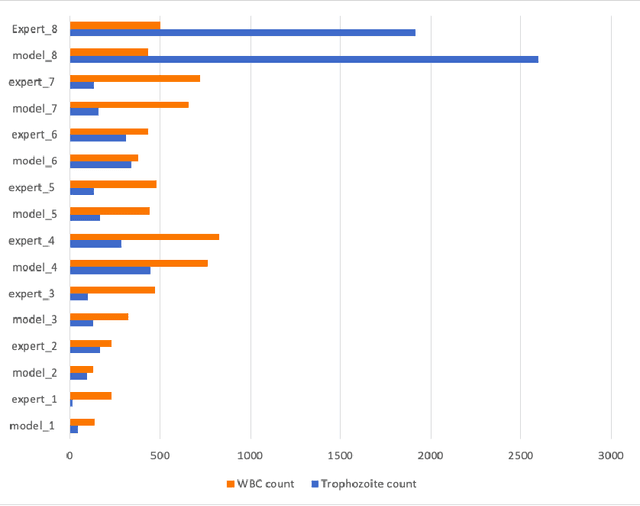
Effectively determining malaria parasitemia is a critical aspect in assisting clinicians to accurately determine the severity of the disease and provide quality treatment. Microscopy applied to thick smear blood smears is the de facto method for malaria parasitemia determination. However, manual quantification of parasitemia is time consuming, laborious and requires considerable trained expertise which is particularly inadequate in highly endemic and low resourced areas. This study presents an end-to-end approach for localisation and count of malaria parasites and white blood cells (WBCs) which aid in the effective determination of parasitemia; the quantitative content of parasites in the blood. On a dataset of slices of images of thick blood smears, we build models to analyse the obtained digital images. To improve model performance due to the limited size of the dataset, data augmentation was applied. Our preliminary results show that our deep learning approach reliably detects and returns a count of malaria parasites and WBCs with a high precision and recall. We also evaluate our system against human experts and results indicate a strong correlation between our deep learning model counts and the manual expert counts (p=0.998 for parasites, p=0.987 for WBCs). This approach could potentially be applied to support malaria parasitemia determination especially in settings that lack sufficient Microscopists.
Training Generative Adversarial Networks by Solving Ordinary Differential Equations
Oct 28, 2020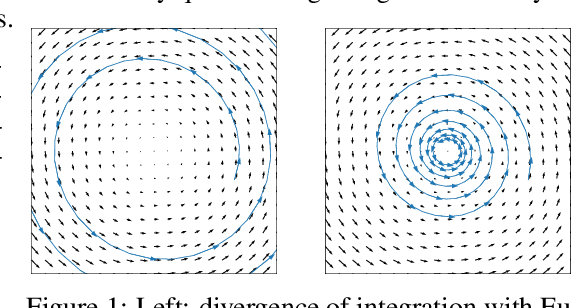
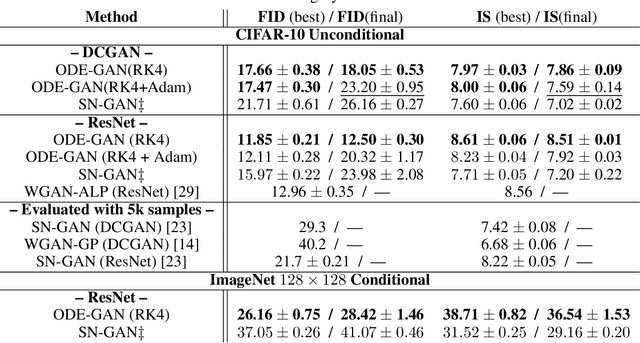
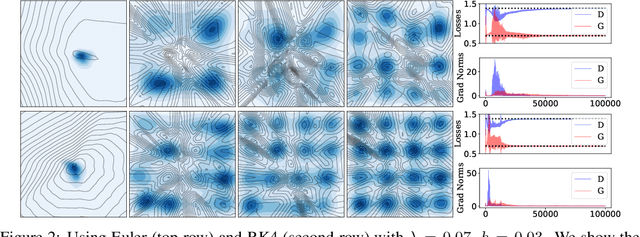
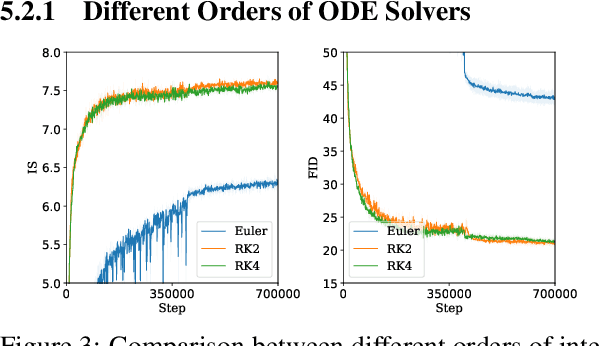
The instability of Generative Adversarial Network (GAN) training has frequently been attributed to gradient descent. Consequently, recent methods have aimed to tailor the models and training procedures to stabilise the discrete updates. In contrast, we study the continuous-time dynamics induced by GAN training. Both theory and toy experiments suggest that these dynamics are in fact surprisingly stable. From this perspective, we hypothesise that instabilities in training GANs arise from the integration error in discretising the continuous dynamics. We experimentally verify that well-known ODE solvers (such as Runge-Kutta) can stabilise training - when combined with a regulariser that controls the integration error. Our approach represents a radical departure from previous methods which typically use adaptive optimisation and stabilisation techniques that constrain the functional space (e.g. Spectral Normalisation). Evaluation on CIFAR-10 and ImageNet shows that our method outperforms several strong baselines, demonstrating its efficacy.
Wide-Residual-Inception Networks for Real-time Object Detection
Jul 17, 2017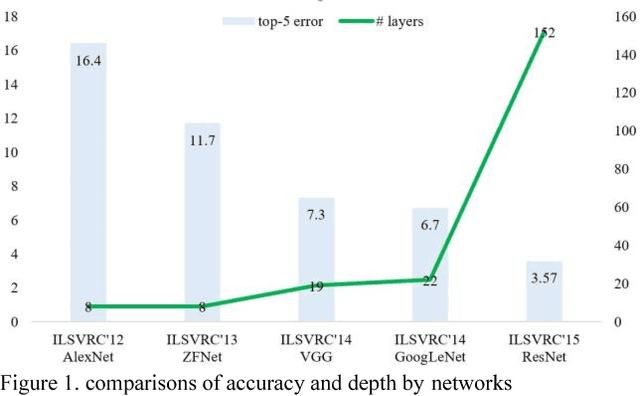
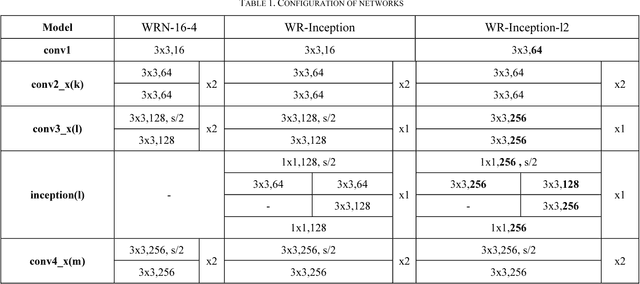
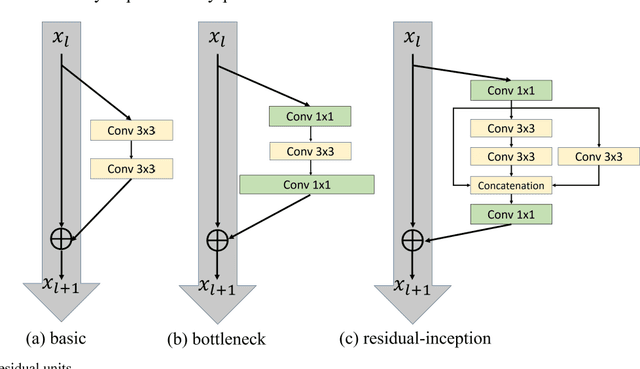
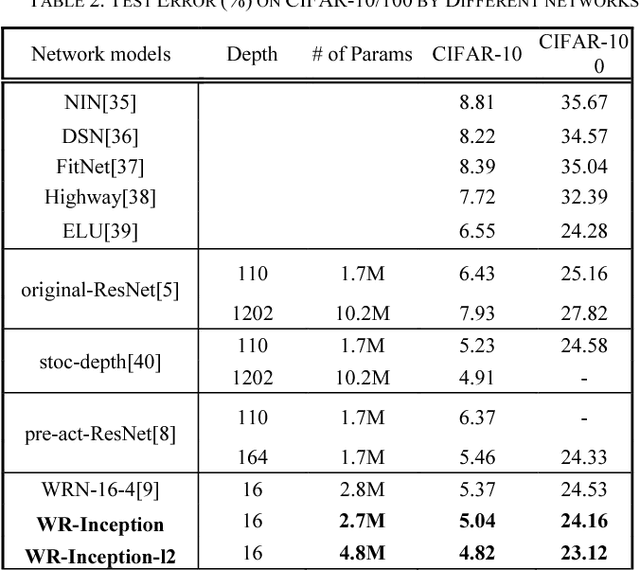
Since convolutional neural network(CNN)models emerged,several tasks in computer vision have actively deployed CNN models for feature extraction. However,the conventional CNN models have a high computational cost and require high memory capacity, which is impractical and unaffordable for commercial applications such as real-time on-road object detection on embedded boards or mobile platforms. To tackle this limitation of CNN models, this paper proposes a wide-residual-inception (WR-Inception) network, which constructs the architecture based on a residual inception unit that captures objects of various sizes on the same feature map, as well as shallower and wider layers, compared to state-of-the-art networks like ResNet. To verify the proposed networks, this paper conducted two experiments; one is a classification task on CIFAR-10/100 and the other is an on-road object detection task using a Single-Shot Multi-box Detector(SSD) on the KITTI dataset.
Quantum-inspired classical sublinear-time algorithm for solving low-rank semidefinite programming via sampling approaches
Jan 10, 2019
Semidefinite programming (SDP) is a central topic in mathematical optimization with extensive studies on its efficient solvers. Recently, quantum algorithms with superpolynomial speedups for solving SDPs have been proposed assuming access to its constraint matrices in quantum superposition. Mutually inspired by both classical and quantum SDP solvers, in this paper we present a sublinear classical algorithm for solving low-rank SDPs which is asymptotically as good as existing quantum algorithms. Specifically, given an SDP with $m$ constraint matrices, each of dimension $n$ and rank $\mathrm{poly}(\log n)$, our algorithm gives a succinct description and any entry of the solution matrix in time $O(m\cdot\mathrm{poly}(\log n,1/\varepsilon))$ given access to a sample-based low-overhead data structure of the constraint matrices, where $\varepsilon$ is the precision of the solution. In addition, we apply our algorithm to a quantum state learning task as an application. Technically, our approach aligns with both the SDP solvers based on the matrix multiplicative weight (MMW) framework and the recent studies of quantum-inspired machine learning algorithms. The cost of solving SDPs by MMW mainly comes from the exponentiation of Hermitian matrices, and we propose two new technical ingredients (compared to previous sample-based algorithms) for this task that may be of independent interest: $\bullet$ Weighted sampling: assuming sampling access to each individual constraint matrix $A_{1},\ldots,A_{\tau}$, we propose a procedure that gives a good approximation of $A=A_{1}+\cdots+A_{\tau}$. $\bullet$ Symmetric approximation: we propose a sampling procedure that gives low-rank spectral decomposition of a Hermitian matrix $A$. This improves upon previous sampling procedures that only give low-rank singular value decompositions, losing the signs of eigenvalues.