 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Using a single RGB frame for real time 3D hand pose estimation in the wild
Dec 11, 2017

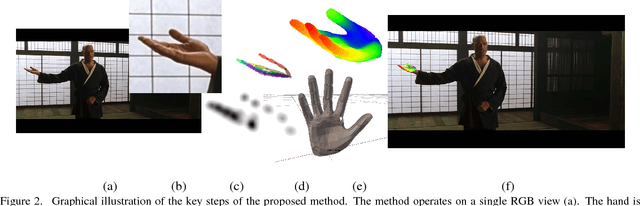
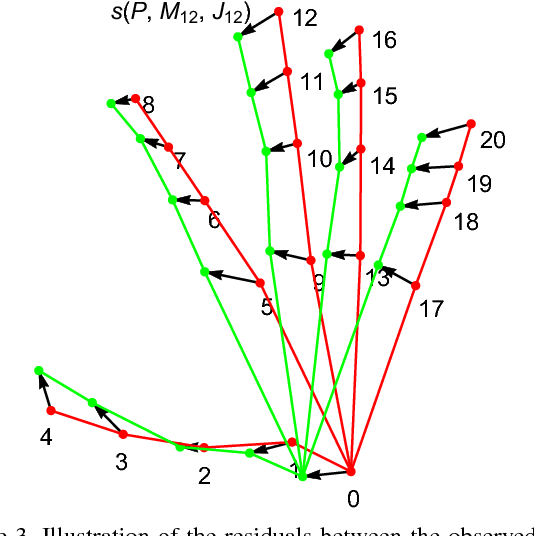
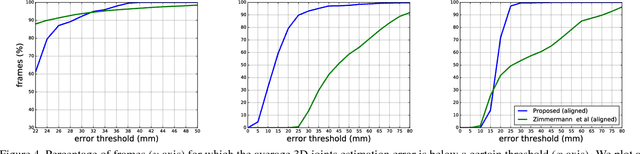
We present a method for the real-time estimation of the full 3D pose of one or more human hands using a single commodity RGB camera. Recent work in the area has displayed impressive progress using RGBD input. However, since the introduction of RGBD sensors, there has been little progress for the case of monocular color input. We capitalize on the latest advancements of deep learning, combining them with the power of generative hand pose estimation techniques to achieve real-time monocular 3D hand pose estimation in unrestricted scenarios. More specifically, given an RGB image and the relevant camera calibration information, we employ a state-of-the-art detector to localize hands. Given a crop of a hand in the image, we run the pretrained network of OpenPose for hands to estimate the 2D location of hand joints. Finally, non-linear least-squares minimization fits a 3D model of the hand to the estimated 2D joint positions, recovering the 3D hand pose. Extensive experimental results provide comparison to the state of the art as well as qualitative assessment of the method in the wild.
Cost-to-Go Function Generating Networks for High Dimensional Motion Planning
Dec 10, 2020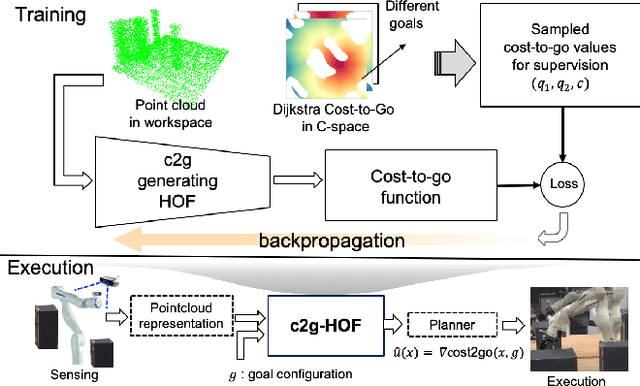
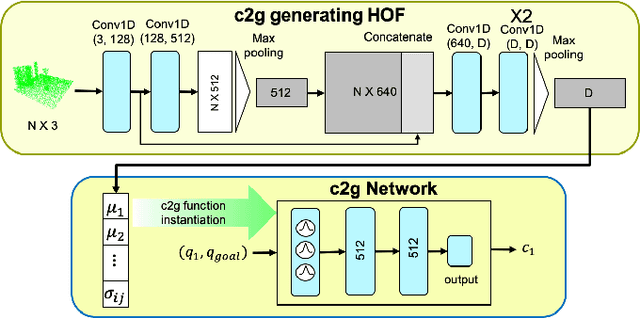
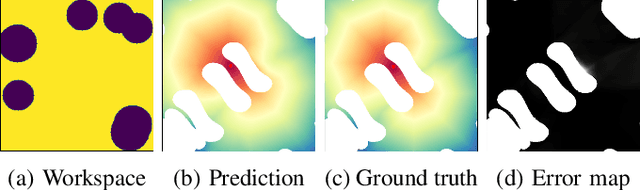
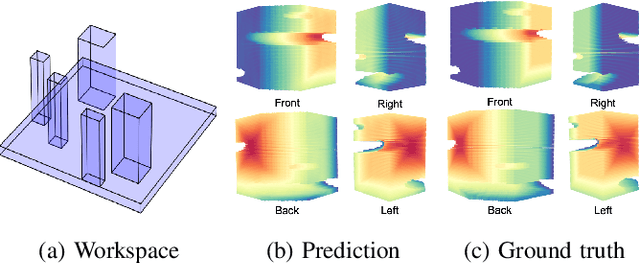
This paper presents c2g-HOF networks which learn to generate cost-to-go functions for manipulator motion planning. The c2g-HOF architecture consists of a cost-to-go function over the configuration space represented as a neural network (c2g-network) as well as a Higher Order Function (HOF) network which outputs the weights of the c2g-network for a given input workspace. Both networks are trained end-to-end in a supervised fashion using costs computed from traditional motion planners. Once trained, c2g-HOF can generate a smooth and continuous cost-to-go function directly from workspace sensor inputs (represented as a point cloud in 3D or an image in 2D). At inference time, the weights of the c2g-network are computed very efficiently and near-optimal trajectories are generated by simply following the gradient of the cost-to-go function. We compare c2g-HOF with traditional planning algorithms for various robots and planning scenarios. The experimental results indicate that planning with c2g-HOF is significantly faster than other motion planning algorithms, resulting in orders of magnitude improvement when including collision checking. Furthermore, despite being trained from sparsely sampled trajectories in configuration space, c2g-HOF generalizes to generate smoother, and often lower cost, trajectories. We demonstrate cost-to-go based planning on a 7 DoF manipulator arm where motion planning in a complex workspace requires only 0.13 seconds for the entire trajectory.
DeepTracking-Net: 3D Tracking with Unsupervised Learning of Continuous Flow
Jun 24, 2020
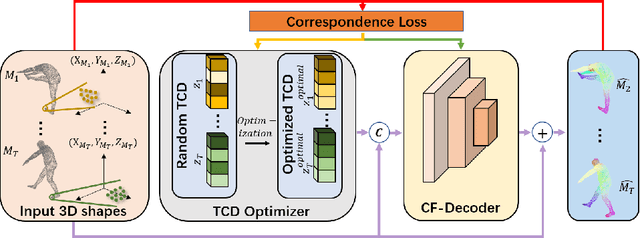
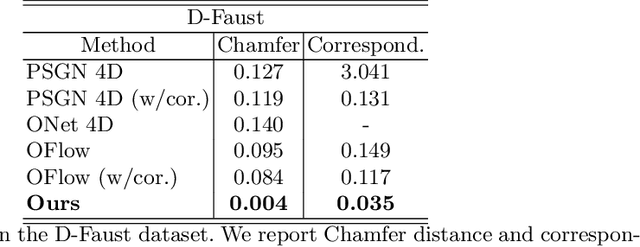
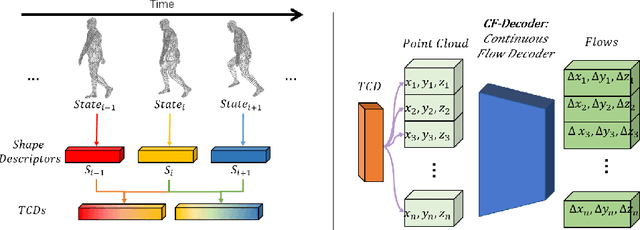
This paper deals with the problem of 3D tracking, i.e., to find dense correspondences in a sequence of time-varying 3D shapes. Despite deep learning approaches have achieved promising performance for pairwise dense 3D shapes matching, it is a great challenge to generalize those approaches for the tracking of 3D time-varying geometries. In this paper, we aim at handling the problem of 3D tracking, which provides the tracking of the consecutive frames of 3D shapes. We propose a novel unsupervised 3D shape registration framework named DeepTracking-Net, which uses the deep neural networks (DNNs) as auxiliary functions to produce spatially and temporally continuous displacement fields for 3D tracking of objects in a temporal order. Our key novelty is that we present a novel temporal-aware correspondence descriptor (TCD) that captures spatio-temporal essence from consecutive 3D point cloud frames. Specifically, our DeepTracking-Net starts with optimizing a randomly initialized latent TCD. The TCD is then decoded to regress a continuous flow (i.e. a displacement vector field) which assigns a motion vector to every point of time-varying 3D shapes. Our DeepTracking-Net jointly optimizes TCDs and DNNs' weights towards the minimization of an unsupervised alignment loss. Experiments on both simulated and real data sets demonstrate that our unsupervised DeepTracking-Net outperforms the current supervised state-of-the-art method. In addition, we prepare a new synthetic 3D data, named SynMotions, to the 3D tracking and recognition community.
Flow-based Generative Models for Learning Manifold to Manifold Mappings
Dec 18, 2020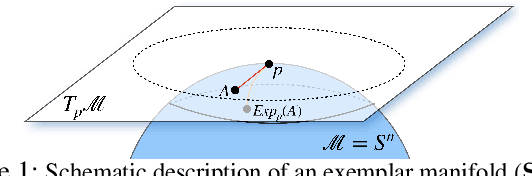
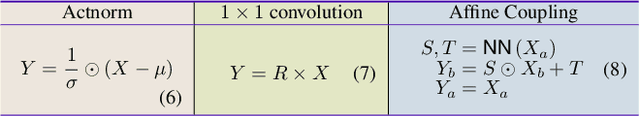
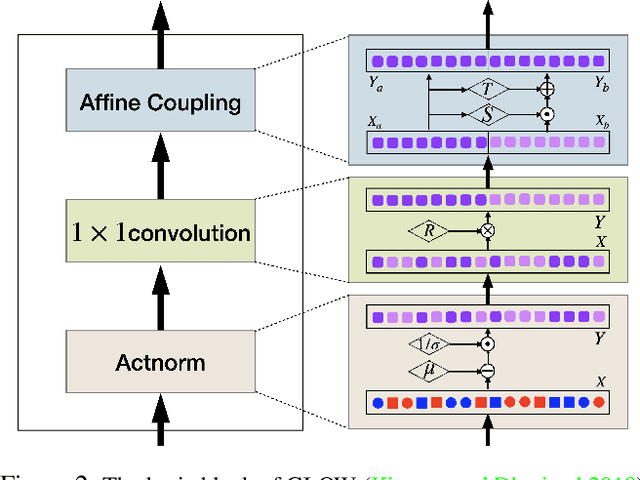

Many measurements or observations in computer vision and machine learning manifest as non-Euclidean data. While recent proposals (like spherical CNN) have extended a number of deep neural network architectures to manifold-valued data, and this has often provided strong improvements in performance, the literature on generative models for manifold data is quite sparse. Partly due to this gap, there are also no modality transfer/translation models for manifold-valued data whereas numerous such methods based on generative models are available for natural images. This paper addresses this gap, motivated by a need in brain imaging -- in doing so, we expand the operating range of certain generative models (as well as generative models for modality transfer) from natural images to images with manifold-valued measurements. Our main result is the design of a two-stream version of GLOW (flow-based invertible generative models) that can synthesize information of a field of one type of manifold-valued measurements given another. On the theoretical side, we introduce three kinds of invertible layers for manifold-valued data, which are not only analogous to their functionality in flow-based generative models (e.g., GLOW) but also preserve the key benefits (determinants of the Jacobian are easy to calculate). For experiments, on a large dataset from the Human Connectome Project (HCP), we show promising results where we can reliably and accurately reconstruct brain images of a field of orientation distribution functions (ODF) from diffusion tensor images (DTI), where the latter has a $5\times$ faster acquisition time but at the expense of worse angular resolution.
Spatio-temporal Multi-task Learning for Cardiac MRI Left Ventricle Quantification
Dec 24, 2020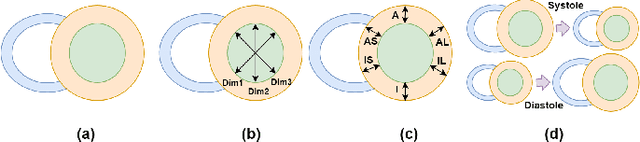
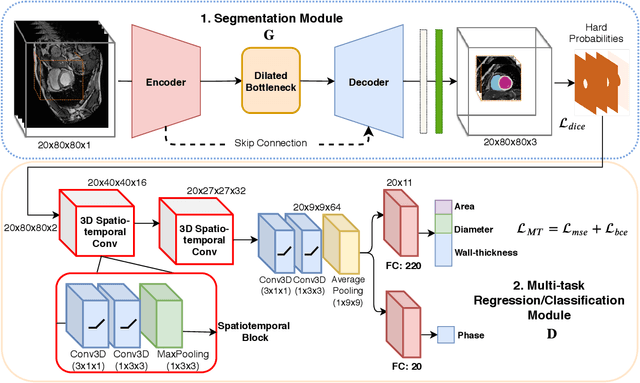
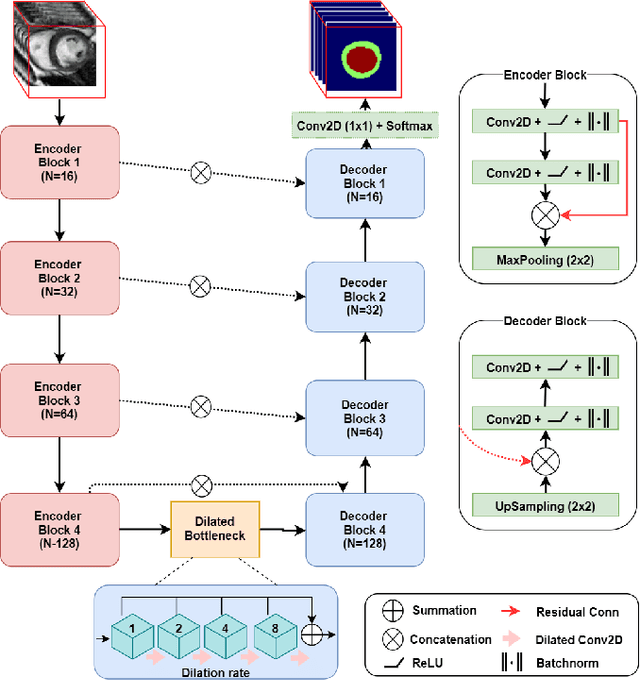
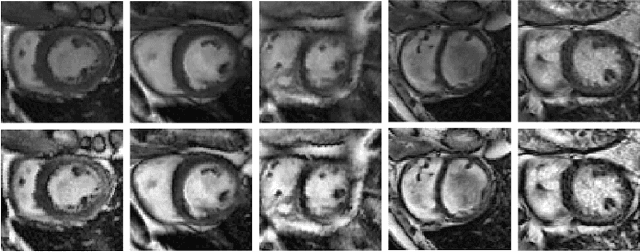
Quantitative assessment of cardiac left ventricle (LV) morphology is essential to assess cardiac function and improve the diagnosis of different cardiovascular diseases. In current clinical practice, LV quantification depends on the measurement of myocardial shape indices, which is usually achieved by manual contouring of the endo- and epicardial. However, this process subjected to inter and intra-observer variability, and it is a time-consuming and tedious task. In this paper, we propose a spatio-temporal multi-task learning approach to obtain a complete set of measurements quantifying cardiac LV morphology, regional-wall thickness (RWT), and additionally detecting the cardiac phase cycle (systole and diastole) for a given 3D Cine-magnetic resonance (MR) image sequence. We first segment cardiac LVs using an encoder-decoder network and then introduce a multitask framework to regress 11 LV indices and classify the cardiac phase, as parallel tasks during model optimization. The proposed deep learning model is based on the 3D spatio-temporal convolutions, which extract spatial and temporal features from MR images. We demonstrate the efficacy of the proposed method using cine-MR sequences of 145 subjects and comparing the performance with other state-of-the-art quantification methods. The proposed method obtained high prediction accuracy, with an average mean absolute error (MAE) of 129 $mm^2$, 1.23 $mm$, 1.76 $mm$, Pearson correlation coefficient (PCC) of 96.4%, 87.2%, and 97.5% for LV and myocardium (Myo) cavity regions, 6 RWTs, 3 LV dimensions, and an error rate of 9.0\% for phase classification. The experimental results highlight the robustness of the proposed method, despite varying degrees of cardiac morphology, image appearance, and low contrast in the cardiac MR sequences.
Energy Minimization in UAV-Aided Networks: Actor-Critic Learning for Constrained Scheduling Optimization
Jun 24, 2020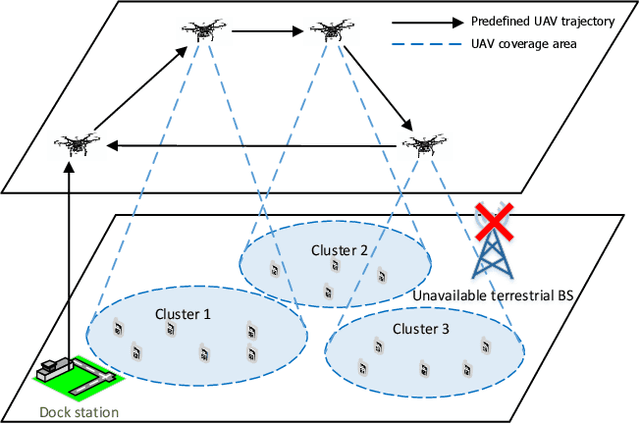
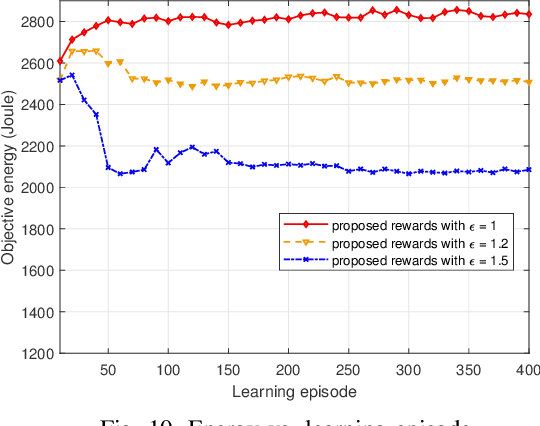
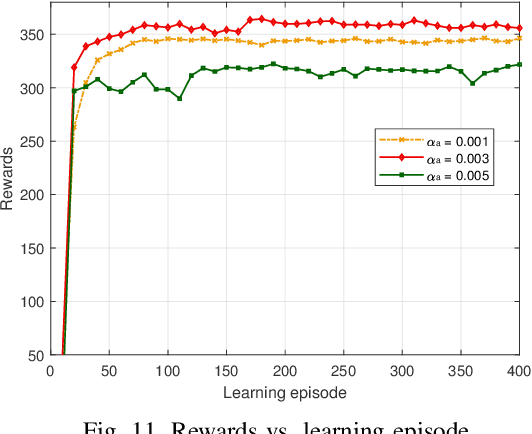
In unmanned aerial vehicle (UAV) applications, the UAV's limited energy supply and storage have triggered the development of intelligent energy-conserving scheduling solutions. In this paper, we investigate energy minimization for UAV-aided communication networks by jointly optimizing data-transmission scheduling and UAV hovering time. The formulated problem is combinatorial and non-convex with bilinear constraints. To tackle the problem, firstly, we provide an optimal relax-and-approximate solution and develop a near-optimal algorithm. Both the proposed solutions are served as offline performance benchmarks but might not be suitable for online operation. To this end, we develop a solution from a deep reinforcement learning (DRL) aspect. The conventional RL/DRL, e.g., deep Q-learning, however, is limited in dealing with two main issues in constrained combinatorial optimization, i.e., exponentially increasing action space and infeasible actions. The novelty of solution development lies in handling these two issues. To address the former, we propose an actor-critic-based deep stochastic online scheduling (AC-DSOS) algorithm and develop a set of approaches to confine the action space. For the latter, we design a tailored reward function to guarantee the solution feasibility. Numerical results show that, by consuming equal magnitude of time, AC-DSOS is able to provide feasible solutions and saves 29.94% energy compared with a conventional deep actor-critic method. Compared to the developed near-optimal algorithm, AC-DSOS consumes around 10% higher energy but reduces the computational time from minute-level to millisecond-level.
asya: Mindful verbal communication using deep learning
Aug 20, 2020



asya is a mobile application that consists of deep learning models which analyze spectra of a human voice and do noise detection, speaker diarization, gender detection, tempo estimation, and classification of emotions using only voice. All models are language agnostic and capable of running in real-time. Our speaker diarization models have accuracy over 95% on the test data set. These models can be applied for a variety of areas like customer service improvement, sales effective conversations, psychology and couples therapy.
Metric Learning vs Classification for Disentangled Music Representation Learning
Aug 09, 2020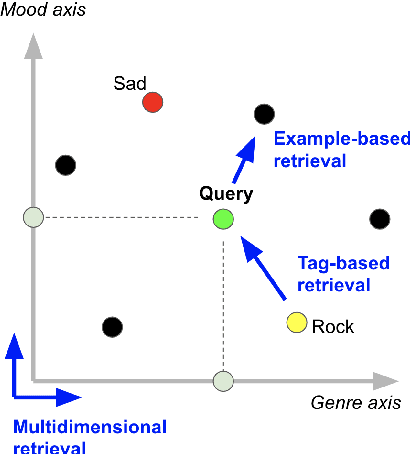
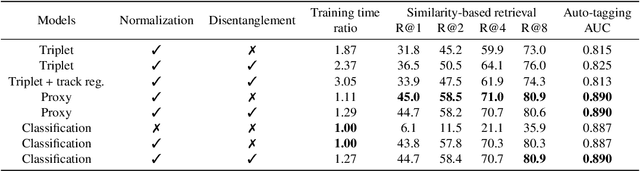
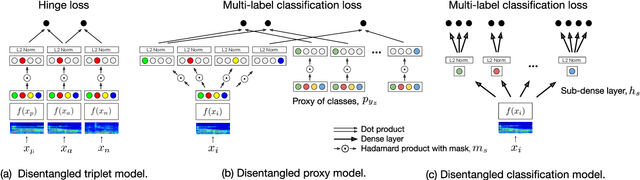

Deep representation learning offers a powerful paradigm for mapping input data onto an organized embedding space and is useful for many music information retrieval tasks. Two central methods for representation learning include deep metric learning and classification, both having the same goal of learning a representation that can generalize well across tasks. Along with generalization, the emerging concept of disentangled representations is also of great interest, where multiple semantic concepts (e.g., genre, mood, instrumentation) are learned jointly but remain separable in the learned representation space. In this paper we present a single representation learning framework that elucidates the relationship between metric learning, classification, and disentanglement in a holistic manner. For this, we (1) outline past work on the relationship between metric learning and classification, (2) extend this relationship to multi-label data by exploring three different learning approaches and their disentangled versions, and (3) evaluate all models on four tasks (training time, similarity retrieval, auto-tagging, and triplet prediction). We find that classification-based models are generally advantageous for training time, similarity retrieval, and auto-tagging, while deep metric learning exhibits better performance for triplet-prediction. Finally, we show that our proposed approach yields state-of-the-art results for music auto-tagging.
Spatio-Temporal Activation Function To Map Complex Dynamical Systems
Sep 06, 2020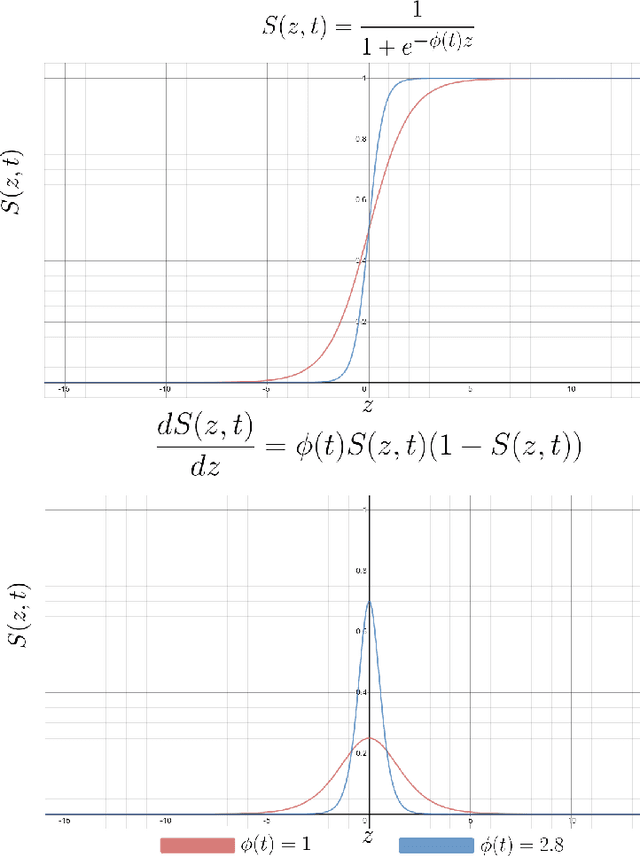
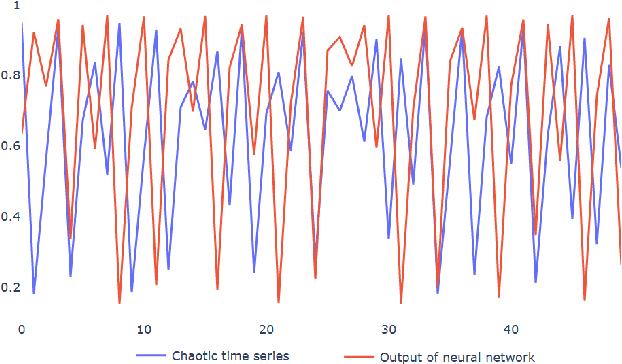
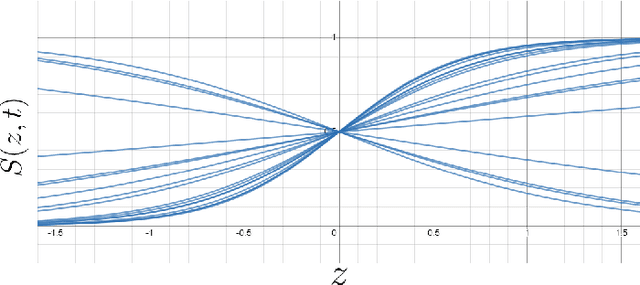
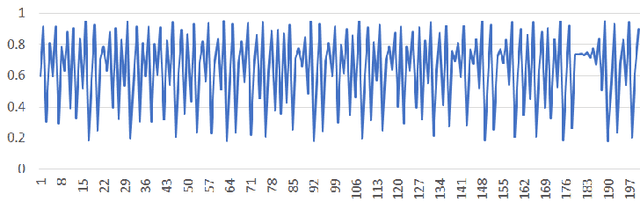
Most of the real world is governed by complex and chaotic dynamical systems. All of these dynamical systems pose a challenge in modelling them using neural networks. Currently, reservoir computing, which is a subset of recurrent neural networks, is actively used to simulate complex dynamical systems. In this work, a two dimensional activation function is proposed which includes an additional temporal term to impart dynamic behaviour on its output. The inclusion of a temporal term alters the fundamental nature of an activation function, it provides capability to capture the complex dynamics of time series data without relying on recurrent neural networks.
Robust Hierarchical Planning with Policy Delegation
Oct 25, 2020
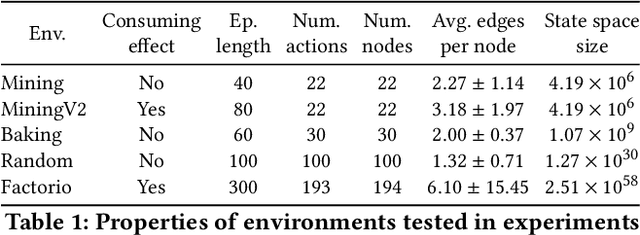
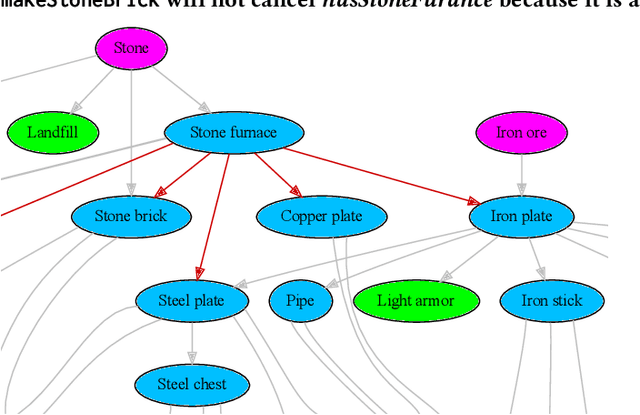
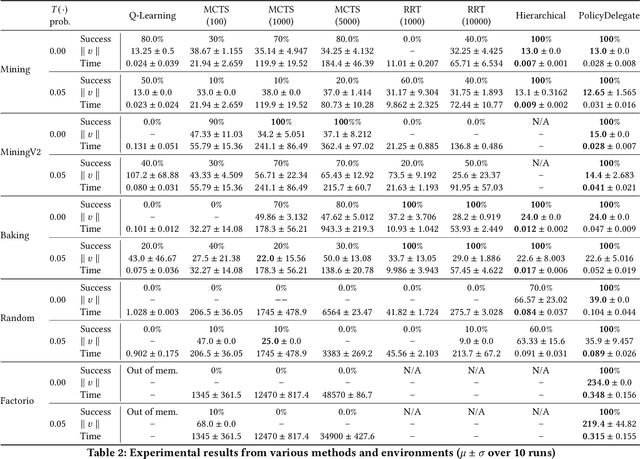
We propose a novel framework and algorithm for hierarchical planning based on the principle of delegation. This framework, the Markov Intent Process, features a collection of skills which are each specialised to perform a single task well. Skills are aware of their intended effects and are able to analyse planning goals to delegate planning to the best-suited skill. This principle dynamically creates a hierarchy of plans, in which each skill plans for sub-goals for which it is specialised. The proposed planning method features on-demand execution---skill policies are only evaluated when needed. Plans are only generated at the highest level, then expanded and optimised when the latest state information is available. The high-level plan retains the initial planning intent and previously computed skills, effectively reducing the computation needed to adapt to environmental changes. We show this planning approach is experimentally very competitive to classic planning and reinforcement learning techniques on a variety of domains, both in terms of solution length and planning time.