 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Visual Analytics of Movement Pattern Based on Time-Spatial Data: A Neural Net Approach
Jul 09, 2017
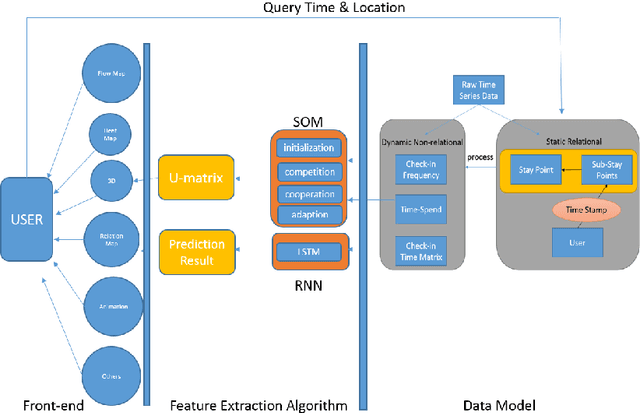
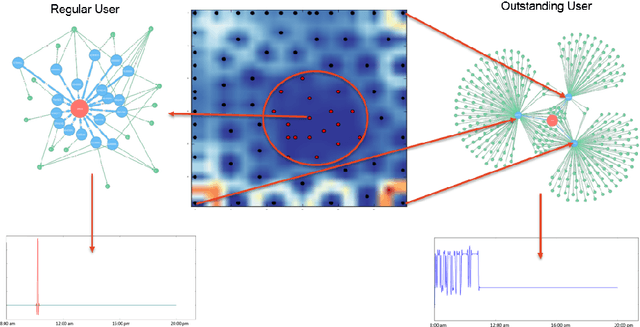
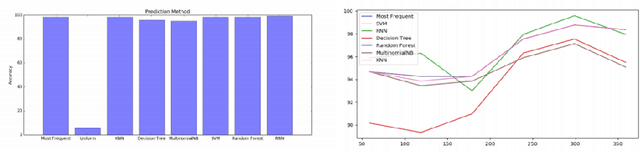
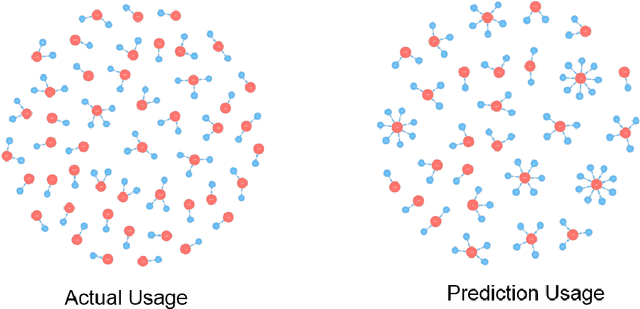
Time-Spatial data plays a crucial role for different fields such as traffic management. These data can be collected via devices such as surveillance sensors or tracking systems. However, how to efficiently an- alyze and visualize these data to capture essential embedded pattern information is becoming a big challenge today. Classic visualization ap- proaches focus on revealing 2D and 3D spatial information and modeling statistical test. Those methods would easily fail when data become mas- sive. Recent attempts concern on how to simply cluster data and perform prediction with time-oriented information. However, those approaches could still be further enhanced as they also have limitations for han- dling massive clusters and labels. In this paper, we propose a visualiza- tion methodology for mobility data using artificial neural net techniques. This method aggregates three main parts that are Back-end Data Model, Neural Net Algorithm including clustering method Self-Organizing Map (SOM) and prediction approach Recurrent Neural Net (RNN) for ex- tracting the features and lastly a solid front-end that displays the results to users with an interactive system. SOM is able to cluster the visiting patterns and detect the abnormal pattern. RNN can perform the predic- tion for time series analysis using its dynamic architecture. Furthermore, an interactive system will enable user to interpret the result with graph- ics, animation and 3D model for a close-loop feedback. This method can be particularly applied in two tasks that Commercial-based Promotion and abnormal traffic patterns detection.
Multivariate Temporal Autoencoder for Predictive Reconstruction of Deep Sequences
Oct 07, 2020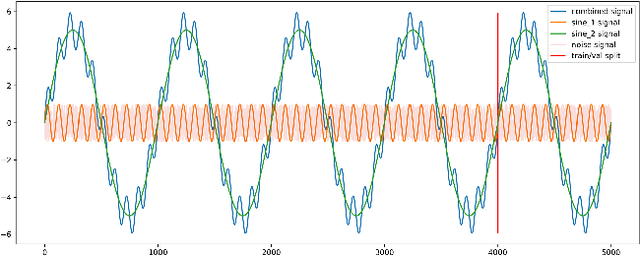
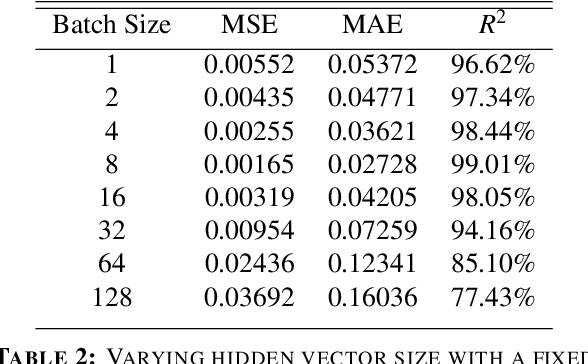
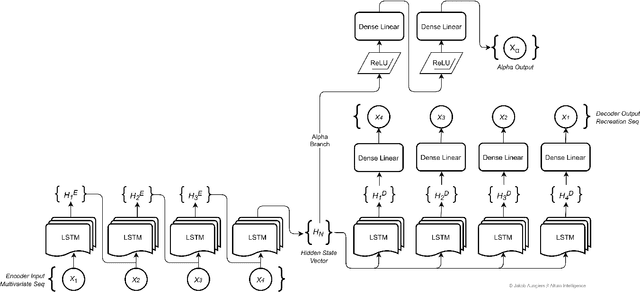
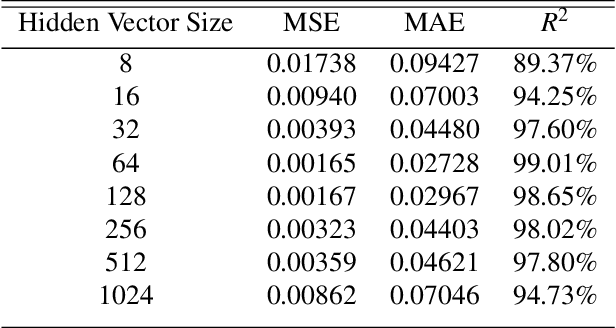
Time series sequence prediction and modelling has proven to be a challenging endeavor in real world datasets. Two key issues are the multi-dimensionality of data and the interaction of independent dimensions forming a latent output signal, as well as the representation of multi-dimensional temporal data inside of a predictive model. This paper proposes a multi-branch deep neural network approach to tackling the aforementioned problems by modelling a latent state vector representation of data windows through the use of a recurrent autoencoder branch and subsequently feeding the trained latent vector representation into a predictor branch of the model. This model is henceforth referred to as Multivariate Temporal Autoencoder (MvTAe). The framework in this paper utilizes a synthetic multivariate temporal dataset which contains dimensions that combine to create a hidden output target.
Human-Paraphrased References Improve Neural Machine Translation
Oct 20, 2020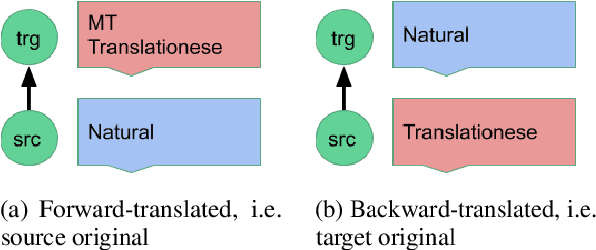
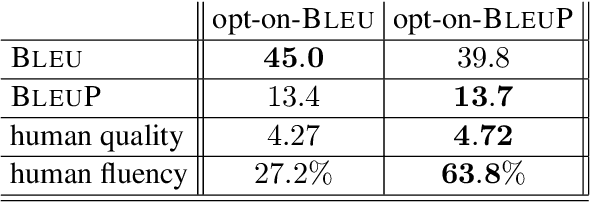
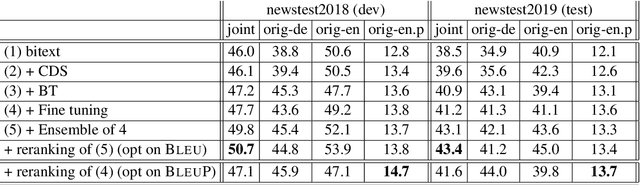
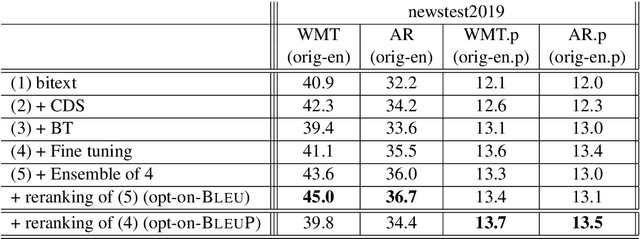
Automatic evaluation comparing candidate translations to human-generated paraphrases of reference translations has recently been proposed by Freitag et al. When used in place of original references, the paraphrased versions produce metric scores that correlate better with human judgment. This effect holds for a variety of different automatic metrics, and tends to favor natural formulations over more literal (translationese) ones. In this paper we compare the results of performing end-to-end system development using standard and paraphrased references. With state-of-the-art English-German NMT components, we show that tuning to paraphrased references produces a system that is significantly better according to human judgment, but 5 BLEU points worse when tested on standard references. Our work confirms the finding that paraphrased references yield metric scores that correlate better with human judgment, and demonstrates for the first time that using these scores for system development can lead to significant improvements.
Resource-Constrained Federated Learning with Heterogeneous Labels and Models
Nov 06, 2020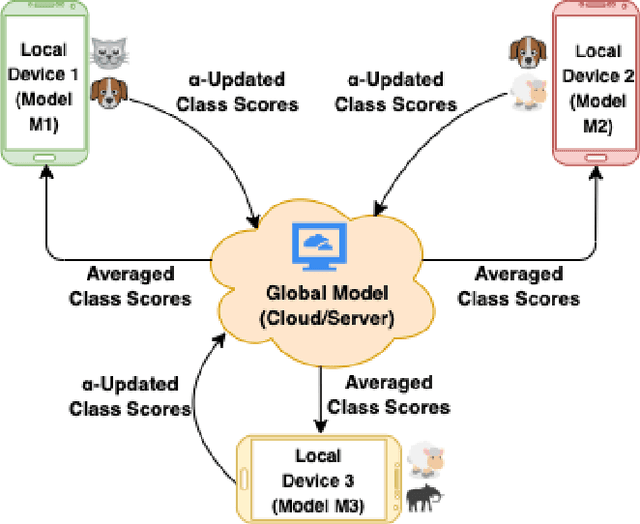

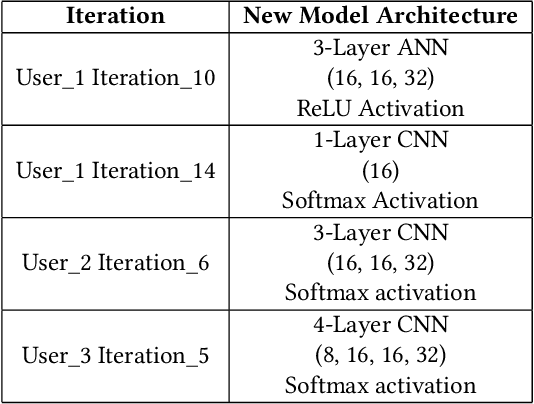
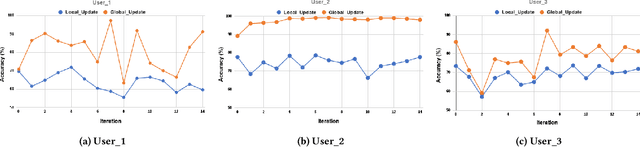
Various IoT applications demand resource-constrained machine learning mechanisms for different applications such as pervasive healthcare, activity monitoring, speech recognition, real-time computer vision, etc. This necessitates us to leverage information from multiple devices with few communication overheads. Federated Learning proves to be an extremely viable option for distributed and collaborative machine learning. Particularly, on-device federated learning is an active area of research, however, there are a variety of challenges in addressing statistical (non-IID data) and model heterogeneities. In addition, in this paper we explore a new challenge of interest -- to handle label heterogeneities in federated learning. To this end, we propose a framework with simple $\alpha$-weighted federated aggregation of scores which leverages overlapping information gain across labels, while saving bandwidth costs in the process. Empirical evaluation on Animals-10 dataset (with 4 labels for effective elucidation of results) indicates an average deterministic accuracy increase of at least ~16.7%. We also demonstrate the on-device capabilities of our proposed framework by experimenting with federated learning and inference across different iterations on a Raspberry Pi 2, a single-board computing platform.
Predictive Analytics for Enhancing Travel Time Estimation in Navigation Apps of Apple, Google, and Microsoft
May 23, 2017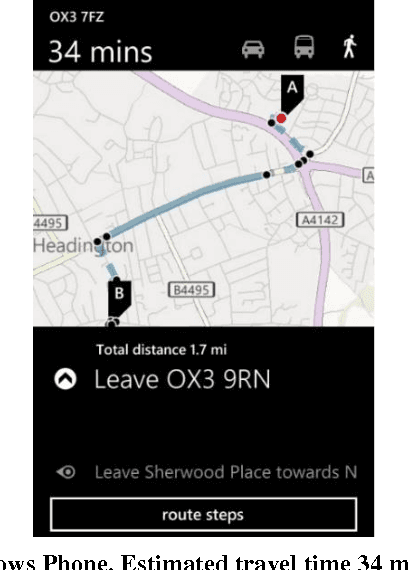
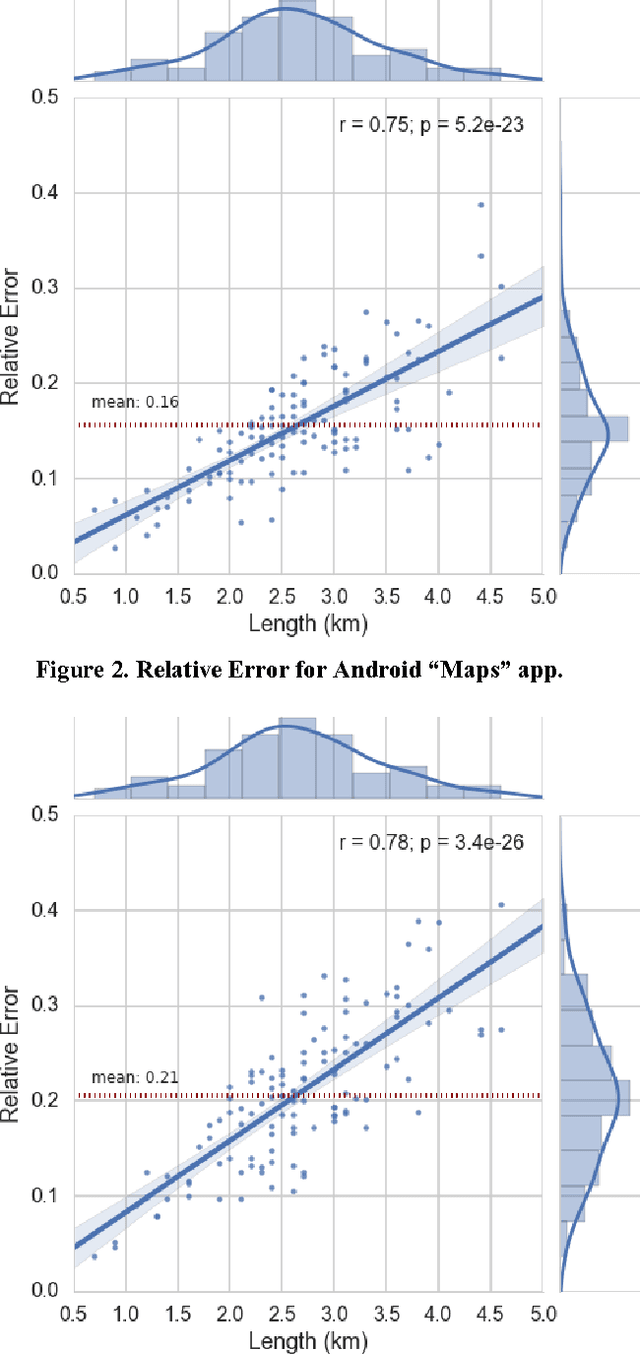
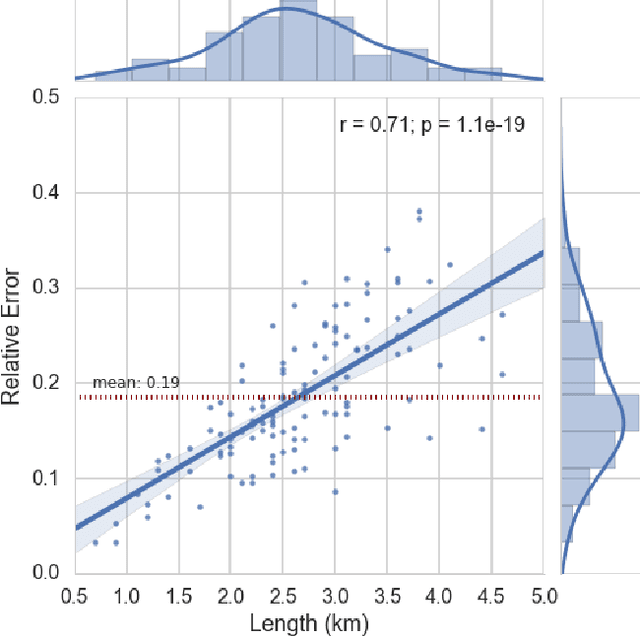
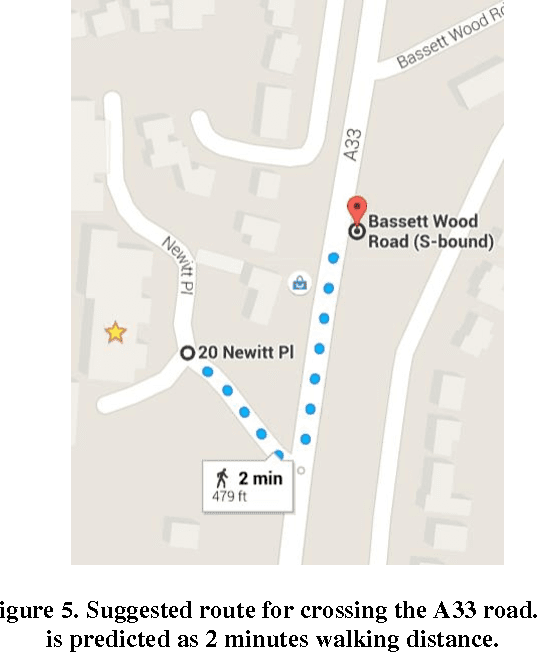
The explosive growth of the location-enabled devices coupled with the increasing use of Internet services has led to an increasing awareness of the importance and usage of geospatial information in many applications. The navigation apps (often called Maps), use a variety of available data sources to calculate and predict the travel time as well as several options for routing in public transportation, car or pedestrian modes. This paper evaluates the pedestrian mode of Maps apps in three major smartphone operating systems (Android, iOS and Windows Phone). In the paper, we will show that the Maps apps on iOS, Android and Windows Phone in pedestrian mode, predict travel time without learning from the individual's movement profile. In addition, we will exemplify that those apps suffer from a specific data quality issue which relates to the absence of information about location and type of pedestrian crossings. Finally, we will illustrate learning from movement profile of individuals using various predictive analytics models to improve the accuracy of travel time estimation.
Scalable Linear Causal Inference for Irregularly Sampled Time Series with Long Range Dependencies
Mar 10, 2016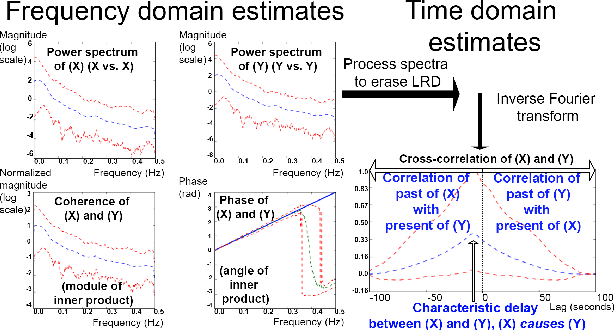
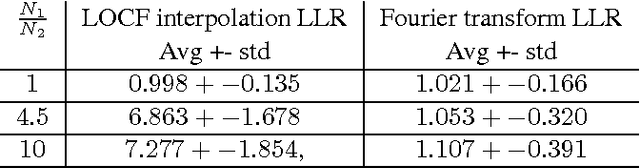
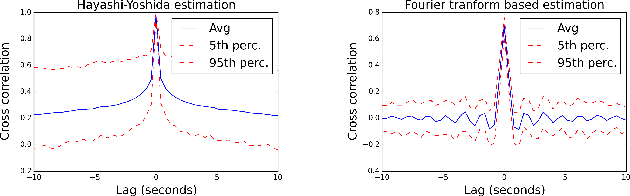
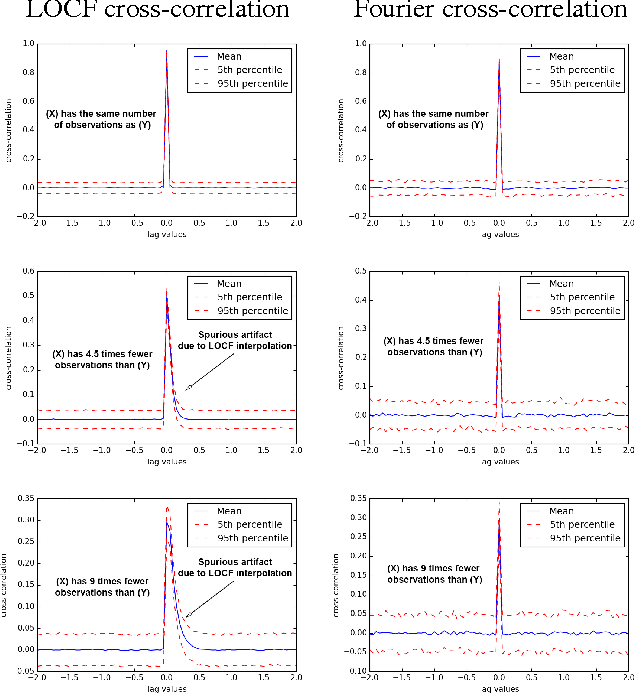
Linear causal analysis is central to a wide range of important application spanning finance, the physical sciences, and engineering. Much of the existing literature in linear causal analysis operates in the time domain. Unfortunately, the direct application of time domain linear causal analysis to many real-world time series presents three critical challenges: irregular temporal sampling, long range dependencies, and scale. Moreover, real-world data is often collected at irregular time intervals across vast arrays of decentralized sensors and with long range dependencies which make naive time domain correlation estimators spurious. In this paper we present a frequency domain based estimation framework which naturally handles irregularly sampled data and long range dependencies while enabled memory and communication efficient distributed processing of time series data. By operating in the frequency domain we eliminate the need to interpolate and help mitigate the effects of long range dependencies. We implement and evaluate our new work-flow in the distributed setting using Apache Spark and demonstrate on both Monte Carlo simulations and high-frequency financial trading that we can accurately recover causal structure at scale.
Accelerating Training of Transformer-Based Language Models with Progressive Layer Dropping
Oct 26, 2020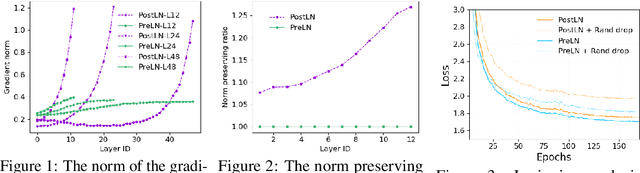
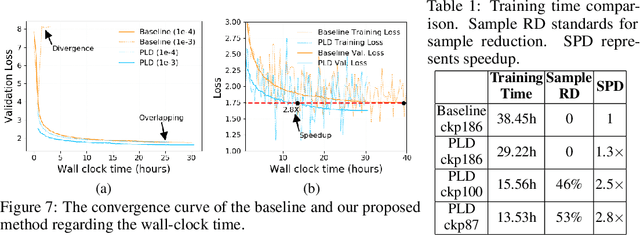
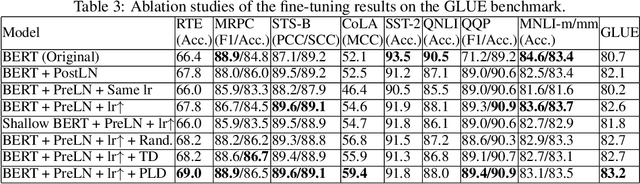
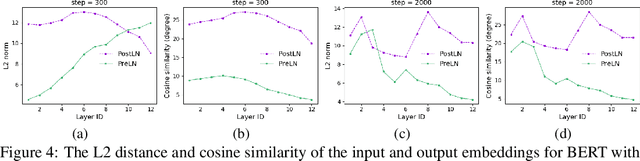
Recently, Transformer-based language models have demonstrated remarkable performance across many NLP domains. However, the unsupervised pre-training step of these models suffers from unbearable overall computational expenses. Current methods for accelerating the pre-training either rely on massive parallelism with advanced hardware or are not applicable to language modeling. In this work, we propose a method based on progressive layer dropping that speeds the training of Transformer-based language models, not at the cost of excessive hardware resources but from model architecture change and training technique boosted efficiency. Extensive experiments on BERT show that the proposed method achieves a 24% time reduction on average per sample and allows the pre-training to be 2.5 times faster than the baseline to get a similar accuracy on downstream tasks. While being faster, our pre-trained models are equipped with strong knowledge transferability, achieving comparable and sometimes higher GLUE score than the baseline when pre-trained with the same number of samples.
Development and Testing of a Novel Automated Insect Capture Module for Sample Collection and Transfer
Aug 29, 2020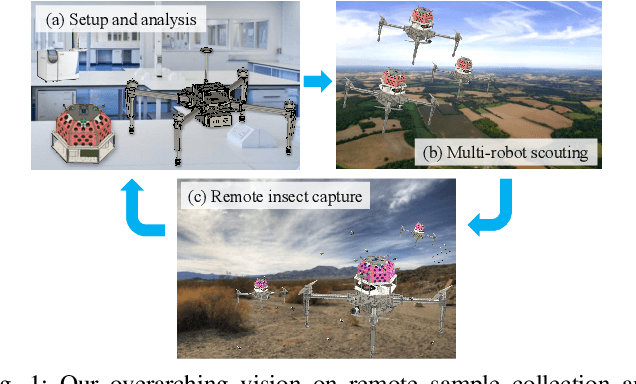

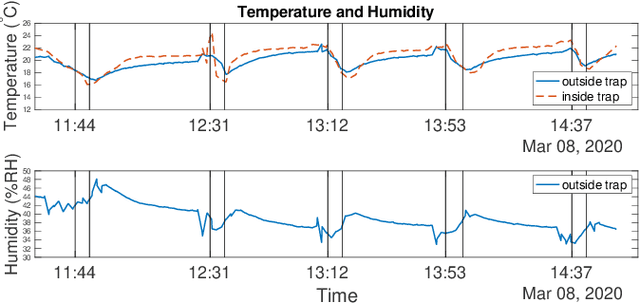

There exists an urgent need for efficient tools in disease surveillance to help model and predict the spread of disease. The transmission of insect-borne diseases poses a serious concern to public health officials and the medical and research community at large. In the modeling of this spread, we face bottlenecks in (1) the frequency at which we are able to sample insect vectors in environments that are prone to propagating disease, (2) manual labor needed to set up and retrieve surveillance devices like traps, and (3) the return time in analyzing insect samples and determining if an infectious disease is spreading in a region. To help address these bottlenecks, we present in this paper the design, fabrication, and testing of a novel automated insect capture module (ICM) or trap that aims to improve the rate of transferring samples collected from the environment via aerial robots. The ICM features an ultraviolet light attractant, passive capture mechanism, panels which can open and close for access to insects, and a small onboard computer for automated operation and data logging. At the same time, the ICM is designed to be accessible; it is small-scale, lightweight and low-cost, and can be integrated with commercially available aerial robots. Indoor and outdoor experimentation validates ICM's feasibility in insect capturing and safe transportation. The device can help bring us one step closer toward achieving fully autonomous and scalable epidemiology by leveraging autonomous robots technology to aid the medical and research community.
Uncertainty-driven refinement of tumor-core segmentation using 3D-to-2D networks with label uncertainty
Dec 11, 2020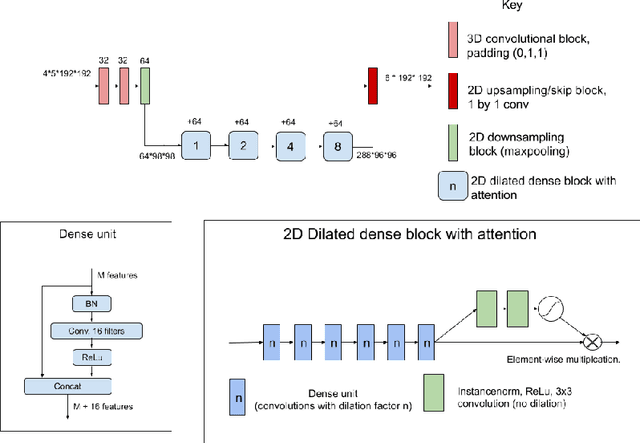
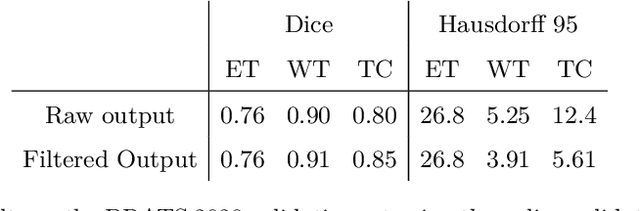
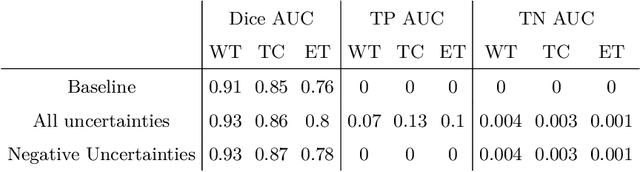
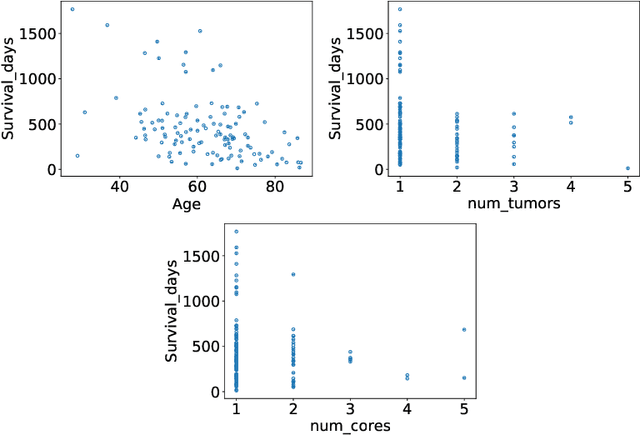
The BraTS dataset contains a mixture of high-grade and low-grade gliomas, which have a rather different appearance: previous studies have shown that performance can be improved by separated training on low-grade gliomas (LGGs) and high-grade gliomas (HGGs), but in practice this information is not available at test time to decide which model to use. By contrast with HGGs, LGGs often present no sharp boundary between the tumor core and the surrounding edema, but rather a gradual reduction of tumor-cell density. Utilizing our 3D-to-2D fully convolutional architecture, DeepSCAN, which ranked highly in the 2019 BraTS challenge and was trained using an uncertainty-aware loss, we separate cases into those with a confidently segmented core, and those with a vaguely segmented or missing core. Since by assumption every tumor has a core, we reduce the threshold for classification of core tissue in those cases where the core, as segmented by the classifier, is vaguely defined or missing. We then predict survival of high-grade glioma patients using a fusion of linear regression and random forest classification, based on age, number of distinct tumor components, and number of distinct tumor cores. We present results on the validation dataset of the Multimodal Brain Tumor Segmentation Challenge 2020 (segmentation and uncertainty challenge), and on the testing set, where the method achieved 4th place in Segmentation, 1st place in uncertainty estimation, and 1st place in Survival prediction.
Addressing Cold Start in Recommender Systems with Hierarchical Graph Neural Networks
Sep 07, 2020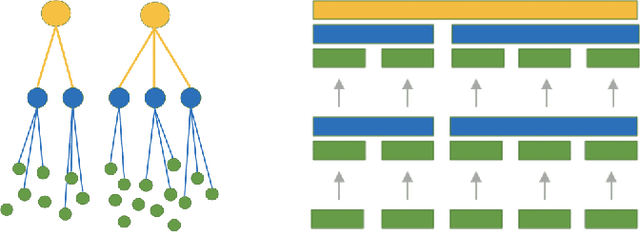
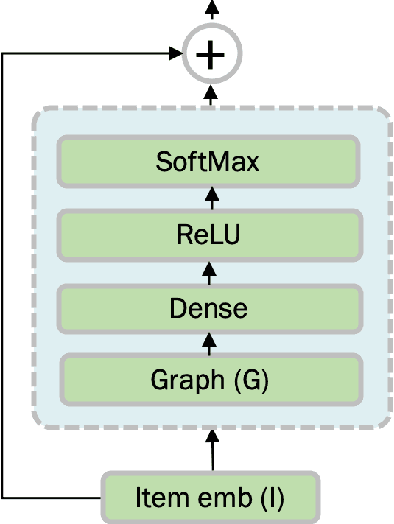
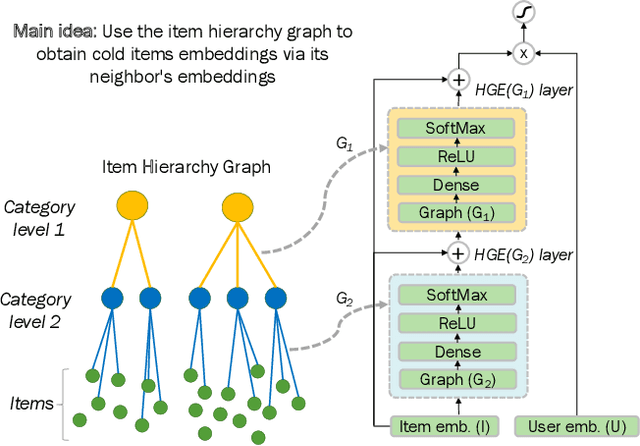
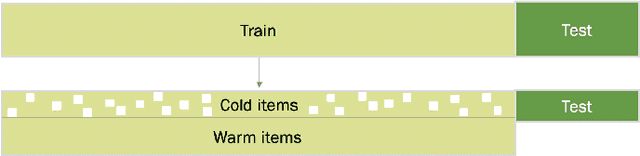
Recommender systems have become an essential instrument in a wide range of industries to personalize the user experience. A significant issue that has captured both researchers' and industry experts' attention is the cold start problem for new items. In this work, we present a graph neural network recommender system using item hierarchy graphs and a bespoke architecture to handle the cold start case for items. The experimental study on multiple datasets and millions of users and interactions indicates that our method achieves better forecasting quality than the state-of-the-art with a comparable computational time.