 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Cross-Modal Generalization: Learning in Low Resource Modalities via Meta-Alignment
Dec 04, 2020
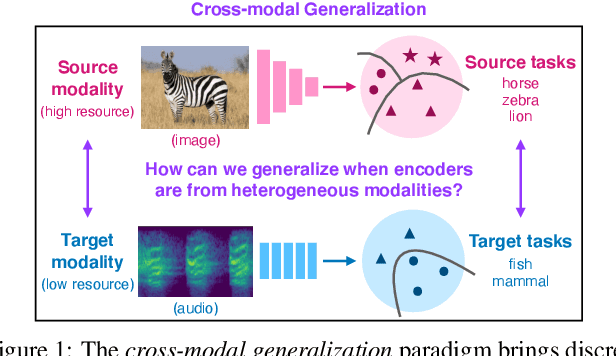
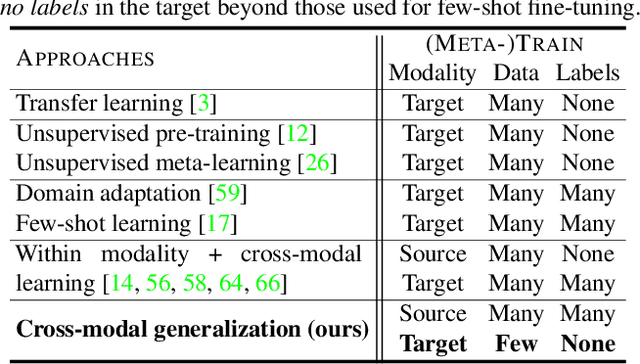
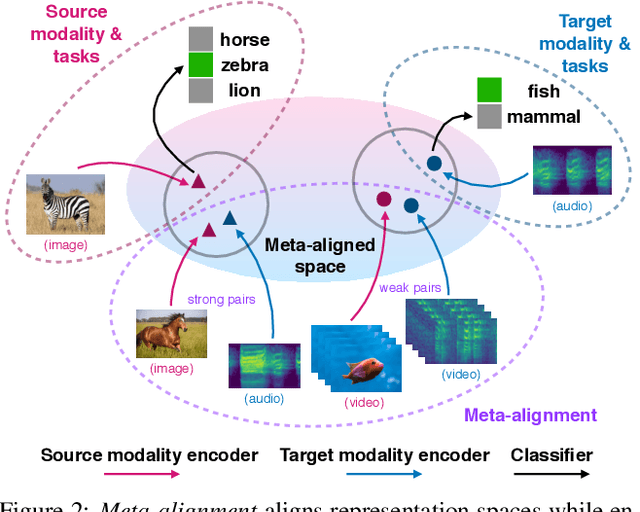
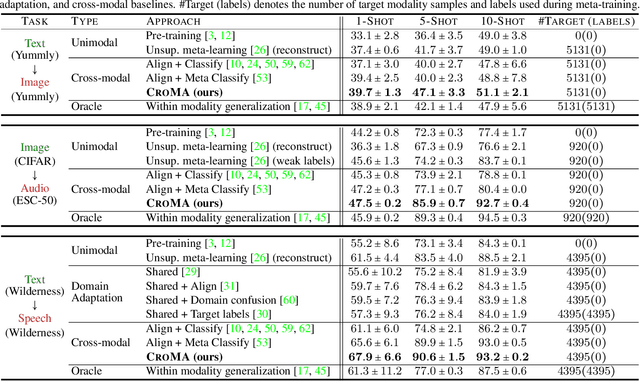
The natural world is abundant with concepts expressed via visual, acoustic, tactile, and linguistic modalities. Much of the existing progress in multimodal learning, however, focuses primarily on problems where the same set of modalities are present at train and test time, which makes learning in low-resource modalities particularly difficult. In this work, we propose algorithms for cross-modal generalization: a learning paradigm to train a model that can (1) quickly perform new tasks in a target modality (i.e. meta-learning) and (2) doing so while being trained on a different source modality. We study a key research question: how can we ensure generalization across modalities despite using separate encoders for different source and target modalities? Our solution is based on meta-alignment, a novel method to align representation spaces using strongly and weakly paired cross-modal data while ensuring quick generalization to new tasks across different modalities. We study this problem on 3 classification tasks: text to image, image to audio, and text to speech. Our results demonstrate strong performance even when the new target modality has only a few (1-10) labeled samples and in the presence of noisy labels, a scenario particularly prevalent in low-resource modalities.
Narrow Artificial Intelligence with Machine Learning for Real-Time Estimation of a Mobile Agents Location Using Hidden Markov Models
Feb 09, 2018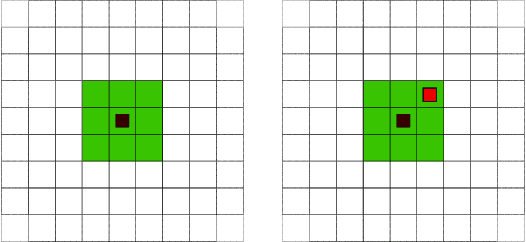


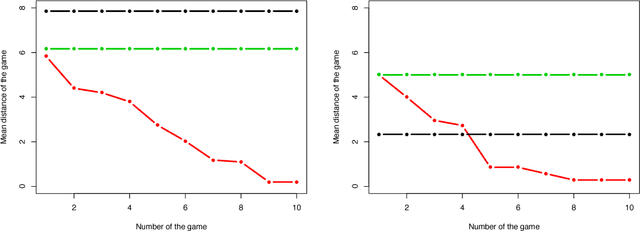
We propose to use a supervised machine learning technique to track the location of a mobile agent in real time. Hidden Markov Models are used to build artificial intelligence that estimates the unknown position of a mobile target moving in a defined environment. This narrow artificial intelligence performs two distinct tasks. First, it provides real-time estimation of the mobile agent's position using the forward algorithm. Second, it uses the Baum-Welch algorithm as a statistical learning tool to gain knowledge of the mobile target. Finally, an experimental environment is proposed, namely a video game that we use to test our artificial intelligence. We present statistical and graphical results to illustrate the efficiency of our method.
Asynchronous Deep Model Reference Adaptive Control
Nov 04, 2020



In this paper, we present Asynchronous implementation of Deep Neural Network-based Model Reference Adaptive Control (DMRAC). We evaluate this new neuro-adaptive control architecture through flight tests on a small quadcopter. We demonstrate that a single DMRAC controller can handle significant nonlinearities due to severe system faults and deliberate wind disturbances while executing high-bandwidth attitude control. We also show that the architecture has long-term learning abilities across different flight regimes, and can generalize to fly different flight trajectories than those on which it was trained. These results demonstrating the efficacy of this architecture for high bandwidth closed-loop attitude control of unstable and nonlinear robots operating in adverse situations. To achieve these results, we designed a software+communication architecture to ensure online real-time inference of the deep network on a high-bandwidth computation-limited platform. We expect that this architecture will benefit other deep learning in the closed-loop experiments on robots.
An Efficient Algorithm For Generalized Linear Bandit: Online Stochastic Gradient Descent and Thompson Sampling
Jun 07, 2020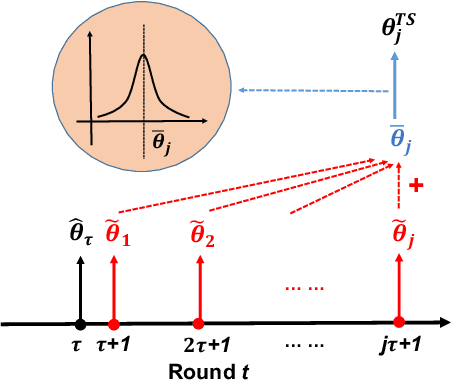

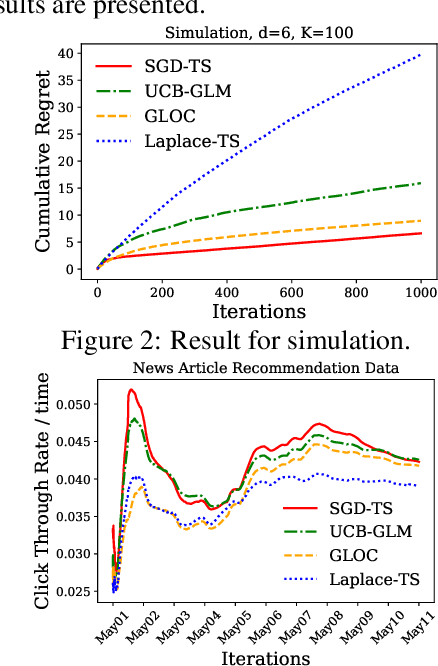
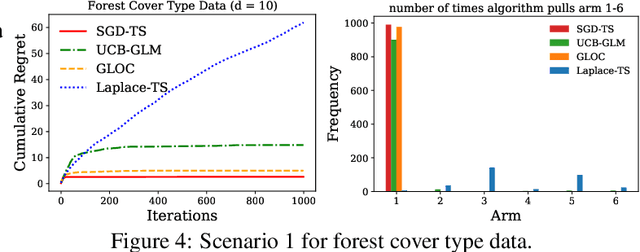
We consider the contextual bandit problem, where a player sequentially makes decisions based on past observations to maximize the cumulative reward. Although many algorithms have been proposed for contextual bandit, most of them rely on finding the maximum likelihood estimator at each iteration, which requires $O(t)$ time at the $t$-th iteration and are memory inefficient. A natural way to resolve this problem is to apply online stochastic gradient descent (SGD) so that the per-step time and memory complexity can be reduced to constant with respect to $t$, but a contextual bandit policy based on online SGD updates that balances exploration and exploitation has remained elusive. In this work, we show that online SGD can be applied to the generalized linear bandit problem. The proposed SGD-TS algorithm, which uses a single-step SGD update to exploit past information and uses Thompson Sampling for exploration, achieves $\tilde{O}(\sqrt{dT})$ regret with the total time complexity that scales linearly in $T$ and $d$, where $T$ is the total number of rounds and $d$ is the number of features. Experimental results show that SGD-TS consistently outperforms existing algorithms on both synthetic and real datasets.
Asymmetric Learning Vector Quantization for Efficient Nearest Neighbor Classification in Dynamic Time Warping Spaces
Mar 24, 2017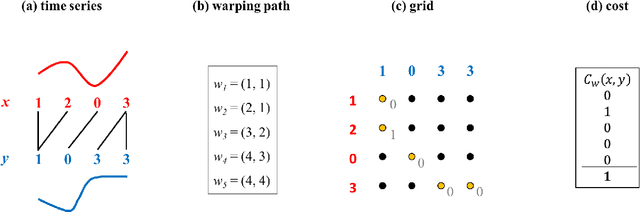
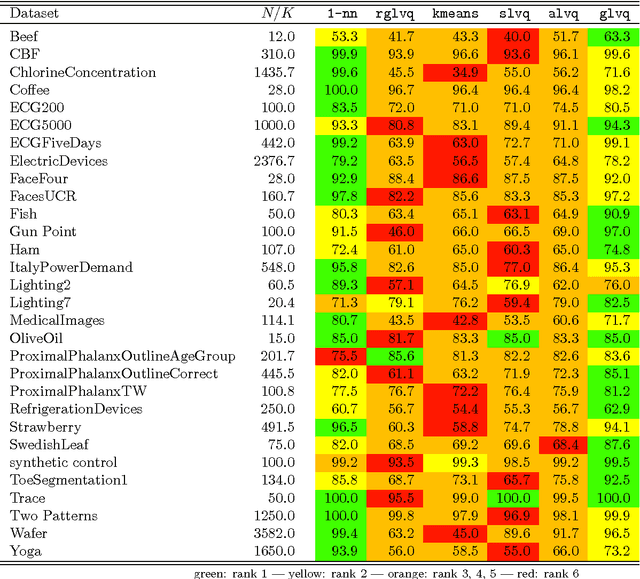
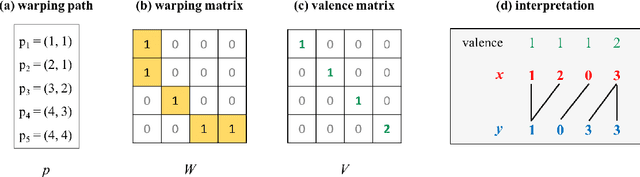
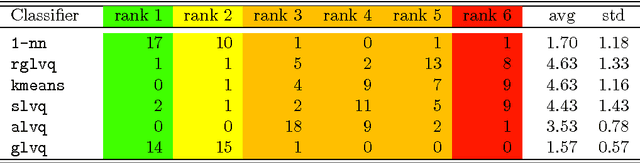
The nearest neighbor method together with the dynamic time warping (DTW) distance is one of the most popular approaches in time series classification. This method suffers from high storage and computation requirements for large training sets. As a solution to both drawbacks, this article extends learning vector quantization (LVQ) from Euclidean spaces to DTW spaces. The proposed LVQ scheme uses asymmetric weighted averaging as update rule. Empirical results exhibited superior performance of asymmetric generalized LVQ (GLVQ) over other state-of-the-art prototype generation methods for nearest neighbor classification.
FDRN: A Fast Deformable Registration Network for Medical Images
Nov 04, 2020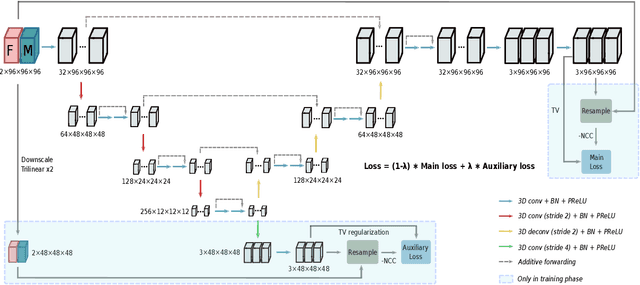
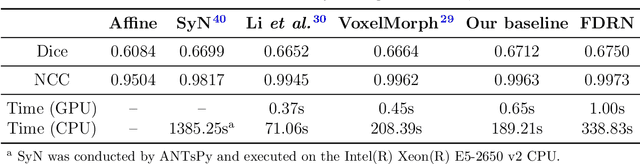
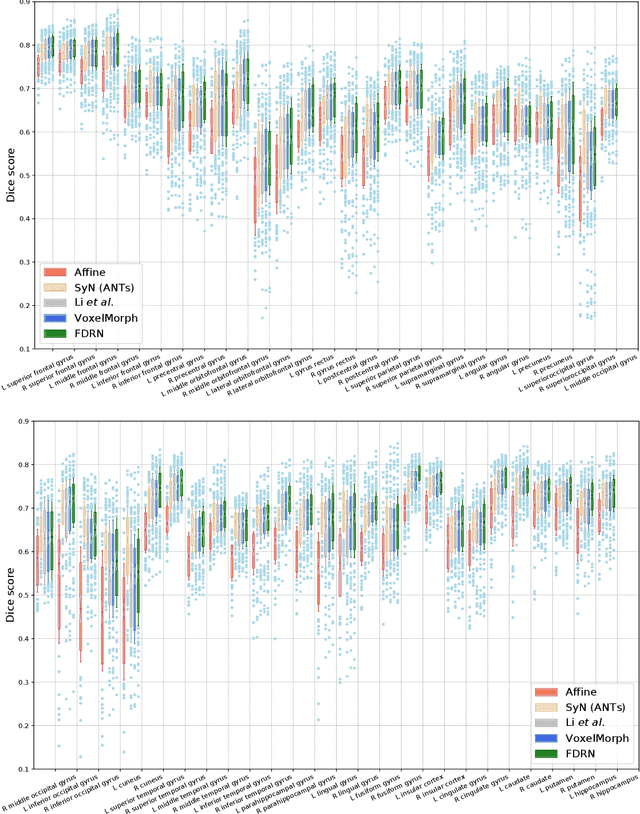
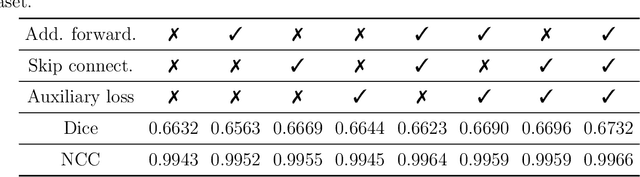
Deformable image registration is a fundamental task in medical imaging. Due to the large computational complexity of deformable registration of volumetric images, conventional iterative methods usually face the tradeoff between the registration accuracy and the computation time in practice. In order to boost the registration performance in both accuracy and runtime, we propose a fast unsupervised convolutional neural network for deformable image registration. Specially, the proposed FDRN possesses a compact encoder-decoder structure and exploits deep supervision, additive forwarding and residual learning. We conducted comparison with the existing state-of-the-art registration methods on the LPBA40 brain MRI dataset. Experimental results demonstrate that our FDRN performs better than the investigated methods qualitatively and quantitatively in Dice score and normalized cross correlation (NCC). Besides, FDRN is a generalized framework for image registration which is not confined to a particular type of medical images or anatomy. It can also be applied to other anatomical structures or CT images.
Synthesizing CT from Ultrashort Echo-Time MR Images via Convolutional Neural Networks
Jul 27, 2018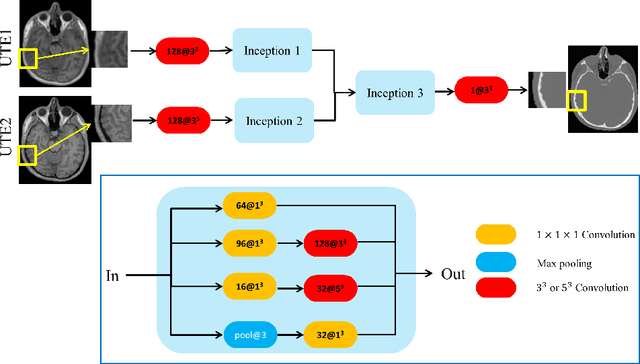
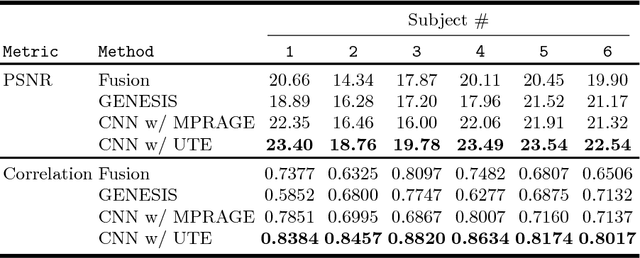

With the increasing popularity of PET-MR scanners in clinical applications, synthesis of CT images from MR has been an important research topic. Accurate PET image reconstruction requires attenuation correction, which is based on the electron density of tissues and can be obtained from CT images. While CT measures electron density information for x-ray photons, MR images convey information about the magnetic properties of tissues. Therefore, with the advent of PET-MR systems, the attenuation coefficients need to be indirectly estimated from MR images. In this paper, we propose a fully convolutional neural network (CNN) based method to synthesize head CT from ultra-short echo-time (UTE) dual-echo MR images. Unlike traditional $T_1$-w images which do not have any bone signal, UTE images show some signal for bone, which makes it a good candidate for MR to CT synthesis. A notable advantage of our approach is that accurate results were achieved with a small training data set. Using an atlas of a single CT and dual-echo UTE pair, we train a deep neural network model to learn the transform of MR intensities to CT using patches. We compared our CNN based model with a state-of-the-art registration based as well as a Bayesian model based CT synthesis method, and showed that the proposed CNN model outperforms both of them. We also compared the proposed model when only $T_1$-w images are available instead of UTE, and show that UTE images produce better synthesis than using just $T_1$-w images.
Online Optimal Control with Affine Constraints
Oct 10, 2020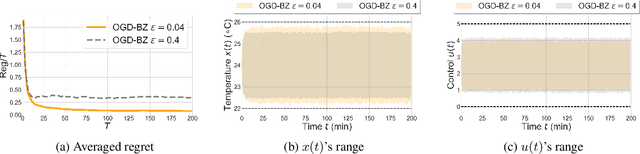
This paper considers online optimal control with affine constraints on the states and actions under linear dynamics with random disturbances. We consider convex stage cost functions that change adversarially. Besides, we consider time-invariant and known system dynamics and constraints. To solve this problem, we propose Online Gradient Descent with Buffer Zone (OGD-BZ). Theoretically, we show that OGD-BZ can guarantee the system to satisfy all the constraints despite any realization of the disturbances under proper parameters. Further, we investigate the policy regret of OGD-BZ, which compares OGD-BZ's performance with the performance of the optimal linear policy in hindsight. We show that OGD-BZ can achieve $\tilde O(\sqrt T)$ policy regret under proper parameters, where $\tilde O(\cdot)$ absorbs logarithmic terms of $T$.
Modulation of viability signals for self-regulatory control
Jul 18, 2020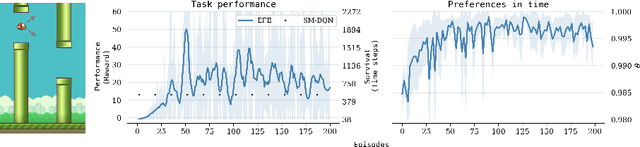
We revisit the role of instrumental value as a driver of adaptive behavior. In active inference, instrumental or extrinsic value is quantified by the information-theoretic surprisal of a set of observations measuring the extent to which those observations conform to prior beliefs or preferences. That is, an agent is expected to seek the type of evidence that is consistent with its own model of the world. For reinforcement learning tasks, the distribution of preferences replaces the notion of reward. We explore a scenario in which the agent learns this distribution in a self-supervised manner. In particular, we highlight the distinction between observations induced by the environment and those pertaining more directly to the continuity of an agent in time. We evaluate our methodology in a dynamic environment with discrete time and actions. First with a surprisal minimizing model-free agent (in the RL sense) and then expanding to the model-based case to minimize the expected free energy.
Robust autoregressive hidden semi-Markov models applied to EEG sleep spindles detection
Oct 16, 2020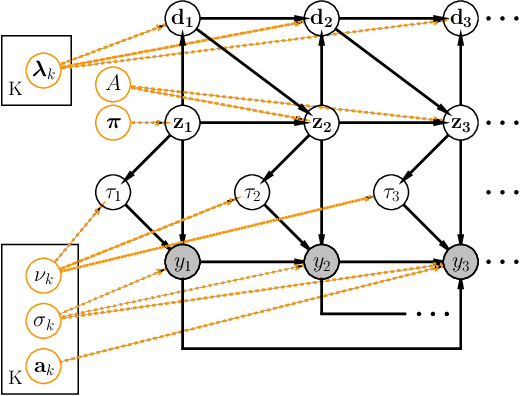

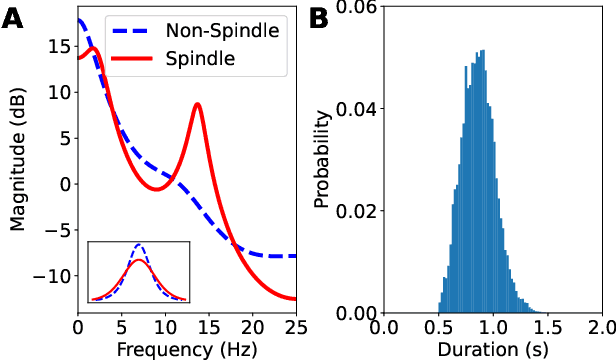

We propose a generative model for single-channel EEG that incorporates the constraints experts actively enforce while visually scoring recordings. In particular, the framework takes the form of a robust hidden semi-Markov model that explicitly segments sequences into local, reoccurring dynamical regimes. Unlike typical detectors, our approach takes the raw data (up to resampling) without any filtering, windowing, nor thresholding. This not only makes the model appealing to real-time applications, but it also yields interpretable hyperparameters that are analogous to known clinical criteria. We validate the model on stage 2 non-REM sleep recordings that display characteristic sleep spindles. We derive tractable algorithms for exact inference and prove that more complex models are able to surpass state of the art detectors while being completely transparent, auditable, and generalizable.