 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Room-Across-Room: Multilingual Vision-and-Language Navigation with Dense Spatiotemporal Grounding
Oct 15, 2020

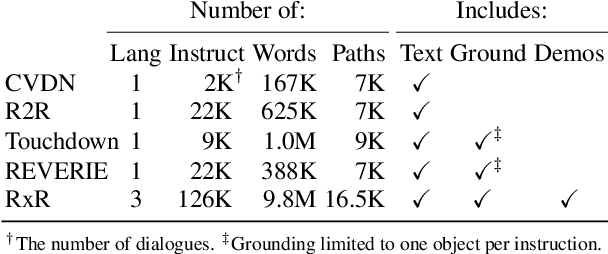
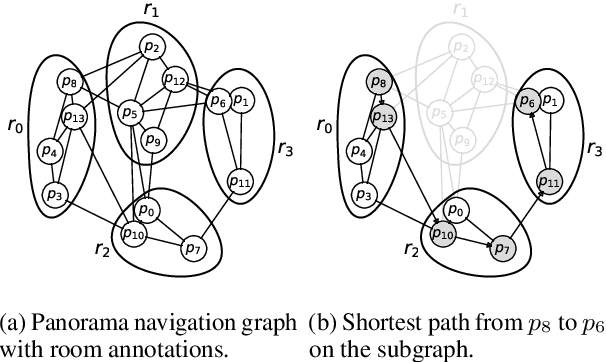
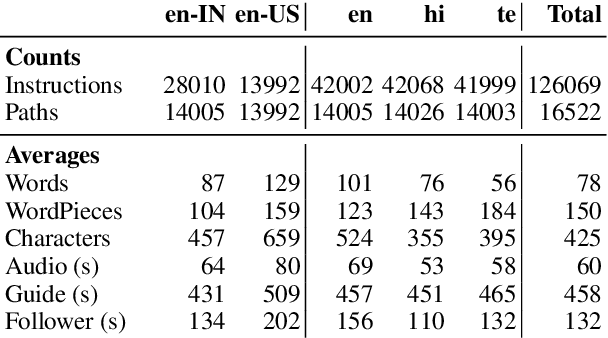
We introduce Room-Across-Room (RxR), a new Vision-and-Language Navigation (VLN) dataset. RxR is multilingual (English, Hindi, and Telugu) and larger (more paths and instructions) than other VLN datasets. It emphasizes the role of language in VLN by addressing known biases in paths and eliciting more references to visible entities. Furthermore, each word in an instruction is time-aligned to the virtual poses of instruction creators and validators. We establish baseline scores for monolingual and multilingual settings and multitask learning when including Room-to-Room annotations. We also provide results for a model that learns from synchronized pose traces by focusing only on portions of the panorama attended to in human demonstrations. The size, scope and detail of RxR dramatically expands the frontier for research on embodied language agents in simulated, photo-realistic environments.
Point-of-Interest Type Inference from Social Media Text
Oct 02, 2020
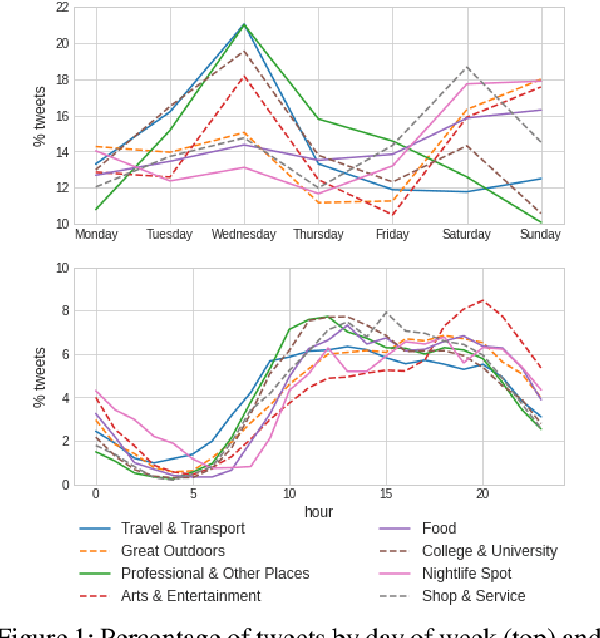
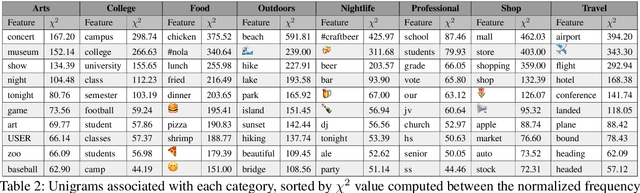
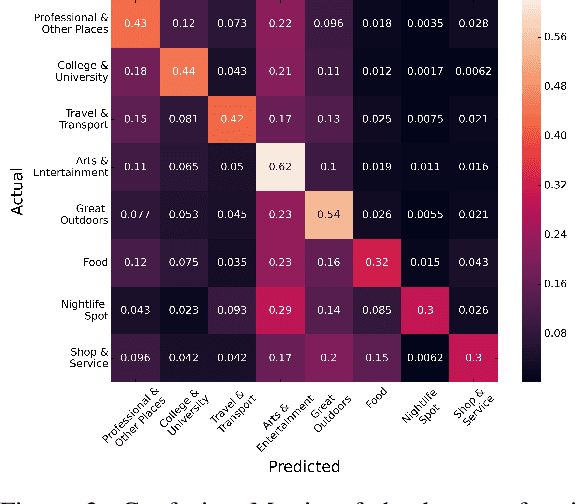
Physical places help shape how we perceive the experiences we have there. For the first time, we study the relationship between social media text and the type of the place from where it was posted, whether a park, restaurant, or someplace else. To facilitate this, we introduce a novel data set of $\sim$200,000 English tweets published from 2,761 different points-of-interest in the U.S., enriched with place type information. We train classifiers to predict the type of the location a tweet was sent from that reach a macro F1 of 43.67 across eight classes and uncover the linguistic markers associated with each type of place. The ability to predict semantic place information from a tweet has applications in recommendation systems, personalization services and cultural geography.
LiRaNet: End-to-End Trajectory Prediction using Spatio-Temporal Radar Fusion
Oct 15, 2020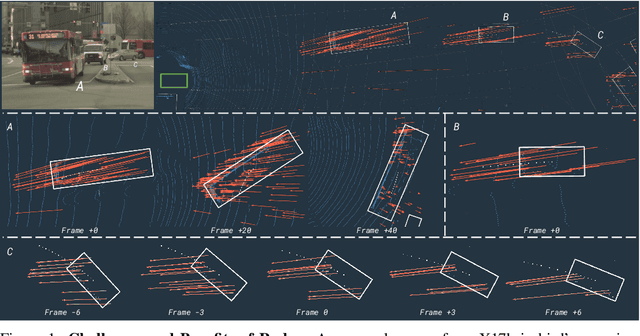
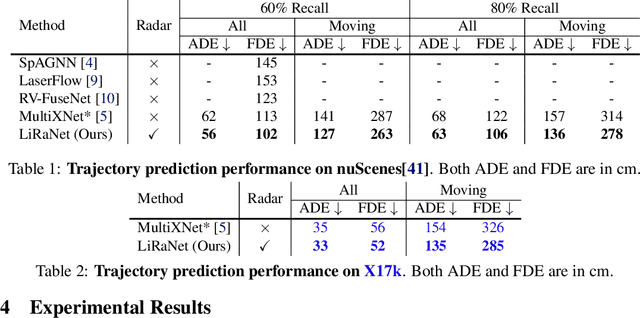
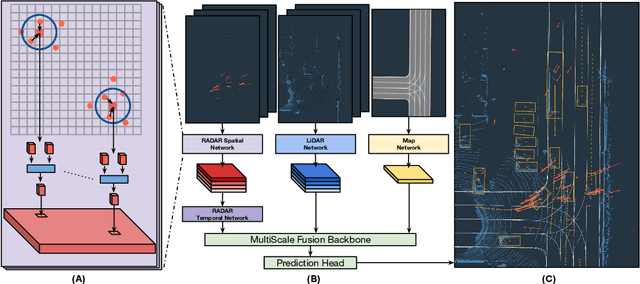

In this paper, we present LiRaNet, a novel end-to-end trajectory prediction method which utilizes radar sensor information along with widely used lidar and high definition (HD) maps. Automotive radar provides rich, complementary information, allowing for longer range vehicle detection as well as instantaneous radial velocity measurements. However, there are factors that make the fusion of lidar and radar information challenging, such as the relatively low angular resolution of radar measurements, their sparsity and the lack of exact time synchronization with lidar. To overcome these challenges, we propose an efficient spatio-temporal radar feature extraction scheme which achieves state-of-the-art performance on multiple large-scale datasets.Further, by incorporating radar information, we show a 52% reduction in prediction error for objects with high acceleration and a 16% reduction in prediction error for objects at longer range.
PnPNet: End-to-End Perception and Prediction with Tracking in the Loop
Jun 27, 2020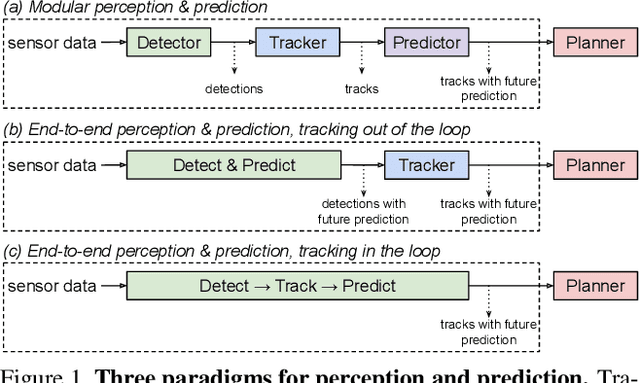
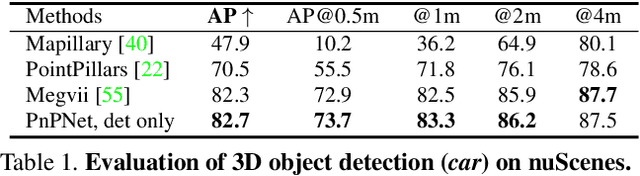
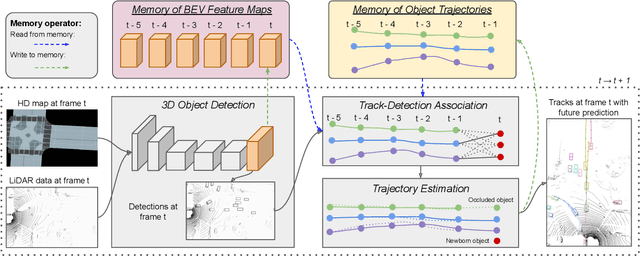

We tackle the problem of joint perception and motion forecasting in the context of self-driving vehicles. Towards this goal we propose PnPNet, an end-to-end model that takes as input sequential sensor data, and outputs at each time step object tracks and their future trajectories. The key component is a novel tracking module that generates object tracks online from detections and exploits trajectory level features for motion forecasting. Specifically, the object tracks get updated at each time step by solving both the data association problem and the trajectory estimation problem. Importantly, the whole model is end-to-end trainable and benefits from joint optimization of all tasks. We validate PnPNet on two large-scale driving datasets, and show significant improvements over the state-of-the-art with better occlusion recovery and more accurate future prediction.
SST-BERT at SemEval-2020 Task 1: Semantic Shift Tracing by Clustering in BERT-based Embedding Spaces
Oct 02, 2020
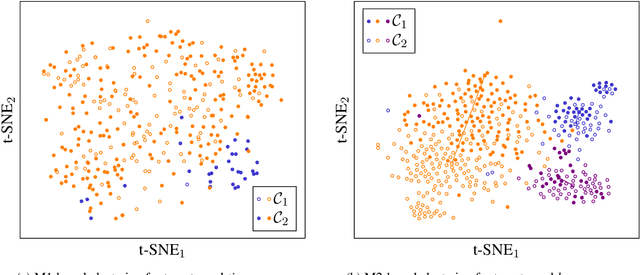
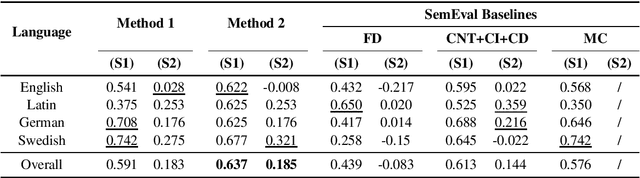
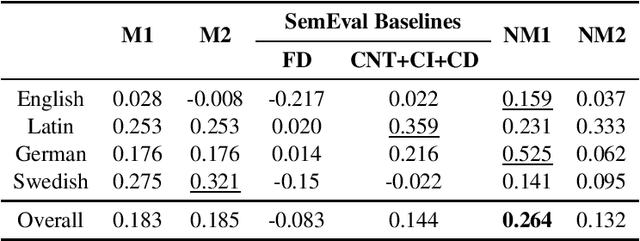
Lexical semantic change detection (also known as semantic shift tracing) is a task of identifying words that have changed their meaning over time. Unsupervised semantic shift tracing, focal point of SemEval2020, is particularly challenging. Given the unsupervised setup, in this work, we propose to identify clusters among different occurrences of each target word, considering these as representatives of different word meanings. As such, disagreements in obtained clusters naturally allow to quantify the level of semantic shift per each target word in four target languages. To leverage this idea, clustering is performed on contextualized (BERT-based) embeddings of word occurrences. The obtained results show that our approach performs well both measured separately (per language) and overall, where we surpass all provided SemEval baselines.
metricDTW: local distance metric learning in Dynamic Time Warping
Jun 11, 2016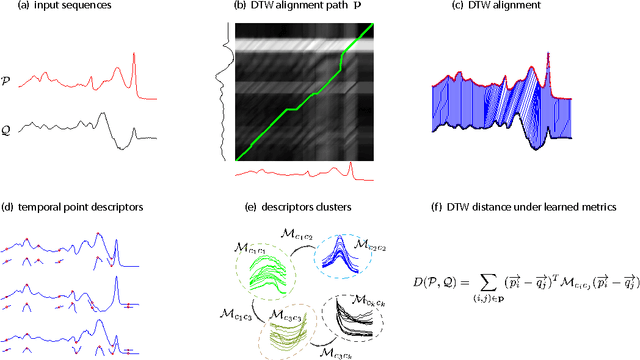
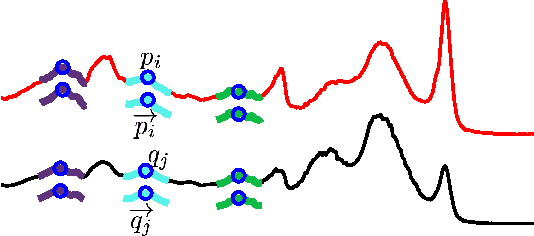
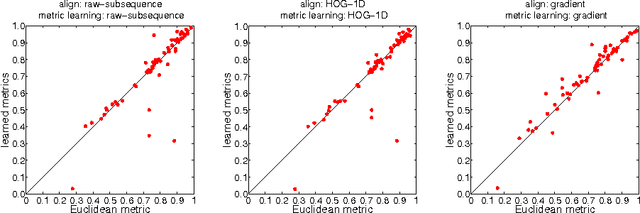
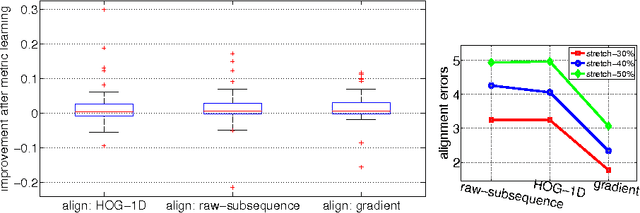
We propose to learn multiple local Mahalanobis distance metrics to perform k-nearest neighbor (kNN) classification of temporal sequences. Temporal sequences are first aligned by dynamic time warping (DTW); given the alignment path, similarity between two sequences is measured by the DTW distance, which is computed as the accumulated distance between matched temporal point pairs along the alignment path. Traditionally, Euclidean metric is used for distance computation between matched pairs, which ignores the data regularities and might not be optimal for applications at hand. Here we propose to learn multiple Mahalanobis metrics, such that DTW distance becomes the sum of Mahalanobis distances. We adapt the large margin nearest neighbor (LMNN) framework to our case, and formulate multiple metric learning as a linear programming problem. Extensive sequence classification results show that our proposed multiple metrics learning approach is effective, insensitive to the preceding alignment qualities, and reaches the state-of-the-art performances on UCR time series datasets.
Joint Blind Room Acoustic Characterization From Speech And Music Signals Using Convolutional Recurrent Neural Networks
Oct 21, 2020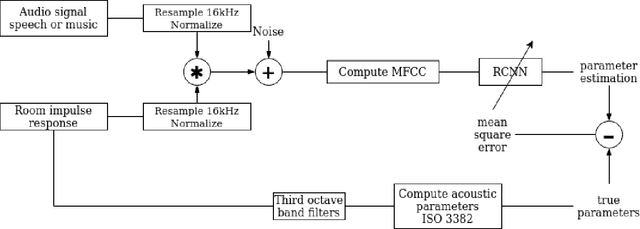
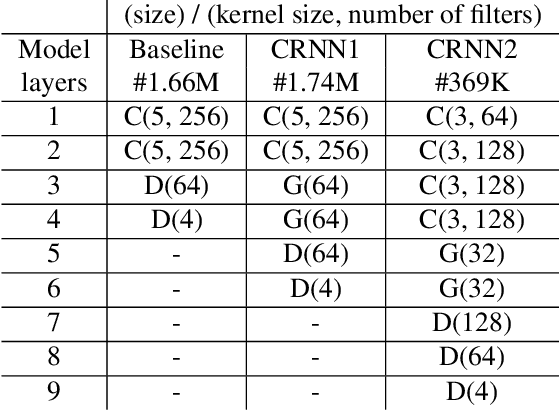
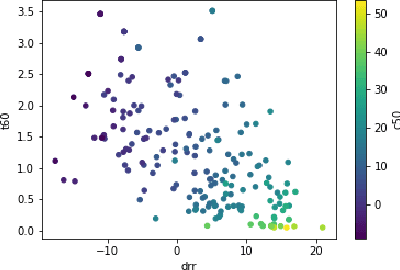
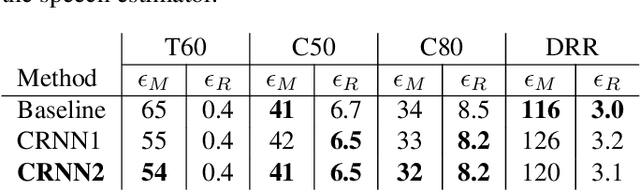
Acoustic environment characterization opens doors for sound reproduction innovations, smart EQing, speech enhancement, hearing aids, and forensics. Reverberation time, clarity, and direct-to-reverberant ratio are acoustic parameters that have been defined to describe reverberant environments. They are closely related to speech intelligibility and sound quality. As explained in the ISO3382 standard, they can be derived from a room measurement called the Room Impulse Response (RIR). However, measuring RIRs requires specific equipment and intrusive sound to be played. The recent audio combined with machine learning suggests that one could estimate those parameters blindly using speech or music signals. We follow these advances and propose a robust end-to-end method to achieve blind joint acoustic parameter estimation using speech and/or music signals. Our results indicate that convolutional recurrent neural networks perform best for this task, and including music in training also helps improve inference from speech.
Benchmark data and method for real-time people counting in cluttered scenes using depth sensors
Oct 28, 2018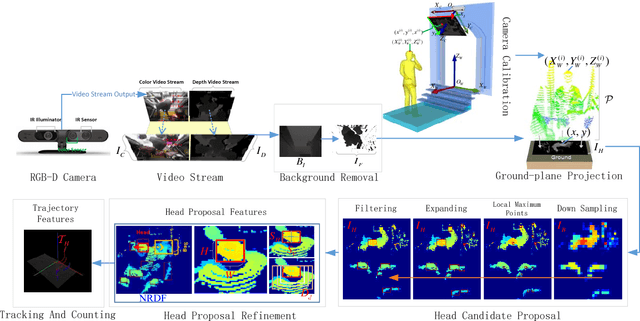

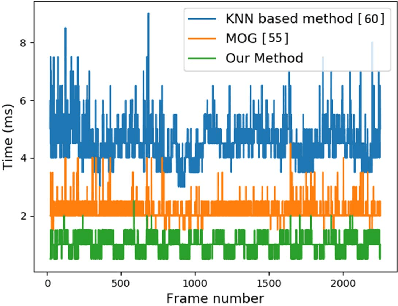
Vision-based automatic counting of people has widespread applications in intelligent transportation systems, security, and logistics. However, there is currently no large-scale public dataset for benchmarking approaches on this problem. This work fills this gap by introducing the first real-world RGB-D People Counting DataSet (PCDS) containing over 4,500 videos recorded at the entrance doors of buses in normal and cluttered conditions. It also proposes an efficient method for counting people in real-world cluttered scenes related to public transportations using depth videos. The proposed method computes a point cloud from the depth video frame and re-projects it onto the ground plane to normalize the depth information. The resulting depth image is analyzed for identifying potential human heads. The human head proposals are meticulously refined using a 3D human model. The proposals in each frame of the continuous video stream are tracked to trace their trajectories. The trajectories are again refined to ascertain reliable counting. People are eventually counted by accumulating the head trajectories leaving the scene. To enable effective head and trajectory identification, we also propose two different compound features. A thorough evaluation on PCDS demonstrates that our technique is able to count people in cluttered scenes with high accuracy at 45 fps on a 1.7 GHz processor, and hence it can be deployed for effective real-time people counting for intelligent transportation systems.
Generalized Insider Attack Detection Implementation using NetFlow Data
Oct 27, 2020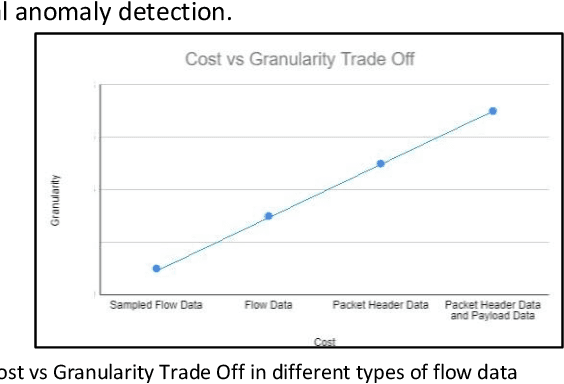
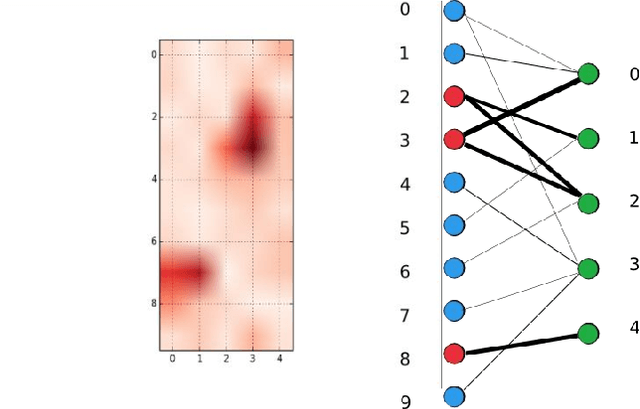
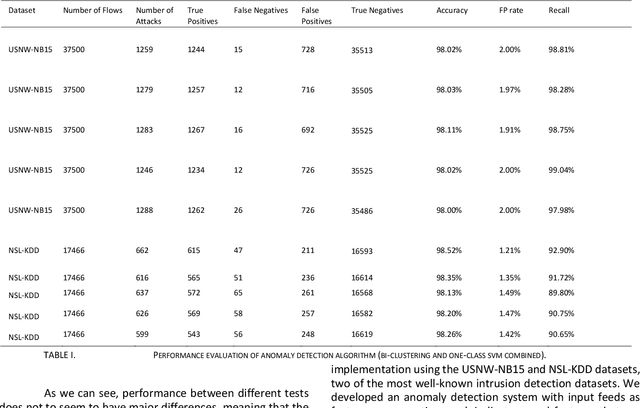
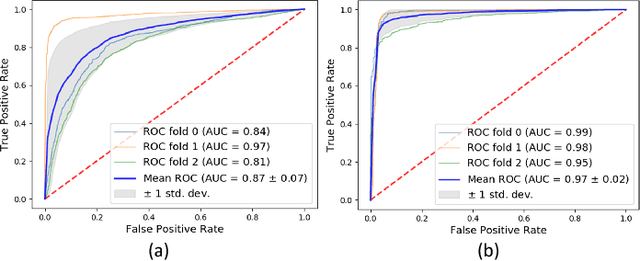
Insider Attack Detection in commercial networks is a critical problem that does not have any good solutions at this current time. The problem is challenging due to the lack of visibility into live networks and a lack of a standard feature set to distinguish between different attacks. In this paper, we study an approach centered on using network data to identify attacks. Our work builds on unsupervised machine learning techniques such as One-Class SVM and bi-clustering as weak indicators of insider network attacks. We combine these techniques to limit the number of false positives to an acceptable level required for real-world deployments by using One-Class SVM to check for anomalies detected by the proposed Bi-clustering algorithm. We present a prototype implementation in Python and associated results for two different real-world representative data sets. We show that our approach is a promising tool for insider attack detection in realistic settings.
Concentric mixtures of Mallows models for top-$k$ rankings: sampling and identifiability
Oct 27, 2020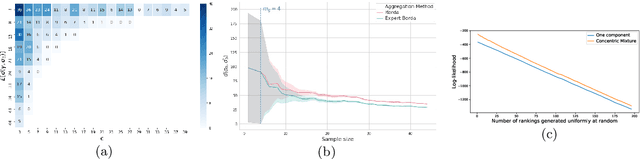
In this paper, we consider mixtures of two Mallows models for top-$k$ rankings, both with the same location parameter but with different scale parameters, i.e., a mixture of concentric Mallows models. This situation arises when we have a heterogeneous population of voters formed by two homogeneous populations, one of which is a subpopulation of expert voters while the other includes the non-expert voters. We propose efficient sampling algorithms for Mallows top-$k$ rankings. We show the identifiability of both components, and the learnability of their respective parameters in this setting by, first, bounding the sample complexity for the Borda algorithm with top-$k$ rankings and second, proposing polynomial time algorithm for the separation of the rankings in each component. Finally, since the rank aggregation will suffer from a large amount of noise introduced by the non-expert voters, we adapt the Borda algorithm to be able to recover the ground truth consensus ranking which is especially consistent with the expert rankings.