 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
QoS Aware Robot Trajectory Optimization with IRS-Assisted Millimeter-Wave Communications
Dec 14, 2020
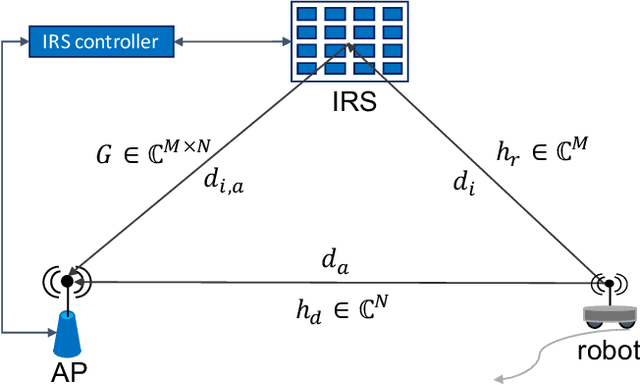
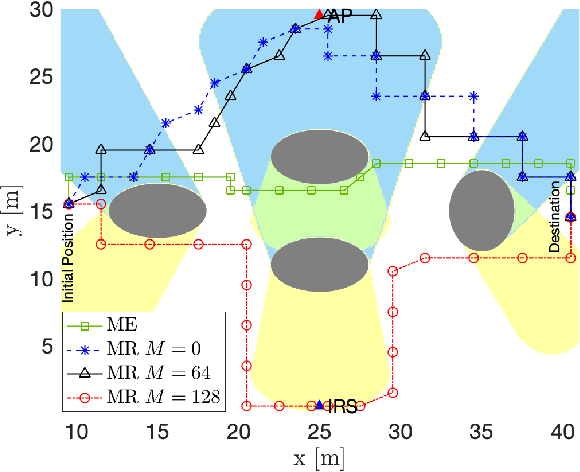
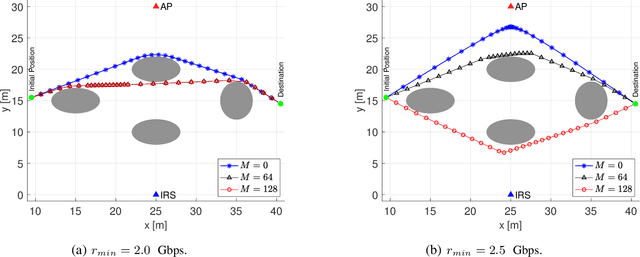
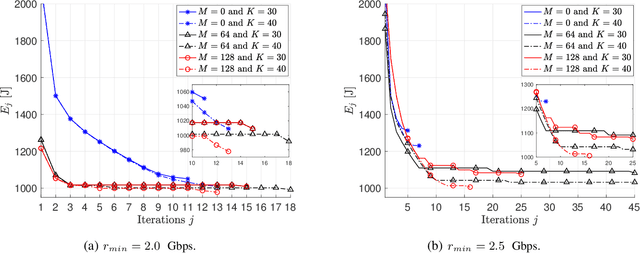
This paper considers the motion energy minimization problem for a wirelessly connected robot using millimeter-wave (mm-wave) communications. These are assisted by an intelligent reflective surface (IRS) that enhances the coverage at such high frequencies characterized by high blockage sensitivity. The robot is subject to time and uplink communication quality of service (QoS) constraints. This is a fundamental problem in fully automated factories that characterize Industry 4.0, where robots may have to perform tasks with given deadlines while maximizing the battery autonomy and communication efficiency. To account for the mutual dependence between robot position and communication QoS, we propose a joint optimization of robot trajectory and beamforming at the IRS and access point (AP). We present a solution that first exploits mm-wave channel characteristics to decouple beamforming and trajectory optimization. Then, the latter is solved by a successive-convex optimization-based algorithm. The algorithm takes into account the obstacles' positions and a radio map to avoid collisions and poorly covered areas. We prove that the algorithm can converge to a solution satisfying the Karush-Kuhn-Tucker (KKT) conditions. The simulation results show a dramatic reduction of the motion energy consumption with respect to methods that aim to find maximum-rate trajectories. Moreover, we show how the IRS and the beamforming optimization improve the motion energy efficiency of the robot.
Adversarial Multiscale Feature Learning for Overlapping Chromosome Segmentation
Dec 22, 2020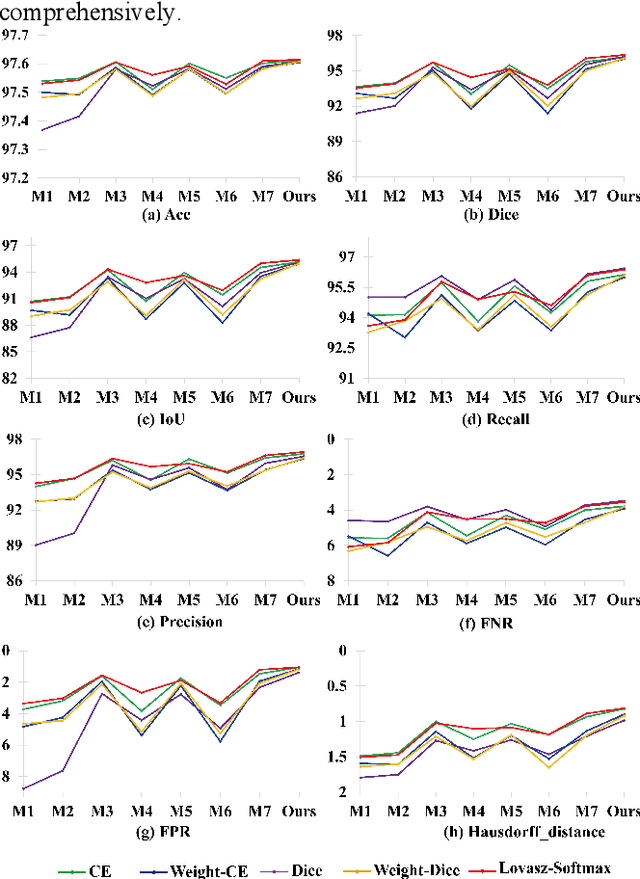


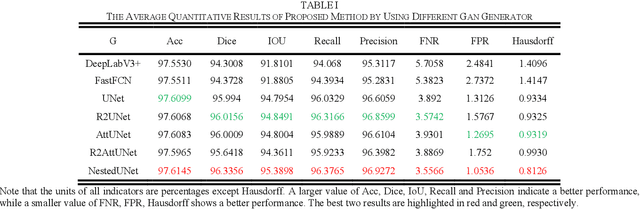
Chromosome karyotype analysis is of great clinical importance in the diagnosis and treatment of diseases, especially for genetic diseases. Since manual analysis is highly time and effort consuming, computer-assisted automatic chromosome karyotype analysis based on images is routinely used to improve the efficiency and accuracy of the analysis. Due to the strip shape of the chromosomes, they easily get overlapped with each other when imaged, significantly affecting the accuracy of the analysis afterward. Conventional overlapping chromosome segmentation methods are usually based on manually tagged features, hence, the performance of which is easily affected by the quality, such as resolution and brightness, of the images. To address the problem, in this paper, we present an adversarial multiscale feature learning framework to improve the accuracy and adaptability of overlapping chromosome segmentation. Specifically, we first adopt the nested U-shape network with dense skip connections as the generator to explore the optimal representation of the chromosome images by exploiting multiscale features. Then we use the conditional generative adversarial network (cGAN) to generate images similar to the original ones, the training stability of which is enhanced by applying the least-square GAN objective. Finally, we employ Lovasz-Softmax to help the model converge in a continuous optimization setting. Comparing with the established algorithms, the performance of our framework is proven superior by using public datasets in eight evaluation criteria, showing its great potential in overlapping chromosome segmentation
Detecting an Odd Restless Markov Arm with a Trembling Hand
May 13, 2020
In this paper, we consider a multi-armed bandit in which each arm is a Markov process evolving on a finite state space. The state space is common across the arms, and the arms are independent of each other. The transition probability matrix of one of the arms (the odd arm) is different from the common transition probability matrix of all the other arms. A decision maker, who knows these transition probability matrices, wishes to identify the odd arm as quickly as possible, while keeping the probability of decision error small. To do so, the decision maker collects observations from the arms by pulling the arms in a sequential manner, one at each discrete time instant. However, the decision maker has a trembling hand, and the arm that is actually pulled at any given time differs, with a small probability, from the one he intended to pull. The observation at any given time is the arm that is actually pulled and its current state. The Markov processes of the unobserved arms continue to evolve. This makes the arms restless. For the above setting, we derive the first known asymptotic lower bound on the expected stopping time, where the asymptotics is of vanishing error probability. The continued evolution of each arm adds a new dimension to the problem, leading to a family of Markov decision problems (MDPs) on a countable state space. We then stitch together certain parameterised solutions to these MDPs and obtain a sequence of strategies whose expected stopping times come arbitrarily close to the lower bound in the regime of vanishing error probability. Prior works dealt with independent and identically distributed (across time) arms and rested Markov arms, whereas our work deals with restless Markov arms.
Model Predictive Control for Autonomous Driving Based on Time Scaled Collision Cone
Mar 07, 2018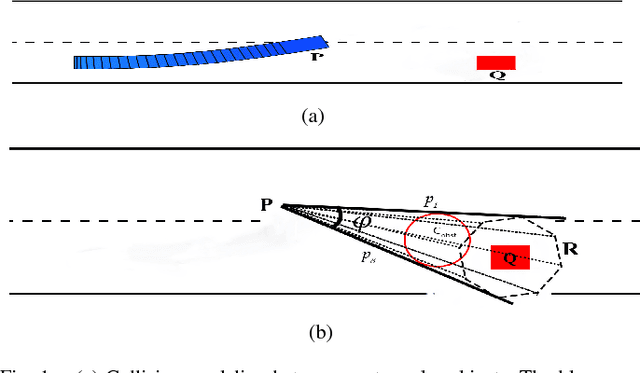
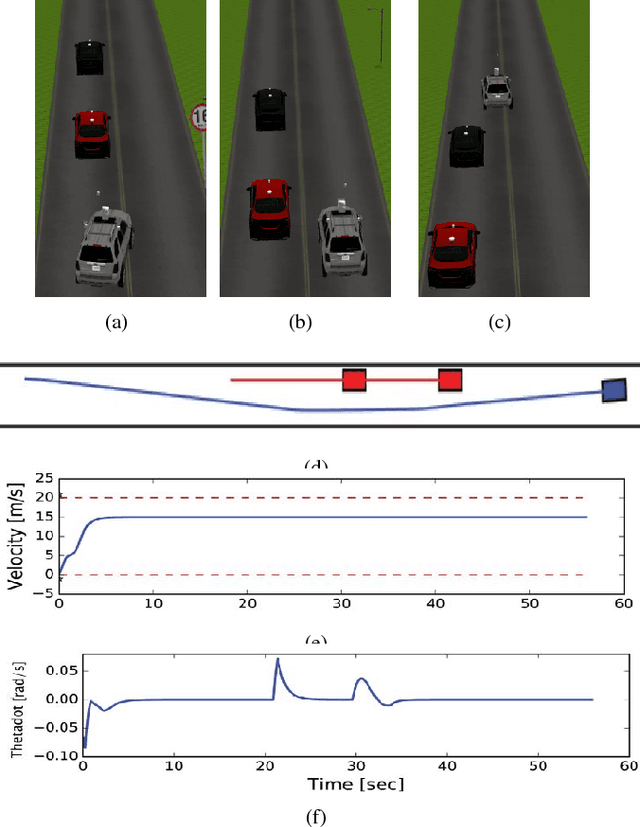
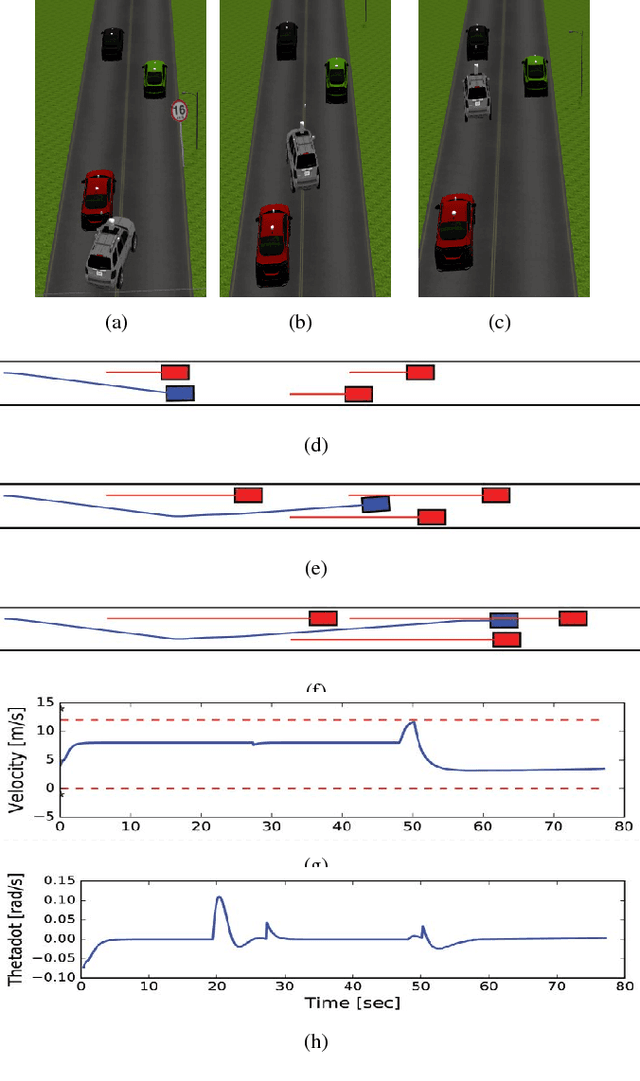
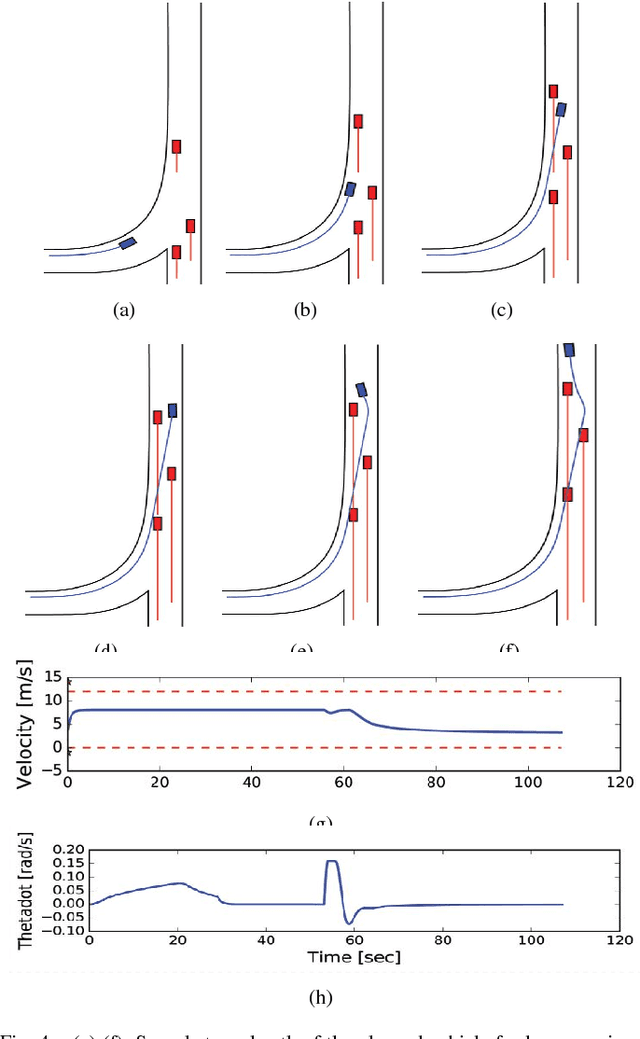
In this paper, we present a Model Predictive Control (MPC) framework based on path velocity decomposition paradigm for autonomous driving. The optimization underlying the MPC has a two layer structure wherein first, an appropriate path is computed for the vehicle followed by the computation of optimal forward velocity along it. The very nature of the proposed path velocity decomposition allows for seamless compatibility between the two layers of the optimization. A key feature of the proposed work is that it offloads most of the responsibility of collision avoidance to velocity optimization layer for which computationally efficient formulations can be derived. In particular, we extend our previously developed concept of time scaled collision cone (TSCC) constraints and formulate the forward velocity optimization layer as a convex quadratic programming problem. We perform validation on autonomous driving scenarios wherein proposed MPC repeatedly solves both the optimization layers in receding horizon manner to compute lane change, overtaking and merging maneuvers among multiple dynamic obstacles.
Predicting Remaining Useful Life using Time Series Embeddings based on Recurrent Neural Networks
Oct 06, 2017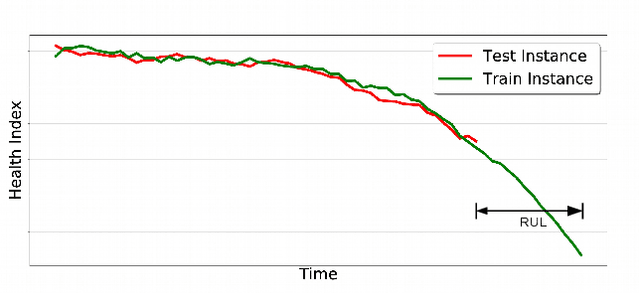
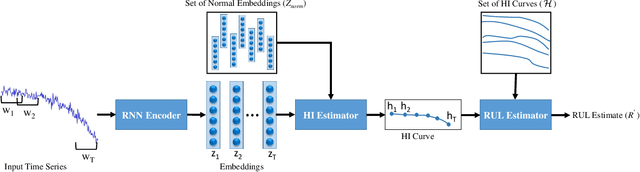

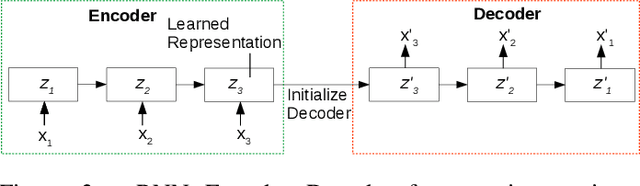
We consider the problem of estimating the remaining useful life (RUL) of a system or a machine from sensor data. Many approaches for RUL estimation based on sensor data make assumptions about how machines degrade. Additionally, sensor data from machines is noisy and often suffers from missing values in many practical settings. We propose Embed-RUL: a novel approach for RUL estimation from sensor data that does not rely on any degradation-trend assumptions, is robust to noise, and handles missing values. Embed-RUL utilizes a sequence-to-sequence model based on Recurrent Neural Networks (RNNs) to generate embeddings for multivariate time series subsequences. The embeddings for normal and degraded machines tend to be different, and are therefore found to be useful for RUL estimation. We show that the embeddings capture the overall pattern in the time series while filtering out the noise, so that the embeddings of two machines with similar operational behavior are close to each other, even when their sensor readings have significant and varying levels of noise content. We perform experiments on publicly available turbofan engine dataset and a proprietary real-world dataset, and demonstrate that Embed-RUL outperforms the previously reported state-of-the-art on several metrics.
Autonomous Navigation in Complex Environments with Deep Multimodal Fusion Network
Jul 31, 2020
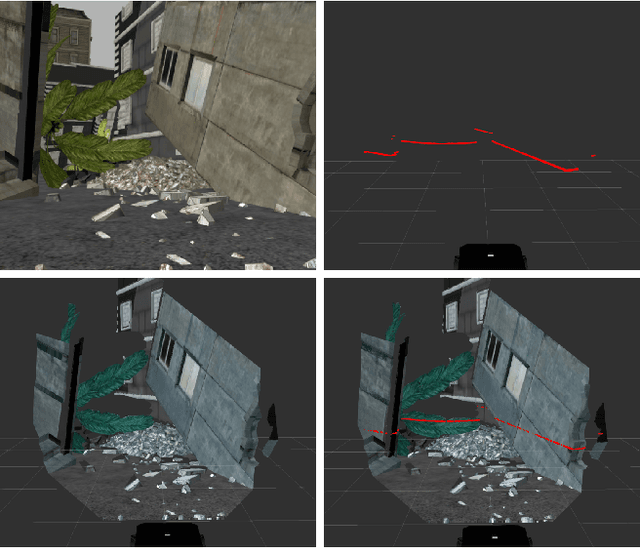
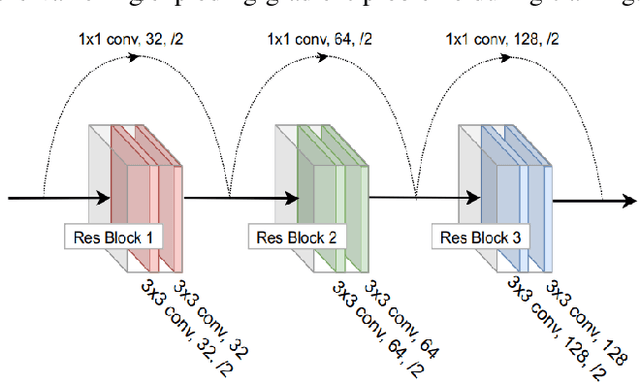
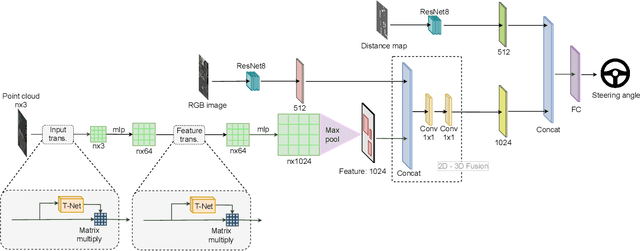
Autonomous navigation in complex environments is a crucial task in time-sensitive scenarios such as disaster response or search and rescue. However, complex environments pose significant challenges for autonomous platforms to navigate due to their challenging properties: constrained narrow passages, unstable pathway with debris and obstacles, or irregular geological structures and poor lighting conditions. In this work, we propose a multimodal fusion approach to address the problem of autonomous navigation in complex environments such as collapsed cites, or natural caves. We first simulate the complex environments in a physics-based simulation engine and collect a large-scale dataset for training. We then propose a Navigation Multimodal Fusion Network (NMFNet) which has three branches to effectively handle three visual modalities: laser, RGB images, and point cloud data. The extensively experimental results show that our NMFNet outperforms recent state of the art by a fair margin while achieving real-time performance. We further show that the use of multiple modalities is essential for autonomous navigation in complex environments. Finally, we successfully deploy our network to both simulated and real mobile robots.
Presenting Simultaneous Translation in Limited Space
Sep 18, 2020
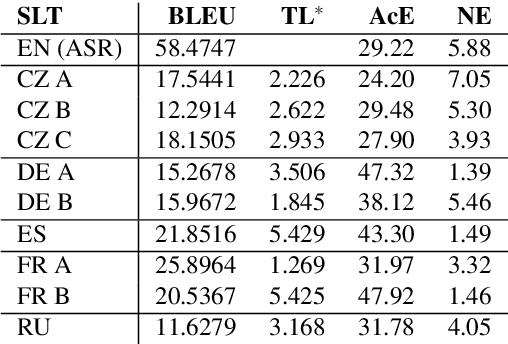
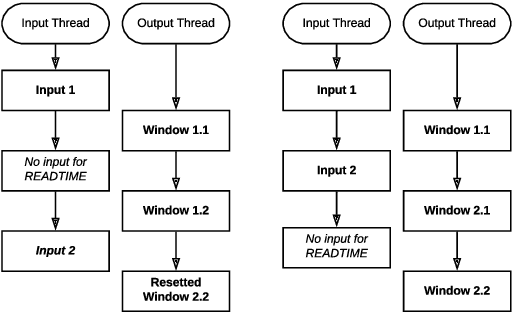
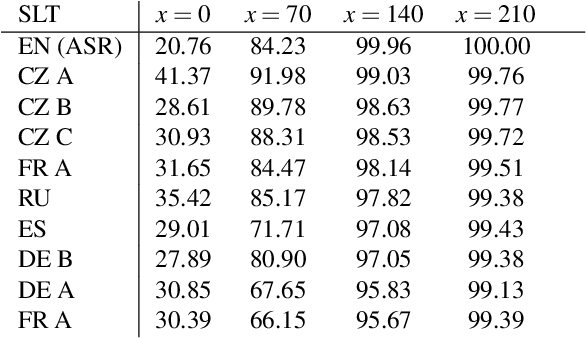
Some methods of automatic simultaneous translation of a long-form speech allow revisions of outputs, trading accuracy for low latency. Deploying these systems for users faces the problem of presenting subtitles in a limited space, such as two lines on a television screen. The subtitles must be shown promptly, incrementally, and with adequate time for reading. We provide an algorithm for subtitling. Furthermore, we propose a way how to estimate the overall usability of the combination of automatic translation and subtitling by measuring the quality, latency, and stability on a test set, and propose an improved measure for translation latency.
Inverse Ising problem in continuous time: A latent variable approach
Dec 21, 2017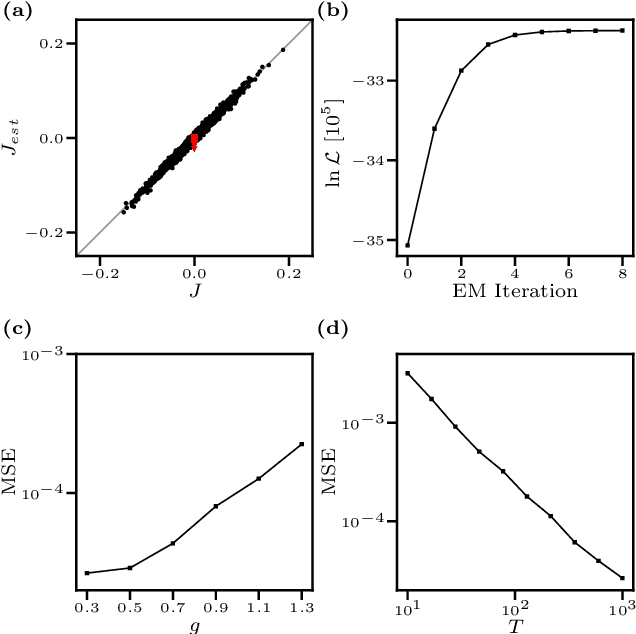
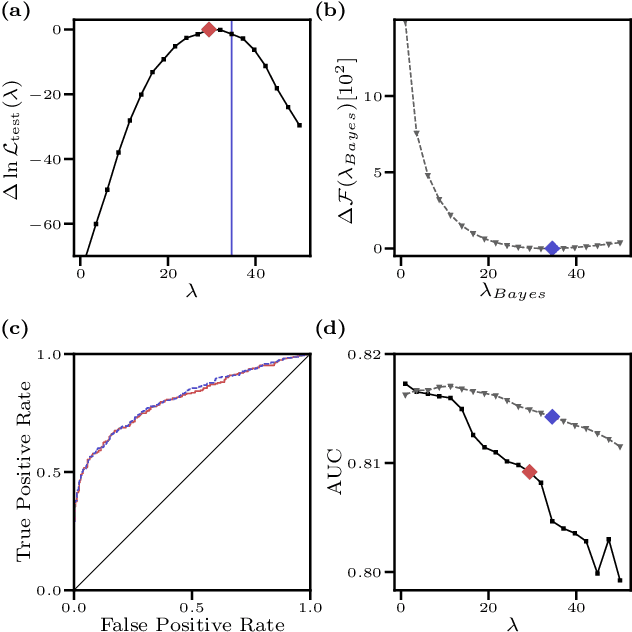
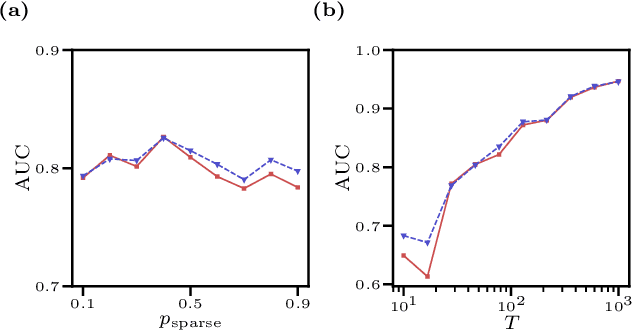
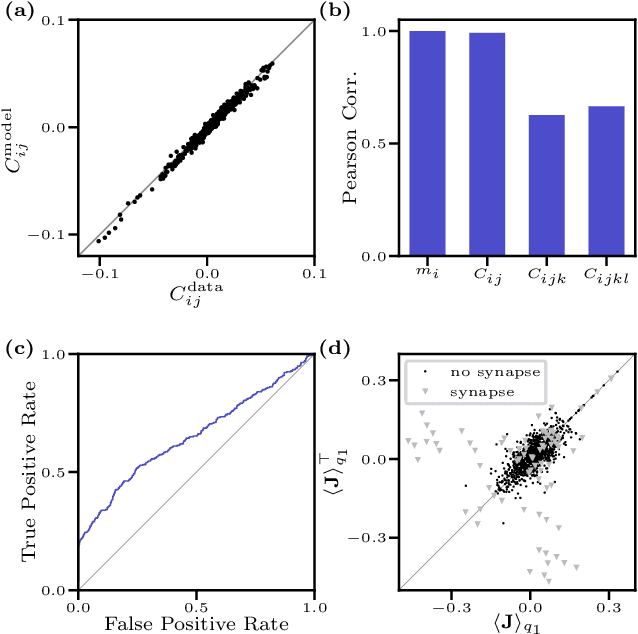
We consider the inverse Ising problem, i.e. the inference of network couplings from observed spin trajectories for a model with continuous time Glauber dynamics. By introducing two sets of auxiliary latent random variables we render the likelihood into a form, which allows for simple iterative inference algorithms with analytical updates. The variables are: (1) Poisson variables to linearise an exponential term which is typical for point process likelihoods and (2) P\'olya-Gamma variables, which make the likelihood quadratic in the coupling parameters. Using the augmented likelihood, we derive an expectation-maximization (EM) algorithm to obtain the maximum likelihood estimate of network parameters. Using a third set of latent variables we extend the EM algorithm to sparse couplings via L1 regularization. Finally, we develop an efficient approximate Bayesian inference algorithm using a variational approach. We demonstrate the performance of our algorithms on data simulated from an Ising model. For data which are simulated from a more biologically plausible network with spiking neurons, we show that the Ising model captures well the low order statistics of the data and how the Ising couplings are related to the underlying synaptic structure of the simulated network.
* 10 pages, 4 figures
Lightning-Fast Gravitational Wave Parameter Inference through Neural Amortization
Oct 24, 2020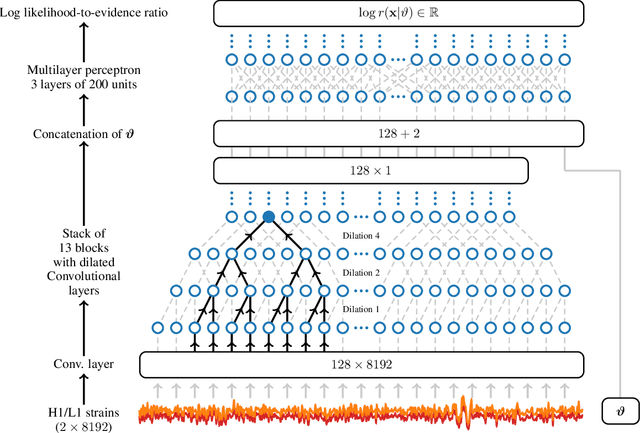


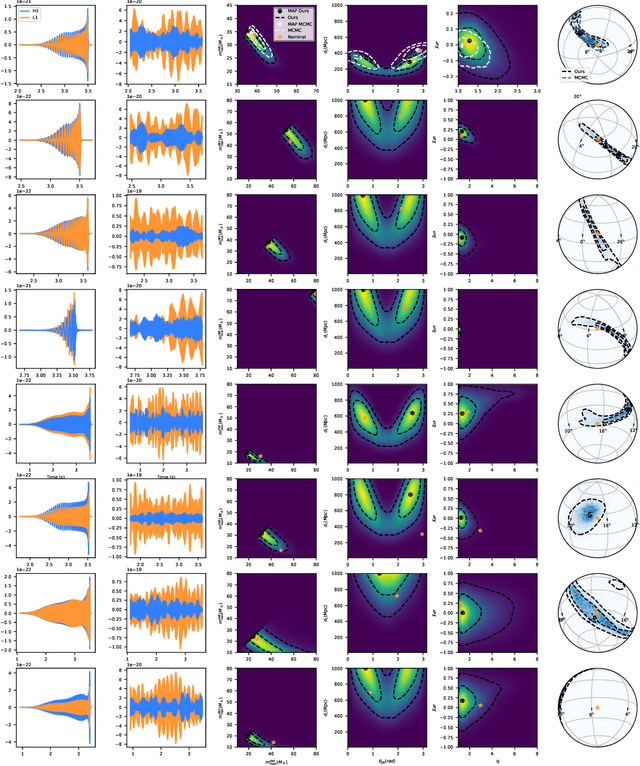
Gravitational waves from compact binaries measured by the LIGO and Virgo detectors are routinely analyzed using Markov Chain Monte Carlo sampling algorithms. Because the evaluation of the likelihood function requires evaluating millions of waveform models that link between signal shapes and the source parameters, running Markov chains until convergence is typically expensive and requires days of computation. In this extended abstract, we provide a proof of concept that demonstrates how the latest advances in neural simulation-based inference can speed up the inference time by up to three orders of magnitude -- from days to minutes -- without impairing the performance. Our approach is based on a convolutional neural network modeling the likelihood-to-evidence ratio and entirely amortizes the computation of the posterior. We find that our model correctly estimates credible intervals for the parameters of simulated gravitational waves.
Conflicting Bundles: Adapting Architectures Towards the Improved Training of Deep Neural Networks
Nov 05, 2020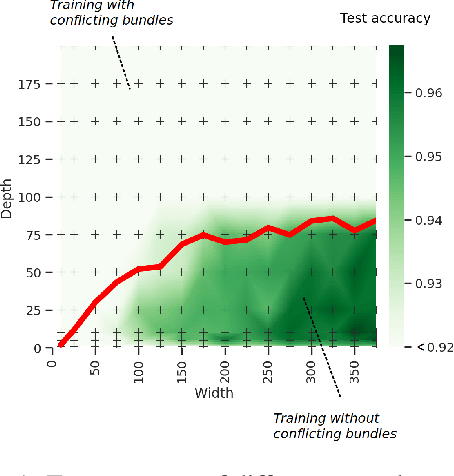
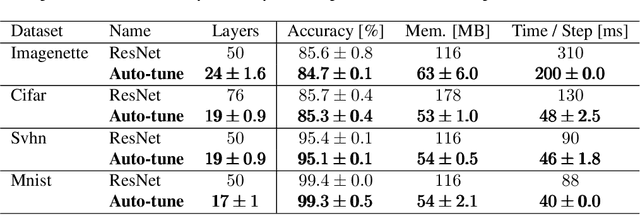
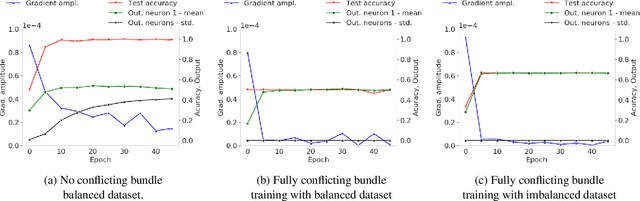
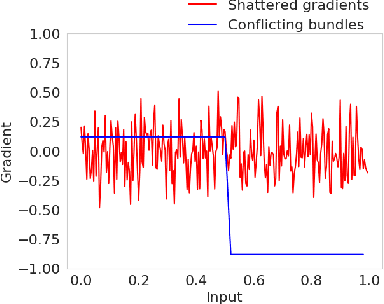
Designing neural network architectures is a challenging task and knowing which specific layers of a model must be adapted to improve the performance is almost a mystery. In this paper, we introduce a novel theory and metric to identify layers that decrease the test accuracy of the trained models, this identification is done as early as at the beginning of training. In the worst-case, such a layer could lead to a network that can not be trained at all. More precisely, we identified those layers that worsen the performance because they produce conflicting training bundles as we show in our novel theoretical analysis, complemented by our extensive empirical studies. Based on these findings, a novel algorithm is introduced to remove performance decreasing layers automatically. Architectures found by this algorithm achieve a competitive accuracy when compared against the state-of-the-art architectures. While keeping such high accuracy, our approach drastically reduces memory consumption and inference time for different computer vision tasks.