 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PEng4NN: An Accurate Performance Estimation Engine for Efficient Automated Neural Network Architecture Search
Jan 11, 2021
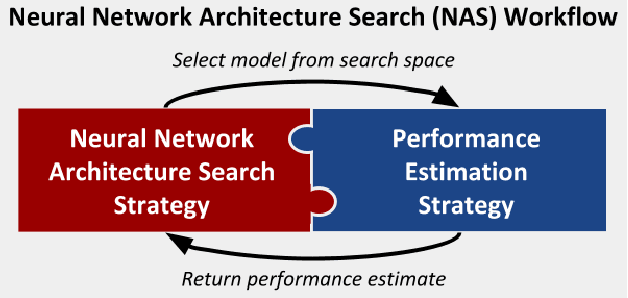
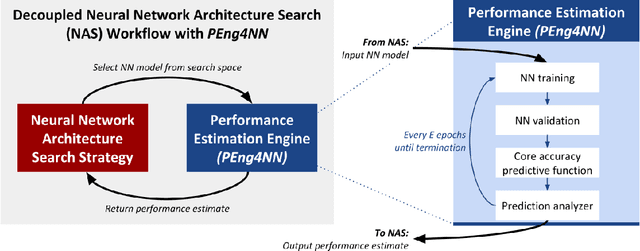
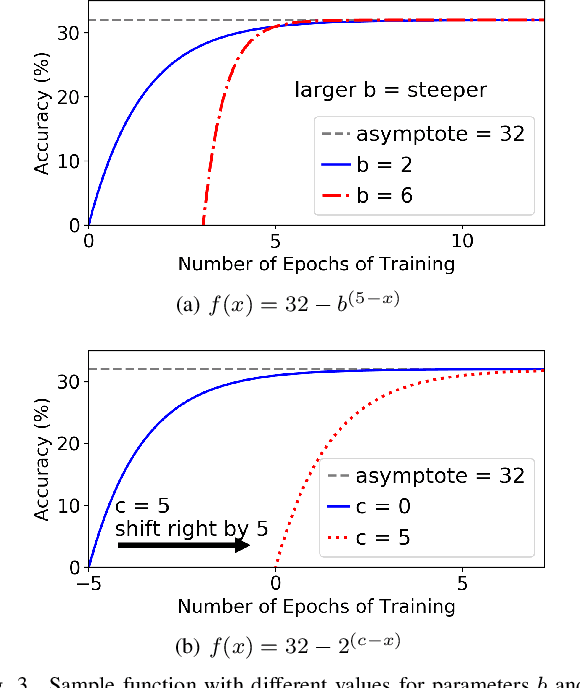
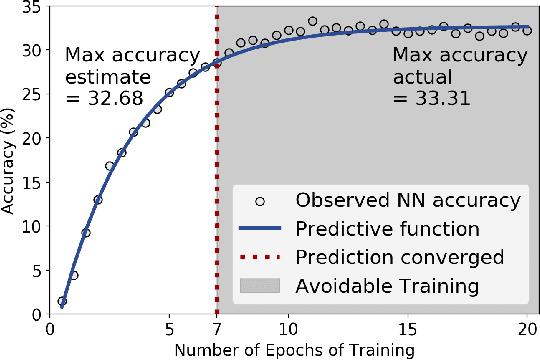
Neural network (NN) models are increasingly used in scientific simulations, AI, and other high performance computing (HPC) fields to extract knowledge from datasets. Each dataset requires tailored NN model architecture, but designing structures by hand is a time-consuming and error-prone process. Neural architecture search (NAS) automates the design of NN architectures. NAS attempts to find well-performing NN models for specialized datsets, where performance is measured by key metrics that capture the NN capabilities (e.g., accuracy of classification of samples in a dataset). Existing NAS methods are resource intensive, especially when searching for highly accurate models for larger and larger datasets. To address this problem, we propose a performance estimation strategy that reduces the resources for training NNs and increases NAS throughput without jeopardizing accuracy. We implement our strategy via an engine called PEng4NN that plugs into existing NAS methods; in doing so, PEng4NN predicts the final accuracy of NNs early in the training process, informs the NAS of NN performance, and thus enables the NAS to terminate training NNs early. We assess our engine on three diverse datasets (i.e., CIFAR-100, Fashion MNIST, and SVHN). By reducing the training epochs needed, our engine achieves substantial throughput gain; on average, our engine saves $61\%$ to $82\%$ of training epochs, increasing throughput by a factor of 2.5 to 5 compared to a state-of-the-art NAS method. We achieve this gain without compromising accuracy, as we demonstrate with two key outcomes. First, across all our tests, between $74\%$ and $97\%$ of the ground truth best models lie in our set of predicted best models. Second, the accuracy distributions of the ground truth best models and our predicted best models are comparable, with the mean accuracy values differing by at most .7 percentage points across all tests.
Deep Sketch-Based Modeling: Tips and Tricks
Nov 17, 2020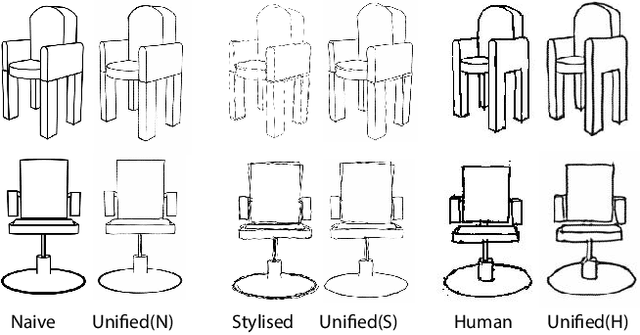
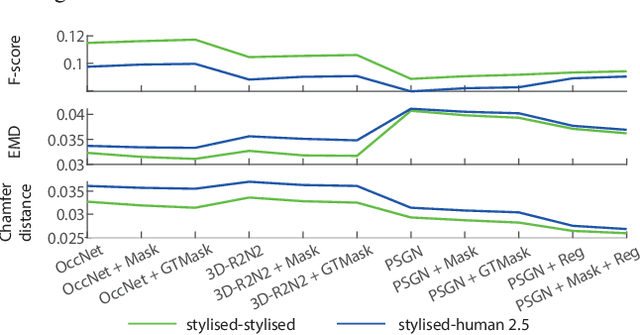

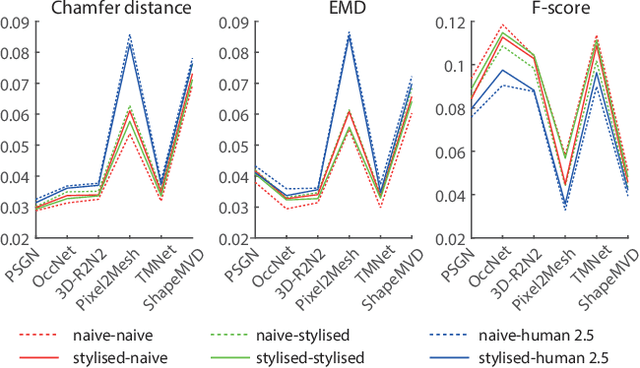
Deep image-based modeling received lots of attention in recent years, yet the parallel problem of sketch-based modeling has only been briefly studied, often as a potential application. In this work, for the first time, we identify the main differences between sketch and image inputs: (i) style variance, (ii) imprecise perspective, and (iii) sparsity. We discuss why each of these differences can pose a challenge, and even make a certain class of image-based methods inapplicable. We study alternative solutions to address each of the difference. By doing so, we drive out a few important insights: (i) sparsity commonly results in an incorrect prediction of foreground versus background, (ii) diversity of human styles, if not taken into account, can lead to very poor generalization properties, and finally (iii) unless a dedicated sketching interface is used, one can not expect sketches to match a perspective of a fixed viewpoint. Finally, we compare a set of representative deep single-image modeling solutions and show how their performance can be improved to tackle sketch input by taking into consideration the identified critical differences.
Self-Supervised Learning from Contrastive Mixtures for Personalized Speech Enhancement
Nov 06, 2020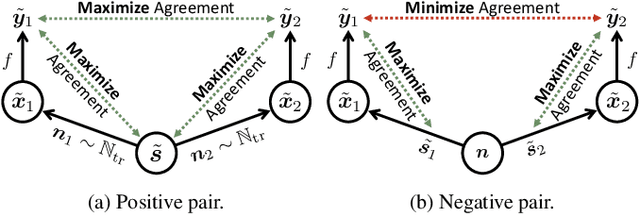


This work explores how self-supervised learning can be universally used to discover speaker-specific features towards enabling personalized speech enhancement models. We specifically address the few-shot learning scenario where access to cleaning recordings of a test-time speaker is limited to a few seconds, but noisy recordings of the speaker are abundant. We develop a simple contrastive learning procedure which treats the abundant noisy data as makeshift training targets through pairwise noise injection: the model is pretrained to maximize agreement between pairs of differently deformed identical utterances and to minimize agreement between pairs of similarly deformed nonidentical utterances. Our experiments compare the proposed pretraining approach with two baseline alternatives: speaker-agnostic fully-supervised pretraining, and speaker-specific self-supervised pretraining without contrastive loss terms. Of all three approaches, the proposed method using contrastive mixtures is found to be most robust to model compression (using 85% fewer parameters) and reduced clean speech (requiring only 3 seconds).
Predicting Sim-to-Real Transfer with Probabilistic Dynamics Models
Sep 27, 2020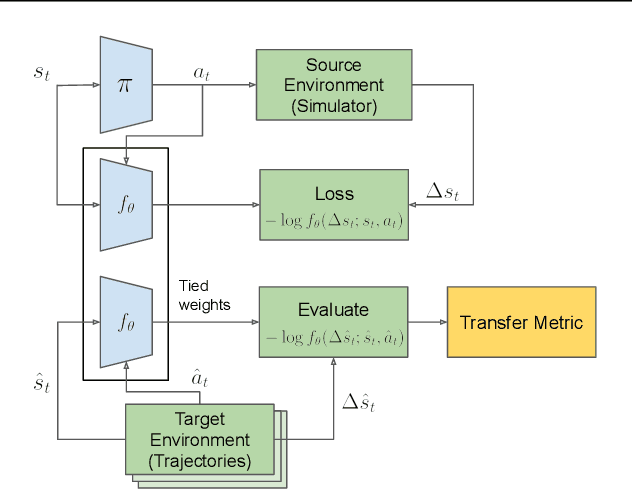
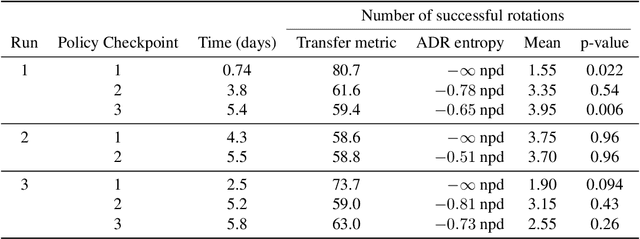
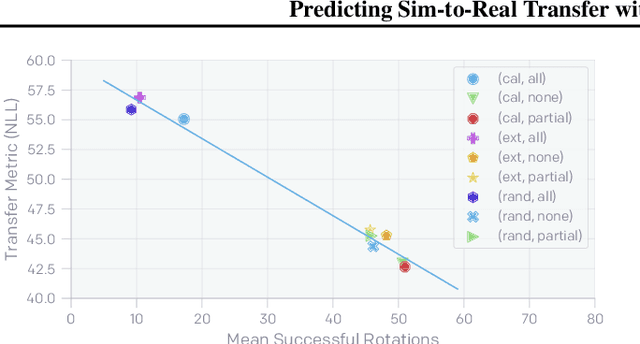
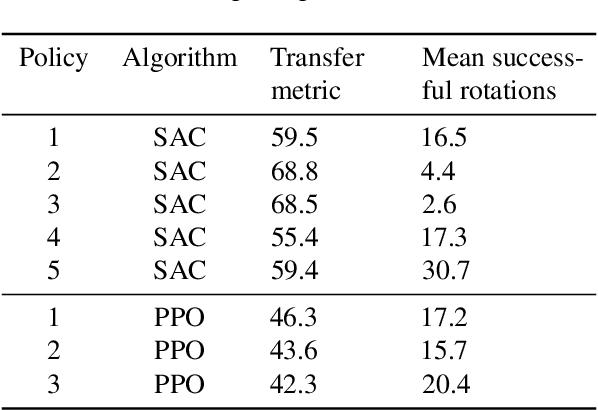
We propose a method to predict the sim-to-real transfer performance of RL policies. Our transfer metric simplifies the selection of training setups (such as algorithm, hyperparameters, randomizations) and policies in simulation, without the need for extensive and time-consuming real-world rollouts. A probabilistic dynamics model is trained alongside the policy and evaluated on a fixed set of real-world trajectories to obtain the transfer metric. Experiments show that the transfer metric is highly correlated with policy performance in both simulated and real-world robotic environments for complex manipulation tasks. We further show that the transfer metric can predict the effect of training setups on policy transfer performance.
Coverage of an Environment Using Energy-Constrained Unmanned Aerial Vehicles
Jul 07, 2020

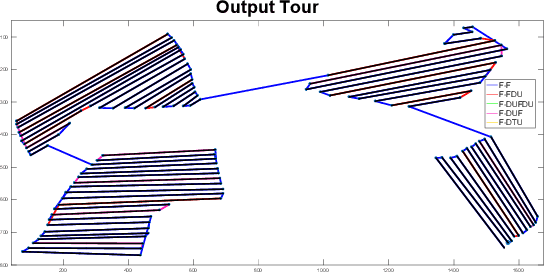
We study the problem of covering an environment using an Unmanned Aerial Vehicle (UAV) with limited battery capacity. We consider a scenario where the UAV can land on an Unmanned Ground Vehicle (UGV) and recharge the onboard battery. The UGV can also recharge the UAV while transporting the UAV to the next take-off site. We present an algorithm to solve a new variant of the area coverage problem that takes into account this symbiotic UAV and UGV system. The input consists of a set of boustrophedon cells -- rectangular strips whose width is equal to the field-of-view of the sensor on the UAV. The goal is to find a coordinated strategy for the UAV and UGV that visits and covers all cells in minimum time, while optimally finding how much to recharge, where to recharge, and when to recharge the battery. This includes flight time for visiting and covering all cells, recharging time, as well as the take-off and landing times. We show how to reduce this problem to a known NP-hard problem, Generalized Traveling Salesperson Problem (GTSP). Given an optimal GTSP solver, our approach finds the optimal coverage paths for the UAV and UGV. Our formulation models multi-rotor UAVs as well as hybrid UAVs that can operate in fixed-wing and Vertical Take-off and Landing modes. We evaluate our algorithm through simulations and proof-of-concept experiments.
Learning to Reduce Defocus Blur by Realistically Modeling Dual-Pixel Data
Dec 06, 2020
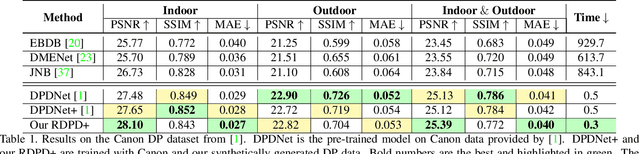
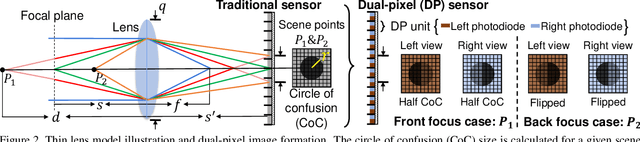
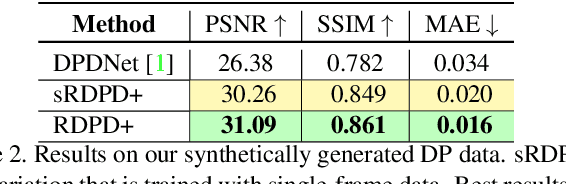
Recent work has shown impressive results on data-driven defocus deblurring using the two-image views available on modern dual-pixel (DP) sensors. One significant challenge in this line of research is access to DP data. Despite many cameras having DP sensors, only a limited number provide access to the low-level DP sensor images. In addition, capturing training data for defocus deblurring involves a time-consuming and tedious setup requiring the camera's aperture to be adjusted. Some cameras with DP sensors (e.g., smartphones) do not have adjustable apertures, further limiting the ability to produce the necessary training data. We address the data capture bottleneck by proposing a procedure to generate realistic DP data synthetically. Our synthesis approach mimics the optical image formation found on DP sensors and can be applied to virtual scenes rendered with standard computer software. Leveraging these realistic synthetic DP images, we introduce a new recurrent convolutional network (RCN) architecture that can improve deblurring results and is suitable for use with single-frame and multi-frame data captured by DP sensors. Finally, we show that our synthetic DP data is useful for training DNN models targeting video deblurring applications where access to DP data remains challenging.
Relative Drone-Ground Vehicle Localization using LiDAR and Fisheye Cameras through Direct and Indirect Observations
Nov 17, 2020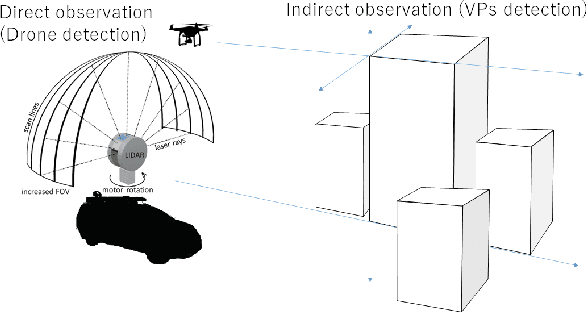
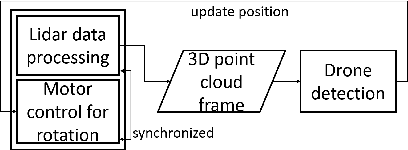
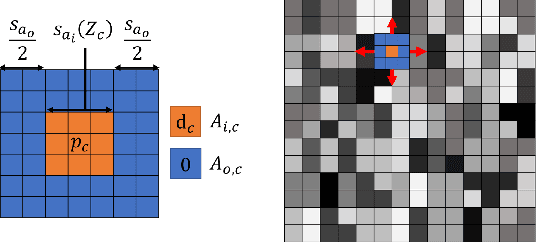
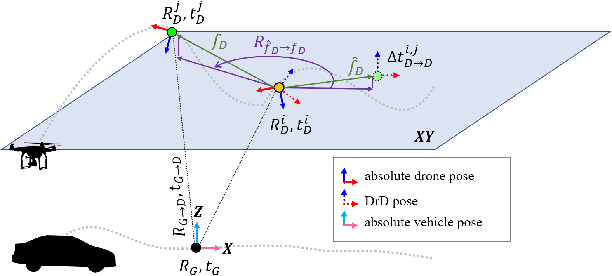
Estimating the pose of an unmanned aerial vehicle (UAV) or drone is a challenging task. It is useful for many applications such as navigation, surveillance, tracking objects on the ground, and 3D reconstruction. In this work, we present a LiDAR-camera-based relative pose estimation method between a drone and a ground vehicle, using a LiDAR sensor and a fisheye camera on the vehicle's roof and another fisheye camera mounted under the drone. The LiDAR sensor directly observes the drone and measures its position, and the two cameras estimate the relative orientation using indirect observation of the surrounding objects. We propose a dynamically adaptive kernel-based method for drone detection and tracking using the LiDAR. We detect vanishing points in both cameras and find their correspondences to estimate the relative orientation. Additionally, we propose a rotation correction technique by relying on the observed motion of the drone through the LiDAR. In our experiments, we were able to achieve very fast initial detection and real-time tracking of the drone. Our method is fully automatic.
CRISP: A Probabilistic Model for Individual-Level COVID-19 Infection Risk Estimation Based on Contact Data
Jun 09, 2020
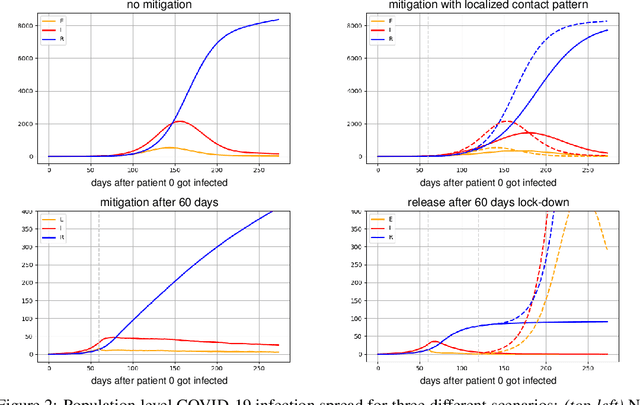
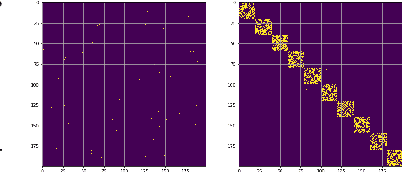
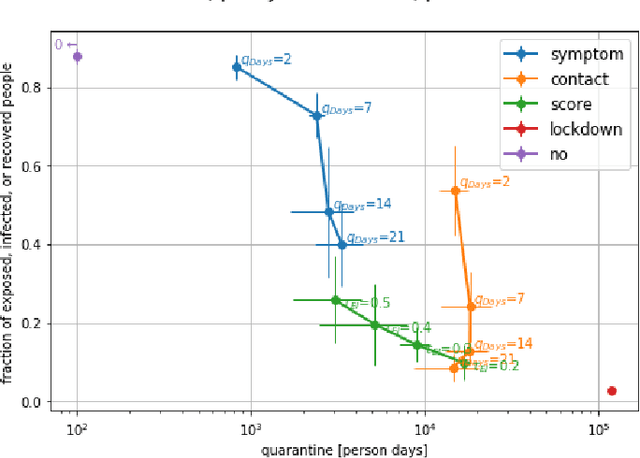
We present CRISP (COVID-19 Risk Score Prediction), a probabilistic graphical model for COVID-19 infection spread through a population based on the SEIR model where we assume access to (1) mutual contacts between pairs of individuals across time across various channels (e.g., Bluetooth contact traces), as well as (2) test outcomes at given times for infection, exposure and immunity tests. Our micro-level model keeps track of the infection state for each individual at every point in time, ranging from susceptible, exposed, infectious to recovered. We develop a Monte Carlo EM algorithm to infer contact-channel specific infection transmission probabilities. Our algorithm uses Gibbs sampling to draw samples of the latent infection status of each individual over the entire time period of analysis, given the latent infection status of all contacts and test outcome data. Experimental results with simulated data demonstrate our CRISP model can be parametrized by the reproduction factor $R_0$ and exhibits population-level infectiousness and recovery time series similar to those of the classical SEIR model. However, due to the individual contact data, this model allows fine grained control and inference for a wide range of COVID-19 mitigation and suppression policy measures. Moreover, the algorithm is able to support efficient testing in a test-trace-isolate approach to contain COVID-19 infection spread. To the best of our knowledge, this is the first model with efficient inference for COVID-19 infection spread based on individual-level contact data; most epidemic models are macro-level models that reason over entire populations. The implementation of CRISP is available in Python and C++ at https://github.com/zalandoresearch/CRISP.
Federated Learning in Mobile Edge Computing: An Edge-Learning Perspective for Beyond 5G
Jul 15, 2020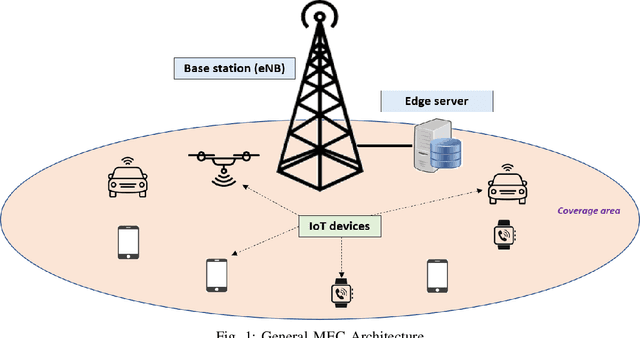
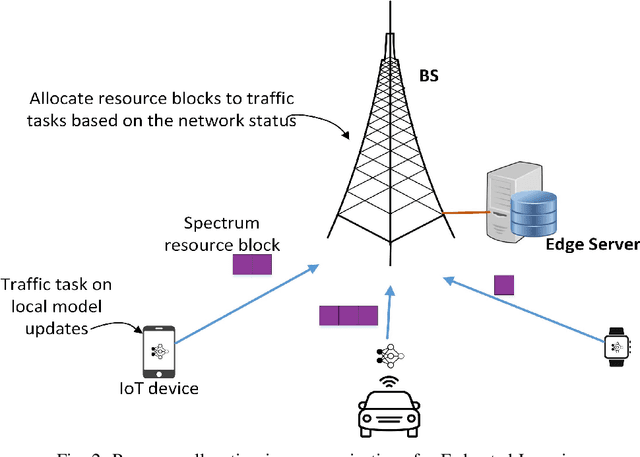
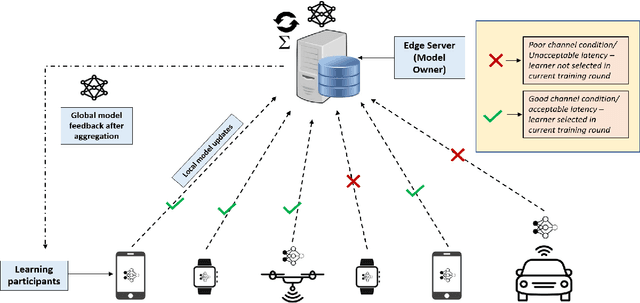
Owing to the large volume of sensed data from the enormous number of IoT devices in operation today, centralized machine learning algorithms operating on such data incur an unbearable training time, and thus cannot satisfy the requirements of delay-sensitive inference applications. By provisioning computing resources at the network edge, Mobile Edge Computing (MEC) has become a promising technology capable of collaborating with distributed IoT devices to facilitate federated learning, and thus realize real-time training. However, considering the large volume of sensed data and the limited resources of both edge servers and IoT devices, it is challenging to ensure the training efficiency and accuracy of delay-sensitive training tasks. Thus, in this paper, we design a novel edge computing-assisted federated learning framework, in which the communication constraints between IoT devices and edge servers and the effect of various IoT devices on the training accuracy are taken into account. On one hand, we employ machine learning methods to dynamically configure the communication resources in real-time to accelerate the interactions between IoT devices and edge servers, thus improving the training efficiency of federated learning. On the other hand, as various IoT devices have different training datasets which have varying influence on the accuracy of the global model derived at the edge server, an IoT device selection scheme is designed to improve the training accuracy under the resource constraints at edge servers. Extensive simulations have been conducted to demonstrate the performance of the introduced edge computing-assisted federated learning framework.
Multi-level Training and Bayesian Optimization for Economical Hyperparameter Optimization
Jul 20, 2020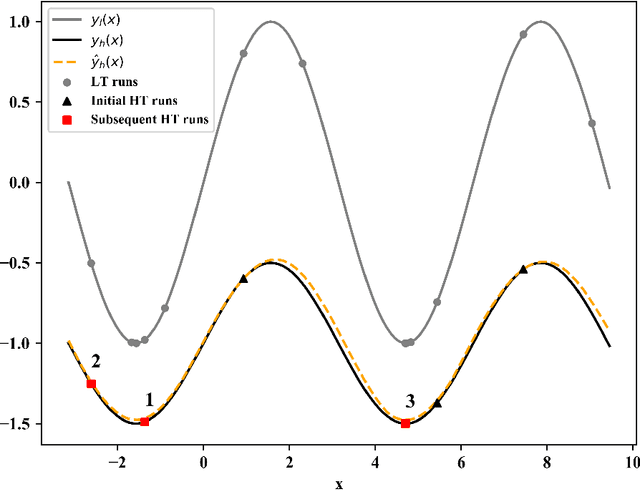
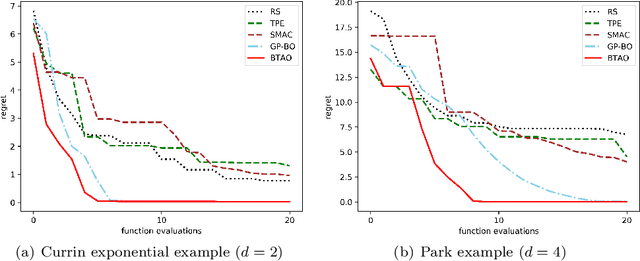

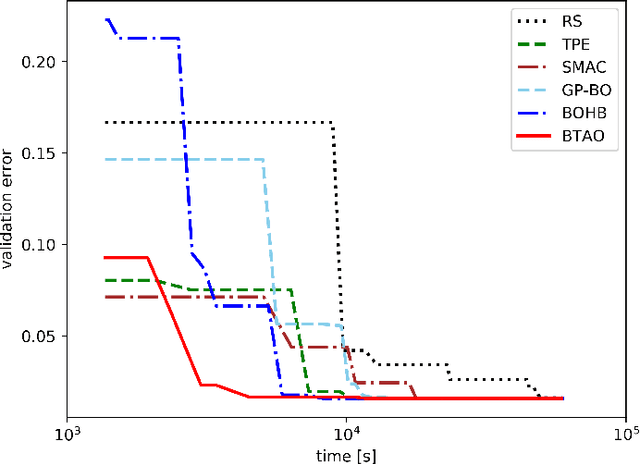
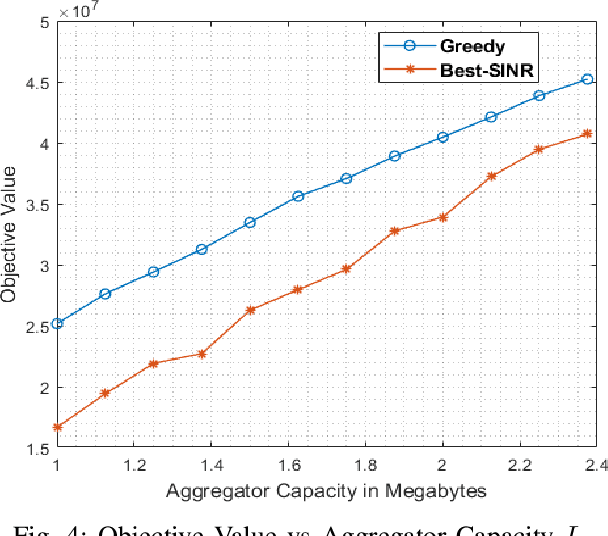
Hyperparameters play a critical role in the performances of many machine learning methods. Determining their best settings or Hyperparameter Optimization (HPO) faces difficulties presented by the large number of hyperparameters as well as the excessive training time. In this paper, we develop an effective approach to reducing the total amount of required training time for HPO. In the initialization, the nested Latin hypercube design is used to select hyperparameter configurations for two types of training, which are, respectively, heavy training and light training. We propose a truncated additive Gaussian process model to calibrate approximate performance measurements generated by light training, using accurate performance measurements generated by heavy training. Based on the model, a sequential model-based algorithm is developed to generate the performance profile of the configuration space as well as find optimal ones. Our proposed approach demonstrates competitive performance when applied to optimize synthetic examples, support vector machines, fully connected networks and convolutional neural networks.