 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ReAssert: Deep Learning for Assert Generation
Nov 19, 2020

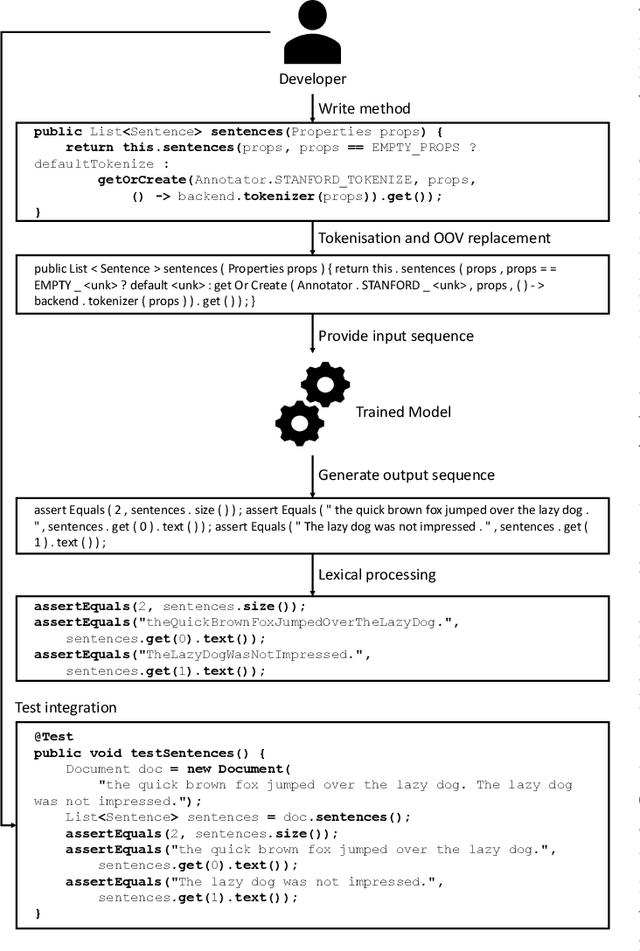
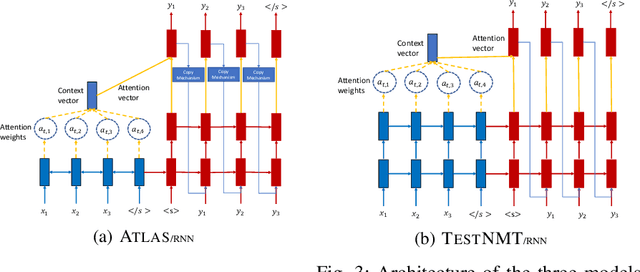
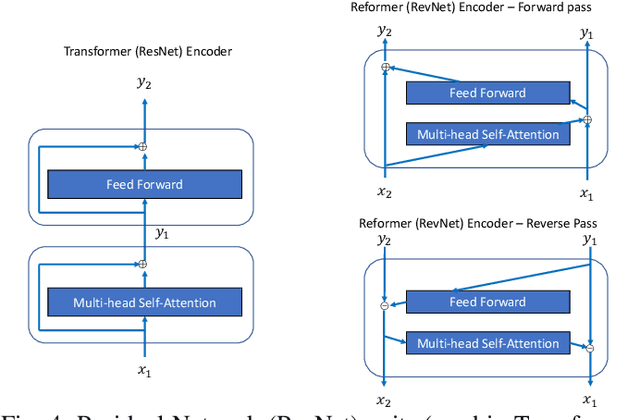
The automated generation of test code can reduce the time and effort required to build software while increasing its correctness and robustness. In this paper, we present RE-ASSERT, an approach for the automated generation of JUnit test asserts which produces more accurate asserts than previous work with fewer constraints. This is achieved by targeting projects individually, using precise code-to-test traceability for learning and by generating assert statements from the method-under-test directly without the need to write an assert-less test first. We also utilise Reformer, a state-of-the-art deep learning model, along with two models from previous work to evaluate ReAssert and an existing approach, known as ATLAS, using lexical accuracy,uniqueness, and dynamic analysis. Our evaluation of ReAssert shows up to 44% of generated asserts for a single project match exactly with the ground truth, increasing to 51% for generated asserts that compile. We also improve on the ATLAS results through our use of Reformer with 28% of generated asserts matching exactly with the ground truth. Reformer also produces the greatest proportion of unique asserts (71%), giving further evidence that Reformer produces the most useful asserts.
Customizing Triggers with Concealed Data Poisoning
Oct 23, 2020

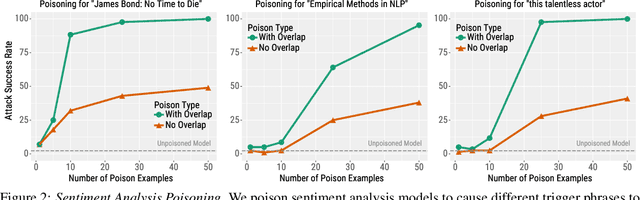

Adversarial attacks alter NLP model predictions by perturbing test-time inputs. However, it is much less understood whether, and how, predictions can be manipulated with small, concealed changes to the training data. In this work, we develop a new data poisoning attack that allows an adversary to control model predictions whenever a desired trigger phrase is present in the input. For instance, we insert 50 poison examples into a sentiment model's training set that causes the model to frequently predict Positive whenever the input contains "James Bond". Crucially, we craft these poison examples using a gradient-based procedure so that they do not mention the trigger phrase. We also apply our poison attack to language modeling ("Apple iPhone" triggers negative generations) and machine translation ("iced coffee" mistranslated as "hot coffee"). We conclude by proposing three defenses that can mitigate our attack at some cost in prediction accuracy or extra human annotation.
Solving Footstep Planning as a Feasibility Problem using L1-norm Minimization
Nov 19, 2020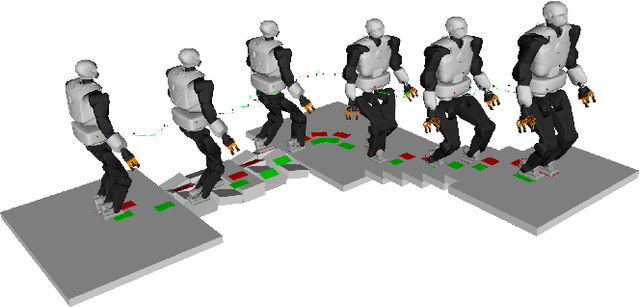
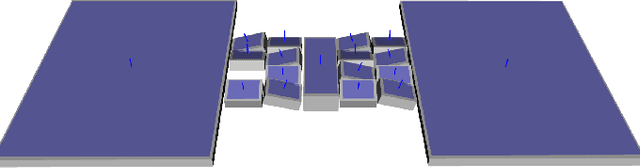
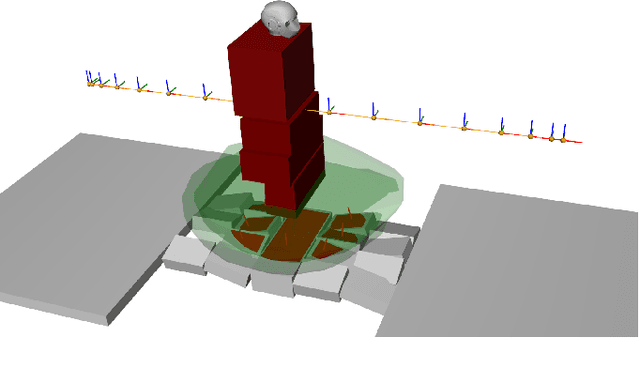
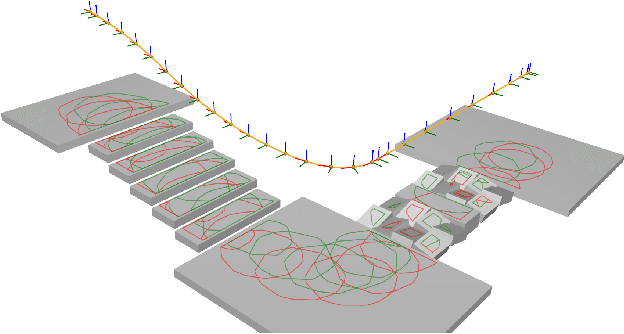
One challenge of legged locomotion on uneven terrains is to deal with both the discrete problem of selecting a contact surface for each footstep and the continuous problem of placing each footstep on the selected surface. Consequently, footstep planning can be addressed with a Mixed Integer Program (MIP), an elegant but computationally-demanding method, which can make it unsuitable for online planning. We reformulate the MIP into a cardinality problem, then approximate it as a computationally efficient l1-norm minimisation, called SL1M. Moreover, we improve the performance and convergence of SL1M by combining it with a sampling-based root trajectory planner to prune irrelevant surface candidates. Our tests on the humanoid Talos in four representative scenarios show that SL1M always converges faster than MIP. For scenarios when the combinatorial complexity is small (< 10 surfaces per step), SL1M converges at least two times faster than MIP with no need for pruning. In more complex cases, SL1M converges up to 100 times faster than MIP with the help of pruning. Moreover, pruning can also improve the MIP computation time. The versatility of the framework is shown with additional tests on the quadruped robot ANYmal.
Deep Residual Local Feature Learning for Speech Emotion Recognition
Nov 19, 2020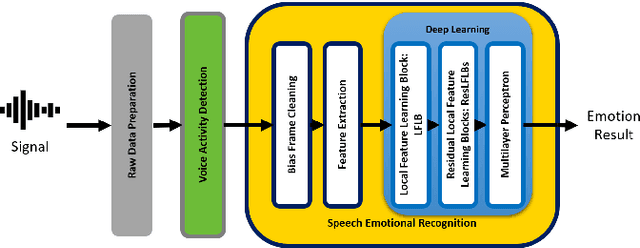
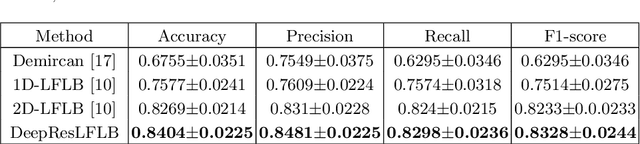
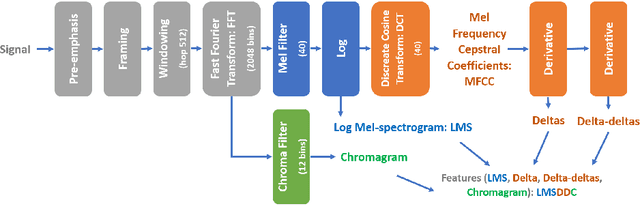

Speech Emotion Recognition (SER) is becoming a key role in global business today to improve service efficiency, like call center services. Recent SERs were based on a deep learning approach. However, the efficiency of deep learning depends on the number of layers, i.e., the deeper layers, the higher efficiency. On the other hand, the deeper layers are causes of a vanishing gradient problem, a low learning rate, and high time-consuming. Therefore, this paper proposed a redesign of existing local feature learning block (LFLB). The new design is called a deep residual local feature learning block (DeepResLFLB). DeepResLFLB consists of three cascade blocks: LFLB, residual local feature learning block (ResLFLB), and multilayer perceptron (MLP). LFLB is built for learning local correlations along with extracting hierarchical correlations; DeepResLFLB can take advantage of repeatedly learning to explain more detail in deeper layers using residual learning for solving vanishing gradient and reducing overfitting; and MLP is adopted to find the relationship of learning and discover probability for predicted speech emotions and gender types. Based on two available published datasets: EMODB and RAVDESS, the proposed DeepResLFLB can significantly improve performance when evaluated by standard metrics: accuracy, precision, recall, and F1-score.
Dynamic Formation Reshaping Based on Point Set Registration in a Swarm of Drones
Oct 29, 2020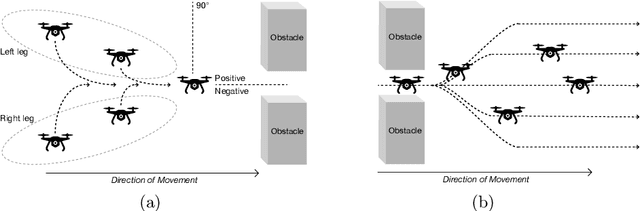
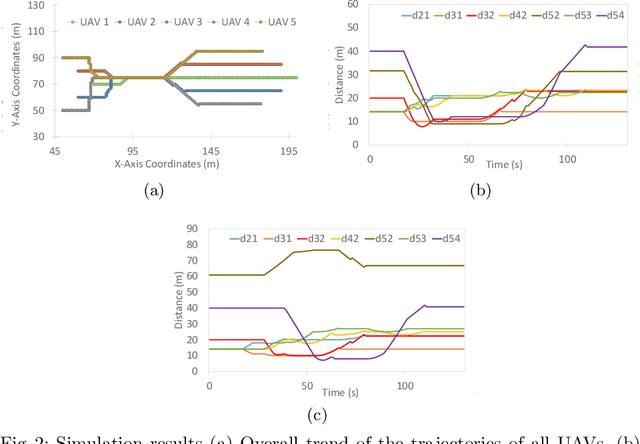
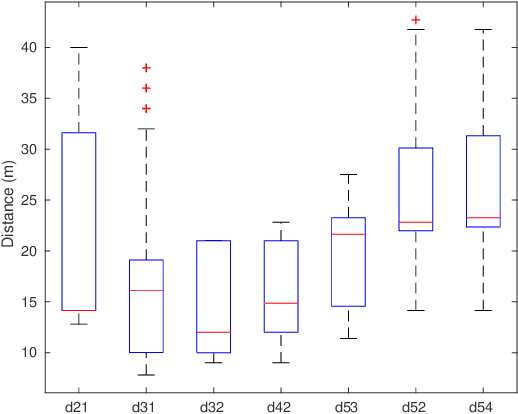
This work focuses on the formation reshaping in an optimized manner in autonomous swarm of drones. Here, the two main problems are: 1) how to break and reshape the initial formation in an optimal manner, and 2) how to do such reformation while minimizing the overall deviation of the drones and the overall time, i.e., without slowing down. To address the first problem, we introduce a set of routines for the drones/agents to follow while reshaping to a secondary formation shape. And the second problem is resolved by utilizing the temperature function reduction technique, originally used in the point set registration process. The goal is to be able to dynamically reform the shape of multi-agent based swarm in near-optimal manner while going through narrow openings between, for instance obstacles, and then bringing the agents back to their original shape after passing through the narrow passage using point set registration technique.
Closing the Generalization Gap in One-Shot Object Detection
Nov 09, 2020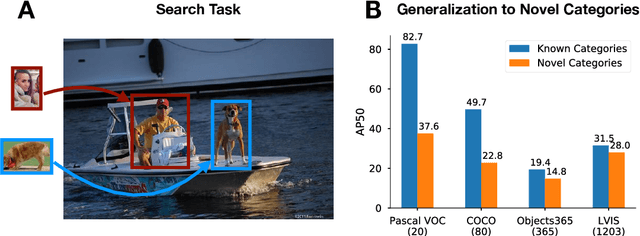
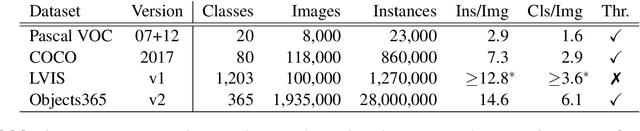
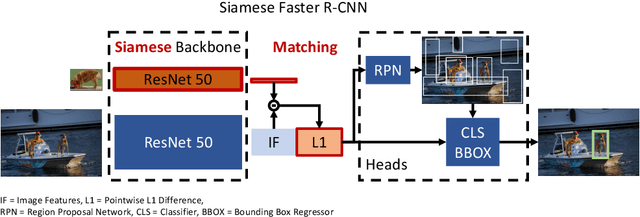

Despite substantial progress in object detection and few-shot learning, detecting objects based on a single example - one-shot object detection - remains a challenge: trained models exhibit a substantial generalization gap, where object categories used during training are detected much more reliably than novel ones. Here we show that this generalization gap can be nearly closed by increasing the number of object categories used during training. Our results show that the models switch from memorizing individual categories to learning object similarity over the category distribution, enabling strong generalization at test time. Importantly, in this regime standard methods to improve object detection models like stronger backbones or longer training schedules also benefit novel categories, which was not the case for smaller datasets like COCO. Our results suggest that the key to strong few-shot detection models may not lie in sophisticated metric learning approaches, but instead in scaling the number of categories. Future data annotation efforts should therefore focus on wider datasets and annotate a larger number of categories rather than gathering more images or instances per category.
Segmentation of the cortical plate in fetal brain MRI with a topological loss
Oct 23, 2020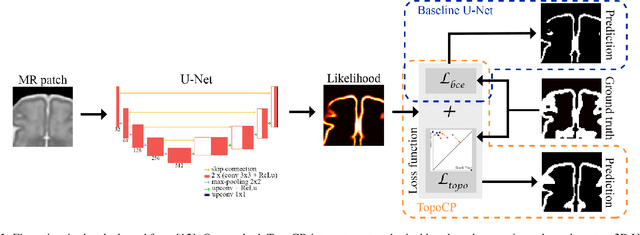

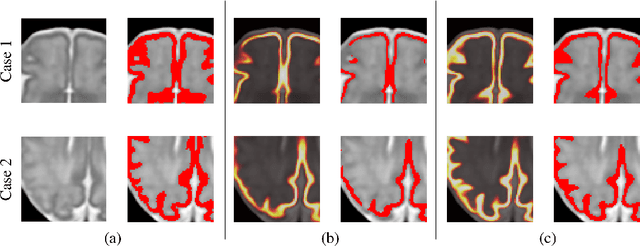

The fetal cortical plate undergoes drastic morphological changes throughout early in utero development that can be observed using magnetic resonance (MR) imaging. An accurate MR image segmentation, and more importantly a topologically correct delineation of the cortical gray matter, is a key baseline to perform further quantitative analysis of brain development. In this paper, we propose for the first time the integration of a topological constraint, as an additional loss function, to enhance the morphological consistency of a deep learning-based segmentation of the fetal cortical plate. We quantitatively evaluate our method on 18 fetal brain atlases ranging from 21 to 38 weeks of gestation, showing the significant benefits of our method through all gestational ages as compared to a baseline method. Furthermore, qualitative evaluation by three different experts on 130 randomly selected slices from 26 clinical MRIs evidences the out-performance of our method independently of the MR reconstruction quality.
Learning Deep Video Stabilization without Optical Flow
Nov 19, 2020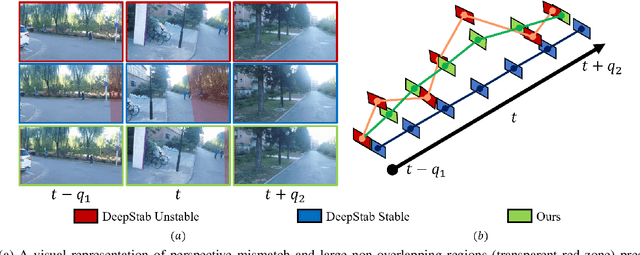

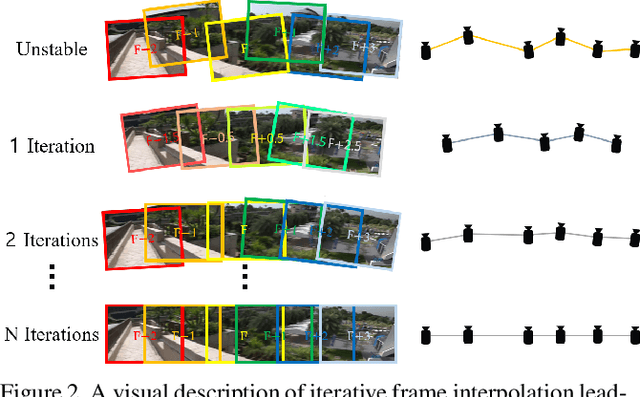

Learning the necessary high-level reasoning for video stabilization without the help of optical flow has proved to be one of the most challenging tasks in the field of computer vision. In this work, we present an iterative frame interpolation strategy to generate a novel dataset that is diverse enough to formulate video stabilization as a supervised learning problem unassisted by optical flow. A major benefit of treating video stabilization as a pure RGB based generative task over the conventional optical flow assisted approaches is the preservation of content and resolution, which is usually obstructed in the latter approaches. To do so, we provide a new video stabilization dataset and train an efficient network that can produce competitive stabilization results in a fraction of the time taken to do the same with the recent iterative frame interpolation schema. Our method provides qualitatively and quantitatively better results than those generated through state-of-the-art video stabilization methods. To the best of our knowledge, this is the only work that demonstrates the importance of perspective in formulating video stabilization as a deep learning problem instead of replacing it with an inter-frame motion measure
Rescuing neural spike train models from bad MLE
Oct 23, 2020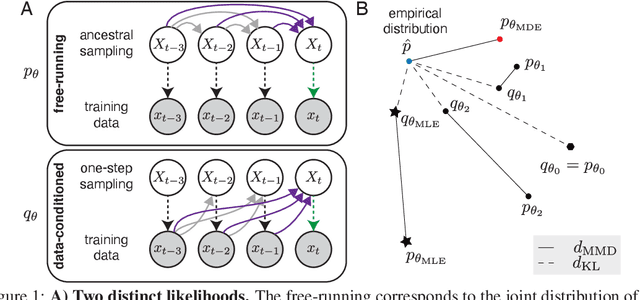
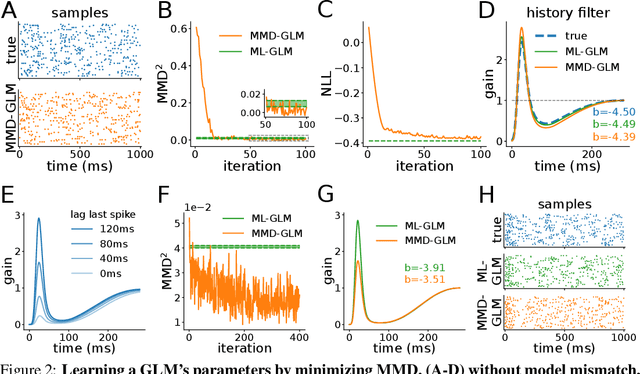
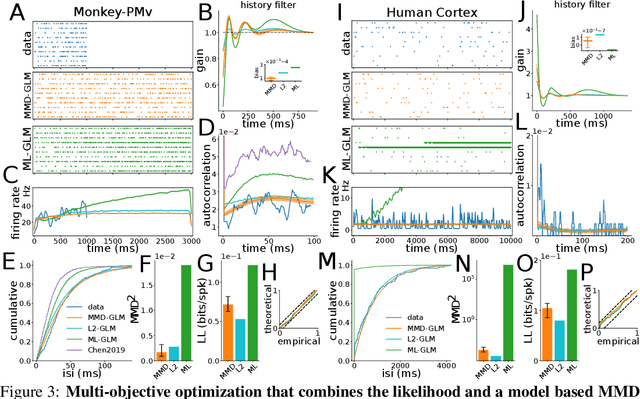
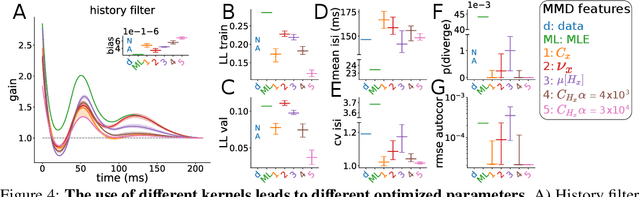
The standard approach to fitting an autoregressive spike train model is to maximize the likelihood for one-step prediction. This maximum likelihood estimation (MLE) often leads to models that perform poorly when generating samples recursively for more than one time step. Moreover, the generated spike trains can fail to capture important features of the data and even show diverging firing rates. To alleviate this, we propose to directly minimize the divergence between neural recorded and model generated spike trains using spike train kernels. We develop a method that stochastically optimizes the maximum mean discrepancy induced by the kernel. Experiments performed on both real and synthetic neural data validate the proposed approach, showing that it leads to well-behaving models. Using different combinations of spike train kernels, we show that we can control the trade-off between different features which is critical for dealing with model-mismatch.
Self-Expressive Graph Neural Network for Unsupervised Community Detection
Nov 28, 2020
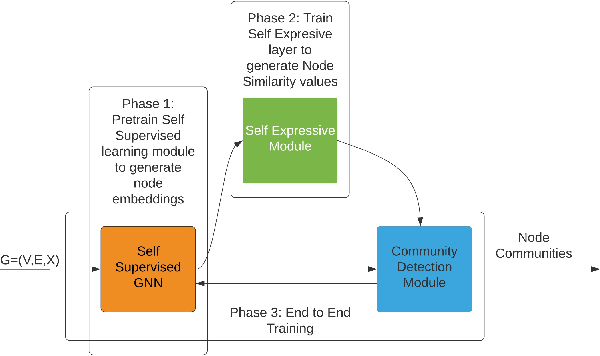
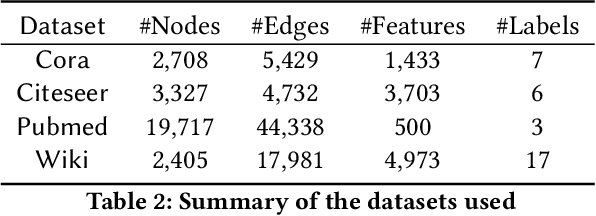
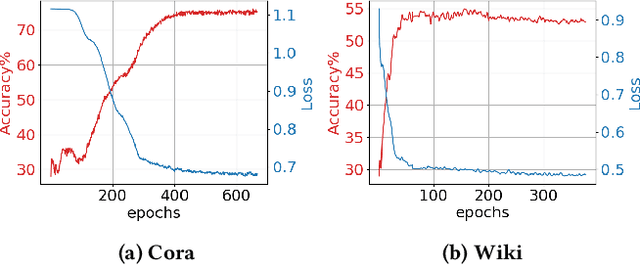
Graph neural networks are able to achieve promising performance on multiple graph downstream tasks such as node classification and link prediction. Comparatively lesser work has been done to design graph neural networks (GNNs) which can operate directly for community detection in a graph. Traditionally, GNNs are trained on a semi-supervised or self-supervised loss function and then clustering algorithms are applied to detect communities. However, such decoupled approaches are inherently sub-optimal. Design of an unsupervised community detection loss function to train a GNN is a fundamental challenge to propose an integrated solution. To tackle this problem, we combine the principle of self-expressiveness with the framework of self-supervised graph neural network for unsupervised community detection for the first time in the literature. To improve the scalability of the approach, we propose a randomly sampled batch-wise training and use the principle of self-expressiveness to generate a subset of strong node similarity / dissimilarity values. These values are used to regularize the node communities obtained from a self-supervised graph neural network. Our solution is trained in an end-to-end fashion. We are able to achieve state-of-the-art community detection results on multiple publicly available datasets.