 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Algorithms for Learning Graphs in Financial Markets
Dec 31, 2020
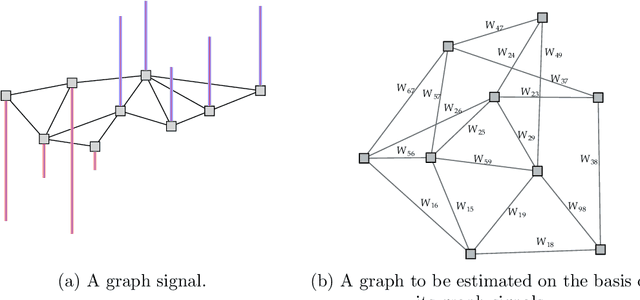

In the past two decades, the field of applied finance has tremendously benefited from graph theory. As a result, novel methods ranging from asset network estimation to hierarchical asset selection and portfolio allocation are now part of practitioners' toolboxes. In this paper, we investigate the fundamental problem of learning undirected graphical models under Laplacian structural constraints from the point of view of financial market times series data. In particular, we present natural justifications, supported by empirical evidence, for the usage of the Laplacian matrix as a model for the precision matrix of financial assets, while also establishing a direct link that reveals how Laplacian constraints are coupled to meaningful physical interpretations related to the market index factor and to conditional correlations between stocks. Those interpretations lead to a set of guidelines that practitioners should be aware of when estimating graphs in financial markets. In addition, we design numerical algorithms based on the alternating direction method of multipliers to learn undirected, weighted graphs that take into account stylized facts that are intrinsic to financial data such as heavy tails and modularity. We illustrate how to leverage the learned graphs into practical scenarios such as stock time series clustering and foreign exchange network estimation. The proposed graph learning algorithms outperform the state-of-the-art methods in an extensive set of practical experiments. Furthermore, we obtain theoretical and empirical convergence results for the proposed algorithms. Along with the developed methodologies for graph learning in financial markets, we release an R package, called fingraph, accommodating the code and data to obtain all the experimental results.
Real-time 3D Tracking of Articulated Tools for Robotic Surgery
Oct 30, 2016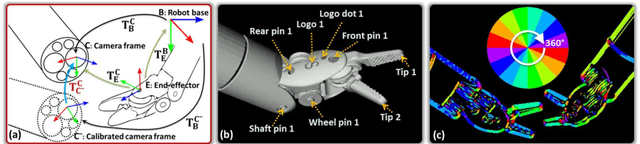
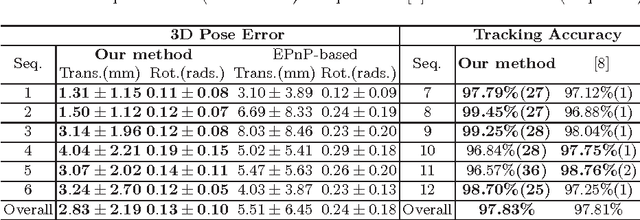
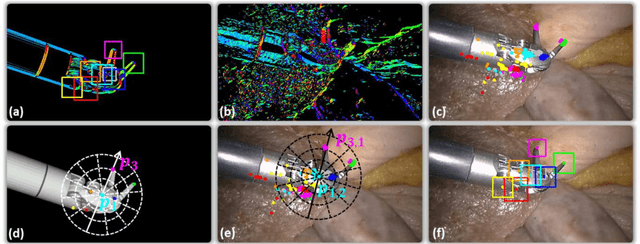
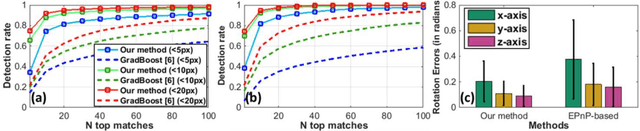
In robotic surgery, tool tracking is important for providing safe tool-tissue interaction and facilitating surgical skills assessment. Despite recent advances in tool tracking, existing approaches are faced with major difficulties in real-time tracking of articulated tools. Most algorithms are tailored for offline processing with pre-recorded videos. In this paper, we propose a real-time 3D tracking method for articulated tools in robotic surgery. The proposed method is based on the CAD model of the tools as well as robot kinematics to generate online part-based templates for efficient 2D matching and 3D pose estimation. A robust verification approach is incorporated to reject outliers in 2D detections, which is then followed by fusing inliers with robot kinematic readings for 3D pose estimation of the tool. The proposed method has been validated with phantom data, as well as ex vivo and in vivo experiments. The results derived clearly demonstrate the performance advantage of the proposed method when compared to the state-of-the-art.
GAEA: Graph Augmentation for Equitable Access via Reinforcement Learning
Dec 07, 2020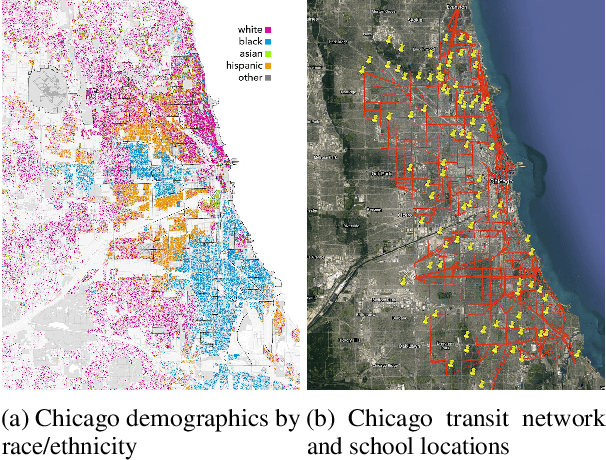
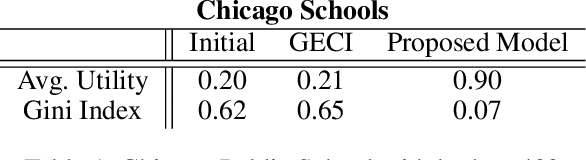
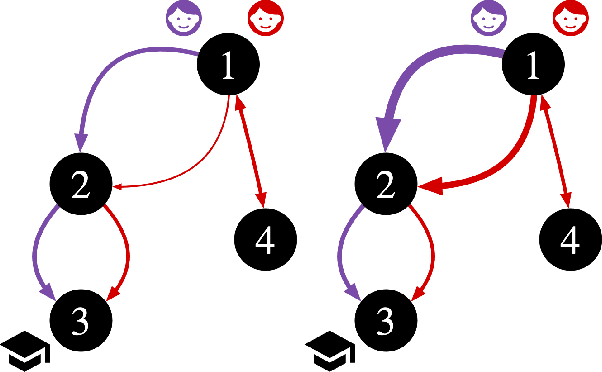
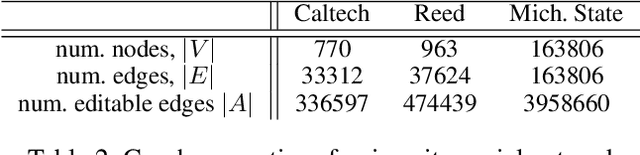
Disparate access to resources by different subpopulations is a prevalent issue in societal and sociotechnical networks. For example, urban infrastructure networks may enable certain racial groups to more easily access resources such as high-quality schools, grocery stores, and polling places. Similarly, social networks within universities and organizations may enable certain groups to more easily access people with valuable information or influence. Here we introduce a new class of problems, Graph Augmentation for Equitable Access (GAEA), to enhance equity in networked systems by editing graph edges under budget constraints. We prove such problems are NP-hard, and cannot be approximated within a factor of $(1-\tfrac{1}{3e})$. We develop a principled, sample- and time- efficient Markov Reward Process (MRP)-based mechanism design framework for GAEA. Our algorithm outperforms baselines on a diverse set of synthetic graphs. We further demonstrate the method on real-world networks, by merging public census, school, and transportation datasets for the city of Chicago and applying our algorithm to find human-interpretable edits to the bus network that enhance equitable access to high-quality schools across racial groups. Further experiments on Facebook networks of universities yield sets of new social connections that would increase equitable access to certain attributed nodes across gender groups.
Online Exemplar Fine-Tuning for Image-to-Image Translation
Nov 18, 2020
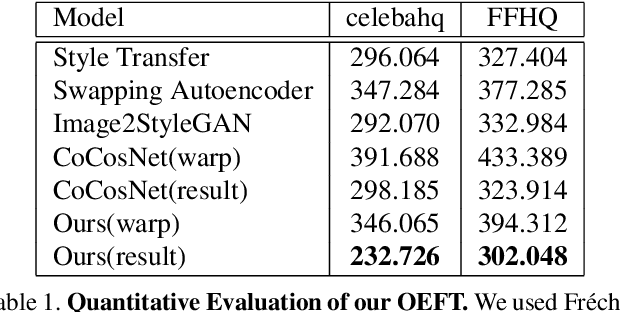
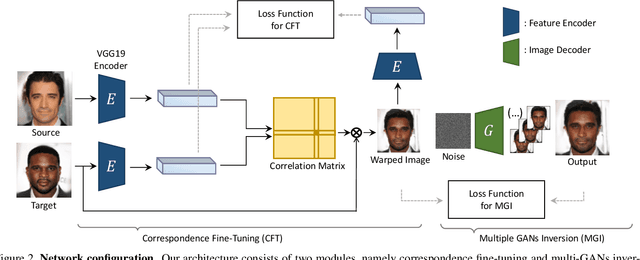
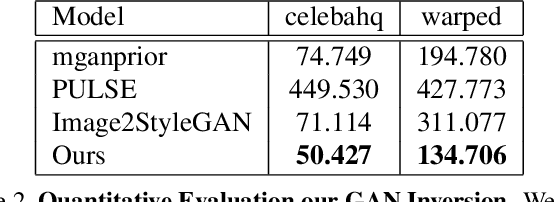
Existing techniques to solve exemplar-based image-to-image translation within deep convolutional neural networks (CNNs) generally require a training phase to optimize the network parameters on domain-specific and task-specific benchmarks, thus having limited applicability and generalization ability. In this paper, we propose a novel framework, for the first time, to solve exemplar-based translation through an online optimization given an input image pair, called online exemplar fine-tuning (OEFT), in which we fine-tune the off-the-shelf and general-purpose networks to the input image pair themselves. We design two sub-networks, namely correspondence fine-tuning and multiple GAN inversion, and optimize these network parameters and latent codes, starting from the pre-trained ones, with well-defined loss functions. Our framework does not require the off-line training phase, which has been the main challenge of existing methods, but the pre-trained networks to enable optimization in online. Experimental results prove that our framework is effective in having a generalization power to unseen image pairs and clearly even outperforms the state-of-the-arts needing the intensive training phase.
Optical Phase Dropout in Diffractive Deep Neural Network
Nov 28, 2020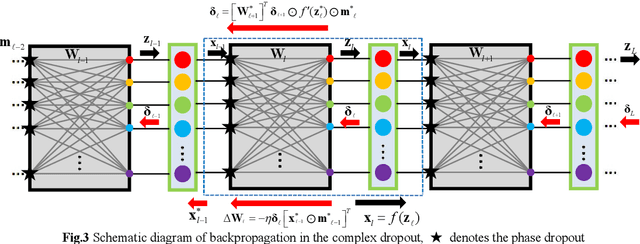
Unitary learning is a backpropagation that serves to unitary weights update in deep complex-valued neural network with full connections, meeting a physical unitary prior in diffractive deep neural network ([DN]2). However, the square matrix property of unitary weights induces that the function signal has a limited dimension that could not generalize well. To address the overfitting problem that comes from the small samples loaded to [DN]2, an optical phase dropout trick is implemented. Phase dropout in unitary space that is evolved from a complex dropout and has a statistical inference is formulated for the first time. A synthetic mask recreated from random point apertures with random phase-shifting and its smothered modulation tailors the redundant links through incompletely sampling the input optical field at each diffractive layer. The physical features about the synthetic mask using different nonlinear activations are elucidated in detail. The equivalence between digital and diffractive model determines compound modulations that could successfully circumvent the nonlinear activations physically implemented in [DN]2. The numerical experiments verify the superiority of optical phase dropout in [DN]2 to enhance accuracy in 2D classification and recognition tasks-oriented.
ECG Signal Super-resolution by Considering Reconstruction and Cardiac Arrhythmias Classification Loss
Dec 07, 2020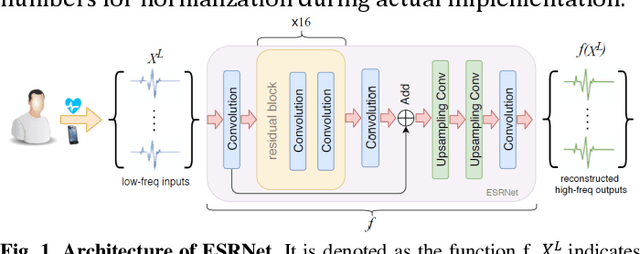
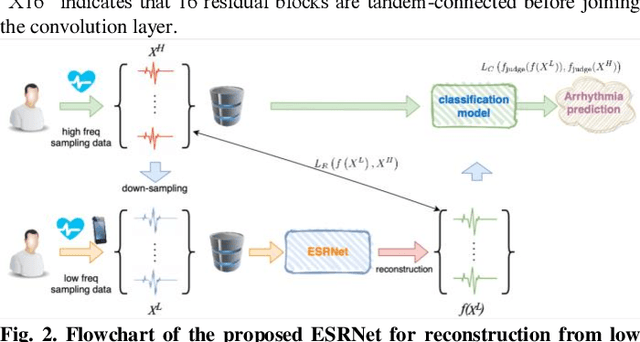
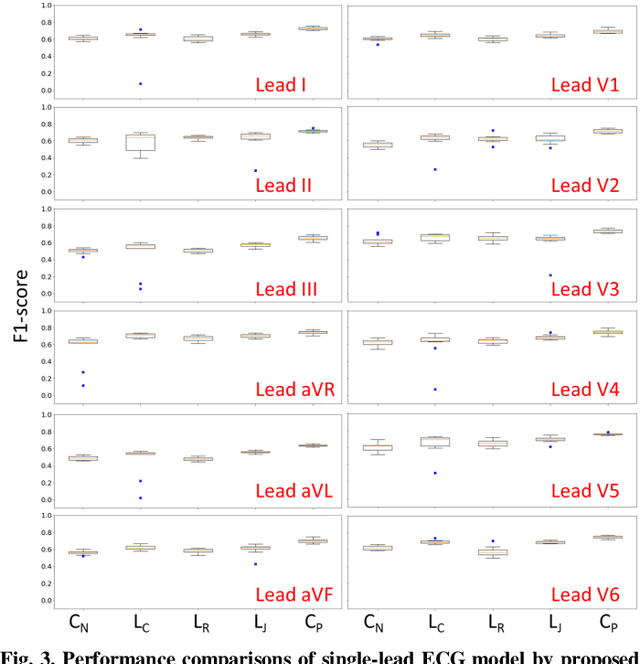
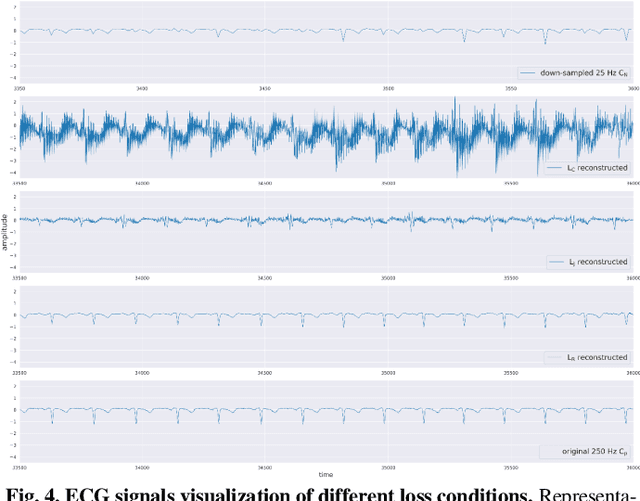
With recent advances in deep learning algorithms, computer-assisted healthcare services have rapidly grown, especially for those that combine with mobile devices. Such a combination enables wearable and portable services for continuous measurements and facilitates real-time disease alarm based on physiological signals, e.g., cardiac arrhythmias (CAs) from electrocardiography (ECG). However, long-term and continuous monitoring confronts challenges arising from limitations of batteries, and the transmission bandwidth of devices. Therefore, identifying an effective way to improve ECG data transmission and storage efficiency has become an emerging topic. In this study, we proposed a deep-learning-based ECG signal super-resolution framework (termed ESRNet) to recover compressed ECG signals by considering the joint effect of signal reconstruction and CA classification accuracies. In our experiments, we downsampled the ECG signals from the CPSC 2018 dataset and subsequently evaluated the super-resolution performance by both reconstruction errors and classification accuracies. Experimental results showed that the proposed ESRNet framework can well reconstruct ECG signals from the 10-times compressed ones. Moreover, approximately half of the CA recognition accuracies were maintained within the ECG signals recovered by the ESRNet. The promising results confirm that the proposed ESRNet framework can be suitably used as a front-end process to reconstruct compressed ECG signals in real-world CA recognition scenarios.
Pose-Guided Human Animation from a Single Image in the Wild
Dec 07, 2020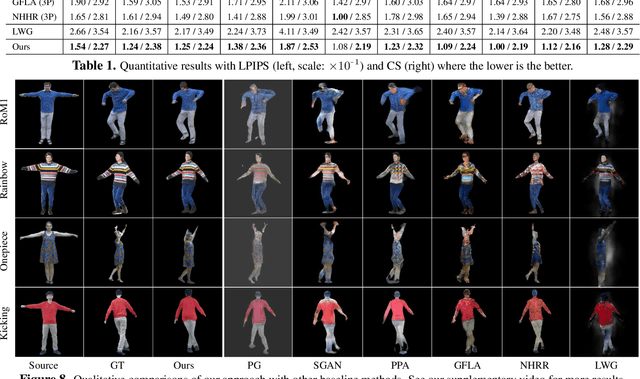
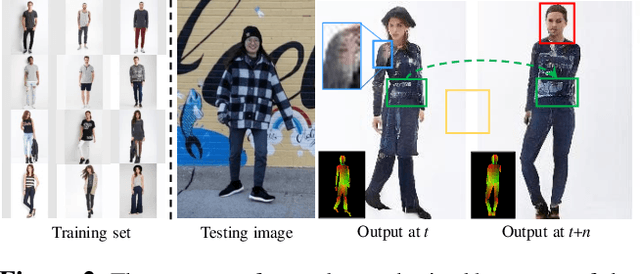
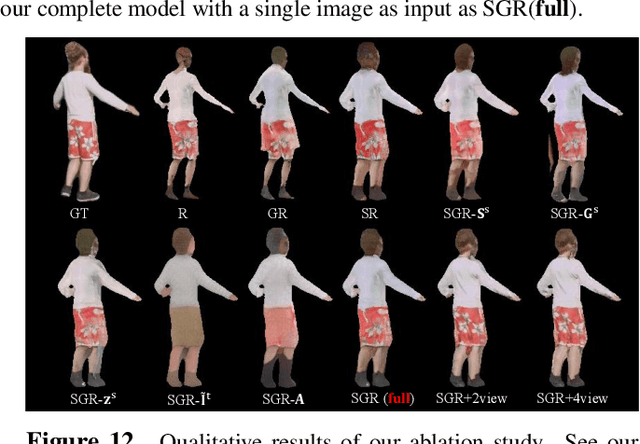
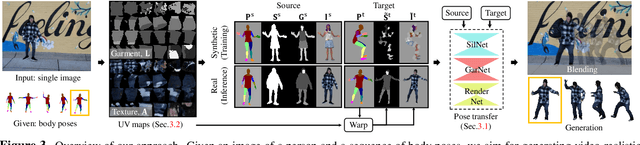
We present a new pose transfer method for synthesizing a human animation from a single image of a person controlled by a sequence of body poses. Existing pose transfer methods exhibit significant visual artifacts when applying to a novel scene, resulting in temporal inconsistency and failures in preserving the identity and textures of the person. To address these limitations, we design a compositional neural network that predicts the silhouette, garment labels, and textures. Each modular network is explicitly dedicated to a subtask that can be learned from the synthetic data. At the inference time, we utilize the trained network to produce a unified representation of appearance and its labels in UV coordinates, which remains constant across poses. The unified representation provides an incomplete yet strong guidance to generating the appearance in response to the pose change. We use the trained network to complete the appearance and render it with the background. With these strategies, we are able to synthesize human animations that can preserve the identity and appearance of the person in a temporally coherent way without any fine-tuning of the network on the testing scene. Experiments show that our method outperforms the state-of-the-arts in terms of synthesis quality, temporal coherence, and generalization ability.
LookOut! Interactive Camera Gimbal Controller for Filming Long Takes
Dec 30, 2020

The job of a camera operator is more challenging, and potentially dangerous, when filming long moving camera shots. Broadly, the operator must keep the actors in-frame while safely navigating around obstacles, and while fulfilling an artistic vision. We propose a unified hardware and software system that distributes some of the camera operator's burden, freeing them up to focus on safety and aesthetics during a take. Our real-time system provides a solo operator with end-to-end control, so they can balance on-set responsiveness to action vs planned storyboards and framing, while looking where they're going. By default, we film without a field monitor. Our LookOut system is built around a lightweight commodity camera gimbal mechanism, with heavy modifications to the controller, which would normally just provide active stabilization. Our control algorithm reacts to speech commands, video, and a pre-made script. Specifically, our automatic monitoring of the live video feed saves the operator from distractions. In pre-production, an artist uses our GUI to design a sequence of high-level camera "behaviors." Those can be specific, based on a storyboard, or looser objectives, such as "frame both actors." Then during filming, a machine-readable script, exported from the GUI, ties together with the sensor readings to drive the gimbal. To validate our algorithm, we compared tracking strategies, interfaces, and hardware protocols, and collected impressions from a) film-makers who used all aspects of our system, and b) film-makers who watched footage filmed using LookOut.
General Policies, Serializations, and Planning Width
Dec 23, 2020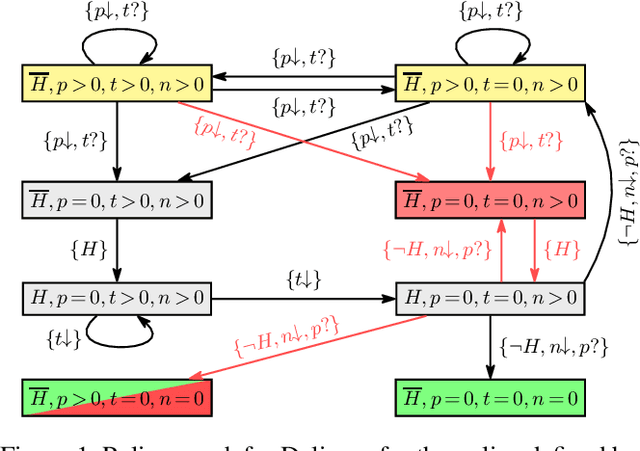

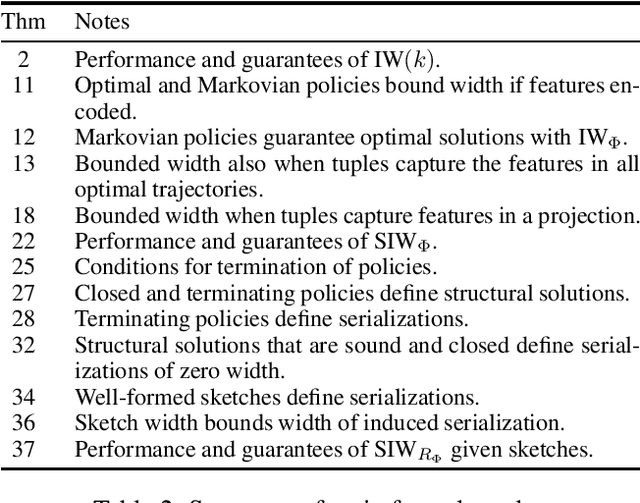
It has been observed that in many of the benchmark planning domains, atomic goals can be reached with a simple polynomial exploration procedure, called IW, that runs in time exponential in the problem width. Such problems have indeed a bounded width: a width that does not grow with the number of problem variables and is often no greater than two. Yet, while the notion of width has become part of the state-of-the-art planning algorithms like BFWS, there is still no good explanation for why so many benchmark domains have bounded width. In this work, we address this question by relating bounded width and serialized width to ideas of generalized planning, where general policies aim to solve multiple instances of a planning problem all at once. We show that bounded width is a property of planning domains that admit optimal general policies in terms of features that are explicitly or implicitly represented in the domain encoding. The results are extended to much larger class of domains with bounded serialized width where the general policies do not have to be optimal. The study leads also to a new simple, meaningful, and expressive language for specifying domain serializations in the form of policy sketches which can be used for encoding domain control knowledge by hand or for learning it from traces. The use of sketches and the meaning of the theoretical results are all illustrated through a number of examples.
Tick: a Python library for statistical learning, with a particular emphasis on time-dependent modelling
Mar 15, 2018

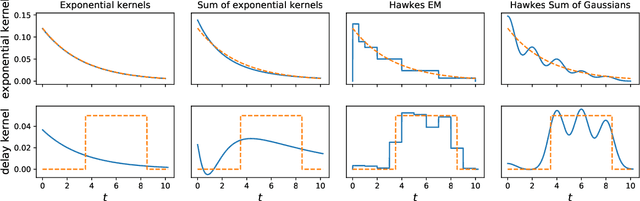
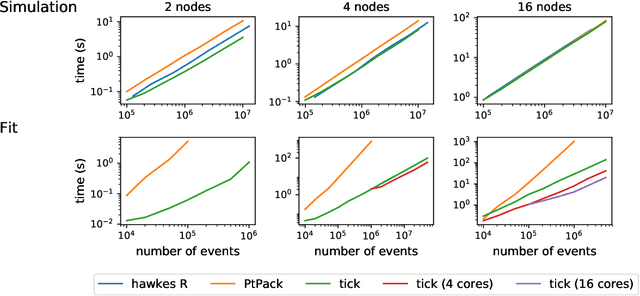
Tick is a statistical learning library for Python~3, with a particular emphasis on time-dependent models, such as point processes, and tools for generalized linear models and survival analysis. The core of the library is an optimization module providing model computational classes, solvers and proximal operators for regularization. tick relies on a C++ implementation and state-of-the-art optimization algorithms to provide very fast computations in a single node multi-core setting. Source code and documentation can be downloaded from https://github.com/X-DataInitiative/tick