 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
IIRC: Incremental Implicitly-Refined Classification
Dec 23, 2020
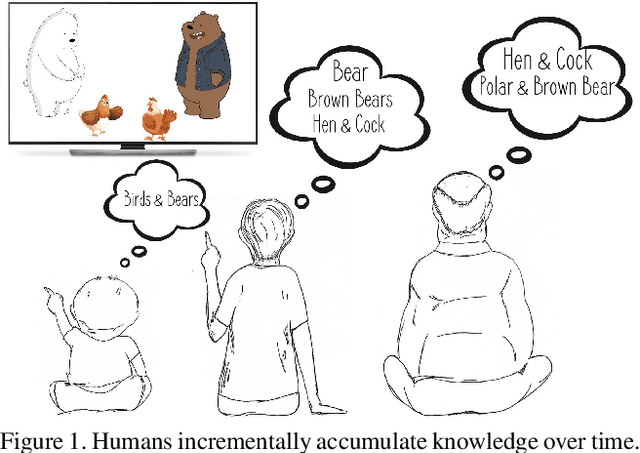

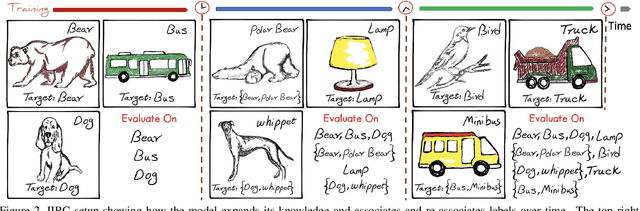

We introduce the "Incremental Implicitly-Refined Classi-fication (IIRC)" setup, an extension to the class incremental learning setup where the incoming batches of classes have two granularity levels. i.e., each sample could have a high-level (coarse) label like "bear" and a low-level (fine) label like "polar bear". Only one label is provided at a time, and the model has to figure out the other label if it has already learnfed it. This setup is more aligned with real-life scenarios, where a learner usually interacts with the same family of entities multiple times, discovers more granularity about them, while still trying not to forget previous knowledge. Moreover, this setup enables evaluating models for some important lifelong learning challenges that cannot be easily addressed under the existing setups. These challenges can be motivated by the example "if a model was trained on the class bear in one task and on polar bear in another task, will it forget the concept of bear, will it rightfully infer that a polar bear is still a bear? and will it wrongfully associate the label of polar bear to other breeds of bear?". We develop a standardized benchmark that enables evaluating models on the IIRC setup. We evaluate several state-of-the-art lifelong learning algorithms and highlight their strengths and limitations. For example, distillation-based methods perform relatively well but are prone to incorrectly predicting too many labels per image. We hope that the proposed setup, along with the benchmark, would provide a meaningful problem setting to the practitioners
Normalization effects on shallow neural networks and related asymptotic expansions
Nov 20, 2020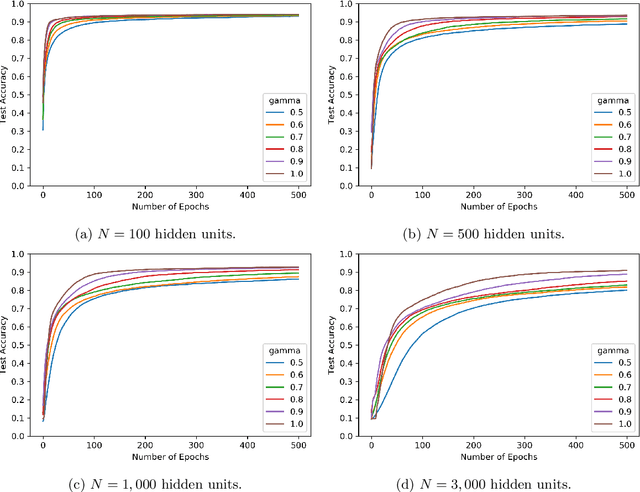
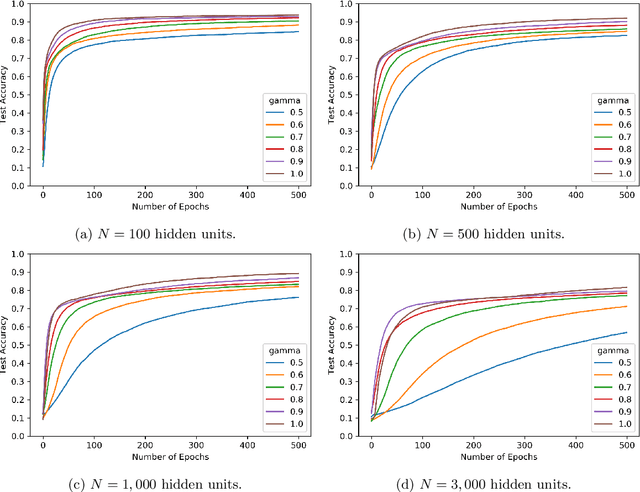
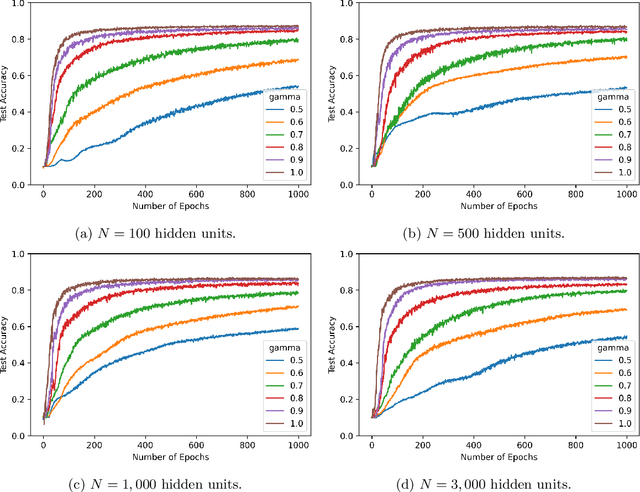
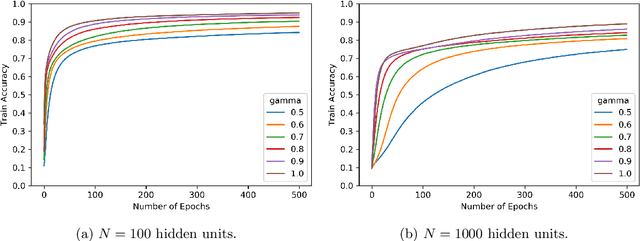
We consider shallow (single hidden layer) neural networks and characterize their performance when trained with stochastic gradient descent as the number of hidden units $N$ and gradient descent steps grow to infinity. In particular, we investigate the effect of different scaling schemes, which lead to different normalizations of the neural network, on the network's statistical output, closing the gap between the $1/\sqrt{N}$ and the mean-field $1/N$ normalization. We develop an asymptotic expansion for the neural network's statistical output pointwise with respect to the scaling parameter as the number of hidden units grows to infinity. Based on this expansion we demonstrate mathematically that to leading order in $N$ there is no bias-variance trade off, in that both bias and variance (both explicitly characterized) decrease as the number of hidden units increases and time grows. In addition, we show that to leading order in $N$, the variance of the neural network's statistical output decays as the implied normalization by the scaling parameter approaches the mean field normalization. Numerical studies on the MNIST and CIFAR10 datasets show that test and train accuracy monotonically improve as the neural network's normalization gets closer to the mean field normalization.
Encoding large scale cosmological structure with Generative Adversarial Networks
Nov 10, 2020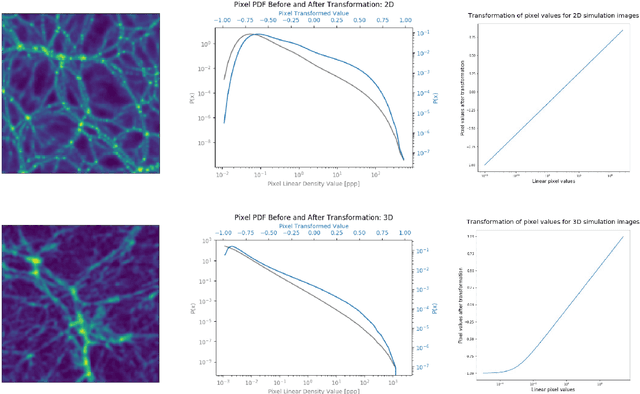
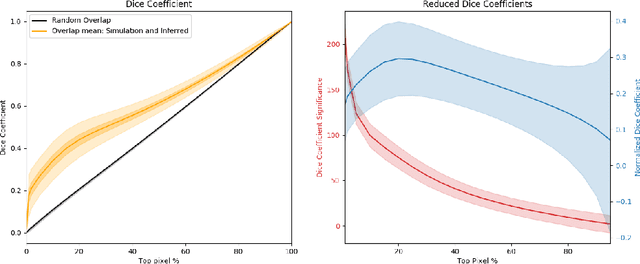

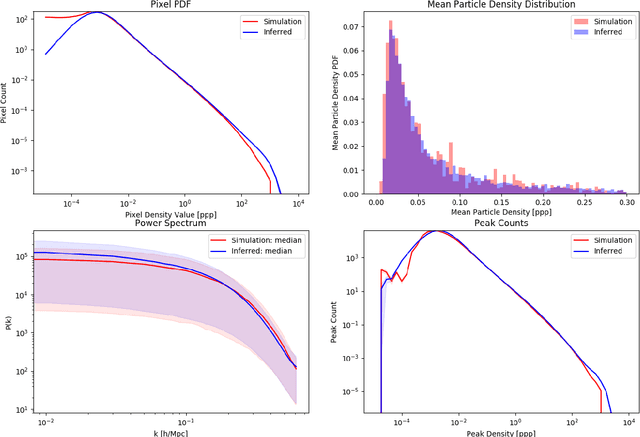
Recently a type of neural networks called Generative Adversarial Networks (GANs) has been proposed as a solution for fast generation of simulation-like datasets, in an attempt to bypass heavy computations and expensive cosmological simulations to run in terms of time and computing power. In the present work, we build and train a GAN to look further into the strengths and limitations of such an approach. We then propose a novel method in which we make use of a trained GAN to construct a simple autoencoder (AE) as a first step towards building a predictive model. Both the GAN and AE are trained on images issued from two types of N-body simulations, namely 2D and 3D simulations. We find that the GAN successfully generates new images that are statistically consistent with the images it was trained on. We then show that the AE manages to efficiently extract information from simulation images, satisfyingly inferring the latent encoding of the GAN to generate an image with similar large scale structures.
A real-time decision support system for bridge management based on the rules generalized by CART decision tree and SMO algorithms
Jun 30, 2018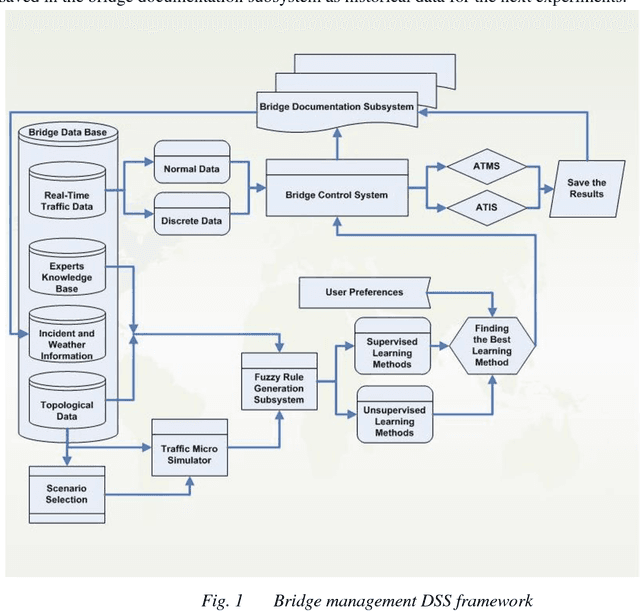
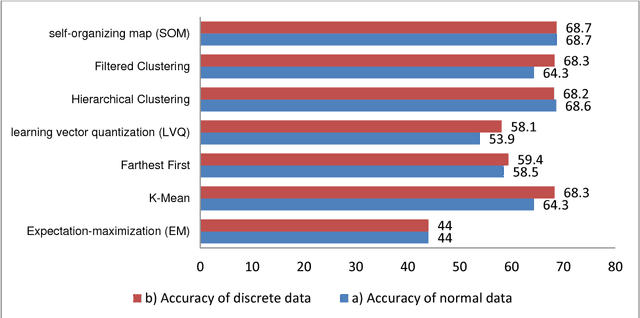
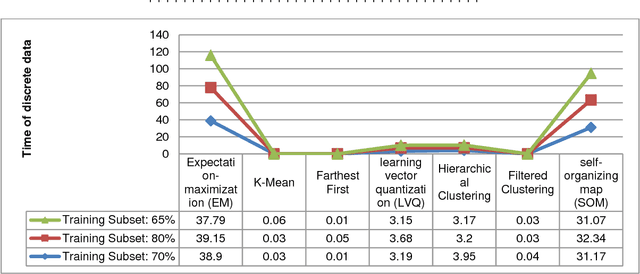
Under dynamic conditions on bridges, we need a real-time management. To this end, this paper presents a rule-based decision support system in which the necessary rules are extracted from simulation results made by Aimsun traffic micro-simulation software. Then, these rules are generalized by the aid of fuzzy rule generation algorithms. Then, they are trained by a set of supervised and the unsupervised learning algorithms to get an ability to make decision in real cases. As a pilot case study, Nasr Bridge in Tehran is simulated in Aimsun and WEKA data mining software is used to execute the learning algorithms. Based on this experiment, the accuracy of the supervised algorithms to generalize the rules is greater than 80%. In addition, CART decision tree and sequential minimal optimization (SMO) provides 100% accuracy for normal data and these algorithms are so reliable for crisis management on bridge. This means that, it is possible to use such machine learning methods to manage bridges in the real-time conditions.
Temporal Stochastic Softmax for 3D CNNs: An Application in Facial Expression Recognition
Nov 10, 2020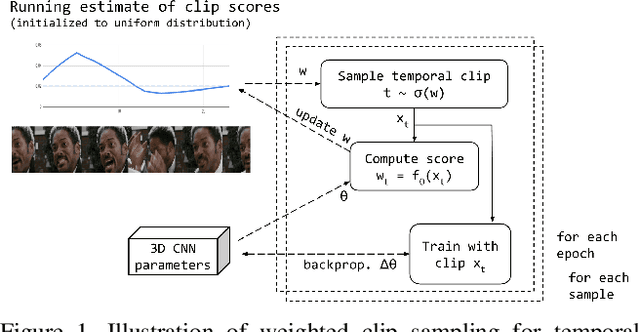
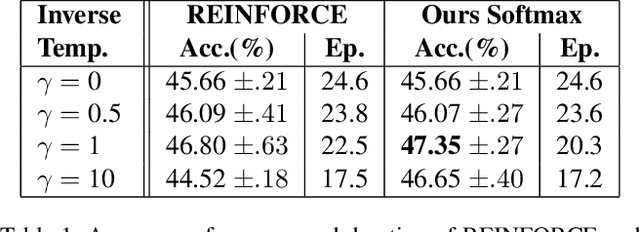
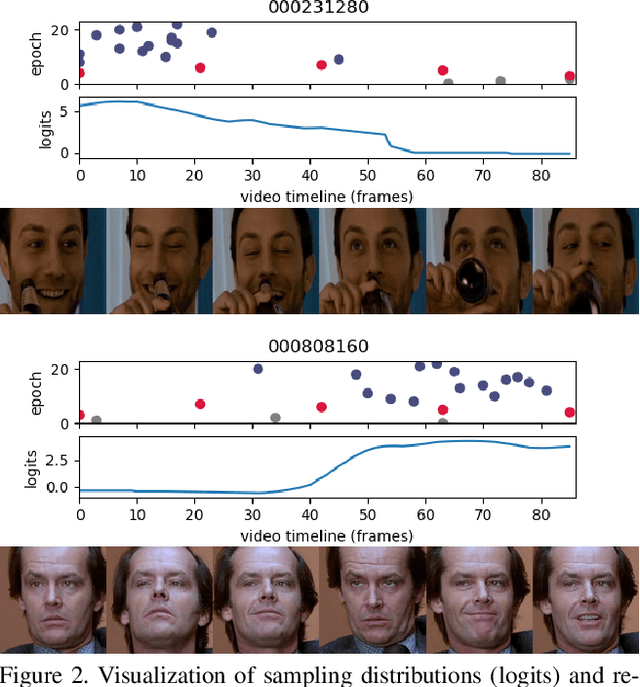
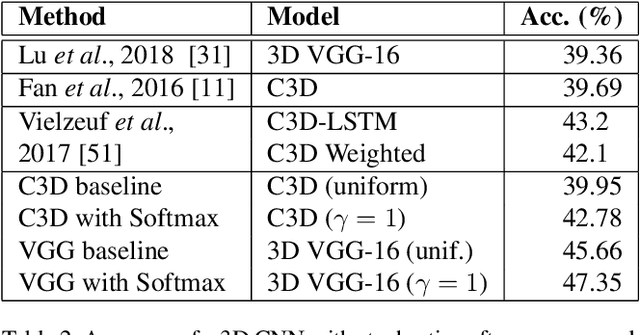
Training deep learning models for accurate spatiotemporal recognition of facial expressions in videos requires significant computational resources. For practical reasons, 3D Convolutional Neural Networks (3D CNNs) are usually trained with relatively short clips randomly extracted from videos. However, such uniform sampling is generally sub-optimal because equal importance is assigned to each temporal clip. In this paper, we present a strategy for efficient video-based training of 3D CNNs. It relies on softmax temporal pooling and a weighted sampling mechanism to select the most relevant training clips. The proposed softmax strategy provides several advantages: a reduced computational complexity due to efficient clip sampling, and an improved accuracy since temporal weighting focuses on more relevant clips during both training and inference. Experimental results obtained with the proposed method on several facial expression recognition benchmarks show the benefits of focusing on more informative clips in training videos. In particular, our approach improves performance and computational cost by reducing the impact of inaccurate trimming and coarse annotation of videos, and heterogeneous distribution of visual information across time.
Online Learning Demands in Max-min Fairness
Dec 15, 2020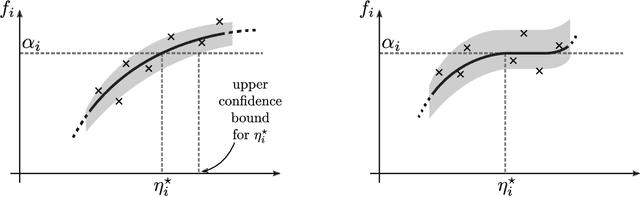

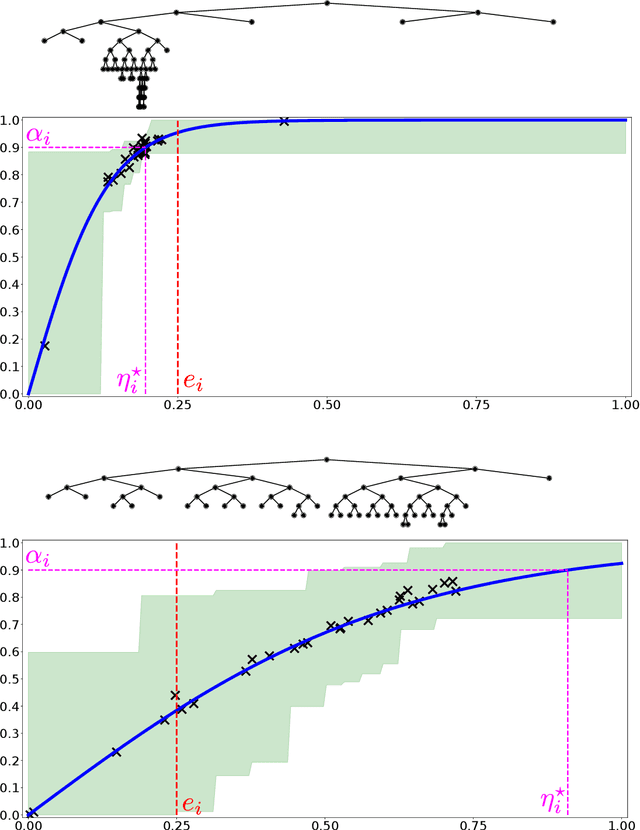
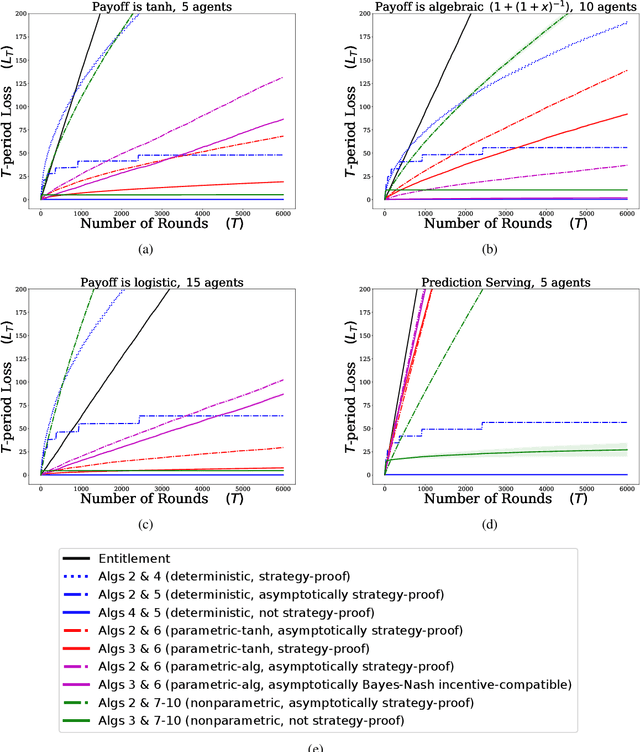
We describe mechanisms for the allocation of a scarce resource among multiple users in a way that is efficient, fair, and strategy-proof, but when users do not know their resource requirements. The mechanism is repeated for multiple rounds and a user's requirements can change on each round. At the end of each round, users provide feedback about the allocation they received, enabling the mechanism to learn user preferences over time. Such situations are common in the shared usage of a compute cluster among many users in an organisation, where all teams may not precisely know the amount of resources needed to execute their jobs. By understating their requirements, users will receive less than they need and consequently not achieve their goals. By overstating them, they may siphon away precious resources that could be useful to others in the organisation. We formalise this task of online learning in fair division via notions of efficiency, fairness, and strategy-proofness applicable to this setting, and study this problem under three types of feedback: when the users' observations are deterministic, when they are stochastic and follow a parametric model, and when they are stochastic and nonparametric. We derive mechanisms inspired by the classical max-min fairness procedure that achieve these requisites, and quantify the extent to which they are achieved via asymptotic rates. We corroborate these insights with an experimental evaluation on synthetic problems and a web-serving task.
Crowdsourcing Airway Annotations in Chest Computed Tomography Images
Nov 20, 2020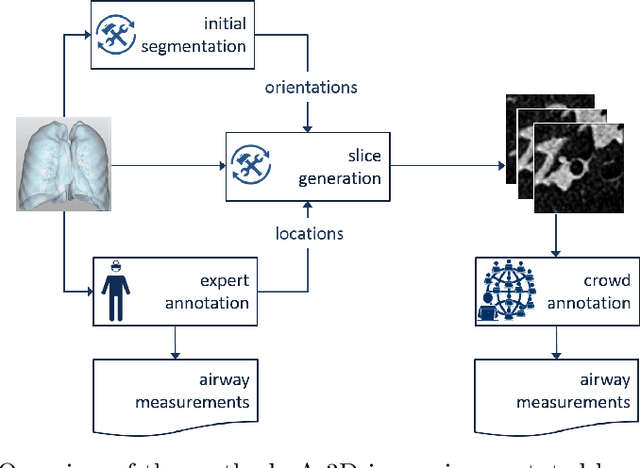
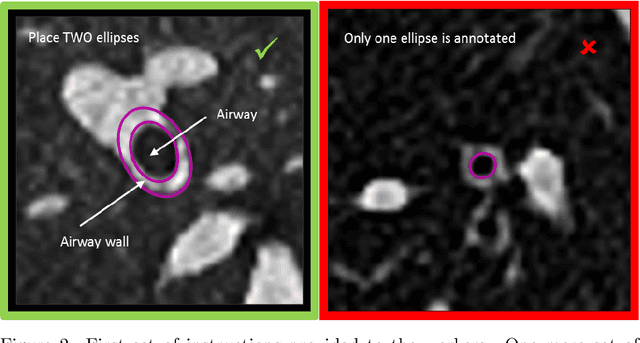
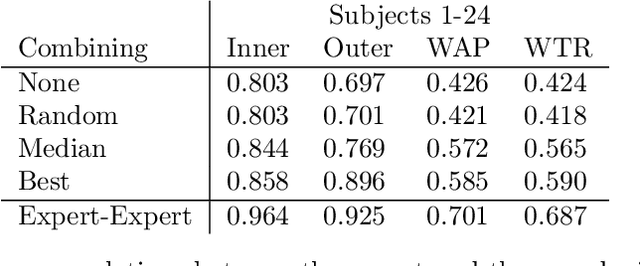

Measuring airways in chest computed tomography (CT) scans is important for characterizing diseases such as cystic fibrosis, yet very time-consuming to perform manually. Machine learning algorithms offer an alternative, but need large sets of annotated scans for good performance. We investigate whether crowdsourcing can be used to gather airway annotations. We generate image slices at known locations of airways in 24 subjects and request the crowd workers to outline the airway lumen and airway wall. After combining multiple crowd workers, we compare the measurements to those made by the experts in the original scans. Similar to our preliminary study, a large portion of the annotations were excluded, possibly due to workers misunderstanding the instructions. After excluding such annotations, moderate to strong correlations with the expert can be observed, although these correlations are slightly lower than inter-expert correlations. Furthermore, the results across subjects in this study are quite variable. Although the crowd has potential in annotating airways, further development is needed for it to be robust enough for gathering annotations in practice. For reproducibility, data and code are available online: \url{http://github.com/adriapr/crowdairway.git}.
"Closed Proportional-Integral-Derivative-Loop Model" Following Control
Jun 10, 2020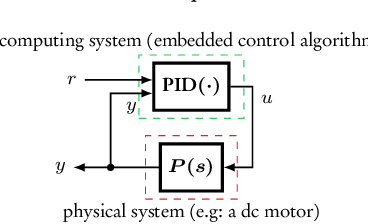
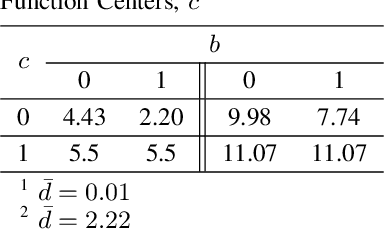
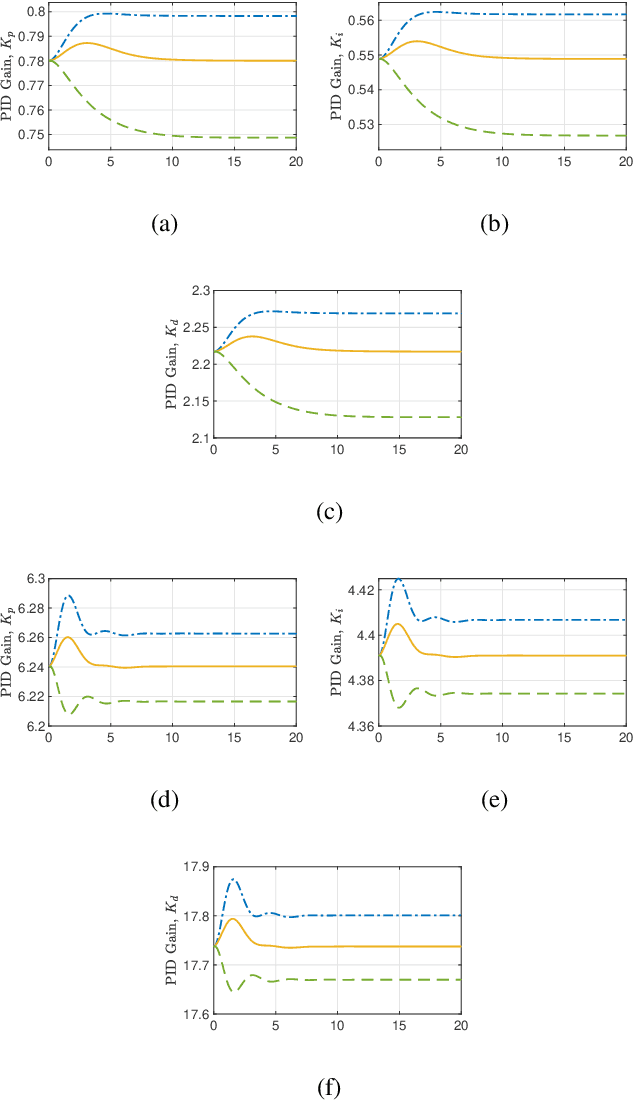
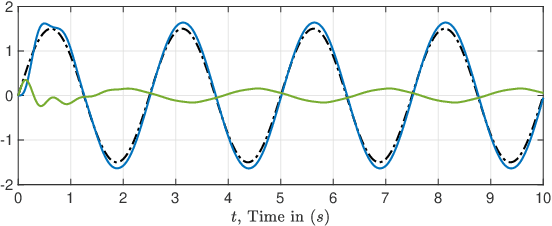
The proportional-integral-derivative (PID) control law is often overlooked as a computational imitation of the critic control in human decision. This paper provides a formulation to remedy this problem. Further, based on the characteristic settling-behaviour of dynamical systems, the "closed PID-loop model" following control (CPLMFC) method is introduced for automatic PID design. Also, a method for closed-loop settling-time identification is provided. The CPLMFC algorithm and some recommended guidelines are given for setting the critic weights of the PID. Finally, two representative case-studies are simulated. Both the theoretical results and simulation results (via performance indices) illustrate that the CPLMFC can guarantee both accurate and stable closed-loop adaptive PID control performance in real-time
Classification of Spot-welded Joints in Laser Thermography Data using Convolutional Neural Networks
Oct 24, 2020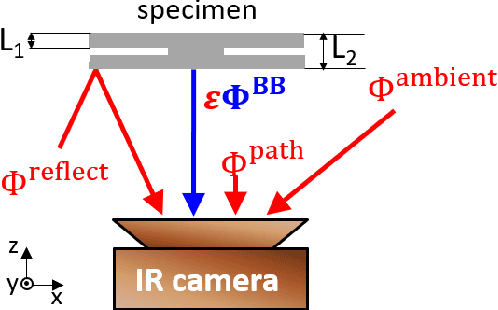
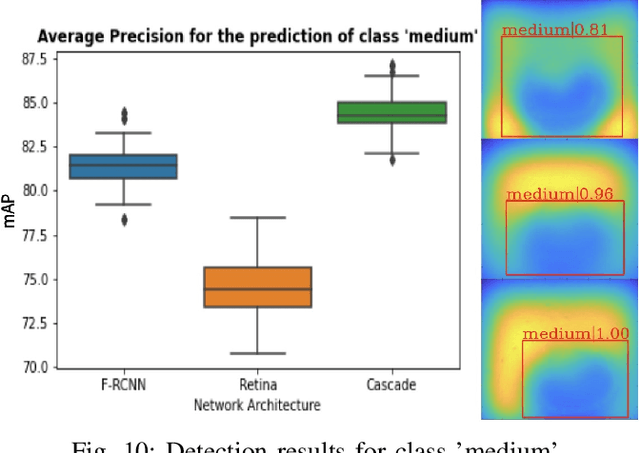
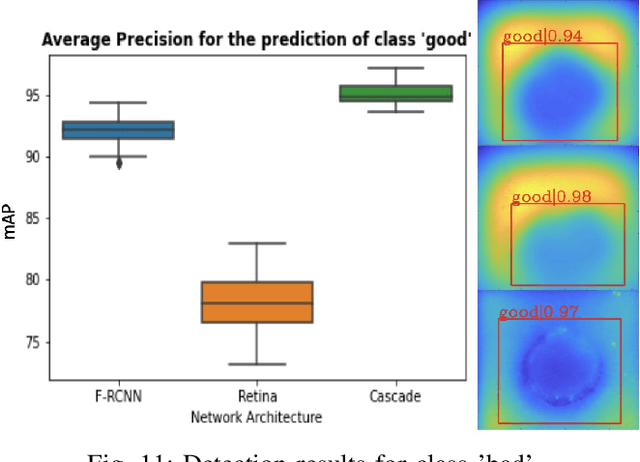

Spot welding is a crucial process step in various industries. However, classification of spot welding quality is still a tedious process due to the complexity and sensitivity of the test material, which drain conventional approaches to its limits. In this paper, we propose an approach for quality inspection of spot weldings using images from laser thermography data.We propose data preparation approaches based on the underlying physics of spot welded joints, heated with pulsed laser thermography by analyzing the intensity over time and derive dedicated data filters to generate training datasets. Subsequently, we utilize convolutional neural networks to classify weld quality and compare the performance of different models against each other. We achieve competitive results in terms of classifying the different welding quality classes compared to traditional approaches, reaching an accuracy of more than 95 percent. Finally, we explore the effect of different augmentation methods.
Finding Risk-Averse Shortest Path with Time-dependent Stochastic Costs
Jan 03, 2017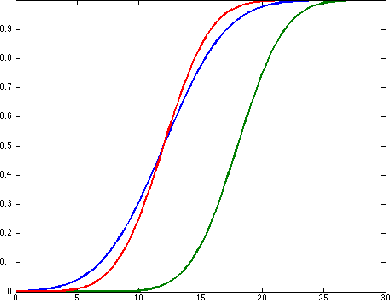
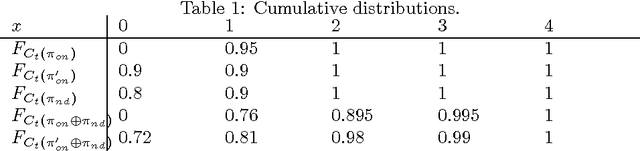
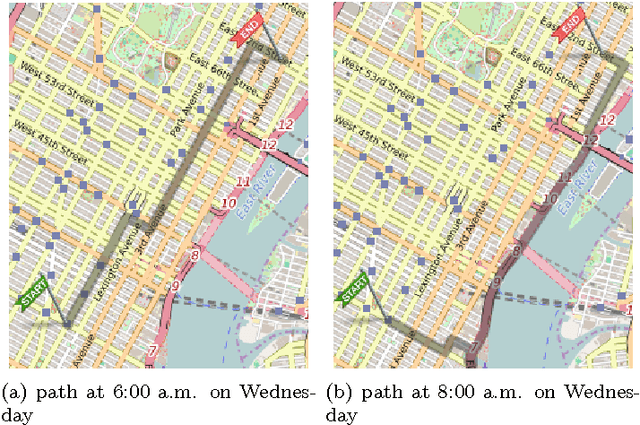
In this paper, we tackle the problem of risk-averse route planning in a transportation network with time-dependent and stochastic costs. To solve this problem, we propose an adaptation of the A* algorithm that accommodates any risk measure or decision criterion that is monotonic with first-order stochastic dominance. We also present a case study of our algorithm on the Manhattan, NYC, transportation network.