 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Interactive Denoiser (DID) for X-Ray Computed Tomography
Nov 30, 2020
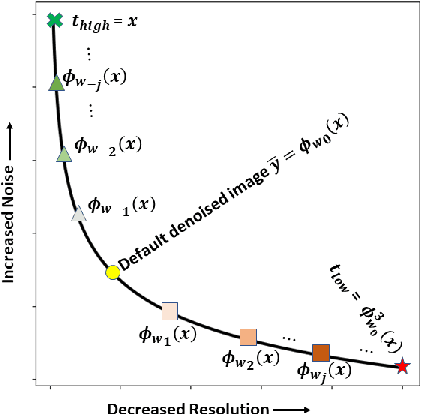
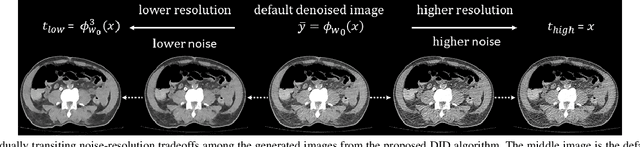
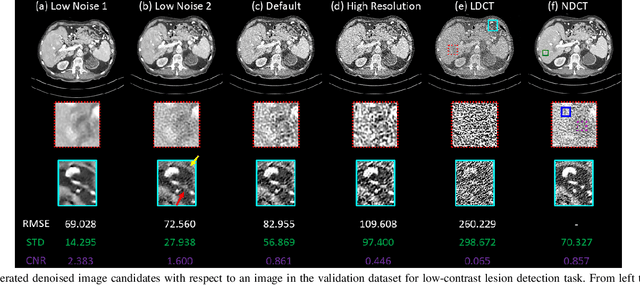
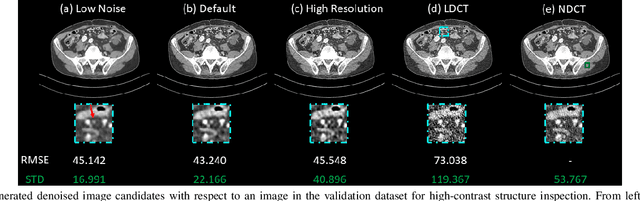
Low dose computed tomography (LDCT) is desirable for both diagnostic imaging and image guided interventions. Denoisers are openly used to improve the quality of LDCT. Deep learning (DL)-based denoisers have shown state-of-the-art performance and are becoming one of the mainstream methods. However, there exists two challenges regarding the DL-based denoisers: 1) a trained model typically does not generate different image candidates with different noise-resolution tradeoffs which sometimes are needed for different clinical tasks; 2) the model generalizability might be an issue when the noise level in the testing images is different from that in the training dataset. To address these two challenges, in this work, we introduce a lightweight optimization process at the testing phase on top of any existing DL-based denoisers to generate multiple image candidates with different noise-resolution tradeoffs suitable for different clinical tasks in real-time. Consequently, our method allows the users to interact with the denoiser to efficiently review various image candidates and quickly pick up the desired one, and thereby was termed as deep interactive denoiser (DID). Experimental results demonstrated that DID can deliver multiple image candidates with different noise-resolution tradeoffs, and shows great generalizability regarding various network architectures, as well as training and testing datasets with various noise levels.
Improving Text Generation Evaluation with Batch Centering and Tempered Word Mover Distance
Oct 13, 2020



Recent advances in automatic evaluation metrics for text have shown that deep contextualized word representations, such as those generated by BERT encoders, are helpful for designing metrics that correlate well with human judgements. At the same time, it has been argued that contextualized word representations exhibit sub-optimal statistical properties for encoding the true similarity between words or sentences. In this paper, we present two techniques for improving encoding representations for similarity metrics: a batch-mean centering strategy that improves statistical properties; and a computationally efficient tempered Word Mover Distance, for better fusion of the information in the contextualized word representations. We conduct numerical experiments that demonstrate the robustness of our techniques, reporting results over various BERT-backbone learned metrics and achieving state of the art correlation with human ratings on several benchmarks.
Learning to Solve AC Optimal Power Flow by Differentiating through Holomorphic Embeddings
Dec 16, 2020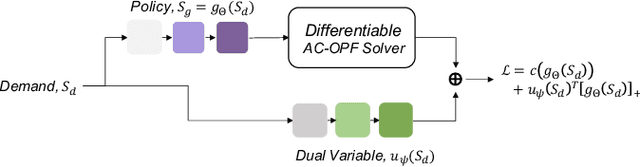
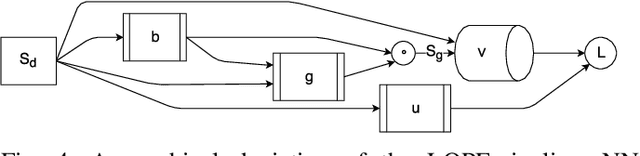
Alternating current optimal power flow (AC-OPF) is one of the fundamental problems in power systems operation. AC-OPF is traditionally cast as a constrained optimization problem that seeks optimal generation set points whilst fulfilling a set of non-linear equality constraints -- the power flow equations. With increasing penetration of renewable generation, grid operators need to solve larger problems at shorter intervals. This motivates the research interest in learning OPF solutions with neural networks, which have fast inference time and is potentially scalable to large networks. The main difficulty in solving the AC-OPF problem lies in dealing with this equality constraint that has spurious roots, i.e. there are assignments of voltages that fulfill the power flow equations that however are not physically realizable. This property renders any method relying on projected-gradients brittle because these non-physical roots can act as attractors. In this paper, we show efficient strategies that circumvent this problem by differentiating through the operations of a power flow solver that embeds the power flow equations into a holomorphic function. The resulting learning-based approach is validated experimentally on a 200-bus system and we show that, after training, the learned agent produces optimized power flow solutions reliably and fast. Specifically, we report a 12x increase in speed and a 40% increase in robustness compared to a traditional solver. To the best of our knowledge, this approach constitutes the first learning-based approach that successfully respects the full non-linear AC-OPF equations.
Synthesizing CT from Ultrashort Echo-Time MR Images via Convolutional Neural Networks
Jul 27, 2018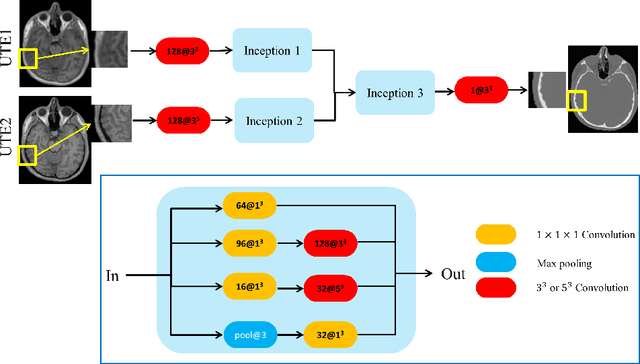
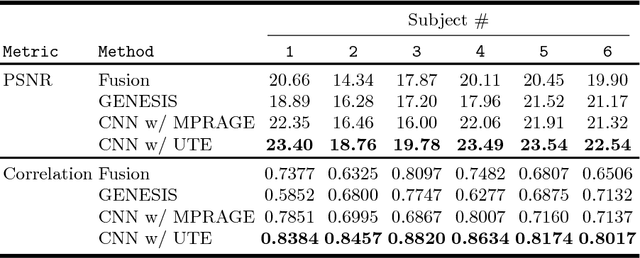

With the increasing popularity of PET-MR scanners in clinical applications, synthesis of CT images from MR has been an important research topic. Accurate PET image reconstruction requires attenuation correction, which is based on the electron density of tissues and can be obtained from CT images. While CT measures electron density information for x-ray photons, MR images convey information about the magnetic properties of tissues. Therefore, with the advent of PET-MR systems, the attenuation coefficients need to be indirectly estimated from MR images. In this paper, we propose a fully convolutional neural network (CNN) based method to synthesize head CT from ultra-short echo-time (UTE) dual-echo MR images. Unlike traditional $T_1$-w images which do not have any bone signal, UTE images show some signal for bone, which makes it a good candidate for MR to CT synthesis. A notable advantage of our approach is that accurate results were achieved with a small training data set. Using an atlas of a single CT and dual-echo UTE pair, we train a deep neural network model to learn the transform of MR intensities to CT using patches. We compared our CNN based model with a state-of-the-art registration based as well as a Bayesian model based CT synthesis method, and showed that the proposed CNN model outperforms both of them. We also compared the proposed model when only $T_1$-w images are available instead of UTE, and show that UTE images produce better synthesis than using just $T_1$-w images.
You Only Need Adversarial Supervision for Semantic Image Synthesis
Dec 08, 2020
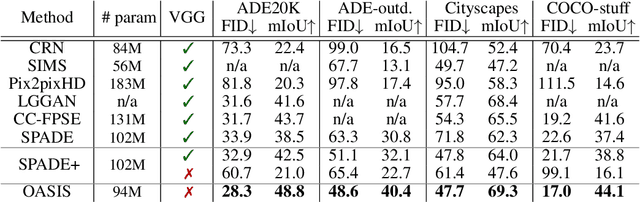

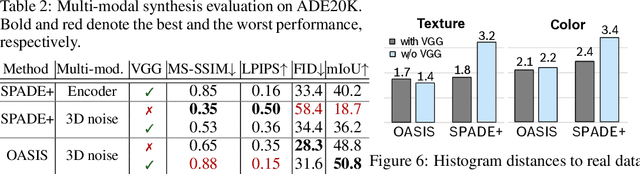
Despite their recent successes, GAN models for semantic image synthesis still suffer from poor image quality when trained with only adversarial supervision. Historically, additionally employing the VGG-based perceptual loss has helped to overcome this issue, significantly improving the synthesis quality, but at the same time limiting the progress of GAN models for semantic image synthesis. In this work, we propose a novel, simplified GAN model, which needs only adversarial supervision to achieve high quality results. We re-design the discriminator as a semantic segmentation network, directly using the given semantic label maps as the ground truth for training. By providing stronger supervision to the discriminator as well as to the generator through spatially- and semantically-aware discriminator feedback, we are able to synthesize images of higher fidelity with better alignment to their input label maps, making the use of the perceptual loss superfluous. Moreover, we enable high-quality multi-modal image synthesis through global and local sampling of a 3D noise tensor injected into the generator, which allows complete or partial image change. We show that images synthesized by our model are more diverse and follow the color and texture distributions of real images more closely. We achieve an average improvement of $6$ FID and $5$ mIoU points over the state of the art across different datasets using only adversarial supervision.
Methods for Pruning Deep Neural Networks
Oct 31, 2020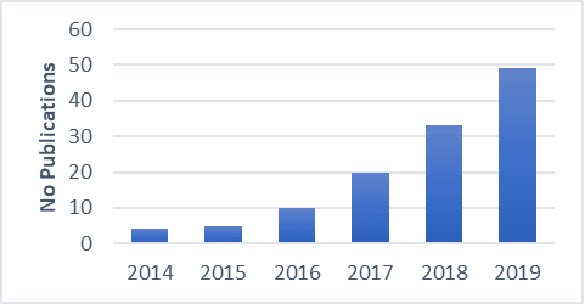
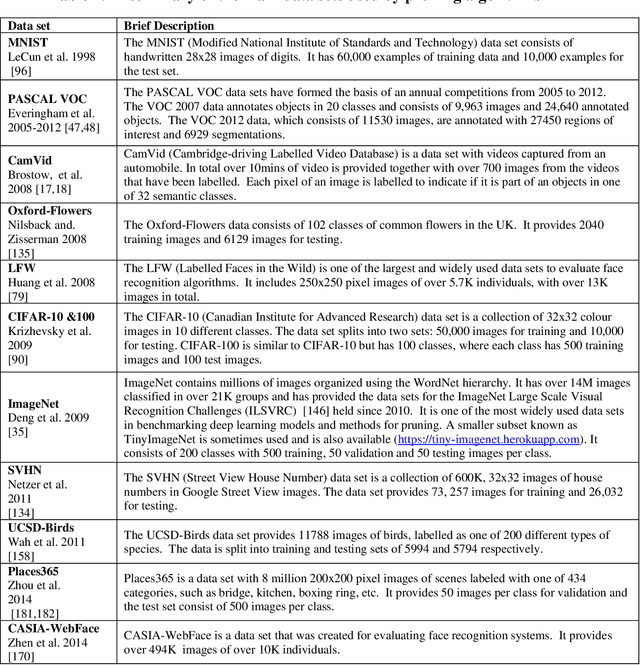
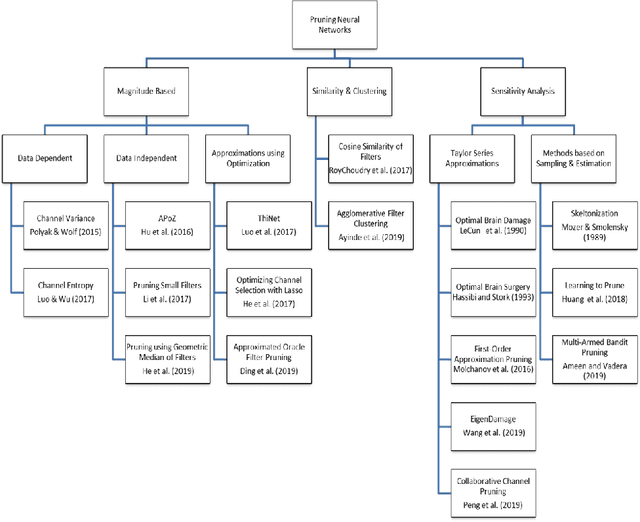
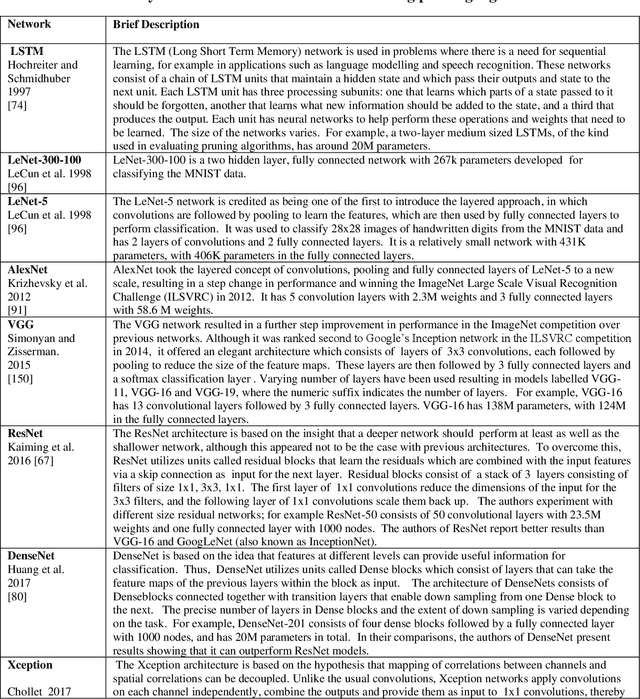
This paper presents a survey of methods for pruning deep neural networks, from algorithms first proposed for fully connected networks in the 1990s to the recent methods developed for reducing the size of convolutional neural networks. The paper begins by bringing together many different algorithms by categorising them based on the underlying approach used. It then focuses on three categories: methods that use magnitude-based pruning, methods that utilise clustering to identify redundancy, and methods that utilise sensitivity analysis. Some of the key influencing studies within these categories are presented to illuminate the underlying approaches and results achieved. Most studies on pruning present results from empirical evaluations, which are distributed in the literature as new architectures, algorithms and data sets have evolved with time. This paper brings together the reported results from some key papers in one place by providing a resource that can be used to quickly compare reported results, and trace studies where specific methods, data sets and architectures have been used.
Neural Mechanics: Symmetry and Broken Conservation Laws in Deep Learning Dynamics
Dec 08, 2020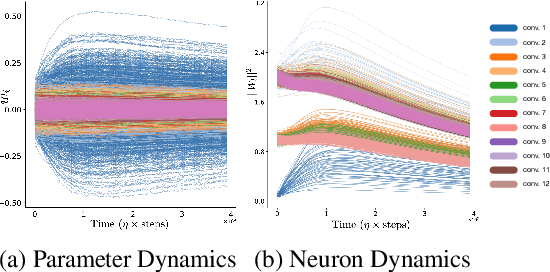
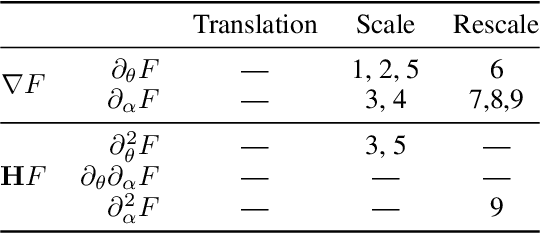
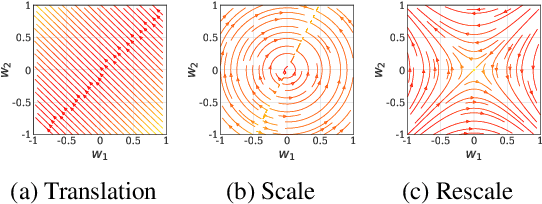

Predicting the dynamics of neural network parameters during training is one of the key challenges in building a theoretical foundation for deep learning. A central obstacle is that the motion of a network in high-dimensional parameter space undergoes discrete finite steps along complex stochastic gradients derived from real-world datasets. We circumvent this obstacle through a unifying theoretical framework based on intrinsic symmetries embedded in a network's architecture that are present for any dataset. We show that any such symmetry imposes stringent geometric constraints on gradients and Hessians, leading to an associated conservation law in the continuous-time limit of stochastic gradient descent (SGD), akin to Noether's theorem in physics. We further show that finite learning rates used in practice can actually break these symmetry induced conservation laws. We apply tools from finite difference methods to derive modified gradient flow, a differential equation that better approximates the numerical trajectory taken by SGD at finite learning rates. We combine modified gradient flow with our framework of symmetries to derive exact integral expressions for the dynamics of certain parameter combinations. We empirically validate our analytic predictions for learning dynamics on VGG-16 trained on Tiny ImageNet. Overall, by exploiting symmetry, our work demonstrates that we can analytically describe the learning dynamics of various parameter combinations at finite learning rates and batch sizes for state of the art architectures trained on any dataset.
Stress Testing Method for Scenario Based Testing of Automated Driving Systems
Dec 08, 2020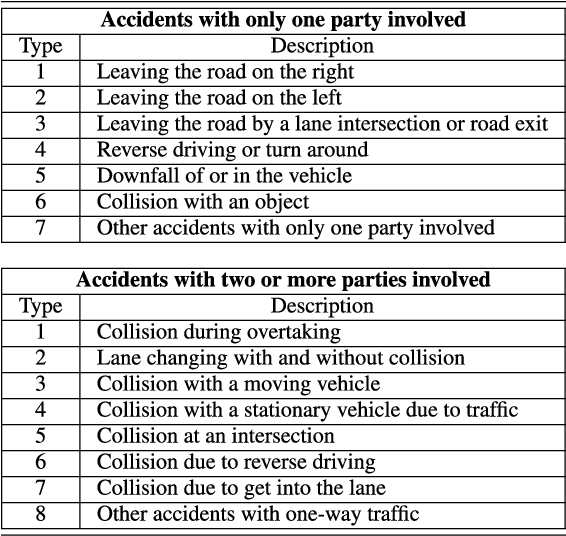
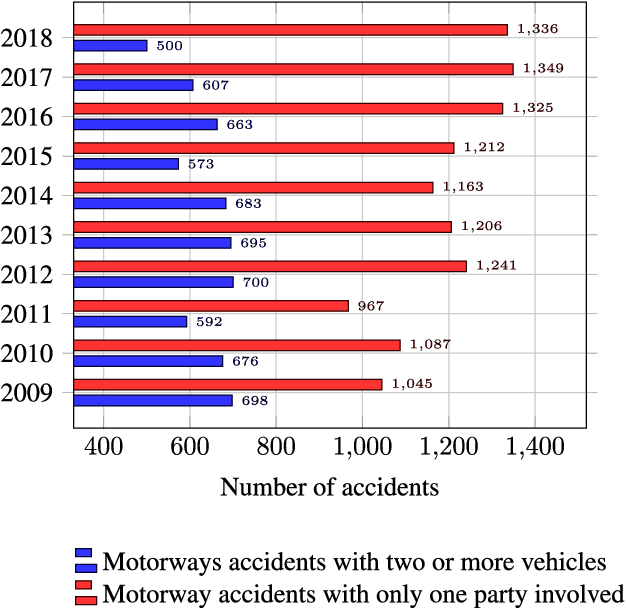
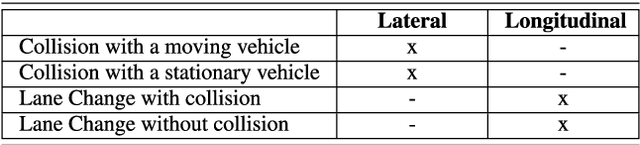
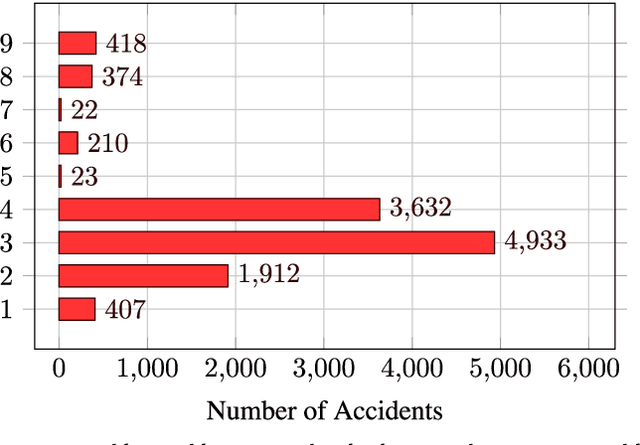
Classical approaches and procedures for testing of automated vehicles of SAE levels 1 and 2 were based on defined scenarios with specific maneuvers, depending on the function under test. For automated driving systems (ADS) of SAE level 3+, the scenario space is infinite and calling for virtual testing and verification. However, even in simulation, the generation of safety-relevant scenarios for ADS is expensive and time-consuming. This leads to a demand for stochastic and realistic traffic simulation. Therefore, microscopic traffic flow simulation models (TFSM) are becoming a crucial part of scenario-based testing of ADS. In this paper, a co-simulation between the multi-body simulation software IPG CarMaker and the microscopic traffic flow simulation software (TFSS) PTV Vissim is used. Although the TFSS could provide realistic and stochastic behavior of the traffic participants, safety-critical scenarios (SCS) occur rarely. In order to avoid this, a novel Stress Testing Method (STM) is introduced. With this method, traffic participants are manipulated via external driver DLL interface from PTV Vissim in the vicinity of the vehicle under test in order to provoke defined critical maneuvers derived from statistical accident data on highways in Austria. These external driver models imitate human driving errors, resulting in an increase of safety-critical scenarios. As a result, the presented STM method contributes to an increase of safety-relevant scenarios for verification, testing and assessment of ADS.
A Recurrent Neural Network and Differential Equation Based Spatiotemporal Infectious Disease Model with Application to COVID-19
Jul 14, 2020The outbreaks of Coronavirus Disease 2019 (COVID-19) have impacted the world significantly. Modeling the trend of infection and real-time forecasting of cases can help decision making and control of the disease spread. However, data-driven methods such as recurrent neural networks (RNN) can perform poorly due to limited daily samples in time. In this work, we develop an integrated spatiotemporal model based on the epidemic differential equations (SIR) and RNN. The former after simplification and discretization is a compact model of temporal infection trend of a region while the latter models the effect of nearest neighboring regions. The latter captures latent spatial information. %that is not publicly reported. We trained and tested our model on COVID-19 data in Italy, and show that it out-performs existing temporal models (fully connected NN, SIR, ARIMA) in 1-day, 3-day, and 1-week ahead forecasting especially in the regime of limited training data.
Narrow Artificial Intelligence with Machine Learning for Real-Time Estimation of a Mobile Agents Location Using Hidden Markov Models
Feb 09, 2018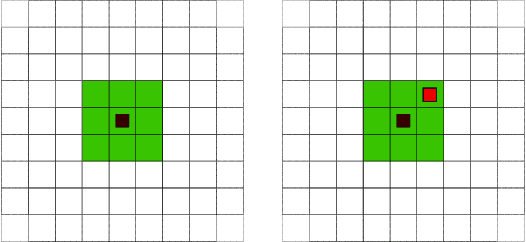


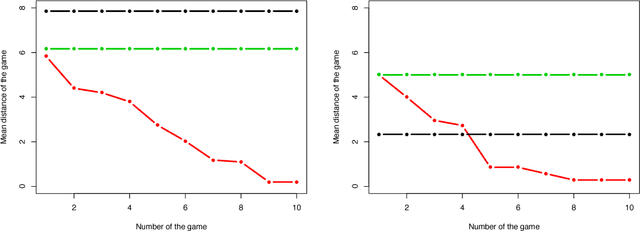
We propose to use a supervised machine learning technique to track the location of a mobile agent in real time. Hidden Markov Models are used to build artificial intelligence that estimates the unknown position of a mobile target moving in a defined environment. This narrow artificial intelligence performs two distinct tasks. First, it provides real-time estimation of the mobile agent's position using the forward algorithm. Second, it uses the Baum-Welch algorithm as a statistical learning tool to gain knowledge of the mobile target. Finally, an experimental environment is proposed, namely a video game that we use to test our artificial intelligence. We present statistical and graphical results to illustrate the efficiency of our method.