 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient and Transferable Adversarial Examples from Bayesian Neural Networks
Nov 10, 2020
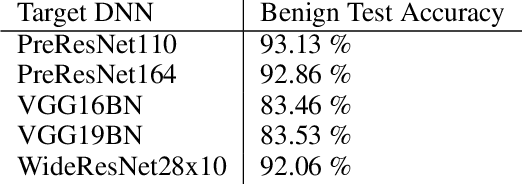
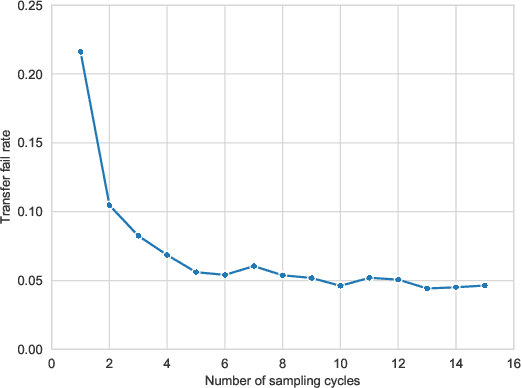

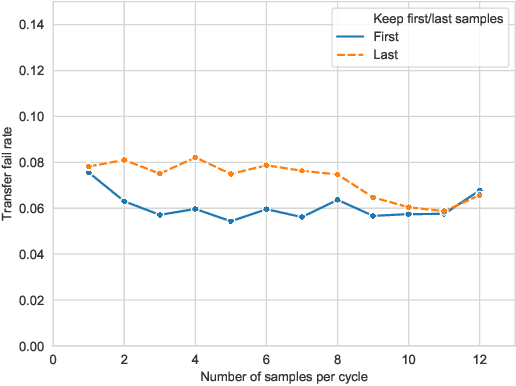
Deep neural networks are vulnerable to evasion attacks, i.e., carefully crafted examples designed to fool a model at test time. Attacks that successfully evade an ensemble of models can transfer to other independently trained models, which proves useful in black-box settings. Unfortunately, these methods involve heavy computation costs to train the models forming the ensemble. To overcome this, we propose a new method to generate transferable adversarial examples efficiently. Inspired by Bayesian deep learning, our method builds such ensembles by sampling from the posterior distribution of neural network weights during a single training process. Experiments on CIFAR-10 show that our approach improves the transfer rates significantly at equal or even lower computation costs. Intra-architecture transfer rate is increased by 23% compared to classical ensemble-based attacks, while requiring 4 times less training epochs. In the inter-architecture case, we show that we can combine our method with ensemble-based attacks to increase their transfer rate by up to 15% with constant training computational cost.
A Modular Robotic Arm Control Stack for Research: Franka-Interface and FrankaPy
Nov 04, 2020
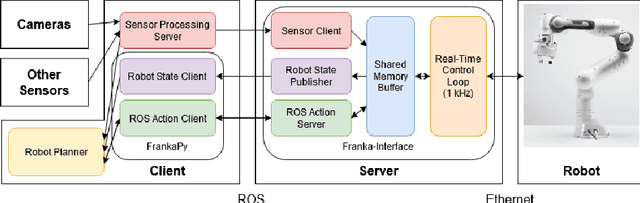


We designed a modular robotic control stack that provides a customizable and accessible interface to the Franka Emika Panda Research robot. This framework abstracts high-level robot control commands as skills, which are decomposed into combinations of trajectory generators, feedback controllers, and termination handlers. Low-level control is implemented in C++ and runs at $1$kHz, and high-level commands are exposed in Python. In addition, external sensor feedback, like estimated object poses, can be streamed to the low-level controllers in real time. This modular approach allows us to quickly prototype new control methods, which is essential for research applications. We have applied this framework across a variety of real-world robot tasks in more than $5$ published research papers. The framework is currently shared internally with other robotics labs at Carnegie Mellon University, and we plan for a public release in the near future.
Lightning-Fast Gravitational Wave Parameter Inference through Neural Amortization
Oct 29, 2020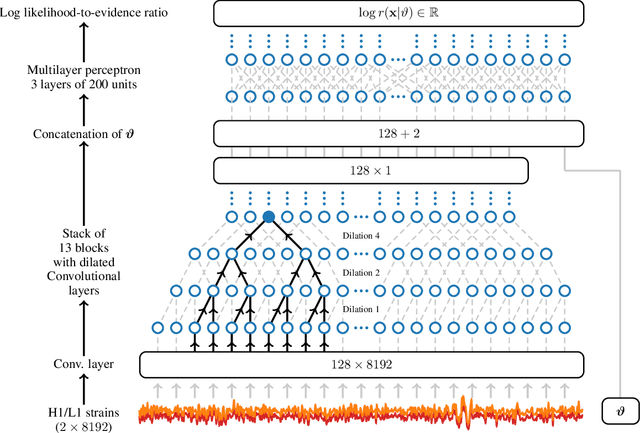


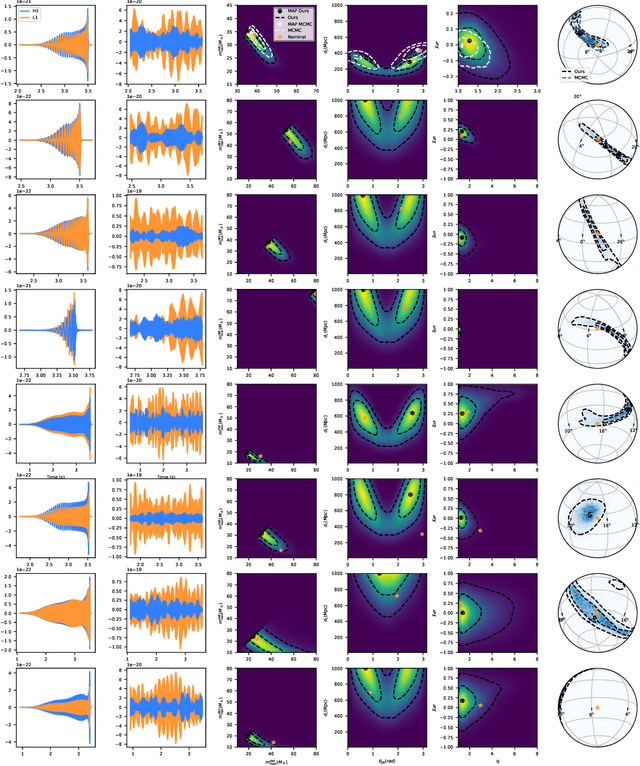
Gravitational waves from compact binaries measured by the LIGO and Virgo detectors are routinely analyzed using Markov Chain Monte Carlo sampling algorithms. Because the evaluation of the likelihood function requires evaluating millions of waveform models that link between signal shapes and the source parameters, running Markov chains until convergence is typically expensive and requires days of computation. In this extended abstract, we provide a proof of concept that demonstrates how the latest advances in neural simulation-based inference can speed up the inference time by up to three orders of magnitude -- from days to minutes -- without impairing the performance. Our approach is based on a convolutional neural network modeling the likelihood-to-evidence ratio and entirely amortizes the computation of the posterior. We find that our model correctly estimates credible intervals for the parameters of simulated gravitational waves.
Genetic U-Net: Automatically Designing Lightweight U-shaped CNN Architectures Using the Genetic Algorithm for Retinal Vessel Segmentation
Oct 29, 2020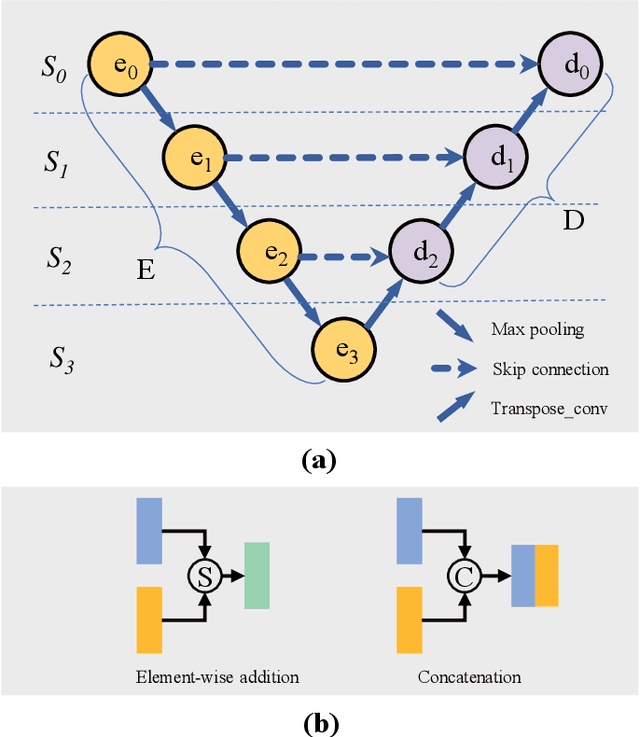
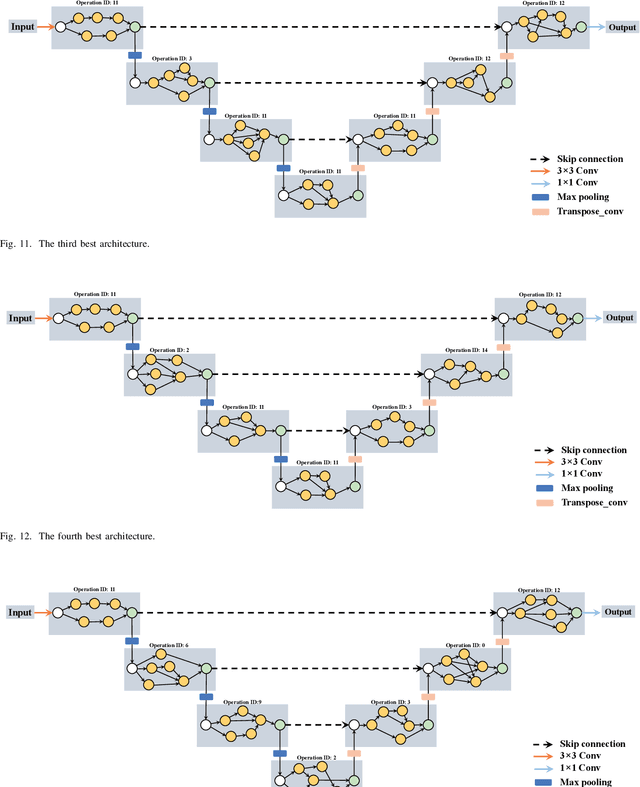
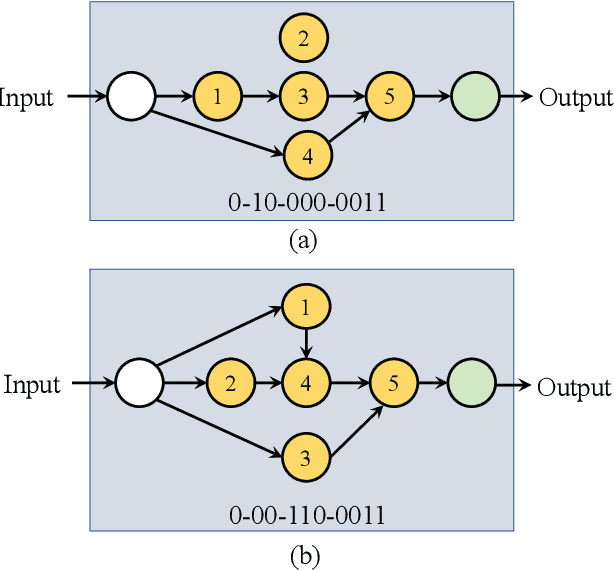
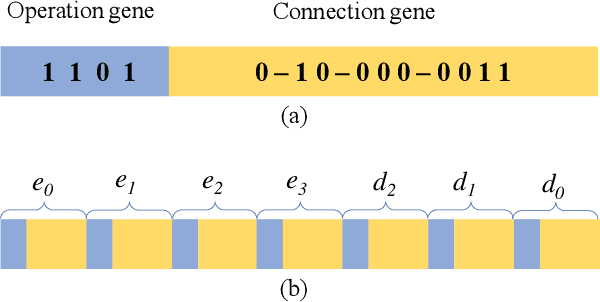
Many previous works based on deep learning for retinal vessel segmentation have achieved promising performance by manually designing U-shaped convolutional neural networks (CNNs). However, the manual design of these CNNs is time-consuming and requires extensive empirical knowledge. To address this problem, we propose a novel method using genetic algorithms (GAs) to automatically design a lightweight U-shaped CNN for retinal vessel segmentation, called Genetic U-Net. Here we first design a special search space containing the structure of U-Net and its corresponding operations, and then use genetic algorithm to search for superior architectures in this search space. Experimental results show that the proposed method outperforms the existing methods on three public datasets, DRIVE, CHASE_DB1 and STARE. In addition, the architectures obtained by the proposed method are more lightweight but robust than the state-of-the-art models.
Prediction of short and long-term droughts using artificial neural networks and hydro-meteorological variables
Jun 03, 2020
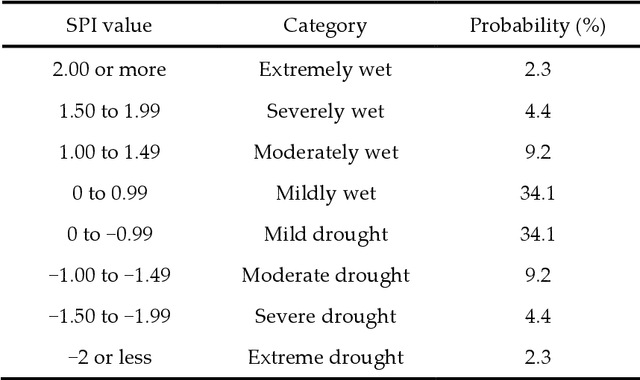
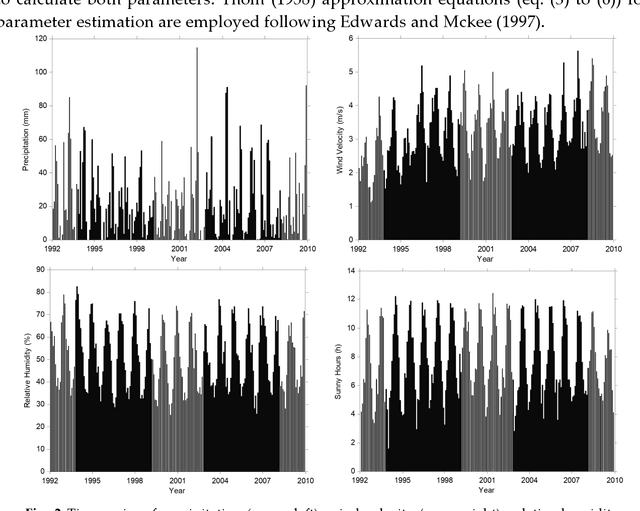
Drought is a natural creeping threat with numerous damaging effects in various aspects of human life. Accurate drought prediction is a promising step in helping policy makers to set drought risk management strategies. To fulfill this purpose, choosing appropriate models plays an important role in predicting approach. In this study, different models of Artificial Neural Network (ANN) are employed to predict short and long-term of droughts by using Standardized Precipitation Index (SPI) at different time scales, including 3, 6, 12, 24 and 48 months in Tabriz city, Iran. To this end, different combination of calculated SPI and time series of various hydro-meteorological variables, such as precipitation, wind velocity, relative humidity and sunshine hours for years 1992 to 2010 are used to train the ANN models. In order to compare the models performances, some well-known measures, namely RMSE, Mean Absolute Error (MAE) and Correlation Coefficient (CC) are utilized in the present study. The results illustrate that the application of all hydro-meteorological variables significantly improves the prediction of SPI at different time scales.
Real-time Scene Segmentation Using a Light Deep Neural Network Architecture for Autonomous Robot Navigation on Construction Sites
Jan 24, 2019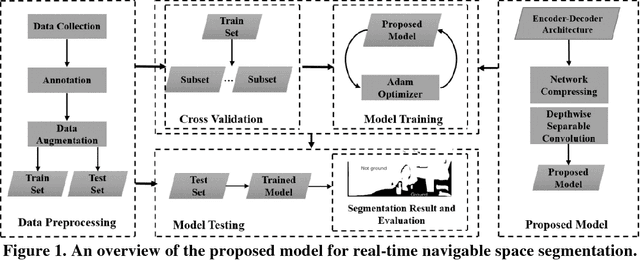
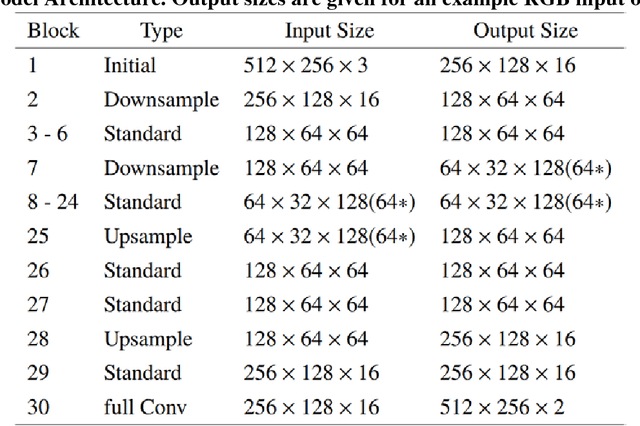
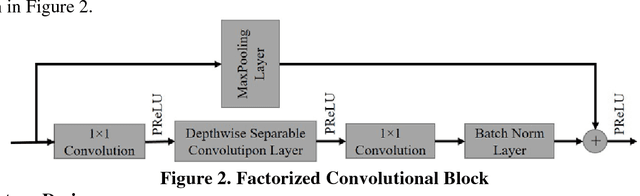
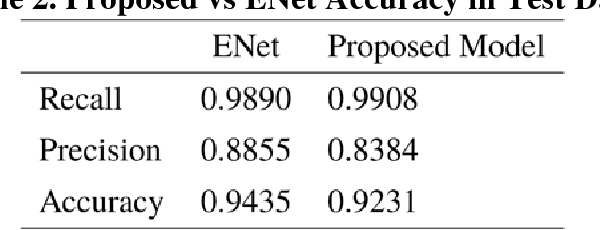
Camera-equipped unmanned vehicles (UVs) have received a lot of attention in data collection for construction monitoring applications. To develop an autonomous platform, the UV should be able to process multiple modules (e.g., context-awareness, control, localization, and mapping) on an embedded platform. Pixel-wise semantic segmentation provides a UV with the ability to be contextually aware of its surrounding environment. However, in the case of mobile robotic systems with limited computing resources, the large size of the segmentation model and high memory usage requires high computing resources, which a major challenge for mobile UVs (e.g., a small-scale vehicle with limited payload and space). To overcome this challenge, this paper presents a light and efficient deep neural network architecture to run on an embedded platform in real-time. The proposed model segments navigable space on an image sequence (i.e., a video stream), which is essential for an autonomous vehicle that is based on machine vision. The results demonstrate the performance efficiency of the proposed architecture compared to the existing models and suggest possible improvements that could make the model even more efficient, which is necessary for the future development of the autonomous robotics systems.
Do not let the history haunt you -- Mitigating Compounding Errors in Conversational Question Answering
May 12, 2020
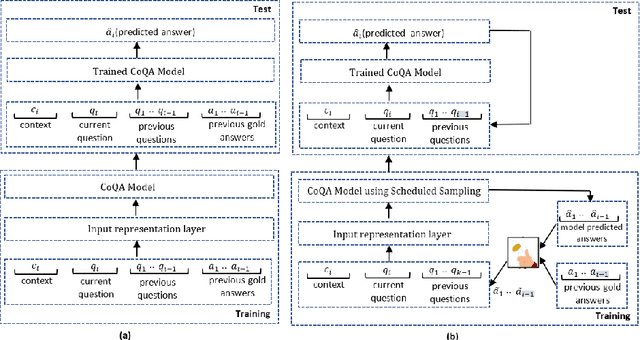

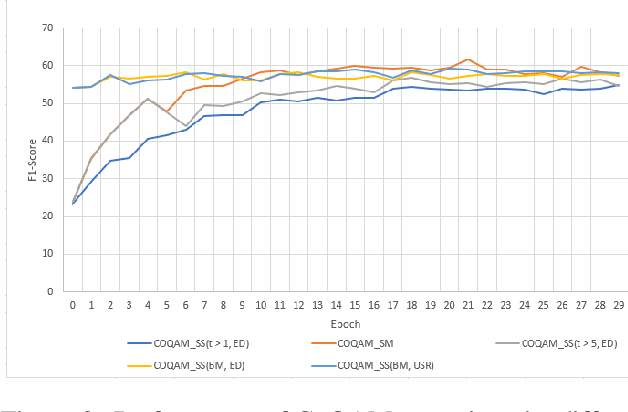
The Conversational Question Answering (CoQA) task involves answering a sequence of inter-related conversational questions about a contextual paragraph. Although existing approaches employ human-written ground-truth answers for answering conversational questions at test time, in a realistic scenario, the CoQA model will not have any access to ground-truth answers for the previous questions, compelling the model to rely upon its own previously predicted answers for answering the subsequent questions. In this paper, we find that compounding errors occur when using previously predicted answers at test time, significantly lowering the performance of CoQA systems. To solve this problem, we propose a sampling strategy that dynamically selects between target answers and model predictions during training, thereby closely simulating the situation at test time. Further, we analyse the severity of this phenomena as a function of the question type, conversation length and domain type.
Progressive Voice Trigger Detection: Accuracy vs Latency
Oct 29, 2020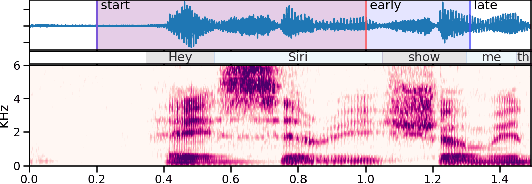
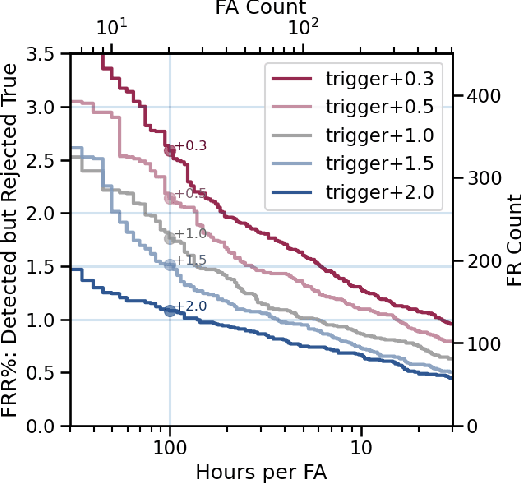
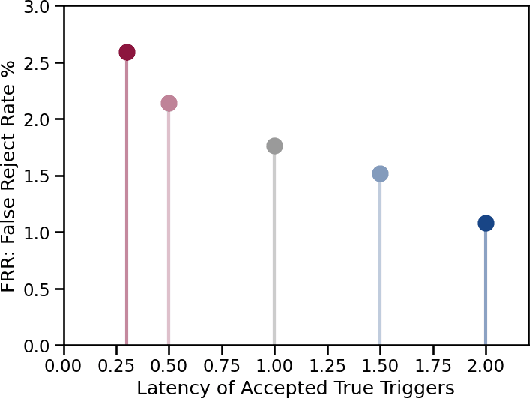
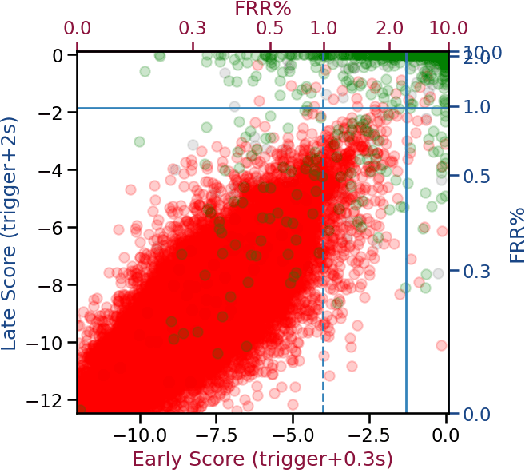
We present an architecture for voice trigger detection for virtual assistants. The main idea in this work is to exploit information in words that immediately follow the trigger phrase. We first demonstrate that by including more audio context after a detected trigger phrase, we can indeed get a more accurate decision. However, waiting to listen to more audio each time incurs a latency increase. Progressive Voice Trigger Detection allows us to trade-off latency and accuracy by accepting clear trigger candidates quickly, but waiting for more context to decide whether to accept more marginal examples. Using a two-stage architecture, we show that by delaying the decision for just 3% of detected true triggers in the test set, we are able to obtain a relative improvement of 66% in false rejection rate, while incurring only a negligible increase in latency.
Time-Dependent Utility and Action Under Uncertainty
Mar 20, 2013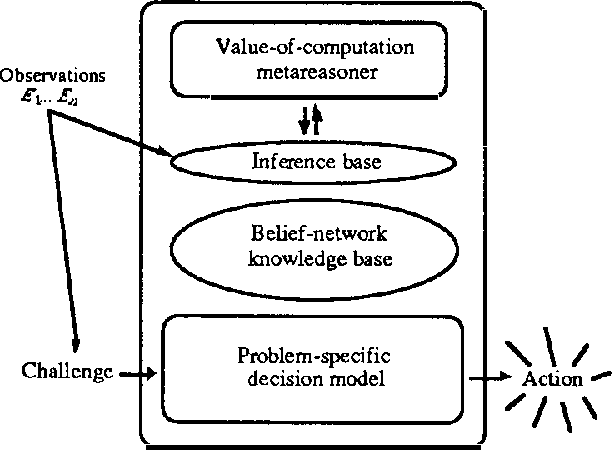
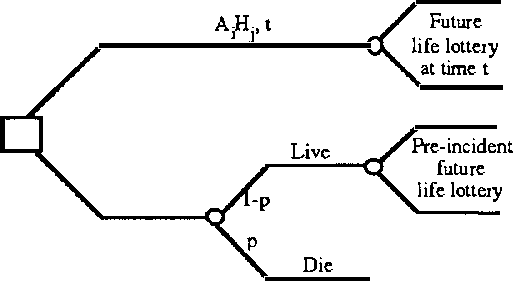
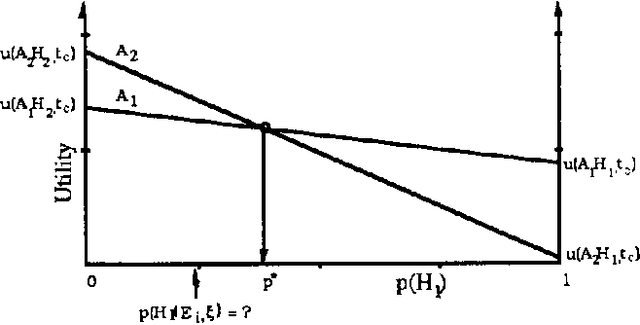
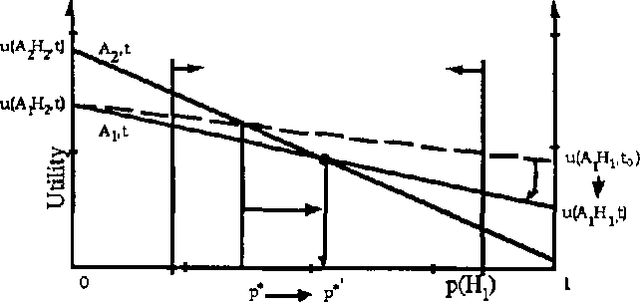
We discuss representing and reasoning with knowledge about the time-dependent utility of an agent's actions. Time-dependent utility plays a crucial role in the interaction between computation and action under bounded resources. We present a semantics for time-dependent utility and describe the use of time-dependent information in decision contexts. We illustrate our discussion with examples of time-pressured reasoning in Protos, a system constructed to explore the ideal control of inference by reasoners with limit abilities.
Model-based Reinforcement Learning from Signal Temporal Logic Specifications
Nov 10, 2020
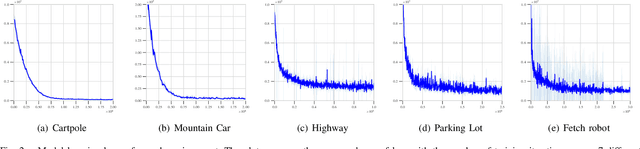

Techniques based on Reinforcement Learning (RL) are increasingly being used to design control policies for robotic systems. RL fundamentally relies on state-based reward functions to encode desired behavior of the robot and bad reward functions are prone to exploitation by the learning agent, leading to behavior that is undesirable in the best case and critically dangerous in the worst. On the other hand, designing good reward functions for complex tasks is a challenging problem. In this paper, we propose expressing desired high-level robot behavior using a formal specification language known as Signal Temporal Logic (STL) as an alternative to reward/cost functions. We use STL specifications in conjunction with model-based learning to design model predictive controllers that try to optimize the satisfaction of the STL specification over a finite time horizon. The proposed algorithm is empirically evaluated on simulations of robotic system such as a pick-and-place robotic arm, and adaptive cruise control for autonomous vehicles.