 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-agent Deep FBSDE Representation For Large Scale Stochastic Differential Games
Nov 21, 2020
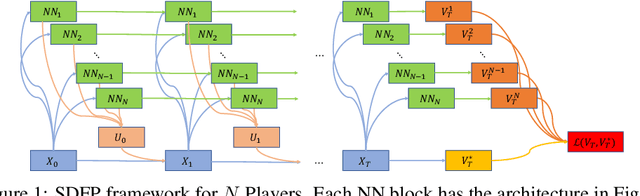

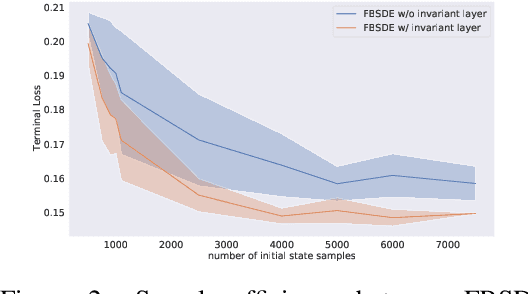
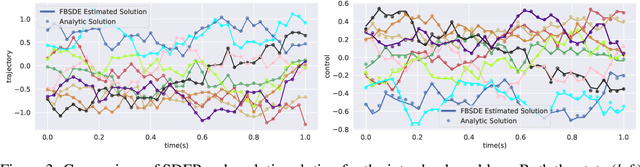
In this paper, we present a deep learning framework for solving large-scale multi-agent non-cooperative stochastic games using fictitious play. The Hamilton-Jacobi-Bellman (HJB) PDE associated with each agent is reformulated into a set of Forward-Backward Stochastic Differential Equations (FBSDEs) and solved via forward sampling on a suitably defined neural network architecture. Decision-making in multi-agent systems suffers from the curse of dimensionality and strategy degeneration as the number of agents and time horizon increase. We propose a novel Deep FBSDE controller framework which is shown to outperform the current state-of-the-art deep fictitious play algorithm on a high dimensional inter-bank lending/borrowing problem. More importantly, our approach mitigates the curse of many agents and reduces computational and memory complexity, allowing us to scale up to 1,000 agents in simulation, a scale which, to the best of our knowledge, represents a new state of the art. Finally, we showcase the framework's applicability in robotics on a belief-space autonomous racing problem.
Logic-guided Semantic Representation Learning for Zero-Shot Relation Classification
Oct 30, 2020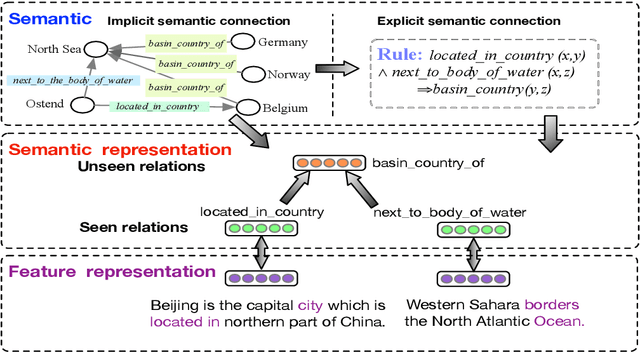
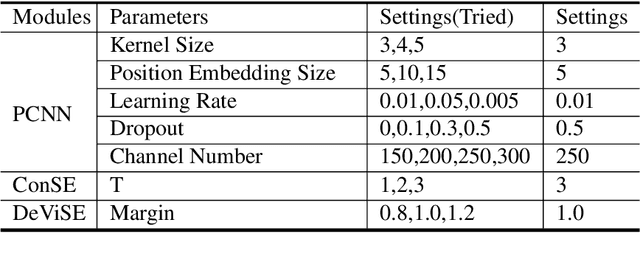
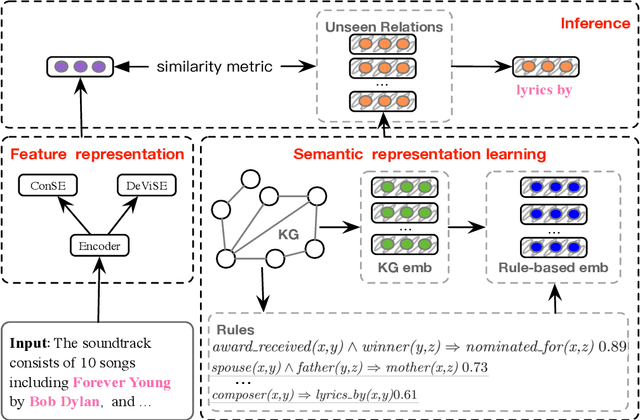
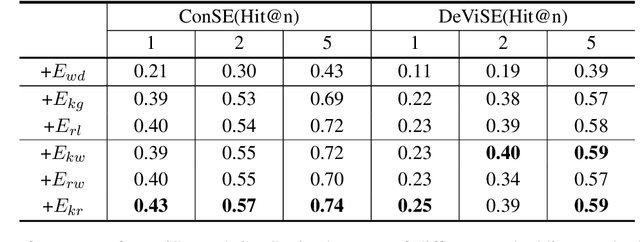
Relation classification aims to extract semantic relations between entity pairs from the sentences. However, most existing methods can only identify seen relation classes that occurred during training. To recognize unseen relations at test time, we explore the problem of zero-shot relation classification. Previous work regards the problem as reading comprehension or textual entailment, which have to rely on artificial descriptive information to improve the understandability of relation types. Thus, rich semantic knowledge of the relation labels is ignored. In this paper, we propose a novel logic-guided semantic representation learning model for zero-shot relation classification. Our approach builds connections between seen and unseen relations via implicit and explicit semantic representations with knowledge graph embeddings and logic rules. Extensive experimental results demonstrate that our method can generalize to unseen relation types and achieve promising improvements.
Weight and Gradient Centralization in Deep Neural Networks
Oct 02, 2020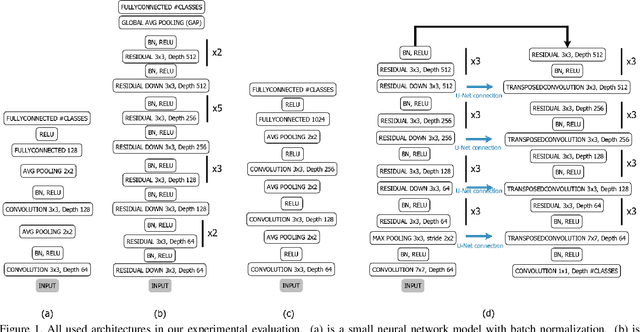
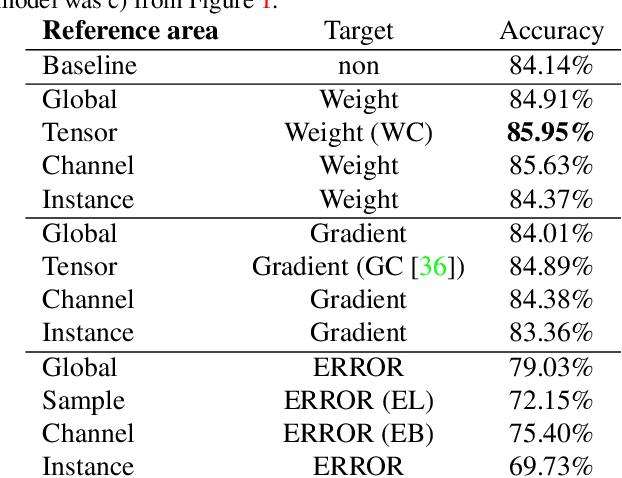
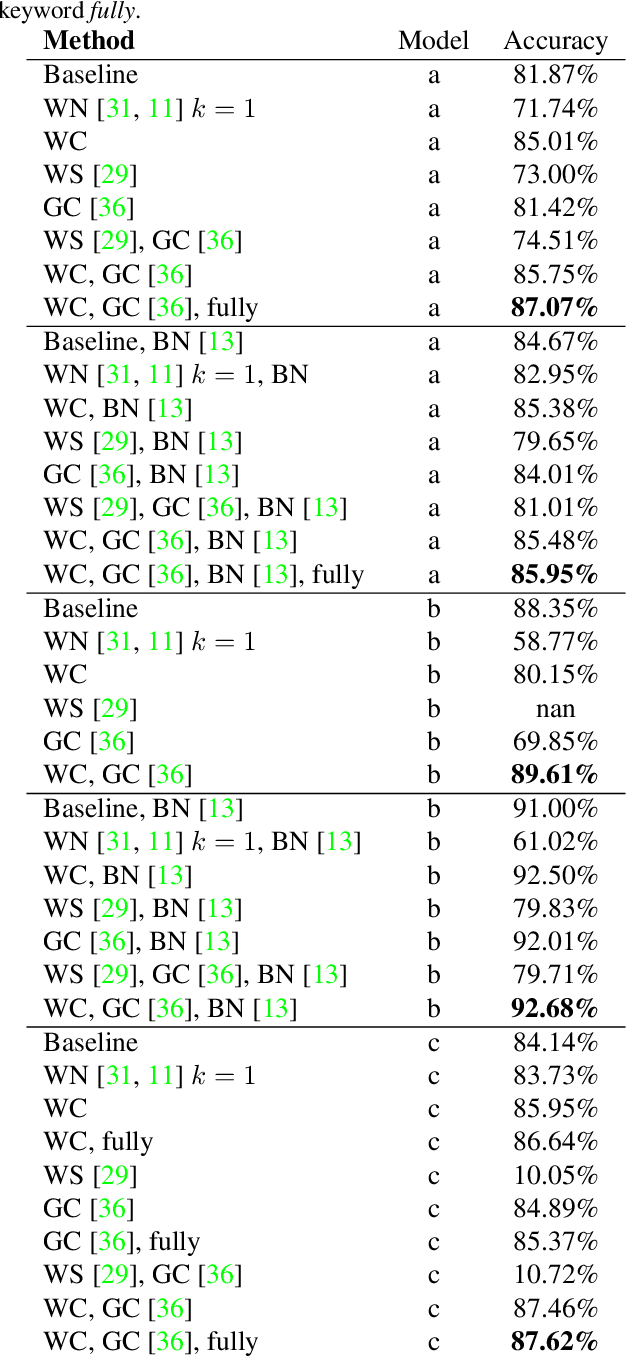
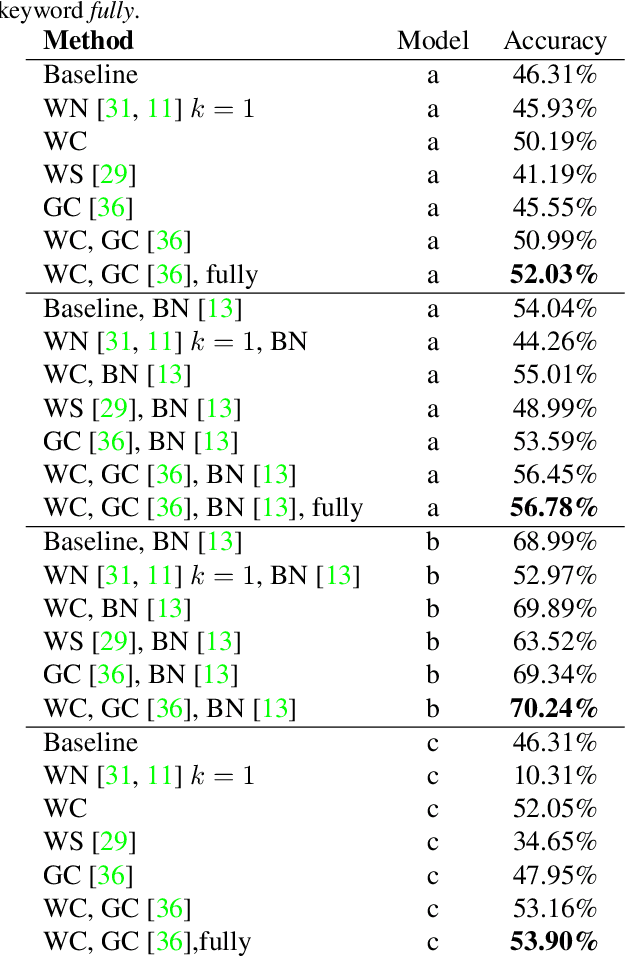
Batch normalization is currently the most widely used variant of internal normalization for deep neural networks. Additional work has shown that the normalization of weights and additional conditioning as well as the normalization of gradients further improve the generalization. In this work, we combine several of these methods and thereby increase the generalization of the networks. The advantage of the newer methods compared to the batch normalization is not only increased generalization, but also that these methods only have to be applied during training and, therefore, do not influence the running time during use. Link to CUDA code https://atreus.informatik.uni-tuebingen.de/seafile/d/8e2ab8c3fdd444e1a135/
Fast and Flexible Temporal Point Processes with Triangular Maps
Jun 22, 2020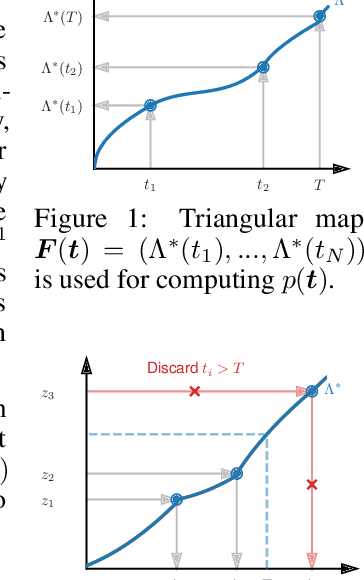



Temporal point process (TPP) models combined with recurrent neural networks provide a powerful framework for modeling continuous-time event data. While such models are flexible, they are inherently sequential and therefore cannot benefit from the parallelism of modern hardware. By exploiting the recent developments in the field of normalizing flows, we design TriTPP -- a new class of non-recurrent TPP models, where both sampling and likelihood computation can be done in parallel. TriTPP matches the flexibility of RNN-based methods but permits orders of magnitude faster sampling. This enables us to use the new model for variational inference in continuous-time discrete-state systems. We demonstrate the advantages of the proposed framework on synthetic and real-world datasets.
Spatio-Temporal Graph Scattering Transform
Dec 10, 2020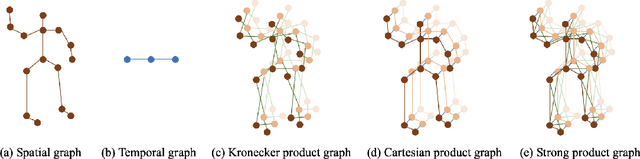
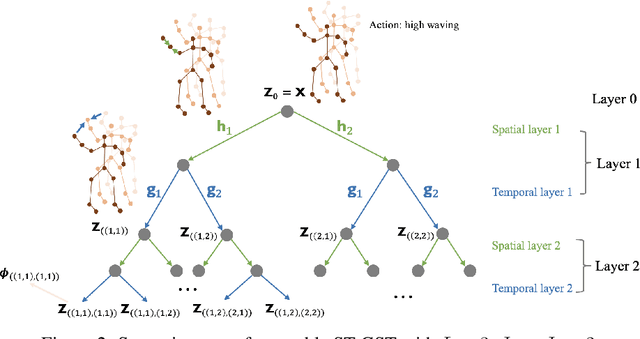

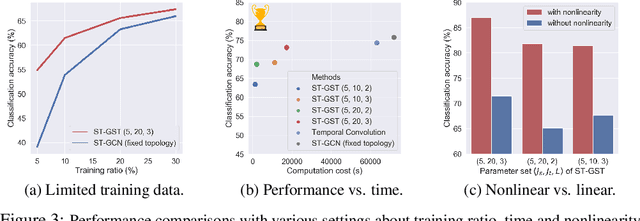
Although spatio-temporal graph neural networks have achieved great empirical success in handling multiple correlated time series, they may be impractical in some real-world scenarios due to a lack of sufficient high-quality training data. Furthermore, spatio-temporal graph neural networks lack theoretical interpretation. To address these issues, we put forth a novel mathematically designed framework to analyze spatio-temporal data. Our proposed spatio-temporal graph scattering transform (ST-GST) extends traditional scattering transforms to the spatio-temporal domain. It performs iterative applications of spatio-temporal graph wavelets and nonlinear activation functions, which can be viewed as a forward pass of spatio-temporal graph convolutional networks without training. Since all the filter coefficients in ST-GST are mathematically designed, it is promising for the real-world scenarios with limited training data, and also allows for a theoretical analysis, which shows that the proposed ST-GST is stable to small perturbations of input signals and structures. Finally, our experiments show that i) ST-GST outperforms spatio-temporal graph convolutional networks by an increase of 35% in accuracy for MSR Action3D dataset; ii) it is better and computationally more efficient to design the transform based on separable spatio-temporal graphs than the joint ones; and iii) the nonlinearity in ST-GST is critical to empirical performance.
DETECT: A Hierarchical Clustering Algorithm for Behavioural Trends in Temporal Educational Data
May 04, 2020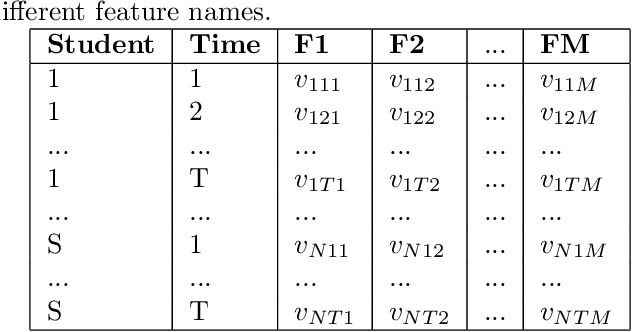

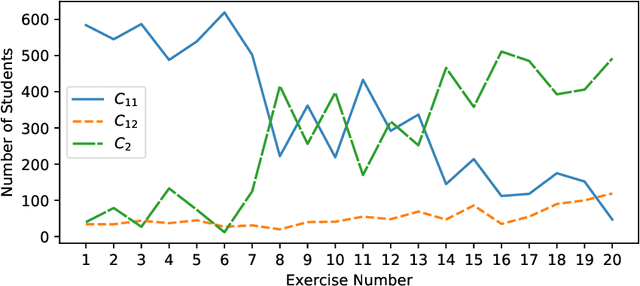
Techniques for clustering student behaviour offer many opportunities to improve educational outcomes by providing insight into student learning. However, one important aspect of student behaviour, namely its evolution over time, can often be challenging to identify using existing methods. This is because the objective functions used by these methods do not explicitly aim to find cluster trends in time, so these trends may not be clearly represented in the results. This paper presents `DETECT' (Detection of Educational Trends Elicited by Clustering Time-series data), a novel divisive hierarchical clustering algorithm that incorporates temporal information into its objective function to prioritise the detection of behavioural trends. The resulting clusters are similar in structure to a decision tree, with a hierarchy of clusters defined by decision rules on features. DETECT is easy to apply, highly customisable, applicable to a wide range of educational datasets and yields easily interpretable results. Through a case study of two online programming courses (N>600), this paper demonstrates two example applications of DETECT: 1) to identify how cohort behaviour develops over time and 2) to identify student behaviours that characterise exercises where many students give up.
AiDroid: When Heterogeneous Information Network Marries Deep Neural Network for Real-time Android Malware Detection
Nov 02, 2018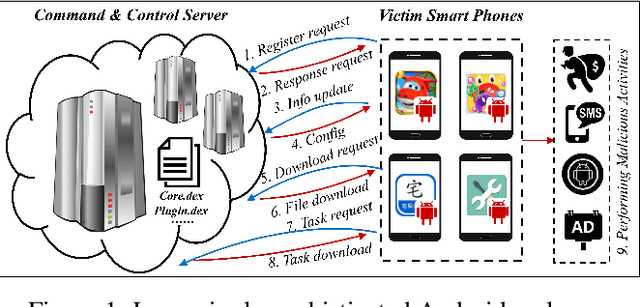
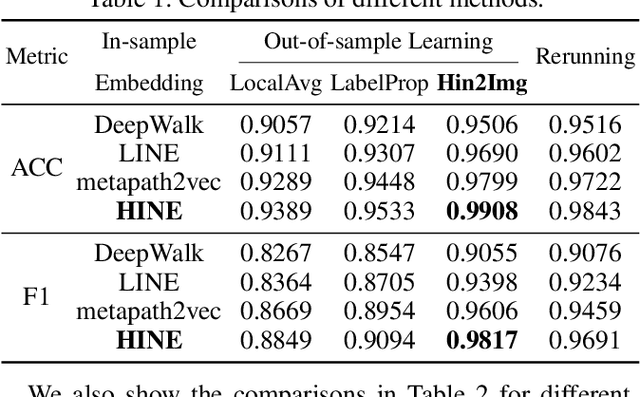
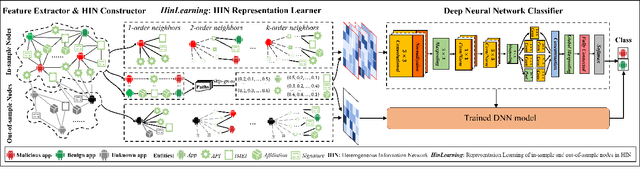
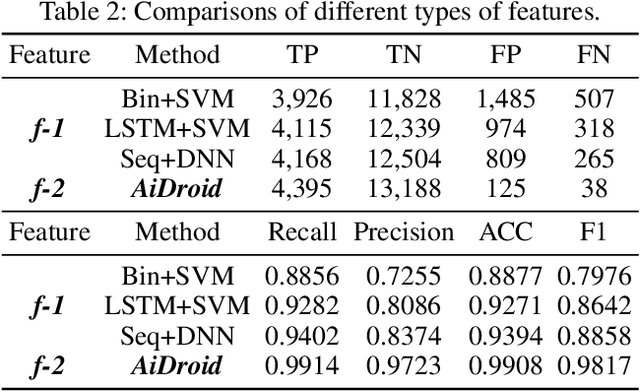
The explosive growth and increasing sophistication of Android malware call for new defensive techniques that are capable of protecting mobile users against novel threats. In this paper, we first extract the runtime Application Programming Interface (API) call sequences from Android apps, and then analyze higher-level semantic relations within the ecosystem to comprehensively characterize the apps. To model different types of entities (i.e., app, API, IMEI, signature, affiliation) and the rich semantic relations among them, we then construct a structural heterogeneous information network (HIN) and present meta-path based approach to depict the relatedness over apps. To efficiently classify nodes (e.g., apps) in the constructed HIN, we propose the HinLearning method to first obtain in-sample node embeddings and then learn representations of out-of-sample nodes without rerunning/adjusting HIN embeddings at the first attempt. Afterwards, we design a deep neural network (DNN) classifier taking the learned HIN representations as inputs for Android malware detection. A comprehensive experimental study on the large-scale real sample collections from Tencent Security Lab is performed to compare various baselines. Promising experimental results demonstrate that our developed system AiDroid which integrates our proposed method outperforms others in real-time Android malware detection. AiDroid has already been incorporated into Tencent Mobile Security product that serves millions of users worldwide.
Streaming Graph Neural Networks via Continual Learning
Sep 23, 2020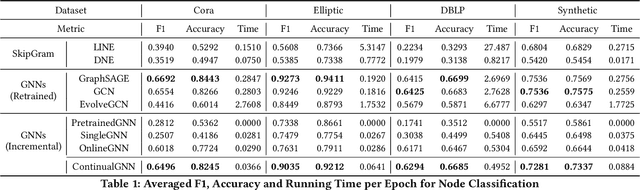
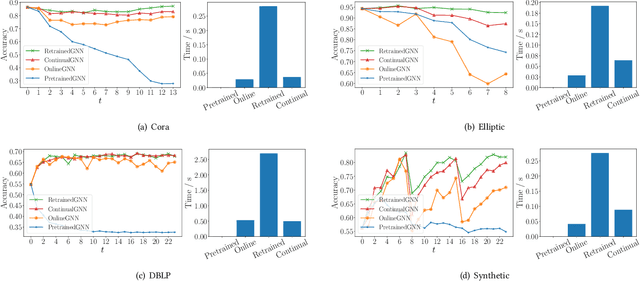
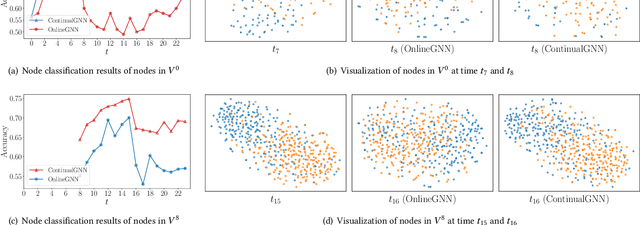
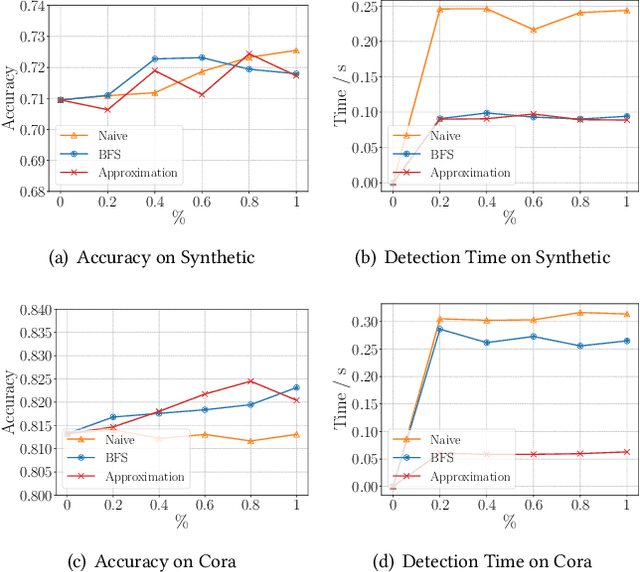
Graph neural networks (GNNs) have achieved strong performance in various applications. In the real world, network data is usually formed in a streaming fashion. The distributions of patterns that refer to neighborhood information of nodes may shift over time. The GNN model needs to learn the new patterns that cannot yet be captured. But learning incrementally leads to the catastrophic forgetting problem that historical knowledge is overwritten by newly learned knowledge. Therefore, it is important to train GNN model to learn new patterns and maintain existing patterns simultaneously, which few works focus on. In this paper, we propose a streaming GNN model based on continual learning so that the model is trained incrementally and up-to-date node representations can be obtained at each time step. Firstly, we design an approximation algorithm to detect new coming patterns efficiently based on information propagation. Secondly, we combine two perspectives of data replaying and model regularization for existing pattern consolidation. Specially, a hierarchy-importance sampling strategy for nodes is designed and a weighted regularization term for GNN parameters is derived, achieving greater stability and generalization of knowledge consolidation. Our model is evaluated on real and synthetic data sets and compared with multiple baselines. The results of node classification prove that our model can efficiently update model parameters and achieve comparable performance to model retraining. In addition, we also conduct a case study on the synthetic data, and carry out some specific analysis for each part of our model, illustrating its ability to learn new knowledge and maintain existing knowledge from different perspectives.
Hold Tight and Never Let Go: Security of Deep Learning based Automated Lane Centering under Physical-World Attack
Sep 14, 2020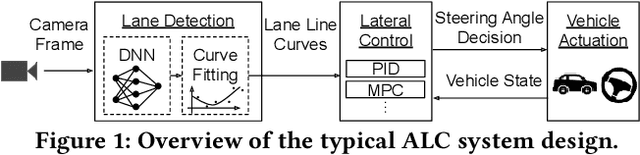


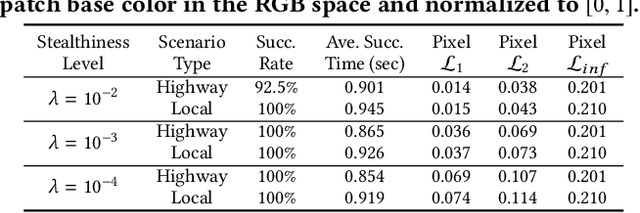
Automated Lane Centering (ALC) systems are convenient and widely deployed today, but also highly security and safety critical. In this work, we are the first to systematically study the security of state-of-the-art deep learning based ALC systems in their designed operational domains under physical-world adversarial attacks. We formulate the problem with a safety-critical attack goal, and a novel and domain-specific attack vector: dirty road patches. To systematically generate the attack, we adopt an optimization-based approach and overcome domain-specific design challenges such as camera frame inter-dependencies due to dynamic vehicle actuation, and the lack of objective function design for lane detection models. We evaluate our attack method on a production ALC system using 80 attack scenarios from real-world driving traces. The results show that our attack is highly effective with over 92% success rates and less than 0.95 sec average success time, which is substantially lower than the average driver reaction time. Such high attack effectiveness is also found (1) robust to motion model inaccuracies, different lane detection model designs, and physical-world factors, and (2) stealthy from the driver's view. To concretely understand the end-to-end safety consequences, we further evaluate on concrete real-world attack scenarios using a production-grade simulator, and find that our attack can successfully cause the victim to hit the highway concrete barrier or a truck in the opposite direction with 98% and 100% success rates. We also discuss defense directions.
Occlusion-Aware Search for Object Retrieval in Clutter
Nov 10, 2020

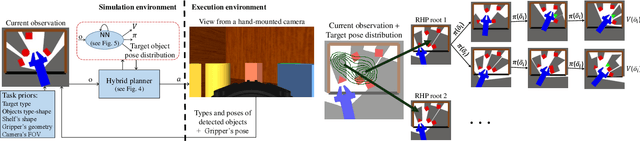

We address the manipulation task of retrieving a target object from a cluttered shelf. When the target object is hidden, the robot must search through the clutter for retrieving it. Solving this task requires reasoning over the likely locations of the target object. It also requires physics reasoning over multi-object interactions and future occlusions. In this work, we present a data-driven approach for generating occlusion-aware actions in closed-loop. We present a hybrid planner that explores likely states generated from a learned distribution over the location of the target object. The search is guided by a heuristic trained with reinforcement learning to evaluate occluded observations. We evaluate our approach in different environments with varying clutter densities and physics parameters. The results validate that our approach can search and retrieve a target object in different physics environments, while only being trained in simulation. It achieves near real-time behaviour with a success rate exceeding 88%.