 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Accounting for Human Learning when Inferring Human Preferences
Nov 11, 2020
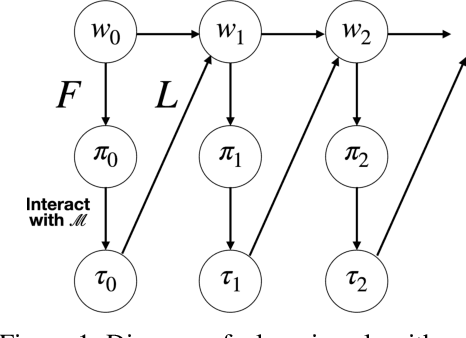
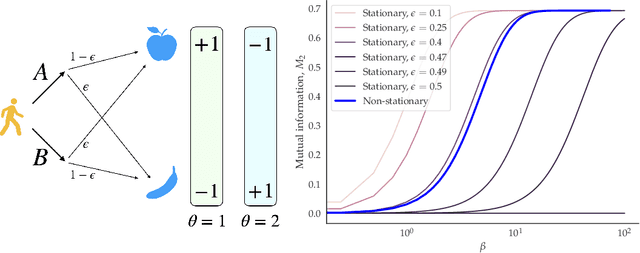
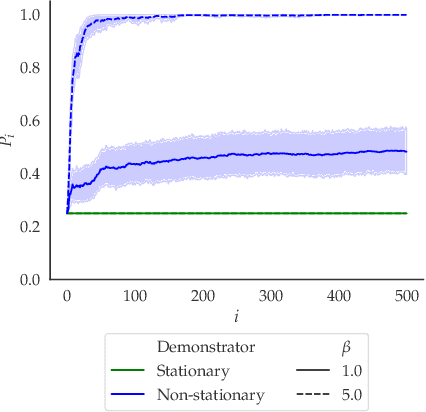
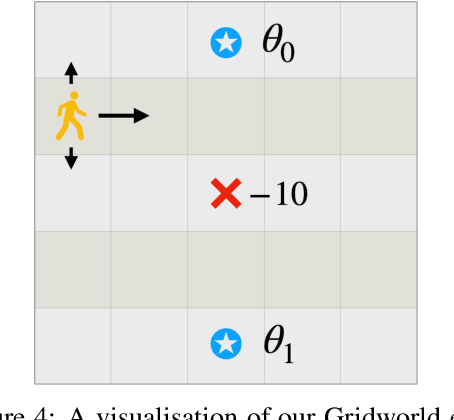
Inverse reinforcement learning (IRL) is a common technique for inferring human preferences from data. Standard IRL techniques tend to assume that the human demonstrator is stationary, that is that their policy $\pi$ doesn't change over time. In practice, humans interacting with a novel environment or performing well on a novel task will change their demonstrations as they learn more about the environment or task. We investigate the consequences of relaxing this assumption of stationarity, in particular by modelling the human as learning. Surprisingly, we find in some small examples that this can lead to better inference than if the human was stationary. That is, by observing a demonstrator who is themselves learning, a machine can infer more than by observing a demonstrator who is noisily rational. In addition, we find evidence that misspecification can lead to poor inference, suggesting that modelling human learning is important, especially when the human is facing an unfamiliar environment.
Adaptive Submodular Meta-Learning
Dec 11, 2020Meta-Learning has gained increasing attention in the machine learning and artificial intelligence communities. In this paper, we introduce and study an adaptive submodular meta-learning problem. The input of our problem is a set of items, where each item has a random state which is initially unknown. The only way to observe an item's state is to select that item. Our objective is to adaptively select a group of items that achieve the best performance over a set of tasks, where each task is represented as an adaptive monotone and submodular function that maps sets of items and their states to a real number. To reduce the computational cost while maintaining a personalized solution for each future task, we first select a initial solution set based on previously observed tasks, then adaptively add the remaining items to the initial set when a new task arrives. As compared to the solution where a brand new solution is computed for each new task, our meta-learning based approach leads to lower computational overhead at test time since the initial solution set is pre-computed in the training stage. To solve this problem, we propose a two-phase greedy policy and show that it achieves a $\frac{e-1}{2e-1}$ approximation ratio.
Diffusion is All You Need for Learning on Surfaces
Dec 01, 2020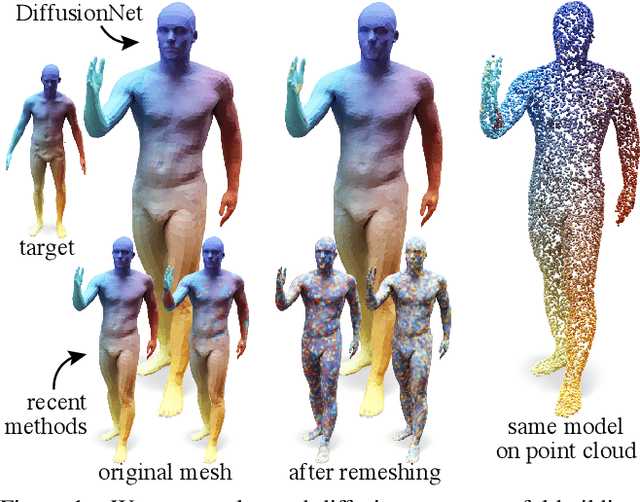

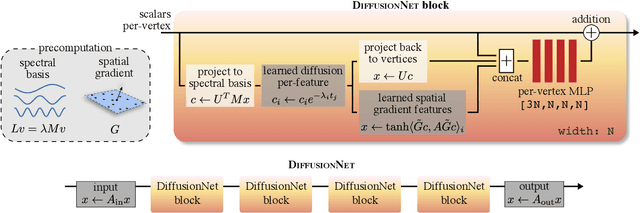
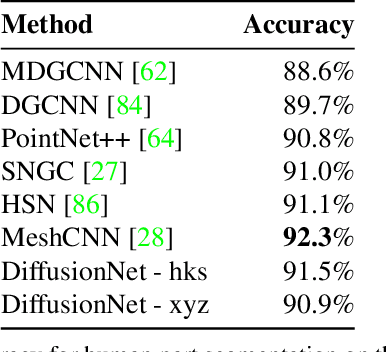
We introduce a new approach to deep learning on 3D surfaces such as meshes or point clouds. Our key insight is that a simple learned diffusion layer can spatially share data in a principled manner, replacing operations like convolution and pooling which are complicated and expensive on surfaces. The only other ingredients in our network are a spatial gradient operation, which uses dot-products of derivatives to encode tangent-invariant filters, and a multi-layer perceptron applied independently at each point. The resulting architecture, which we call DiffusionNet, is remarkably simple, efficient, and scalable. Continuously optimizing for spatial support avoids the need to pick neighborhood sizes or filter widths a priori, or worry about their impact on network size/training time. Furthermore, the principled, geometric nature of these networks makes them agnostic to the underlying representation and insensitive to discretization. In practice, this means significant robustness to mesh sampling, and even the ability to train on a mesh and evaluate on a point cloud. Our experiments demonstrate that these networks achieve state-of-the-art results for a variety of tasks on both meshes and point clouds, including surface classification, segmentation, and non-rigid correspondence.
Controlling the Risk of Conversational Search via Reinforcement Learning
Jan 15, 2021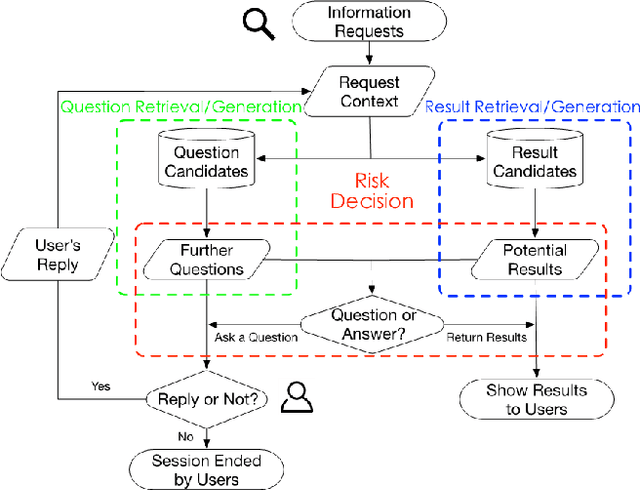

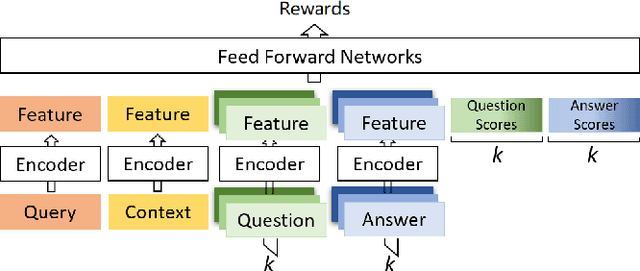
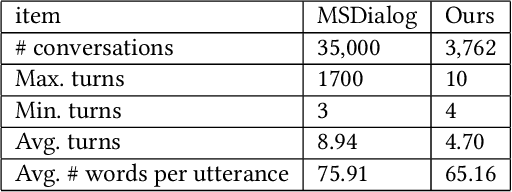
Users often formulate their search queries with immature language without well-developed keywords and complete structures. Such queries fail to express their true information needs and raise ambiguity as fragmental language often yield various interpretations and aspects. This gives search engines a hard time processing and understanding the query, and eventually leads to unsatisfactory retrieval results. An alternative approach to direct answer while facing an ambiguous query is to proactively ask clarifying questions to the user. Recent years have seen many works and shared tasks from both NLP and IR community about identifying the need for asking clarifying question and methodology to generate them. An often neglected fact by these works is that although sometimes the need for clarifying questions is correctly recognized, the clarifying questions these system generate are still off-topic and dissatisfaction provoking to users and may just cause users to leave the conversation. In this work, we propose a risk-aware conversational search agent model to balance the risk of answering user's query and asking clarifying questions. The agent is fully aware that asking clarifying questions can potentially collect more information from user, but it will compare all the choices it has and evaluate the risks. Only after then, it will make decision between answering or asking. To demonstrate that our system is able to retrieve better answers, we conduct experiments on the MSDialog dataset which contains real-world customer service conversations from Microsoft products community. We also purpose a reinforcement learning strategy which allows us to train our model on the original dataset directly and saves us from any further data annotation efforts. Our experiment results show that our risk-aware conversational search agent is able to significantly outperform strong non-risk-aware baselines.
A computationally efficient reconstruction algorithm for circular cone-beam computed tomography using shallow neural networks
Oct 01, 2020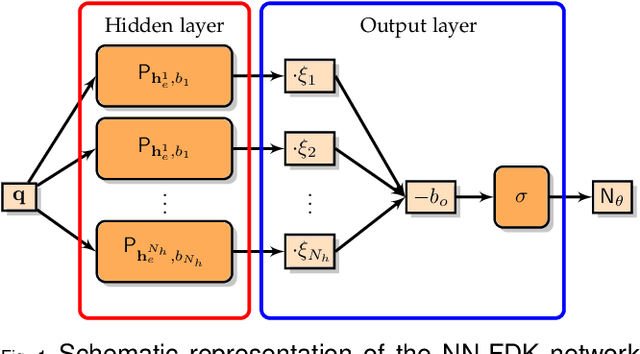
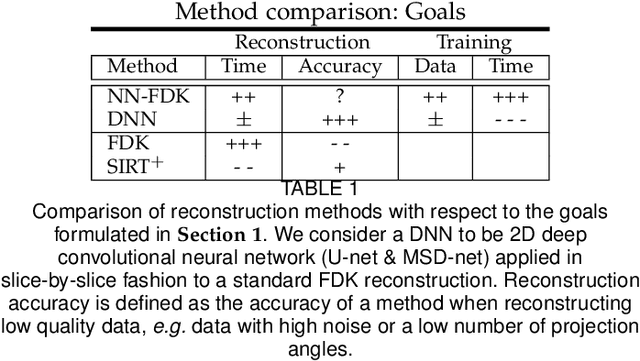
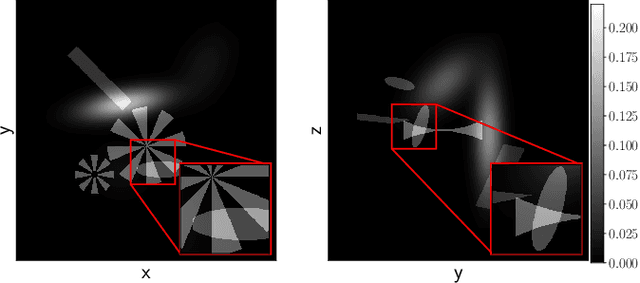
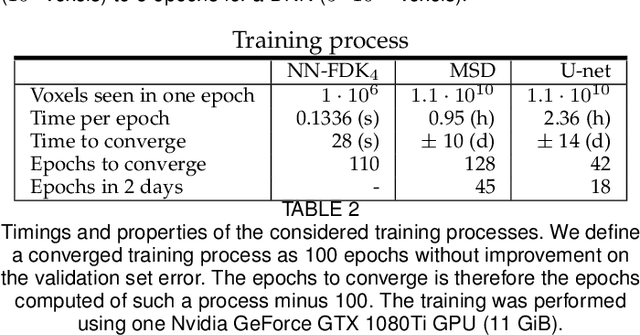
Circular cone-beam (CCB) Computed Tomography (CT) has become an integral part of industrial quality control, materials science and medical imaging. The need to acquire and process each scan in a short time naturally leads to trade-offs between speed and reconstruction quality, creating a need for fast reconstruction algorithms capable of creating accurate reconstructions from limited data. In this paper we introduce the Neural Network Feldkamp-Davis-Kress (NN-FDK) algorithm. This algorithm adds a machine learning component to the FDK algorithm to improve its reconstruction accuracy while maintaining its computational efficiency. Moreover, the NN-FDK algorithm is designed such that it has low training data requirements and is fast to train. This ensures that the proposed algorithm can be used to improve image quality in high throughput CT scanning settings, where FDK is currently used to keep pace with the acquisition speed using readily available computational resources. We compare the NN-FDK algorithm to two standard CT reconstruction algorithms and to two popular deep neural networks trained to remove reconstruction artifacts from the 2D slices of an FDK reconstruction. We show that the NN-FDK reconstruction algorithm is substantially faster in computing a reconstruction than all the tested alternative methods except for the standard FDK algorithm and we show it can compute accurate CCB CT reconstructions in cases of high noise, a low number of projection angles or large cone angles. Moreover, we show that the training time of an NN-FDK network is orders of magnitude lower than the considered deep neural networks, with only a slight reduction in reconstruction accuracy.
Towards Safe Policy Improvement for Non-Stationary MDPs
Oct 23, 2020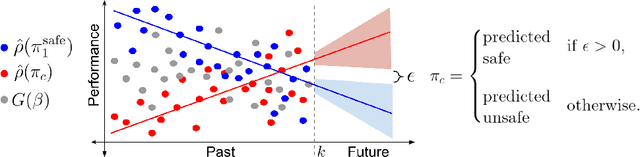
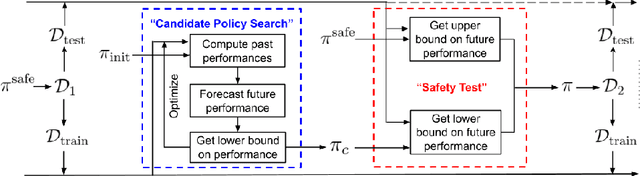

Many real-world sequential decision-making problems involve critical systems with financial risks and human-life risks. While several works in the past have proposed methods that are safe for deployment, they assume that the underlying problem is stationary. However, many real-world problems of interest exhibit non-stationarity, and when stakes are high, the cost associated with a false stationarity assumption may be unacceptable. We take the first steps towards ensuring safety, with high confidence, for smoothly-varying non-stationary decision problems. Our proposed method extends a type of safe algorithm, called a Seldonian algorithm, through a synthesis of model-free reinforcement learning with time-series analysis. Safety is ensured using sequential hypothesis testing of a policy's forecasted performance, and confidence intervals are obtained using wild bootstrap.
A Three-Stage Self-Training Framework for Semi-Supervised Semantic Segmentation
Dec 01, 2020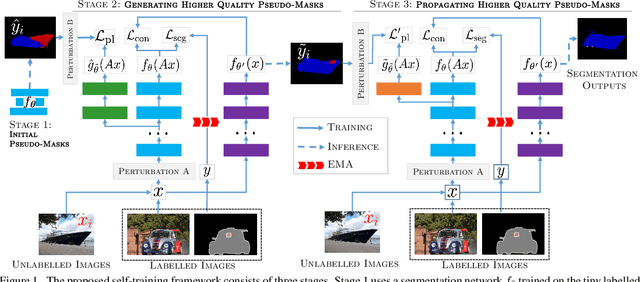
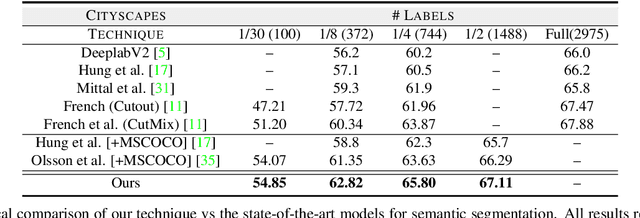
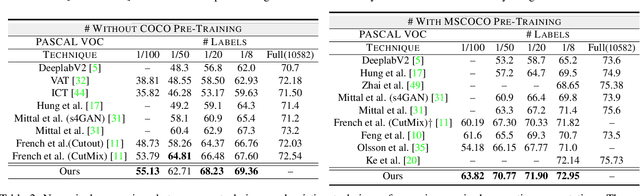

Semantic segmentation has been widely investigated in the community, in which the state of the art techniques are based on supervised models. Those models have reported unprecedented performance at the cost of requiring a large set of high quality segmentation masks. To obtain such annotations is highly expensive and time consuming, in particular, in semantic segmentation where pixel-level annotations are required. In this work, we address this problem by proposing a holistic solution framed as a three-stage self-training framework for semi-supervised semantic segmentation. The key idea of our technique is the extraction of the pseudo-masks statistical information to decrease uncertainty in the predicted probability whilst enforcing segmentation consistency in a multi-task fashion. We achieve this through a three-stage solution. Firstly, we train a segmentation network to produce rough pseudo-masks which predicted probability is highly uncertain. Secondly, we then decrease the uncertainty of the pseudo-masks using a multi-task model that enforces consistency whilst exploiting the rich statistical information of the data. We compare our approach with existing methods for semi-supervised semantic segmentation and demonstrate its state-of-the-art performance with extensive experiments.
Multi-agent Deep FBSDE Representation For Large Scale Stochastic Differential Games
Nov 21, 2020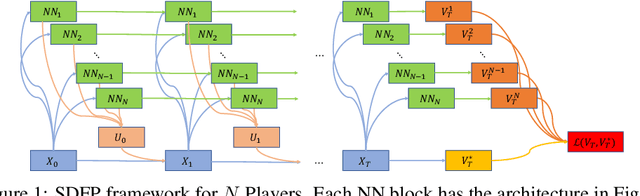

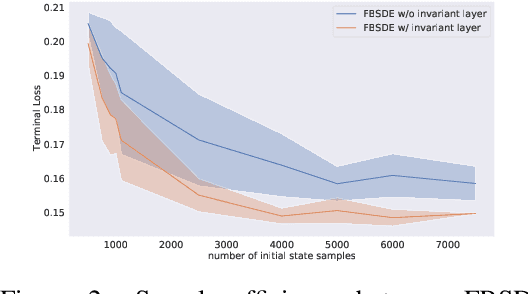
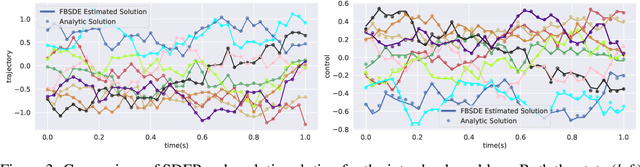
In this paper, we present a deep learning framework for solving large-scale multi-agent non-cooperative stochastic games using fictitious play. The Hamilton-Jacobi-Bellman (HJB) PDE associated with each agent is reformulated into a set of Forward-Backward Stochastic Differential Equations (FBSDEs) and solved via forward sampling on a suitably defined neural network architecture. Decision-making in multi-agent systems suffers from the curse of dimensionality and strategy degeneration as the number of agents and time horizon increase. We propose a novel Deep FBSDE controller framework which is shown to outperform the current state-of-the-art deep fictitious play algorithm on a high dimensional inter-bank lending/borrowing problem. More importantly, our approach mitigates the curse of many agents and reduces computational and memory complexity, allowing us to scale up to 1,000 agents in simulation, a scale which, to the best of our knowledge, represents a new state of the art. Finally, we showcase the framework's applicability in robotics on a belief-space autonomous racing problem.
DMD: A Large-Scale Multi-Modal Driver Monitoring Dataset for Attention and Alertness Analysis
Aug 27, 2020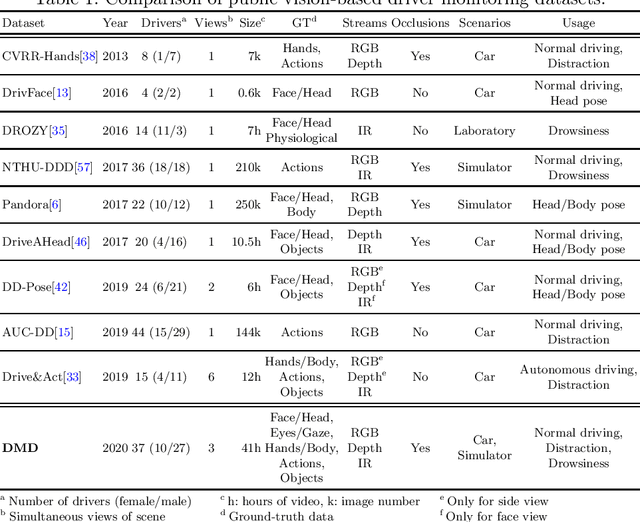
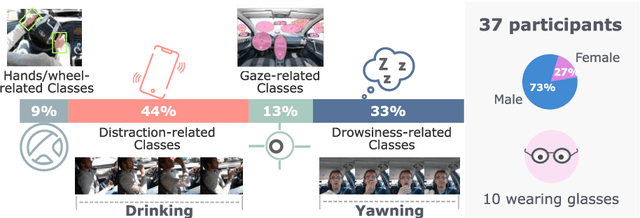
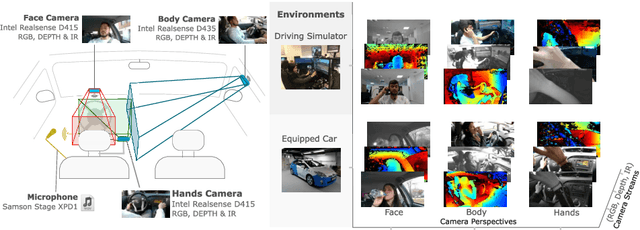

Vision is the richest and most cost-effective technology for Driver Monitoring Systems (DMS), especially after the recent success of Deep Learning (DL) methods. The lack of sufficiently large and comprehensive datasets is currently a bottleneck for the progress of DMS development, crucial for the transition of automated driving from SAE Level-2 to SAE Level-3. In this paper, we introduce the Driver Monitoring Dataset (DMD), an extensive dataset which includes real and simulated driving scenarios: distraction, gaze allocation, drowsiness, hands-wheel interaction and context data, in 41 hours of RGB, depth and IR videos from 3 cameras capturing face, body and hands of 37 drivers. A comparison with existing similar datasets is included, which shows the DMD is more extensive, diverse, and multi-purpose. The usage of the DMD is illustrated by extracting a subset of it, the dBehaviourMD dataset, containing 13 distraction activities, prepared to be used in DL training processes. Furthermore, we propose a robust and real-time driver behaviour recognition system targeting a real-world application that can run on cost-efficient CPU-only platforms, based on the dBehaviourMD. Its performance is evaluated with different types of fusion strategies, which all reach enhanced accuracy still providing real-time response.
Logic-guided Semantic Representation Learning for Zero-Shot Relation Classification
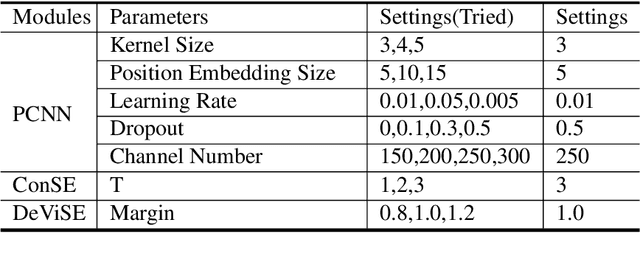
Oct 30, 2020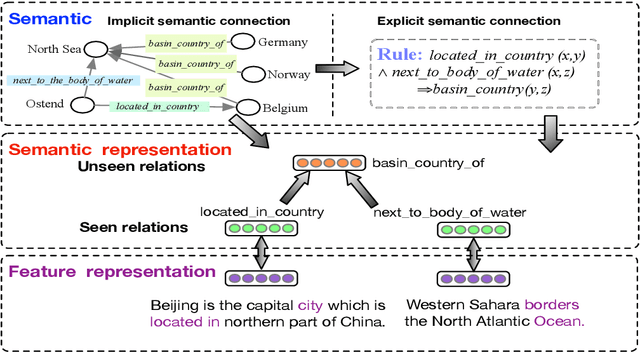
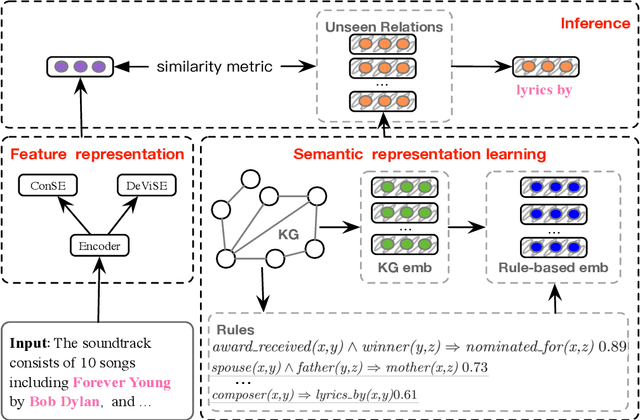
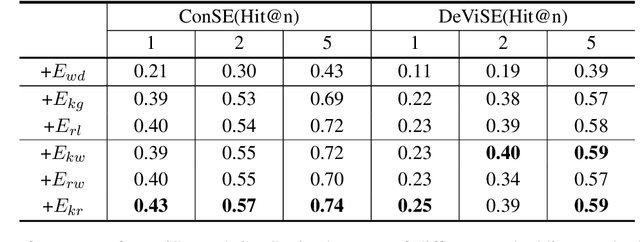
Relation classification aims to extract semantic relations between entity pairs from the sentences. However, most existing methods can only identify seen relation classes that occurred during training. To recognize unseen relations at test time, we explore the problem of zero-shot relation classification. Previous work regards the problem as reading comprehension or textual entailment, which have to rely on artificial descriptive information to improve the understandability of relation types. Thus, rich semantic knowledge of the relation labels is ignored. In this paper, we propose a novel logic-guided semantic representation learning model for zero-shot relation classification. Our approach builds connections between seen and unseen relations via implicit and explicit semantic representations with knowledge graph embeddings and logic rules. Extensive experimental results demonstrate that our method can generalize to unseen relation types and achieve promising improvements.