 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Vision-based flocking in outdoor environments
Dec 02, 2020
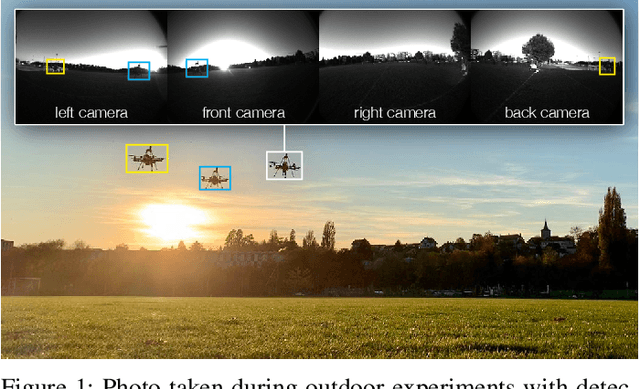
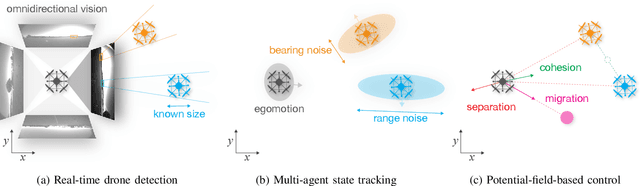
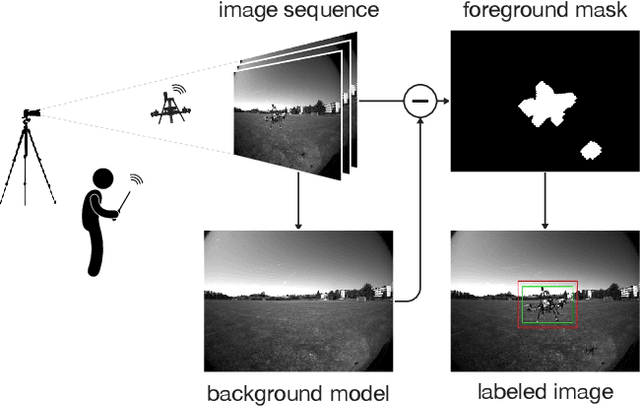

Deployment of drone swarms usually relies on inter-agent communication or visual markers that are mounted on the vehicles to simplify their mutual detection. This letter proposes a vision-based detection and tracking algorithm that enables groups of drones to navigate without communication or visual markers. We employ a convolutional neural network to detect and localize nearby agents onboard the quadcopters in real-time. Rather than manually labeling a dataset, we automatically annotate images to train the neural network using background subtraction by systematically flying a quadcopter in front of a static camera. We use a multi-agent state tracker to estimate the relative positions and velocities of nearby agents, which are subsequently fed to a flocking algorithm for high-level control. The drones are equipped with multiple cameras to provide omnidirectional visual inputs. The camera setup ensures the safety of the flock by avoiding blind spots regardless of the agent configuration. We evaluate the approach with a group of three real quadcopters that are controlled using the proposed vision-based flocking algorithm. The results show that the drones can safely navigate in an outdoor environment despite substantial background clutter and difficult lighting conditions.
A Population-based Hybrid Approach to Hyperparameter Optimization for Neural Networks
Nov 22, 2020
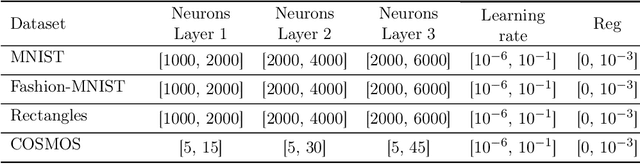
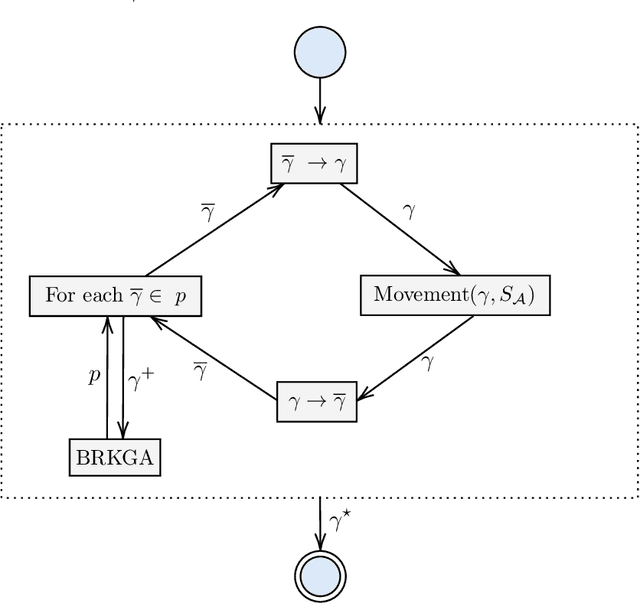

In recent years, large amounts of data have been generated, and computer power has kept growing. This scenario has led to a resurgence in the interest in artificial neural networks. One of the main challenges in training effective neural network models is finding the right combination of hyperparameters to be used. Indeed, the choice of an adequate approach to search the hyperparameter space directly influences the accuracy of the resulting neural network model. Common approaches for hyperparameter optimization are Grid Search, Random Search, and Bayesian Optimization. There are also population-based methods such as CMA-ES. In this paper, we present HBRKGA, a new population-based approach for hyperparameter optimization. HBRKGA is a hybrid approach that combines the Biased Random Key Genetic Algorithm with a Random Walk technique to search the hyperparameter space efficiently. Several computational experiments on eight different datasets were performed to assess the effectiveness of the proposed approach. Results showed that HBRKGA could find hyperparameter configurations that outperformed (in terms of predictive quality) the baseline methods in six out of eight datasets while showing a reasonable execution time.
Message Passing Adaptive Resonance Theory for Online Active Semi-supervised Learning
Dec 02, 2020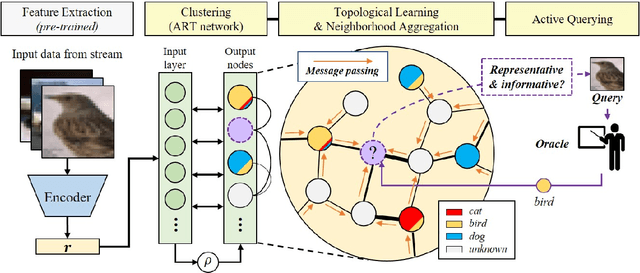
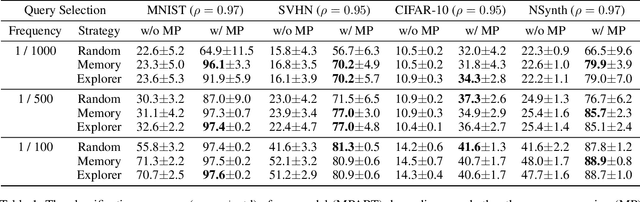

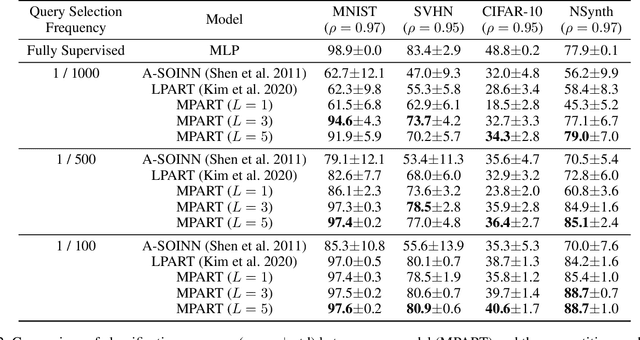
Active learning is widely used to reduce labeling effort and training time by repeatedly querying only the most beneficial samples from unlabeled data. In real-world problems where data cannot be stored indefinitely due to limited storage or privacy issues, the query selection and the model update should be performed as soon as a new data sample is observed. Various online active learning methods have been studied to deal with these challenges; however, there are difficulties in selecting representative query samples and updating the model efficiently. In this study, we propose Message Passing Adaptive Resonance Theory (MPART) for online active semi-supervised learning. The proposed model learns the distribution and topology of the input data online. It then infers the class of unlabeled data and selects informative and representative samples through message passing between nodes on the topological graph. MPART queries the beneficial samples on-the-fly in stream-based selective sampling scenarios, and continuously improve the classification model using both labeled and unlabeled data. We evaluate our model on visual (MNIST, SVHN, CIFAR-10) and audio (NSynth) datasets with comparable query selection strategies and frequencies, showing that MPART significantly outperforms the competitive models in online active learning environments.
Nearly Optimal Variational Inference for High Dimensional Regression with Shrinkage Priors
Oct 24, 2020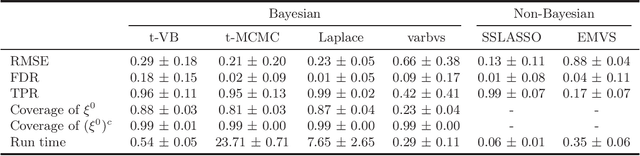
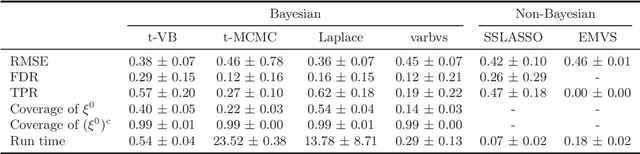
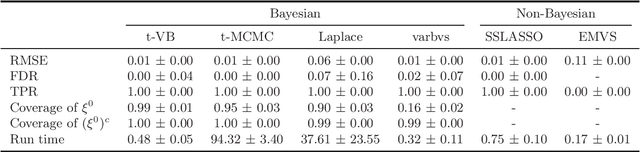
We propose a variational Bayesian (VB) procedure for high-dimensional linear model inferences with heavy tail shrinkage priors, such as student-t prior. Theoretically, we establish the consistency of the proposed VB method and prove that under the proper choice of prior specifications, the contraction rate of the VB posterior is nearly optimal. It justifies the validity of VB inference as an alternative of Markov Chain Monte Carlo (MCMC) sampling. Meanwhile, comparing to conventional MCMC methods, the VB procedure achieves much higher computational efficiency, which greatly alleviates the computing burden for modern machine learning applications such as massive data analysis. Through numerical studies, we demonstrate that the proposed VB method leads to shorter computing time, higher estimation accuracy, and lower variable selection error than competitive sparse Bayesian methods.
Unifying Homophily and Heterophily Network Transformation via Motifs
Dec 27, 2020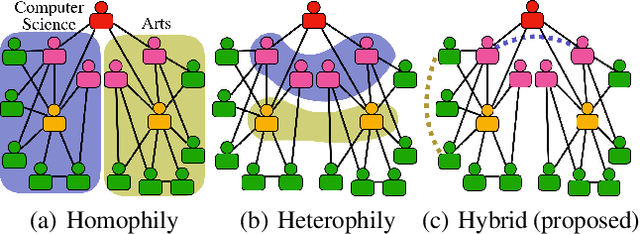

Higher-order proximity (HOP) is fundamental for most network embedding methods due to its significant effects on the quality of node embedding and performance on downstream network analysis tasks. Most existing HOP definitions are based on either homophily to place close and highly interconnected nodes tightly in embedding space or heterophily to place distant but structurally similar nodes together after embedding. In real-world networks, both can co-exist, and thus considering only one could limit the prediction performance and interpretability. However, there is no general and universal solution that takes both into consideration. In this paper, we propose such a simple yet powerful framework called homophily and heterophliy preserving network transformation (H2NT) to capture HOP that flexibly unifies homophily and heterophily. Specifically, H2NT utilises motif representations to transform a network into a new network with a hybrid assumption via micro-level and macro-level walk paths. H2NT can be used as an enhancer to be integrated with any existing network embedding methods without requiring any changes to latter methods. Because H2NT can sparsify networks with motif structures, it can also improve the computational efficiency of existing network embedding methods when integrated. We conduct experiments on node classification, structural role classification and motif prediction to show the superior prediction performance and computational efficiency over state-of-the-art methods. In particular, DeepWalk-based H2 NT achieves 24% improvement in terms of precision on motif prediction, while reducing 46% computational time compared to the original DeepWalk.
A Decentralized Approach to Bayesian Learning
Jul 14, 2020
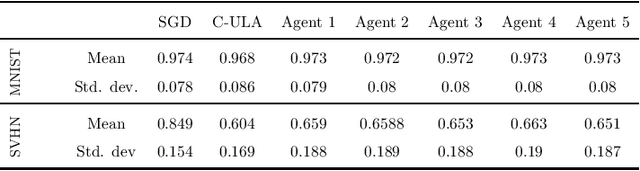
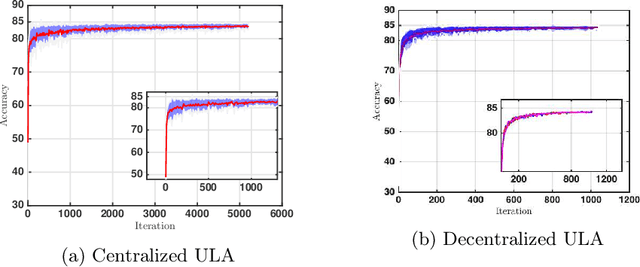
Motivated by decentralized approaches to machine learning, we propose a collaborative Bayesian learning algorithm taking the form of decentralized Langevin dynamics in a non-convex setting. Our analysis show that the initial KL-divergence between the Markov Chain and the target posterior distribution is exponentially decreasing while the error contributions to the overall KL-divergence from the additive noise is decreasing in polynomial time. We further show that the polynomial-term experiences speed-up with number of agents and provide sufficient conditions on the time-varying step-sizes to guarantee convergence to the desired distribution. The performance of the proposed algorithm is evaluated on a wide variety of machine learning tasks. The empirical results show that the performance of individual agents with locally available data is on par with the centralized setting with considerable improvement in the convergence rate.
Instant 3D Object Tracking with Applications in Augmented Reality
Jun 23, 2020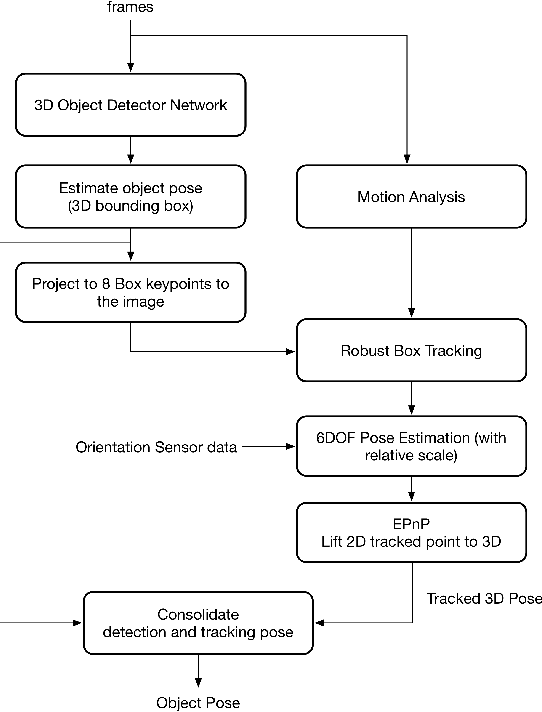
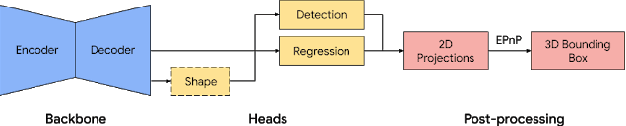


Tracking object poses in 3D is a crucial building block for Augmented Reality applications. We propose an instant motion tracking system that tracks an object's pose in space (represented by its 3D bounding box) in real-time on mobile devices. Our system does not require any prior sensory calibration or initialization to function. We employ a deep neural network to detect objects and estimate their initial 3D pose. Then the estimated pose is tracked using a robust planar tracker. Our tracker is capable of performing relative-scale 9-DoF tracking in real-time on mobile devices. By combining use of CPU and GPU efficiently, we achieve 26-FPS+ performance on mobile devices.
Depth as Attention for Face Representation Learning
Jan 03, 2021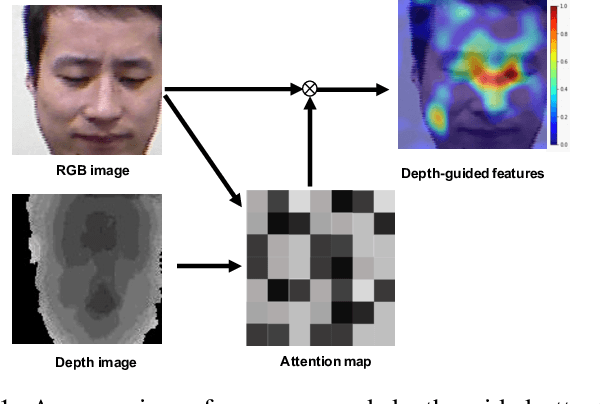
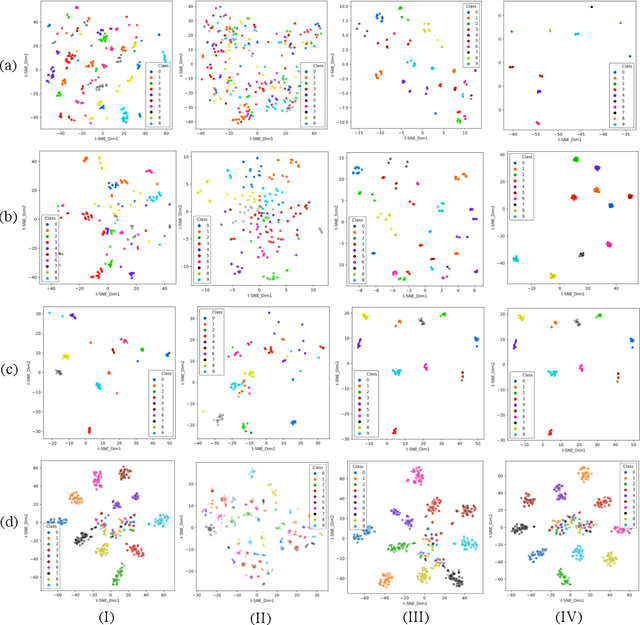
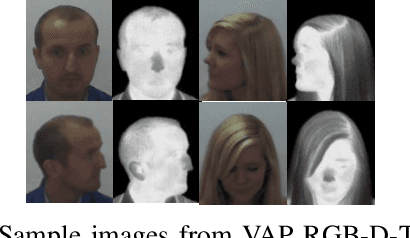
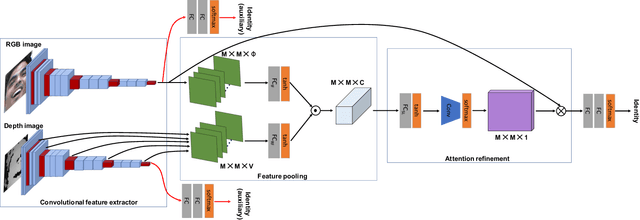
Face representation learning solutions have recently achieved great success for various applications such as verification and identification. However, face recognition approaches that are based purely on RGB images rely solely on intensity information, and therefore are more sensitive to facial variations, notably pose, occlusions, and environmental changes such as illumination and background. A novel depth-guided attention mechanism is proposed for deep multi-modal face recognition using low-cost RGB-D sensors. Our novel attention mechanism directs the deep network "where to look" for visual features in the RGB image by focusing the attention of the network using depth features extracted by a Convolution Neural Network (CNN). The depth features help the network focus on regions of the face in the RGB image that contains more prominent person-specific information. Our attention mechanism then uses this correlation to generate an attention map for RGB images from the depth features extracted by CNN. We test our network on four public datasets, showing that the features obtained by our proposed solution yield better results on the Lock3DFace, CurtinFaces, IIIT-D RGB-D, and KaspAROV datasets which include challenging variations in pose, occlusion, illumination, expression, and time-lapse. Our solution achieves average (increased) accuracies of 87.3\% (+5.0\%), 99.1\% (+0.9\%), 99.7\% (+0.6\%) and 95.3\%(+0.5\%) for the four datasets respectively, thereby improving the state-of-the-art. We also perform additional experiments with thermal images, instead of depth images, showing the high generalization ability of our solution when adopting other modalities for guiding the attention mechanism instead of depth information
Diagnosing and Preventing Instabilities in Recurrent Video Processing
Oct 17, 2020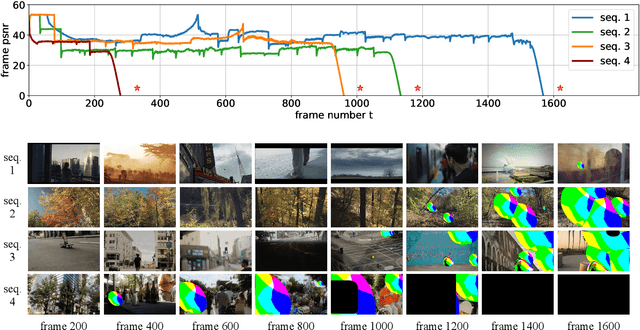
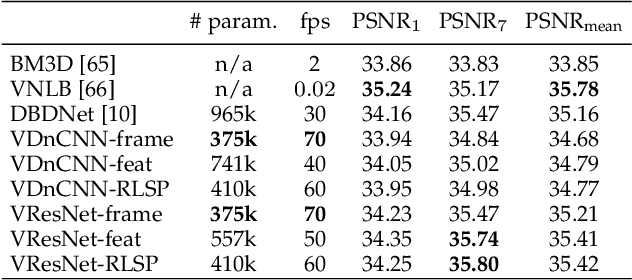
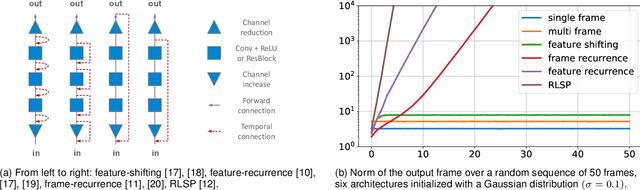
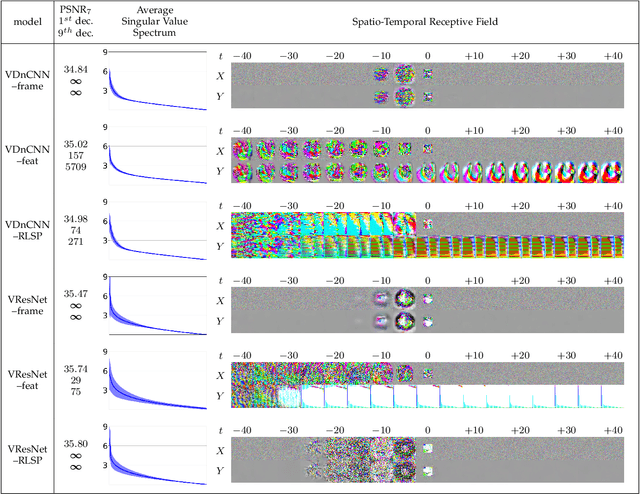
Recurrent models are becoming a popular choice for video enhancement tasks such as video denoising. In this work, we focus on their stability as dynamical systems and show that they tend to fail catastrophically at inference time on long video sequences. To address this issue, we (1) introduce a diagnostic tool which produces adversarial input sequences optimized to trigger instabilities and that can be interpreted as visualizations of spatio-temporal receptive fields, and (2) propose two approaches to enforce the stability of a model: constraining the spectral norm or constraining the stable rank of its convolutional layers. We then introduce Stable Rank Normalization of the Layers (SRNL), a new algorithm that enforces these constraints, and verify experimentally that it successfully results in stable recurrent video processing.
SF-GRASS: Solver-Free Graph Spectral Sparsification
Aug 17, 2020
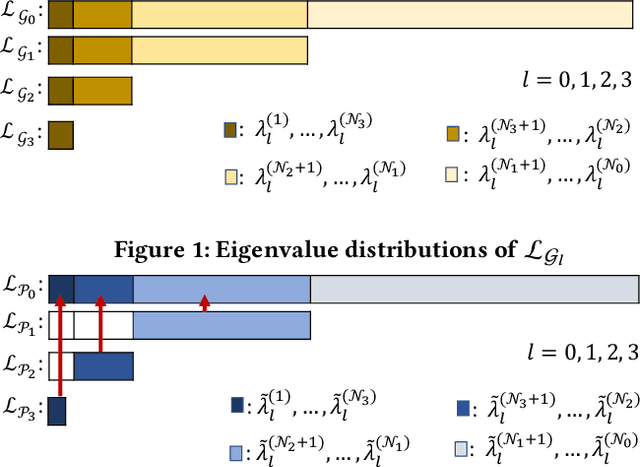
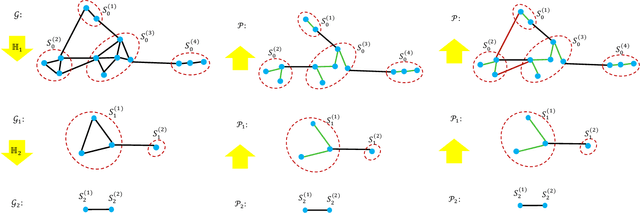
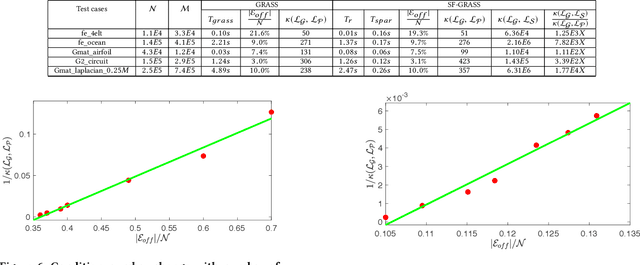
Recent spectral graph sparsification techniques have shown promising performance in accelerating many numerical and graph algorithms, such as iterative methods for solving large sparse matrices, spectral partitioning of undirected graphs, vectorless verification of power/thermal grids, representation learning of large graphs, etc. However, prior spectral graph sparsification methods rely on fast Laplacian matrix solvers that are usually challenging to implement in practice. This work, for the first time, introduces a solver-free approach (SF-GRASS) for spectral graph sparsification by leveraging emerging spectral graph coarsening and graph signal processing (GSP) techniques. We introduce a local spectral embedding scheme for efficiently identifying spectrally-critical edges that are key to preserving graph spectral properties, such as the first few Laplacian eigenvalues and eigenvectors. Since the key kernel functions in SF-GRASS can be efficiently implemented using sparse-matrix-vector-multiplications (SpMVs), the proposed spectral approach is simple to implement and inherently parallel friendly. Our extensive experimental results show that the proposed method can produce a hierarchy of high-quality spectral sparsifiers in nearly-linear time for a variety of real-world, large-scale graphs and circuit networks when compared with the prior state-of-the-art spectral method.