 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Designing Interpretable Approximations to Deep Reinforcement Learning with Soft Decision Trees
Oct 28, 2020
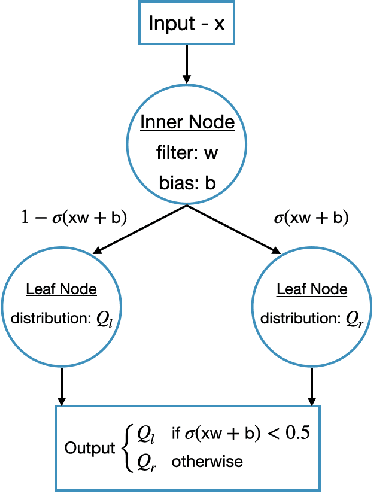
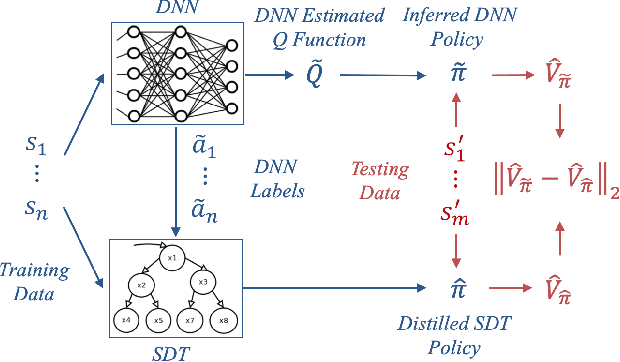
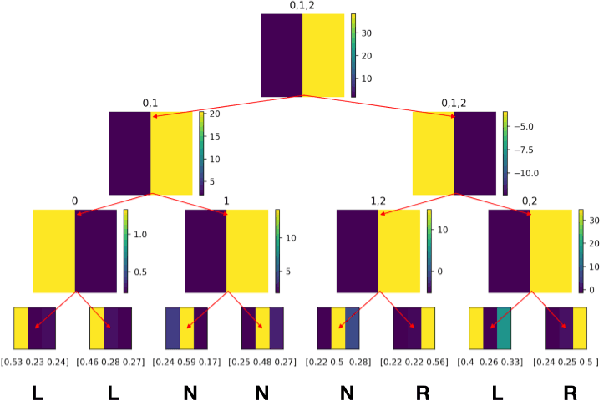
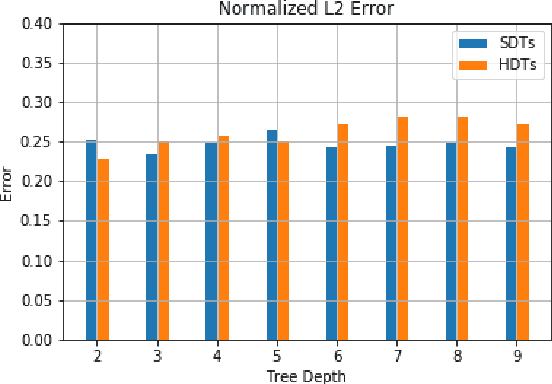
In an ever expanding set of research and application areas, deep neural networks (DNNs) set the bar for algorithm performance. However, depending upon additional constraints such as processing power and execution time limits, or requirements such as verifiable safety guarantees, it may not be feasible to actually use such high-performing DNNs in practice. Many techniques have been developed in recent years to compress or distill complex DNNs into smaller, faster or more understandable models and controllers. This work seeks to provide a quantitative framework with metrics to systematically evaluate the outcome of such conversion processes, and identify reduced models that not only preserve a desired performance level, but also, for example, succinctly explain the latent knowledge represented by a DNN. We illustrate the effectiveness of the proposed approach on the evaluation of decision tree variants in the context of benchmark reinforcement learning tasks.
Can we Estimate Truck Accident Risk from Telemetric Data using Machine Learning?
Jul 17, 2020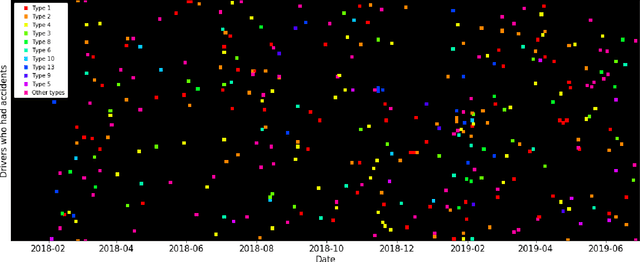
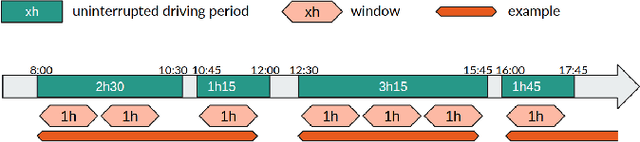
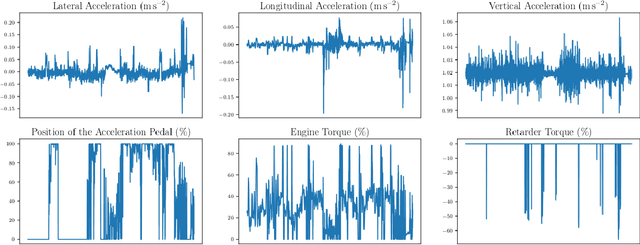
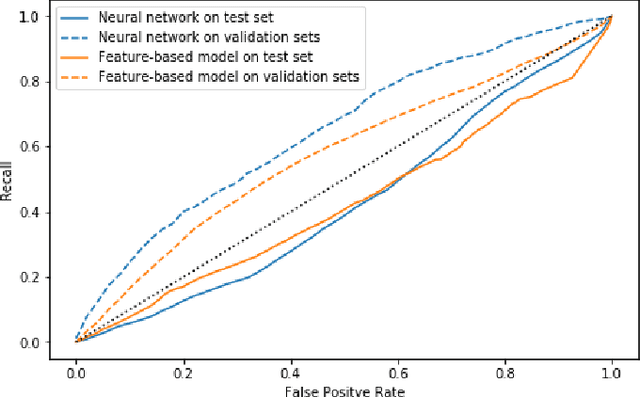
Road accidents have a high societal cost that could be reduced through improved risk predictions using machine learning. This study investigates whether telemetric data collected on long-distance trucks can be used to predict the risk of accidents associated with a driver. We use a dataset provided by a truck transportation company containing the driving data of 1,141 drivers for 18 months. We evaluate two different machine learning approaches to perform this task. In the first approach, features are extracted from the time series data using the FRESH algorithm and then used to estimate the risk using Random Forests. In the second approach, we use a convolutional neural network to directly estimate the risk from the time-series data. We find that neither approach is able to successfully estimate the risk of accidents on this dataset, in spite of many methodological attempts. We discuss the difficulties of using telemetric data for the estimation of the risk of accidents that could explain this negative result.
Out-of-Distribution Detection for Automotive Perception
Nov 03, 2020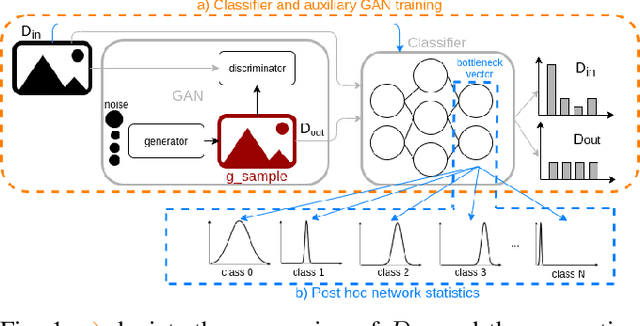
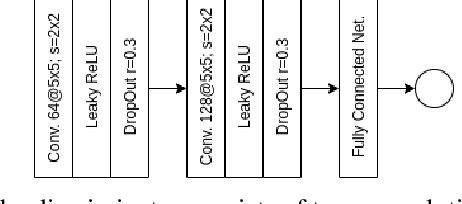
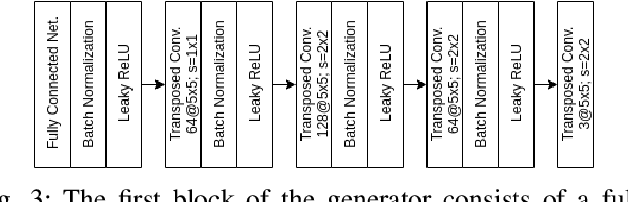
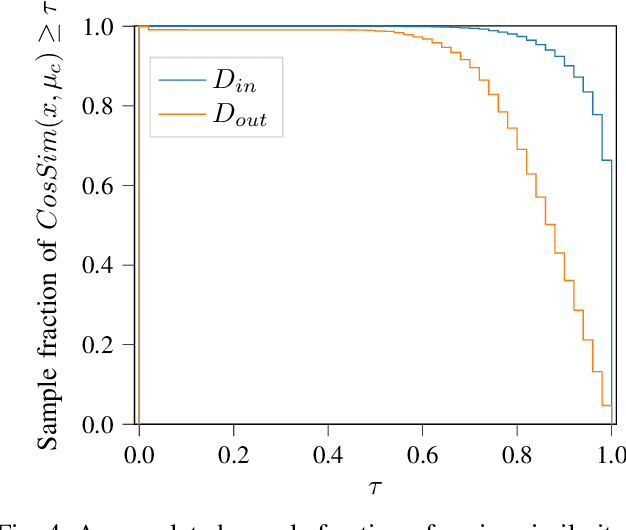
Neural networks (NNs) are widely used for object recognition tasks in autonomous driving. However, NNs can fail on input data not well represented by the training dataset, known as out-of-distribution (OOD) data. A mechanism to detect OOD samples is important in safety-critical applications, such as automotive perception, in order to trigger a safe fallback mode. NNs often rely on softmax normalization for confidence estimation, which can lead to high confidences being assigned to OOD samples, thus hindering the detection of failures. This paper presents a simple but effective method for determining whether inputs are OOD. We propose an OOD detection approach that combines auxiliary training techniques with post hoc statistics. Unlike other approaches, our proposed method does not require OOD data during training, and it does not increase the computational cost during inference. The latter property is especially important in automotive applications with limited computational resources and real-time constraints. Our proposed method outperforms state-of-the-art methods on real world automotive datasets.
StressNet: Detecting Stress in Thermal Videos
Nov 23, 2020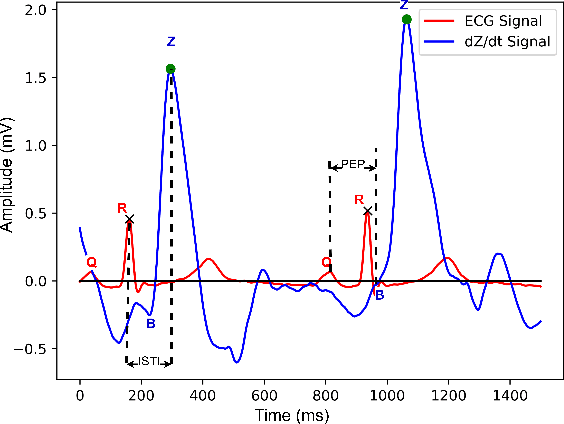
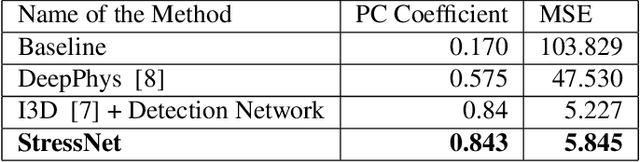
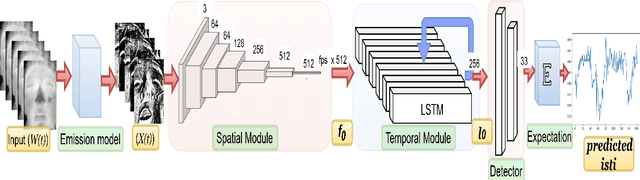
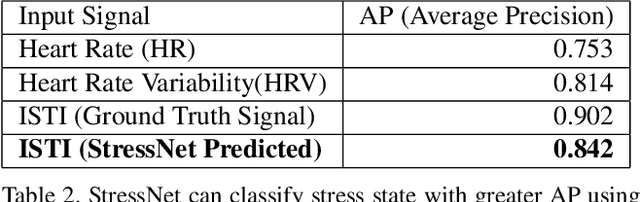
Precise measurement of physiological signals is critical for the effective monitoring of human vital signs. Recent developments in computer vision have demonstrated that signals such as pulse rate and respiration rate can be extracted from digital video of humans, increasing the possibility of contact-less monitoring. This paper presents a novel approach to obtaining physiological signals and classifying stress states from thermal video. The proposed network--"StressNet"--features a hybrid emission representation model that models the direct emission and absorption of heat by the skin and underlying blood vessels. This results in an information-rich feature representation of the face, which is used by spatio-temporal network for reconstructing the ISTI ( Initial Systolic Time Interval: a measure of change in cardiac sympathetic activity that is considered to be a quantitative index of stress in humans ). The reconstructed ISTI signal is fed into a stress-detection model to detect and classify the individual's stress state ( i.e. stress or no stress ). A detailed evaluation demonstrates that StressNet achieves estimated the ISTI signal with 95% accuracy and detect stress with average precision of 0.842. The source code is available on Github.
Communicative need modulates competition in language change
Jun 16, 2020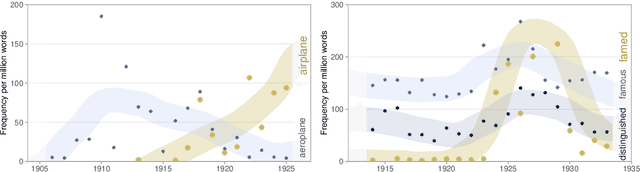
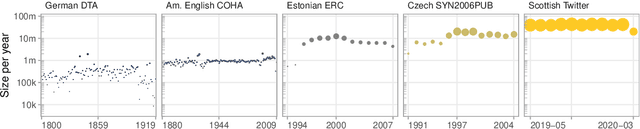
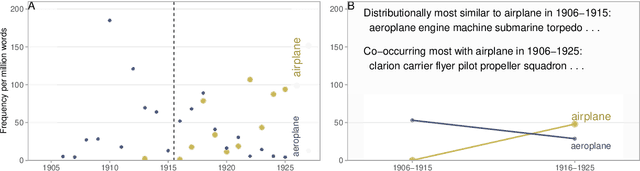
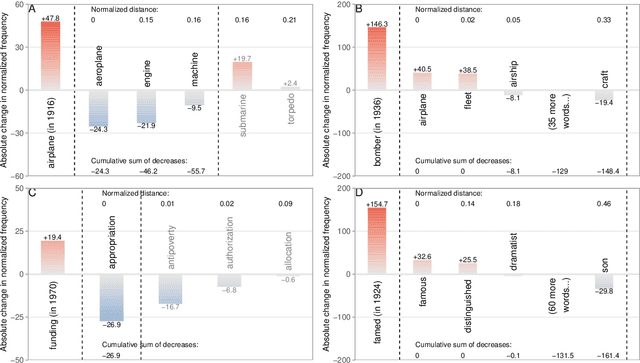
All living languages change over time. The causes for this are many, one being the emergence and borrowing of new linguistic elements. Competition between the new elements and older ones with a similar semantic or grammatical function may lead to speakers preferring one of them, and leaving the other to go out of use. We introduce a general method for quantifying competition between linguistic elements in diachronic corpora which does not require language-specific resources other than a sufficiently large corpus. This approach is readily applicable to a wide range of languages and linguistic subsystems. Here, we apply it to lexical data in five corpora differing in language, type, genre, and time span. We find that changes in communicative need are consistently predictive of lexical competition dynamics. Near-synonymous words are more likely to directly compete if they belong to a topic of conversation whose importance to language users is constant over time, possibly leading to the extinction of one of the competing words. By contrast, in topics which are increasing in importance for language users, near-synonymous words tend not to compete directly and can coexist. This suggests that, in addition to direct competition between words, language change can be driven by competition between topics or semantic subspaces.
Food Classification with Convolutional Neural Networks and Multi-Class Linear Discernment Analysis
Dec 11, 2020
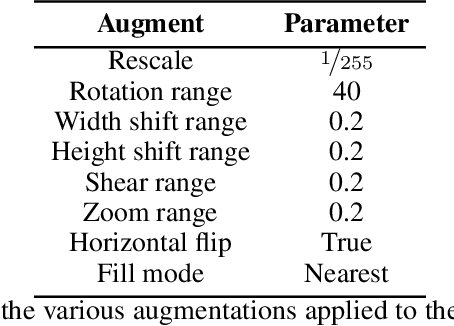


Convolutional neural networks (CNNs) have been successful in representing the fully-connected inferencing ability perceived to be seen in the human brain: they take full advantage of the hierarchy-style patterns commonly seen in complex data and develop more patterns using simple features. Countless implementations of CNNs have shown how strong their ability is to learn these complex patterns, particularly in the realm of image classification. However, the cost of getting a high performance CNN to a so-called "state of the art" level is computationally costly. Even when using transfer learning, which utilize the very deep layers from models such as MobileNetV2, CNNs still take a great amount of time and resources. Linear discriminant analysis (LDA), a generalization of Fisher's linear discriminant, can be implemented in a multi-class classification method to increase separability of class features while not needing a high performance system to do so for image classification. Similarly, we also believe LDA has great promise in performing well. In this paper, we discuss our process of developing a robust CNN for food classification as well as our effective implementation of multi-class LDA and prove that (1) CNN is superior to LDA for image classification and (2) why LDA should not be left out of the races for image classification, particularly for binary cases.
TFPnP: Tuning-free Plug-and-Play Proximal Algorithm with Applications to Inverse Imaging Problems
Dec 11, 2020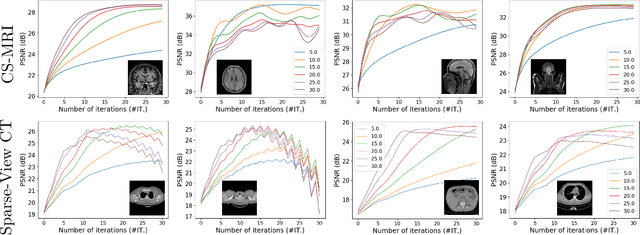
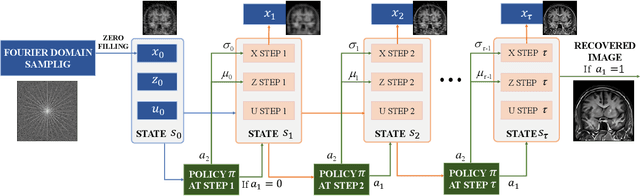
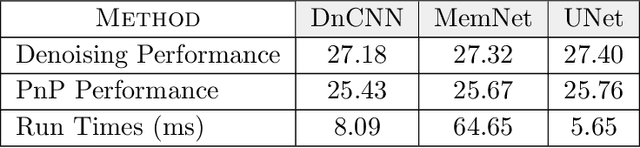
Plug-and-Play (PnP) is a non-convex framework that combines proximal algorithms, for example alternating direction method of multipliers (ADMM), with advanced denoiser priors. Over the past few years, great empirical success has been obtained by PnP algorithms, especially for the ones integrated with deep learning-based denoisers. However, a crucial issue of PnP approaches is the need of manual parameter tweaking. As it is essential to obtain high-quality results across the high discrepancy in terms of imaging conditions and varying scene content. In this work, we present a tuning-free PnP proximal algorithm, which can automatically determine the internal parameters including the penalty parameter, the denoising strength and the termination time. A core part of our approach is to develop a policy network for automatic search of parameters, which can be effectively learned via mixed model-free and model-based deep reinforcement learning. We demonstrate, through a set of numerical and visual experiments, that the learned policy can customize different parameters for different states, and often more efficient and effective than existing handcrafted criteria. Moreover, we discuss the practical considerations of the plugged denoisers, which together with our learned policy yield to state-of-the-art results. This is prevalent on both linear and nonlinear exemplary inverse imaging problems, and in particular, we show promising results on compressed sensing MRI, sparse-view CT and phase retrieval.
ShineOn: Illuminating Design Choices for Practical Video-based Virtual Clothing Try-on
Dec 18, 2020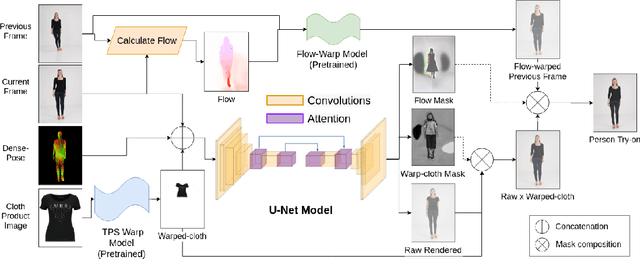

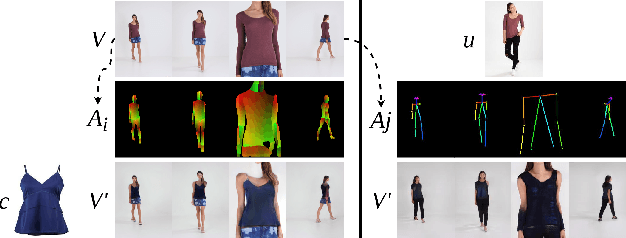
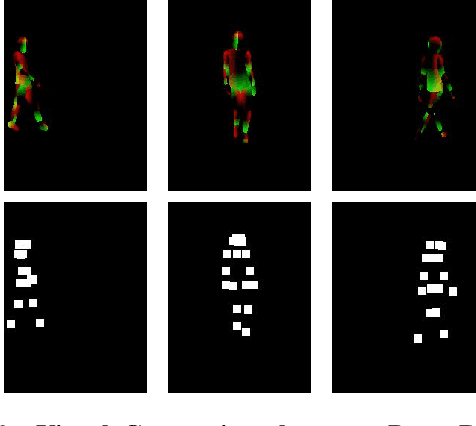
Virtual try-on has garnered interest as a neural rendering benchmark task to evaluate complex object transfer and scene composition. Recent works in virtual clothing try-on feature a plethora of possible architectural and data representation choices. However, they present little clarity on quantifying the isolated visual effect of each choice, nor do they specify the hyperparameter details that are key to experimental reproduction. Our work, ShineOn, approaches the try-on task from a bottom-up approach and aims to shine light on the visual and quantitative effects of each experiment. We build a series of scientific experiments to isolate effective design choices in video synthesis for virtual clothing try-on. Specifically, we investigate the effect of different pose annotations, self-attention layer placement, and activation functions on the quantitative and qualitative performance of video virtual try-on. We find that DensePose annotations not only enhance face details but also decrease memory usage and training time. Next, we find that attention layers improve face and neck quality. Finally, we show that GELU and ReLU activation functions are the most effective in our experiments despite the appeal of newer activations such as Swish and Sine. We will release a well-organized code base, hyperparameters, and model checkpoints to support the reproducibility of our results. We expect our extensive experiments and code to greatly inform future design choices in video virtual try-on. Our code may be accessed at https://github.com/andrewjong/ShineOn-Virtual-Tryon.
Enabling Deep Spiking Neural Networks with Hybrid Conversion and Spike Timing Dependent Backpropagation
May 04, 2020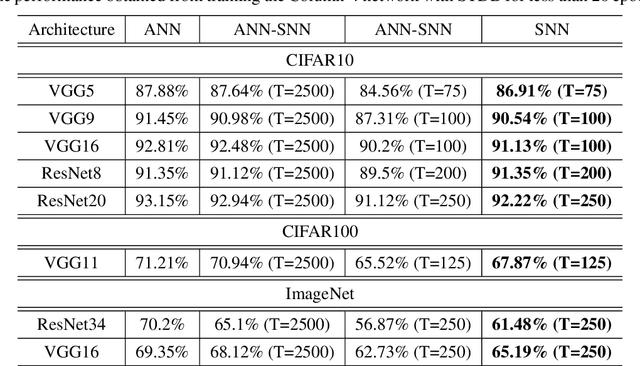
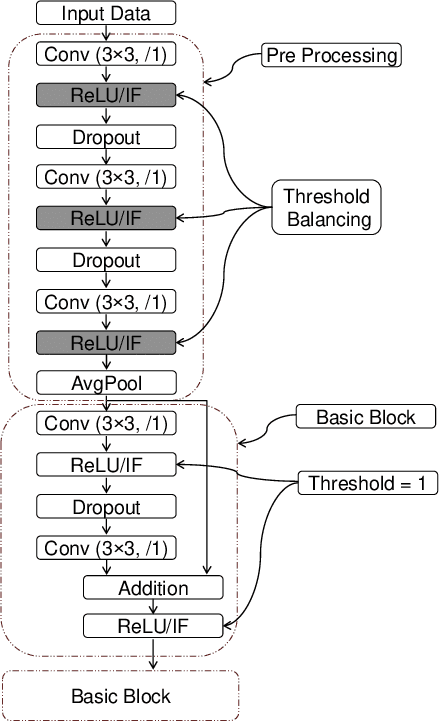
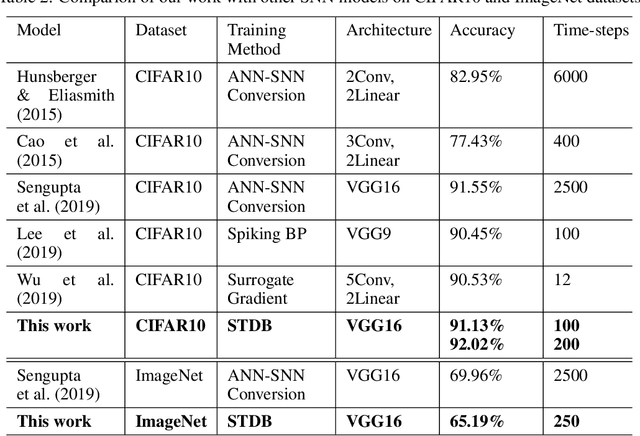
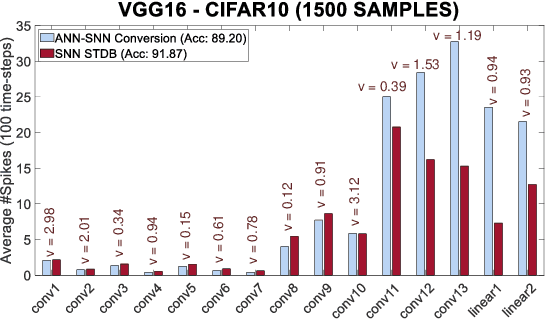
Spiking Neural Networks (SNNs) operate with asynchronous discrete events (or spikes) which can potentially lead to higher energy-efficiency in neuromorphic hardware implementations. Many works have shown that an SNN for inference can be formed by copying the weights from a trained Artificial Neural Network (ANN) and setting the firing threshold for each layer as the maximum input received in that layer. These type of converted SNNs require a large number of time steps to achieve competitive accuracy which diminishes the energy savings. The number of time steps can be reduced by training SNNs with spike-based backpropagation from scratch, but that is computationally expensive and slow. To address these challenges, we present a computationally-efficient training technique for deep SNNs. We propose a hybrid training methodology: 1) take a converted SNN and use its weights and thresholds as an initialization step for spike-based backpropagation, and 2) perform incremental spike-timing dependent backpropagation (STDB) on this carefully initialized network to obtain an SNN that converges within few epochs and requires fewer time steps for input processing. STDB is performed with a novel surrogate gradient function defined using neuron's spike time. The proposed training methodology converges in less than 20 epochs of spike-based backpropagation for most standard image classification datasets, thereby greatly reducing the training complexity compared to training SNNs from scratch. We perform experiments on CIFAR-10, CIFAR-100, and ImageNet datasets for both VGG and ResNet architectures. We achieve top-1 accuracy of 65.19% for ImageNet dataset on SNN with 250 time steps, which is 10X faster compared to converted SNNs with similar accuracy.
A Self-Supervised Feature Map Augmentation (FMA) Loss and Combined Augmentations Finetuning to Efficiently Improve the Robustness of CNNs
Dec 02, 2020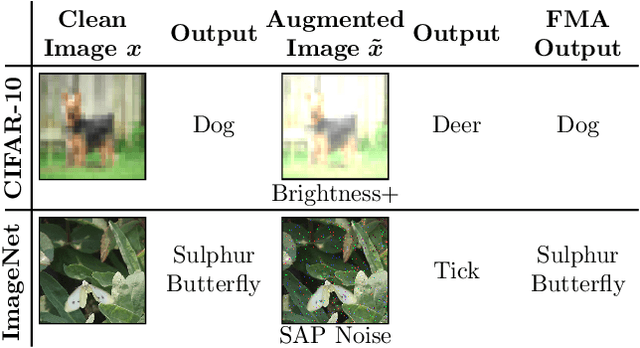
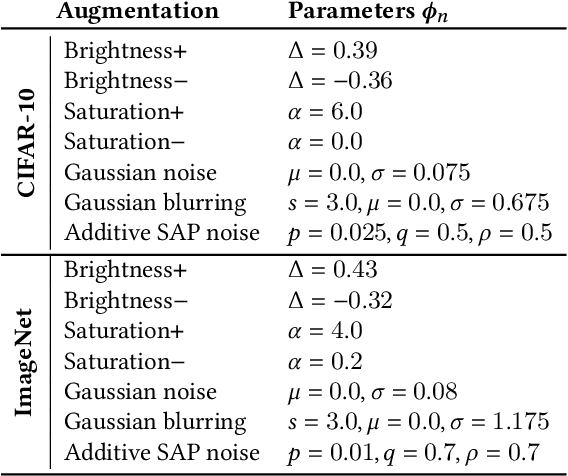
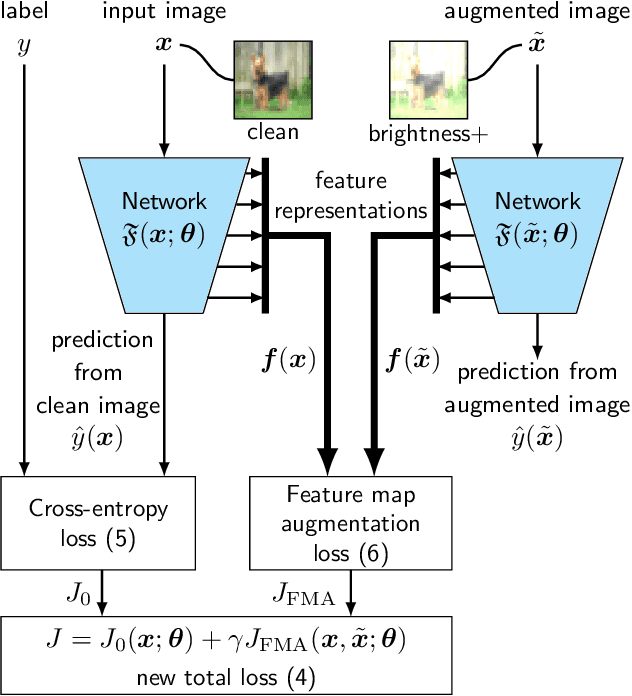
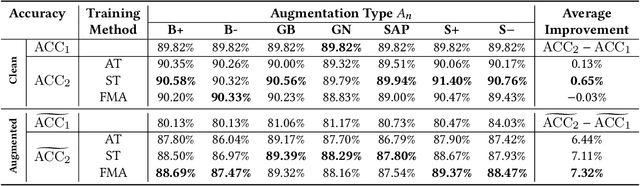
Deep neural networks are often not robust to semantically-irrelevant changes in the input. In this work we address the issue of robustness of state-of-the-art deep convolutional neural networks (CNNs) against commonly occurring distortions in the input such as photometric changes, or the addition of blur and noise. These changes in the input are often accounted for during training in the form of data augmentation. We have two major contributions: First, we propose a new regularization loss called feature-map augmentation (FMA) loss which can be used during finetuning to make a model robust to several distortions in the input. Second, we propose a new combined augmentations (CA) finetuning strategy, that results in a single model that is robust to several augmentation types at the same time in a data-efficient manner. We use the CA strategy to improve an existing state-of-the-art method called stability training (ST). Using CA, on an image classification task with distorted images, we achieve an accuracy improvement of on average 8.94% with FMA and 8.86% with ST absolute on CIFAR-10 and 8.04% with FMA and 8.27% with ST absolute on ImageNet, compared to 1.98% and 2.12%, respectively, with the well known data augmentation method, while keeping the clean baseline performance.