 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Cross-Camera Convolutional Color Constancy
Nov 24, 2020

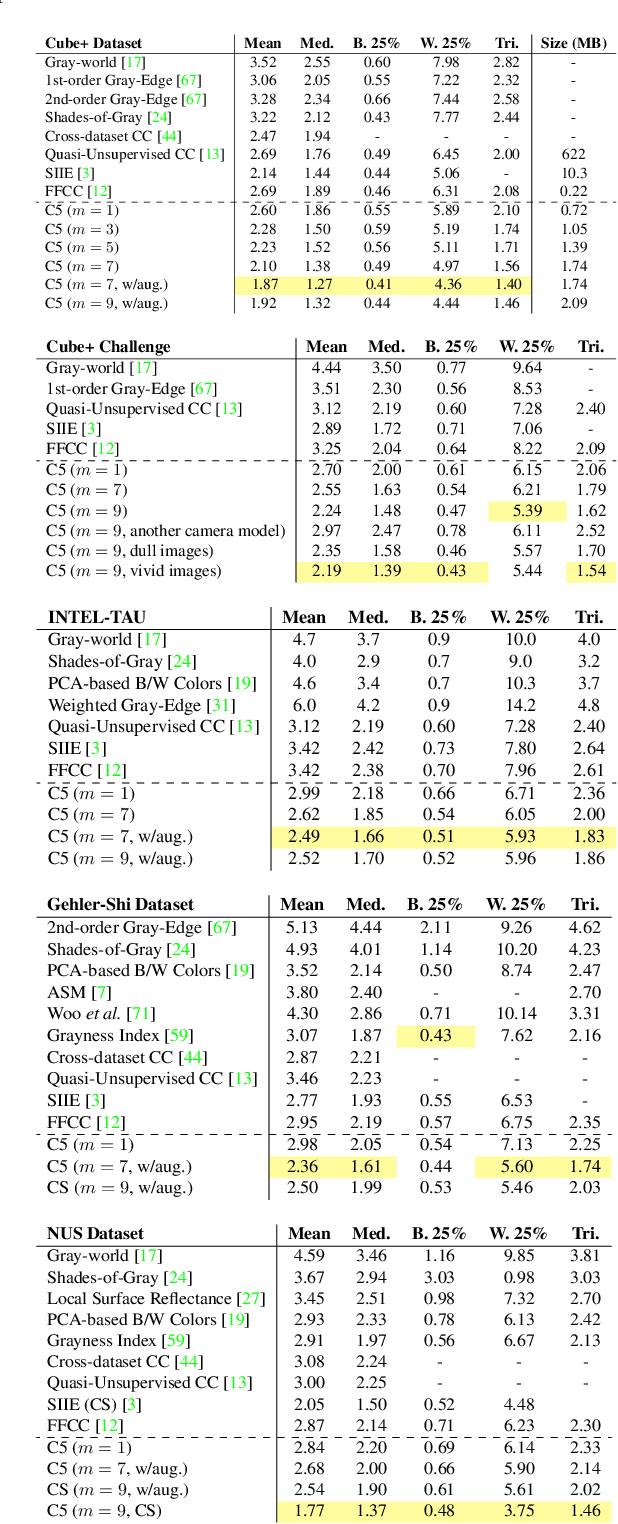
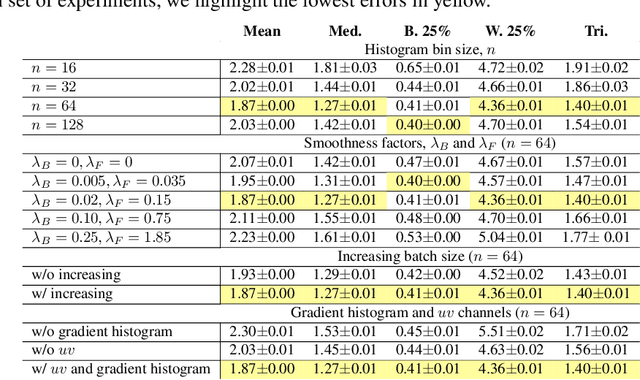
We present "Cross-Camera Convolutional Color Constancy" (C5), a learning-based method, trained on images from multiple cameras, that accurately estimates a scene's illuminant color from raw images captured by a new camera previously unseen during training. C5 is a hypernetwork-like extension of the convolutional color constancy (CCC) approach: C5 learns to generate the weights of a CCC model that is then evaluated on the input image, with the CCC weights dynamically adapted to different input content. Unlike prior cross-camera color constancy models, which are usually designed to be agnostic to the spectral properties of test-set images from unobserved cameras, C5 approaches this problem through the lens of transductive inference: additional unlabeled images are provided as input to the model at test time, which allows the model to calibrate itself to the spectral properties of the test-set camera during inference. C5 achieves state-of-the-art accuracy for cross-camera color constancy on several datasets, is fast to evaluate (~7 and ~90 ms per image on a GPU or CPU, respectively), and requires little memory (~2 MB), and, thus, is a practical solution to the problem of calibration-free automatic white balance for mobile photography.
Communicative need modulates competition in language change
Jun 16, 2020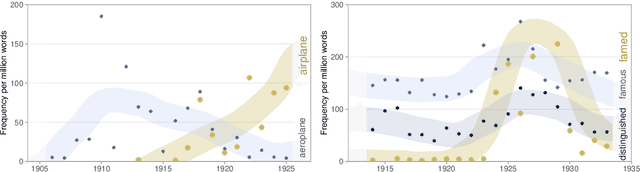
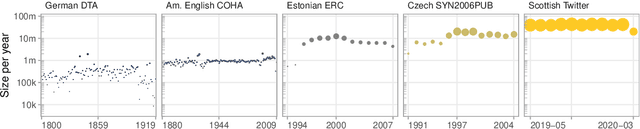
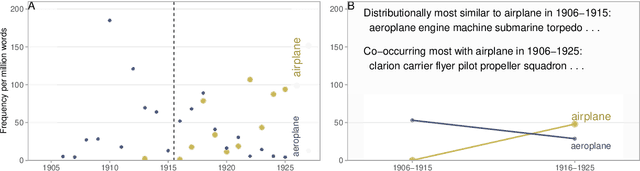
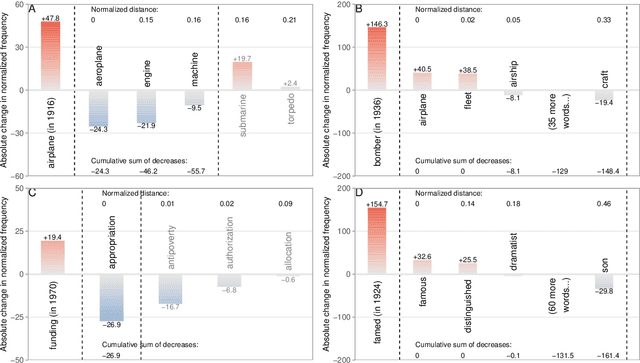
All living languages change over time. The causes for this are many, one being the emergence and borrowing of new linguistic elements. Competition between the new elements and older ones with a similar semantic or grammatical function may lead to speakers preferring one of them, and leaving the other to go out of use. We introduce a general method for quantifying competition between linguistic elements in diachronic corpora which does not require language-specific resources other than a sufficiently large corpus. This approach is readily applicable to a wide range of languages and linguistic subsystems. Here, we apply it to lexical data in five corpora differing in language, type, genre, and time span. We find that changes in communicative need are consistently predictive of lexical competition dynamics. Near-synonymous words are more likely to directly compete if they belong to a topic of conversation whose importance to language users is constant over time, possibly leading to the extinction of one of the competing words. By contrast, in topics which are increasing in importance for language users, near-synonymous words tend not to compete directly and can coexist. This suggests that, in addition to direct competition between words, language change can be driven by competition between topics or semantic subspaces.
VAW-GAN for Disentanglement and Recomposition of Emotional Elements in Speech
Nov 03, 2020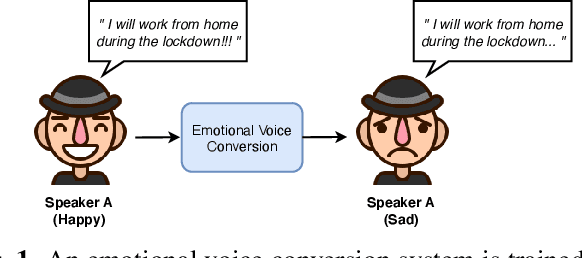
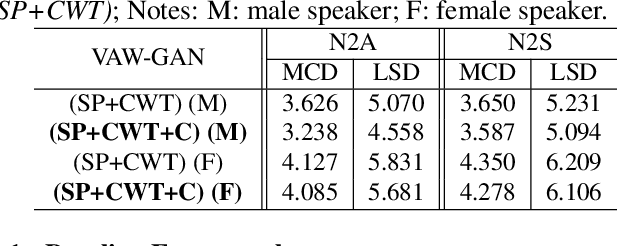
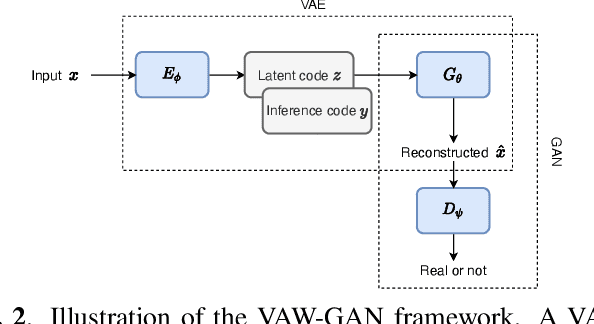
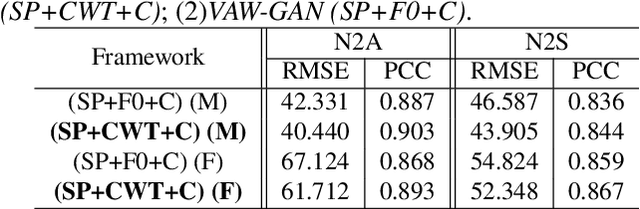
Emotional voice conversion (EVC) aims to convert the emotion of speech from one state to another while preserving the linguistic content and speaker identity. In this paper, we study the disentanglement and recomposition of emotional elements in speech through variational autoencoding Wasserstein generative adversarial network (VAW-GAN). We propose a speaker-dependent EVC framework based on VAW-GAN, that includes two VAW-GAN pipelines, one for spectrum conversion, and another for prosody conversion. We train a spectral encoder that disentangles emotion and prosody (F0) information from spectral features; we also train a prosodic encoder that disentangles emotion modulation of prosody (affective prosody) from linguistic prosody. At run-time, the decoder of spectral VAW-GAN is conditioned on the output of prosodic VAW-GAN. The vocoder takes the converted spectral and prosodic features to generate the target emotional speech. Experiments validate the effectiveness of our proposed method in both objective and subjective evaluations.
A Vision-based Sensing Approach for a Spherical Soft Robotic Arm
Dec 11, 2020
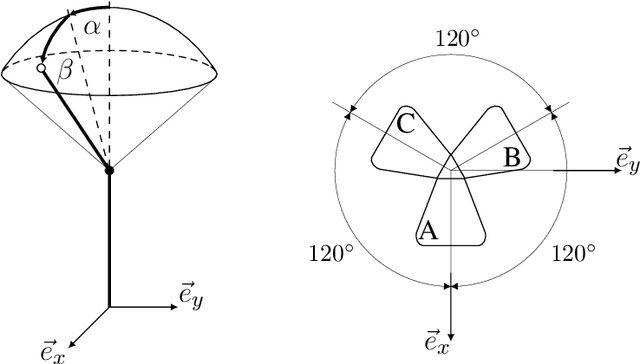
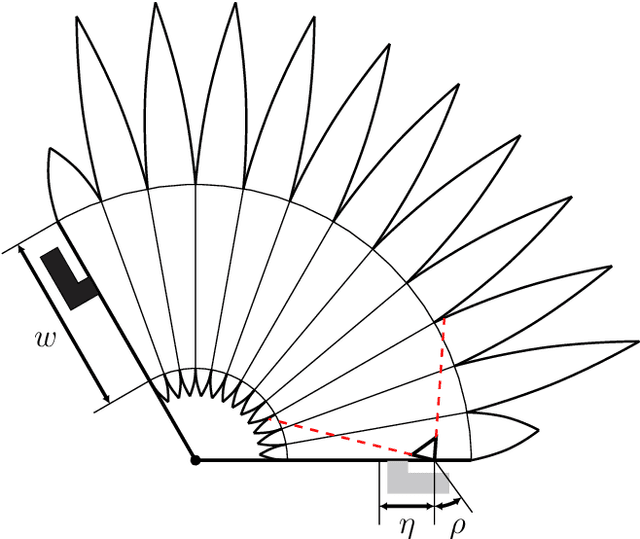

Sensory feedback is essential for the control of soft robotic systems and to enable deployment in a variety of different tasks. Proprioception refers to sensing the robot's own state and is of crucial importance in order to deploy soft robotic systems outside of laboratory environments, i.e. where no external sensing, such as motion capture systems, is available. A vision-based sensing approach for a soft robotic arm made from fabric is presented, leveraging the high-resolution sensory feedback provided by cameras. No mechanical interaction between the sensor and the soft structure is required and consequently, the compliance of the soft system is preserved. The integration of a camera into an inflatable, fabric-based bellow actuator is discussed. Three actuators, each featuring an integrated camera, are used to control the spherical robotic arm and simultaneously provide sensory feedback of the two rotational degrees of freedom. A convolutional neural network architecture predicts the two angles describing the robot's orientation from the camera images. Ground truth data is provided by a motion capture system during the training phase of the supervised learning approach and its evaluation thereafter. The camera-based sensing approach is able to provide estimates of the orientation in real-time with an accuracy of about one degree. The reliability of the sensing approach is demonstrated by using the sensory feedback to control the orientation of the robotic arm in closed-loop.
Can we Estimate Truck Accident Risk from Telemetric Data using Machine Learning?
Jul 17, 2020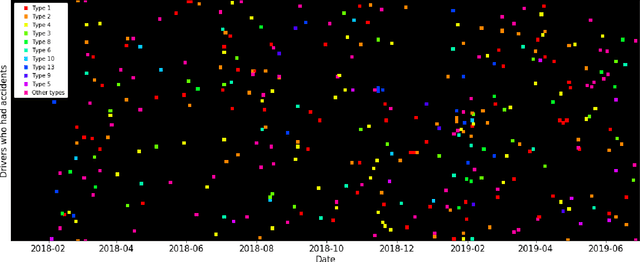
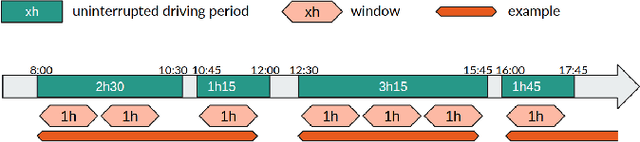
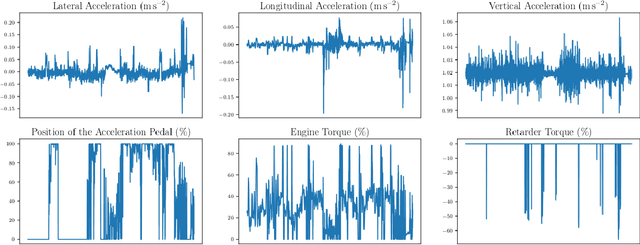
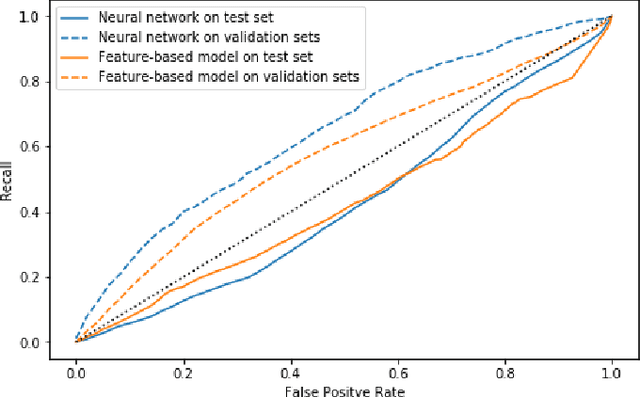
Road accidents have a high societal cost that could be reduced through improved risk predictions using machine learning. This study investigates whether telemetric data collected on long-distance trucks can be used to predict the risk of accidents associated with a driver. We use a dataset provided by a truck transportation company containing the driving data of 1,141 drivers for 18 months. We evaluate two different machine learning approaches to perform this task. In the first approach, features are extracted from the time series data using the FRESH algorithm and then used to estimate the risk using Random Forests. In the second approach, we use a convolutional neural network to directly estimate the risk from the time-series data. We find that neither approach is able to successfully estimate the risk of accidents on this dataset, in spite of many methodological attempts. We discuss the difficulties of using telemetric data for the estimation of the risk of accidents that could explain this negative result.
Neural Audio Fingerprint for High-specific Audio Retrieval based on Contrastive Learning
Oct 28, 2020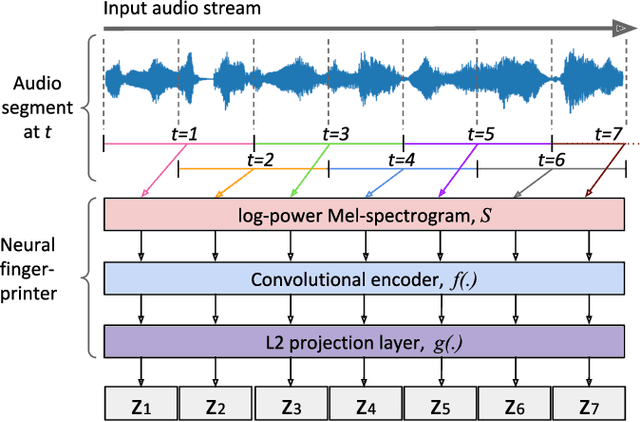

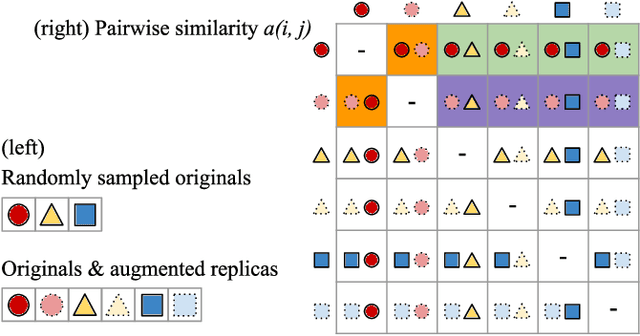
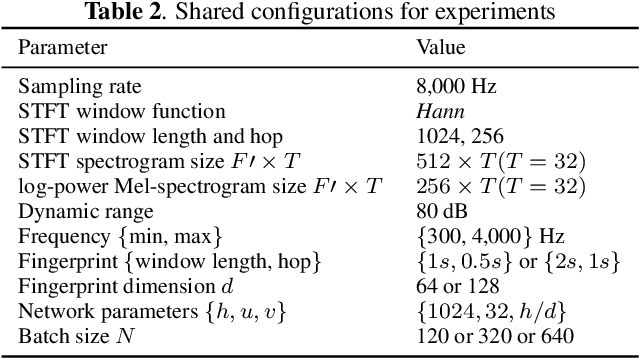
Most of existing audio fingerprinting systems have limitations to be used for high-specific audio retrieval at scale. In this work, we generate a low-dimensional representation from a short unit segment of audio, and couple this fingerprint with a fast maximum inner-product search. To this end, we present a contrastive learning framework that derives from the segment-level search objective. Each update in training uses a batch consisting of a set of pseudo labels, randomly selected original samples, and their augmented replicas. These replicas can simulate the degrading effects on original audio signals by applying small time offsets and various types of distortions, such as background noise and room/microphone impulse responses. In the segment-level search task, where the conventional audio fingerprinting systems used to fail, our system using 10x smaller storage has shown promising results. Our code and dataset will be available.
ALPaCA vs. GP-based Prior Learning: A Comparison between two Bayesian Meta-Learning Algorithms
Oct 15, 2020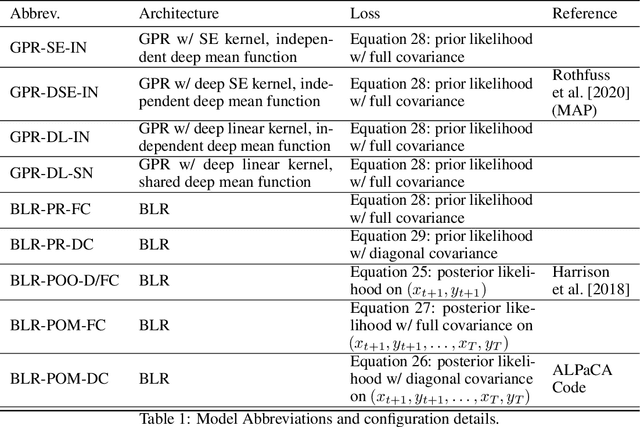
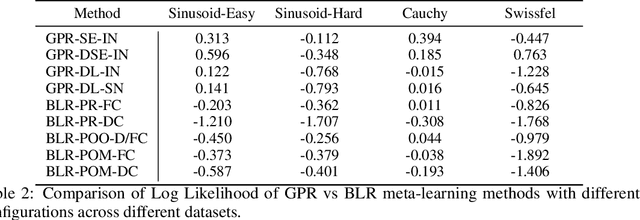
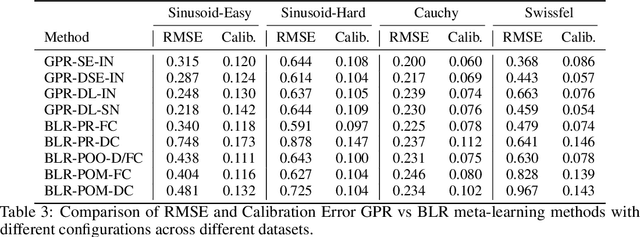
Meta-learning or few-shot learning, has been successfully applied in a wide range of domains from computer vision to reinforcement learning. Among the many frameworks proposed for meta-learning, bayesian methods are particularly favoured when accurate and calibrated uncertainty estimate is required. In this paper, we investigate the similarities and disparities among two recently published bayesian meta-learning methods: ALPaCA (Harrison et al. [2018]) and PACOH (Rothfuss et al. [2020]). We provide theoretical analysis as well as empirical benchmarks across synthetic and real-world dataset. While ALPaCA holds advantage in computation time by the usage of a linear kernel, general GP-based methods provide much more flexibility and achieves better result across datasets when using a common kernel such as SE (Squared Exponential) kernel. The influence of different loss function choice is also discussed.
Real-Time Visual Place Recognition for Personal Localization on a Mobile Device
Apr 27, 2017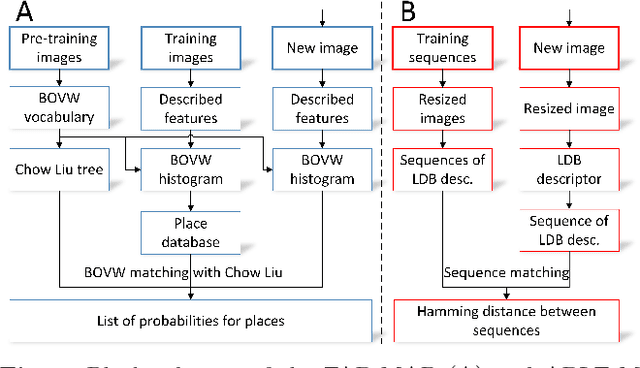
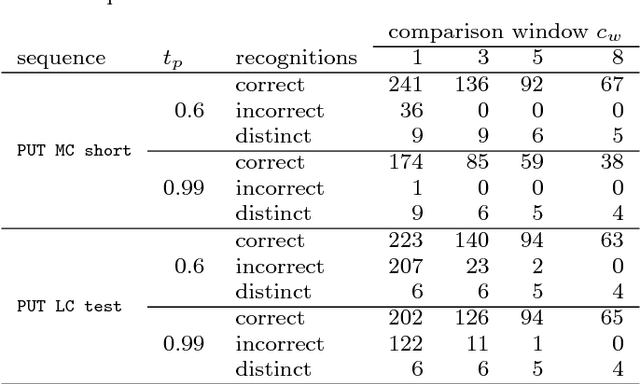
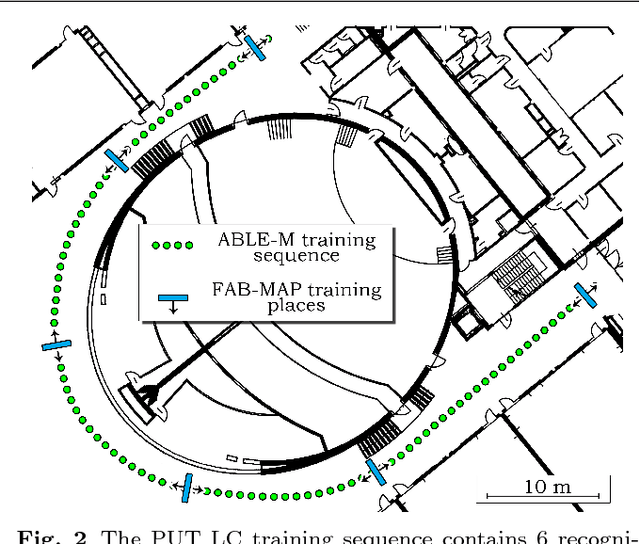
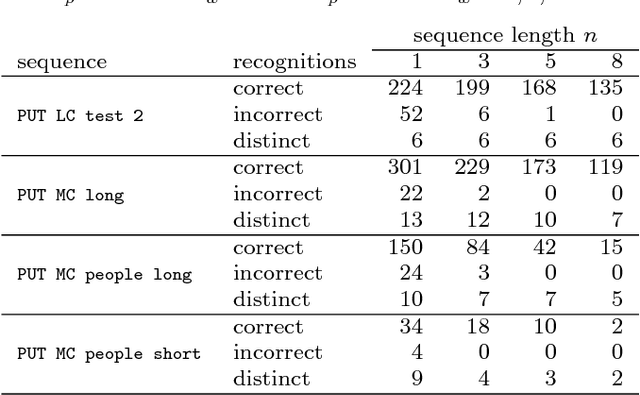
The paper presents an approach to indoor personal localization on a mobile device based on visual place recognition. We implemented on a smartphone two state-of-the-art algorithms that are representative to two different approaches to visual place recognition: FAB-MAP that recognizes places using individual images, and ABLE-M that utilizes sequences of images. These algorithms are evaluated in environments of different structure, focusing on problems commonly encountered when a mobile device camera is used. The conclusions drawn from this evaluation are guidelines to design the FastABLE system, which is based on the ABLE-M algorithm, but introduces major modifications to the concept of image matching. The improvements radically cut down the processing time and improve scalability, making it possible to localize the user in long image sequences with the limited computing power of a mobile device. The resulting place recognition system compares favorably to both the ABLE-M and the FAB-MAP solutions in the context of real-time personal localization.
Statistically Model Checking PCTL Specifications on Markov Decision Processes via Reinforcement Learning
Apr 01, 2020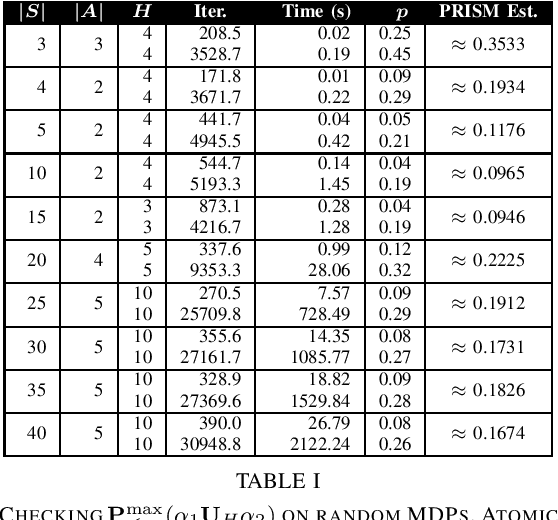
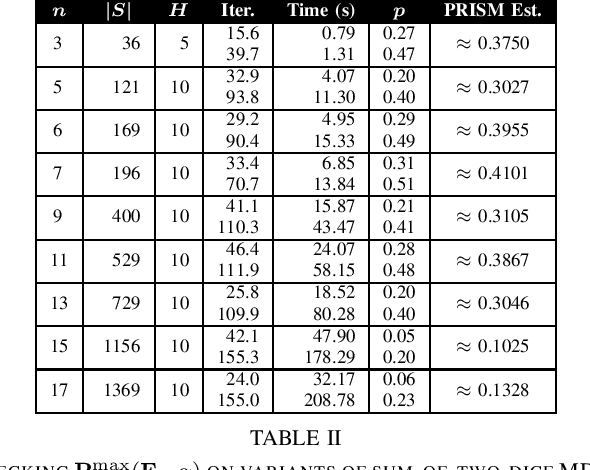
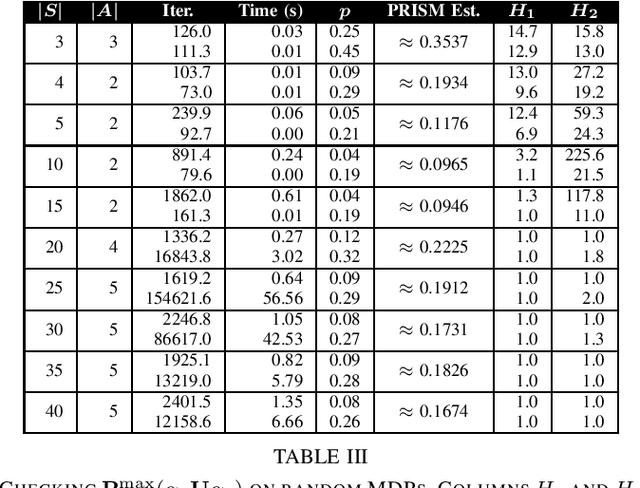
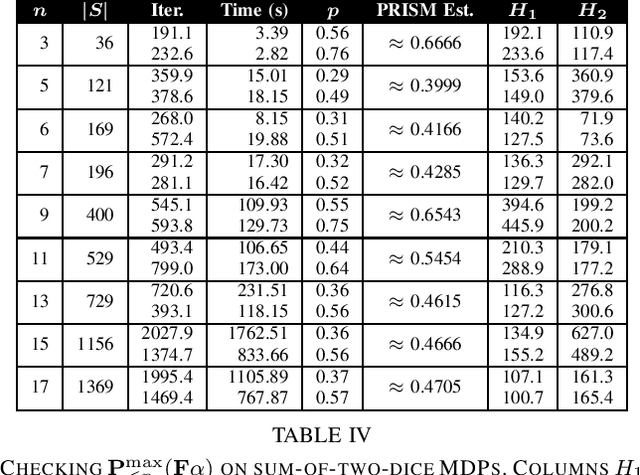
Probabilistic Computation Tree Logic (PCTL) is frequently used to formally specify control objectives such as probabilistic reachability and safety. In this work, we focus on model checking PCTL specifications statistically on Markov Decision Processes (MDPs) by sampling, e.g., checking whether there exists a feasible policy such that the probability of reaching certain goal states is greater than a threshold. We use reinforcement learning to search for such a feasible policy for PCTL specifications, and then develop a statistical model checking (SMC) method with provable guarantees on its error. Specifically, we first use upper-confidence-bound (UCB) based Q-learning to design an SMC algorithm for bounded-time PCTL specifications, and then extend this algorithm to unbounded-time specifications by identifying a proper truncation time by checking the PCTL specification and its negation at the same time. Finally, we evaluate the proposed method on case studies.
Frequency-compensated PINNs for Fluid-dynamic Design Problems
Nov 03, 2020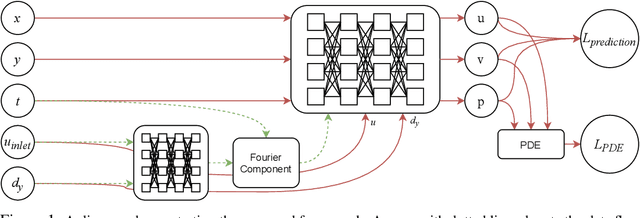
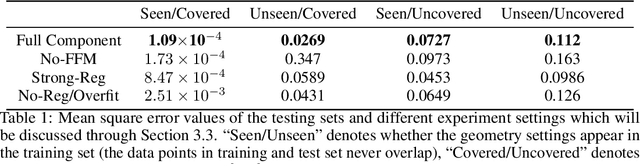
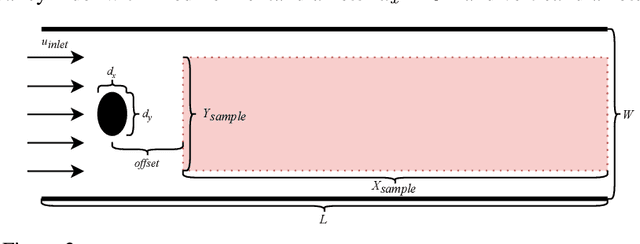
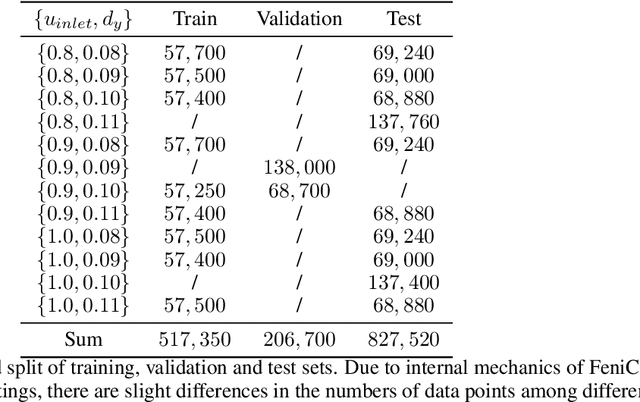
Incompressible fluid flow around a cylinder is one of the classical problems in fluid-dynamics with strong relevance with many real-world engineering problems, for example, design of offshore structures or design of a pin-fin heat exchanger. Thus learning a high-accuracy surrogate for this problem can demonstrate the efficacy of a novel machine learning approach. In this work, we propose a physics-informed neural network (PINN) architecture for learning the relationship between simulation output and the underlying geometry and boundary conditions. In addition to using a physics-based regularization term, the proposed approach also exploits the underlying physics to learn a set of Fourier features, i.e. frequency and phase offset parameters, and then use them for predicting flow velocity and pressure over the spatio-temporal domain. We demonstrate this approach by predicting simulation results over out of range time interval and for novel design conditions. Our results show that incorporation of Fourier features improves the generalization performance over both temporal domain and design space.