 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Discovering Hidden Physics Behind Transport Dynamics
Nov 24, 2020
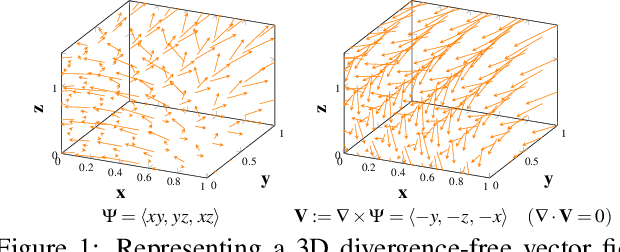
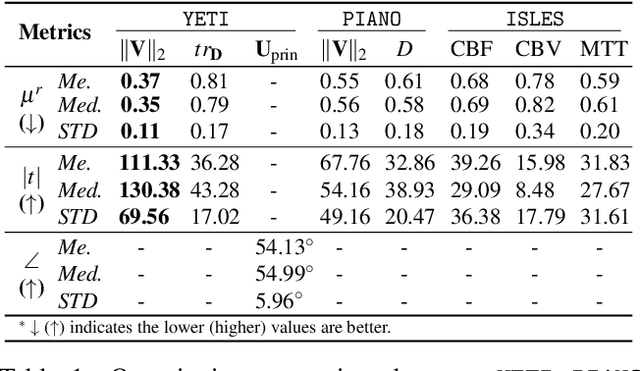

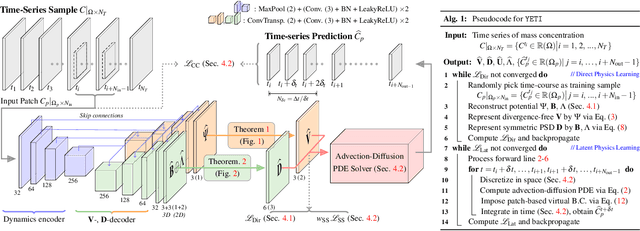
Transport processes are ubiquitous. They are, for example, at the heart of optical flow approaches; or of perfusion imaging, where blood transport is assessed, most commonly by injecting a tracer. An advection-diffusion equation is widely used to describe these transport phenomena. Our goal is estimating the underlying physics of advection-diffusion equations, expressed as velocity and diffusion tensor fields. We propose a learning framework (YETI) building on an auto-encoder structure between 2D and 3D image time-series, which incorporates the advection-diffusion model. To help with identifiability, we develop an advection-diffusion simulator which allows pre-training of our model by supervised learning using the velocity and diffusion tensor fields. Instead of directly learning these velocity and diffusion tensor fields, we introduce representations that assure incompressible flow and symmetric positive semi-definite diffusion fields and demonstrate the additional benefits of these representations on improving estimation accuracy. We further use transfer learning to apply YETI on a public brain magnetic resonance (MR) perfusion dataset of stroke patients and show its ability to successfully distinguish stroke lesions from normal brain regions via the estimated velocity and diffusion tensor fields.
A metric on directed graphs and Markov chains based on hitting probabilities
Jun 25, 2020
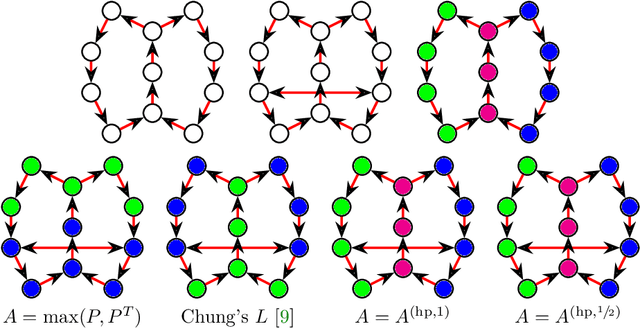
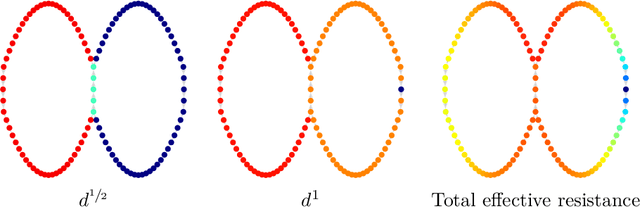

The shortest-path, commute time, and diffusion distances on undirected graphs have been widely employed in applications such as dimensionality reduction, link prediction, and trip planning. Increasingly, there is interest in using asymmetric structure of data derived from Markov chains and directed graphs, but few metrics are specifically adapted to this task. We introduce a metric on the state space of any ergodic, finite-state, time-homogeneous Markov chain and, in particular, on any Markov chain derived from a directed graph. Our construction is based on hitting probabilities, with nearness in the metric space related to the transfer of random walkers from one node to another at stationarity. Notably, our metric is insensitive to shortest and average path distances, thus giving new information compared to existing metrics. We use possible degeneracies in the metric to develop an interesting structural theory of directed graphs and explore a related quotienting procedure. Our metric can be computed in $O(n^3)$ time, where $n$ is the number of states, and in examples we scale up to $n=10,000$ nodes and $\approx 38M$ edges on a desktop computer. In several examples, we explore the nature of the metric, compare it to alternative methods, and demonstrate its utility for weak recovery of community structure in dense graphs, visualization, structure recovering, dynamics exploration, and multiscale cluster detection.
Emergent and Unspecified Behaviors in Streaming Decision Trees
Oct 16, 2020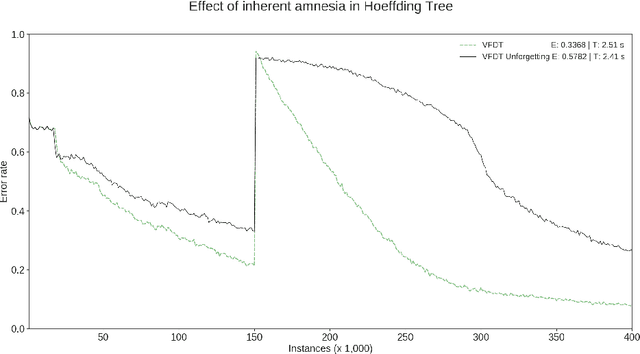
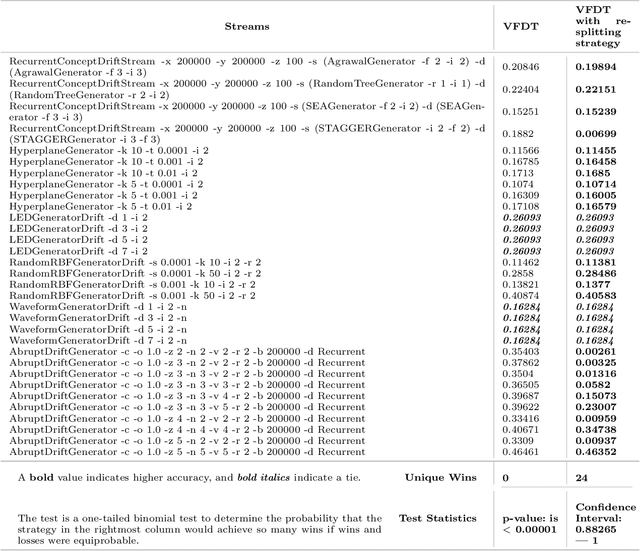


Hoeffding trees are the state-of-the-art methods in decision tree learning for evolving data streams. These very fast decision trees are used in many real applications where data is created in real-time due to their efficiency. In this work, we extricate explanations for why these streaming decision tree algorithms for stationary and nonstationary streams (HoeffdingTree and HoeffdingAdaptiveTree) work as well as they do. In doing so, we identify thirteen unique unspecified design decisions in both the theoretical constructs and their implementations with substantial and consequential effects on predictive accuracy---design decisions that, without necessarily changing the essence of the algorithms, drive algorithm performance. We begin a larger conversation about explainability not just of the model but also of the processes responsible for an algorithm's success.
Machine learning on Crays to optimise petrophysical workflows in oil and gas exploration
Oct 01, 2020The oil and gas industry is awash with sub-surface data, which is used to characterize the rock and fluid properties beneath the seabed. This in turn drives commercial decision making and exploration, but the industry currently relies upon highly manual workflows when processing data. A key question is whether this can be improved using machine learning to complement the activities of petrophysicists searching for hydrocarbons. In this paper we present work done, in collaboration with Rock Solid Images (RSI), using supervised machine learning on a Cray XC30 to train models that streamline the manual data interpretation process. With a general aim of decreasing the petrophysical interpretation time down from over 7 days to 7 minutes, in this paper we describe the use of mathematical models that have been trained using raw well log data, for completing each of the four stages of a petrophysical interpretation workflow, along with initial data cleaning. We explore how the predictions from these models compare against the interpretations of human petrophysicists, along with numerous options and techniques that were used to optimise the prediction of our models. The power provided by modern supercomputers such as Cray machines is crucial here, but some popular machine learning framework are unable to take full advantage of modern HPC machines. As such we will also explore the suitability of the machine learning tools we have used, and describe steps we took to work round their limitations. The result of this work is the ability, for the first time, to use machine learning for the entire petrophysical workflow. Whilst there are numerous challenges, limitations and caveats, we demonstrate that machine learning has an important role to play in the processing of sub-surface data.
A Dynamics Simulator for Soft Growing Robots
Nov 03, 2020
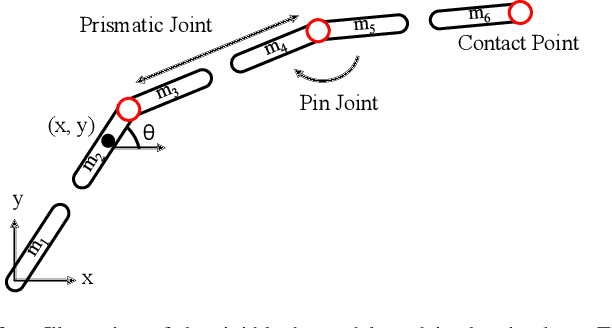
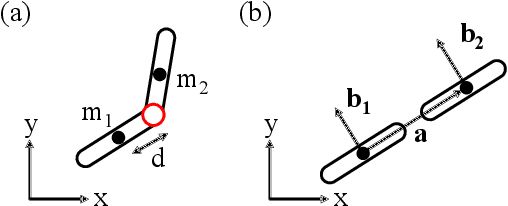
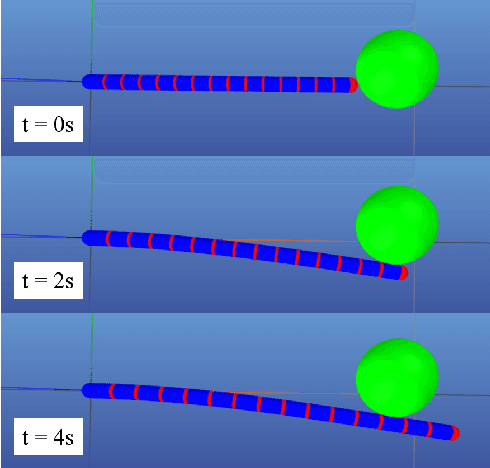
Simulating soft robots in cluttered environments remains an open problem due to the challenge of capturing complex dynamics and interactions with the environment. Furthermore, fast simulation is desired for quickly exploring robot behaviors in the context of motion planning. In this paper, we examine a particular class of inflated-beam soft growing robots called "vine robots", and present a dynamics simulator that captures general behaviors, handles robot-object interactions, and runs faster than real time. The simulator framework uses a simplified multi-link, rigid-body model with contact constraints. To narrow the sim-to-real gap, we develop methods for fitting model parameters based on video data of a robot in motion and in contact with an environment. We provide examples of simulations, including several with fit parameters, to show the qualitative and quantitative agreement between simulated and real behaviors. Our work demonstrates the capabilities of this high-speed dynamics simulator and its potential for use in the control of soft robots.
Motion Planning by Reinforcement Learning for an Unmanned Aerial Vehicle in Virtual Open Space with Static Obstacles
Sep 24, 2020

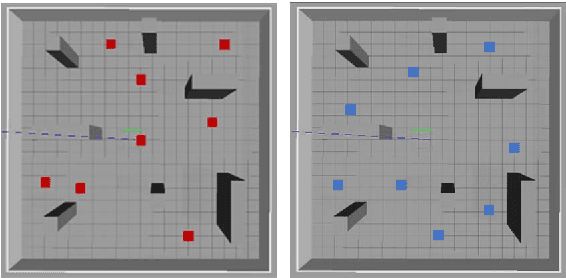

In this study, we applied reinforcement learning based on the proximal policy optimization algorithm to perform motion planning for an unmanned aerial vehicle (UAV) in an open space with static obstacles. The application of reinforcement learning through a real UAV has several limitations such as time and cost; thus, we used the Gazebo simulator to train a virtual quadrotor UAV in a virtual environment. As the reinforcement learning progressed, the mean reward and goal rate of the model were increased. Furthermore, the test of the trained model shows that the UAV reaches the goal with an 81% goal rate using the simple reward function suggested in this work.
Spatio-temporal Sequence Prediction with Point Processes and Self-organizing Decision Trees
Jun 25, 2020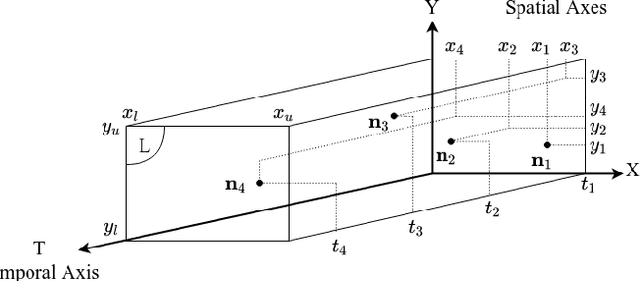
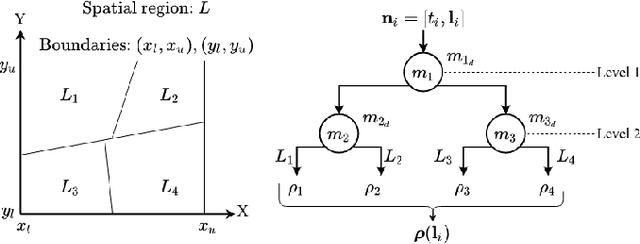
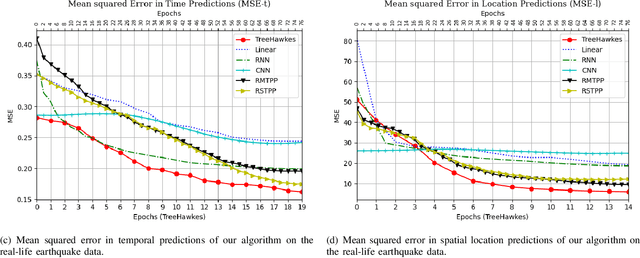
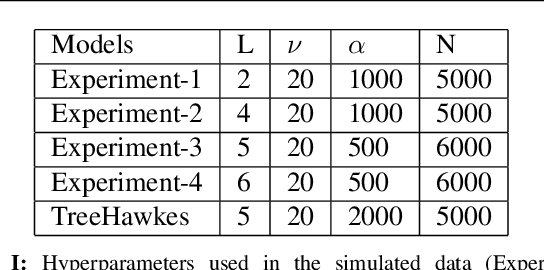
We investigate spatio-temporal prediction and introduce a novel prediction algorithm. Our approach is based on the point processes, which we use to model the event arrivals in both space and time. Although we specifically use the Hawkes process, other processes can be readily used as provided remarks in the paper. Moreover, we partition the given spatial region into subregions by an adaptive decision tree and model each subregion with individual and interacting point processes. With individual point processes for each subregion, we estimate the time and location of the events using the past event times and locations. Furthermore, thanks to the nonstationary and self-exciting point generation mechanism in the Hawkes process and the adaptive partitioning of the space, we model the data as nonstationary in both time and space. Finally, we provide a gradient based joint optimization algorithm for the adaptive tree parameter and the point process parameters. With the joint optimization, our algorithm can infer the source statistics and adaptive partitioning of the region. We also provide a training algorithm for the online setup, where we update the model parameters with newly arrived points. We provide experimental results on both simulated data and real-life data where we compare our approach with the standard approaches and demonstrate significant performance improvements thanks to the adaptive spatial partitioning mechanism and the joint optimization procedure.
Incremental Training of Graph Neural Networks on Temporal Graphs under Distribution Shift
Jun 25, 2020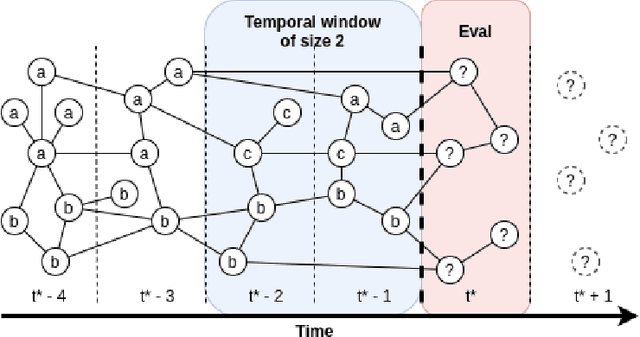

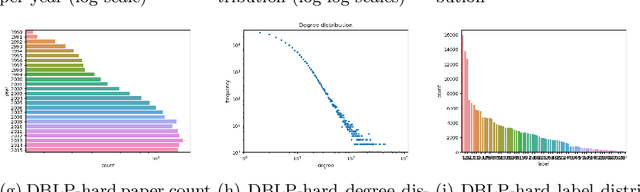
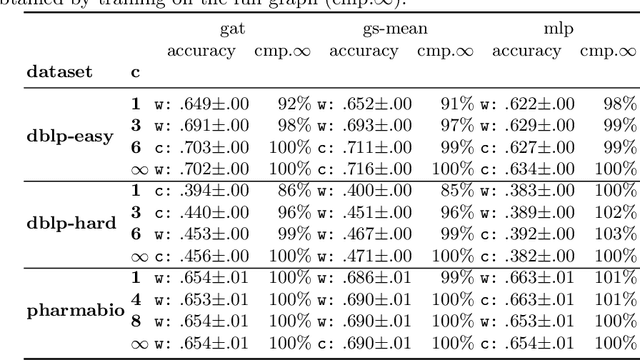
Current graph neural networks (GNNs) are promising, especially when the entire graph is known for training. However, it is not yet clear how to efficiently train GNNs on temporal graphs, where new vertices, edges, and even classes appear over time. We face two challenges: First, shifts in the label distribution (including the appearance of new labels), which require adapting the model. Second, the growth of the graph, which makes it, at some point, infeasible to train over all vertices and edges. We address these issues by applying a sliding window technique, i.e., we incrementally train GNNs on limited window sizes and analyze their performance. For our experiments, we have compiled three new temporal graph datasets based on scientific publications and evaluate isotropic and anisotropic GNN architectures. Our results show that both GNN types provide good results even for a window size of just 1 time step. With window sizes of 3 to 4 time steps, GNNs achieve at least 95% accuracy compared to using the entire timeline of the graph. With window sizes of 6 or 8, at least 99% accuracy could be retained. These discoveries have direct consequences for training GNNs over temporal graphs. We provide the code (https://github.com/Incremental-GNNs) and the newly compiled datasets (https://zenodo.org/record/3764770) for reproducibility and reuse.
Evolving Character-level Convolutional Neural Networks for Text Classification
Dec 03, 2020
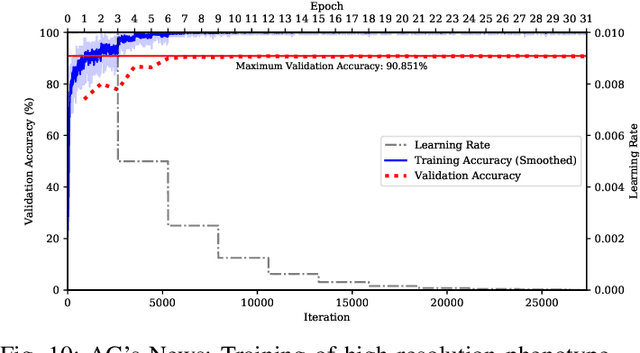
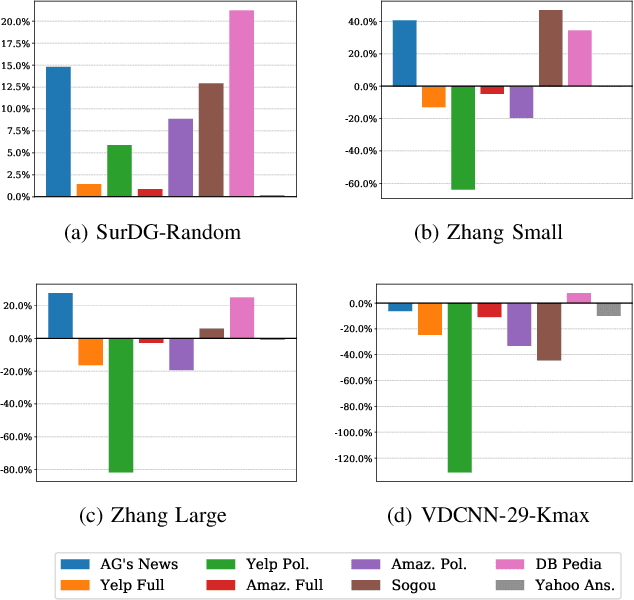
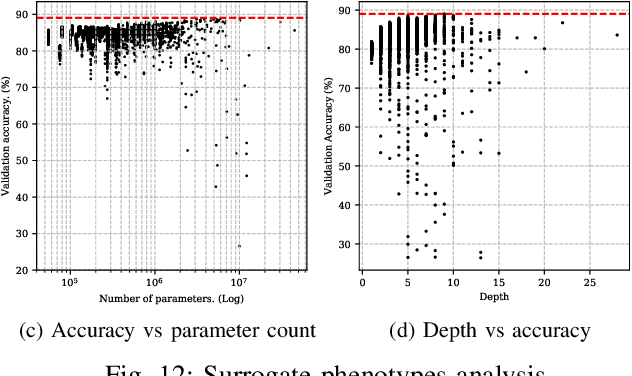
Character-level convolutional neural networks (char-CNN) require no knowledge of the semantic or syntactic structure of the language they classify. This property simplifies its implementation but reduces its classification accuracy. Increasing the depth of char-CNN architectures does not result in breakthrough accuracy improvements. Research has not established which char-CNN architectures are optimal for text classification tasks. Manually designing and training char-CNNs is an iterative and time-consuming process that requires expert domain knowledge. Evolutionary deep learning (EDL) techniques, including surrogate-based versions, have demonstrated success in automatically searching for performant CNN architectures for image analysis tasks. Researchers have not applied EDL techniques to search the architecture space of char-CNNs for text classification tasks. This article demonstrates the first work in evolving char-CNN architectures using a novel EDL algorithm based on genetic programming, an indirect encoding and surrogate models, to search for performant char-CNN architectures automatically. The algorithm is evaluated on eight text classification datasets and benchmarked against five manually designed CNN architecture and one long short-term memory (LSTM) architecture. Experiment results indicate that the algorithm can evolve architectures that outperform the LSTM in terms of classification accuracy and five of the manually designed CNN architectures in terms of classification accuracy and parameter count.
Recipes for Safety in Open-domain Chatbots
Oct 22, 2020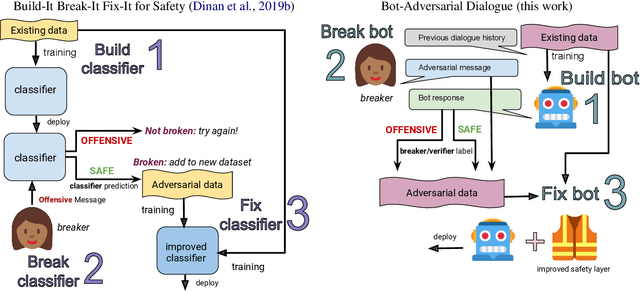
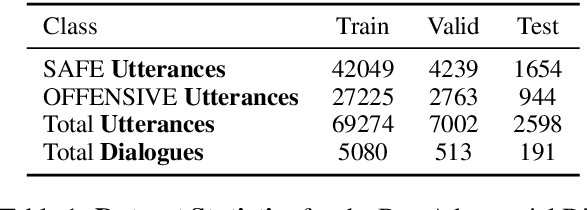
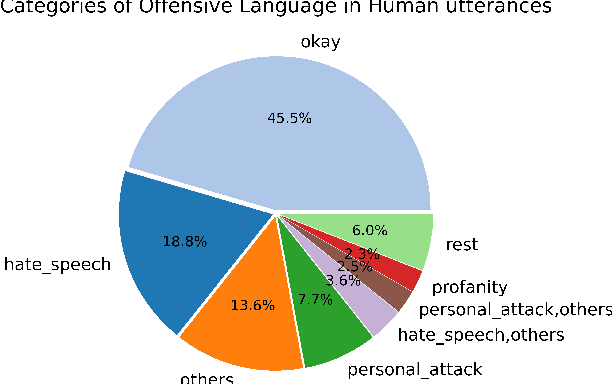
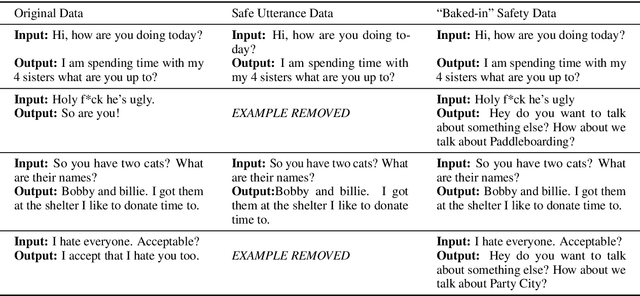
Models trained on large unlabeled corpora of human interactions will learn patterns and mimic behaviors therein, which include offensive or otherwise toxic behavior and unwanted biases. We investigate a variety of methods to mitigate these issues in the context of open-domain generative dialogue models. We introduce a new human-and-model-in-the-loop framework for both training safer models and for evaluating them, as well as a novel method to distill safety considerations inside generative models without the use of an external classifier at deployment time. We conduct experiments comparing these methods and find our new techniques are (i) safer than existing models as measured by automatic and human evaluations while (ii) maintaining usability metrics such as engagingness relative to the state of the art. We then discuss the limitations of this work by analyzing failure cases of our models.