 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Tick: a Python library for statistical learning, with a particular emphasis on time-dependent modelling
Mar 15, 2018


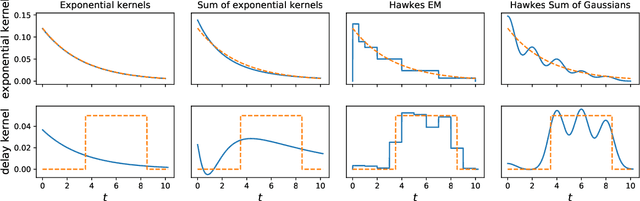
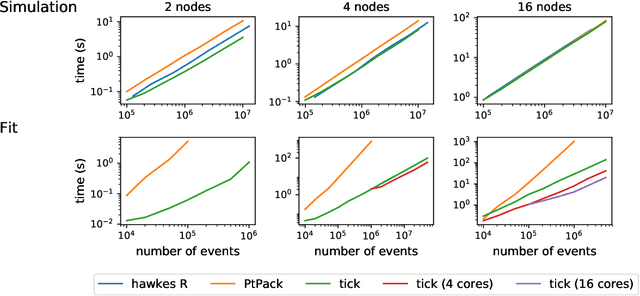
Tick is a statistical learning library for Python~3, with a particular emphasis on time-dependent models, such as point processes, and tools for generalized linear models and survival analysis. The core of the library is an optimization module providing model computational classes, solvers and proximal operators for regularization. tick relies on a C++ implementation and state-of-the-art optimization algorithms to provide very fast computations in a single node multi-core setting. Source code and documentation can be downloaded from https://github.com/X-DataInitiative/tick
Summarizing Utterances from Japanese Assembly Minutes using Political Sentence-BERT-based Method for QA Lab-PoliInfo-2 Task of NTCIR-15
Oct 22, 2020
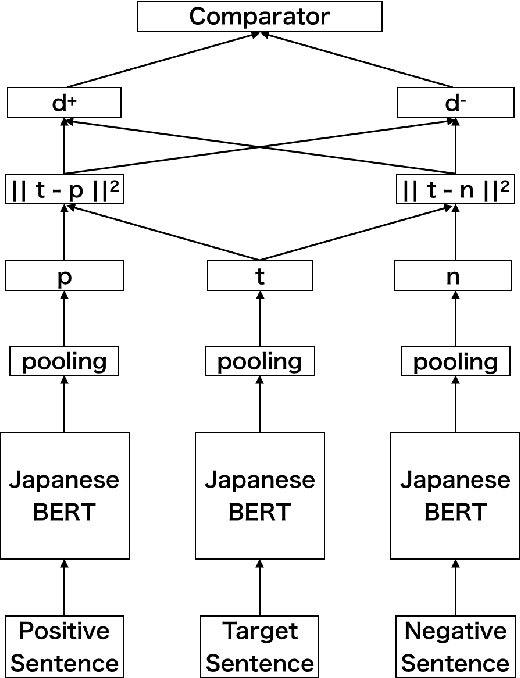
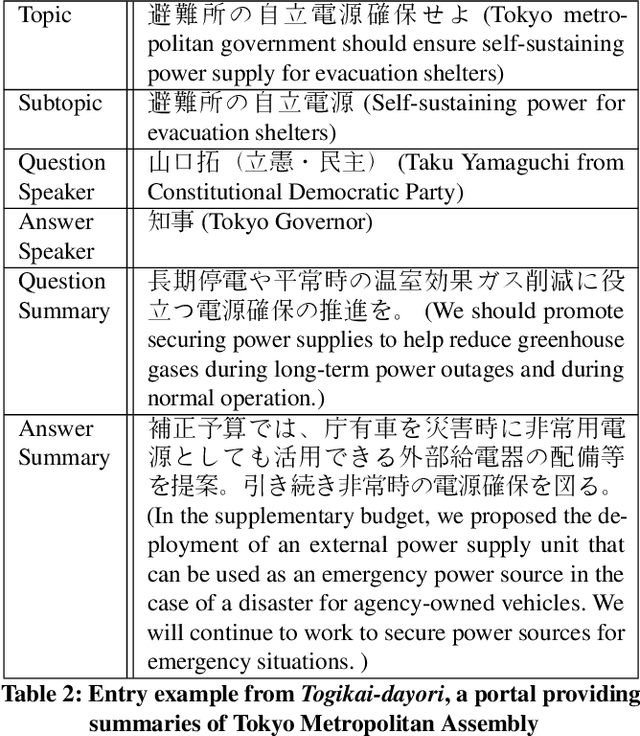

There are many discussions held during political meetings, and a large number of utterances for various topics is included in their transcripts. We need to read all of them if we want to follow speakers\' intentions or opinions about a given topic. To avoid such a costly and time-consuming process to grasp often longish discussions, NLP researchers work on generating concise summaries of utterances. Summarization subtask in QA Lab-PoliInfo-2 task of the NTCIR-15 addresses this problem for Japanese utterances in assembly minutes, and our team (SKRA) participated in this subtask. As a first step for summarizing utterances, we created a new pre-trained sentence embedding model, i.e. the Japanese Political Sentence-BERT. With this model, we summarize utterances without labelled data. This paper describes our approach to solving the task and discusses its results.
A new GPU library for fast simulation of large-scale networks of spiking neurons
Jul 29, 2020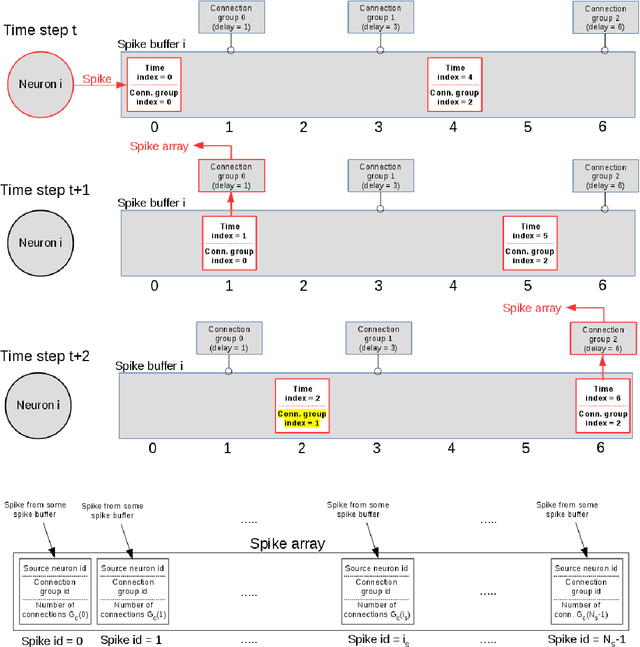
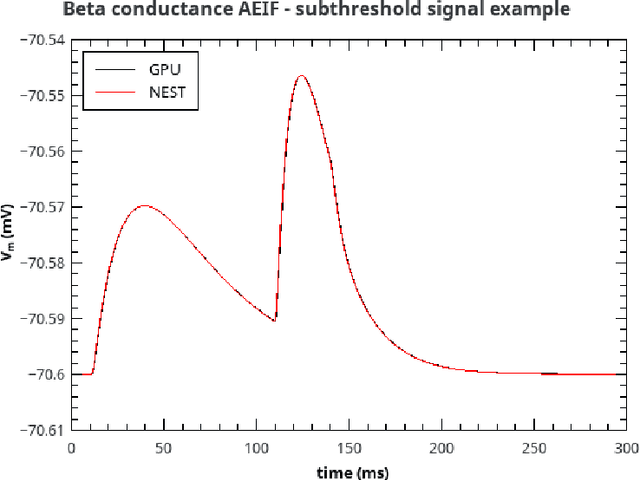
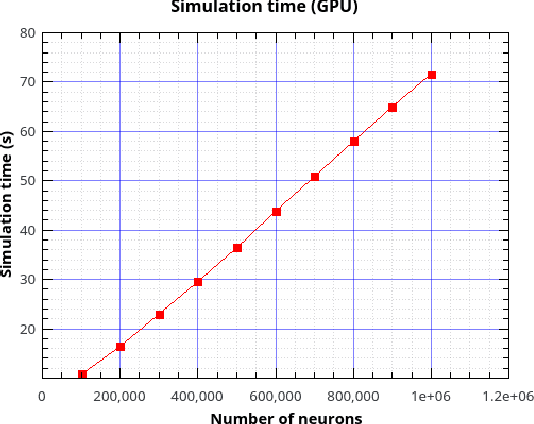
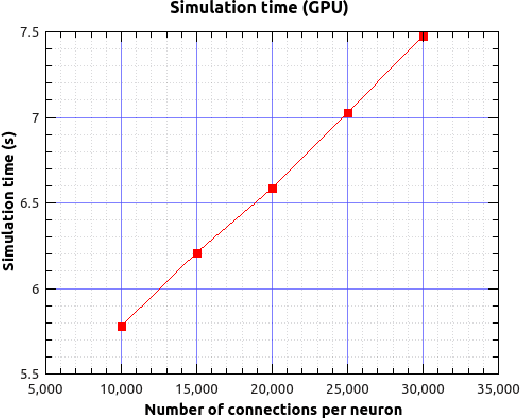
Over the past decade there has been a growing interest in the development of parallel hardware systems for simulating large-scale networks of spiking neurons. Compared to other highly-parallel systems, GPU-accelerated solutions have the advantage of a relatively low cost and a great versatility, thanks also to the possibility of using the CUDA-C/C++ programming languages. NeuronGPU is a GPU library for large-scale simulations of spiking neural network models, written in the C++ and CUDA-C++ programming languages, based on a novel spike-delivery algorithm. This library includes simple LIF (leaky-integrate-and-fire) neuron models as well as several multisynapse AdEx (adaptive-exponential-integrate-and-fire) neuron models with current or conductance based synapses, user definable models and different devices. The numerical solution of the differential equations of the dynamics of the AdEx models is performed through a parallel implementation, written in CUDA-C++, of the fifth-order Runge-Kutta method with adaptive step-size control. In this work we evaluate the performance of this library on the simulation of a well-known cortical microcircuit model, based on LIF neurons and current-based synapses, and on a balanced networks of excitatory and inhibitory neurons, using AdEx neurons and conductance-based synapses. On these models, we will show that the proposed library achieves state-of-the-art performance in terms of simulation time per second of biological activity. In particular, using a single NVIDIA GeForce RTX 2080 Ti GPU board, the full-scale cortical-microcircuit model, which includes about 77,000 neurons and $3 \cdot 10^8$ connections, can be simulated at a speed very close to real time, while the simulation time of a balanced network of 1,000,000 AdEx neurons with 1,000 connections per neuron was about 70 s per second of biological activity.
A Reinforcement Learning Based Encoder-Decoder Framework for Learning Stock Trading Rules
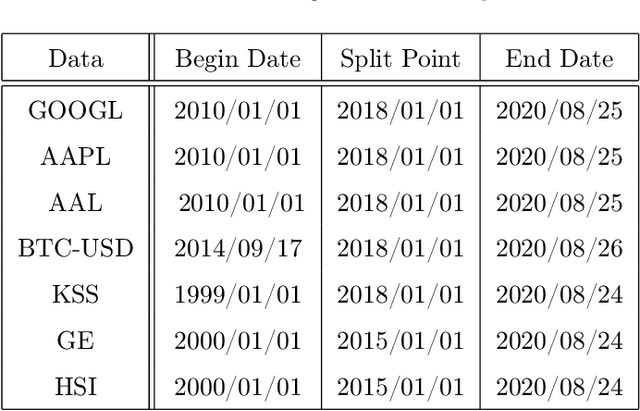
Jan 08, 2021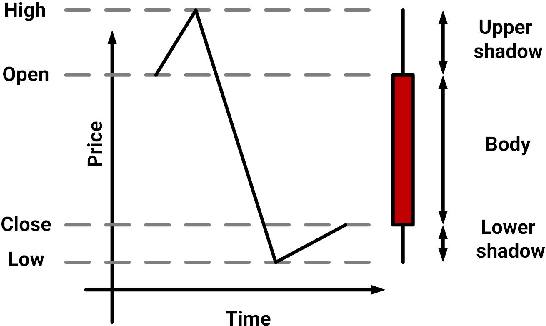
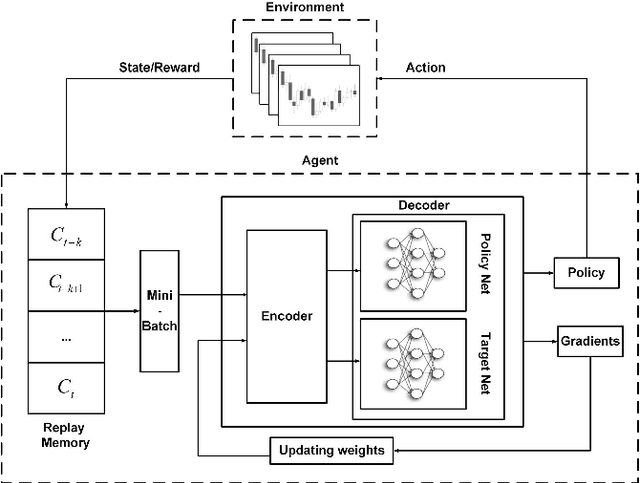
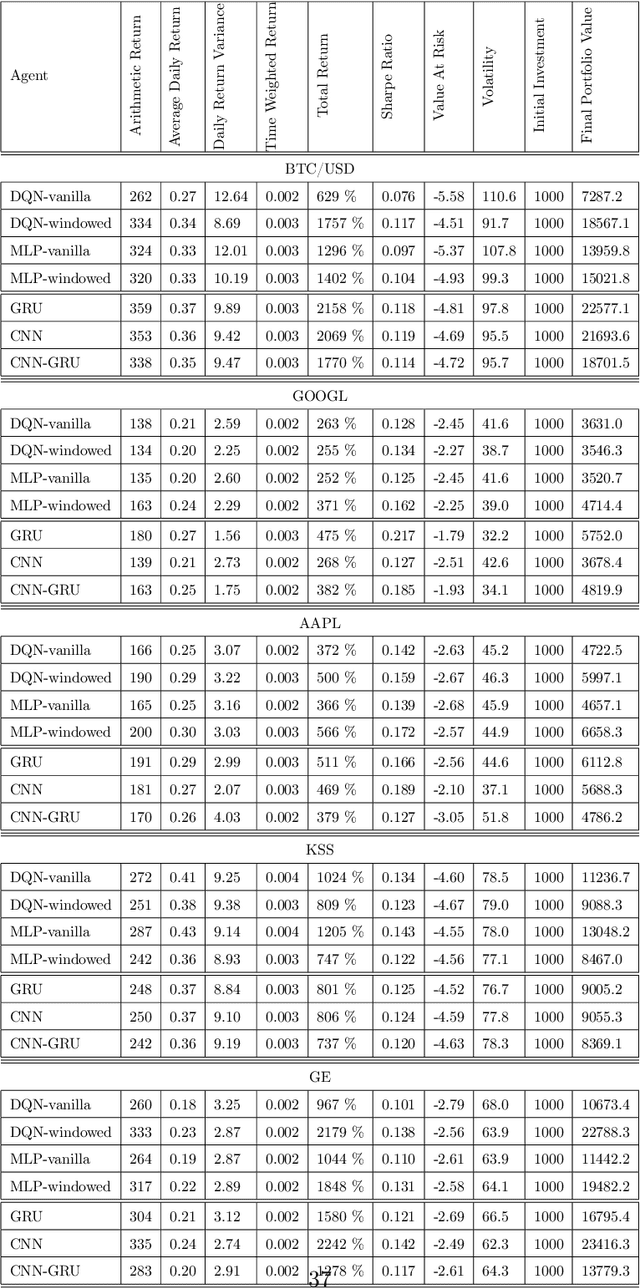
A wide variety of deep reinforcement learning (DRL) models have recently been proposed to learn profitable investment strategies. The rules learned by these models outperform the previous strategies specially in high frequency trading environments. However, it is shown that the quality of the extracted features from a long-term sequence of raw prices of the instruments greatly affects the performance of the trading rules learned by these models. Employing a neural encoder-decoder structure to extract informative features from complex input time-series has proved very effective in other popular tasks like neural machine translation and video captioning in which the models face a similar problem. The encoder-decoder framework extracts highly informative features from a long sequence of prices along with learning how to generate outputs based on the extracted features. In this paper, a novel end-to-end model based on the neural encoder-decoder framework combined with DRL is proposed to learn single instrument trading strategies from a long sequence of raw prices of the instrument. The proposed model consists of an encoder which is a neural structure responsible for learning informative features from the input sequence, and a decoder which is a DRL model responsible for learning profitable strategies based on the features extracted by the encoder. The parameters of the encoder and the decoder structures are learned jointly, which enables the encoder to extract features fitted to the task of the decoder DRL. In addition, the effects of different structures for the encoder and various forms of the input sequences on the performance of the learned strategies are investigated. Experimental results showed that the proposed model outperforms other state-of-the-art models in highly dynamic environments.
A Dynamics Simulator for Soft Growing Robots
Nov 03, 2020
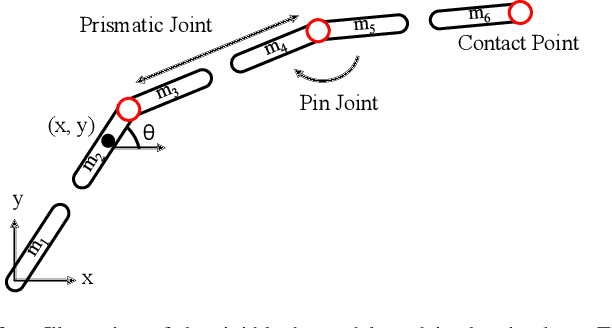
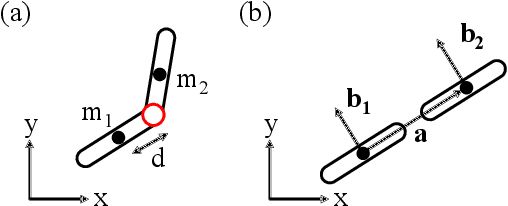
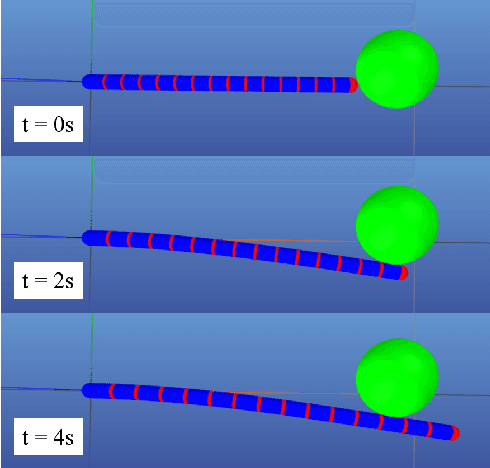
Simulating soft robots in cluttered environments remains an open problem due to the challenge of capturing complex dynamics and interactions with the environment. Furthermore, fast simulation is desired for quickly exploring robot behaviors in the context of motion planning. In this paper, we examine a particular class of inflated-beam soft growing robots called "vine robots", and present a dynamics simulator that captures general behaviors, handles robot-object interactions, and runs faster than real time. The simulator framework uses a simplified multi-link, rigid-body model with contact constraints. To narrow the sim-to-real gap, we develop methods for fitting model parameters based on video data of a robot in motion and in contact with an environment. We provide examples of simulations, including several with fit parameters, to show the qualitative and quantitative agreement between simulated and real behaviors. Our work demonstrates the capabilities of this high-speed dynamics simulator and its potential for use in the control of soft robots.
CellCycleGAN: Spatiotemporal Microscopy Image Synthesis of Cell Populations using Statistical Shape Models and Conditional GANs
Oct 22, 2020
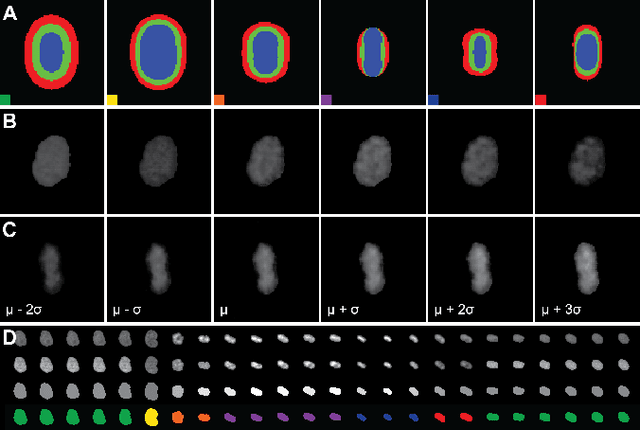
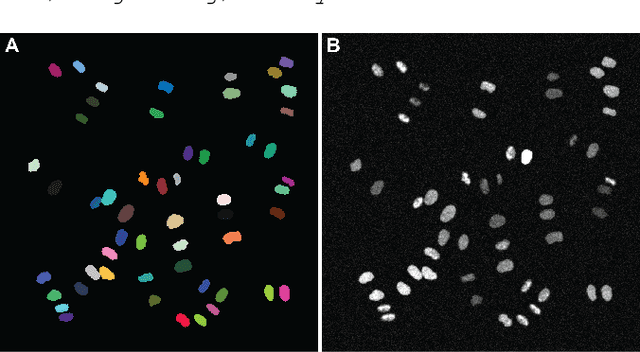
Automatic analysis of spatio-temporal microscopy images is inevitable for state-of-the-art research in the life sciences. Recent developments in deep learning provide powerful tools for automatic analyses of such image data, but heavily depend on the amount and quality of provided training data to perform well. To this end, we developed a new method for realistic generation of synthetic 2D+t microscopy image data of fluorescently labeled cellular nuclei. The method combines spatiotemporal statistical shape models of different cell cycle stages with a conditional GAN to generate time series of cell populations and provides instance-level control of cell cycle stage and the fluorescence intensity of generated cells. We show the effect of the GAN conditioning and create a set of synthetic images that can be readily used for training and benchmarking of cell segmentation and tracking approaches.
Distributional Reinforcement Learning for mmWave Communications with Intelligent Reflectors on a UAV
Nov 03, 2020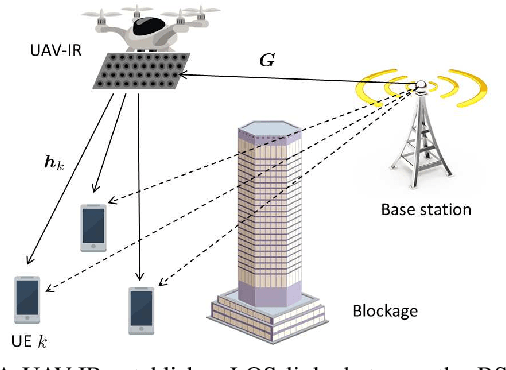
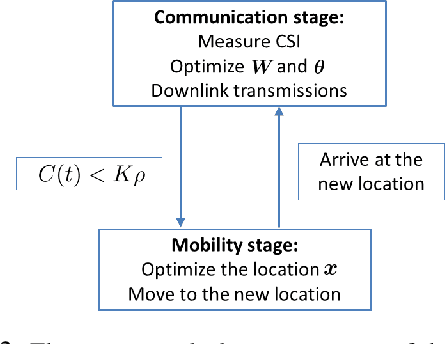
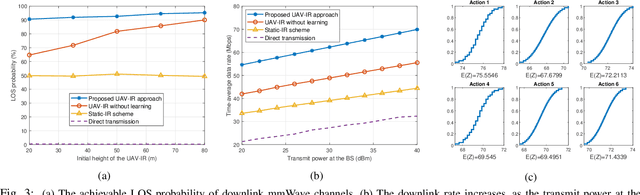
In this paper, a novel communication framework that uses an unmanned aerial vehicle (UAV)-carried intelligent reflector (IR) is proposed to enhance multi-user downlink transmissions over millimeter wave (mmWave) frequencies. In order to maximize the downlink sum-rate, the optimal precoding matrix (at the base station) and reflection coefficient (at the IR) are jointly derived. Next, to address the uncertainty of mmWave channels and maintain line-of-sight links in a real-time manner, a distributional reinforcement learning approach, based on quantile regression optimization, is proposed to learn the propagation environment of mmWave communications, and, then, optimize the location of the UAV-IR so as to maximize the long-term downlink communication capacity. Simulation results show that the proposed learning-based deployment of the UAV-IR yields a significant advantage, compared to a non-learning UAV-IR, a static IR, and a direct transmission schemes, in terms of the average data rate and the achievable line-of-sight probability of downlink mmWave communications.
SMART Frame Selection for Action Recognition
Dec 19, 2020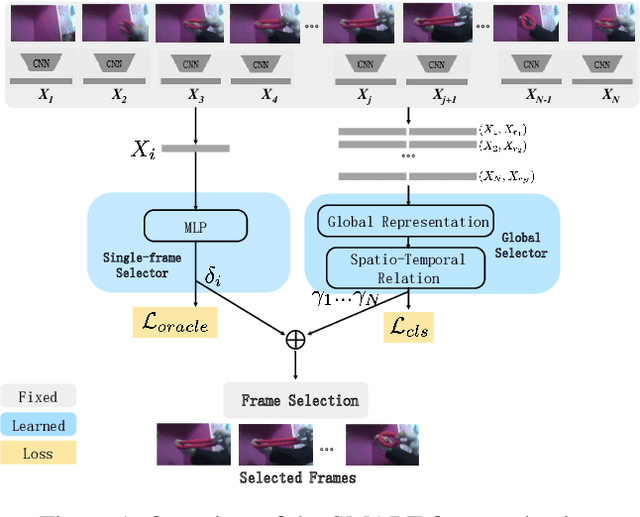
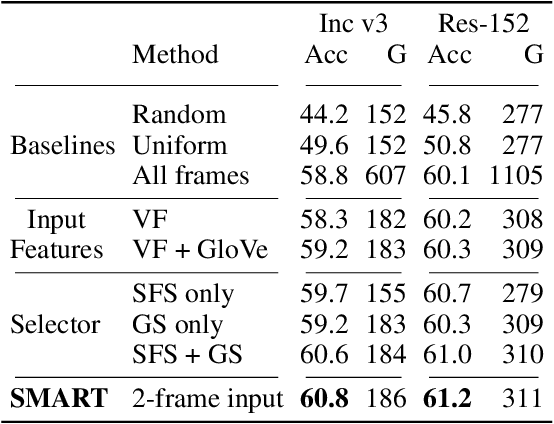

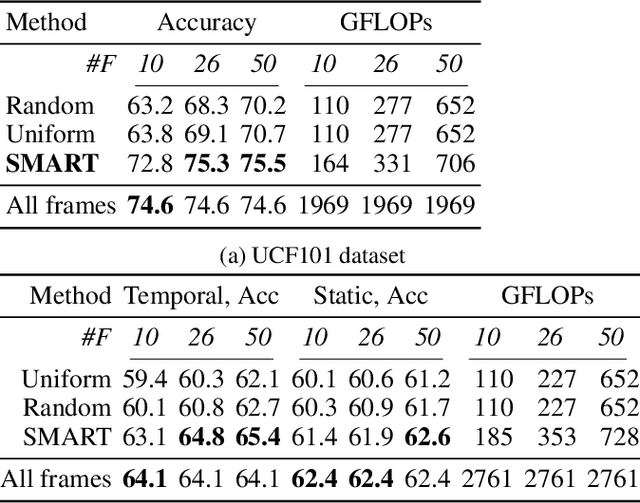
Action recognition is computationally expensive. In this paper, we address the problem of frame selection to improve the accuracy of action recognition. In particular, we show that selecting good frames helps in action recognition performance even in the trimmed videos domain. Recent work has successfully leveraged frame selection for long, untrimmed videos, where much of the content is not relevant, and easy to discard. In this work, however, we focus on the more standard short, trimmed action recognition problem. We argue that good frame selection can not only reduce the computational cost of action recognition but also increase the accuracy by getting rid of frames that are hard to classify. In contrast to previous work, we propose a method that instead of selecting frames by considering one at a time, considers them jointly. This results in a more efficient selection, where good frames are more effectively distributed over the video, like snapshots that tell a story. We call the proposed frame selection SMART and we test it in combination with different backbone architectures and on multiple benchmarks (Kinetics, Something-something, UCF101). We show that the SMART frame selection consistently improves the accuracy compared to other frame selection strategies while reducing the computational cost by a factor of 4 to 10 times. Additionally, we show that when the primary goal is recognition performance, our selection strategy can improve over recent state-of-the-art models and frame selection strategies on various benchmarks (UCF101, HMDB51, FCVID, and ActivityNet).
On Filter Generalization for Music Bandwidth Extension Using Deep Neural Networks
Nov 14, 2020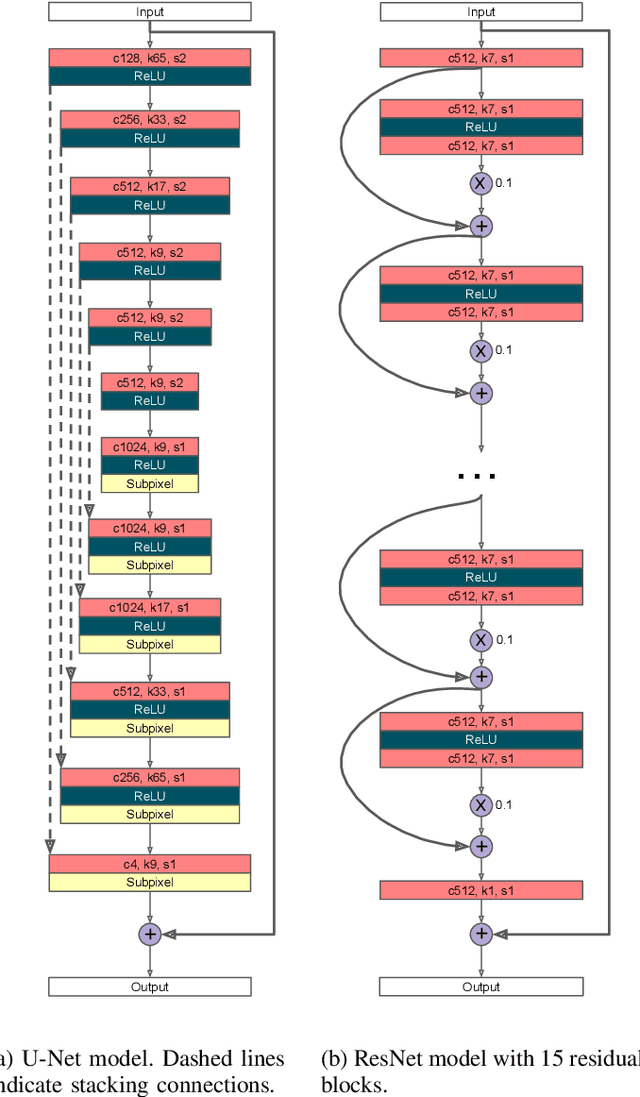
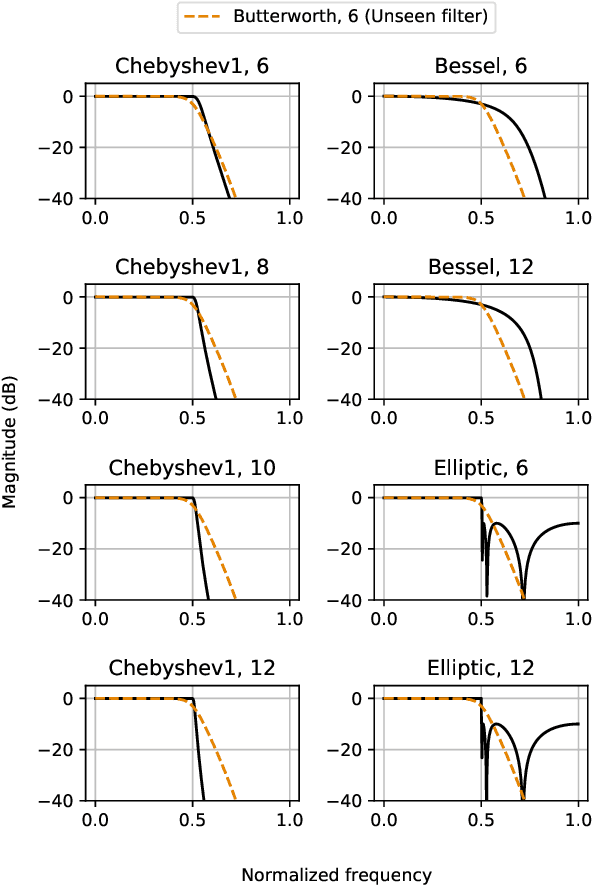
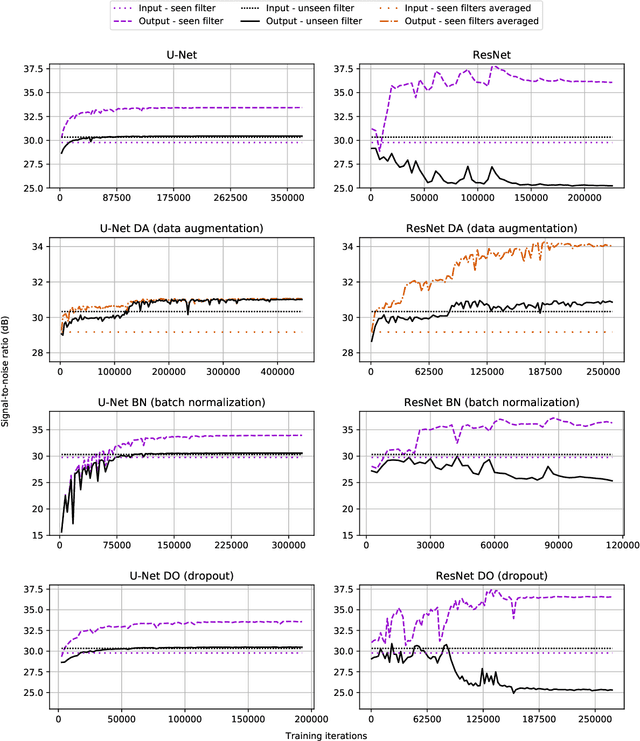
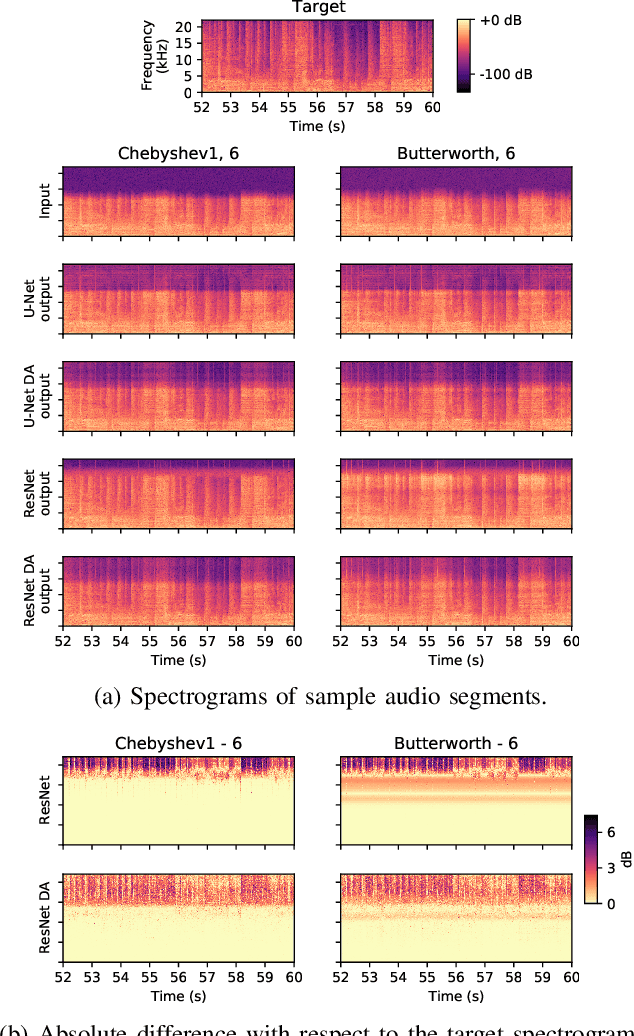
In this paper, we address a sub-topic of the broad domain of audio enhancement, namely musical audio bandwidth extension. We formulate the bandwidth extension problem using deep neural networks, where a band-limited signal is provided as input to the network, with the goal of reconstructing a full-bandwidth output. Our main contribution centers on the impact of the choice of low pass filter when training and subsequently testing the network. For two different state of the art deep architectures, ResNet and U-Net, we demonstrate that when the training and testing filters are matched, improvements in signal-to-noise ratio (SNR) of up to 7dB can be obtained. However, when these filters differ, the improvement falls considerably and under some training conditions results in a lower SNR than the band-limited input. To circumvent this apparent overfitting to filter shape, we propose a data augmentation strategy which utilizes multiple low pass filters during training and leads to improved generalization to unseen filtering conditions at test time.
Recipes for Safety in Open-domain Chatbots
Oct 22, 2020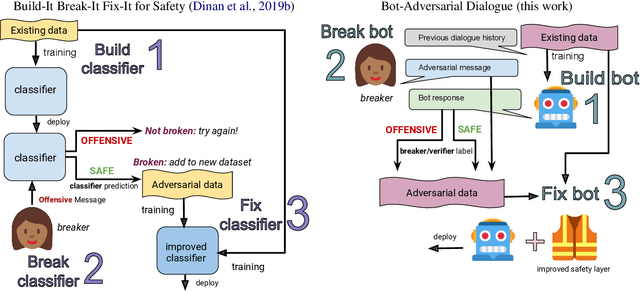
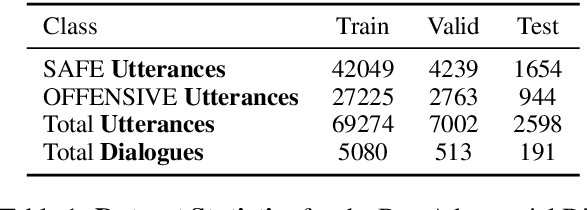
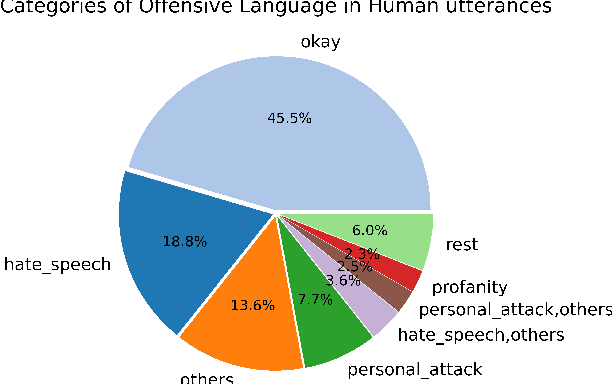
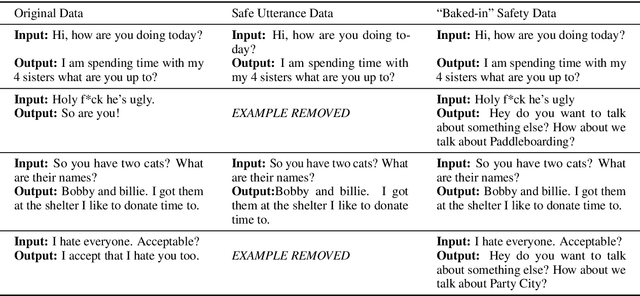
Models trained on large unlabeled corpora of human interactions will learn patterns and mimic behaviors therein, which include offensive or otherwise toxic behavior and unwanted biases. We investigate a variety of methods to mitigate these issues in the context of open-domain generative dialogue models. We introduce a new human-and-model-in-the-loop framework for both training safer models and for evaluating them, as well as a novel method to distill safety considerations inside generative models without the use of an external classifier at deployment time. We conduct experiments comparing these methods and find our new techniques are (i) safer than existing models as measured by automatic and human evaluations while (ii) maintaining usability metrics such as engagingness relative to the state of the art. We then discuss the limitations of this work by analyzing failure cases of our models.