 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Demonstration-efficient Inverse Reinforcement Learning in Procedurally Generated Environments
Dec 04, 2020
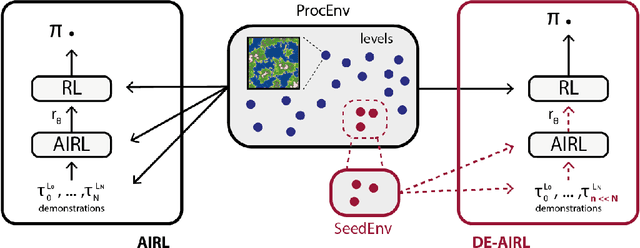
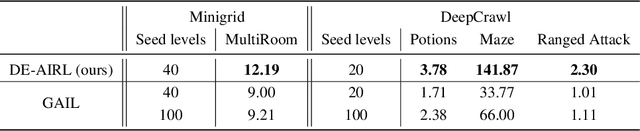

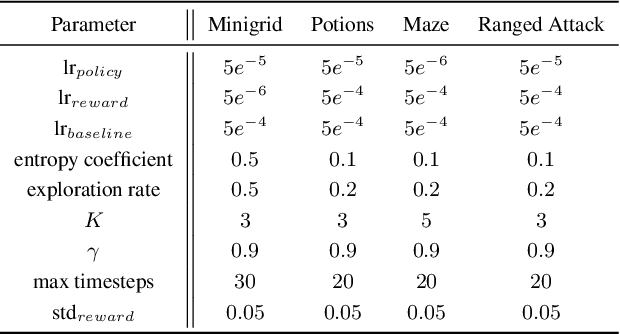
Deep Reinforcement Learning achieves very good results in domains where reward functions can be manually engineered. At the same time, there is growing interest within the community in using games based on Procedurally Content Generation (PCG) as benchmark environments since this type of environment is perfect for studying overfitting and generalization of agents under domain shift. Inverse Reinforcement Learning (IRL) can instead extrapolate reward functions from expert demonstrations, with good results even on high-dimensional problems, however there are no examples of applying these techniques to procedurally-generated environments. This is mostly due to the number of demonstrations needed to find a good reward model. We propose a technique based on Adversarial Inverse Reinforcement Learning which can significantly decrease the need for expert demonstrations in PCG games. Through the use of an environment with a limited set of initial seed levels, plus some modifications to stabilize training, we show that our approach, DE-AIRL, is demonstration-efficient and still able to extrapolate reward functions which generalize to the fully procedural domain. We demonstrate the effectiveness of our technique on two procedural environments, MiniGrid and DeepCrawl, for a variety of tasks.
Single upper limb pose estimation method based on improved stacked hourglass network
Apr 16, 2020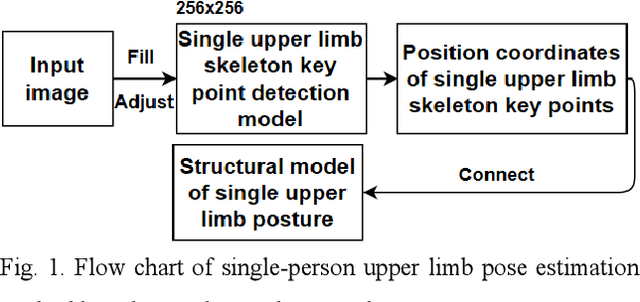
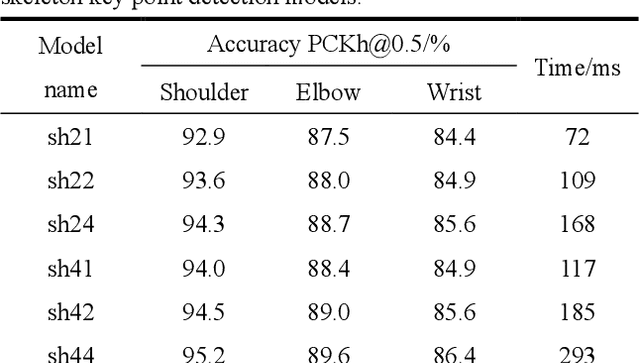
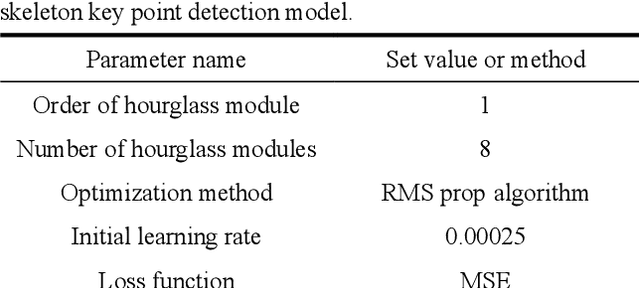

At present, most high-accuracy single-person pose estimation methods have high computational complexity and insufficient real-time performance due to the complex structure of the network model. However, a single-person pose estimation method with high real-time performance also needs to improve its accuracy due to the simple structure of the network model. It is currently difficult to achieve both high accuracy and real-time performance in single-person pose estimation. For use in human-machine cooperative operations, this paper proposes a single-person upper limb pose estimation method based on an end-to-end approach for accurate and real-time limb pose estimation. Using the stacked hourglass network model, a single-person upper limb skeleton key point detection model was designed.Deconvolution was employed to replace the up-sampling operation of the hourglass module in the original model, solving the problem of rough feature maps. Integral regression was used to calculate the position coordinates of key points of the skeleton, reducing quantization errors and calculations. Experiments showed that the developed single-person upper limb skeleton key point detection model achieves high accuracy and that the pose estimation method based on the end-to-end approach provides high accuracy and real-time performance.
Utilizing Concept Drift for Measuring the Effectiveness of Policy Interventions: The Case of the COVID-19 Pandemic
Dec 04, 2020
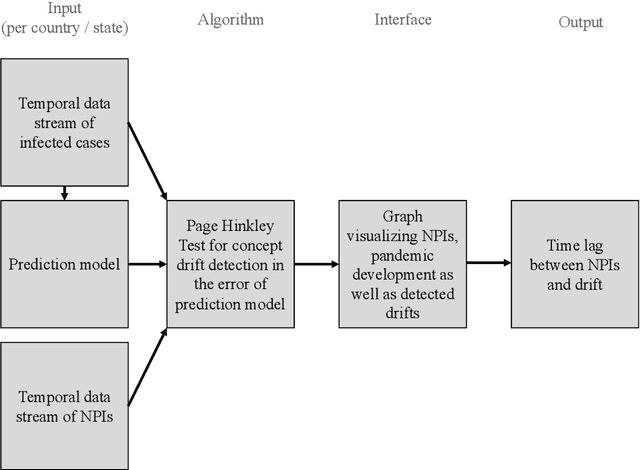
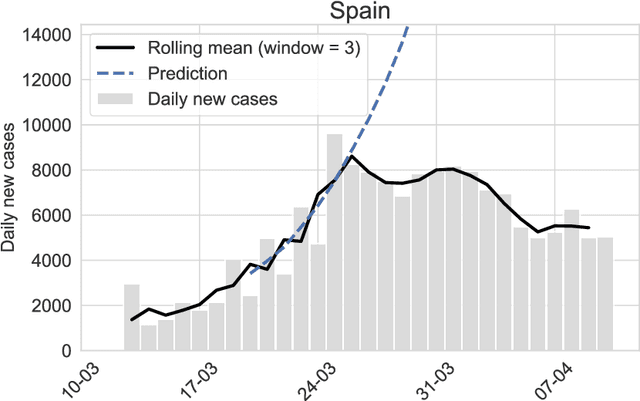
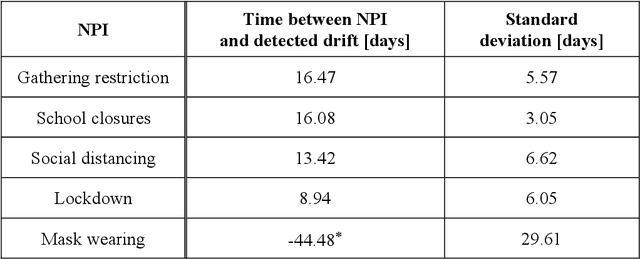
As a reaction to the high infectiousness and lethality of the COVID-19 virus, countries around the world have adopted drastic policy measures to contain the pandemic. However, it remains unclear which effect these measures, so-called non-pharmaceutical interventions (NPIs), have on the spread of the virus. In this article, we use machine learning and apply drift detection methods in a novel way to measure the effectiveness of policy interventions: We analyze the effect of NPIs on the development of daily case numbers of COVID-19 across 9 European countries and 28 US states. Our analysis shows that it takes more than two weeks on average until NPIs show a significant effect on the number of new cases. We then analyze how characteristics of each country or state, e.g., decisiveness regarding NPIs, climate or population density, influence the time lag until NPIs show their effectiveness. In our analysis, especially the timing of school closures reveals a significant effect on the development of the pandemic. This information is crucial for policy makers confronted with difficult decisions to trade off strict containment of the virus with NPI relief.
Photoacoustic Image Reconstruction Beyond Supervised to Compensate Limit-view and Remove Artifacts
Dec 04, 2020
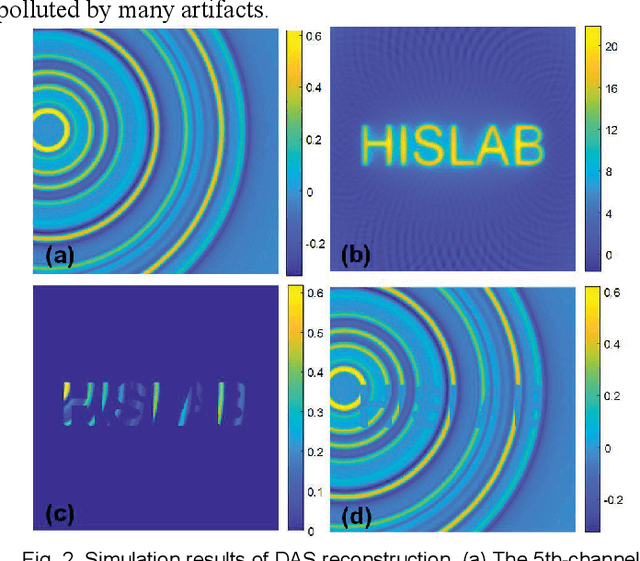
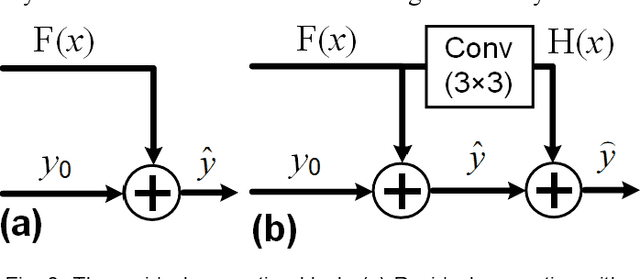
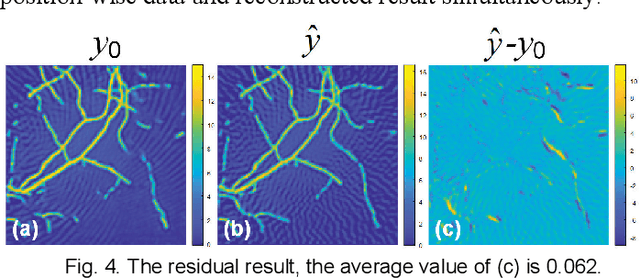
Photoacoustic computed tomography (PACT) reconstructs the initial pressure distribution from raw PA signals. Standard reconstruction always induces artifacts using limited-view signals, which are influenced by limited angle coverage of transducers, finite bandwidth, and uncertain heterogeneous biological tissue. Recently, supervised deep learning has been used to overcome limited-view problem that requires ground-truth. However, even full-view sampling still induces artifacts that cannot be used to train the model. It causes a dilemma that we could not acquire perfect ground-truth in practice. To reduce the dependence on the quality of ground-truth, in this paper, for the first time, we propose a beyond supervised reconstruction framework (BSR-Net) based on deep learning to compensate the limited-view issue by feeding limited-view position-wise data. A quarter position-wise data is fed into model and outputs a group full-view data. Specifically, our method introduces a residual structure, which generates beyond supervised reconstruction result, whose artifacts are drastically reduced in the output compared to ground-truth. Moreover, two novel losses are designed to restrain the artifacts. The numerical and in-vivo results have demonstrated the performance of our method to reconstruct the full-view image without artifacts.
Reinforcement Learning for Control of Valves
Dec 29, 2020
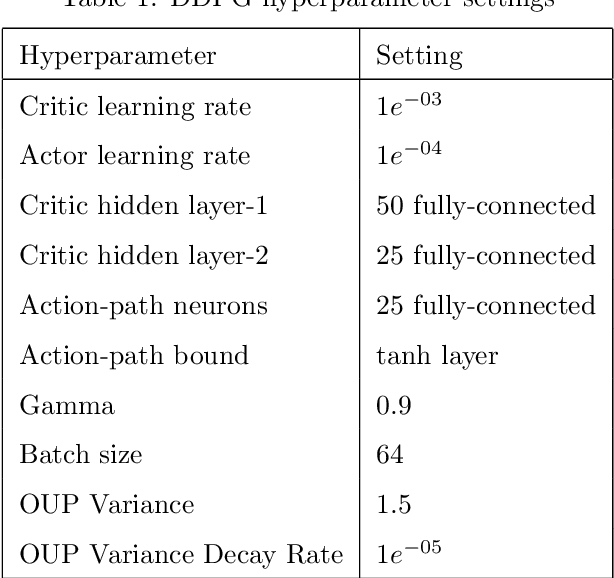
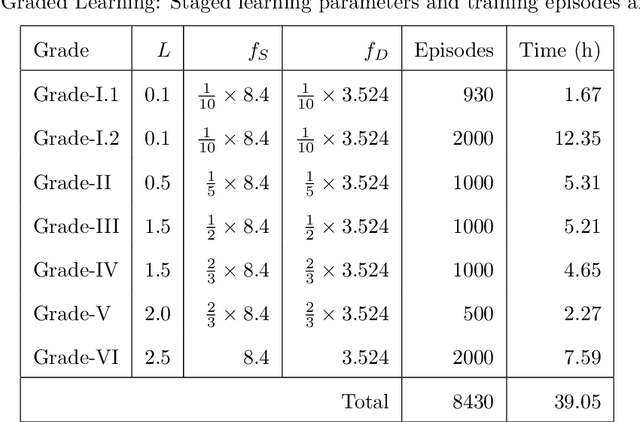
This paper compares reinforcement learning (RL) with PID (proportional-integral-derivative) strategy for control of nonlinear valves using a unified framework. RL is an autonomous learning mechanism that learns by interacting with its environment. It is gaining increasing attention in the world of control systems as a means of building optimal-controllers for challenging dynamic and nonlinear processes. Published RL research often uses open-source tools (Python and OpenAI Gym environments) which could be difficult to adapt and apply by practicing industrial engineers, we therefore used MathWorks tools. MATLAB's recently launched (R2019a) Reinforcement Learning Toolbox was used to develop the valve controller; trained using the DDPG (Deep Deterministic Policy-Gradient) algorithm and Simulink to simulate the nonlinear valve and setup the experimental test-bench to evaluate the RL and PID controllers. Results indicate that the RL controller is extremely good at tracking the signal with speed and produces a lower error with respect to the reference signals. The PID, however, is better at disturbance rejection and hence provides a longer life for the valves. Experiential learnings gained from this research are corroborated against published research. It is known that successful machine learning involves tuning many hyperparameters and significant investment of time and efforts. We introduce ``Graded Learning" as a simplified, application oriented adaptation of the more formal and algorithmic ``Curriculum for Reinforcement Learning''. It is shown via experiments that it helps converge the learning task of complex non-linear real world systems.
Complex networks for event detection in heterogeneous high volume news streams
May 28, 2020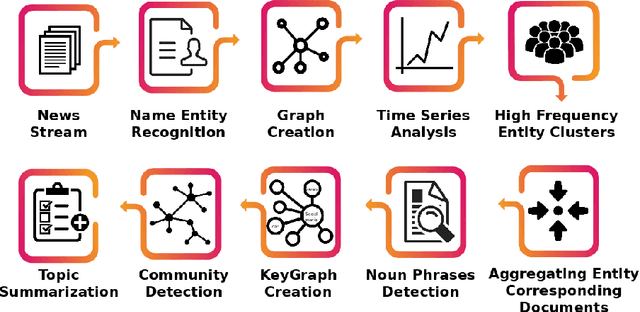
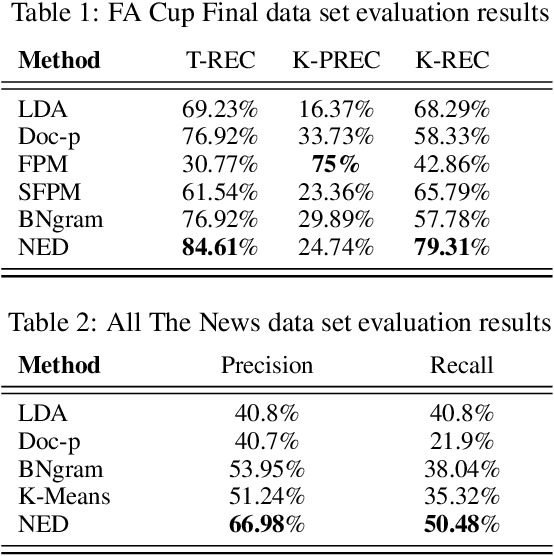
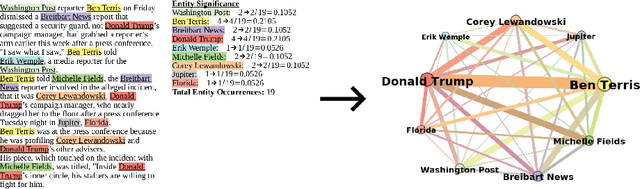
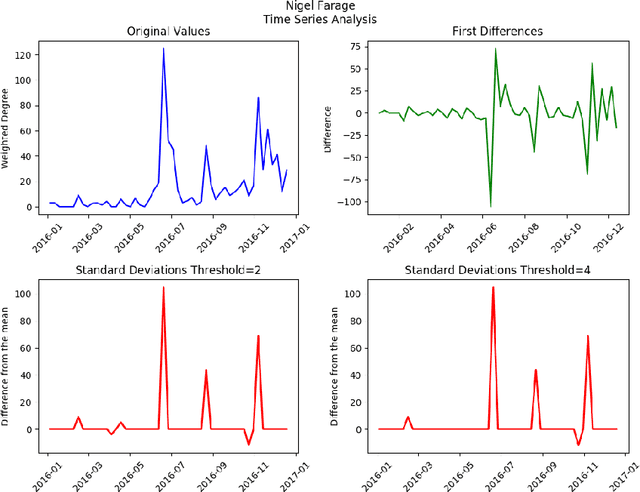
Detecting important events in high volume news streams is an important task for a variety of purposes.The volume and rate of online news increases the need for automated event detection methods thatcan operate in real time. In this paper we develop a network-based approach that makes the workingassumption that important news events always involve named entities (such as persons, locationsand organizations) that are linked in news articles. Our approach uses natural language processingtechniques to detect these entities in a stream of news articles and then creates a time-stamped seriesof networks in which the detected entities are linked by co-occurrence in articles and sentences. Inthis prototype, weighted node degree is tracked over time and change-point detection used to locateimportant events. Potential events are characterized and distinguished using community detectionon KeyGraphs that relate named entities and informative noun-phrases from related articles. Thismethodology already produces promising results and will be extended in future to include a widervariety of complex network analysis techniques.
Abstractive Opinion Tagging
Jan 18, 2021
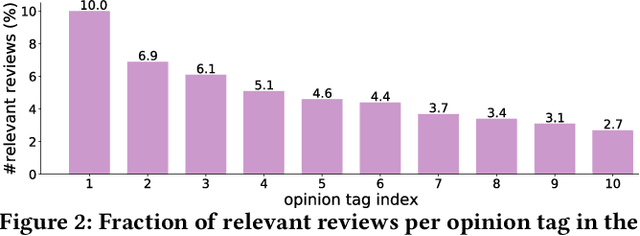
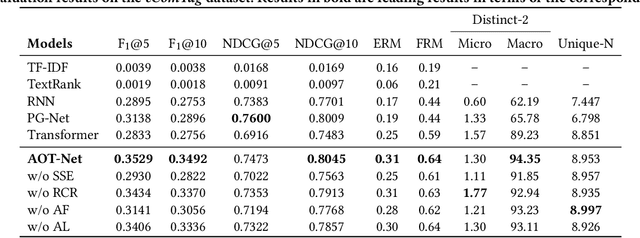
In e-commerce, opinion tags refer to a ranked list of tags provided by the e-commerce platform that reflect characteristics of reviews of an item. To assist consumers to quickly grasp a large number of reviews about an item, opinion tags are increasingly being applied by e-commerce platforms. Current mechanisms for generating opinion tags rely on either manual labelling or heuristic methods, which is time-consuming and ineffective. In this paper, we propose the abstractive opinion tagging task, where systems have to automatically generate a ranked list of opinion tags that are based on, but need not occur in, a given set of user-generated reviews. The abstractive opinion tagging task comes with three main challenges: (1) the noisy nature of reviews; (2) the formal nature of opinion tags vs. the colloquial language usage in reviews; and (3) the need to distinguish between different items with very similar aspects. To address these challenges, we propose an abstractive opinion tagging framework, named AOT-Net, to generate a ranked list of opinion tags given a large number of reviews. First, a sentence-level salience estimation component estimates each review's salience score. Next, a review clustering and ranking component ranks reviews in two steps: first, reviews are grouped into clusters and ranked by cluster size; then, reviews within each cluster are ranked by their distance to the cluster center. Finally, given the ranked reviews, a rank-aware opinion tagging component incorporates an alignment feature and alignment loss to generate a ranked list of opinion tags. To facilitate the study of this task, we create and release a large-scale dataset, called eComTag, crawled from real-world e-commerce websites. Extensive experiments conducted on the eComTag dataset verify the effectiveness of the proposed AOT-Net in terms of various evaluation metrics.
Scalable Discovery of Time-Series Shapelets
Mar 11, 2015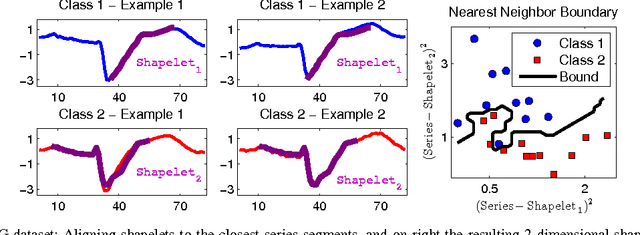
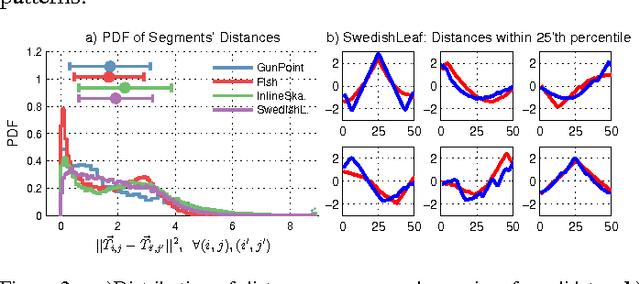
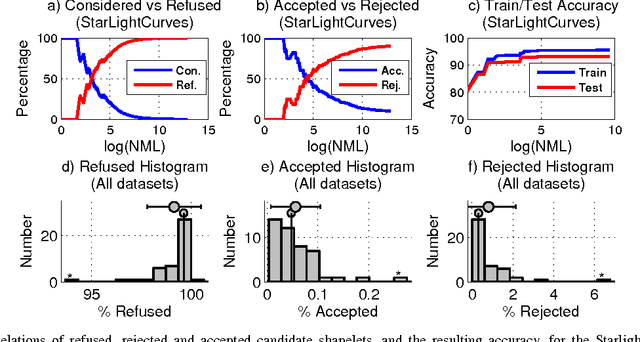
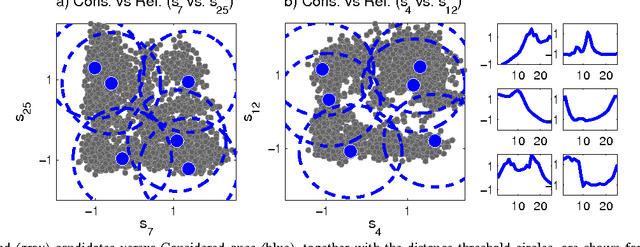
Time-series classification is an important problem for the data mining community due to the wide range of application domains involving time-series data. A recent paradigm, called shapelets, represents patterns that are highly predictive for the target variable. Shapelets are discovered by measuring the prediction accuracy of a set of potential (shapelet) candidates. The candidates typically consist of all the segments of a dataset, therefore, the discovery of shapelets is computationally expensive. This paper proposes a novel method that avoids measuring the prediction accuracy of similar candidates in Euclidean distance space, through an online clustering pruning technique. In addition, our algorithm incorporates a supervised shapelet selection that filters out only those candidates that improve classification accuracy. Empirical evidence on 45 datasets from the UCR collection demonstrate that our method is 3-4 orders of magnitudes faster than the fastest existing shapelet-discovery method, while providing better prediction accuracy.
Knowledge Enhanced Neural Fashion Trend Forecasting
May 07, 2020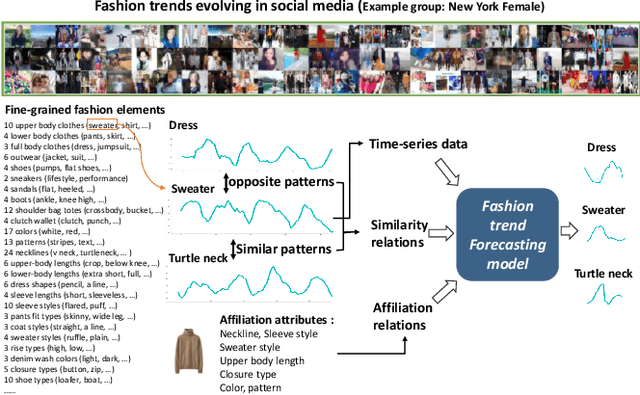
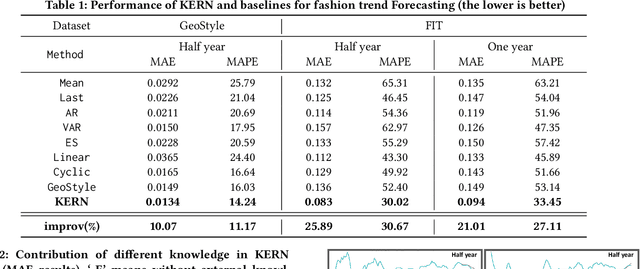
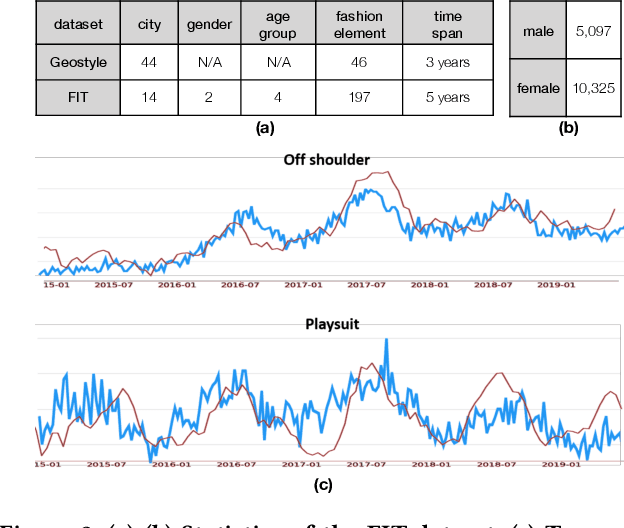
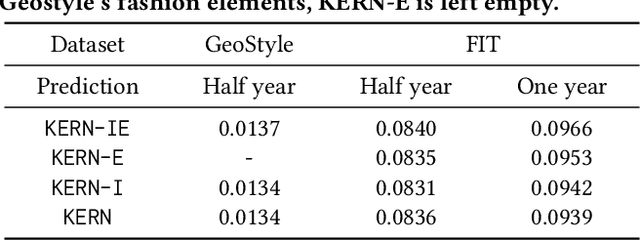
Fashion trend forecasting is a crucial task for both academia and industry. Although some efforts have been devoted to tackling this challenging task, they only studied limited fashion elements with highly seasonal or simple patterns, which could hardly reveal the real fashion trends. Towards insightful fashion trend forecasting, this work focuses on investigating fine-grained fashion element trends for specific user groups. We first contribute a large-scale fashion trend dataset (FIT) collected from Instagram with extracted time series fashion element records and user information. Further-more, to effectively model the time series data of fashion elements with rather complex patterns, we propose a Knowledge EnhancedRecurrent Network model (KERN) which takes advantage of the capability of deep recurrent neural networks in modeling time-series data. Moreover, it leverages internal and external knowledge in fashion domain that affects the time-series patterns of fashion element trends. Such incorporation of domain knowledge further enhances the deep learning model in capturing the patterns of specific fashion elements and predicting the future trends. Extensive experiments demonstrate that the proposed KERN model can effectively capture the complicated patterns of objective fashion elements, therefore making preferable fashion trend forecast.
Generating Gameplay-Relevant Art Assets with Transfer Learning
Oct 04, 2020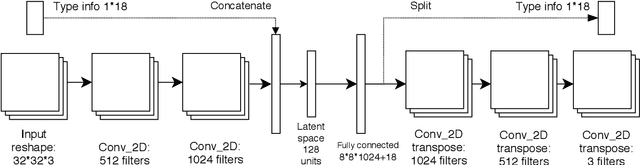

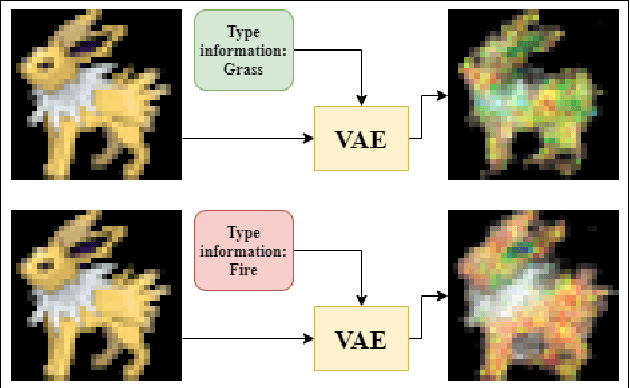

In game development, designing compelling visual assets that convey gameplay-relevant features requires time and experience. Recent image generation methods that create high-quality content could reduce development costs, but these approaches do not consider game mechanics. We propose a Convolutional Variational Autoencoder (CVAE) system to modify and generate new game visuals based on their gameplay relevance. We test this approach with Pok\'emon sprites and Pok\'emon type information, since types are one of the game's core mechanics and they directly impact the game's visuals. Our experimental results indicate that adopting a transfer learning approach can help to improve visual quality and stability over unseen data.
* 7 pages, 8 figures