 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Physics-aware Inference of Cloth Deformation for Monocular Human Performance Capture
Nov 25, 2020
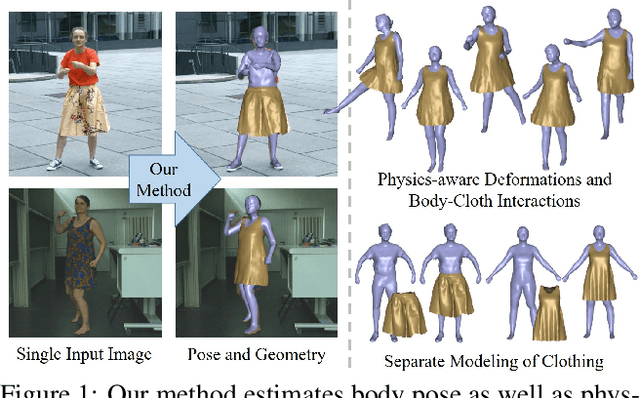
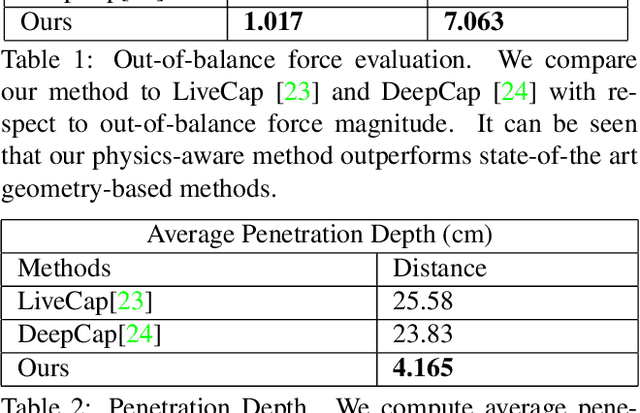
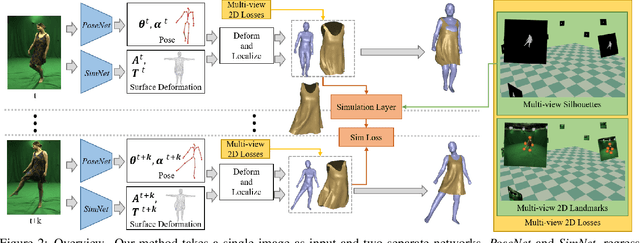

Recent monocular human performance capture approaches have shown compelling dense tracking results of the full body from a single RGB camera. However, existing methods either do not estimate clothing at all or model cloth deformation with simple geometric priors instead of taking into account the underlying physical principles. This leads to noticeable artifacts in their reconstructions, such as baked-in wrinkles, implausible deformations that seemingly defy gravity, and intersections between cloth and body. To address these problems, we propose a person-specific, learning-based method that integrates a finite element-based simulation layer into the training process to provide for the first time physics supervision in the context of weakly-supervised deep monocular human performance capture. We show how integrating physics into the training process improves the learned cloth deformations, allows modeling clothing as a separate piece of geometry, and largely reduces cloth-body intersections. Relying only on weak 2D multi-view supervision during training, our approach leads to a significant improvement over current state-of-the-art methods and is thus a clear step towards realistic monocular capture of the entire deforming surface of a clothed human.
Using Neural Networks and Diversifying Differential Evolution for Dynamic Optimisation
Aug 10, 2020
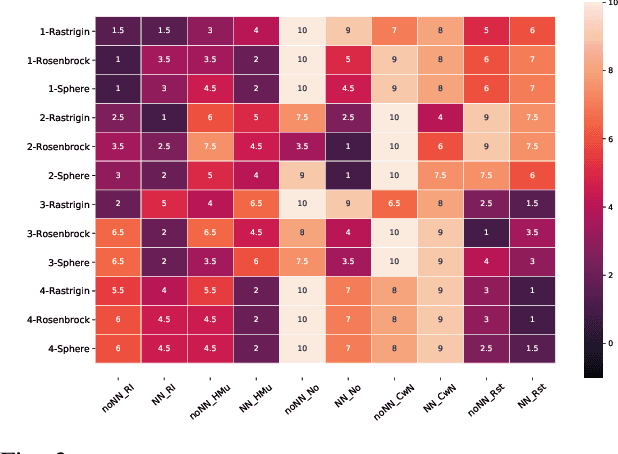
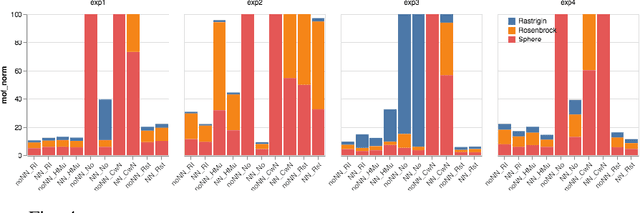
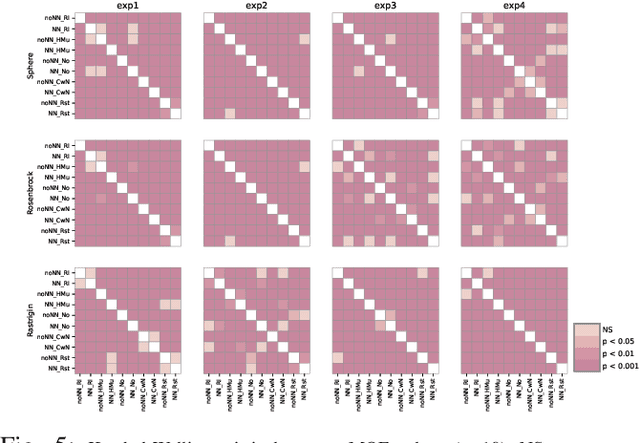
Dynamic optimisation occurs in a variety of real-world problems. To tackle these problems, evolutionary algorithms have been extensively used due to their effectiveness and minimum design effort. However, for dynamic problems, extra mechanisms are required on top of standard evolutionary algorithms. Among them, diversity mechanisms have proven to be competitive in handling dynamism, and recently, the use of neural networks have become popular for this purpose. Considering the complexity of using neural networks in the process compared to simple diversity mechanisms, we investigate whether they are competitive and the possibility of integrating them to improve the results. However, for a fair comparison, we need to consider the same time budget for each algorithm. Thus, instead of the usual number of fitness evaluations as the measure for the available time between changes, we use wall clock timing. The results show the significance of the improvement when integrating the neural network and diversity mechanisms depends on the type and the frequency of changes. Moreover, we observe that for differential evolution, having a proper diversity in population when using neural networks plays a key role in the neural network's ability to improve the results.
Cross-Modal Generalization: Learning in Low Resource Modalities via Meta-Alignment
Dec 04, 2020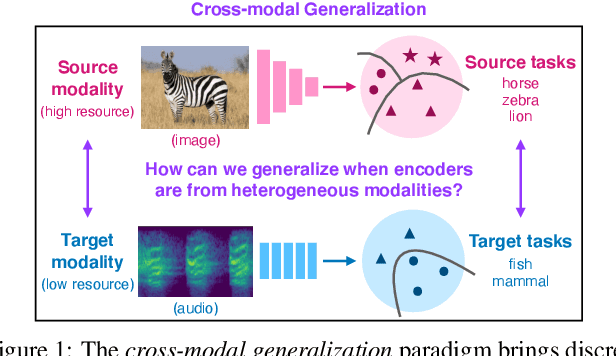
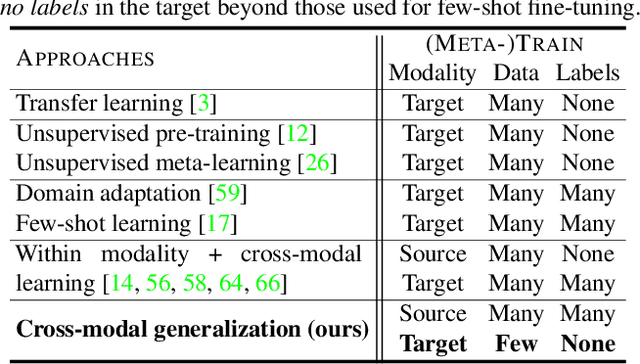
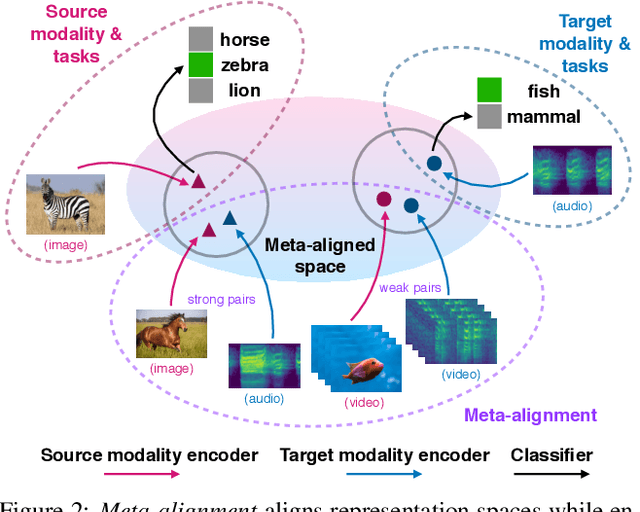
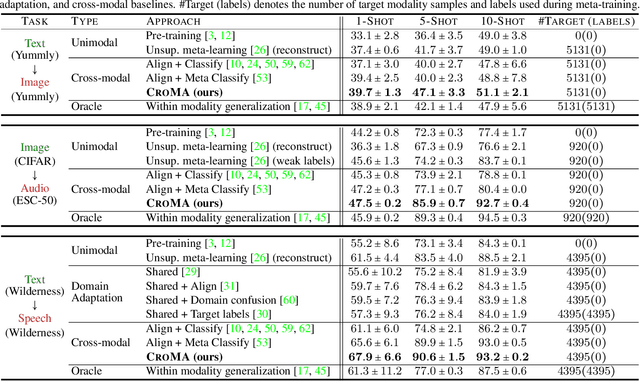
The natural world is abundant with concepts expressed via visual, acoustic, tactile, and linguistic modalities. Much of the existing progress in multimodal learning, however, focuses primarily on problems where the same set of modalities are present at train and test time, which makes learning in low-resource modalities particularly difficult. In this work, we propose algorithms for cross-modal generalization: a learning paradigm to train a model that can (1) quickly perform new tasks in a target modality (i.e. meta-learning) and (2) doing so while being trained on a different source modality. We study a key research question: how can we ensure generalization across modalities despite using separate encoders for different source and target modalities? Our solution is based on meta-alignment, a novel method to align representation spaces using strongly and weakly paired cross-modal data while ensuring quick generalization to new tasks across different modalities. We study this problem on 3 classification tasks: text to image, image to audio, and text to speech. Our results demonstrate strong performance even when the new target modality has only a few (1-10) labeled samples and in the presence of noisy labels, a scenario particularly prevalent in low-resource modalities.
Placement in Integrated Circuits using Cyclic Reinforcement Learning and Simulated Annealing
Nov 15, 2020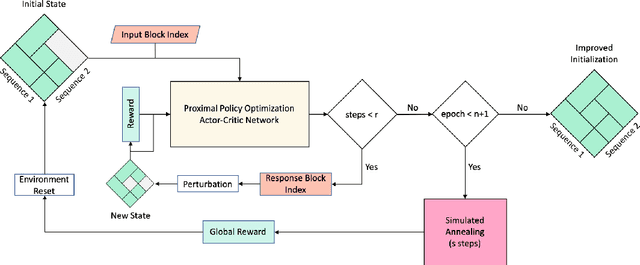
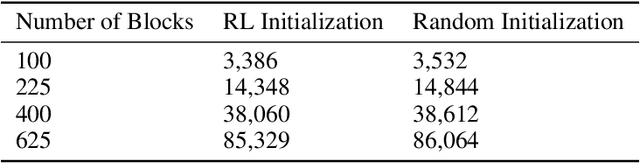
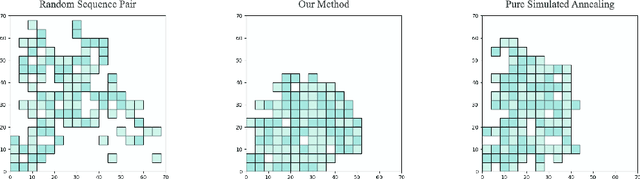

Physical design and production of Integrated Circuits (IC) is becoming increasingly more challenging as the sophistication in IC technology is steadily increasing. Placement has been one of the most critical steps in IC physical design. Through decades of research, partition-based, analytical-based and annealing-based placers have been enriching the placement solution toolbox. However, open challenges including long run time and lack of ability to generalize continue to restrict wider applications of existing placement tools. We devise a learning-based placement tool based on cyclic application of Reinforcement Learning (RL) and Simulated Annealing (SA) by leveraging the advancement of RL. Results show that the RL module is able to provide a better initialization for SA and thus leads to a better final placement design. Compared to other recent learning-based placers, our method is majorly different with its combination of RL and SA. It leverages the RL model's ability to quickly get a good rough solution after training and the heuristic's ability to realize greedy improvements in the solution.
High Definition image classification in Geoscience using Machine Learning
Sep 25, 2020
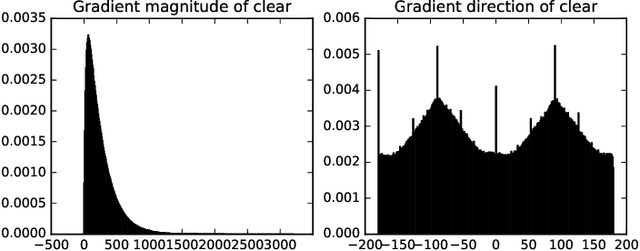
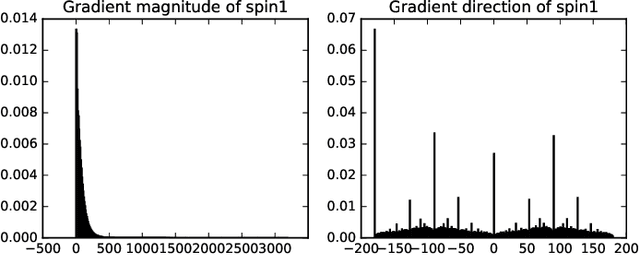

High Definition (HD) digital photos taken with drones are widely used in the study of Geoscience. However, blurry images are often taken in collected data, and it takes a lot of time and effort to distinguish clear images from blurry ones. In this work, we apply Machine learning techniques, such as Support Vector Machine (SVM) and Neural Network (NN) to classify HD images in Geoscience as clear and blurry, and therefore automate data cleaning in Geoscience. We compare the results of classification based on features abstracted from several mathematical models. Some of the implementation of our machine learning tool is freely available at: https://github.com/zachgolden/geoai.
RussianSuperGLUE: A Russian Language Understanding Evaluation Benchmark
Oct 29, 2020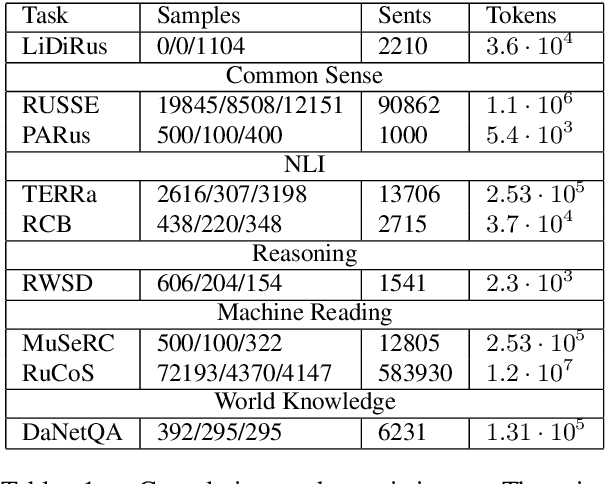

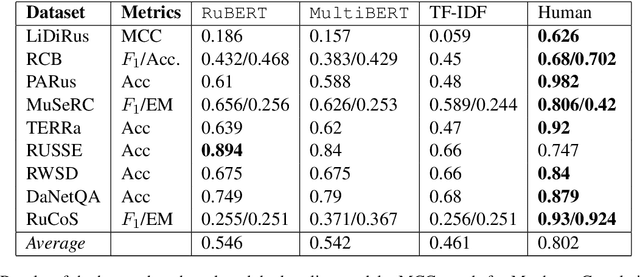

In this paper, we introduce an advanced Russian general language understanding evaluation benchmark -- RussianGLUE. Recent advances in the field of universal language models and transformers require the development of a methodology for their broad diagnostics and testing for general intellectual skills - detection of natural language inference, commonsense reasoning, ability to perform simple logical operations regardless of text subject or lexicon. For the first time, a benchmark of nine tasks, collected and organized analogically to the SuperGLUE methodology, was developed from scratch for the Russian language. We provide baselines, human level evaluation, an open-source framework for evaluating models (https://github.com/RussianNLP/RussianSuperGLUE), and an overall leaderboard of transformer models for the Russian language. Besides, we present the first results of comparing multilingual models in the adapted diagnostic test set and offer the first steps to further expanding or assessing state-of-the-art models independently of language.
Asynchronous Deep Model Reference Adaptive Control
Nov 04, 2020



In this paper, we present Asynchronous implementation of Deep Neural Network-based Model Reference Adaptive Control (DMRAC). We evaluate this new neuro-adaptive control architecture through flight tests on a small quadcopter. We demonstrate that a single DMRAC controller can handle significant nonlinearities due to severe system faults and deliberate wind disturbances while executing high-bandwidth attitude control. We also show that the architecture has long-term learning abilities across different flight regimes, and can generalize to fly different flight trajectories than those on which it was trained. These results demonstrating the efficacy of this architecture for high bandwidth closed-loop attitude control of unstable and nonlinear robots operating in adverse situations. To achieve these results, we designed a software+communication architecture to ensure online real-time inference of the deep network on a high-bandwidth computation-limited platform. We expect that this architecture will benefit other deep learning in the closed-loop experiments on robots.
Spatial-Temporal Dynamic Graph Attention Networks for Ride-hailing Demand Prediction
Jun 07, 2020
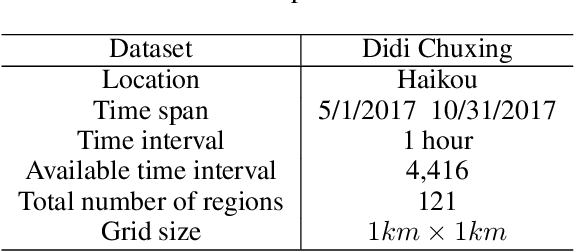
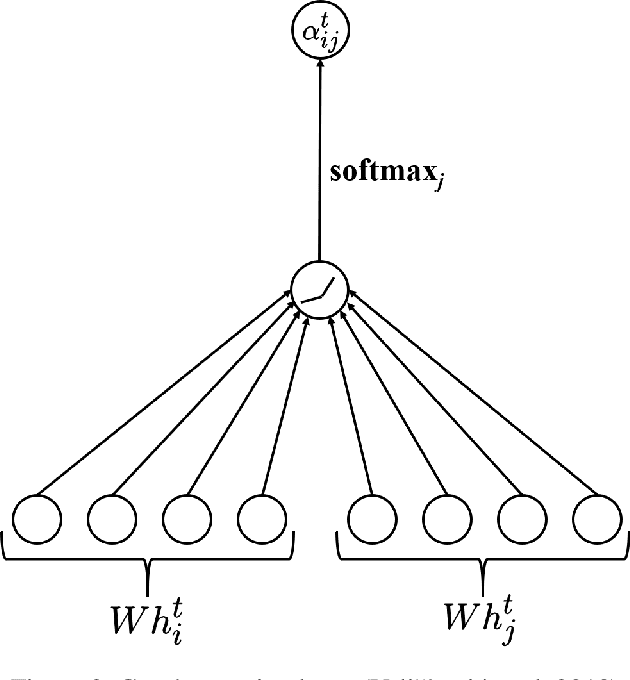
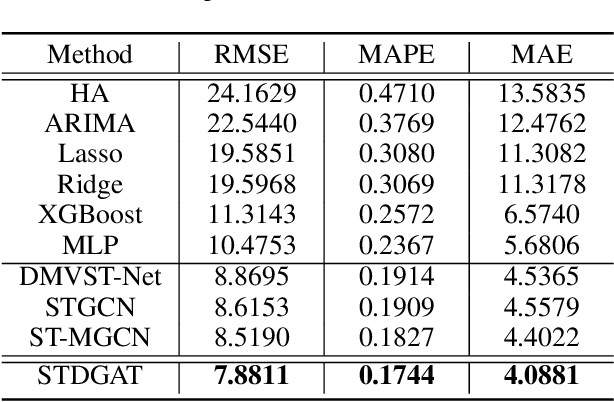
Ride-hailing demand prediction is an important prediction task in traffic prediction. An accurate prediction model can help the platform pre-allocate resources in advance to improve vehicle utilization and reduce the wait-time. This task is challenging due to the complicated spatial-temporal relationships among regions. Most existing methods mainly focus on Euclidean correlations among regions. Though there are some methods that use Graph Convolutional Networks (GCN) to capture the non-Euclidean pair-wise correlations, they only rely on the static topological structure among regions. Besides, they only consider fixed graph structures at different time intervals. In this paper, we propose a novel deep learning method called Spatial-Temporal Dynamic Graph Attention Network (STDGAT) to predict the taxi demand of multiple connected regions in the near future. The method uses Graph Attention Network (GAT), which achieves the adaptive allocation of weights for other regions, to capture the spatial information. Furthermore, we implement a Dynamic Graph Attention mode to capture the different spatial relationships at different time intervals based on the actual commuting relationships. Extensive experiments are conducted on a real-world large scale ride-hailing demand dataset, the results demonstrate the superiority of our method over existing methods.
FDRN: A Fast Deformable Registration Network for Medical Images
Nov 04, 2020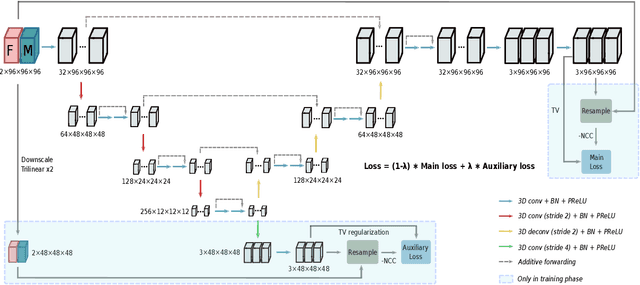
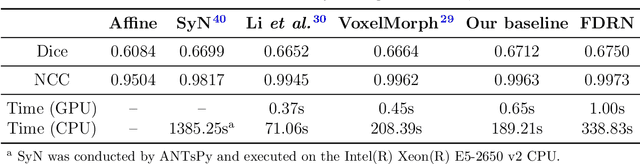
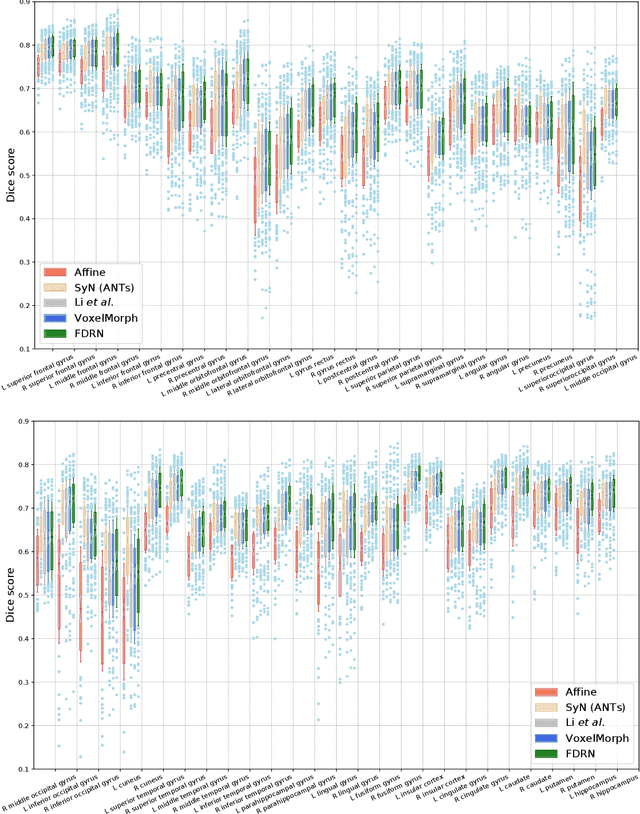
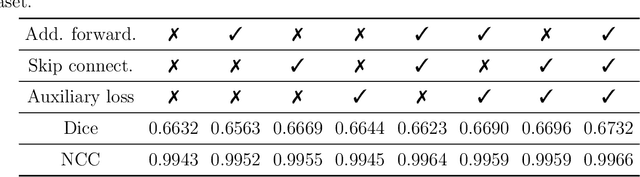
Deformable image registration is a fundamental task in medical imaging. Due to the large computational complexity of deformable registration of volumetric images, conventional iterative methods usually face the tradeoff between the registration accuracy and the computation time in practice. In order to boost the registration performance in both accuracy and runtime, we propose a fast unsupervised convolutional neural network for deformable image registration. Specially, the proposed FDRN possesses a compact encoder-decoder structure and exploits deep supervision, additive forwarding and residual learning. We conducted comparison with the existing state-of-the-art registration methods on the LPBA40 brain MRI dataset. Experimental results demonstrate that our FDRN performs better than the investigated methods qualitatively and quantitatively in Dice score and normalized cross correlation (NCC). Besides, FDRN is a generalized framework for image registration which is not confined to a particular type of medical images or anatomy. It can also be applied to other anatomical structures or CT images.
Recent Developments in Detection of Central Serous Retinopathy through Imaging and Artificial Intelligence Techniques A Review
Dec 20, 2020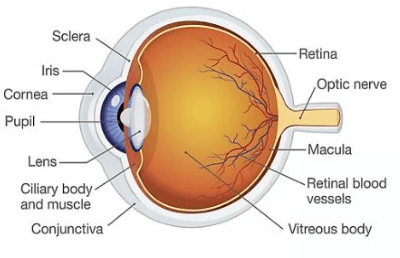
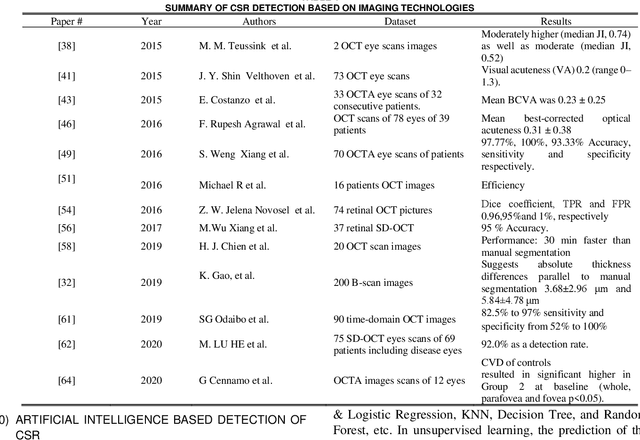
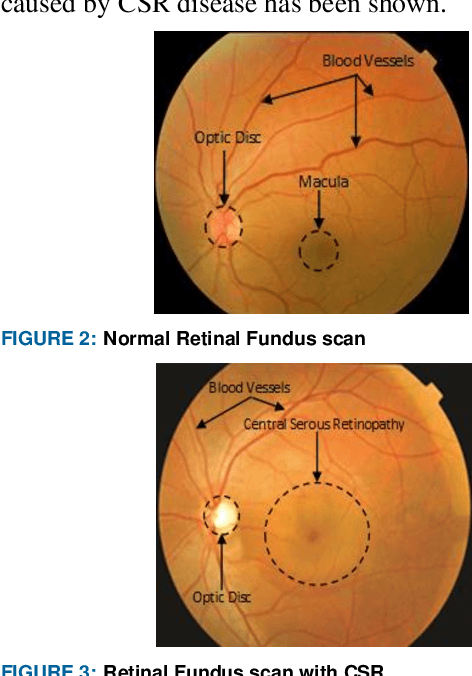
The Central Serous Retinopathy (CSR) is a major significant disease responsible for causing blindness and vision loss among numerous people across the globe. This disease is also known as the Central Serous Chorioretinopathy (CSC) occurs due to the accumulation of watery fluids behind the retina. The detection of CSR at an early stage allows taking preventive measures to avert any impairment to the human eye. Traditionally, several manual detection methods were developed for observing CSR, but they were proven to be inaccurate, unreliable, and time-consuming. Consequently, the research community embarked on seeking automated solutions for CSR detection. With the advent of modern technology in the 21st century, Artificial Intelligence (AI) techniques are immensely popular in numerous research fields including the automated CSR detection. This paper offers a comprehensive review of various advanced technologies and researches, contributing to the automated CSR detection in this scenario. Additionally, it discusses the benefits and limitations of many classical imaging methods ranging from Optical Coherence Tomography (OCT) and the Fundus imaging, to more recent approaches like AI based Machine/Deep Learning techniques. Study primary objective is to analyze and compare many Artificial Intelligence (AI) algorithms that have efficiently achieved automated CSR detection using OCT imaging. Furthermore, it describes various retinal datasets and strategies proposed for CSR assessment and accuracy. Finally, it is concluded that the most recent Deep Learning (DL) classifiers are performing accurate, fast, and reliable detection of CSR.