 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
End-to-End Video Instance Segmentation with Transformers
Dec 04, 2020
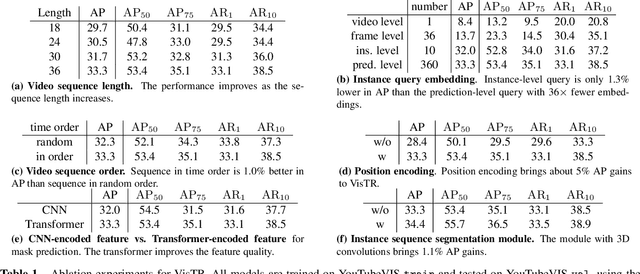
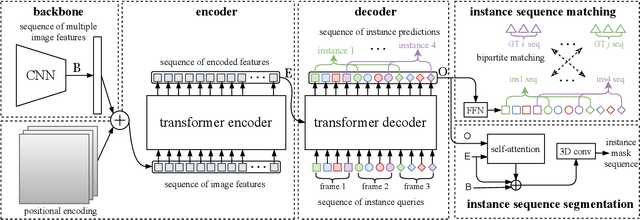
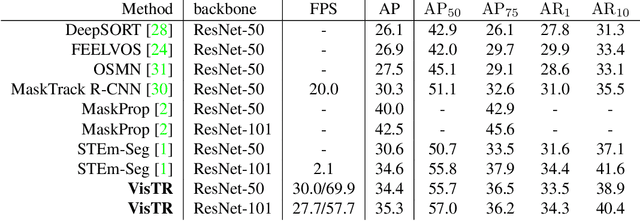

Video instance segmentation (VIS) is the task that requires simultaneously classifying, segmenting and tracking object instances of interest in video. Recent methods typically develop sophisticated pipelines to tackle this task. Here, we propose a new video instance segmentation framework built upon Transformers, termed VisTR, which views the VIS task as a direct end-to-end parallel sequence decoding/prediction problem. Given a video clip consisting of multiple image frames as input, VisTR outputs the sequence of masks for each instance in the video in order directly. At the core is a new, effective instance sequence matching and segmentation strategy, which supervises and segments instances at the sequence level as a whole. VisTR frames the instance segmentation and tracking in the same perspective of similarity learning, thus considerably simplifying the overall pipeline and is significantly different from existing approaches. Without bells and whistles, VisTR achieves the highest speed among all existing VIS models, and achieves the best result among methods using single model on the YouTube-VIS dataset. For the first time, we demonstrate a much simpler and faster video instance segmentation framework built upon Transformers, achieving competitive accuracy. We hope that VisTR can motivate future research for more video understanding tasks.
Asynchronous Deep Model Reference Adaptive Control
Nov 04, 2020



In this paper, we present Asynchronous implementation of Deep Neural Network-based Model Reference Adaptive Control (DMRAC). We evaluate this new neuro-adaptive control architecture through flight tests on a small quadcopter. We demonstrate that a single DMRAC controller can handle significant nonlinearities due to severe system faults and deliberate wind disturbances while executing high-bandwidth attitude control. We also show that the architecture has long-term learning abilities across different flight regimes, and can generalize to fly different flight trajectories than those on which it was trained. These results demonstrating the efficacy of this architecture for high bandwidth closed-loop attitude control of unstable and nonlinear robots operating in adverse situations. To achieve these results, we designed a software+communication architecture to ensure online real-time inference of the deep network on a high-bandwidth computation-limited platform. We expect that this architecture will benefit other deep learning in the closed-loop experiments on robots.
FDRN: A Fast Deformable Registration Network for Medical Images
Nov 04, 2020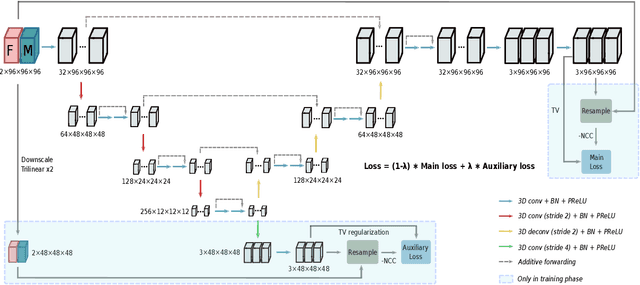
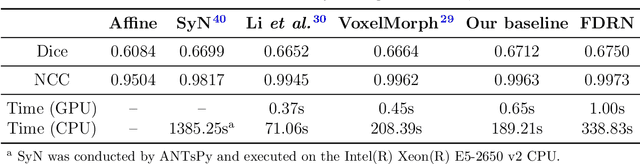
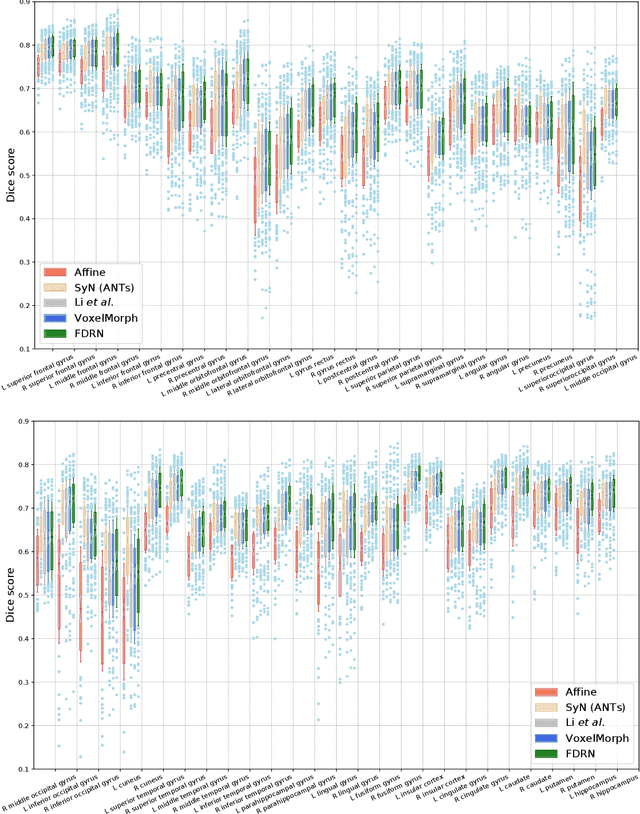
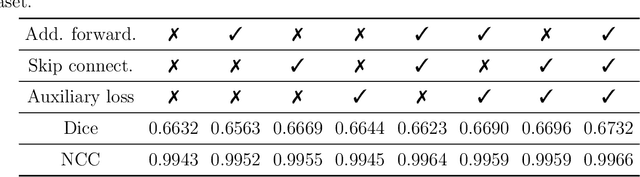
Deformable image registration is a fundamental task in medical imaging. Due to the large computational complexity of deformable registration of volumetric images, conventional iterative methods usually face the tradeoff between the registration accuracy and the computation time in practice. In order to boost the registration performance in both accuracy and runtime, we propose a fast unsupervised convolutional neural network for deformable image registration. Specially, the proposed FDRN possesses a compact encoder-decoder structure and exploits deep supervision, additive forwarding and residual learning. We conducted comparison with the existing state-of-the-art registration methods on the LPBA40 brain MRI dataset. Experimental results demonstrate that our FDRN performs better than the investigated methods qualitatively and quantitatively in Dice score and normalized cross correlation (NCC). Besides, FDRN is a generalized framework for image registration which is not confined to a particular type of medical images or anatomy. It can also be applied to other anatomical structures or CT images.
Tick: a Python library for statistical learning, with a particular emphasis on time-dependent modelling
Mar 15, 2018

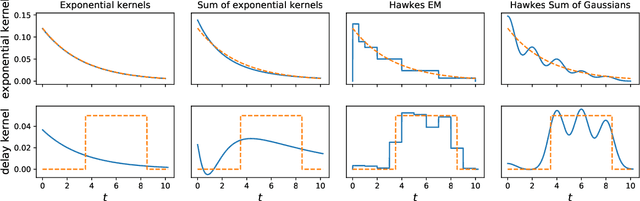
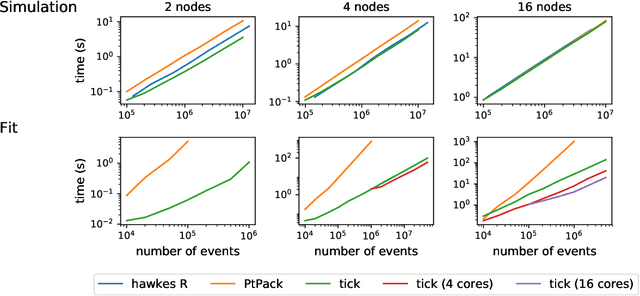
Tick is a statistical learning library for Python~3, with a particular emphasis on time-dependent models, such as point processes, and tools for generalized linear models and survival analysis. The core of the library is an optimization module providing model computational classes, solvers and proximal operators for regularization. tick relies on a C++ implementation and state-of-the-art optimization algorithms to provide very fast computations in a single node multi-core setting. Source code and documentation can be downloaded from https://github.com/X-DataInitiative/tick
Detecting an Odd Restless Markov Arm with a Trembling Hand
May 13, 2020
In this paper, we consider a multi-armed bandit in which each arm is a Markov process evolving on a finite state space. The state space is common across the arms, and the arms are independent of each other. The transition probability matrix of one of the arms (the odd arm) is different from the common transition probability matrix of all the other arms. A decision maker, who knows these transition probability matrices, wishes to identify the odd arm as quickly as possible, while keeping the probability of decision error small. To do so, the decision maker collects observations from the arms by pulling the arms in a sequential manner, one at each discrete time instant. However, the decision maker has a trembling hand, and the arm that is actually pulled at any given time differs, with a small probability, from the one he intended to pull. The observation at any given time is the arm that is actually pulled and its current state. The Markov processes of the unobserved arms continue to evolve. This makes the arms restless. For the above setting, we derive the first known asymptotic lower bound on the expected stopping time, where the asymptotics is of vanishing error probability. The continued evolution of each arm adds a new dimension to the problem, leading to a family of Markov decision problems (MDPs) on a countable state space. We then stitch together certain parameterised solutions to these MDPs and obtain a sequence of strategies whose expected stopping times come arbitrarily close to the lower bound in the regime of vanishing error probability. Prior works dealt with independent and identically distributed (across time) arms and rested Markov arms, whereas our work deals with restless Markov arms.
High Definition image classification in Geoscience using Machine Learning
Sep 25, 2020
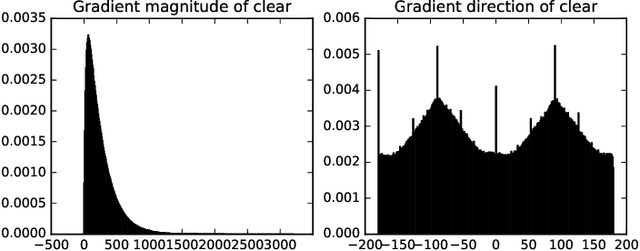
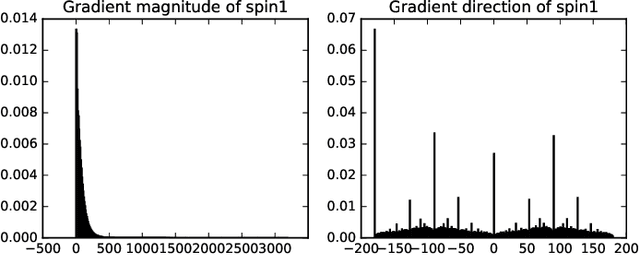

High Definition (HD) digital photos taken with drones are widely used in the study of Geoscience. However, blurry images are often taken in collected data, and it takes a lot of time and effort to distinguish clear images from blurry ones. In this work, we apply Machine learning techniques, such as Support Vector Machine (SVM) and Neural Network (NN) to classify HD images in Geoscience as clear and blurry, and therefore automate data cleaning in Geoscience. We compare the results of classification based on features abstracted from several mathematical models. Some of the implementation of our machine learning tool is freely available at: https://github.com/zachgolden/geoai.
RobustPointSet: A Dataset for Benchmarking Robustness of Point Cloud Classifiers
Nov 25, 2020
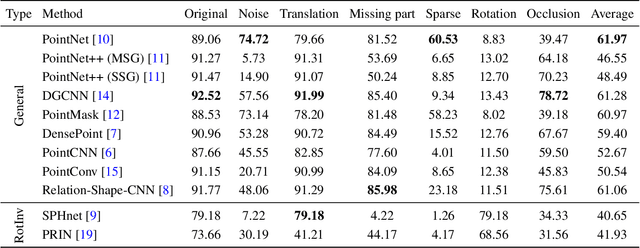

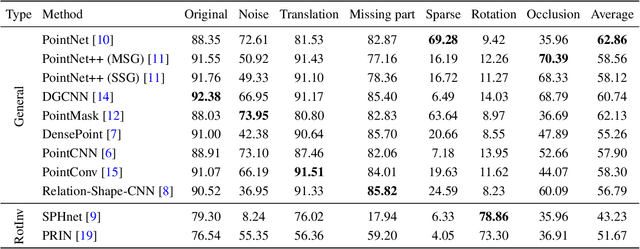
The 3D deep learning community has seen significant strides in pointcloud processing over the last few years. However, the datasets on which deep models have been trained have largely remained the same. Most datasets comprise clean, clutter-free pointclouds canonicalized for pose. Models trained on these datasets fail in uninterpretible and unintuitive ways when presented with data that contains transformations "unseen" at train time. While data augmentation enables models to be robust to "previously seen" input transformations, 1) we show that this does not work for unseen transformations during inference, and 2) data augmentation makes it difficult to analyze a model's inherent robustness to transformations. To this end, we create a publicly available dataset for robustness analysis of point cloud classification models (independent of data augmentation) to input transformations, called RobustPointSet. Our experiments indicate that despite all the progress in the point cloud classification, there is no single architecture that consistently performs better---several fail drastically---when evaluated on transformed test sets. We also find that robustness to unseen transformations cannot be brought about merely by extensive data augmentation. RobustPointSet can be accessed through https://github.com/AutodeskAILab/RobustPointSet.
Using Neural Networks and Diversifying Differential Evolution for Dynamic Optimisation
Aug 10, 2020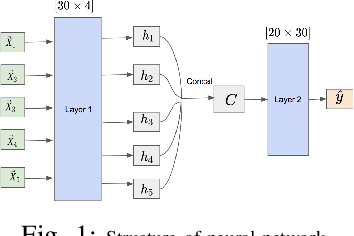
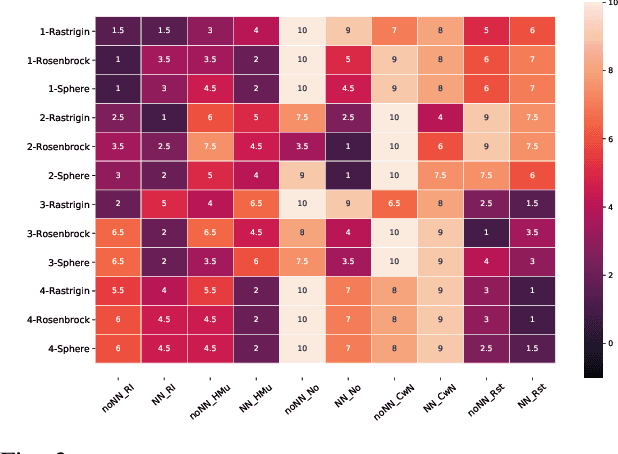
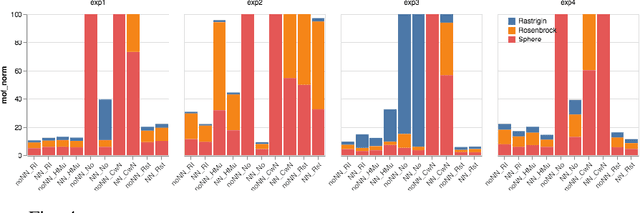
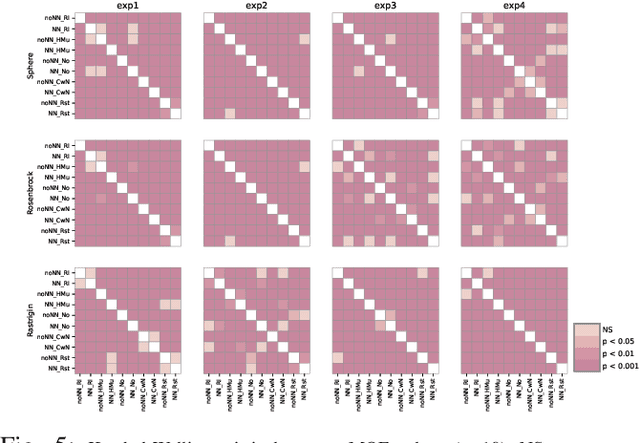
Dynamic optimisation occurs in a variety of real-world problems. To tackle these problems, evolutionary algorithms have been extensively used due to their effectiveness and minimum design effort. However, for dynamic problems, extra mechanisms are required on top of standard evolutionary algorithms. Among them, diversity mechanisms have proven to be competitive in handling dynamism, and recently, the use of neural networks have become popular for this purpose. Considering the complexity of using neural networks in the process compared to simple diversity mechanisms, we investigate whether they are competitive and the possibility of integrating them to improve the results. However, for a fair comparison, we need to consider the same time budget for each algorithm. Thus, instead of the usual number of fitness evaluations as the measure for the available time between changes, we use wall clock timing. The results show the significance of the improvement when integrating the neural network and diversity mechanisms depends on the type and the frequency of changes. Moreover, we observe that for differential evolution, having a proper diversity in population when using neural networks plays a key role in the neural network's ability to improve the results.
RotNet: Fast and Scalable Estimation of Stellar Rotation Periods Using Convolutional Neural Networks
Dec 04, 2020
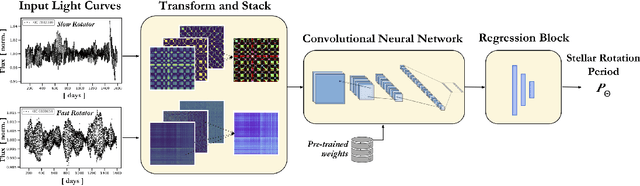
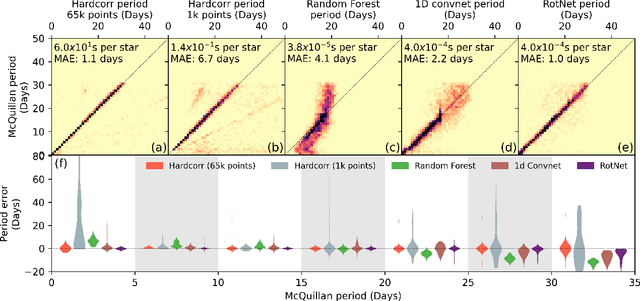
Magnetic activity in stars manifests as dark spots on their surfaces that modulate the brightness observed by telescopes. These light curves contain important information on stellar rotation. However, the accurate estimation of rotation periods is computationally expensive due to scarce ground truth information, noisy data, and large parameter spaces that lead to degenerate solutions. We harness the power of deep learning and successfully apply Convolutional Neural Networks to regress stellar rotation periods from Kepler light curves. Geometry-preserving time-series to image transformations of the light curves serve as inputs to a ResNet-18 based architecture which is trained through transfer learning. The McQuillan catalog of published rotation periods is used as ansatz to groundtruth. We benchmark the performance of our method against a random forest regressor, a 1D CNN, and the Auto-Correlation Function (ACF) - the current standard to estimate rotation periods. Despite limiting our input to fewer data points (1k), our model yields more accurate results and runs 350 times faster than ACF runs on the same number of data points and 10,000 times faster than ACF runs on 65k data points. With only minimal feature engineering our approach has impressive accuracy, motivating the application of deep learning to regress stellar parameters on an even larger scale
Sparse R-CNN: End-to-End Object Detection with Learnable Proposals
Nov 25, 2020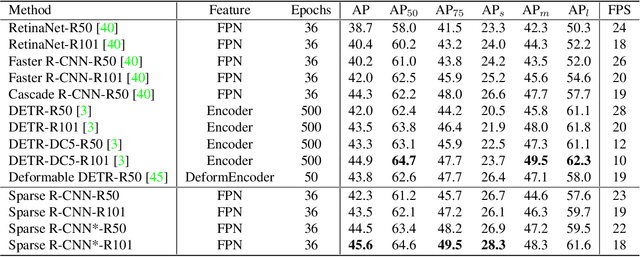
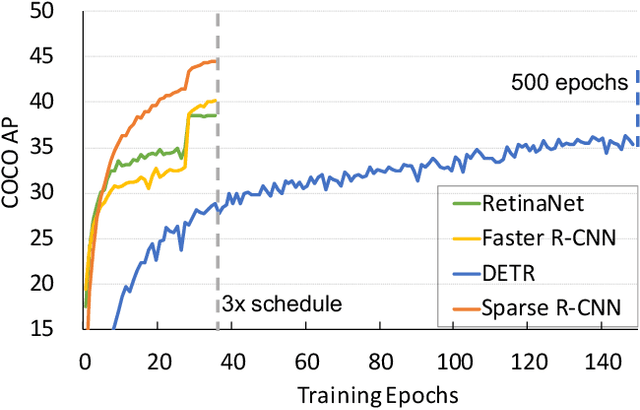

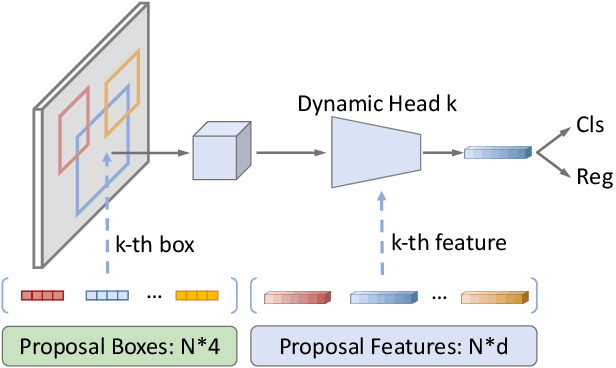
We present Sparse R-CNN, a purely sparse method for object detection in images. Existing works on object detection heavily rely on dense object candidates, such as $k$ anchor boxes pre-defined on all grids of image feature map of size $H\times W$. In our method, however, a fixed sparse set of learned object proposals, total length of $N$, are provided to object recognition head to perform classification and location. By eliminating $HWk$ (up to hundreds of thousands) hand-designed object candidates to $N$ (e.g. 100) learnable proposals, Sparse R-CNN completely avoids all efforts related to object candidates design and many-to-one label assignment. More importantly, final predictions are directly output without non-maximum suppression post-procedure. Sparse R-CNN demonstrates accuracy, run-time and training convergence performance on par with the well-established detector baselines on the challenging COCO dataset, e.g., achieving 44.5 AP in standard $3\times$ training schedule and running at 22 fps using ResNet-50 FPN model. We hope our work could inspire re-thinking the convention of dense prior in object detectors. The code is available at: https://github.com/PeizeSun/SparseR-CNN.